






目录
关于bgsave(不影响redis处理其他客户端请求和命令)
select 1. /xxx 切换数据库
默认情况下redis给我们提了16个数据库(就是和mysql那种一样的数据库)

DBSIZE- 获取当前数据库中的key的个数

flushdb-删除当前数据的所有key
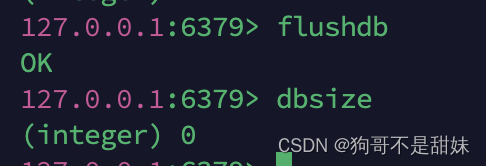
flushall-删除所有表的所有库
Redis应用层协议
redis客户端,使用程序操作redis——RESP(redis的应用层协议名字)
简单好去实现
快速进行解析
肉眼可读
进阶第一法
Redis事务
事务就要联想到mysql (一致性,原子性,持久性,隔离性)
mysql原子性:要么操作打包一起全部成功,要么全部失败
但是Redis的他只是一起打包,他打包的命令中有可能有的没有执行成功,所以一般都说Redis不具有原子性
redis不具有一致性:redis没有约束,没有回滚,事务执行过程中如果修改某个操作出现失败,可能会引起不一致的情况
Redis更是不具有隔离性(Redis所有的操作都是基于共享内存的,多个客户端可以同时访问和修改Redis中的数据,redis并没有直接的隔离性机制,可以考虑Redis的乐观锁机制,通过版本号,或者时间戳来去判断数据是否被其他客户端修改过)
不具备持久性->数据存硬盘中->才会持久 Redis是一个内存数据库,把数据存储在内存中的(持久化,放到内存中(为了快)) 最终redis会在硬盘和内存中都存储数据,但是此处的持久化机制,和事务并没有直接关系。
Redis实现事务是引入了队列,开始事务的时候,此时客户端输入的命令,就会发给服务器并且进入这个队列中(并不是立即执行),当遇到了"执行事务"命令的时候,此时就会把队列中这些任务都按照顺序依次执行。
Redis事务为啥搞这么简单,不像是mysql这样呢?(mysql在背后付出了代价(额外开空间等等开销。时间上:也要有更大的执行开销)
什么时候用Redis事务呢?如果需要把多个操作打包进行,使用事务比较合适的秒杀场景。
典型写法
如果不加任何限制,就可能会出现"线程安全"问题
获取仓库中剩余商品的个数 if(个数>0){ 下单成功 商品个数-= }开启事务
get count
if count>0
decr count
执行事务(redis收到执行事务的操作时候,才会真正执行)
假如第二个客户端(执行命令发过来,才会真正执行第二个事务中的内容,此时第一个事务执行事务命令已经运行过了,此时第二个事务get到的count就已经是第一个事务--之后的结果了)
可以用lua脚本实现redis进阶事务
开启事务:MULTI(猫体)
执行事务:EXEC
放弃当前事务:DISCARD
此时并没有执行上述指令,而是保存了上述请求,此时如果再开一个客户端,再尝试这几个key对应的数据,是没有结果的~~
dicard丢失事务操作,当开启事务,并且给服务器发送若干个命令之后,此时服务器重启~此时这个事务怎么办,此时的效果就等同于discard
WATCH监控某个key是否在事务执行前,发生了改变,等同于乐观锁
乐观锁:加锁之前,有一个心理预期,预期接下来锁冲突的概率比较低。
悲观锁:加锁之前,也有一个心理预期,接下来锁冲突的概率比较高(锁冲突:两个线程,针对一个锁加锁,一个加锁成功,一个就阻塞等待,冲突概率低和冲突概率高接下来要做的工作是不一样的。)
只有exec之后,才会真正执行事务的操作(同样CAS的ABA问题也涉及过)




具体该如何进行持久化呢
1.RDB(Redis Database)
2.AOF(Append only File)
1)定期备份:
RDB定期把我们Redis内存中数据,都写给硬盘中,生成一个"快照"
定期具体两种方式:
(1)手动触发:程序员通过redis客户端,执行特定的命令,来触发快照生成
save,执行save时,redis全力以赴进行快照生成操作,此时会阻塞redis的其他客户端命令,类似于keys *这种
bgsave,bg->bachground(后面)并不会影响Redis服务器处理其他客户端请求和命令(并发编程的场景,此处redis使用多进程,完成并发编程,完成bgsave实现
(2)自动触发(配置文件)
关于bgsave(不影响redis处理其他客户端请求和命令)
1.判断当前是否已经存在其他正在工作的子进程,比如已经有一个子进程正在执行bgsave,此时直接把bgsave返回
2.如果没有其他工作子进程,就通过fork这样的系统调用,创造出一个子进程来
fork
fork是Linux系统创造子进程的一个api(系统不同,api也不会相同),直接把当前进程,复制一份(会复制,pcb,虚拟地址空间,文件描述符表),作为子进程,安排子进程(Pob,->(复制的性能开销),文件描述表,虚拟,地址 ,空间)
否,写时拷贝,若子进程,父进程内存数据完全一样,此时并非会真拷贝,一旦某一方针对这个内存数据做出了修改,则会立即触发,物理内存上的拷贝(父进程,不会大批内存数据的变化,因此子进程的写时拷贝并不会触发多次,可保证了整体拷贝时间可控。
二进制文件->(把内存中的数据,压缩)->生成rdb镜像操作把要生成的快照数据,先保存到临时文件,当快照生成完毕之后,在删除之前的rdb文件,把新生成的rdb文件,把新生成的rdb替换成dump.rdb

rdb文件中中数据,并非你这边插入了数据,就立即更新
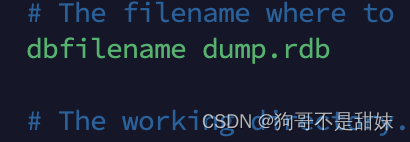
rdb生成的持久化文件的名字
rdb文件存储的位置
rdb触发时间:
1.手动(save bgsave)
2.自动触发条件(看配置文件)
15min至少存在一次修改
5分钟10次修改
一分钟内10000次修改
12:00:00开始插入数据
12:00:01开始redis收到了大量key变化的请求,(假如断电了,那么这个数据就会丢失,那么我们该怎么办呢? 采用AOF解决
12:01生成下一个快照文件
注意这里数值可以自动修改,但是有个基本原则:生成一次rdb快照,这个成本是一个比较高的成本,不能让这个操作执行的过于频繁。

手动save/bgsave自动生成快照
redis生成快照也可以自动触发
1.通过配置文件,save执行M时间,修改N次
2.通过shutdown命令,关闭redis服务器,也会自动触发(service redis-server restart正常关闭,kill -9 -xxx端口号,结束进程,rdb此时就会来不及复制数据,就会丢失)
3.redis进行主从复制,主节点也会自动生成rdb快照,后把rdb快照文件传输给从节点
正常重启的情况,redis会推出自动触发rdb,异常则会丢失
stat dump.rdb文件。 innode编号 linux的stat命令
Linux文件系统,组织方式(ext4),把文件系统分成三个部分
1.超级块(放的一些管理信息)
2.innode(存放innode数据结构,包含了文件各种元数据
3.block(存文件数据内容)
直接用save,不会触发子进程
bgsave:创造子进程,子进程完成持久化操作(持久化把数据写入新文件,用新文件换旧的文件)直接使用save,此时不会触发子进程&文件替换,而是,直接在当前进程中,往刚才同一个文件中写入数据。
4.通过自动配置生成rdb快照
手动改坏rdb,一定通过kill进程方式,重新启动redis服务器(这样才会真正损坏,不要损坏,问题还是蛮麻烦的,前后改还没准能跑,但是一旦中间位置被毁就g)
假如通过service redis-server restart重启,就会在redis服务器退出后重新生成rdb快照,把改坏的文件替换掉了
redis-check-rdb检查工具和redis服务器在5.0版本是同一可执行程序,可运行时,假如不同选项,从而使用不同的功能。
运行时候以rdb为参数,此时就是检查工具来运行,并不会真正启动redis服务器
AOF使用文本来组织数据,进行一系列字符串切分
老版本的rdb,放到新版本不一定能够识别
遍历旧的redis有key,取数据后,放到新redis服务器即可
RDB最大问题就是不能够实时化保存数据,两次快照之间,实时数据kennel随着重启而去丢失,这时也就引入另一个AOF
AOF(append only file)
类似于mysql的binlog会把用户的每个操作,都记录到文件中
当aof生效的时候,rdb就会关闭,启动的时候就不在读取rdb文件内容了
aof默认是关闭状态

上面表示开始,还是关闭aof操作(当前是关闭),下面这个是aof的文件名,和rdb文件的所在位置一样
AOF是一个文本文件,每次操作都会把记录到文本文件中,通过一些特殊符号作为分隔符。
那么我们思考一个问题:他这东西又写内存,又写硬盘,又写内存,会快吗?
实际上是没有影响的!并没有影响到redis处理请求的速度
1.AOF机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓存区,积累一波之后,再统一写入硬盘(大大降低了,写硬盘的次数)
2.硬盘上读写数据,顺序读写的速度是比较快的(还是比较内存要慢很多)随机访问则速度比较慢~~
AOF是每次把新的操作写入原有文件的末尾,属于顺序写入~。
刷新频率越高,性能影响越大,同时数据的可靠性越高。
刷频率越低,性能越小,数据可靠性越低。
AOF文件持续增长,体积会越来越大,会影响到,redis下次启动时间,redis启动的时候读取aof文件内容
aof中是记录了中间的过程,但是实际上redis重新启动的时候,只是关注结果,因此redis存在一个机制,就是针对aof文件进行整理,可以剔除其中冗余操作,并且合并一些操作,达到aof文件瘦身的效果。
同样也是分为手动触发和自动触发
手动触发:调用bgrewriteaof命令
自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数自动触发时机
auto-aof-rewrite-min-size:表示触发重写时AOF的最小文件大小,默认是64MB
auto-aof-rewrite-percentage:代表当前AOF占用大小相比较上次重写的时候增加的比例
父进程负责接收请求,子进程负责针对aof文件进行重写
注意!!!重写的时候,不关心aof文件原来都有啥~,只是关心内存中最终的数据状态!!
子进程只需要把内存中当前数据,获取出来,以AOF格式写入到一个新的AOF文件中
(内存中的数据的状态,就已经是把AOF文件整理后的模样了)
此处的子进程写数据过程,十分类似于RDB生成的一个镜像快照,只不过RDB这里是按照二进制方式来生成的,AOF重写,则是按照AOF要求的文本格式,来生成的,都是为了把当前内存中的数据状态记录到文件中。
子进程在写新的AOF文件的同时,父进程仍在不停的接收客户端的新的请求,父进程还是会写把这些请求产生的AOF数据写入缓存区,再刷新到原有的AOF文件里面。
在创建子进程的一瞬间,子进程就继承了当前父进程的内存状态,因此,子进程的内存数据是父进程fork之前的状态,fork之后,新来的请求,对内存的修改,子进程是不知道的
此时父进程这里,有准备了一个aof_rewrite_buf缓冲区~专门放fork之后收到的数据。
子进程这边,把aof数据写完之后,会通过信号通知父进程,父进程再把aof_rewrite_buf缓冲区的内容也写入到新AOF文件里~(子进程fork之前,父进程fork之后,两个写完之后,就可以用新的aof文件代替旧的aof文件里。)
如果,在执行bgrewriteaof时候,当前redis已经正在进行aof重写了,会怎么样呢?
此次,不会再次aof重写,直接返回了。
如果,在执行bgwirteaof的时候,发现redis在生成rdb文件的快照,会咋样呢?
此时,aof重写操作就会等待,等待rdb快照生成完毕之后,再进行执行aof重写
rdb对于fork之后的新数据,就置之不理了,而aof对于fork之后的新数据,采取了aof_rewrite_buf缓冲区的方式来处理
rdb本身的设计理念,就是来定期备份的
只要是定期备份,就难以最新的数据保持一致
aof的理念就是实时备份。哪个好,具体看场景
父进程fork完毕之后,就已经让子进程写新的aof文件了,并且随着时间的推移,子进程就很快写完了新的文件,要让新的aof文件代替旧的,父进程此时还在继续写这个即将消亡的旧的aof是否有意义呢?(考虑断电情况,子进程内存数据会丢失,新的aof文件内容还不完整,如果父进程不坚持写旧的aof文件,重启没办法保证数据完整性)


混合持久化
redis引用了混合持久化的方式,结合了rdb和aof的特点,按照aof的方式,每一个请求/操作,都记录文件,在触发aof重写之后,就会把当前内存的状态按照rdb二进制格式写入到新的aof文件中,后续再进行到操作,仍然是按照aof文本的方式追加到文件后面
下面这个yes表示开启混合持久化
当redis同时存在aof和rdb文件时候,以aof为主

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











