






一、Llama2的安装部署操作步骤
1.1、docker环境的使用
说明:根据服务器部署的环境来分析,由于此服务器为多人使用,且不相互影响,故此服务器需要进行自己的docker环境下,如果是自己部署那么本身便不存在docker直接滤过1.1即可。
1.1.1、启用docker环境
服务器环境执行
docker run -itd --name myj myj:latest /bin/bash
名字可以自行命名
1.1.2、查看docker目录
查看现在的docker目录(只能查看正在运行的docker)
docker ps
1.1.3、进入docker容器
根据上一步的命名查看自己的CONTAINER ID
执行
docker attach b3fed5352531进行自己的镜像下

1.1.4、查看docker状态
在本地查看目前的docker容器 (查看所有的docker)
docker ps -aup 为已经启动的docker容器,exited为以及停止的docker容器

1.1.5、启用docker容器
启动docker容器,
docker start b3fed5352531我们可以看到CONTAINER ID为b3fed5352531的状态已由Exited (137) 16 hours ago改变为了Up 5 seconds。可以看到该docker容器已成功启动

1.1.6、停用docker容器
停止docker容器 ,
docker stop b3fed5352531我们可以看到CONTAINER ID为b3fed5352531的状态已由Up 5 seconds改变为了Exited (137) 16 hours ago。可以看到该docker容器已成功停止
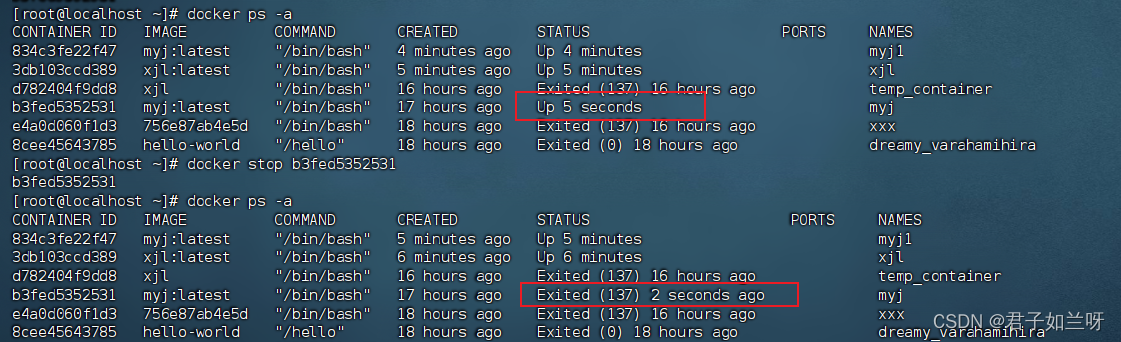
1.1.7、删除docker容器
删除docker容器,
docker rm e4a0d060f1d3我们可以看到CONTAINER ID为e4a0d060f1d3的docker容器已被成功删除。
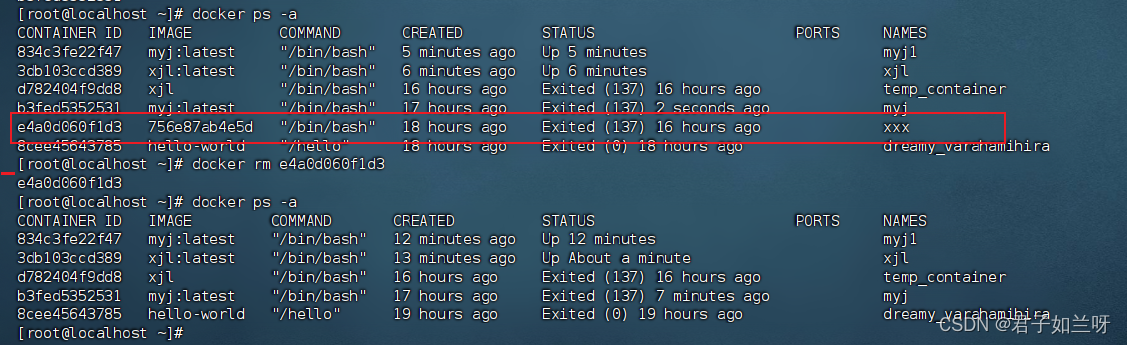
1.1.8、打包docker容器
docker容器打包,由于服务器关机后docker会清空,故需要再关机前打包
执行
docker commit myj myj1.0,将原本名为myj的docker打包为myj1.0

1.1.9、查看是否打包成功
查看是否打包成功
docker images
1.2、安装Anaconda3 (1.2和1.3选其一即可)
Anaconda是一个大型的Python数据科学平台,它包含了大量的Python包和工具,如NumPy、Pandas、Scikit-learn等,还包括了conda包管理器、某个版本的Python、以及众多的科学计算工具。Miniconda则是一个更小的发行版,它只包含最基本的Python和conda包管理器,以及一些必要的依赖项。
用户界面和工具。Anaconda提供了一个可视化的集成开发环境(IDE)Spyder,以及一个图形用户界面(Anaconda Navigator),这有助于简化库的安装、环境的创建和管理,特别适合新手用户或不熟悉命令行的用户。Miniconda则不包含这些额外的用户界面和工具,所有的操作都需要通过命令行来完成。
安装体积和存储需求。由于Anaconda预装了大量的包和工具,它的安装体积相对较大,占用更多的存储空间。Miniconda相对较小,占用空间更少,适合对存储空间有严格要求的用户。
灵活性和更新周期。Miniconda提供了更大的灵活性,用户可以根据实际需求安装必要的包,避免不必要的存储占用。Anaconda的更新周期通常几个月才会发布一个新版本,而Miniconda则更频繁地更新,经常会推出新的版本。
Anaconda适合需要使用大量Python包和工具进行数据科学项目的用户,而Miniconda则更适合只需要基本Python环境和少量工具,或对存储空间有严格要求的用户
1.2.1、上传文件
先将文件上传至本地目录下
再讲文件拷贝至镜像下,
docker cp /home/Anaconda3-2024.02-1-Linux-x86_64.sh b3fed5352531:/home/拷贝本地环境home下的Anaconda3-2024.02-1-Linux-x86_64.sh到镜像b3fed5352531的根目录的下一级的home文件夹下
在本地环境下执行语句

到docker环境下查看,文件已成功导入进来了

1.2.2、为文件设置权限
chmod +x Anaconda3-2024.02-1-Linux-x86_64.sh
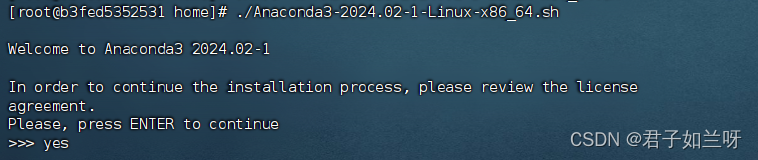
1.2.3、安装.sh文件
./Anaconda3-2024.02-1-Linux-x86_64.sh
或sh Anaconda3-2024.02-1-Linux-x86_64.sh
或bash Anaconda3-2024.02-1-Linux-x86_64.sh跳出In order to continue the installation process, please review the license
agreement.意思是为了继续安装你需要查看许可证,输入yes回车
协议很长一直回车即可
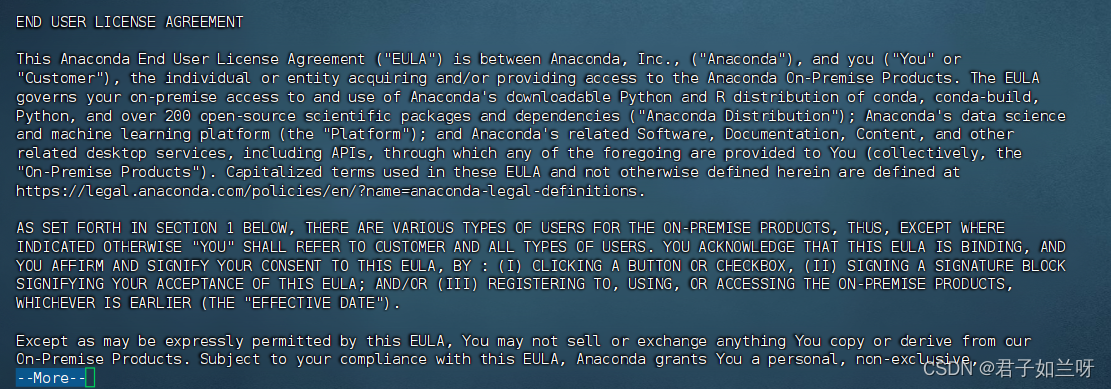
出现Do you accept the license terms?(你接受许可吗?)

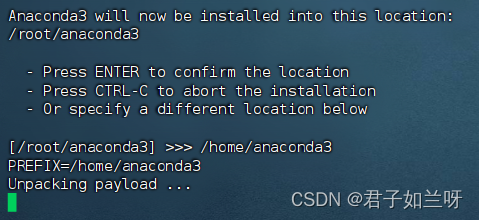
Anaconda3 will now be installed into this location:
Anaconda3现在将安装到此位置:/root/anaconda3

这里我们安装到/home/anaconda3下,(这里因为磁盘在/home 下挂载,实际根据情况而定)无需再去创建anaconda3文件夹直接指定即可,这里可以看到已经开始安装了
这里的大致意思是:安装完成。您想更新您的shell配置文件以自动初始化conda吗?这将在启动时激活conda,并在激活时更改命令提示符。

输入yes,也可以输入no,后续自行配置
到这里anaconda3已经安装成功了

1.2.4、配置环境变量
如果不配置环境变量的话,采用conda -V命令会提示找不到这个命令。

打开profile 文件配置anaconda环境vim /etc/profile
i插入;在最后一行添加
export PATH=/home/anaconda3/bin:$PATH此处的路径为时间安装的路径

esc : wq
刷新配置
source /etc/profile再执行conda -V这个命令就可以看见 anaconda的版本

1.2.5、使用Anaconda
打开一个新的终端窗口,您应该就可以正常使用conda命令。(把其他终端窗口关闭);查看当前Anaconda的虚拟环境conda env list;只有base的基础目录

使用conda创建一个新的虚拟环境。以下是创建名为myjenv的环境,并指定python的版本为3.8;
conda create --name myjenv python=3.8遇到输入的y/n的时候选择y
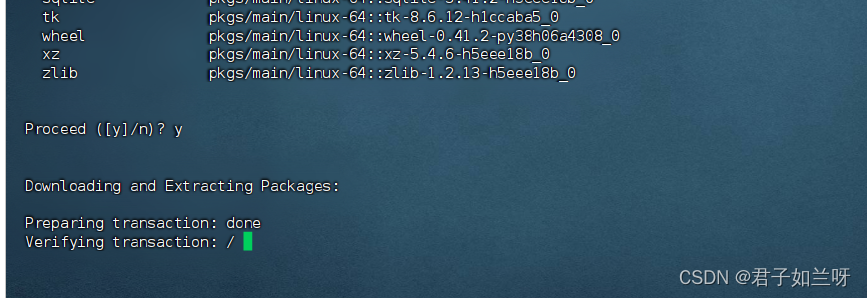
再次查看
conda env list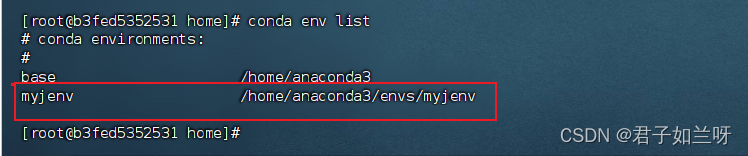
将环境切换到base下
source ~/.bashrc
激活创建的环境
conda activate myjenv
在此环境下输入python -V,可以看到此时的python版本为python3.8和之前指定的相对应;如果要退出虚拟环境使用conda deactivate

1.3、安装minconda3
1.3.1、上传文件
先将文件上传至本地目录下
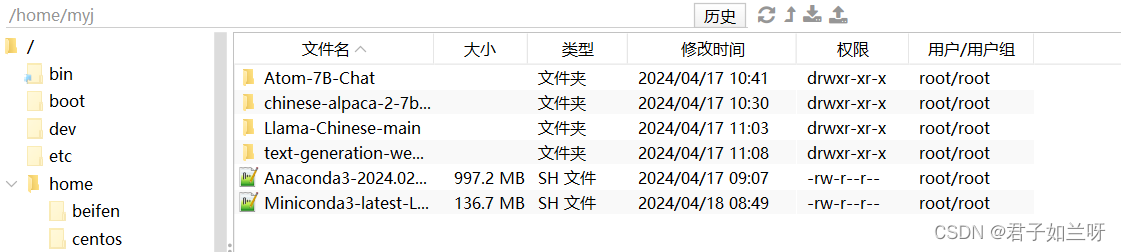
再将文件拷贝至镜像下,
docker cp /home/myj/Miniconda3-latest-Linux-x86_64.sh 6c7ebf47272a:/home/拷贝本地环境home下的文件夹到镜像6c7ebf47272a的根目录的下一级的home文件夹下。
在本地环境下执行语句

到docker环境下查看,文件已成功导入进来了

1.3.2、为文件设置权限
chmod +x Miniconda3-latest-Linux-x86_64.sh
1.3.3、安装.sh文件
./Miniconda3-latest-Linux-x86_64.sh
或sh Miniconda3-latest-Linux-x86_64.sh
或bash Miniconda3-latest-Linux-x86_64.sh跳出In order to continue the installation process, please review the license
agreement.意思是为了继续安装你需要查看许可证,输入yes回车

协议很长一直回车即可
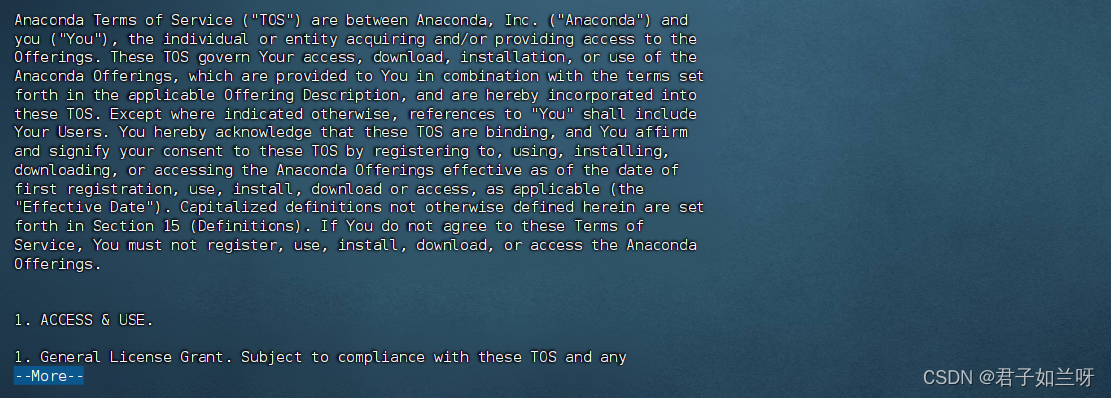
出现Do you accept the license terms?(你接受许可吗?)

Minconda3 will now be installed into this location:
Minconda3现在将安装到此位置:/root/minconda3
这里我们安装到/home/minconda3下,(这里因为磁盘在/home 下挂载,实际根据情况而定)无需再去创建minconda3文件夹直接指定即可,这里可以看到已经开始安装了
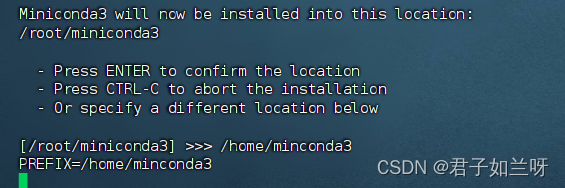
这里的大致意思是:安装完成。您想更新您的shell配置文件以自动初始化conda吗?这将在启动时激活conda,并在激活时更改命令提示符。

输入yes,也可以输入no,后续自行配置
到这里anaconda3已经安装成功了

1.3.4、配置环境变量
如果不配置环境变量的话,采用conda -V命令会提示找不到这个命令。

打开profile 文件配置anaconda环境vim /etc/profile
i插入;在最后一行添加
export PATH=/home/minconda3/bin:$PATH此处的路径为时间安装的路径
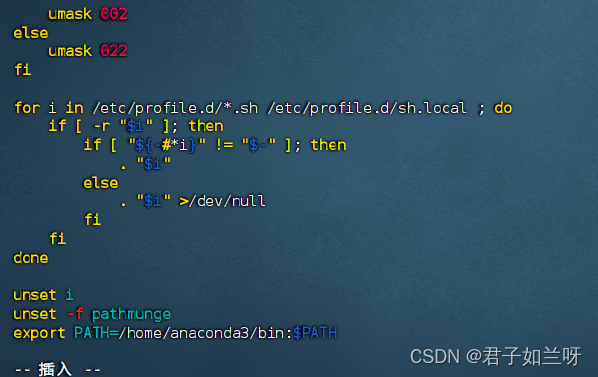
esc : wq
刷新配置
source /etc/profile再执行conda -V这个命令就可以看见 anaconda的版本

1.3.5、使用minconda
打开一个新的终端窗口,您应该就可以正常使用conda命令。(把其他终端窗口关闭);查看当前minconda的虚拟环境conda env list;只有base的基础目录

使用conda创建一个新的虚拟环境。以下是创建名为myjenv的环境,并指定python的版本为3.12;conda create --name myjenv python=3.12,遇到输入的y/n的时候选择y

再次查看conda env list
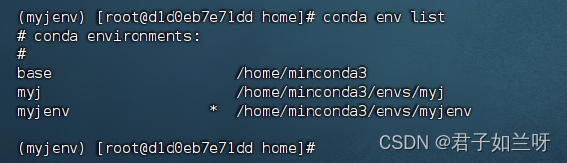
输入source ~/.bashrc,将环境切换到base下

激活创建的环境conda activate myj

在此环境下输入python -V,可以看到此时的python版本为python3.8和之前指定的相对应;如果要退出虚拟环境使用conda deactivate

1.3.6、查看当前和Python有关的进程
ps aux | grep python1.4、基于CPU启动Atom-7B-Chat大模型
本次以Llama自带的底座作为此次项目部署的底座。
1.4.1、下载并上传文件
在GitHub - LlamaFamily/Llama-Chinese: Llama中文社区,Llama3在线体验和微调模型已开放,实时汇总最新Llama3学习资料,已将所有代码更新适配Llama3,构建最好的中文Llama大模型,完全开源可商用下载对应的包,下载完成后上传至服务器中,解压后得到以下项目文件

注意此时的项目中并不包含模型文件
可在Atom-7B-Chat Hugging Face仓库获取模型,由于hugging face无法直接访问,这里推荐下载到本地
故需要通过git clone 魔搭社区获取模型文件,总计大小(15G)

这里获取到的文件中,文件包不正确需要手动下载
访问地址魔搭社区
进入后显示的页面中的红线框中的部分需要手动下载并上传到服务器中替换之前的文件

把这里面的红框中每一个文件都下载了。(总共下载下来大概14G)
先将文件上传至本地目录下

再将文件拷贝至镜像下,
docker cp /home/myj/Miniconda3-latest-Linux-x86_64.sh 6c7ebf47272a:/home/myj/拷贝本地环境home下的文件夹到镜像的根目录的下一级的home文件夹下的myj文件夹中。
1.4.2、启用docker环境
服务器环境执行
docker run -itd --name myj myj:latest /bin/bash
1.4.3、进入docker容器
根据上一步的命名查看自己的CONTAINER ID
执行 docker attach b3fed5352531 进行自己的镜像下

1.4.4、进入Python虚拟环境
执行:conda activate myj310

1.4.5、conda更换镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --set show_channel_urls yes
1.4.6、python更换镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
1.4.7、选择一个底座进入
本次使用Llama的底座通过命令行执行文件
cd /home/myj/Llama-Chinese-main/Llama-Chinese-main
1.4.8、安装底座所依赖的包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
安装过程中发现Llama-Chinese底座需要的依赖部分包是有版本限制的。依赖包的版本与Python的版本有关系,所以本次安装时指定的虚拟环境的版本是3.12的版本,而Python3.12的版本对应的torch最低版本是2.2.0,torch的版本不能低于2.1.2否则无法支撑方法,目前根据遇见的问题得出Python的版本不低于3.9,如果低于3.9则bitsandbytes无法到0.42.0版本。而且transformers无法安装4.39.0。
1.4.9、启动项目,在命令行输出结果
进入底座所在的文件夹下创建一个text.py文件
vim text.py 。将下面的语句复制进去
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 这里面是下载的Atom-7B-Chat模型的文件位置
model = AutoModelForCausalLM.from_pretrained('/home/myj/Atom-7B-Chat',device_map='auto',torch_dtype=torch.float32)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('/home/myj/Atom-7B-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human:价签日常巡查检查评测标准如下,共分四项,每项得分25分。01、要求价签与商品能对应;02、要求商品价签有无缺失、破损;03、要求商品价签使用类型正确;04>、要求所有商品都必须有价签。请根据价签日常巡查要求对以下检查结果进行分析并评分汇总:所摆放的商品与价签一致,所摆放的价格标签干净整洁没有破损缺失,其中部分商品标签没有摆放,检查价格标签的摆放,所摆放标签和实际商品基本一致。按照项目和得分的方式对每一项进行评分,对每项评分进行单项得分计算。 \n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)中间的语句可以自由的换为你自己的语句
执行
python text.py --model_name_or_path /home/myj/Atom-7B-Chat目前我这里的算力执行需要5分钟,内存使用达到28个G

1.4.10、从MySQL数据库中读取输入文本并将输出结果写入数据中
建立数据库链接
connect = pymysql.Connect(host='自己的数据库地址',port=端口号,user='用户名',passwd='密码',db='数据库',charset='utf8')拼接从数据库中读取的input字段中的内容
cursor.execute("SELECT id,concat('<s>Human:',input,'根据场景分析顾客购买的香烟品牌和购买的数量。 </s><s>') as input FROM text WHERE output='' or output is null;")文中的意思是读取数据库表text中的id和input字段,其中input要拼接上语句的头和尾部用于大模型识别,后面放上你要问的问题。
进入底座所在的文件夹下创建一个text.py文件
vim text1.py 。将下面的语句复制进去
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import pymysql.cursors
# 创建数据库连接
connect = pymysql.Connect(host='sh-cdb-hj9th2n4.sql.tencentcdb.com',port=60068,user='root',passwd='NJjjs@2020',db='py_text',charset='utf8')
# 创建游标对象
cursor = connect.cursor()
# 读取数据
cursor.execute("SELECT id,concat('<s>Human:',input,'根据场景分析顾客购买的香烟品牌和购买的数量。 </s><s>') as input FROM text WHERE output='' or output is null;")
# 获取结果
result = cursor.fetchall()
# 加载预训练模型,这里面是下载的Atom-7B-Chat模型的文件位置
model = AutoModelForCausalLM.from_pretrained('/home/myj/Atom-7B-Chat',device_map='auto',torch_dtype=torch.float32)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('/home/myj/Atom-7B-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
# 遍历结果,解析文本并更新数据库
for id, input_text in result:
# 使用模型生成output文本
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 更新数据库中的output字段
update_query = "UPDATE text SET output = %s WHERE id = %s"
update_data = (output_text, id)
cursor.execute(update_query, update_data)
connect.commit()
# 关闭数据库连接
cursor.close()
connect.close()读取input的内容为
顾客:拿包中华。店员:好的,需要哪一款?顾客:硬中华。店员:好的,请问你需要几包?顾客:我要买一包。店员:好的,一包硬中华45元。
经过大模型后写入数据库中的output的内容为
Human:顾客:拿包中华。店员:好的,需要哪一款?顾客:硬中华。店员:好的,请问你需要几包?顾客:我要买一包。店员:好的,一包硬中华45元。根据场景分析顾客购买的香烟品牌和购买的数量。
场景分析:顾客在购买香烟时,询问店员需要购买什么品牌和数量。店员回答顾客需要购买硬中华,顾客要求购买一包。店员收取顾客45元。
在docker的虚拟环境中运行,不报错基本就成功,去数据库中查看即可。

1.4.11、技术架构解读
1、读取对话文件:音频文件,音频流。
2、读取后通过语音模型进行处理,根据音色音调不同区分出对话
3、设置定时调度任务自动执行,将得出文本对话结果,非结构化数据,写入数据库表中,数据模型携带:UID,商户Id属性,对话内容(input)属性,创建时间属性。UID为唯一索引
4、语音对话模型得到数据库中的对话内容属性中存储的内容,不断检索数据库UID,对话内容(input)。
5、对非结构化数据处理后,根据UID需改表中字段output。output用于存储解析后的非结构化数据。
6、构建品牌模型表,比如小苏代表五星红杉树。
7、通过jieba库构建分词,将非结构化数据转为结构化数据。存储到商户销售模型表中,模型属性有:UID,商户ID,品牌,数量,销售时间(文本创建时间)
8、对商户销售模型做数据可视化分析。
9、对核心文本进行检讨加密。
10、可以CPU+GPU运行的,但是我的服务器GPU太小跑不起来
1.5、模型文件实操
1、CPU运行Llama底座和Atom模型
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 这里面是下载的Atom-7B-Chat模型的文件位置
model = AutoModelForCausalLM.from_pretrained('/home/myj/Atom-7B-Chat',device_map='auto',torch_dtype=torch.float32)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('/home/myj/Atom-7B-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human:价签日常巡查检查评测标准如下,共分四项,每项得分25分。01、要求价签与商品能对应;02、要求商品价签有无缺失、破损;03、要求商品价签使用类型正确;04>、要求所有商品都必须有价签。请根据价签日常巡查要求对以下检查结果进行分析并评分汇总:所摆放的商品与价签一致,所摆放的价格标签干净整洁没有破损缺失,其中部分商品标签没有摆放,检查价格标签的摆放,所摆放标签和实际商品基本一致。按照项目和得分的方式对每一项进行评分,对每项评分进行单项得分计算。 \n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
2、定时执行读取修改数据库
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import pymysql.cursors
import pytime
def process_data():
# 创建数据库连接
connect = pymysql.Connect(host='sh-cdb-hj9th2n4.sql.tencentcdb.com', port=60068, user='root', passwd='NJjjs@2020', db='py_text', charset='utf8')
# 创建游标对象
cursor = connect.cursor()
while True:
try:
# 读取数据
cursor.execute("SELECT id, concat('<s>Human:', input, '根据场景分析顾客购买的香烟品牌和购买的数量。</s><s>') AS input FROM text WHERE output='' OR output IS NULL;")
# 获取结果
result = cursor.fetchall()
# 加载预训练模型
model = AutoModelForCausalLM.from_pretrained('/home/myj/Atom-7B-Chat', device='cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = AutoTokenizer.from_pretrained('/home/myj/Atom-7B-Chat', use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
for id, input_text in result:
# 使用模型生成output文本
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 更新数据库中的output字段
update_query = "UPDATE text SET output = %s WHERE id = %s"
update_data = (output_text, id)
cursor.execute(update_query, update_data)
connect.commit()
# 关闭游标
cursor.close()
# 等待一段时间再次处理数据
pytime.sleep(60) # 10秒钟
except Exception as e:
print("Error occurred:", str(e))
# 出现异常时回滚并关闭连接
connect.rollback()
cursor.close()
connect.close()
break
if __name__ == "__main__":
process_data()3、读取数据库中的某个字段再放入数据库中
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import pymysql.cursors
# 创建数据库连接
connect = pymysql.Connect(host='sh-cdb-hj9th2n4.sql.tencentcdb.com',port=60068,user='root',passwd='NJjjs@2020',db='py_text',charset='utf8')
# 创建游标对象
cursor = connect.cursor()
# 读取数据
cursor.execute("SELECT id, input FROM text WHERE output='' or output is null;")
# 获取结果
result = cursor.fetchall()
# 加载预训练模型,这里面是下载的Atom-7B-Chat模型的文件位置
model = AutoModelForCausalLM.from_pretrained('/home/myj/Atom-7B-Chat',device_map='auto',torch_dtype=torch.float32)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('/home/myj/Atom-7B-Chat',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
# 遍历结果,解析文本并更新数据库
for id, input_text in result:
# 使用模型生成output文本
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 更新数据库中的output字段
update_query = "UPDATE text SET output = %s WHERE id = %s"
update_data = (output_text, id)
cursor.execute(update_query, update_data)
connect.commit()
# 关闭数据库连接
cursor.close()
connect.close()
4、文本分词后写入数据库中两个数据表,一个插入一个修改
# 利用Python对dialogue表中存储的output中的文本数据进行分词,获取购买数量和单位和购买品牌,定义数量后面即是单位。写入到analysis表中的brand: 购买品牌unit: 购买单位(盒,包,条)num: 购买数量。并且将dialogue表中的UID对应analysis 表中的textId,dialogue表中的targetId对应analysis 表中的targetId,dialogue表中的deviceId对应analysis 表中的deviceId,dialogue表中的dialogueTime对应analysis 表中的dialogueTime,dialogue表中的createTime对应analysis 表中的textTime,dialogue表中的updateTime对应analysis 表中的analysisTime,analysis 表中的UID在插入时默认为UUID()
# dialogue 表中的output的示例为:香烟品牌:硬中华/n购买数量:1包。并根据读取的数据根据UID将dialogue 表中的状态改为4
# 根据以上代码生成Python语句
import uuid
import jieba
import pymysql
# 创建数据库连接
connect = pymysql.Connect(host='8.130.39.203',port=3306,user='root',passwd='NJjjs@2020',db='py_text',charset='utf8')
# 创建游标对象
cursor = connect.cursor()
# 分词函数
def tokenize(text):
return jieba.lcut(text)
# 查询 dialogue 表中的数据
query = "SELECT UID, targetId, deviceId, dialogueTime, output, createTime, updateTime FROM dialogue WHERE state = 3"
try:
cursor.execute(query)
dialogue_records = cursor.fetchall()
# 将分词结果插入到 analysis 表中
for record in dialogue_records:
uid, target_id, device_id, dialogue_time, output, create_time, update_time = record
tokens = tokenize(output)
brand = None
unit = None
num = None
# 查找购买数量
for i, token in enumerate(tokens):
if token.isdigit() and i + 1 < len(tokens):
num = int(token)
unit = tokens[i + 1]
break
if num is not None and unit is not None:
# 获取购买品牌
brand_index = output.find("品牌:")
if brand_index != -1:
brand = output[brand_index + len("品牌:"):].split("\n")[0]
# 将数据插入到 analysis 表中
analysis_uid = uuid.uuid4() # 生成 UUID
insert_query = """
INSERT INTO analysis (UID, textId, targetId, deviceId, dialogueTime, brand, unit, num, textTime, analysisTime)
VALUES (%s,%s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(
insert_query,
(analysis_uid,uid, target_id, device_id, dialogue_time, brand, unit, num, create_time, update_time)
)
# 更新 dialogue 表中的状态为 4
update_query = "UPDATE dialogue SET state = 4 WHERE UID = %s"
cursor.execute(update_query, (uid,))
except Exception as e:
print("Error occurred:", e)
connect.rollback() # 回滚事务以取消之前的更改
# 提交更改并关闭连接
connect.commit()
cursor.close()
connect.close()















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











