






GPT助力爬虫
我将会介绍三种GPT爬虫的方式,话不多说直接上干货
以下内容建立在你已经拥有ChatGPT-4,如果没有可以去这里办理一下业务
一.Scraper
这种方式比较简单,但是简单的代价就是它爬取的范围也比较有限,不能应对高级的反爬手段。
1.1安装Scraper
直接在ChatGPT–4的插件商店中选择Scraper安装即可
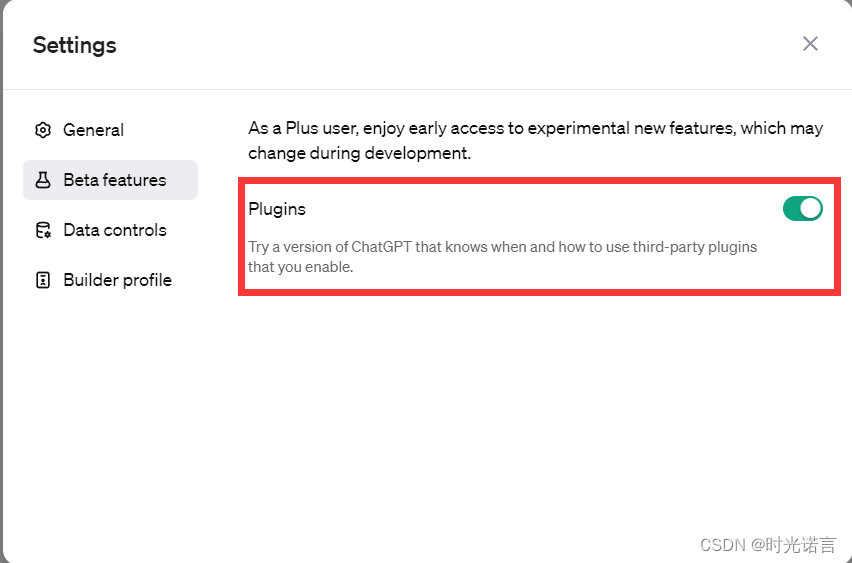
首先确定插件功能已打开:
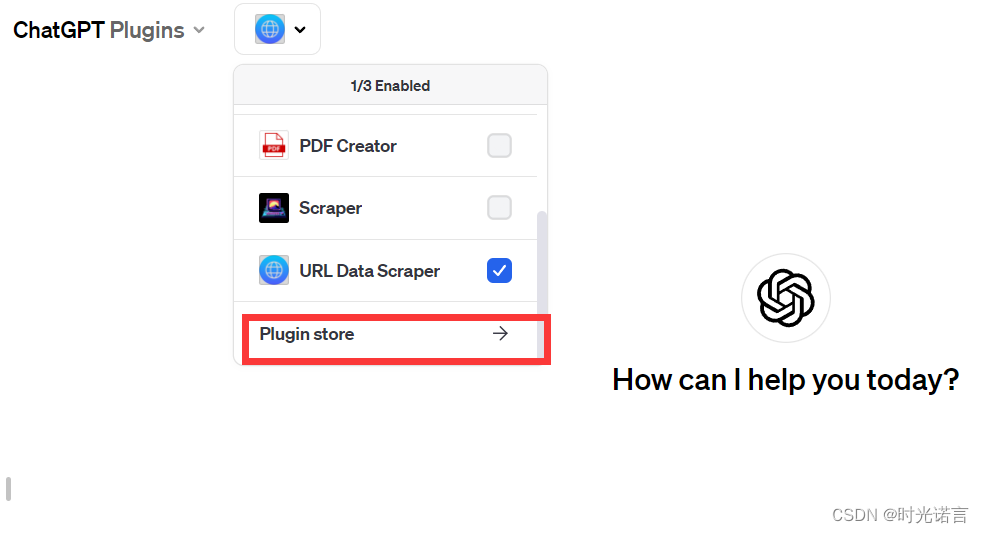
然后打开插件商店:
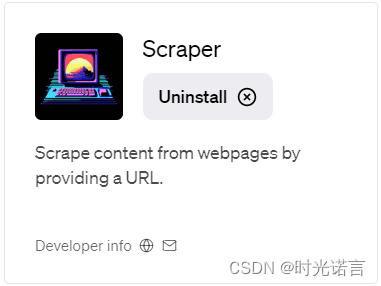
然后下载即可:(我这里已经下载过了)
1.2 开始爬取想要的内容
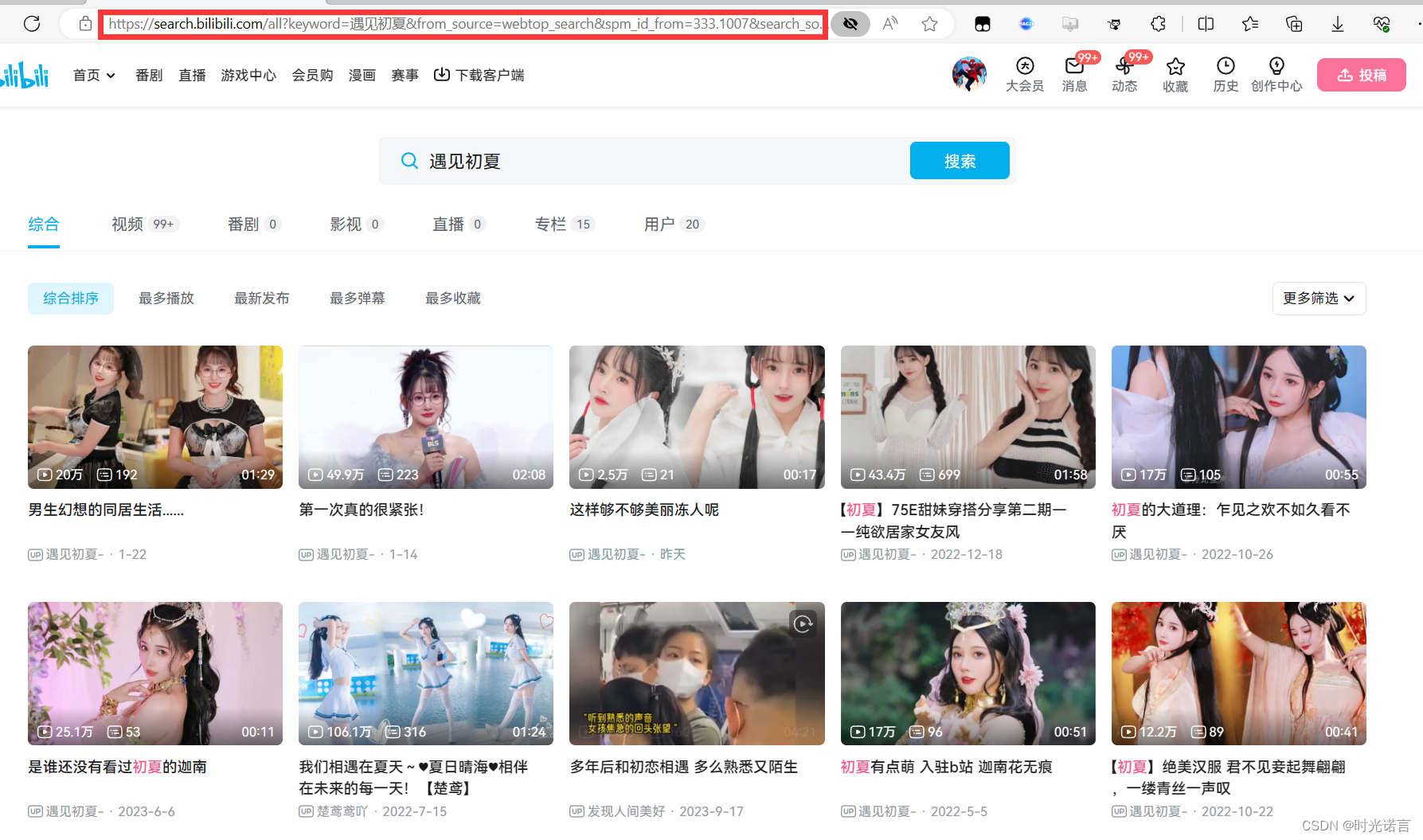
以B站为例,抓取自己喜欢的up主
咳咳,内容是什么并不重要,重要的是一定要复制上面的url信息(这是对干部的考验)
然后将类似于下面的自定义问题对GPT进行提问:
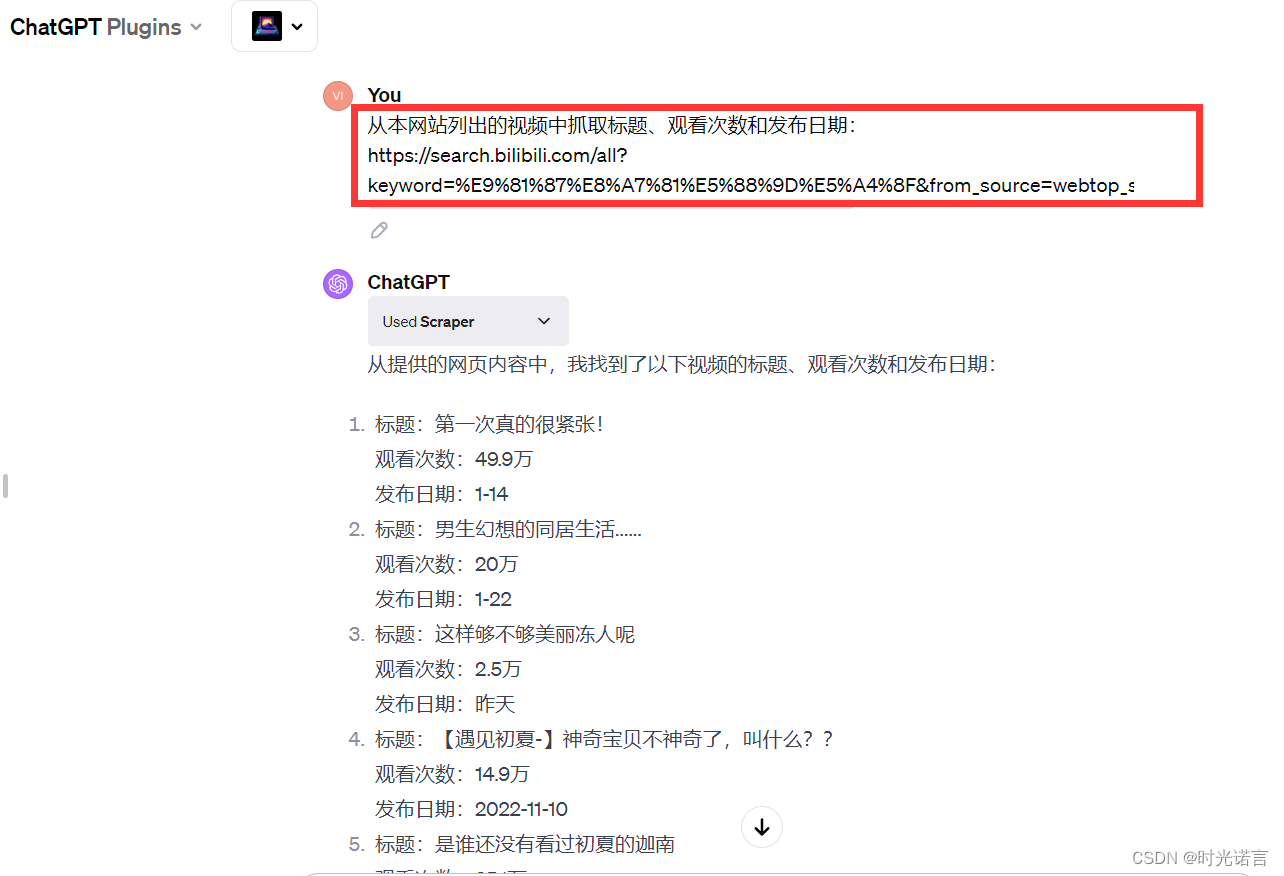
他会得出你想要的答案,当然,也可以继续追问(如果你觉得数量不够或者有其他问题)。
1.3 导出数据
由于此插件不能导出文件,所以要先告诉他要生成什么格式的文件,这样方便我们后续创建相应文件
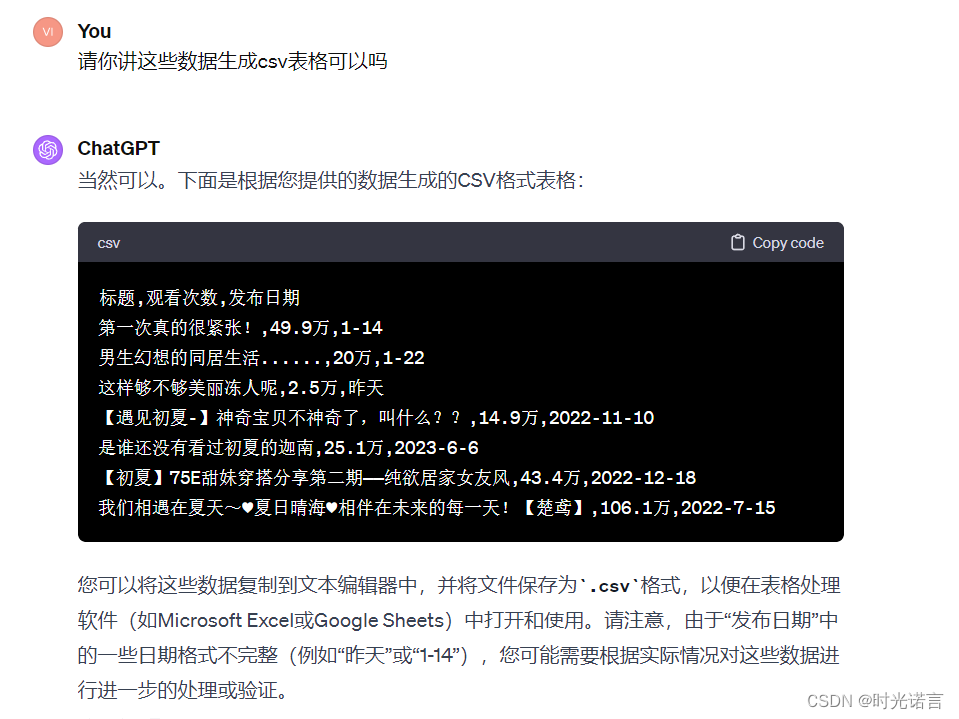
大概就是这么多,其他的功能需要你们来探索。
二. 大杀器——GPT-Crawler
这款工具的核心在于利用代码工具将GPT和爬虫联系在一起,爬取到的无序信息可以让GPT帮忙梳理。
2.1 克隆GitHub相关仓库
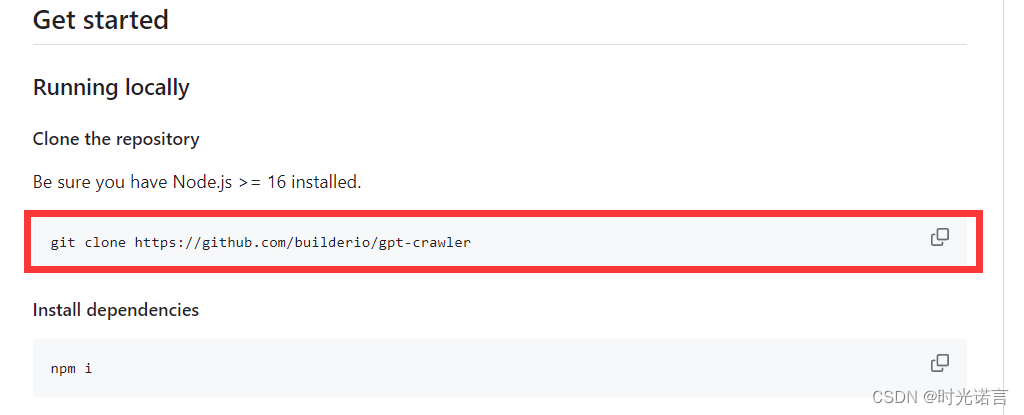
这一步其实比较简单,但是会出现一些很费时间的小问题。
在执行克隆操作时,如果出现类似于Failed to connect to github.com port 443 after 21098 ms: Timed out这种错误,请尝试以下措施:
需要去设置里看看,开启的系统代理的port是多少?

我这里是7890,所以需要在cmd中执行下列命令:
git config --global http.proxy http://127.0.0.1:7890
git config --global https.proxy http://127.0.0.1:7890
这样之后再试一次clone命令会发现克隆成功并且网速飞快。
2.2 安装相关依赖项
首先就是要下载Node.js,GPT-Crawler对Node.js的依赖必须大于等于16
这个下载基本无脑装,实在不放心随便搜一个教程跟着走就行了。
安装好Node.js后,就可以继续往下走了
注意这次一定要以管理员的身份打开命令行窗口cmd!!!
然后进入你克隆仓库的位置,我的目录如下图:

一定一定是以管理员身份运行的,否则没有权限!
随后执行下列命令即可
npm install
没什么问题的话就安装好依赖项了。
2.3 配置参数并运行
随后打开仓库中的config.ts文件,这是你的爬虫配置文件,有什么需要可以在这里面改
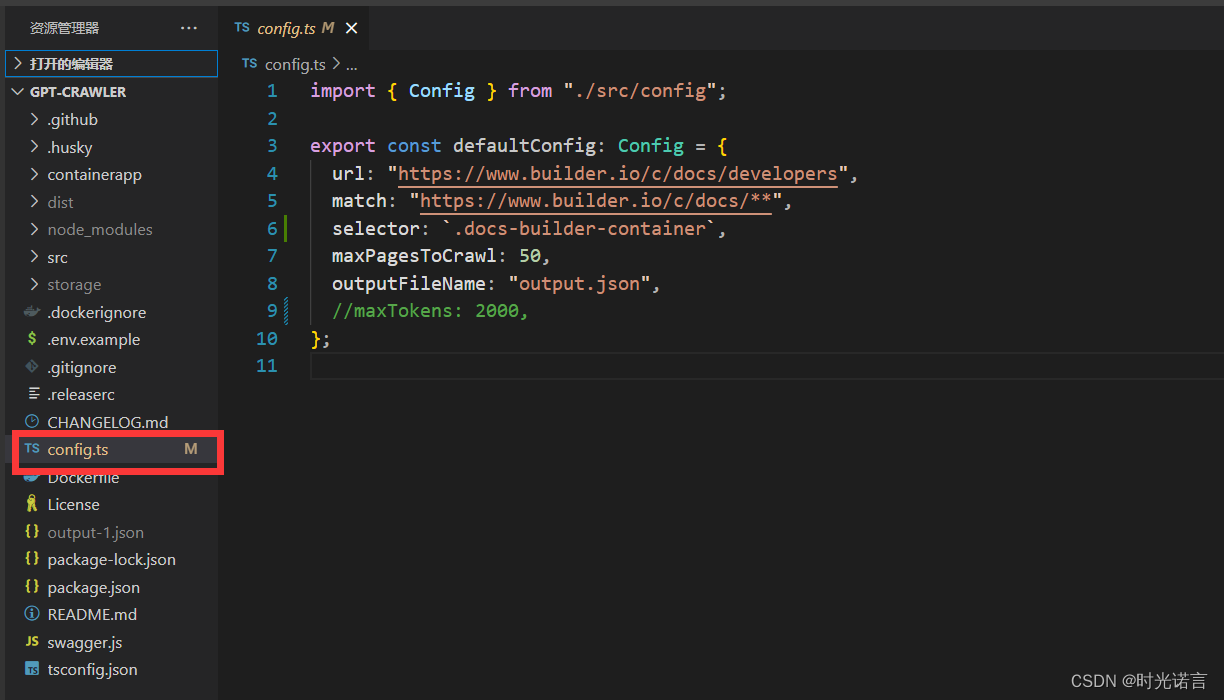
这是可设置的参数的解释:
- url:爬虫开始爬取的 URL。
- match:用于在页面上查找链接的模式。
- selector:用于抓取文本内容的选择器。
- maxPagesToCrawl:爬虫最多爬取的页面数。
- outputFileName:数据输出的文件名。
- resourceExclusions:可选项,用于排除资源,如图片或字体文件的扩展名。
- maxFileSize:可选项,最大文件大小,单位为兆字节,包含在输出文件中。
- maxTokens:可选项,输出文件中包含的最大令牌数。
调整好参数后,选择在命令行或者VSCode中终端运行下列代码(在本目录中)即可开始抓取数据
npm start
我爬取的是小红书的一个户外运动网页的评论
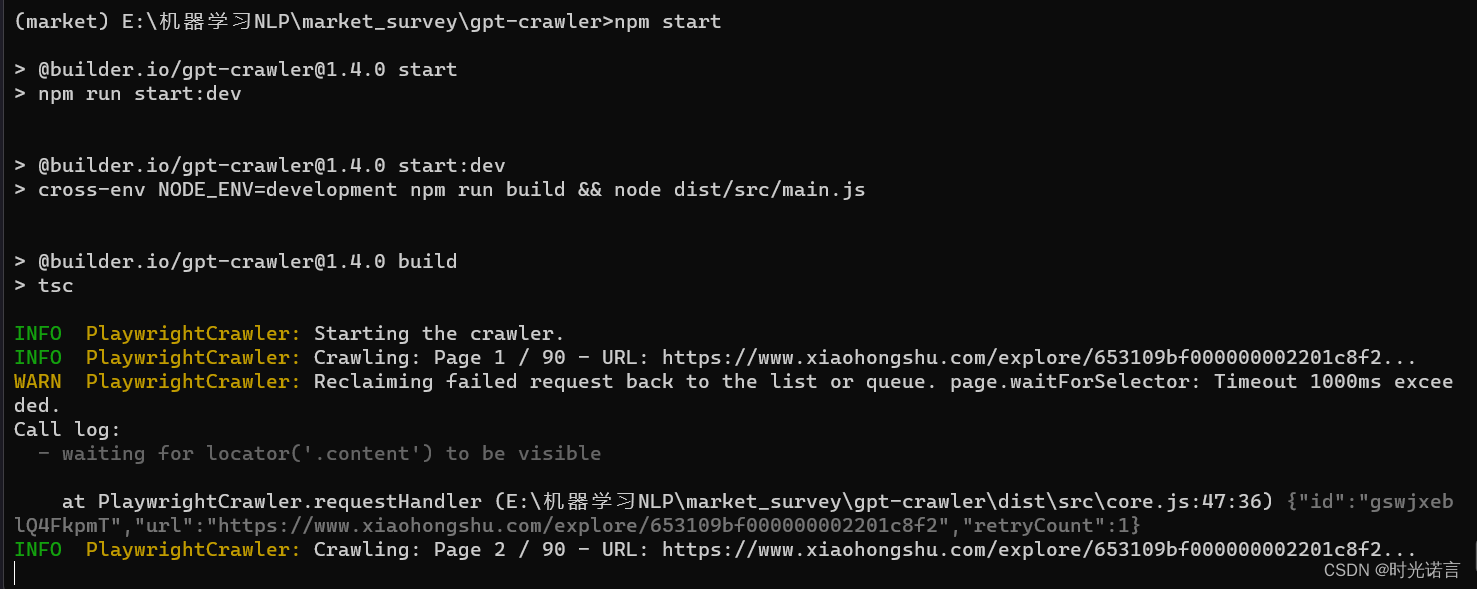
时间会依照你设置的参数等比例增加,请耐心等待,最后完成后的结果会输出到output.json文件中(如下图)

2.4 使用GPTs进行分析
创建一个专属自己的GPTs
首先点击Explore键

然后创建一个专属自己的GPT
进入之后会有专门的配置单元
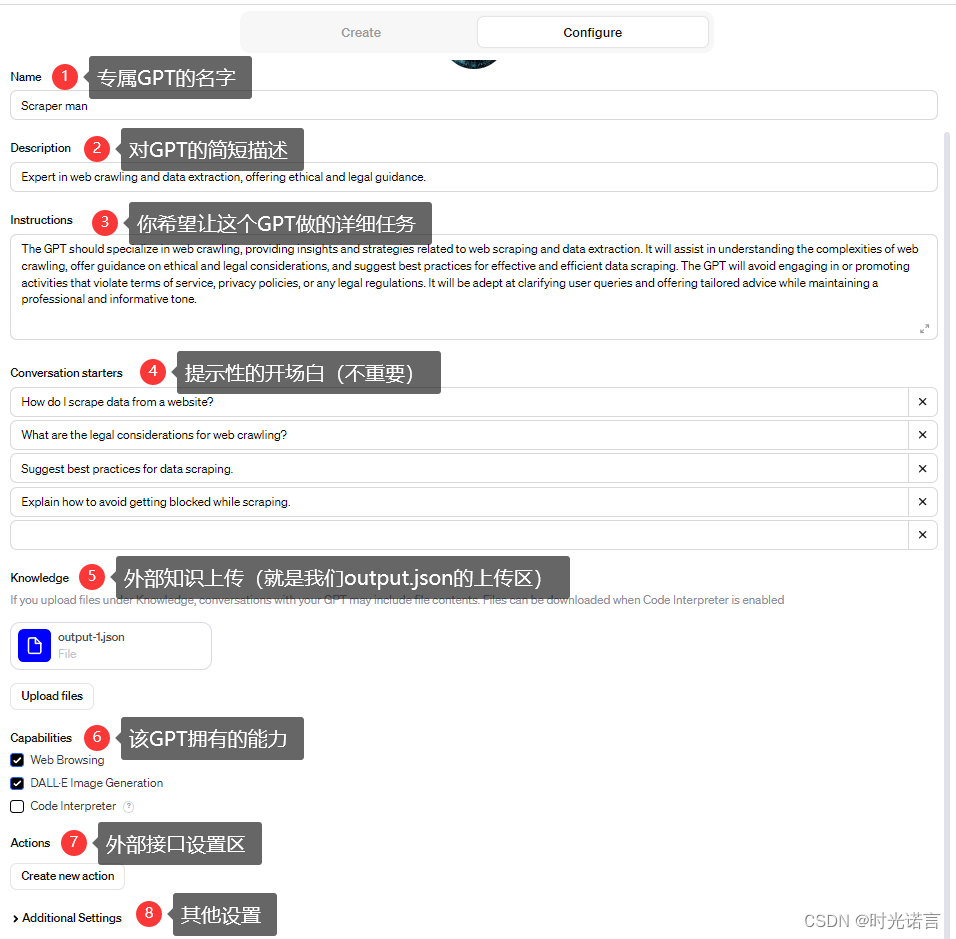
将写好的output.json文件传入给你的指定GPT进行分析(上传给GPT的知识区),如下图
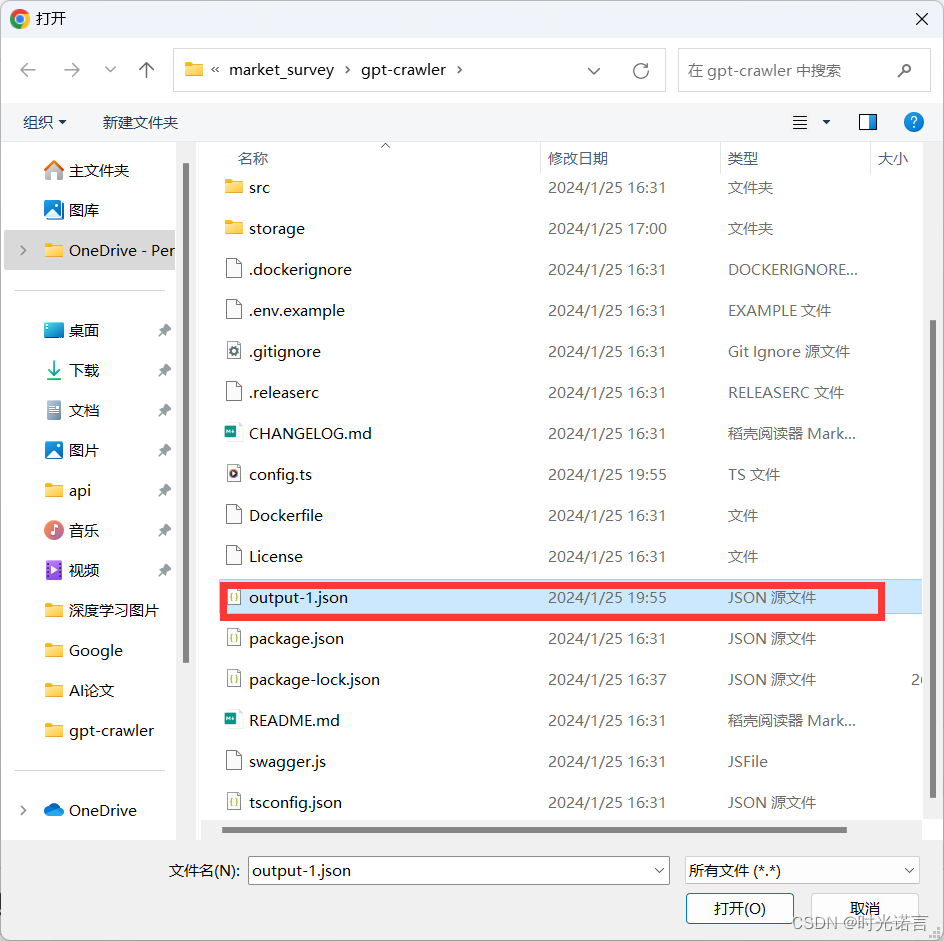
之后要对GPT进行提问(针对所传入的知识)
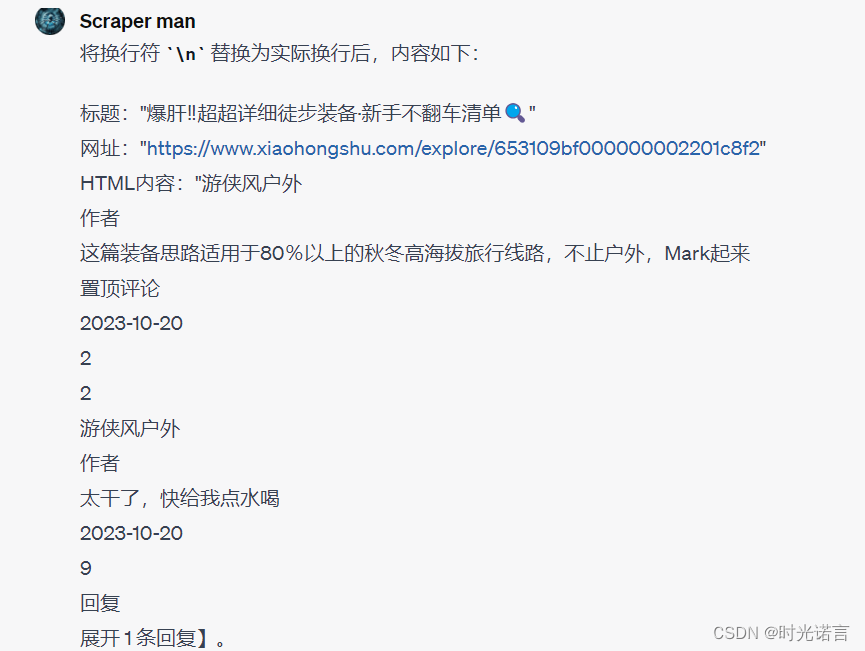
由于我这里的数据量实在有限,所以分析价值不大,但是一但爬取的数据非常多时,用GPT进行数据清洗和数据整理是非常高效方便的!
三. 八爪鱼
八爪鱼其实已经不是GPT的范畴了,但是他在某种意义上仍然非常方便,并且使用起来也非常简单
3.1无脑下载八爪鱼
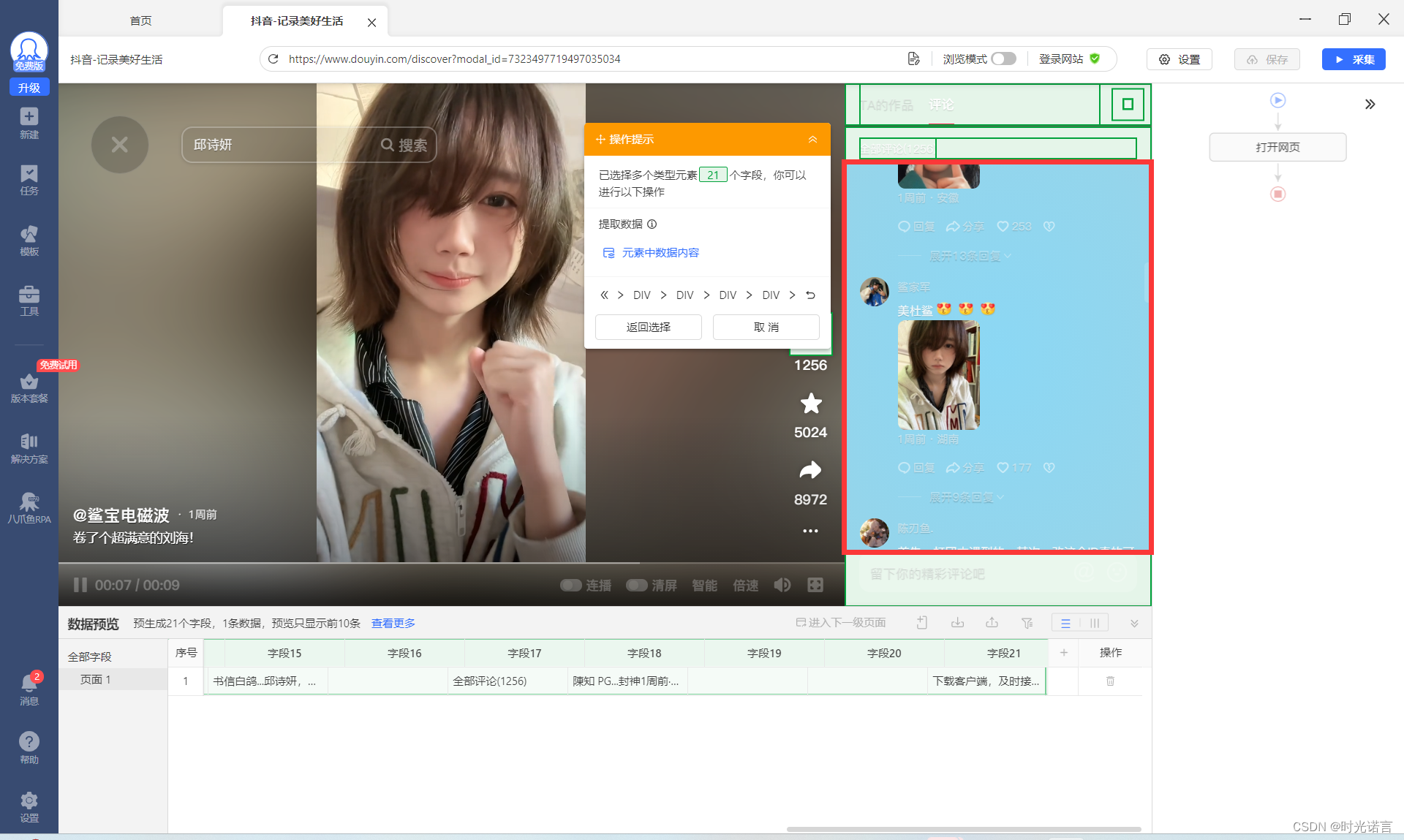
3.2 选取爬取区域
这也是八爪鱼特别独特的功能,采用图像分割的方式将不同区域分割出来,方便采集不同区域的信息
同时,在爬取APP时还支持cookie登录,这样就不会有权限的阻碍。
咳咳,我也是随便选了一个视频的一个评论进行抓取。
3.3开始采集
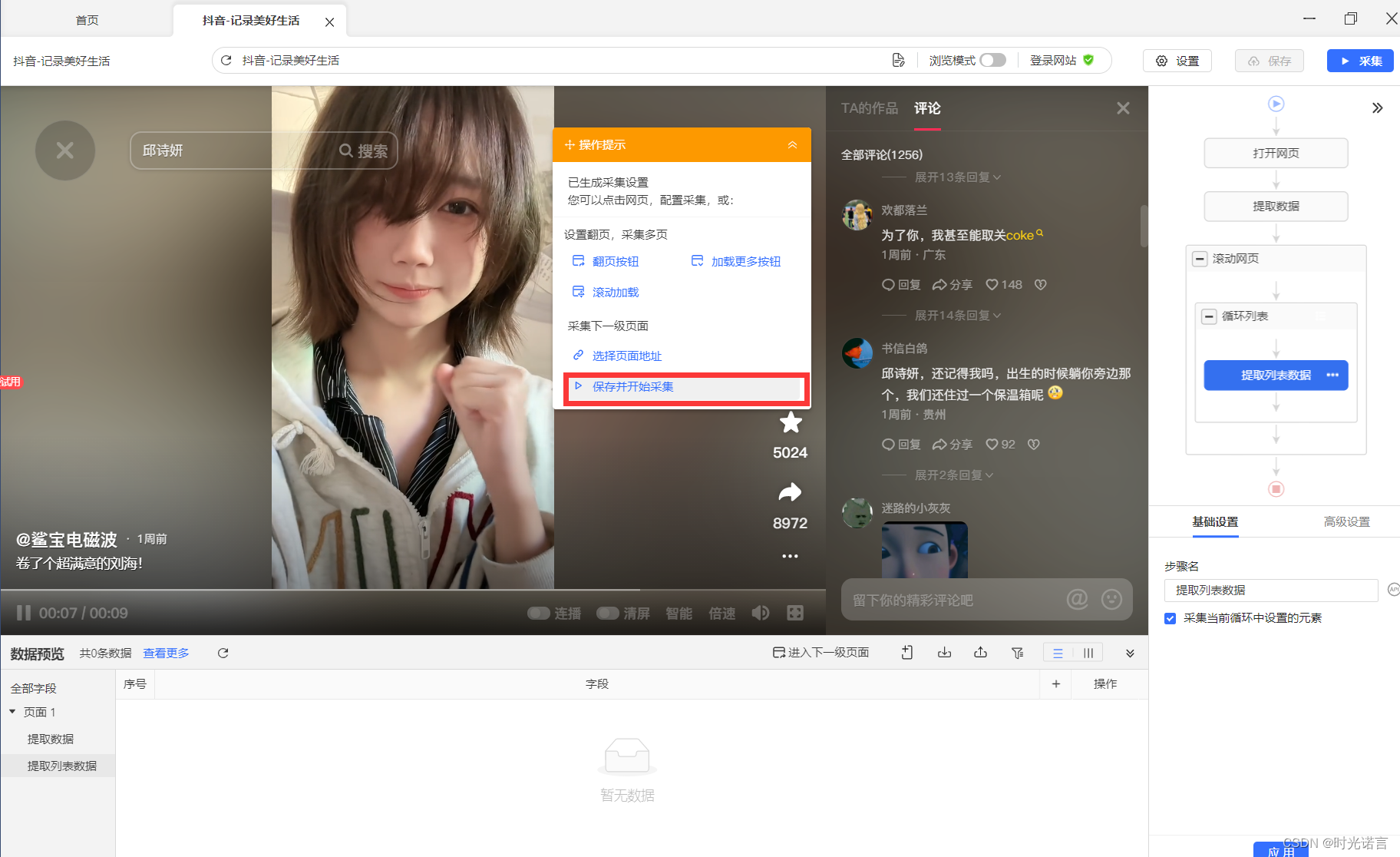
一般用户只能选用本地里的普通导出
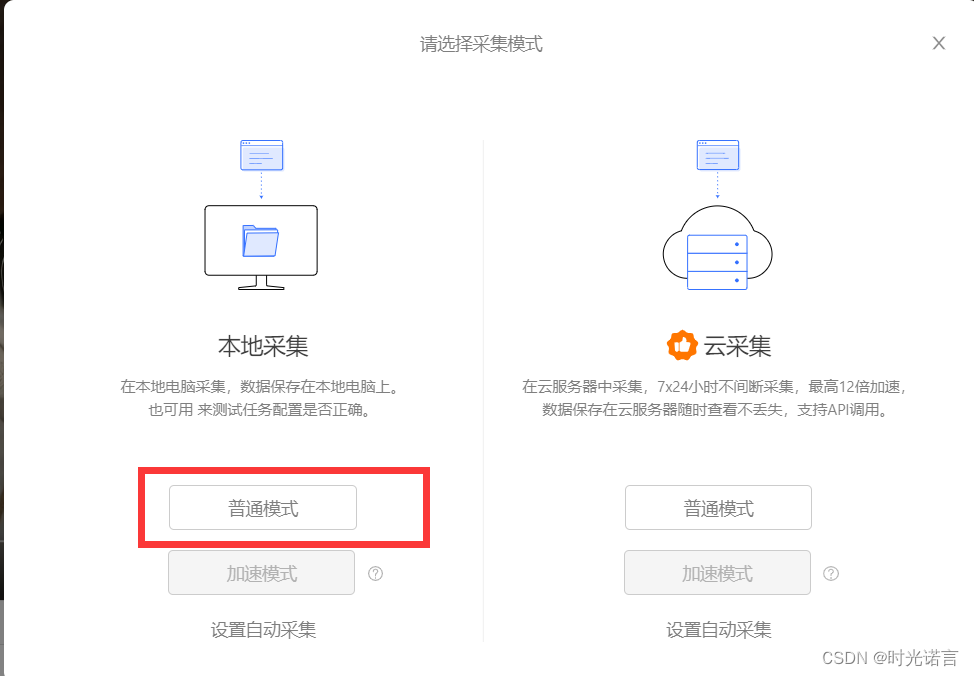
3.4 导出数据
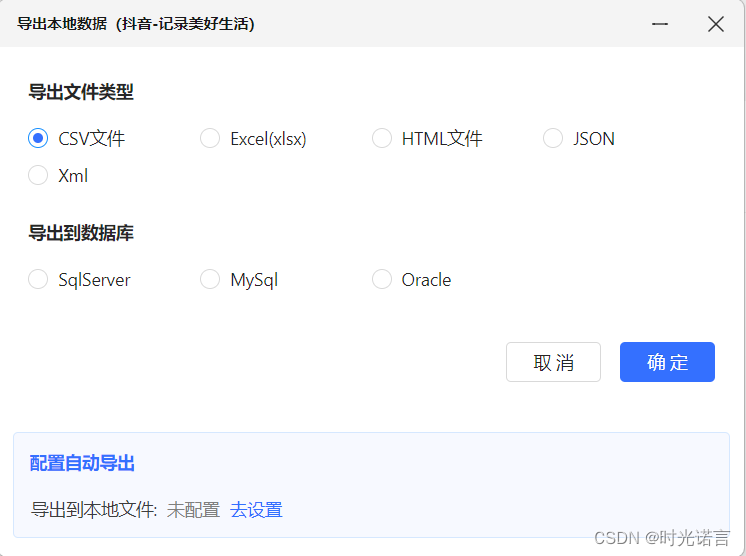
数据采集完成后,点击导出数据

最后选择你需要的数据格式就OK啦!
以上就是我认为的三种爬虫比较省事的方法,有其他方法的大佬欢迎交流,码字不易,还请点赞收藏啦哈哈。















 2206
2206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











