






 本文详细介绍了如何使用Python和jieba库统计英文和中文文本的词频,包括英文单词的空格分割、中文词语的分词处理,以及如何通过正则表达式预处理文本。此技能在学术研究和文本挖掘中十分实用。
本文详细介绍了如何使用Python和jieba库统计英文和中文文本的词频,包括英文单词的空格分割、中文词语的分词处理,以及如何通过正则表达式预处理文本。此技能在学术研究和文本挖掘中十分实用。
中文词汇与英文词频统计
1.如何统计英文单词和中文词语的词频?
今天我来教大家如何使用Python统计英文文本中单词的词频和中文词语的词频。你是不是遇到过需要对大量中文文本进行分析的情况?比如,你想要分析一篇英文文章或一本中文小说中出现频率最高的词汇是哪些?无论是在学术研究、语言分析还是文本挖掘方面,统计词频都是一项非常有用的技能。让我们一起来探索这个有趣又有用的主题吧!

2.准备工作
(1)英文词频统计
因为本次使用的代码使用的库为python的内置库,所以直接进行导入即可
(2)中文词汇统计
首先,我们需要安装jieba包,这是一个开源的中文分词工具。
pip install jieba
接下来,我们需要准备一篇中文文本作为分析的对象。你可以使用自己的中文文本。
3.分析原理
英文分析
在进行单词词频统计之前,我们需要了解一下具体的分析原理。对于英文文本,我们可以按照空格来分隔单词。但是需要注意的是,可能会有一些标点符号、换行符等特殊字符,这些字符并不属于单词本身。因此,在分割单词之前,我们需要对文本进行一些预处理工作,例如删除特殊字符和标点符号。
在Python中,我们可以使用正则表达式模块re来进行文本处理。通过使用re模块的split()函数,我们可以按照非单词字符进行分割,得到一个单词列表。然后,我们可以遍历这个单词列表,统计每个单词出现的次数,并将结果存储在一个字典中。
中文分析
中文文本的词语之间并没有像英文那样的空格来进行分隔,所以我们需要进行一些额外的步骤来实现中文词频统计。
首先,我们可以使用Python中的中文分词库,例如jieba,来进行中文文本的分词。通过jieba库的cut()函数,我们可以将中文文本分割为一个个词语,得到一个词语列表。然后,我们可以遍历这个词语列表,统计每个词语出现的次数,并将结果存储在一个字典中。
需要注意的是,我们还需要处理一些特殊情况,例如标点符号、停用词等。本文并没有对文本进行停用词处理,但是给出方法,对于标点符号,我们可以使用正则表达式来进行过滤。而停用词则是那些在分析时不具有实际意义的常用词语,例如“的”、“了”等。我们可以在分词后,去除这些停用词,以提高词频统计的准确性。
4.代码实现
本文在代码实现方面对代码进行了很多注释,方便理解和学习
(1)下面是我们使用Python实现的代码,来帮助我们统计英文单词的词频:
import sys
import re
# countFile函数用于统计文件中的单词频率。它接受两个参数:filename表示要统计的文件名,words表示存储统计结果的字典。
def countFile(filename, words):
# 函数首先尝试打开文件并读取内容。如果文件不存在或打开失败,会抛出异常并返回0
try:
f = open(filename, "r", encoding="gbk") # 打开文件以读取内容,使用gbk编码
except Exception as e: # 如果文件不存在或打开失败,会抛出异常并返回0。
print(e)
return 0
text = f.read() # 将文件内容全部读取为字符串
f.close()
lst = re.split(r"\W+", text) # 将文本(text)按非单词字符(\W)进行分割,并将结果保存在lst列表中(获得单词列表)。
for word in lst:
if word == "": # 如果单词为空字符串,跳过该单词继续循环。
continue
wx = word.lower() # lower()将单词转换为小写,便于统一防止计算错误,因为如果不统一大小写形式,这两个相同的单词将被视为两个不同的单词
if wx in words:
words[wx] += 1 # 如果在词典中已存在该单词,则频率加1
else:
words[wx] = 1 # 如果词典中不存在该单词,则将其添加,并设置频率为1
return 1 # 表示统计成功
# 统计指定文件的单词频率,将结果存入result字典
result = {} # 存储统计结果的字典,格式为{"单词":频率}
if countFile(sys.argv[1], result) == 0: # 调用 countFile 函数,传入命令行参数 sys.argv[1] (表示统计的文件路径)和 result 字典。
exit() # 如果 countFile 返回值为 0,即统计失败,则执行 exit() 函数结束程序。
# 文件进行处理以达到需要处理 ”单词“: 词频 的效果
lst = list(result.items()) # 将result字典转换为列表形式:通过调用result.items()方法,会返回一个可迭代对象,
# 其中包含了 result 字典中的所有键值对。每个键值对以元组的形式表示.例如:[("apple", 3), ("banana", 2), ("orange", 1)]
lst.sort() # 按照字典顺序对单词进行排序:sort() 方法是一种原地排序,也就是说它会直接修改原列表的顺序,而不会创建一个新的排序后的列表。
f = open(sys.argv[2], "w") # 打开结果文件以写入结果
for word, frequency in lst:
f.write("%s\t%d\n" % (word, frequency)) # 将单词及其频率写入文件
f.close() # 关闭文件
| 原文 | 词频 |
|---|---|
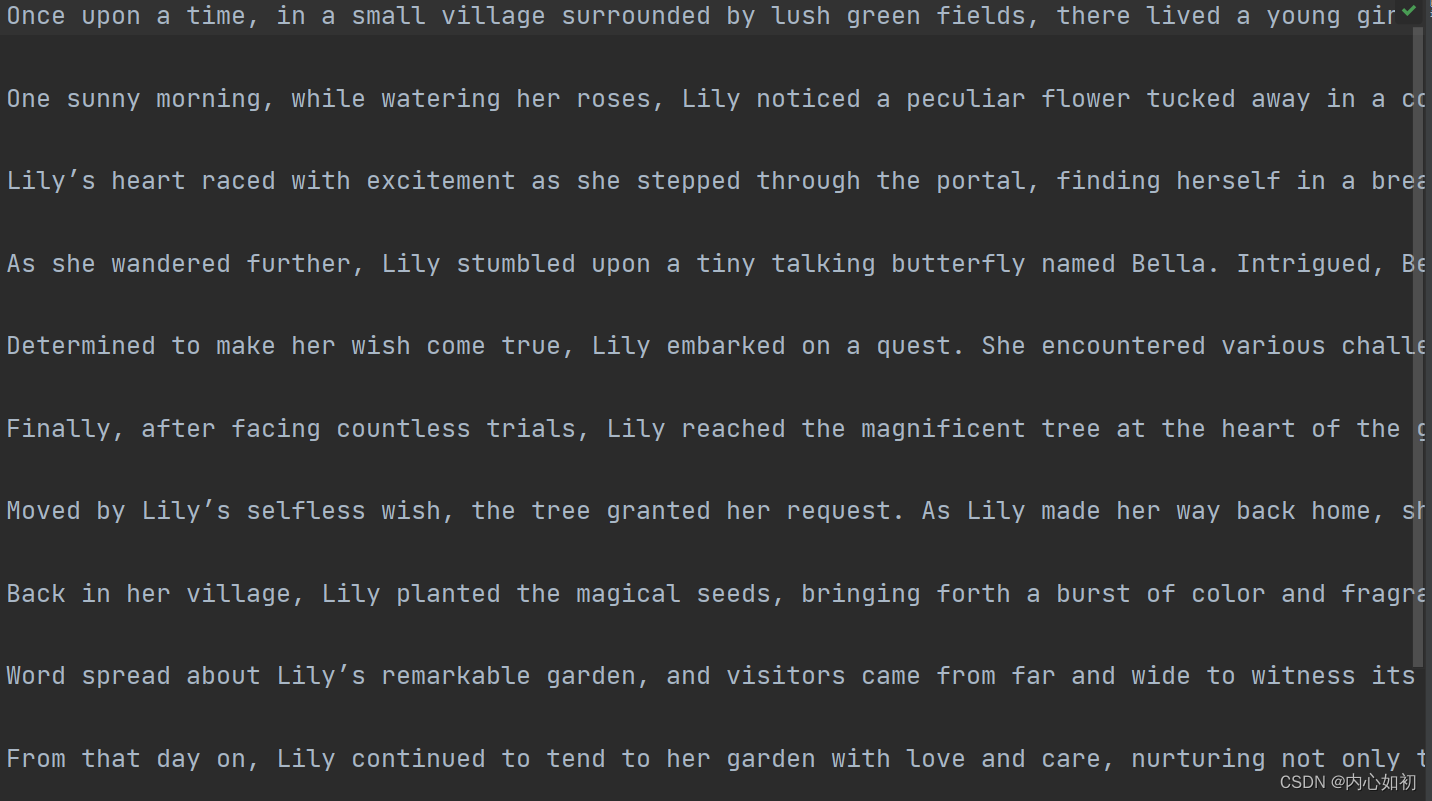 | 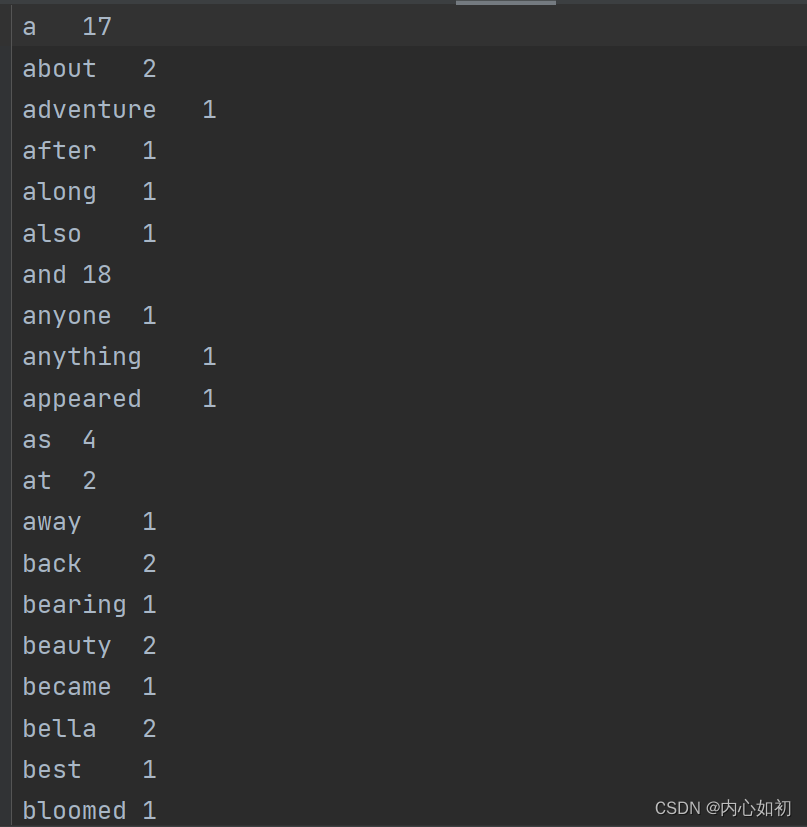 |
(2)下面是我们使用Python实现的代码,来帮助我们统计英文单词的词频:
# 统计中文词频,与统计英文类似,只是在分词时使用的方法不同
import sys
import jieba
def countFile(filename, words):
try:
f = open(filename, "r", encoding="utf-8") # 打开文件以读取内容,使用utf-8编码
except Exception as e:
print(e)
return 0
txt = f.read() # 将文件内容全部读取为字符串
f.close()
seg_list = jieba.lcut(txt) # 使用结巴分词将文本分割为词语列表
for word in seg_list:
if word.strip() == "":
continue
if word in words:
words[word] += 1 # 如果在词典中已存在该词语,则频率加1
else:
words[word] = 1 # 如果词典中不存在该词语,则将其添加,并设置频率为1
return 1
result = {} # 存储统计结果的字典,格式为{"词语":频率}
if countFile(sys.argv[1], result) == 0: # 统计指定文件的词语频率,将结果存入result字典
exit()
lst = list(result.items()) # 将result字典转换为列表形式
lst.sort() # 按照字典顺序对词语进行排序
f = open(sys.argv[2], "w", encoding="utf-8") # 打开结果文件以写入结果
for word, frequency in lst:
f.write("%s\t%d\n" % (word, frequency)) # 将词语及其频率写入文件
f.close() # 关闭文件
| 原文 | 词汇 |
|---|---|
 | 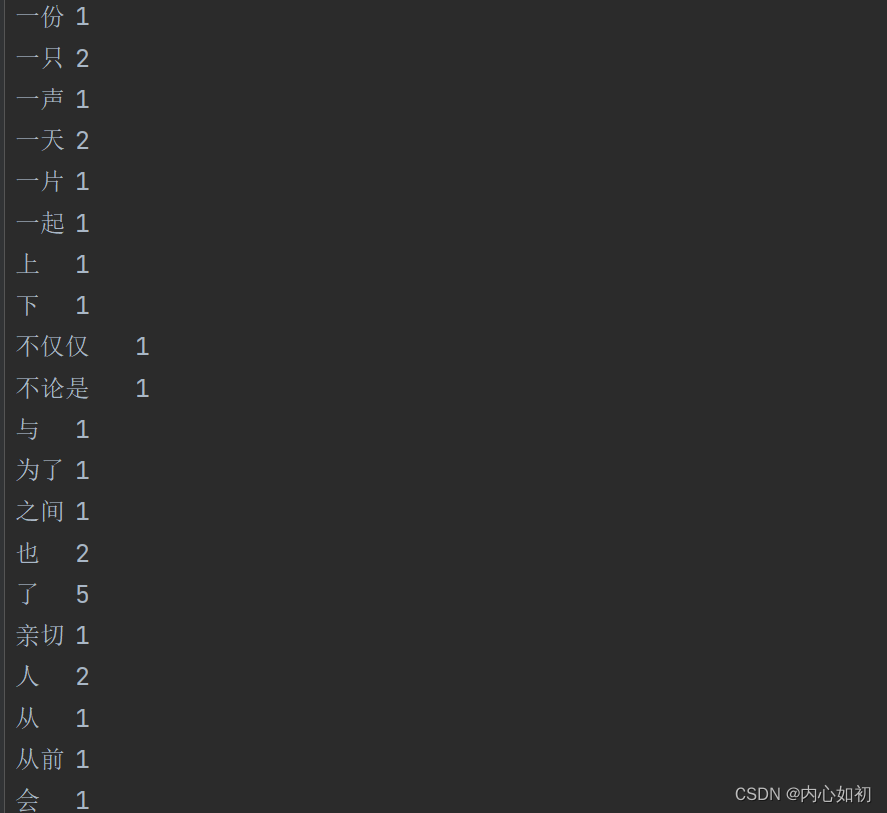 |
5.使用方法
在你的系统上保存以上代码为自己命名的.py文件,并准备一篇中文文本和英文文件
然后,打开命令提示符或终端,运行以下命令:
python`自己命名的.py 需要处理的文本.txt result.txt
这个命令将会将词频统计结果保存在result.txt文件中。
代码中使用命令行参数进行编写,这样做可以直接使用命令进行,无需打开IDE方便好用
6.运用
使用终端,运行以下命令:
python 自己命名的.py 需要处理的文本.txt result.txt
这个命令将会将词频统计结果保存在result.txt文件中。
代码中使用命令行参数进行编写,这样做可以直接使用命令进行,无需打开IDE方便好用
7.总结
通过这篇文章,我们学习了如何使用Python来统计英文文本和中文小说中的词频。通过使用正则表达式来处理文本,并使用字典来存储和计算词频,我们能够更好地理解文本中的词汇使用情况。这对于学术研究、语言分析和文本挖掘都非常有帮助。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











