







一、语音识别不文明用语
1.1、语言检查库profanity-check
这是一个快速、强大的Python库,用于检测字符串中的不雅或冒犯性语言。更多关于profanity-check如何构建以及为何要构建它的信息可在这篇博客文章中找到。
1.2、测试模型
运行环境:
python 3.8.19
jieba 0.42.1
numpy 1.20.0
scikit-learn 0.22.2
profanity-check 1.0.3
这是一个简单的示例
import joblib
from profanity_check import predict_prob
import jieba
# 自定义的中文黑名单词语
chinese_blacklist = {'卧槽', '屌', 'TM'}
def contains_profanity(text, chinese_blacklist):
# 使用jieba进行中文分词
words = set(jieba.lcut(text))
# 检查分词后的词语是否在自定义黑名单中
if any(word in chinese_blacklist for word in words):
return True
# 使用profanity-check库进行中文不文明用语检测
try:
prediction = predict_prob([text])[0]
if prediction > 0.5: # 使用预测概率来判断是否含有不文明用语
return True
except Exception as e:
print(f"Error predicting profanity in text: {text}")
print(e)
return False
# 测试文本
texts = [
"卧槽,什么屌玩意这么贵。",
"嫌贵你TM不买。",
"不买了,你家卖的真贵"
]
for text in texts:
if contains_profanity(text, chinese_blacklist):
print(f"'{text}' 此句有不文明用语")
else:
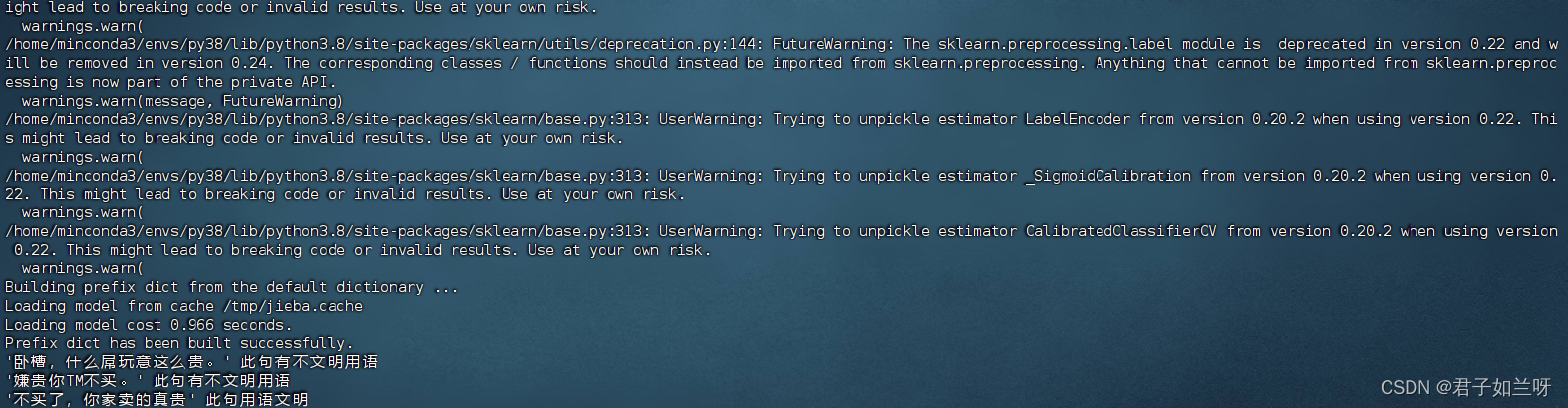
print(f"'{text}' 此句用语文明")结果:根据结果可以看到输入的三段话被准确的识别出来了
1.3、读取自定义的中文黑名单词语
创建自定义的中文黑名单txt文件,在正式环境中应当放置在MySQL服务器上构建自定义中文黑名单库
以下是一个简单的示例
import joblib
from profanity_check import predict_prob
import jieba
# 从文件读取中文黑名单词语
def load_chinese_blacklist(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
blacklist = set([word.strip() for word in file.readlines()])
return blacklist
def contains_profanity(text, chinese_blacklist):
# 使用jieba进行中文分词
words = set(jieba.lcut(text))
# 检查分词后的词语是否在自定义黑名单中
if any(word in chinese_blacklist for word in words):
return True
# 使用profanity-check库进行中文不文明用语检测
try:
prediction = predict_prob([text])[0]
if prediction > 0.5: # 使用预测概率来判断是否含有不文明用语
return True
except Exception as e:
print(f"Error predicting profanity in text: {text}")
print(e)
return False
# 从文件加载自定义的中文黑名单词语
chinese_blacklist = load_chinese_blacklist('/home/myj/uncivilized_words.txt')
# 测试文本
texts = [
"卧槽,什么屌玩意这么贵。",
"嫌贵你TM不买。",
"不买了,你家卖的真贵"
]
for text in texts:
if contains_p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











