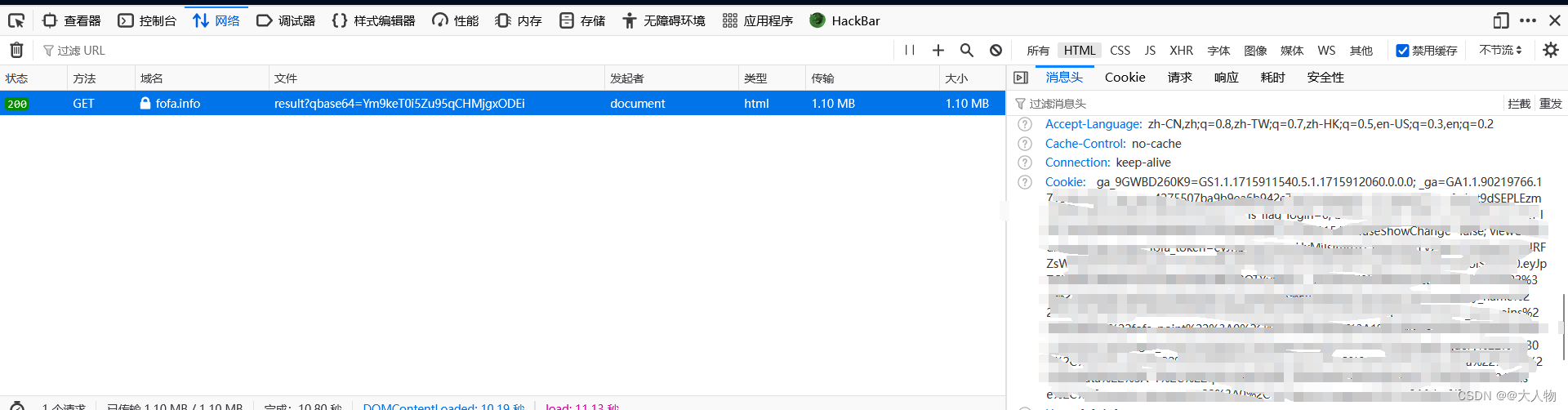
fofa凭据
- 如果没有凭据也就是没有登陆的情况下,fofa的搜索次数是有限的
- 所以在请求头中加入我们登陆后的cookie即可,cookie包含了fofa_token即可
headers = {
'User-Agent': 'xxxxxx',
'Cookie': 'xxxxxx;fofa_token=xxxxxx'
}
分析url
title="apache2"
https://fofa.info/result?qbase64=dGl0bGU9ImFwYWNoZTIi
https://fofa.info/result?qbase64=(输入的语法经过base64编码)
- 我们可以在python中引导用户输入fofa语法,然后对其进行base64编码,再拼接到url后面
result = input("输入fofa语法> ")
base64_result = base64.b64encode(result.encode()).decode('utf-8')
url = f'https://fofa.info/result?qbase64={base64_result}'
import base64
import requests
def main():
global url, headers
try:
result = input("输入fofa语法> ")
headers = {
'User-Agent': 'xxxxxx',
'Cookie': 'xxxxxx;fofa_token=xxxxxx'
}
base64_result = base64.b64encode(result.encode()).decode('utf-8')
url = f'https://fofa.info/result?qbase64={base64_result}'
except KeyboardInterrupt as e:
print(f"error: {e}")
try:
response = requests.get(url, headers=headers)
print(response.text)
except Exception as e:
print(f"error: {e}")
if __name__ == '__main__':
main()
分析响应内容


- 分析了一波响应内容,我们大致可以确定过滤a标签比较理想
- 写个函数来获取这些我们想要的ip或域名
import base64
import requests
from bs4 import BeautifulSoup
def Get_ip(response):
ip_set = set()
# 解析html内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有带有data-clipboard-text属性的span标签
spans = soup.find_all('span', attrs={'data-clipboard-text': True})
for span in spans:
ip_tar = span.get('data-clipboard-text')
if 'http' not in ip_tar:
ip_tar = f'http://{ip_tar}'
# 集合主动去重
ip_set.add(ip_tar)
print(list(ip_set))
return list(ip_set)

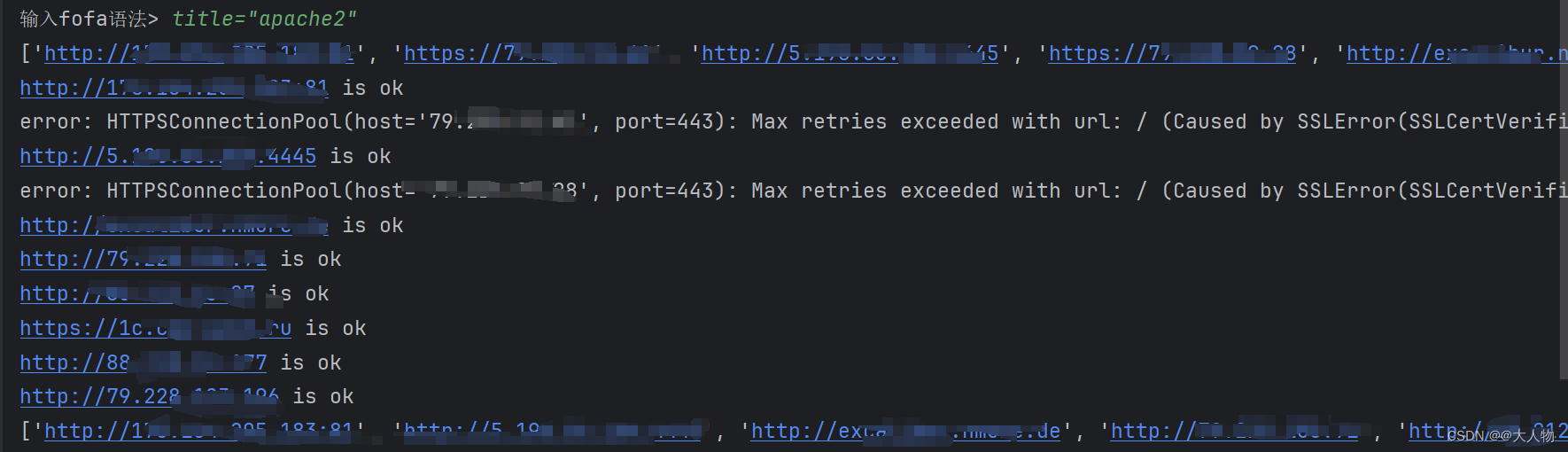
对获取到的url进行异常处理
- 有些url访问可能会超时或者是ssl证书验证等
- 对于这些异常我们对url进行筛选
def Get_requests_ip_tar(ip_tar_list):
good_ip_tar_list = []
# 3秒后超时
timeout = 3
for ip_tar in ip_tar_list:
try:
response = requests.get(ip_tar, timeout=timeout, verify=True) # 对ssl证书进行验证,避免被中间人攻击
print(f"{ip_tar} is ok")
good_ip_tar_list.append(ip_tar)
except Exception as e:
print(f"error: {e}")
continue
print(good_ip_tar_list)
完整代码
import base64
import requests
from bs4 import BeautifulSoup
def Get_requests_ip_tar(ip_tar_list):
good_ip_tar_list = []
# 3秒后超时
timeout = 3
for ip_tar in ip_tar_list:
try:
response = requests.get(ip_tar, timeout=timeout, verify=True) # 对ssl证书进行验证,避免被中间人攻击
print(f"{ip_tar} is ok")
good_ip_tar_list.append(ip_tar)
except Exception as e:
print(f"error: {e}")
continue
print(good_ip_tar_list)
def Get_ip(response):
ip_set = set()
# 解析html内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有带有data-clipboard-text属性的span标签
spans = soup.find_all('span', attrs={'data-clipboard-text': True})
for span in spans:
ip_tar = span.get('data-clipboard-text')
if 'http' not in ip_tar:
ip_tar = f'http://{ip_tar}'
# 集合主动去重
ip_set.add(ip_tar)
print(list(ip_set))
return list(ip_set)
def main():
global url, headers
try:
result = input("输入fofa语法> ")
headers = {
'User-Agent': 'xxxxxx',
'Cookie': 'xxxxxx;fofa_token=xxxxxx'
}
base64_result = base64.b64encode(result.encode()).decode('utf-8')
url = f'https://fofa.info/result?qbase64={base64_result}'
except KeyboardInterrupt as e:
print(f"error: {e}")
try:
response = requests.get(url, headers=headers)
ip_tar_list = Get_ip(response)
Get_requests_ip_tar(ip_tar_list)
except Exception as e:
print(f"error: {e}")
if __name__ == '__main__':
main()
仅供学习参考






















 2440
2440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









