







-
导入所需的库和模块,如requests、json等。这些库可以帮助你发送HTTP请求和解析HTML页面。

-
使用requests库发送一个GET请求到新发地的网站,获取网页的内容。

-
提取所需的价格信息,并进行处理或存储,以便后续使用。
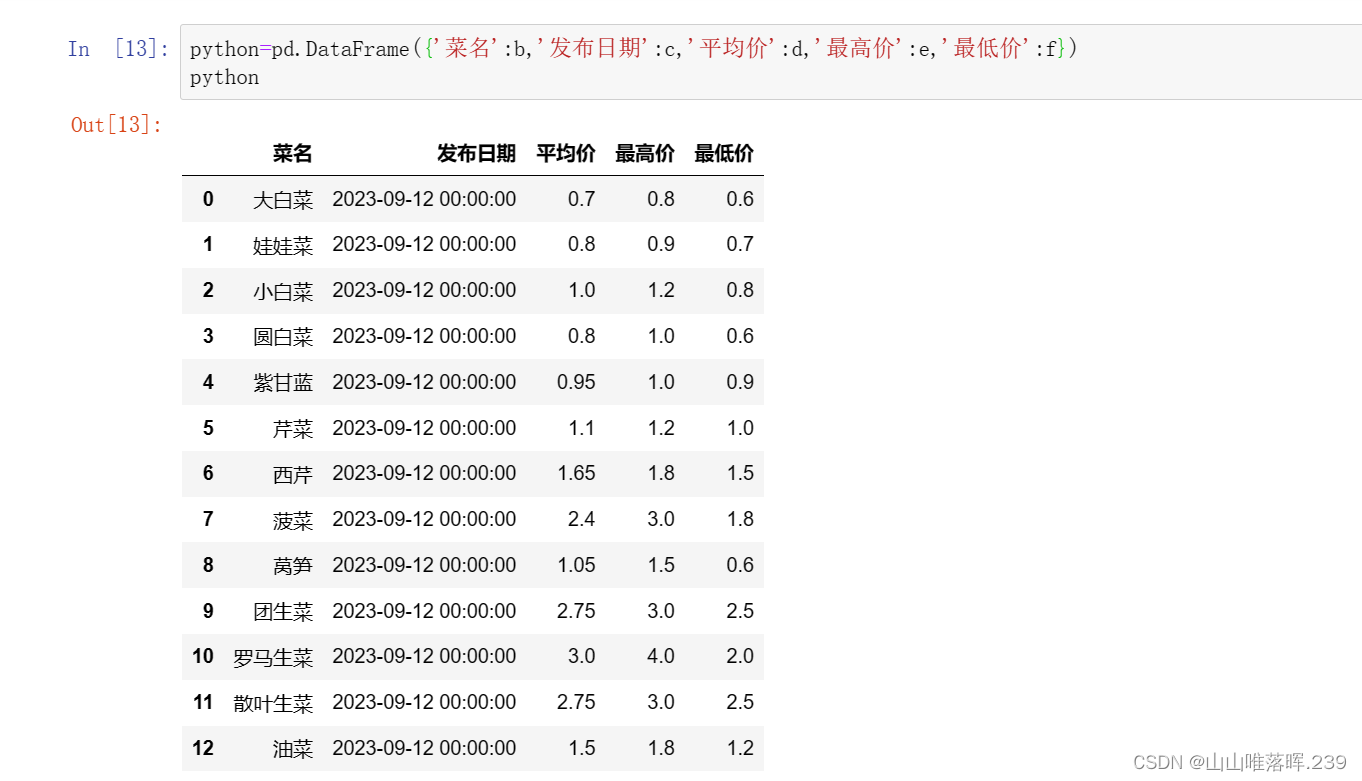
-
完整代码
#导入需要的库 import requests import json import pandas as pd #获取网页 rq=requests.get('http://www.xinfadi.com.cn/getCat.html').content.decode('utf-8') rq type(rq) data=json.loads(rq) data data['list'] #提取需要的信息 b=[i['prodName'] for i in data['list']] b c=[i['pubDate'] for i in data['list']] c d=[i['avgPrice'] for i in data['list']] d e=[i['highPrice'] for i in data['list']] e f=[i['lowPrice'] for i in data['list']] f python=pd.DataFrame({'菜名':b,'发布日期':c,'平均价':d,'最高价':e,'最低价':f}) python
















07-29
 7406
7406
7406
10-28
1万+
1万+
07-20
107
107
07-17
567
567
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









