






一、引言
在日常使用网易云音乐的过程中,小编常常遇到这样的困扰:当 VIP 会员过期后,曾经下载的音乐便无法播放,想听的歌曲仿佛被上了锁,这让听歌体验大打折扣。为了能够随时畅听喜爱的歌曲,不再受会员期限的束缚,小编决定花费 2.88 元巨资购买 VIP 会员,趁着会员有效期内,将心仪的歌曲下载到本地保存。
在这个过程中,小编深入研究了网易云音乐的数据获取机制,发现其中涉及到诸多有趣的技术细节。于是,便萌生了将整个探索过程记录下来的想法,希望通过这篇文章,和大家分享如何在合规合法的前提下,将 VIP 期间可听的歌曲进行下载保存
本文将详细解析爬取网易云音乐网站数据的流程,旨在为相关学习与研究提供参考。需强调的是,本文内容仅用于学习交流,严禁任何违法行为。
二、整体流程概述
在 Python 文件中,主要使用以下几个库:
- httpx:用于发起网络请求,实现与网易云音乐服务器的数据交互。
- execjs:调用外部 JavaScript 文件(如demo.js),借助 JavaScript 的功能处理数据,例如加密参数的生成。
- os:用于文件和目录操作,如创建存储下载歌曲的文件夹。
- re:通过正则表达式匹配并删除音乐歌名中不符合标准的符号,确保文件名的合法性。
爬取网易云音乐网站数据的整体流程主要包含以下几个步骤:
- 发送请求,获取包含音乐列表信息的 JSON 数据。
- 解析 JSON 数据,从中提取歌曲的 ID(song_id)等关键信息。
- 通过特定的媒体链接,找到所需歌曲的请求数据,获取歌曲的下载链接。
- 发送请求获取歌曲内容,并将其保存到本地。
接下来,将结合具体代码详细阐述每个步骤。
1.(1)分析音乐列表组成并尝试解密
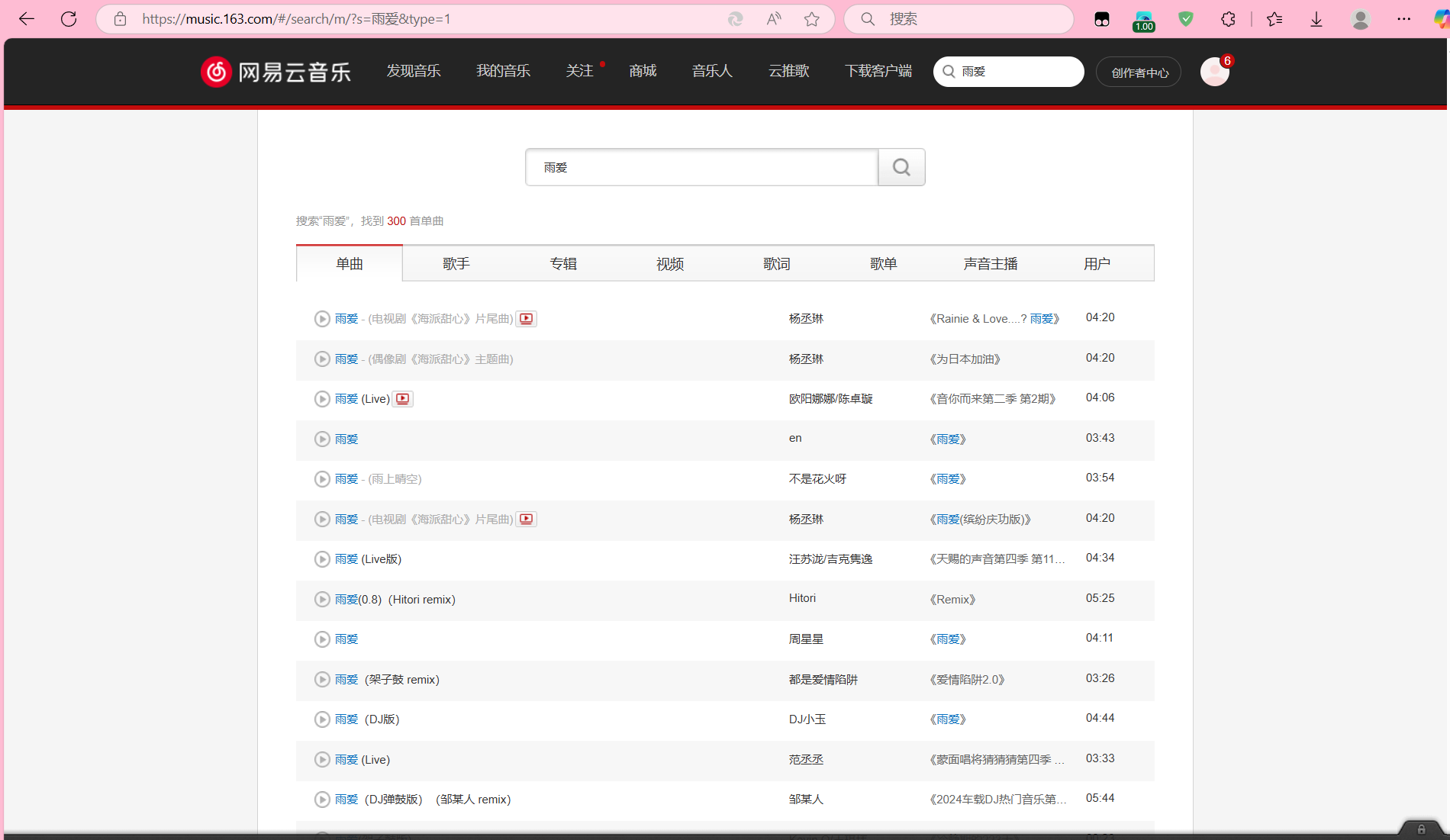
通过在关键词进入列表后我们可以看见一个歌曲表单,这就是我们这一步需要获取的东西。首先打开f12进入开发者模式进行查找这个歌单是怎么得来的
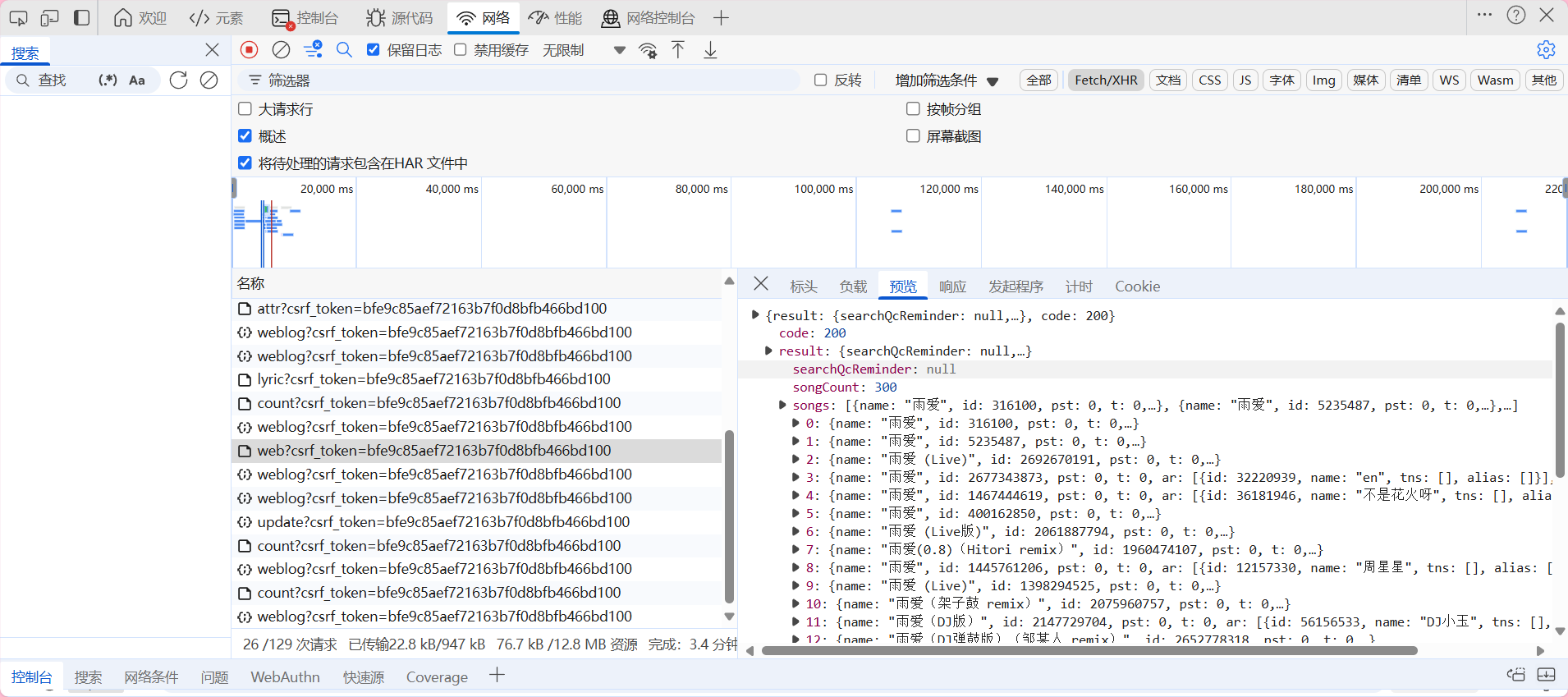
通过查找后发现这个表单并不在文档里,而是通过接口返回的json中(如上图)那么我们现在就是要通过请求获取到该链接的json
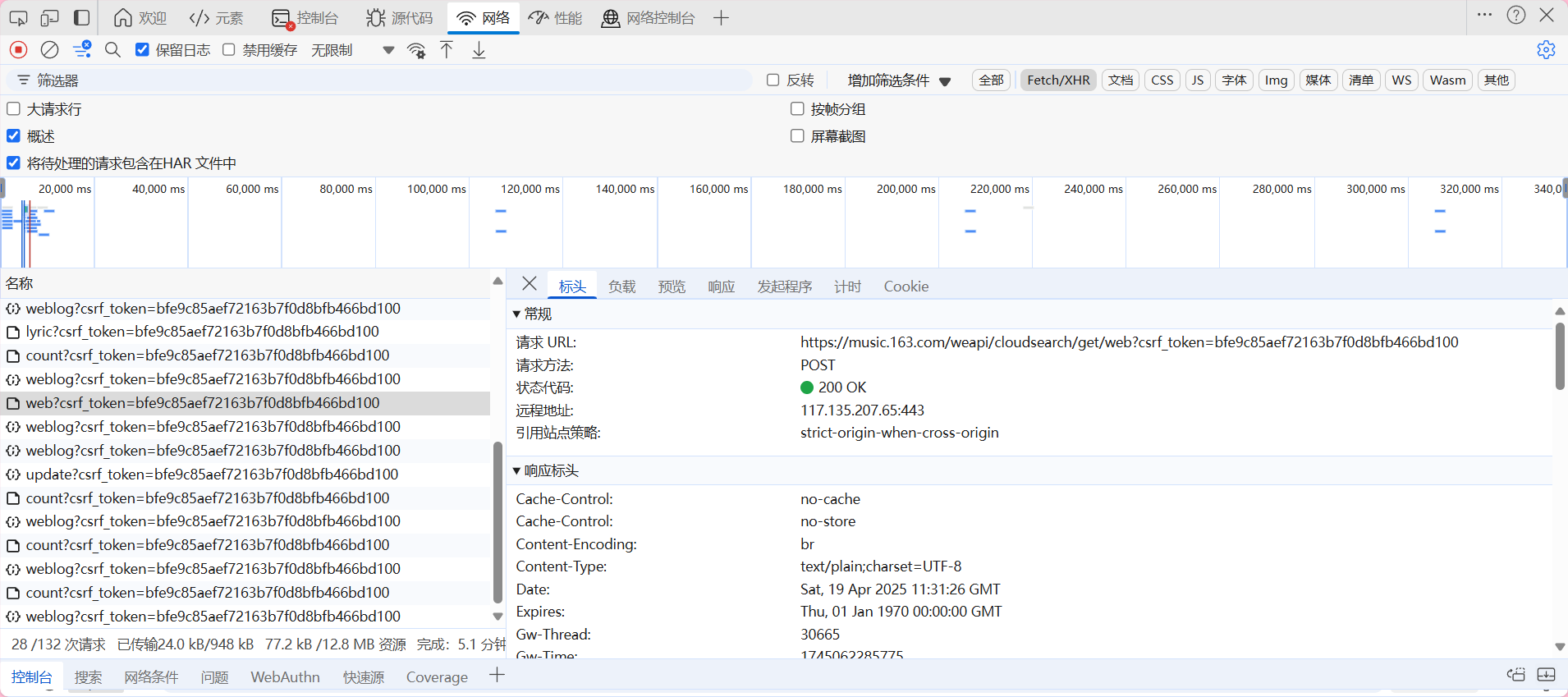
点击标头我们可以看见该链接是通过post进行请求的 接下来再次点击负载查看需要的参数。看到表单数据有 params以及encSecKey 看不懂 应该是加密过了 那就去看他的发起程序 通过断点找到解密方法
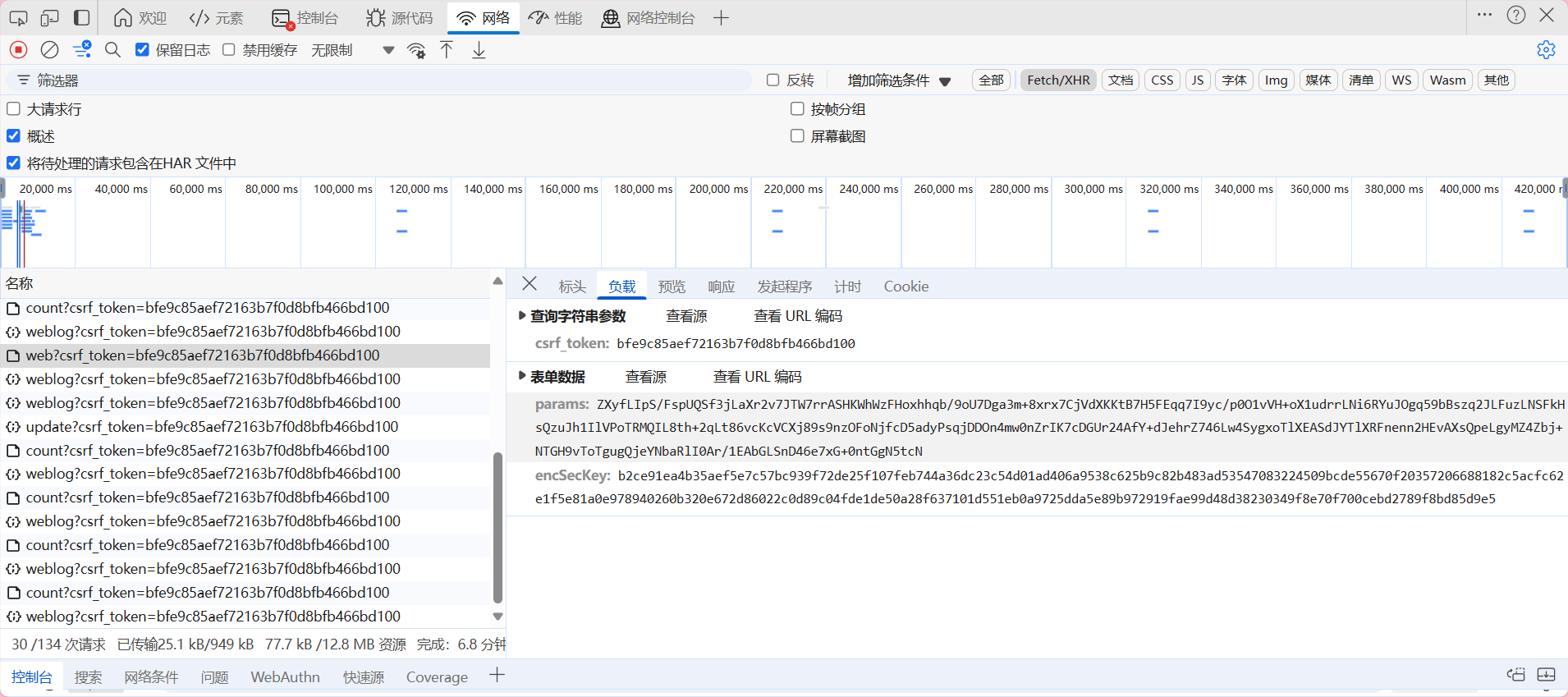
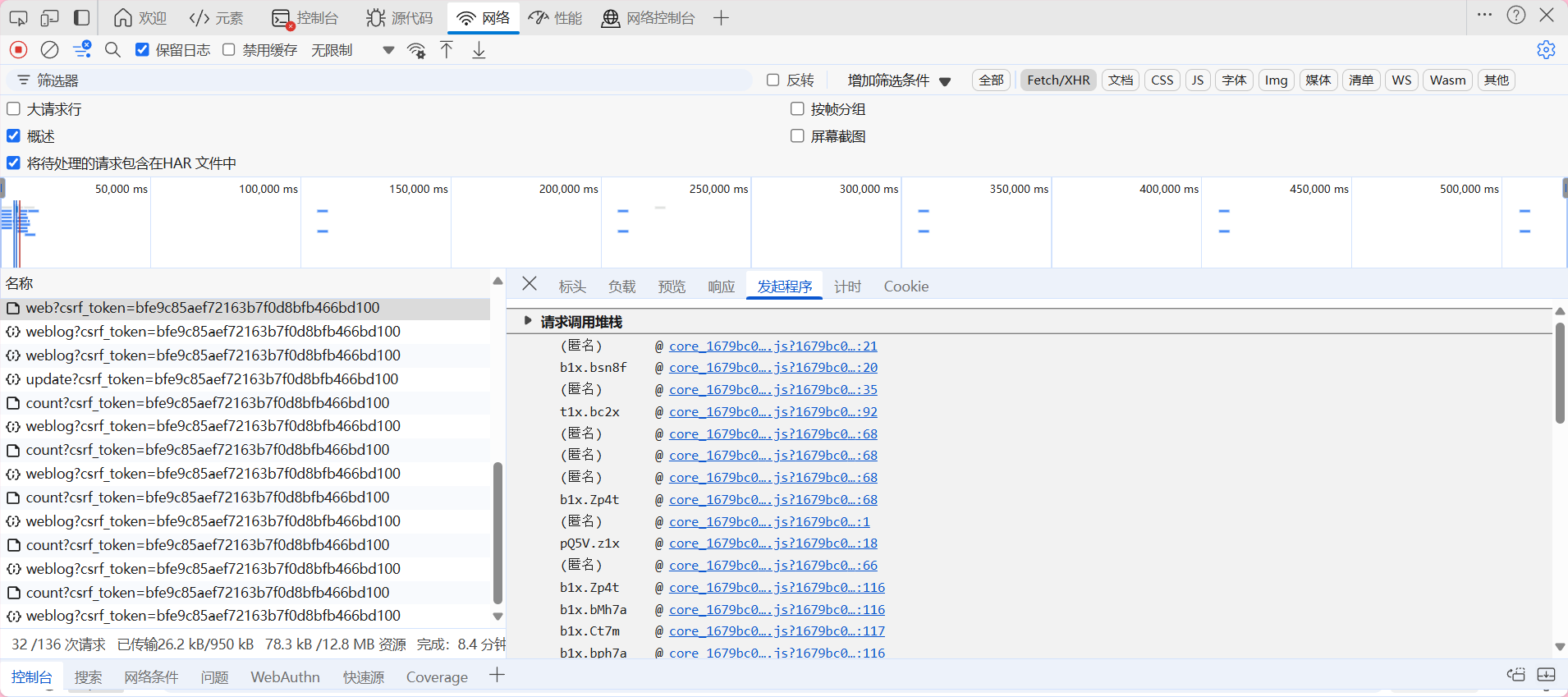
既然不知道是哪个 那就先从最顶上的查看一下
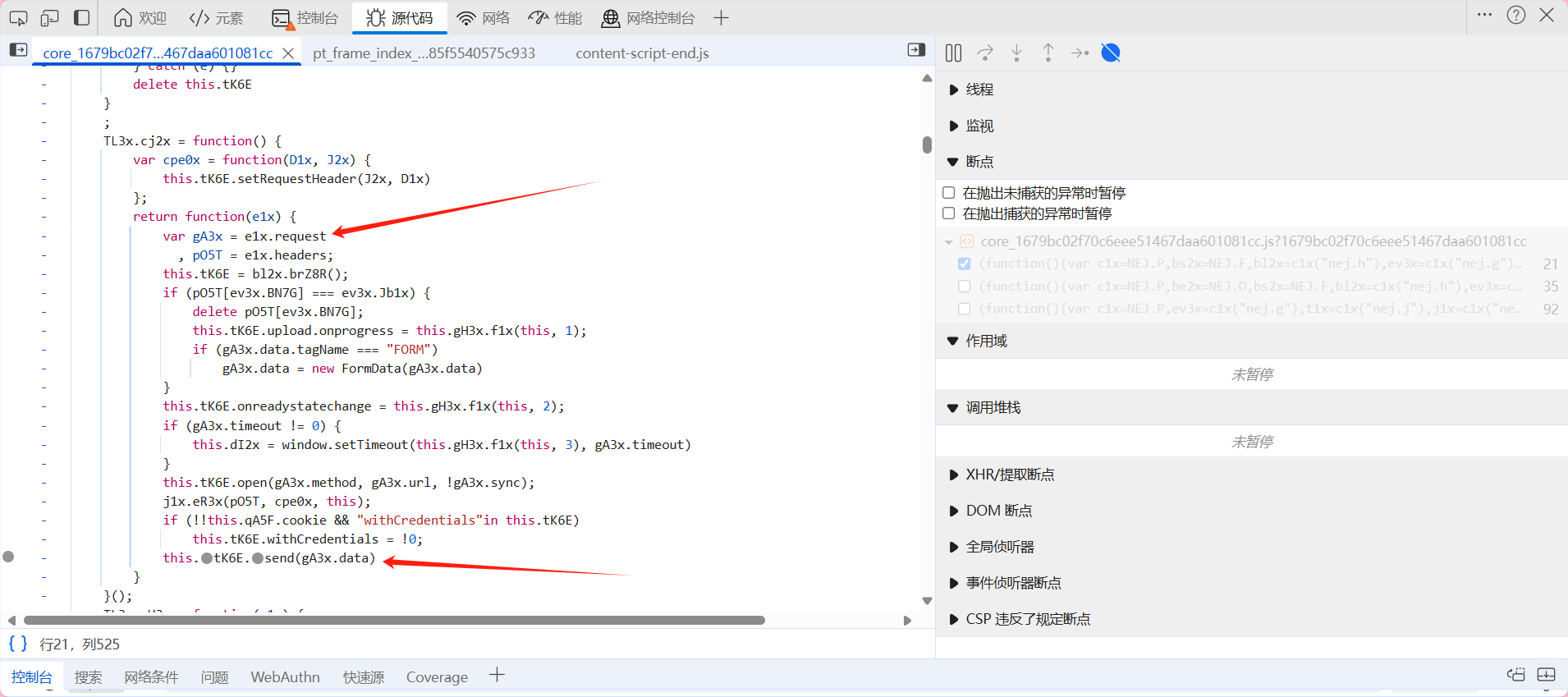
可以看到是通过这里有个send 那应该是通过这个gA3x.data来传输数据的,而这个gA3x又是通过这个e1x得来的 在这里打上断点 刷新页面
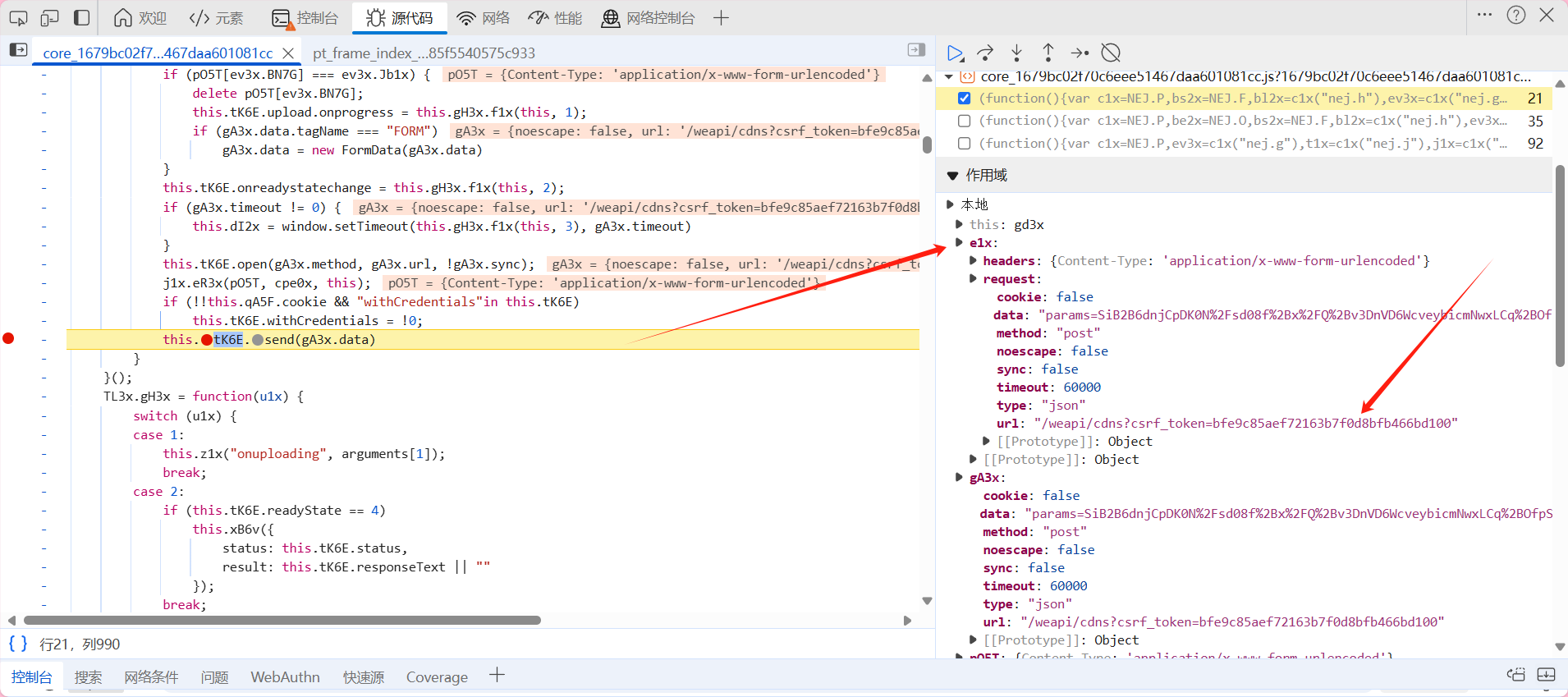
观察右边作用域 打开本地 点开e1x 查看request中的url是否是我们的目的url'https://music.163.com/weapi/cloudsearch/get/web?csrf_token='如果不是这个 那就不是我们需要的链接 点击下图中蓝色按钮继续加载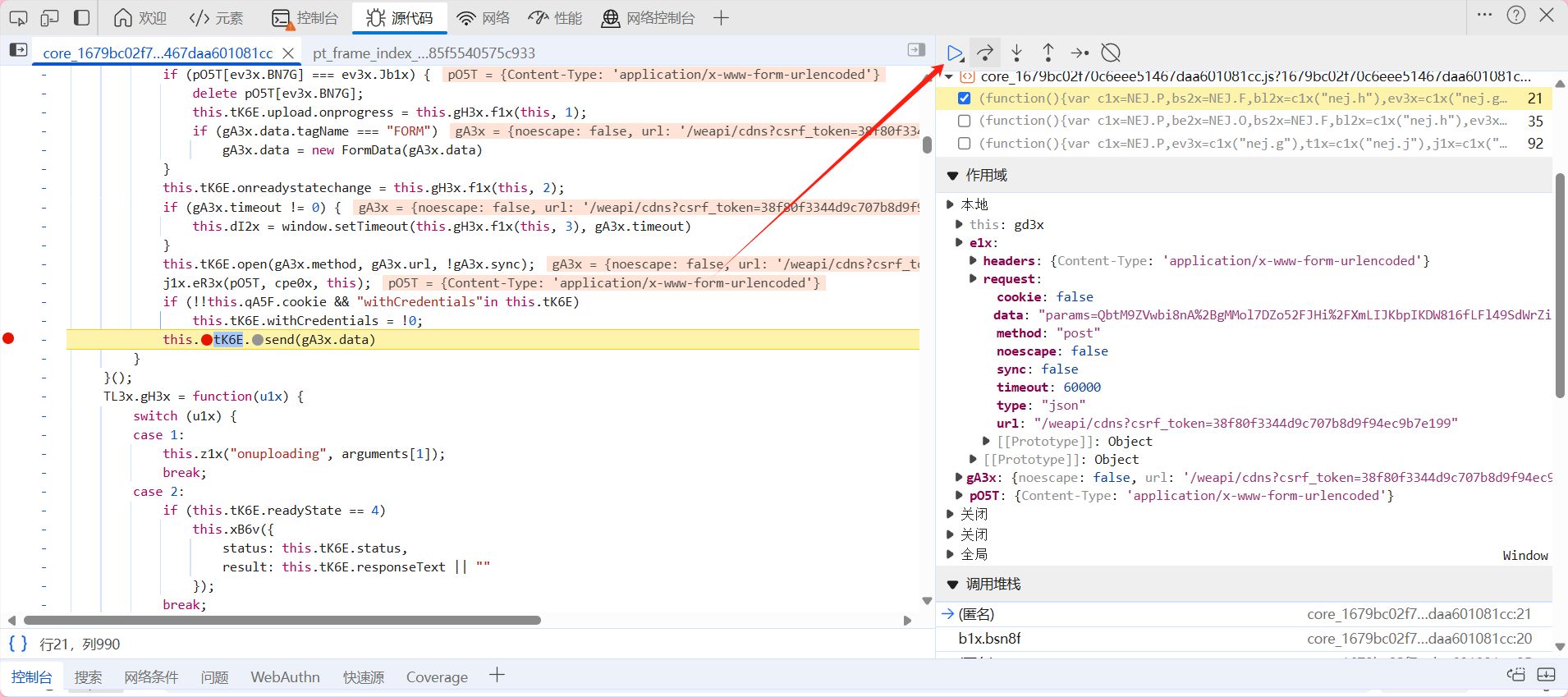
直到找到我们需要的url为止 ok 通过不断点击 我们找到了我们需要的url 接下来我们往下滑 找到调用堆栈
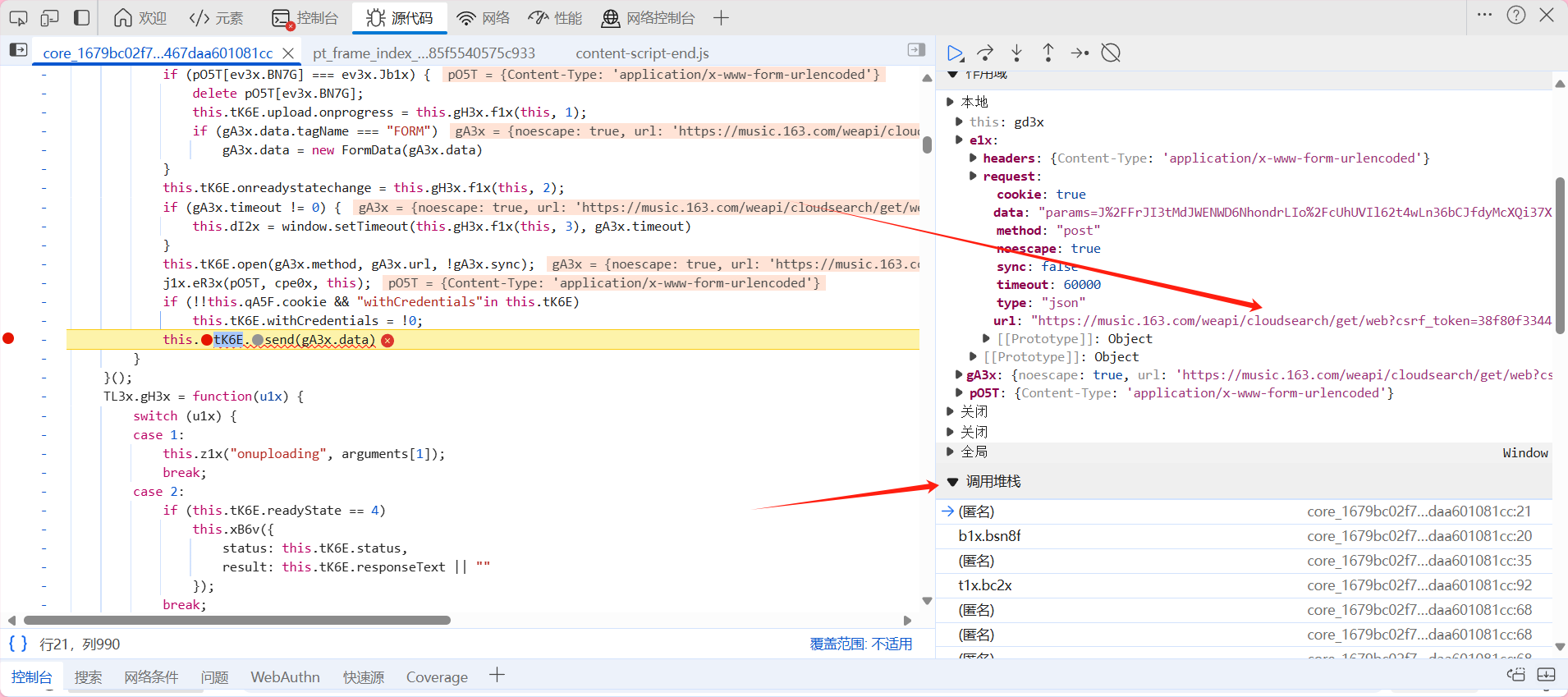
在这里查找一下data数据变换的地方
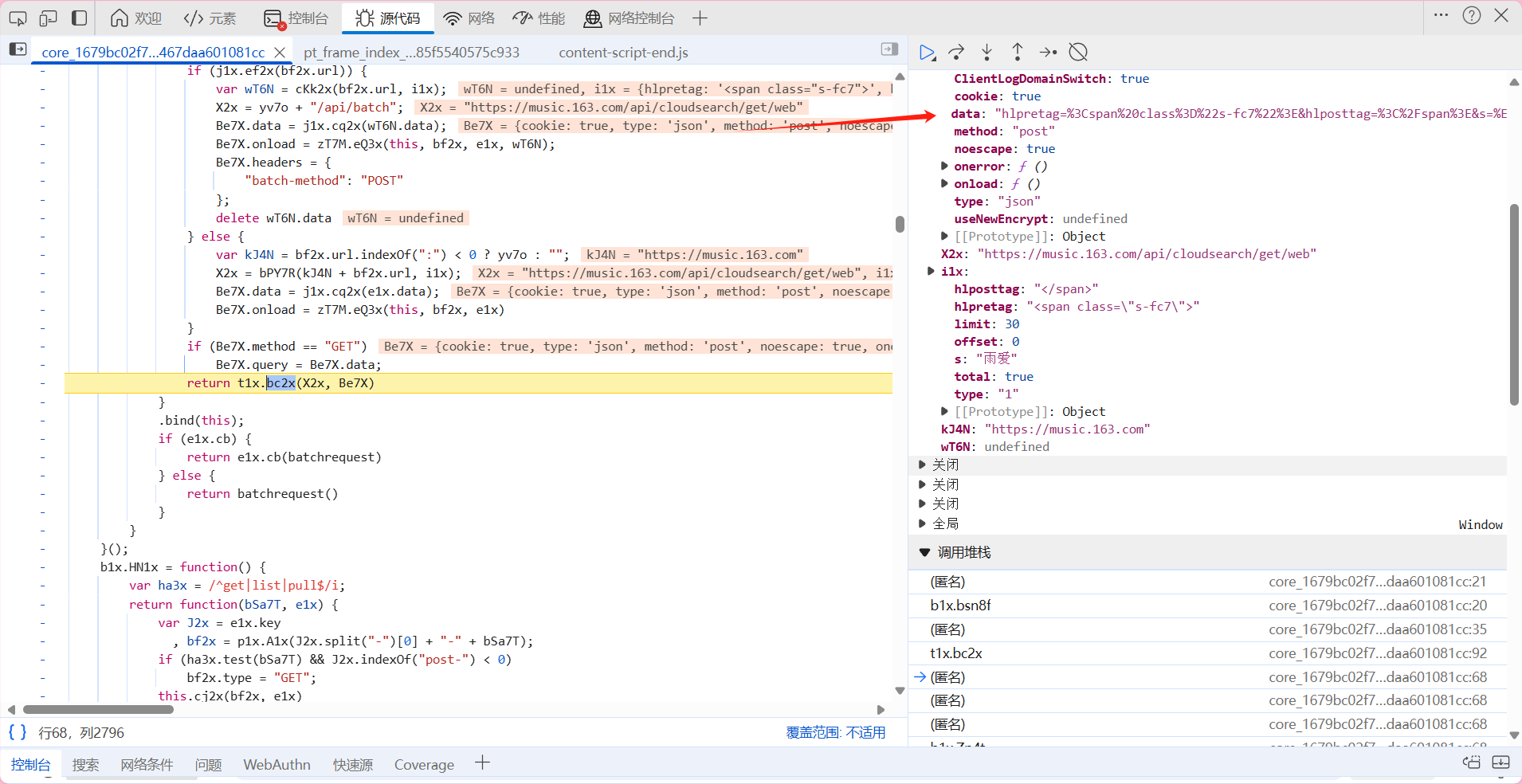
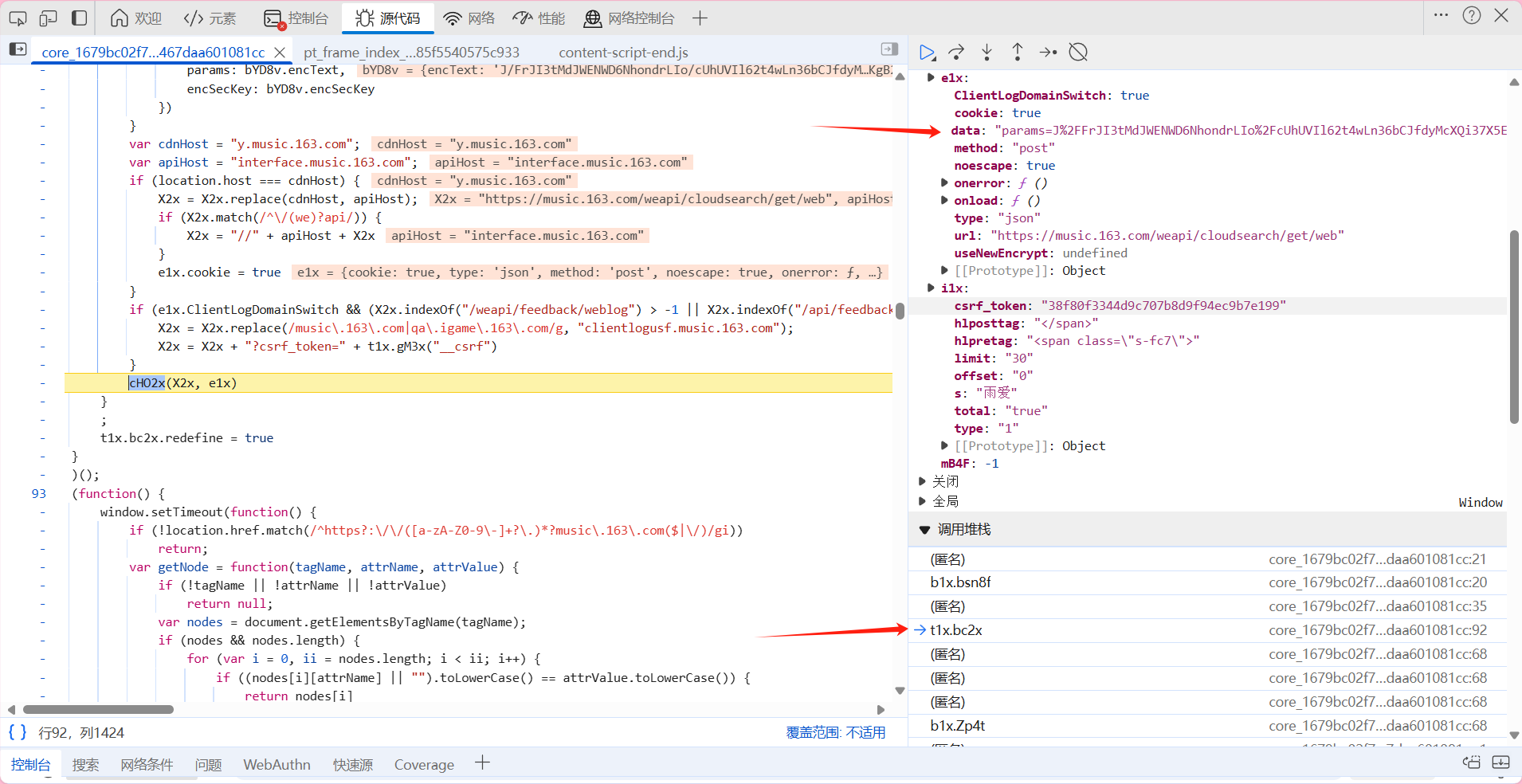
我们可以看到data的数据在t1x.bc2x之前都没有发生变化 在t1x.bc2x这里才开始发生改变,故猜测应该是在这一步进行了对data的加密 那我们点进去看看这一步到底发生了什么
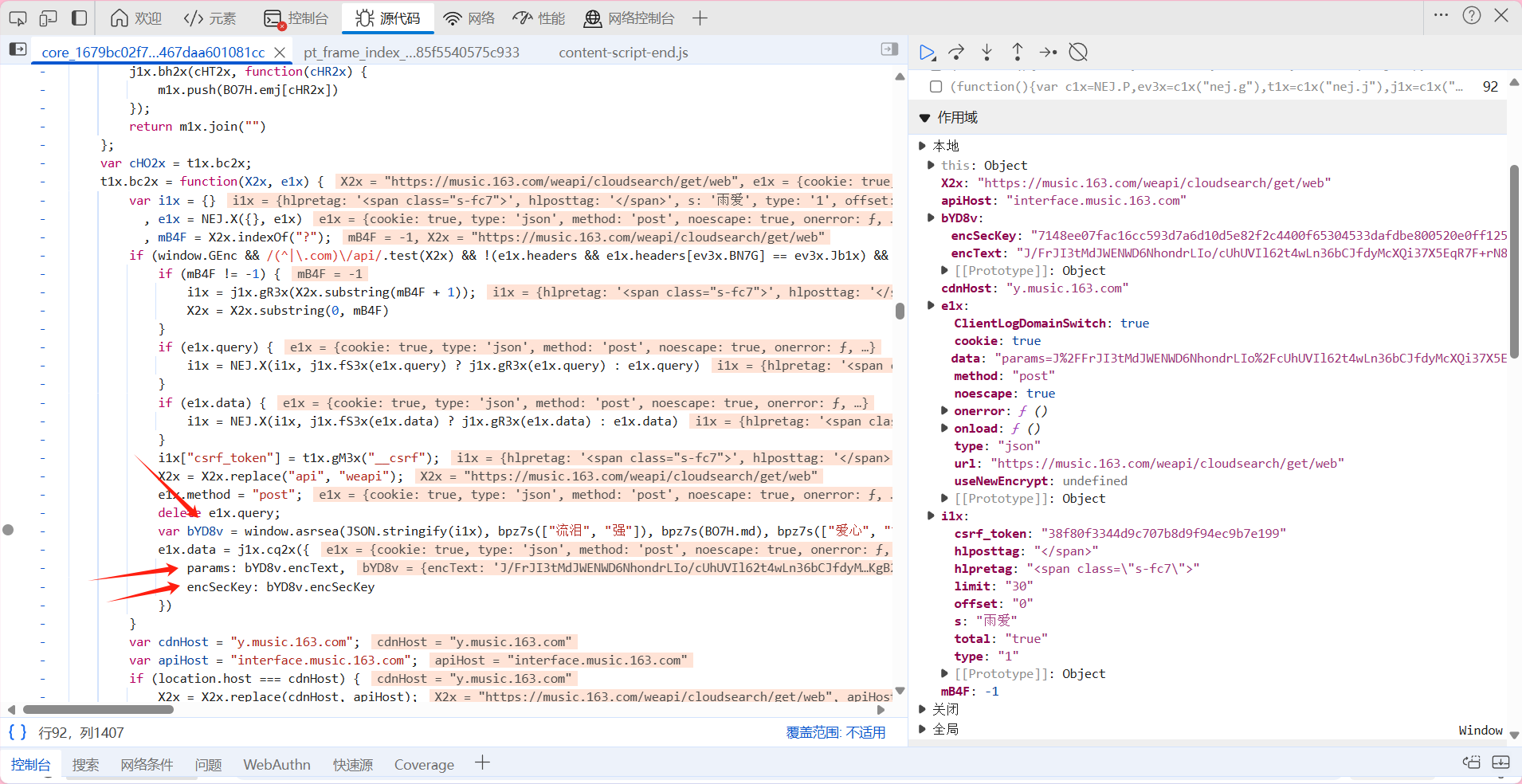
可以看出来params与encSecKey是由bYD8v进行赋值的 而bYD8v又是通过window.asrsea这个函数而得来 而这个函数又有四个参数 我们分别通过控制台进行查看


通过另外几首歌的重复操作 我们可以发现除了JSON.stringify(i1x)这个参数有变化外 其他三个参数是没有变化的 并且i1x中只有s:""中的内容是变化的 所以合理猜测其他三个参数是定值 只有这个i1x这个参数是作为关键词搜索的数据进行传入 i1x中的其他参数是什么意思我们后面在慢慢讲解
言归正传 现在我们已经知道这些参数是什么意思了 那我们可以展开对window.asrsea 的溯源了
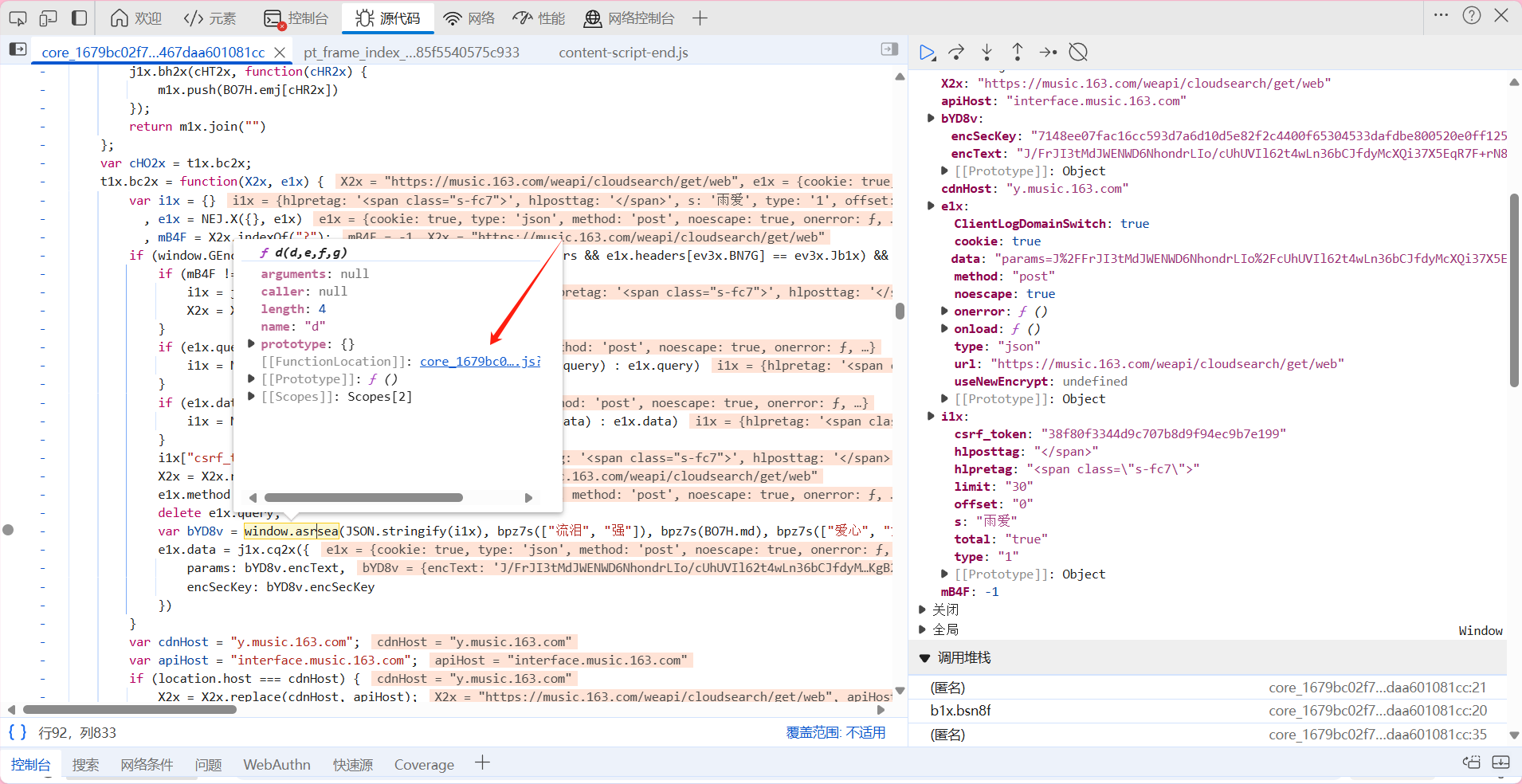
通过FunctionLocaltion进入 我们可以发现我们需要的内容是由d函数进行作用 而d又是由a b c构成
至于e函数。。。我也不知道干嘛的 所以我们需要的应该就是这四个函数了 我们将整个部分全部拿下来放入我们的新建js中 在将之前i1x以及var bYD8v = window.asrsea(JSON.stringify(i1x), bpz7s(["流泪", "强"]), bpz7s(BO7H.md), bpz7s(["爱心", "女孩", "惊恐", "大笑"]));也传入,由于有三个参数是定值,所以我们将他们修改一下 然后在进行打印看看
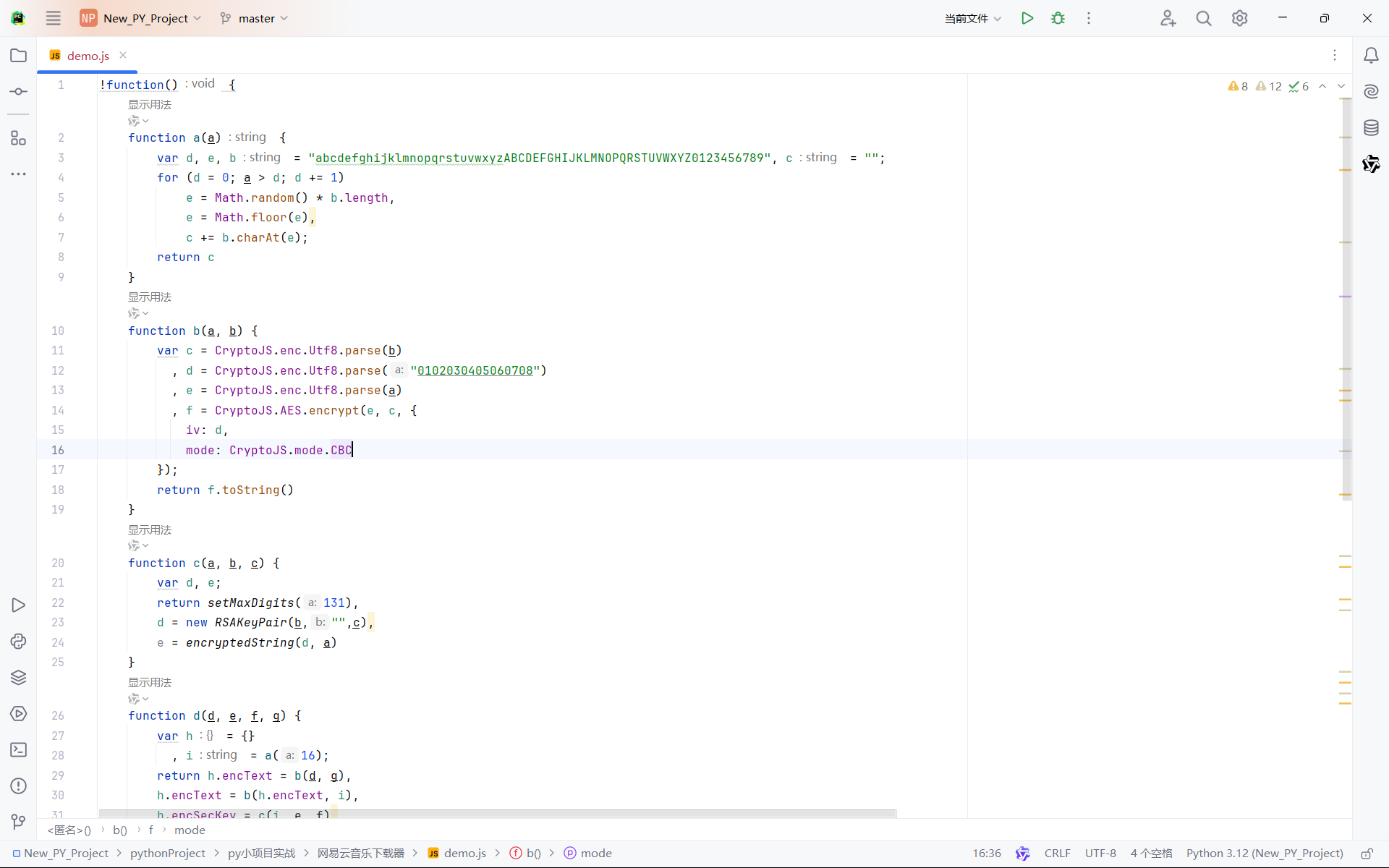
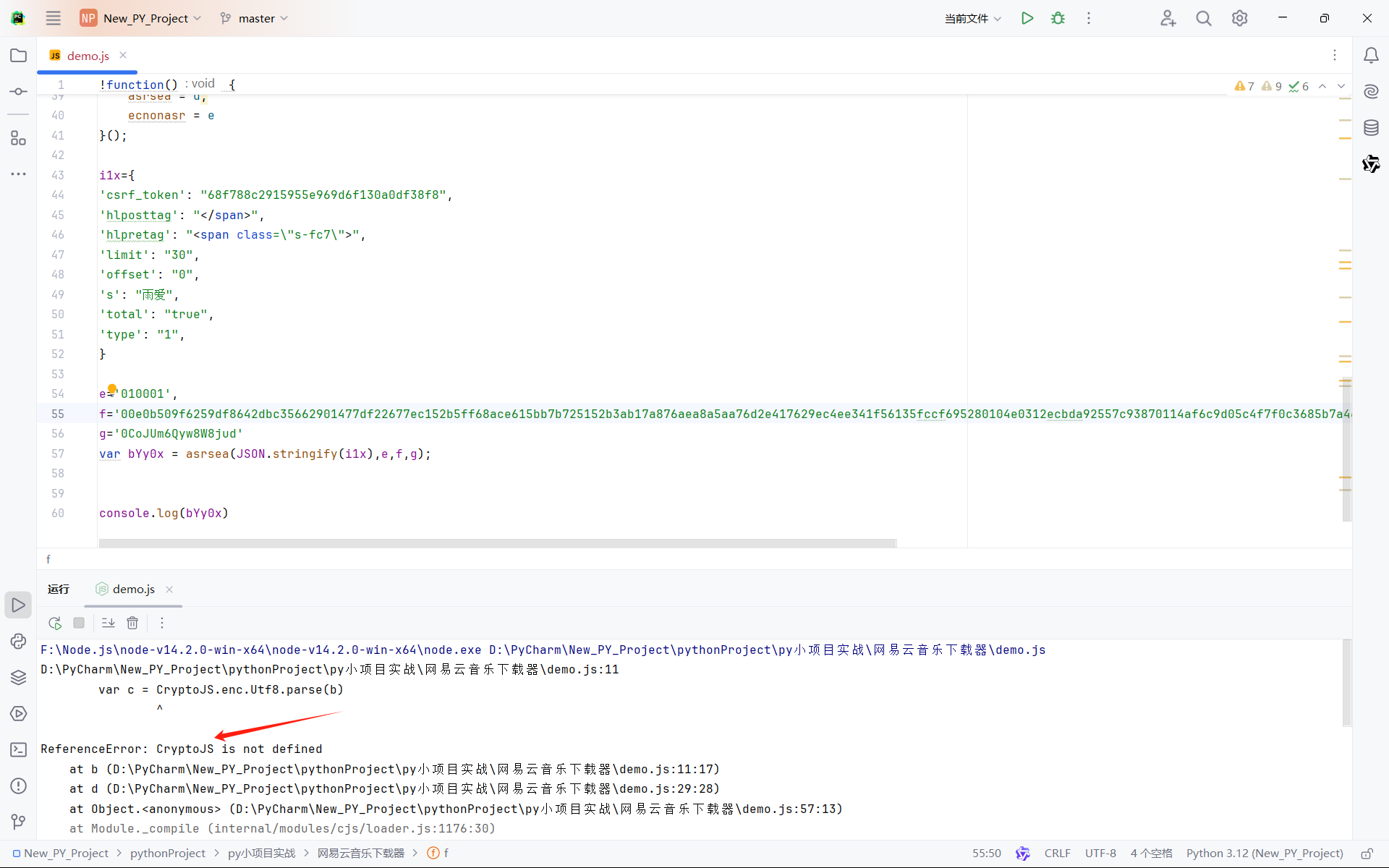
但并没有获得我们需要的内容,显然是缺少了环境,那么我们复制一下这个去刚刚的页面通过ctrl+f进行查找一下
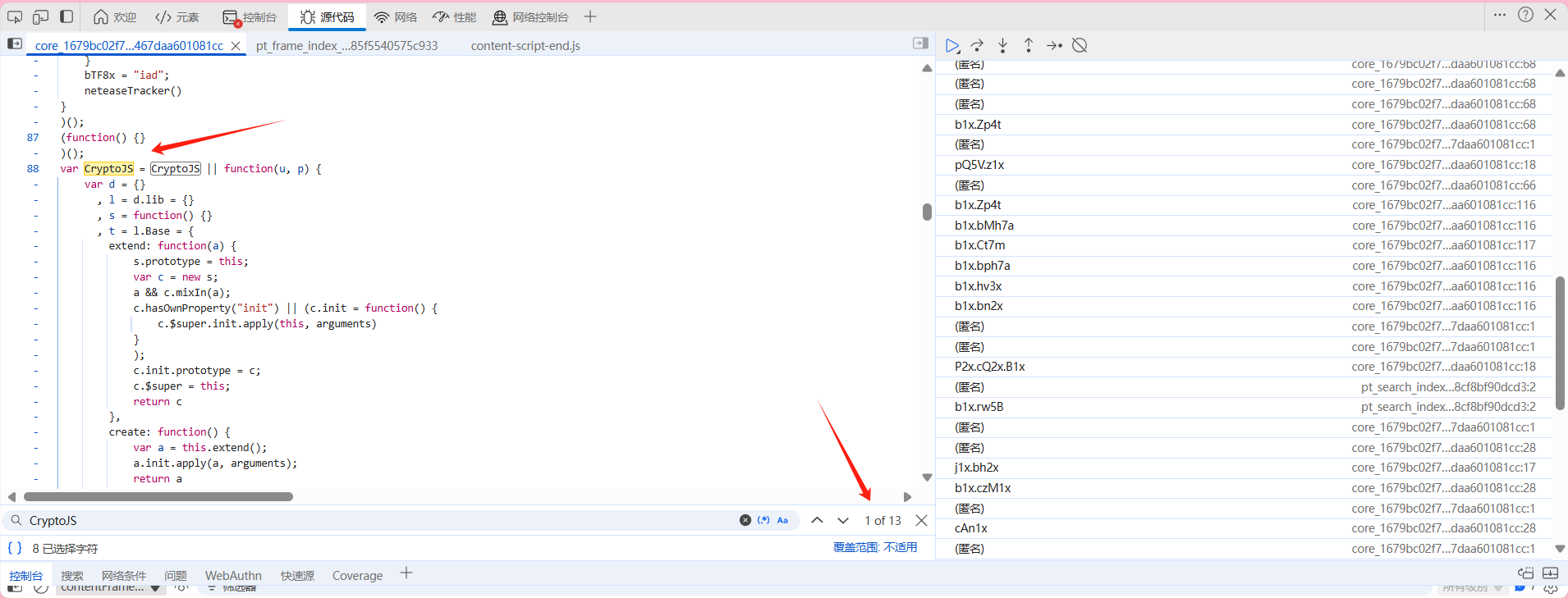
可以看到有13处之多 那么接下来我们就得慢慢的补上了,为了不浪费大家时间 所以小编直接跟大家说一下范围就行了 不用大家浪费在漫长的时间中——大概就是第一个CryptoJS往后的1135行 其实就是到window.asrsea函数之前,我们将他们复制到我们的demo.js中进行试验
我们发现补完环境后就可以运行了(如下图)
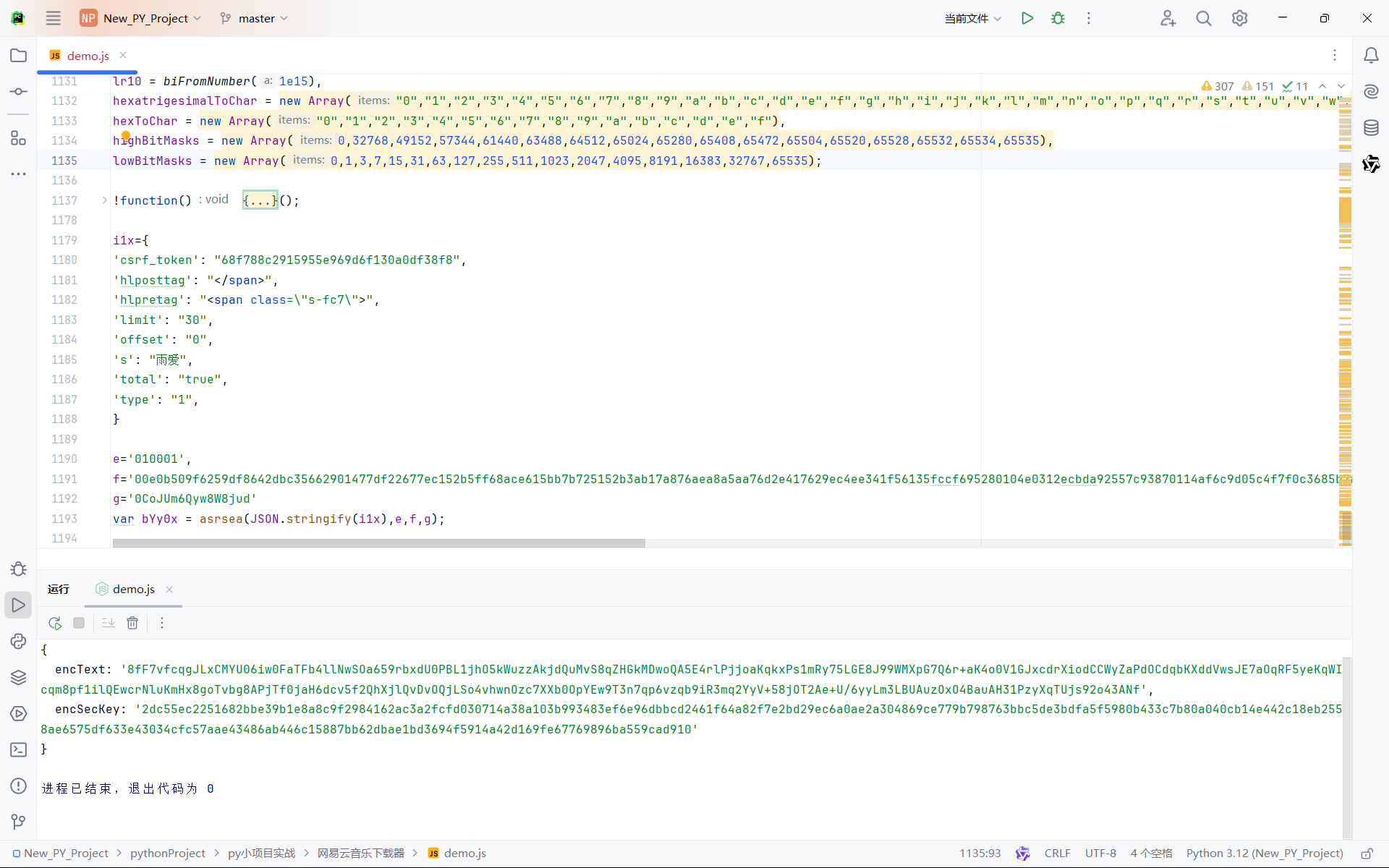
为了后续进行顺利我们应该构造一个函数返回bYy0x,到这一步我们的逆向基本已经结束了,接下来要进行python的编写
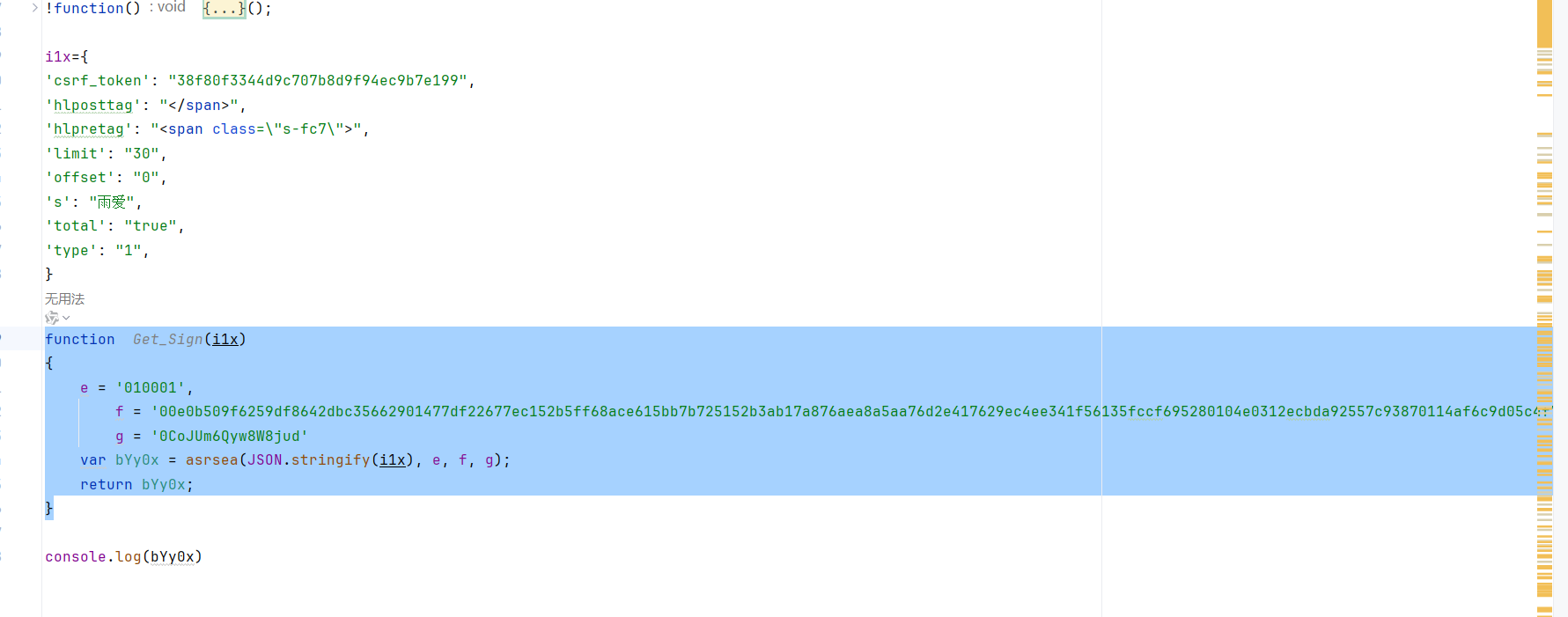
1.(2)编写请求,尝试获取音乐列表的json
ok,接下来我们创建一个py文件进行尝试对音乐列表的请求
在进行请求时,我们首先要完成参数的处理 已知该url是post,那么我们需要获取到请求头以及通过调用js获取到data

请求头的位置在开发者模式中的标头这里 我们下滑可以看见有个请求标头 其中我们需要的是“cookie”,“referer”,以及“user-agent”我们设立headers进行存入,将其放入httpx.post里我们可以通过请求获取到歌单json。那么我们的第一部分就结束了
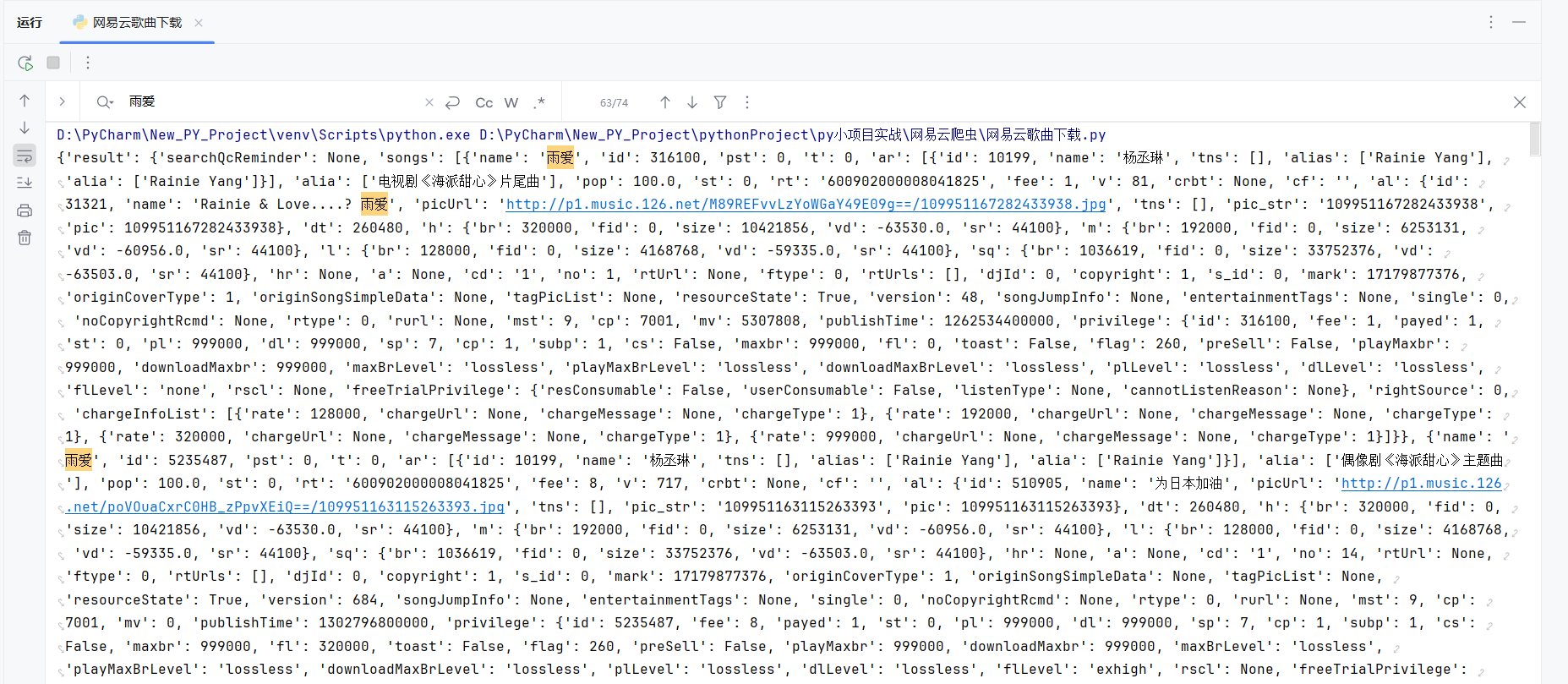
下面是部分代码:
import httpx
import execjs
headers={
'Cookie':'your cookie',
'referer':'https://music.163.com/',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0'
}
def Get_Song_data():
js_file_path = 'demo.js'
# 读取js代码
js_file = open(js_file_path, encoding='utf-8').read()
# 编译js代码
js_code = execjs.compile(js_file)
# 调用js代码获取加密值
i1x = {
'csrf_token': "38f80f3344d9c707b8d9f94ec9b7e199",
'hlposttag': "</span>",
'hlpretag': "<span class=\"s-fc7\">",
'limit': "30",
'offset': "0",
's': "雨爱",
'total': "true",
'type': "1",
}
result = js_code.call('Get_Sign', i1x)
params = result['encText']
encSecKey = result['encSecKey']
data = {
'params': params,
'encSecKey': encSecKey
}
return data
def Get_json():
music_list_url = 'https://music.163.com/weapi/cloudsearch/get/web?csrf_token=38f80f3344d9c707b8d9f94ec9b7e199'
data = Get_Song_data()
resp = httpx.post(url=music_list_url, headers=headers, data=data)
print(resp.json())
return resp
2.(1)解析json 获取到我们需要的信息
在开发者模式中找到当前连接的预览,我们可以看见是有个json的形式通过查找我们发现我们需要的内容有歌名,歌手名以及song_id
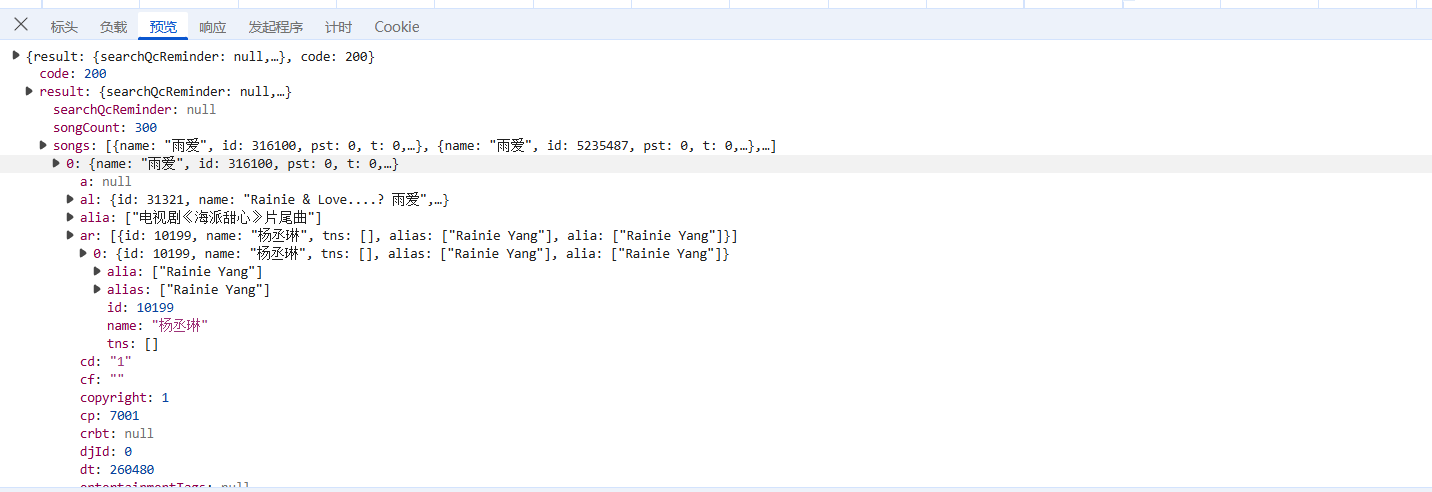
通过分析我们可以发现整个音乐列表是在json['result']['songs']中的。然后通过循环获得每一首歌里面的内容

部分代码如下:
class Song:
song_name=''
song_id=''
artist=''
def __init__(self,song_name,song_id,artist):
self.song_name=song_name
self.song_id=song_id
self.artist=artist
def Get_music_list(resp, song_list):
songs = resp.json()['result']['songs']
for song_item in songs:
music_name = song_item['name']
song_id = song_item['id']
if len(song_item['ar']) > 1:
artist = song_item['ar'][0]['name']
artist += "/" + song_item['ar'][1]['name']
else:
artist = song_item['ar'][0]['name']
music = Song(music_name, song_id, artist)
song_list.append(music)
print(music_name, song_id, artist)
3.(1)查找音乐来源
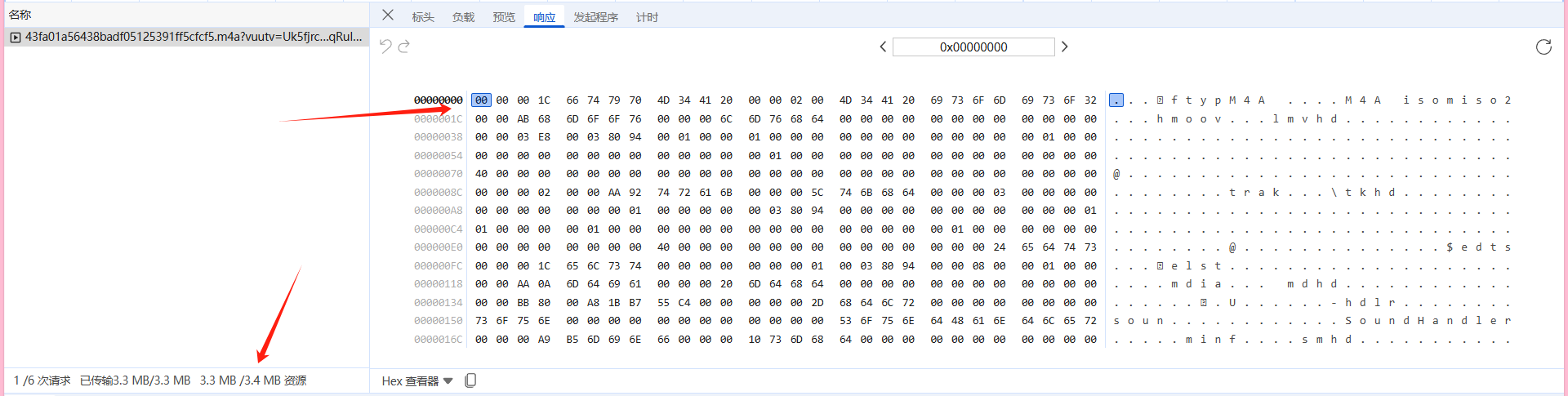
一般来说想要获取歌曲都是通过'http://music.163.com/song/media/outer/url?id=' + str(music_id)这个接口来下载的,但是也有限制:下载不了vip歌曲 那么有没有一种方法可以直接获取vip歌曲呢? 有的 通过抓包我们可以发现当点击播放音乐时会出现一个响应(如下图)发现他传输了3.4mb的资源 而且都是通过二进制的形式 再查看发现是一个MP3的格式
通过搜索.m4a前面的内容 我们可以知道应该是这个v1什么的传回来的数据,下面的那个url就是我们要寻找的 通过观看负载我们发现这个也是一个加密过的 那么参数是什么呢?继续像之前那般寻找这个调用堆栈
我们继续查看
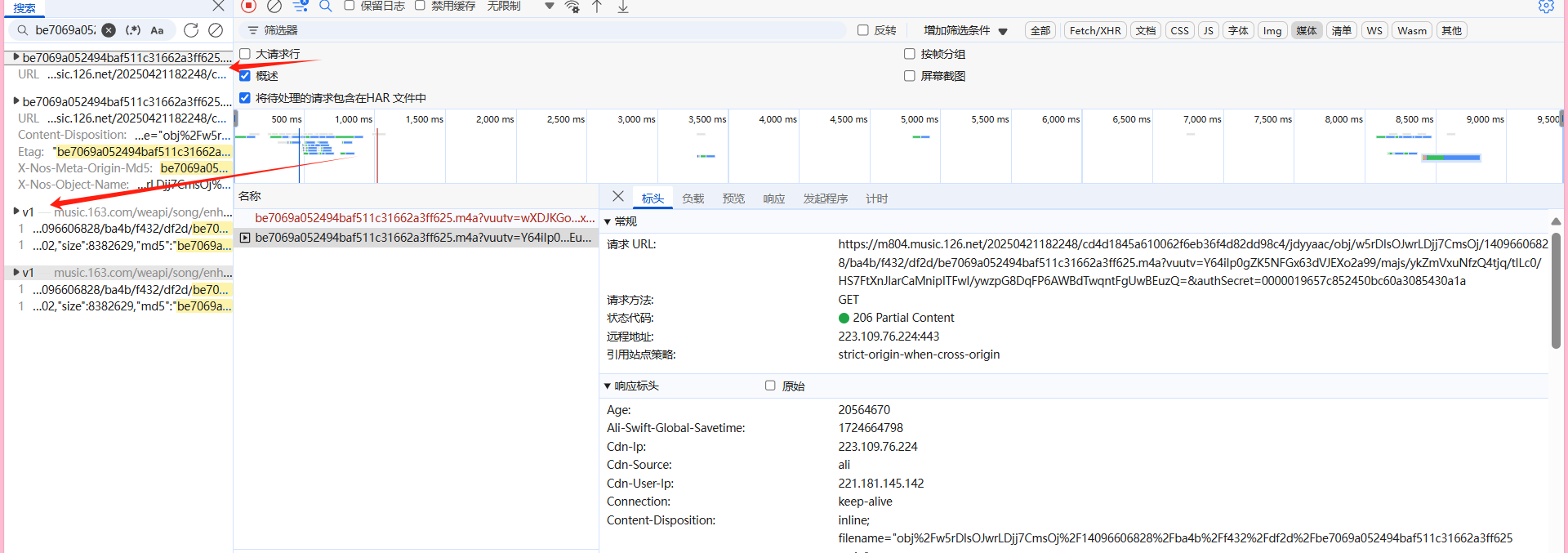
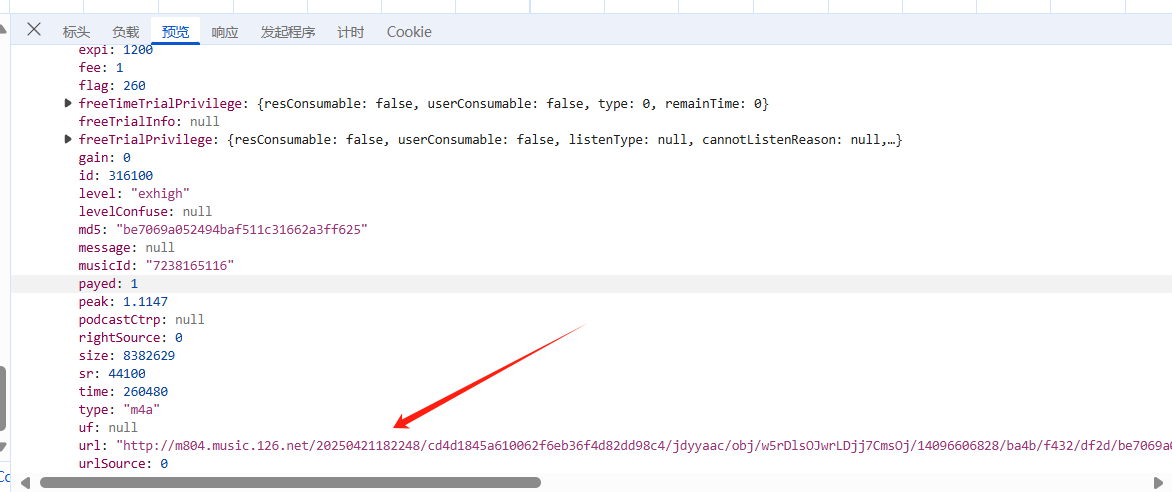
首先点回这个发送数据的位置 取消断点 刷新一下页面 等页面完整之后点上断点 然后点击播放音乐 之后会显现我们要寻找的内容(如下图)但是这是以及加密过后的了 所以我们还是像之前那样下滑找到调用堆栈 找到加密的地方
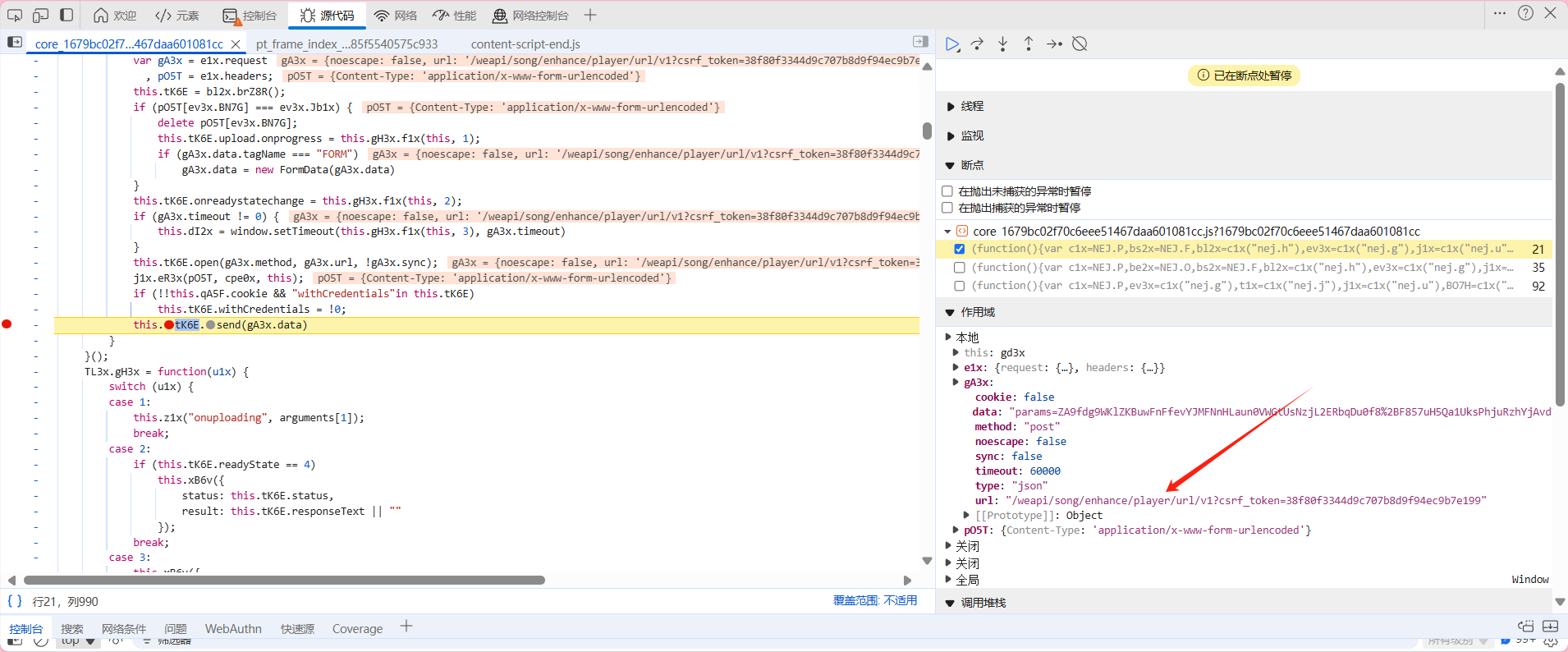
经过查找,我们发现这跟之前的其实是大差不差的,只是传输的数据内容不一样
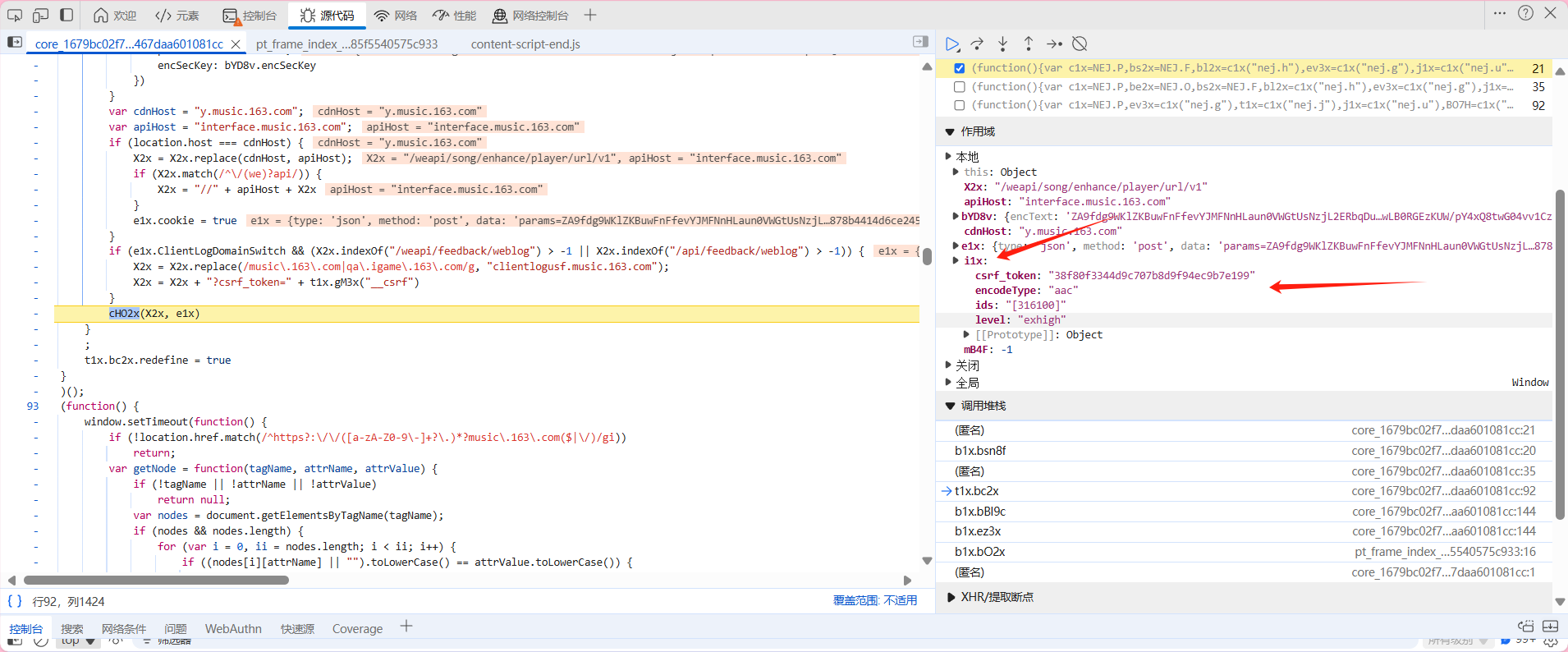
我们将i1x复制一下 在放入js中设置一个函数进行调用(其实除了这个传入内容的格式不同外 跟前面的是一样的)

4.(1)下载并保存音乐
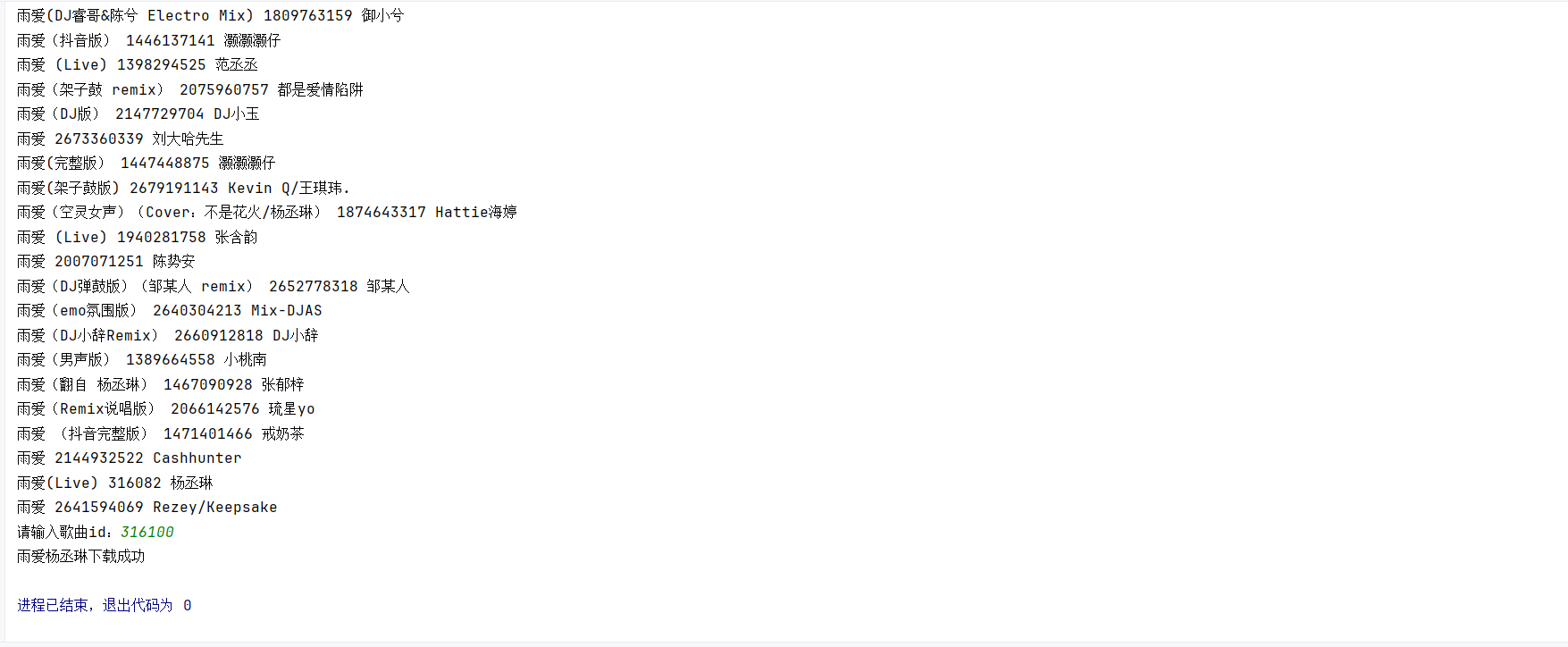
然后我们返回py文件中写一个函数去调用Get_music并下载音乐效果如下图
以下是部分代码:
import re
import httpx
import execjs
import os
file_path='./网易云歌曲下载//'
if not os.path.exists(file_path):
os.mkdir(file_path)
class Song:
song_name=''
song_id=''
artist=''
def __init__(self,song_name,song_id,artist):
self.song_name=song_name
self.song_id=song_id
self.artist=artist
def search_song(self,song_id):
if self.song_id==song_id:
return self
else:
return None
headers={
'Cookie':'your cookie',
'referer':'https://music.163.com/',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0'
}
def Get_download_data(song_id):
song_id = int(song_id)
js_file_path = 'demo.js'
# 读取js代码
js_file = open(js_file_path, encoding='utf-8').read()
# 编译js代码
js_code = execjs.compile(js_file)
# 调用js代码获取加密值
i2x = {
'csrf_token': "bfe9c85aef72163b7f0d8bfb466bd100",
'encodeType': "aac",
'ids': f"[{song_id}]",
'level': "exhigh",
}
result = js_code.call('Get_music', i2x)
params = result['encText']
encSecKey = result['encSecKey']
data = {
'params': params,
'encSecKey': encSecKey
}
return data
def Download_Music(song_list):
try:
song_id = input("请输入歌曲id:")
song_id = int(song_id)
for song in song_list:
download_song = song.search_song(song_id)
if download_song:
download_data = Get_download_data(download_song.song_id)
songurl = 'https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token=38f80f3344d9c707b8d9f94ec9b7e199'
res = httpx.post(url=songurl, headers=headers, data=download_data)
download_json = res.json()
music_url = download_json['data'][0]['url']
music_content = httpx.get(music_url, headers=headers)
music_name = download_song.song_name + download_song.artist
music_name = clean_filename(music_name)
with open(f'./网易云歌曲下载//{music_name}.mp3', 'wb') as f:
f.write(music_content.content)
print(f'{music_name}下载成功')
except Exception as e:
print(e)
def clean_filename(filename):
# 替换非法字符
illegal_chars = r'[\\/:*?"<>|]'
cleaned_filename = re.sub(illegal_chars, '', filename)
return cleaned_filename
至此,我们的整体都已经完成了。
总结:整个部分小编感觉其实是第一部分最难,耗时也是最多的 特别是整理js环境的 然后就是这个VIP曲目的下载 之前都是用那个'http://music.163.com/song/media/outer/url?id=' + str(music_id)下载 但不知道这个只能下载非VIP歌曲 所以也困扰了不久(当然要下载vip歌曲首先自己的cookie得是vip的才行,不然一切都是不太可能的)除此之外也可以通过传入不同的数据格式(i1x中的不同内容)获得评论歌词等等 也可以通过offset,pageno,cursor等的改变实现翻页效果具体情况具体分析。
免责声明
- 仅供学习交流:本文所涉及的网易云音乐数据爬取相关内容,仅为个人学习交流目的而创作。旨在分享技术探索过程、帮助初学者理解网络数据获取原理,绝无任何商业用途。若您将相关技术用于商业活动,由此引发的一切法律责任与经济纠纷,均与作者无关。
- 数据使用限制:通过文中方法获取的网易云音乐数据,应严格遵循数据来源平台的使用规则及相关法律法规。禁止将这些数据用于非法目的,如侵犯他人知识产权、恶意传播、用于不正当竞争等行为。否则,您需自行承担相应的法律后果。
- 技术风险提示:文中所描述的技术手段可能会因网易云音乐平台的更新、反爬虫策略调整等因素而失效。在尝试复现相关操作时,您可能会遇到各种技术问题,甚至导致账号受限、设备异常等情况。作者无法对这些风险提供任何担保或承担责任,请您谨慎操作。
- 法律责任自负:网络数据爬取涉及诸多法律问题,不同地区的法律法规对数据获取、使用的规定存在差异。在使用本文技术前,请确保您已充分了解并遵守当地法律法规。若因您的操作违反法律规定而产生法律纠纷,作者不承担任何法律责任,一切后果由您自行承担。
- 内容准确性与时效性:尽管作者在创作过程中尽力确保内容的准确性,但由于技术的快速发展和平台的不断变化,文中信息可能存在过时或不准确的情况。如果您发现内容存在错误或需要更新,请及时指出,但作者不承担因内容不准确或过时给您造成的任何损失。
下面是完整的py代码:
import re
import httpx
import execjs
import os
file_path='./网易云歌曲下载//'
if not os.path.exists(file_path):
os.mkdir(file_path)
class Song:
song_name=''
song_id=''
artist=''
def __init__(self,song_name,song_id,artist):
self.song_name=song_name
self.song_id=song_id
self.artist=artist
def search_song(self,song_id):
if self.song_id==song_id:
return self
else:
return None
headers={
'Cookie':'your cookie',
'referer':'https://music.163.com/',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0'
}
def Get_Song_data():
js_file_path = 'demo.js'
# 读取js代码
js_file = open(js_file_path, encoding='utf-8').read()
# 编译js代码
js_code = execjs.compile(js_file)
# 调用js代码获取加密值
i1x = {
'csrf_token': "38f80f3344d9c707b8d9f94ec9b7e199",
'hlposttag': "</span>",
'hlpretag': "<span class=\"s-fc7\">",
'limit': "30",
'offset': "0",
's': "雨爱",
'total': "true",
'type': "1",
}
result = js_code.call('Get_Sign', i1x)
params = result['encText']
encSecKey = result['encSecKey']
data = {
'params': params,
'encSecKey': encSecKey
}
return data
def Get_download_data(song_id):
song_id = int(song_id)
js_file_path = 'demo.js'
# 读取js代码
js_file = open(js_file_path, encoding='utf-8').read()
# 编译js代码
js_code = execjs.compile(js_file)
# 调用js代码获取加密值
i2x = {
'csrf_token': "bfe9c85aef72163b7f0d8bfb466bd100",
'encodeType': "aac",
'ids': f"[{song_id}]",
'level': "exhigh",
}
result = js_code.call('Get_music', i2x)
params = result['encText']
encSecKey = result['encSecKey']
data = {
'params': params,
'encSecKey': encSecKey
}
return data
def main():
resp = Get_json()
song_list=Get_music_list(resp)
Download_Music(song_list)
def Download_Music(song_list):
try:
song_id = input("请输入歌曲id:")
song_id = int(song_id)
for song in song_list:
download_song = song.search_song(song_id)
if download_song:
download_data = Get_download_data(download_song.song_id)
songurl = 'https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token=38f80f3344d9c707b8d9f94ec9b7e199'
res = httpx.post(url=songurl, headers=headers, data=download_data)
download_json = res.json()
music_url = download_json['data'][0]['url']
music_content = httpx.get(music_url, headers=headers)
music_name = download_song.song_name + download_song.artist
music_name = clean_filename(music_name)
with open(f'./网易云歌曲下载//{music_name}.mp3', 'wb') as f:
f.write(music_content.content)
print(f'{music_name}下载成功')
except Exception as e:
print(e)
def Get_json():
music_list_url = 'https://music.163.com/weapi/cloudsearch/get/web?csrf_token=38f80f3344d9c707b8d9f94ec9b7e199'
data = Get_Song_data()
resp = httpx.post(url=music_list_url, headers=headers, data=data)
print(resp.json())
return resp
def clean_filename(filename):
# 替换非法字符
illegal_chars = r'[\\/:*?"<>|]'
cleaned_filename = re.sub(illegal_chars, '', filename)
return cleaned_filename
def Get_music_list(resp ):
song_list=[]
songs = resp.json()['result']['songs']
for song_item in songs:
music_name = song_item['name']
song_id = song_item['id']
if len(song_item['ar']) > 1:
artist = song_item['ar'][0]['name']
artist += "/" + song_item['ar'][1]['name']
else:
artist = song_item['ar'][0]['name']
music = Song(music_name, song_id, artist)
song_list.append(music)
print(music_name, song_id, artist)
return song_list
if __name__ == '__main__':
main()
















 1910
1910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









