






Redis
基于内存的KV键值对内存数据库
优势
- 性能极高 --Redis能读的速度是110000次/秒,写的速度是81000次/秒
- Redis数据类型丰富,不仅仅支持简单的key-value类型的数据
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
- Redis支持数据的备份,即master-slave模式的数据备份
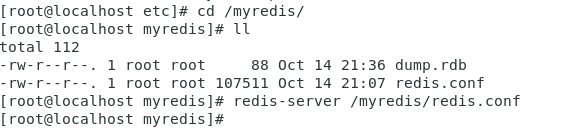
Redis启动(Linux)
-
- 切换目录
- 执行redis-server /myredis/redis.conf
初始化服务端命令跳出警告的解决方法

-
ps -ef|grep redis|grep -v grep//作用不大,不用输入
-
连接redis: redis-cli -a 666666 -p 6379
-
输入ping 得到PONG

-
退出redis客户端的连接 : quit
-
客户端关闭

十大数据类型
redis字符串(String)
- string是redis最基本的类型,一个key对应一个value
- string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象
- string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
redis列表(List)
Redis列表是最简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边)
他的底层实际是个双端链表,最多可以包含2^32-1个元素(4294967295,每个列表超过40亿个元素)
redis 哈希表(Hash)
Redis hash是一个string类型的field(字段)和value(值)的映射表,hash特别适用于存储对象
Redis中每个hash可以存储2^32-1键值对(40多亿)
redis集合(Set)
Redis的Set是String类型的无序集合,集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是intset或者hashtable
Redis中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
集合中最大的成员数为2^32-1(每个集合可以存储40多亿个成员)
redis有序集合 Zset
Redis zset和set一样也是string类元素的集合,且不允许重复的成员
不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序
zset的成员是唯一的,但分数却可以重复
zset集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1),集合中最大的成员数2^32-1
redis地理空间(GEO)
Redis GEO主要用于存储地理位置信息,并对存储的信息,进行操作,包括
- 添加地理位置的坐标
- 获取地理weihzi的坐标
- 计算两个位置之间的距离
- 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
redis基数统计(HyperLogLog)
HyperLogLog是用来做基数统计的算法,Hyperper的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总数固定且是很小的

举例:
淘宝访问量的统计
redis位图(bitmap)

举例:
打卡,签到,点赞
redis位域

redis流(stream)
redis命令
切换数据库: select 数据库号
备注:
- 命令不区分大小写,而key是区分大小写的
- 永远的帮助命令,help@类型
如 help @string

key的常见操作
| 命令 | 解释 |
|---|---|
| keys * | 查看当前库所有的key |
| exists key | 判断某个key是否存在 |
| type key | 查看你的key是什么类型 |
| del key | 删除指定的key数据 |
| unlink | 非阻塞删除,仅仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作中进行删除 |
| ttl key | 查看还有多少秒过期,-1表示永不过期,-2表示已过期 |
| expire key 秒钟 | 为给定的key设置过期时间 |
| move key dbindex [0-15] | 将当前数据库的key移动到给定的数据库db |
| select dbindex | 切换数据库[0-15],默认为0 |
| dbsize | 查看当前数据库key的数量 |
| flushdb | 清空当前库 |
| fushalll | 通杀全部库 |
String的相关命令
官网查看相关方法的命令步骤

set命令中的keepttl的相关解释说明

- mset和mget
同时设置或者获取多个键值

- msetnx:批量设置键值不存在的键
需要所有需创建的键都不存在,有一个存在其他所有的都会创建不成功

- setrange和getrange方法

- 数字的加减 : INCR和DECR,INCRBY,DECRBY
相关示例如下


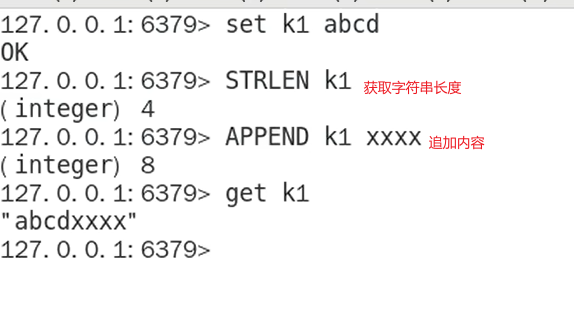
- 获取字符串长度和追加内容
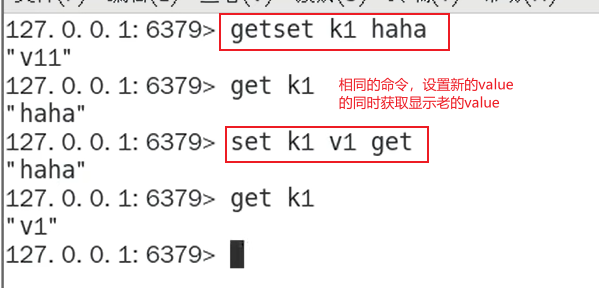
- getset,先get再set
- 应用场景
- 抖音的无线点赞某个视频,或者商品,点一下加一次
- 是否喜欢的文章
List
一个key对应多个value
底层是一个双端列表的结构,主要功能有push/pop等,一般用在栈、队列、消息队列等场景。left、right都可以插入添加
- 如果键不存在,创建新的链表
- 如果键已存在,新增内容
- 如果值全部移除,对应的键也就消失了
他的底层是一个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会比较差
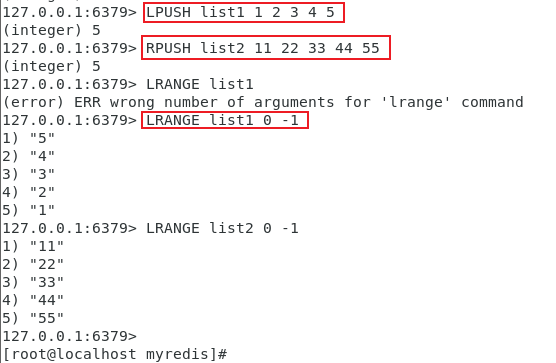
- LPUSH \RPUSH\LRANGE
从左边插入数据,从右边插入数据,遍历集合
只存在LRANGE遍历,不存在RRANGE遍历
- lpop \rpop
从左边弹出元素\从右边弹出元素
LRANGE key
- lindex key
从上大小根据传入的下标得到对应的元素
lindex key index(下标)
-
llen: 获取列表中的元素个数
-
lrem key N v1:删除N个值等于v1的元素
-
ltrim key 开始index,结束index,截取指定范围的值后再赋值给key
-
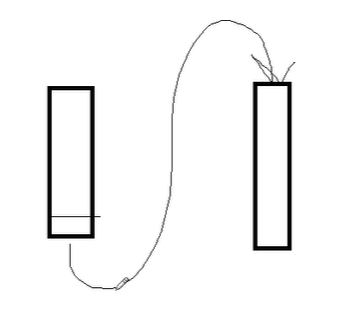
rpoplpush 源列表 目的列表
相当于将源列表的最后一个元素弹出,添加到目的列表的最上方
左边为源列表,右边为目的列表
- lset key index value
给指定列表的指定下标设置值
- linsert key before/after 已有值 插入的新值
引用场景:
微信公众号订阅的消息
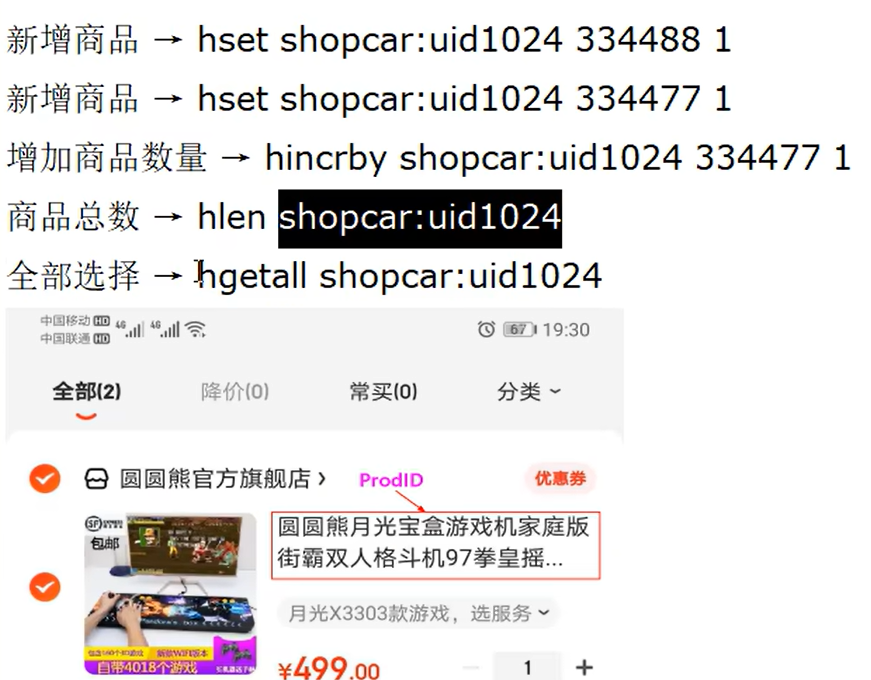
Hash
value是一个kv键值对
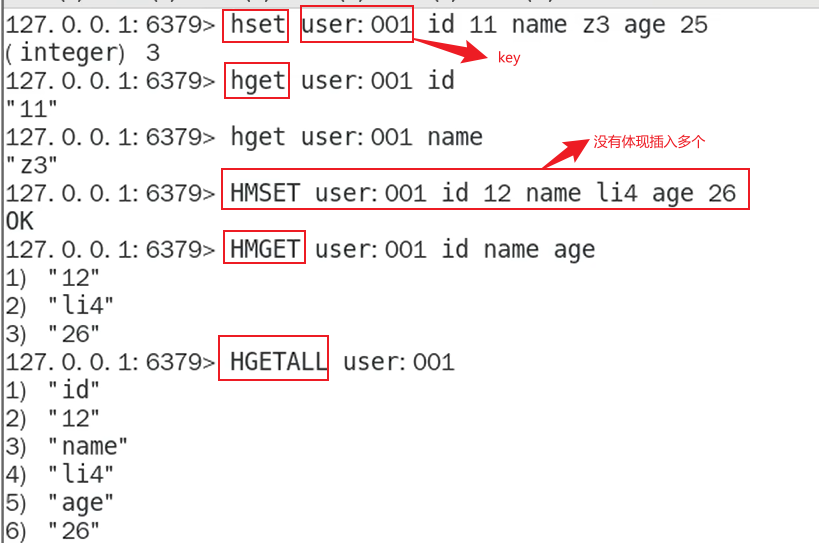
- hget,hset,hmset,hmget,hgetall
- HDEL

- HLEN
获取某个key内的全部数量
- HEXISTS
判断某个hash是否存在某个字段

- HKEYS\HVALUES
罗列所有的key\value

- HINCRBY \HINCRBYFLOAT
给某个字段的value添加指定大小的数

- hsetnx
创建的时候判断是否存在,不存在才能创建
使用场景
Set
- SCARD
查看集合的元素个数
- SADD\SMEMBERS\SISMEMBER
添加数据\遍历查询显示集合\判断是否存在某个值
用法

- SREM\SCARD
删除某个值\统计set里面的元素个数
用法

- SRANDMEMBER key [数字]
从集合中随机展现设置的数字个数元素,元素不删除
- SPOP key [N]
从集合中随机弹出N个元素,出一个删一个
- SMEMBERS
遍历集合
- smove key1 key2 在key1里已经存在的某个值
将key1里已经存在的某个值key2
集合运算
- SDIFF key[key…]
集合的差集运算A-B
属于A但是不属于B的元素构成的集合
- SUNION key[key…]
集合的并集计算A∪B:属于A或者属于B的元素合并后的集合
- SINTER key [key…]
属于A同时也属于B的共同拥有的元素构成的集合
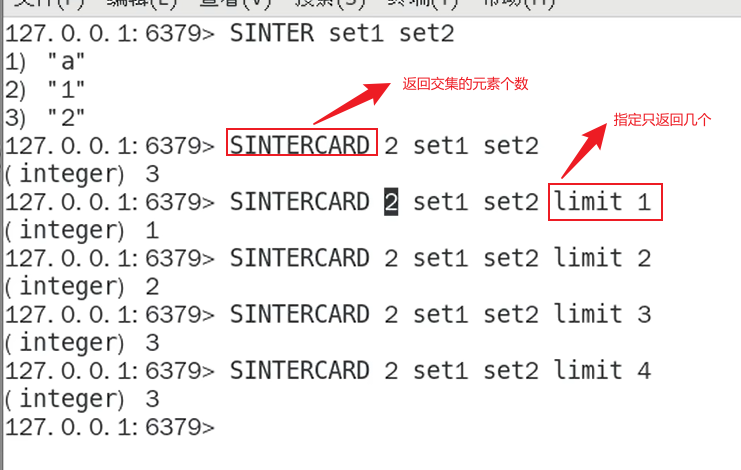
- SINTERCARD numkeys key [key…] [LIMIT 限制数]
应用场景
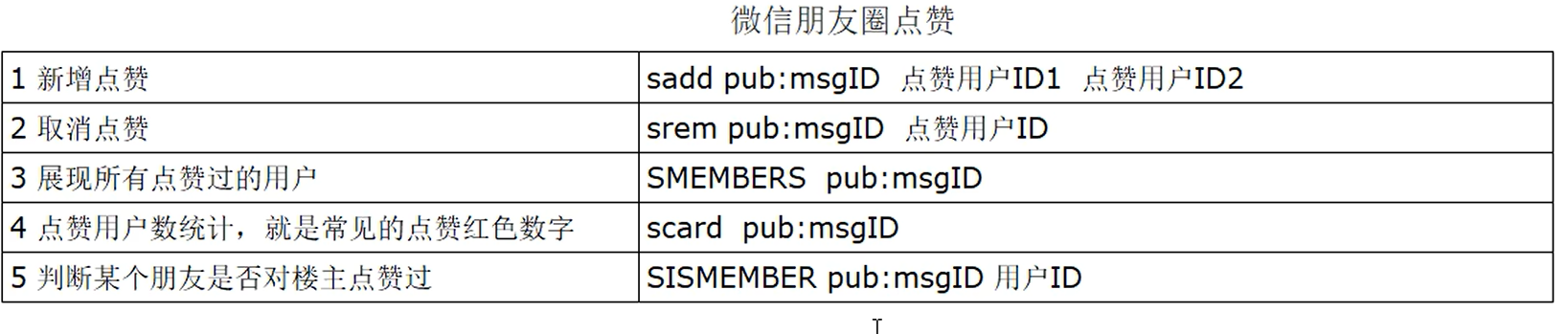
如微信朋友圈点赞
Zset(sorted set)
排序结果集
会自动根据score进行升序排序
- 添加,遍历value,带分数的遍历

- ZREVRANGE
反转set的某个范围内的排序

- ZREANGEBYSCORE
按照分数进行排序

- zrem key 某score下对应的value值
作用是删除元素
-
ZINCREBY key increment member
增加某个元素的分数
-
ZCOUNT key min max
获得指定范围内的元素个数
- ZMPOP

- zrank\zrevrank

应用场景
根据商品销售对商品进行排序显示
Redis位图(bitmap)
由0和1 状态表现的二进制位的bit 数组
需求

是什么?

用String类型作为底层数据结构实现的一种统计二值状态的数据类型,位图的本质是数组,它是基于String数据类型的按位的操作,该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们称之为一个索引)
BItmap支持的最大位数是2^32位,它可以极大的节约内存存储空间,使用512M内存就可以存储多达42.9亿的字节信息
能干嘛?
主要用于状态的统计Y\N
常用命令
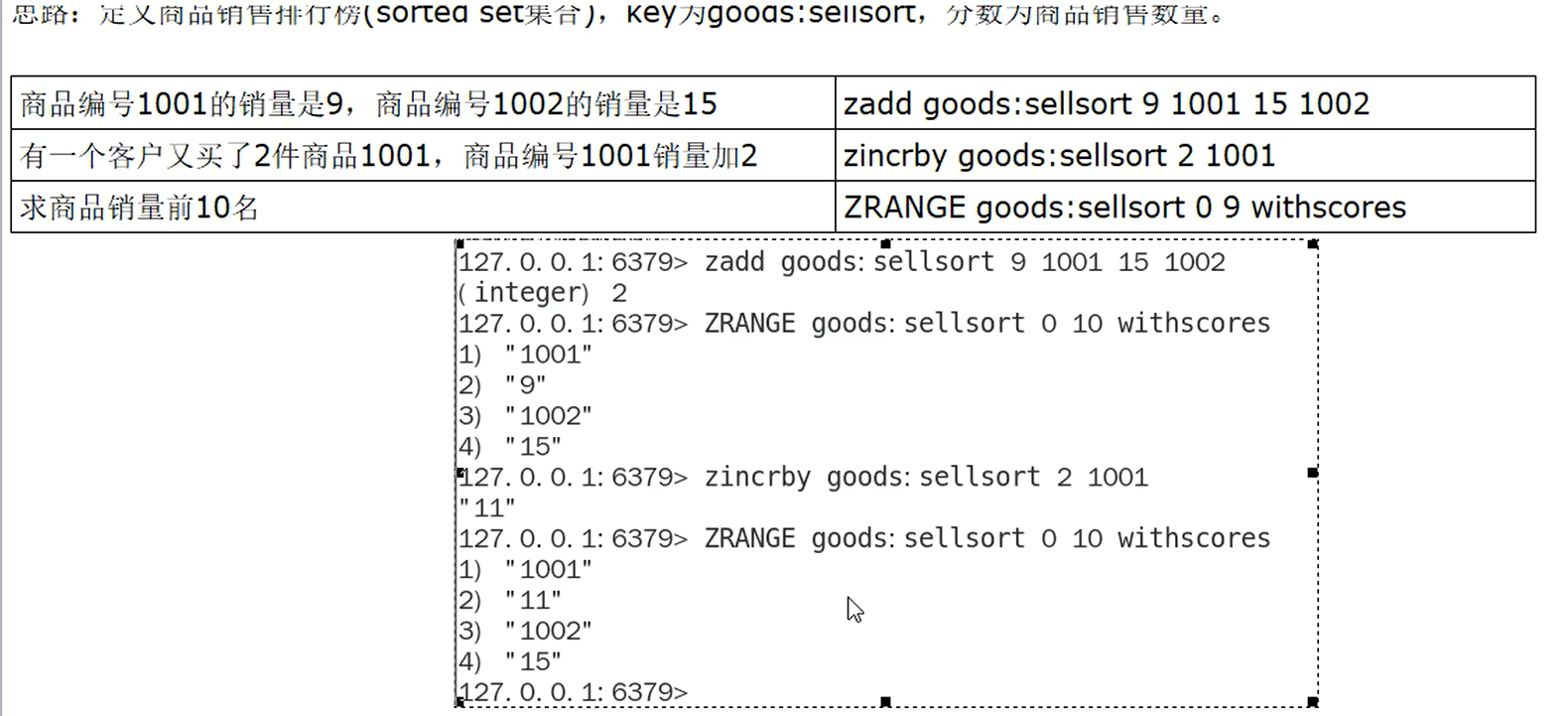
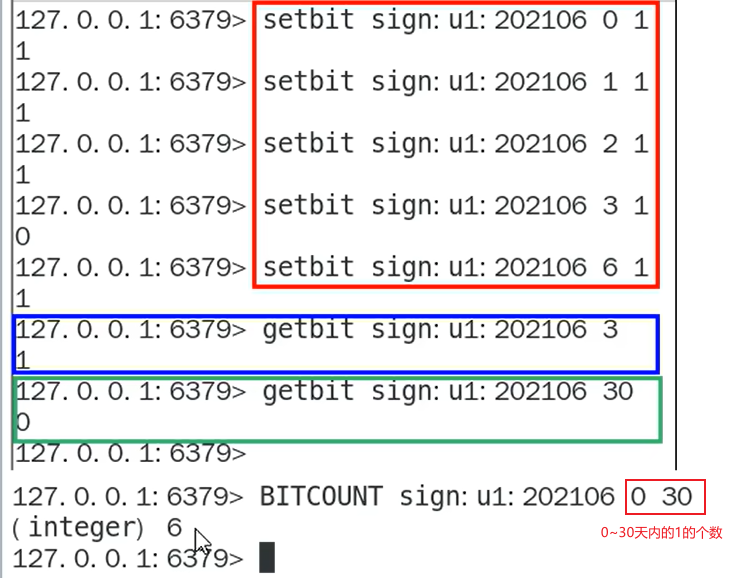
- SETBIT
- GETBIT

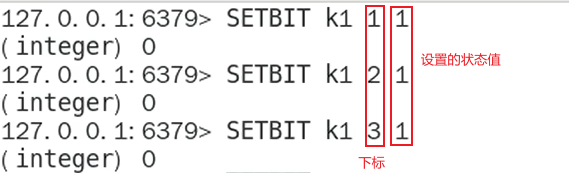
- STRLEN
计算占据了多少个字节,一个字节=八个比特位
如果超过八位,自己按照八位一组一byte再扩容
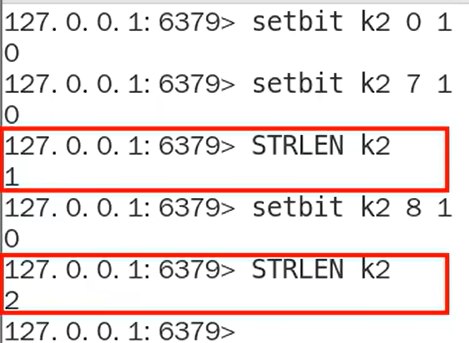
- bitcount
某个键里面的1有多少个
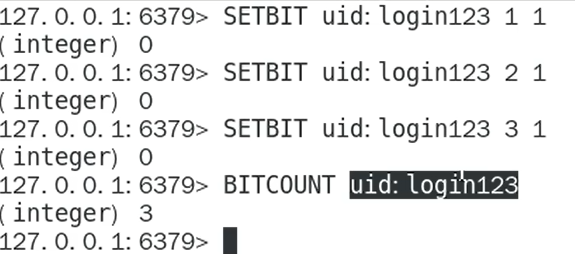
还可以指定范围进行1的个数的查询
- bitop
对不同的二进制存储数据进行位运算(AND,OR,NOT,XOR)

Redis基数统计(HyperLogLog)
需求
UV:unique viisitor独立访客,一般理解为客户端IP

是什么?
去重复功能的基数估计算法

基数统计:
用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
基本命令

Redis地理空间(GEO)
应用场景
主要应用于高并发访问的附近某个范围内的事物的查询

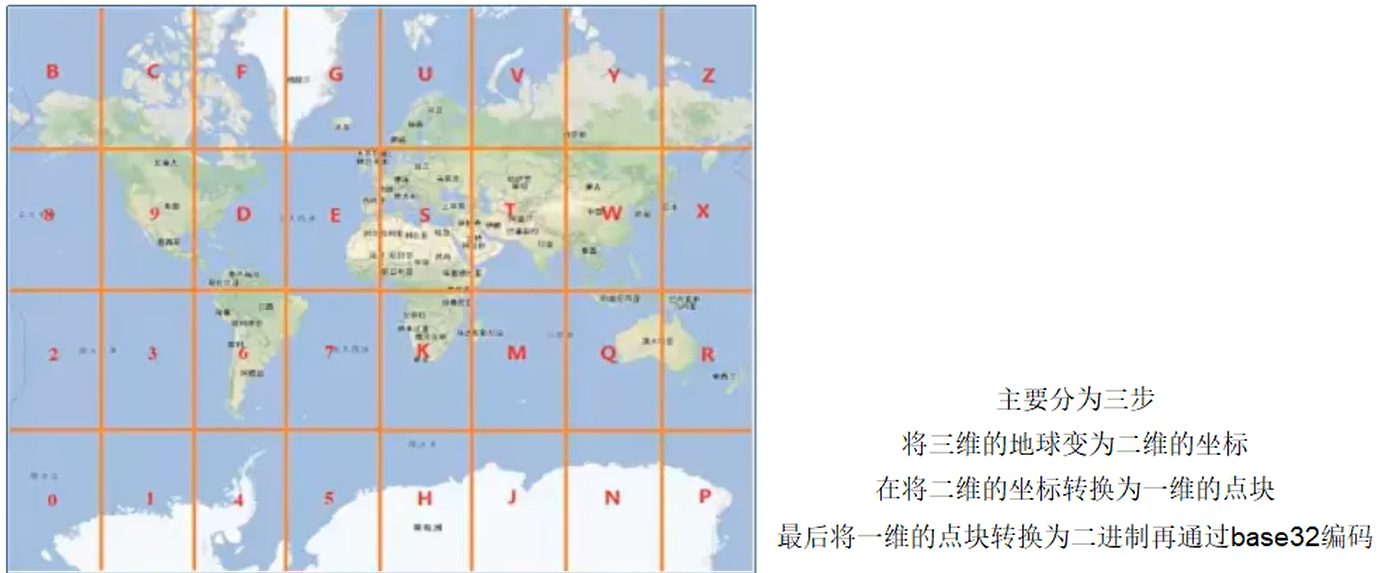
原理
核心思想就是将球体转换为平面,区块转换为一点
命令
-
GEOADD

-
ZRANGE

- GEOPOS

- Geohash
用于获取一个或多个位置的geohash值

- GEODIST
用于计算两个地理位置坐标的距离

- GEORADIUS
用于查找某个范围内的元素

- GEORADIUSbymember
可以输入元素名而不是经纬度进行查找

Redis流(Stream)
redis-stream就是redis版本的MQ消息中间件
redis消息队列的两种方案
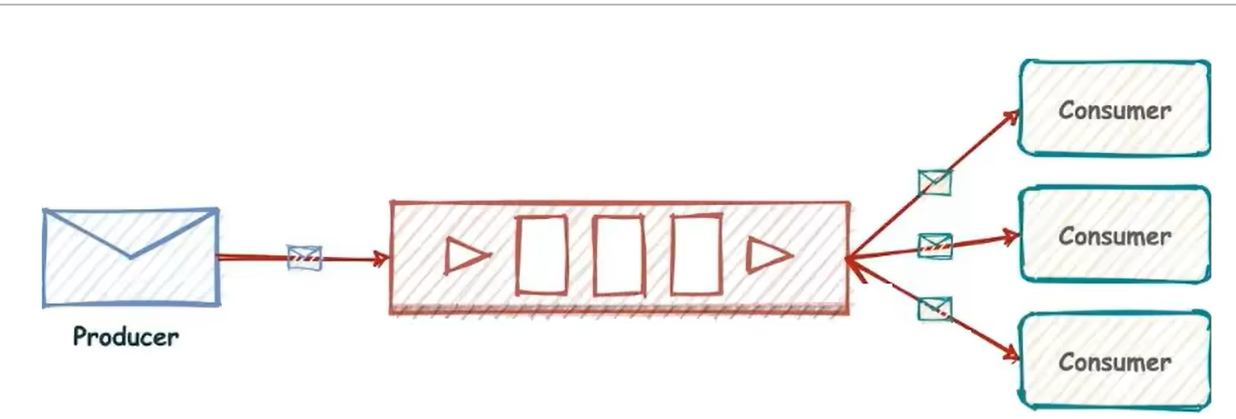
- list实现消息队列,点对点的方式

- pub\sub 一对多的方式
缺点
发布订阅(pub\sub)有个缺点就是无法持久化,如果出现网络断开,Redis宕机,消息就会被丢弃,而且没有Ack机制来保证数据的可靠性,假设一个消费者都没有,那消息就可以直接被丢弃
能干嘛?
实现消息队列,它支持消息的持久化,支持自动生成全局唯一的ID、支持ack确认消息的模式,支持消费组模式等,让消息队列更加稳定和可靠
底层结构和原理


指令
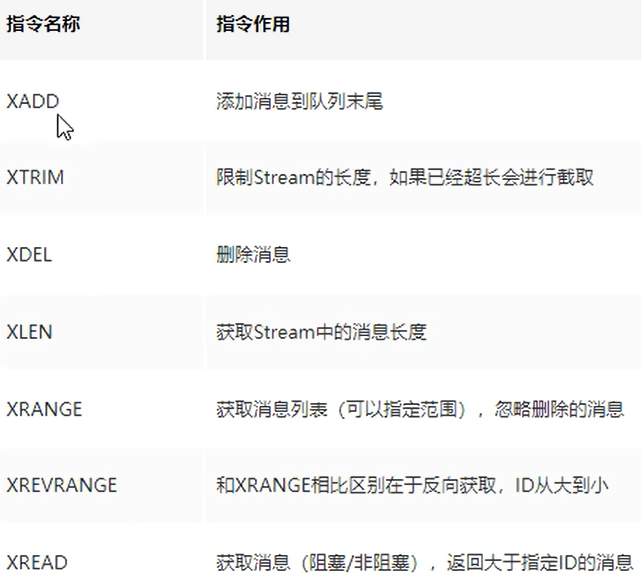
队列相关指令
对应命令示例
- 添加数据
*: 表示自动生成ID,id为毫秒级时间戳-对应时间戳下的顺序

- 遍历查看数据

- 反向遍历输出XREVRANGE
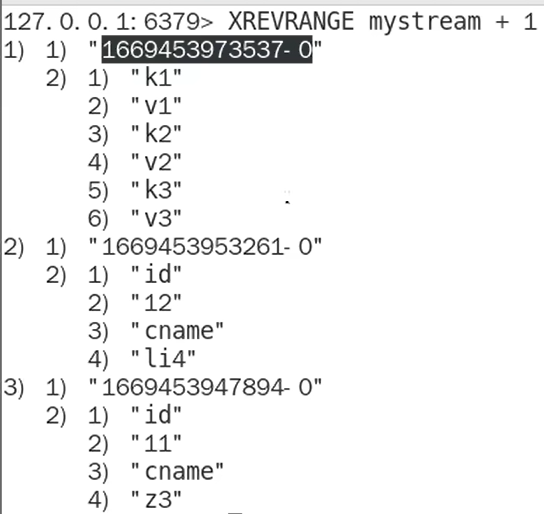
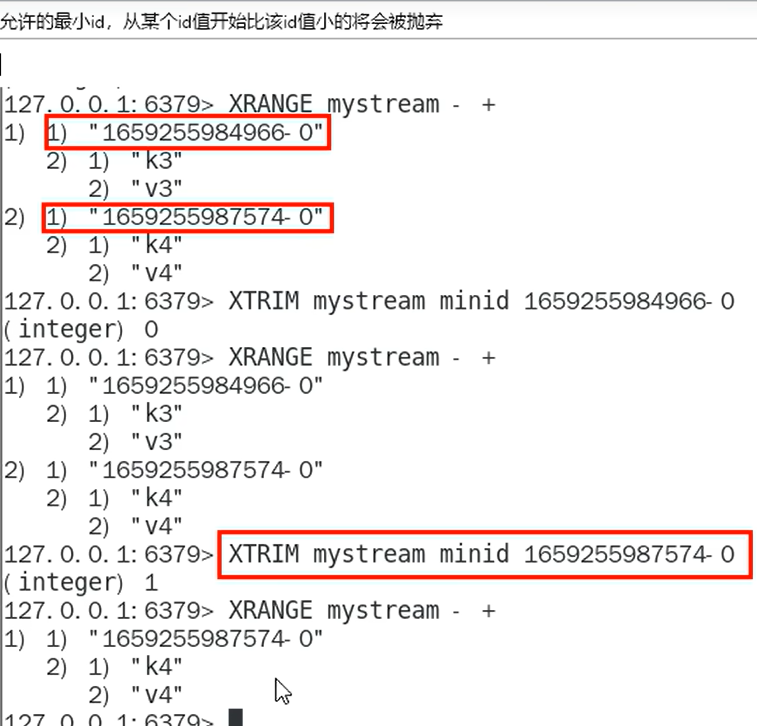
- 截取数据XTRIM ( minid,允许的最小id,maxlen,允许的最大的id)比minlen小的id数据将被删除,maxlen获得时间戳较大的几个
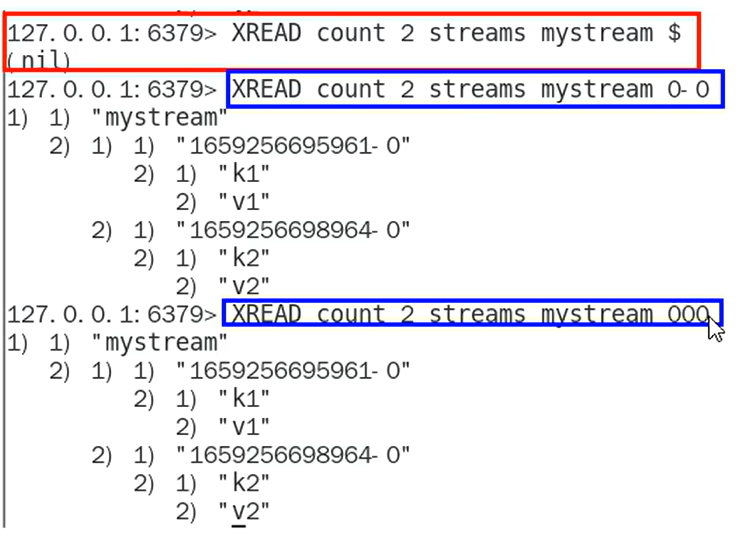
- XREAD
非阻塞

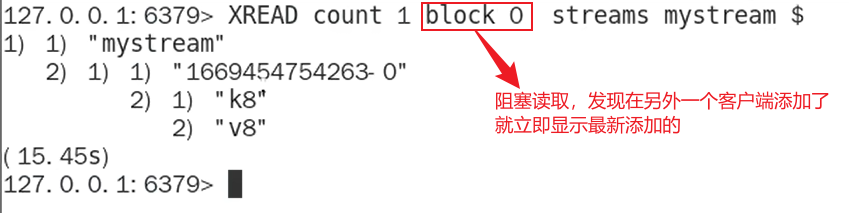
阻塞
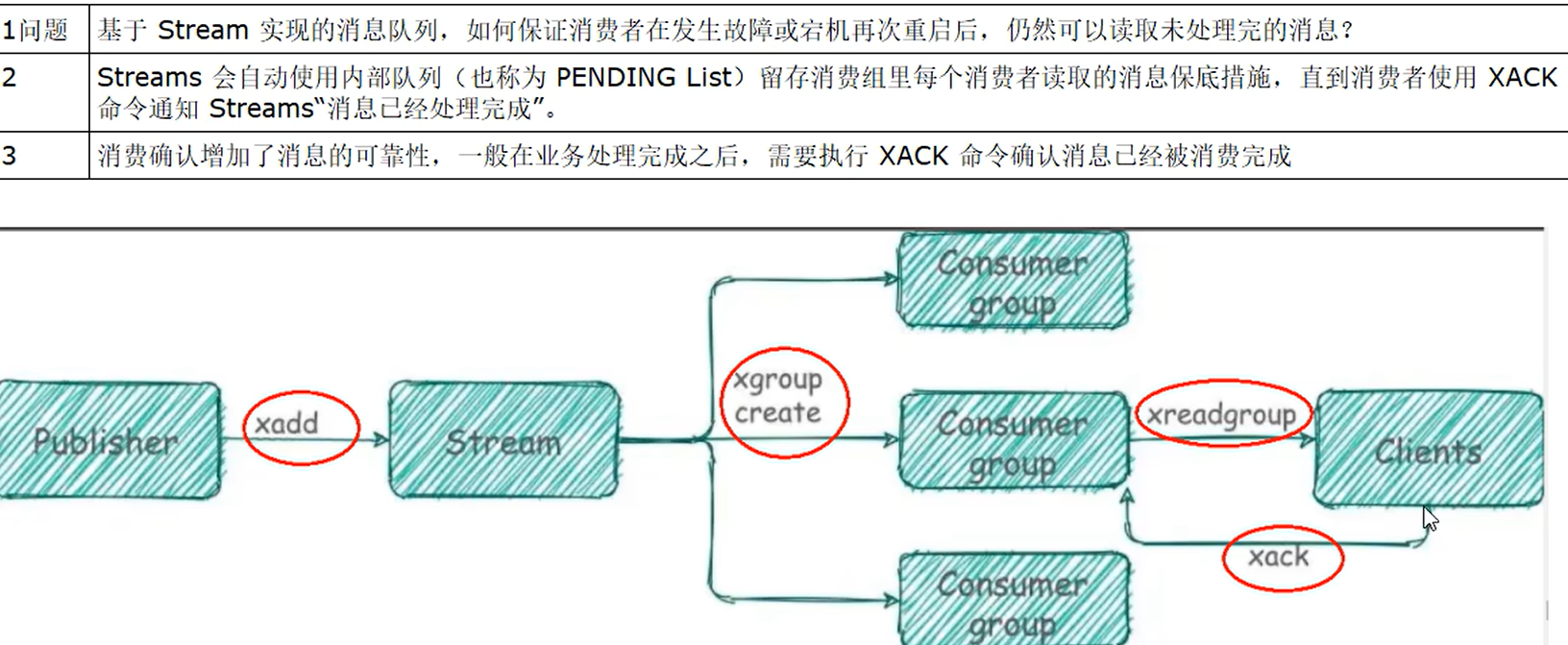
消费组

- 创建消费者组

$表示从Stream尾部开始消费
0表示Stream头部开始消费
创建消费者组的时候必须指定ID,ID为0 表示从头开始消费,为$表示只消费新的消息,队尾新来
- 消费者读取消息队列里面的数据XREADGROUP
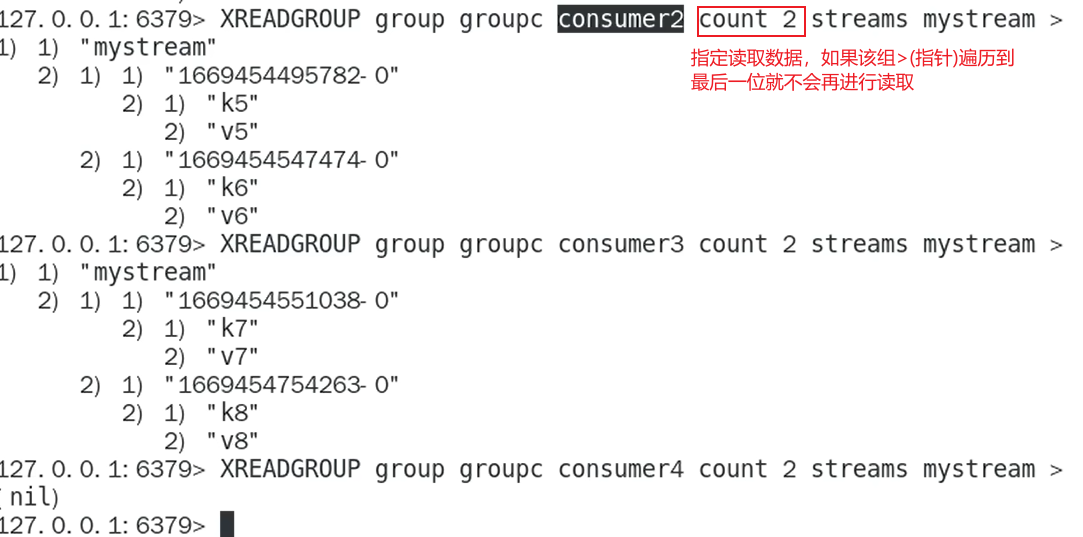
特殊符号

重点问题
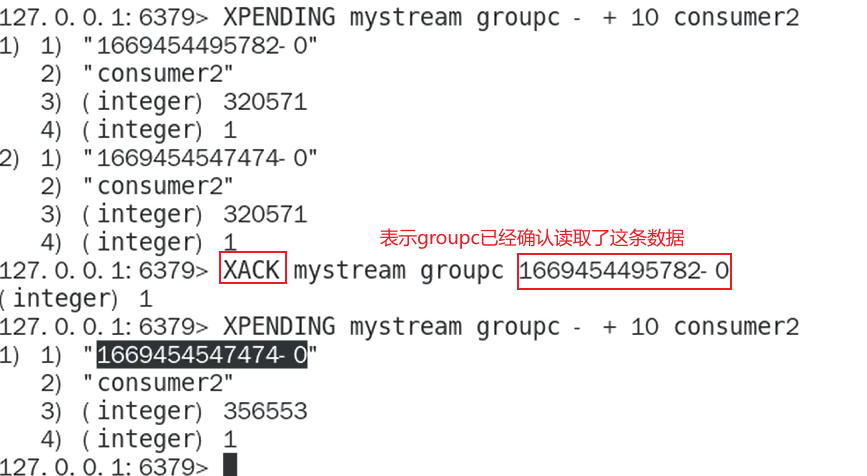
- XPENDING
查询每个消费组内所有消费者(已读取,但尚为确认)的消息

查看某个消费者具体读取了那些数据

- XACK
Redis位域(bitfield)(了解即可)
p27
Redis持久化
通过RDB和AOF两种方式将内存中的数据写进磁盘中从而达到持久化
默认使用的RDB,如果需要使用AOF则需要在配置文件中手动开启
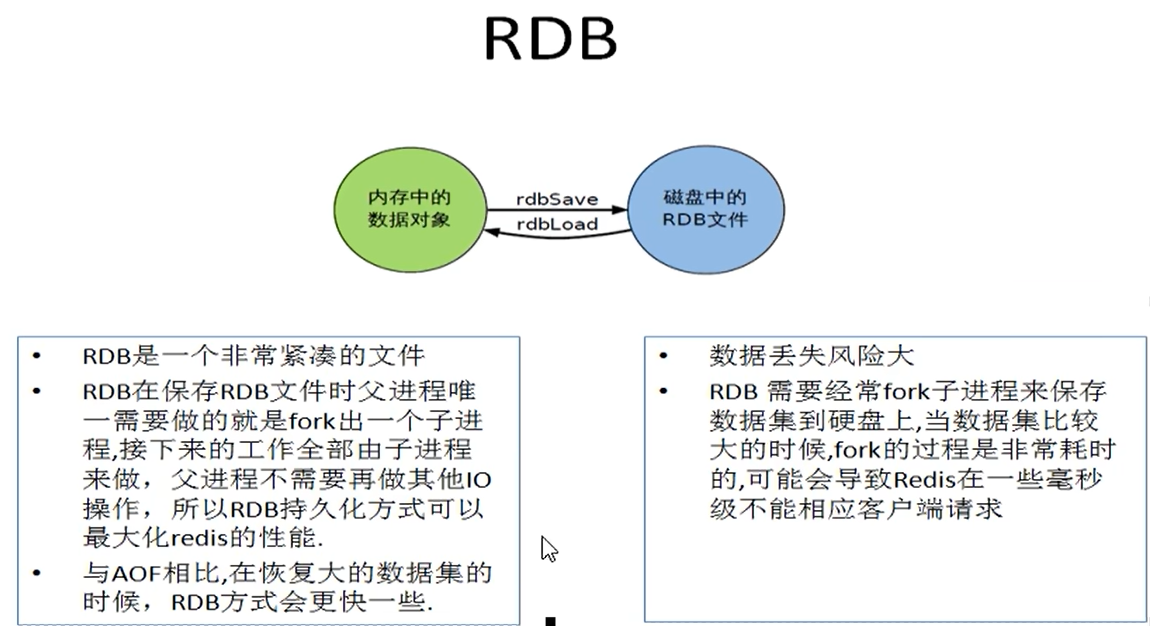
RDB
RDB持久性以指定的时间间隔执行数据集的时间点快照
快照文件称为RDB文件(dump.rdb),其中RDB就是Redis DataBase的缩写
能干嘛?
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot内存快照,它恢复时再将硬盘快照文件直接读回到内存里
RDB保存到磁盘中的文件就叫dump.rdb
快照记录时间间隔和频率
- redis7以前
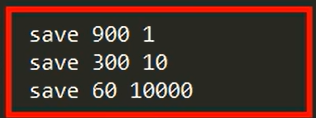
save 900 1 表示在900秒内如果存在一个key的变化将从新写入快照文件
- redis7

操作步骤
config get 需要查看的配置( 也可以配合set进行设置相关属性)
自动触发
既要设定的时间间隔又要满足修改的key的数量才能生成快照文件

执行flushall/flushdb命令与也会产生dump.rdb文件,但里面是空的,无意义
物理恢复,一定要服务和备份分机隔离
手动触发
Save和 BGSAVE命令
线上禁止使用Save

仅使用BGSAVE

Redis会使用bgsave对当前内存中的所有数据做快照,这个操作是子进程在后台完成的,这就允许主进程同时可以修改数据
- LASTSAVE
这个命令可以获取最后一次成功执行快照的时间
优缺点和数据丢失案例
优点

优点总结
- 适合大规模的数据恢复
- 按照业务定时备份
- 对数据完整性和一致性要求不高
- RDB文件在内存的加载速度要比AOF快得多
缺点
-
在一定时间间隔内做一次备份,所以如果redis意外down掉的话,就会丢失从当前至最近一次快照期间的数据,快照之间的数据会丢失
-
内存数据的全量同步,如果数据量太大会导致I/O严重影响服务器性能
-
RDB依赖于主进程的fork,在更大的数据集中,这可能会导致服务请求的瞬间延迟,fork的时候内存中的数据被克隆一份,大致2倍的膨胀性
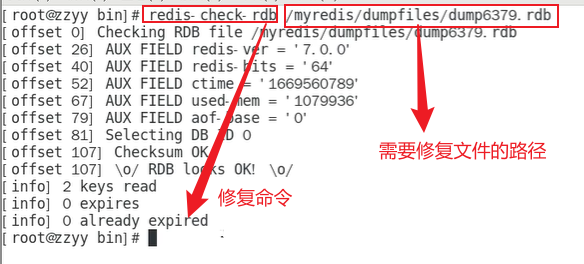
RDB修复命令简介
-
cd /usr/local/bin 切换目录
-
redis修复命令
RDB触发小结和快照禁用

如何禁用快照?
- 使用命令
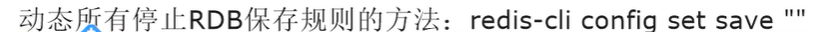
2.修改配置文件禁用快照
在配置文件中写入save “ ”

RDB总结
AOF(Append Only File)
是什么?

Aof保存的是appendonly.aof文件
AOF持久化工作流程
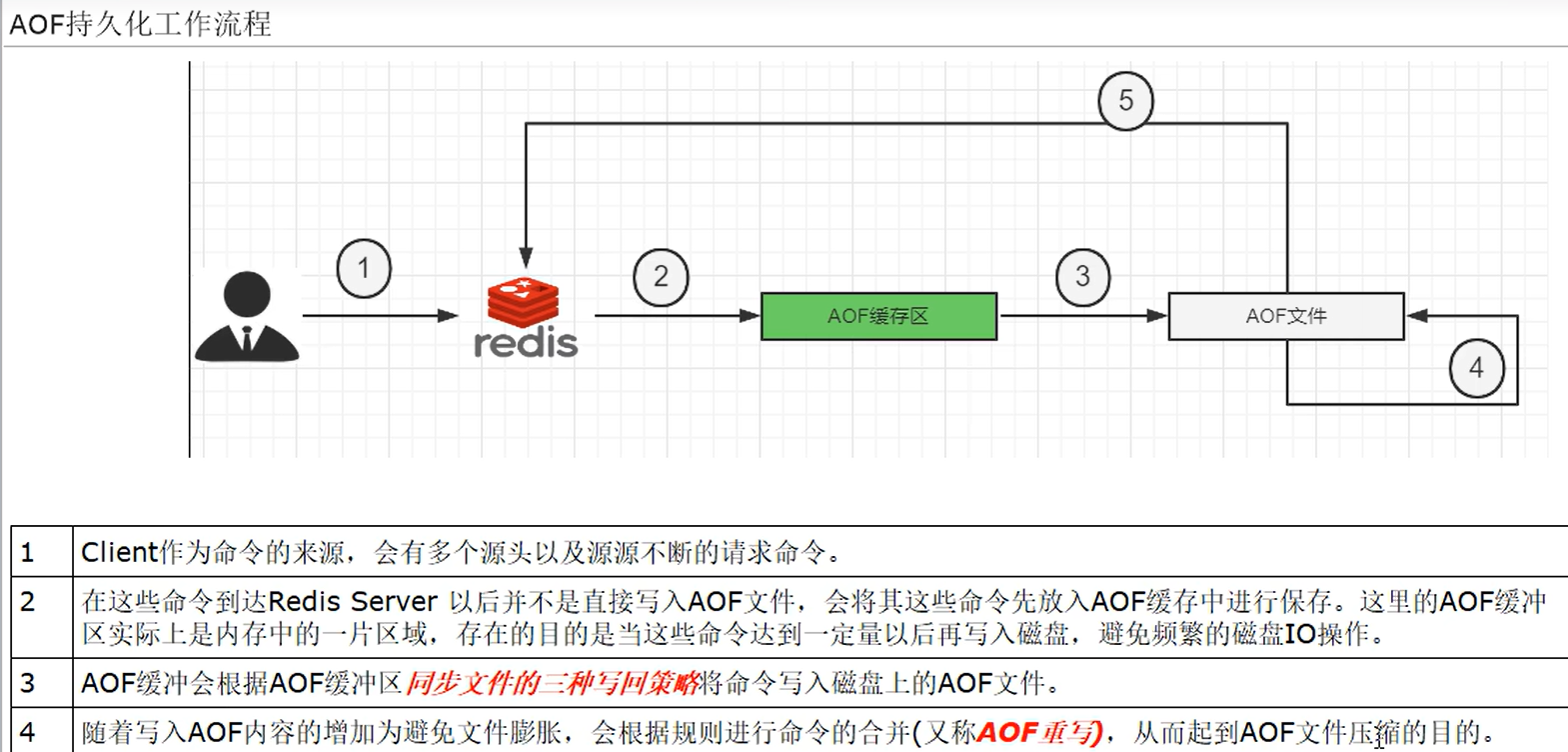
三种写回策略
默认的写回策略是Everysec

AOF的使用


默认写回策略设置

MP-AOF实现
将原来redis-6的单个AOF文件拆分为多个AOF文件



配置项总结
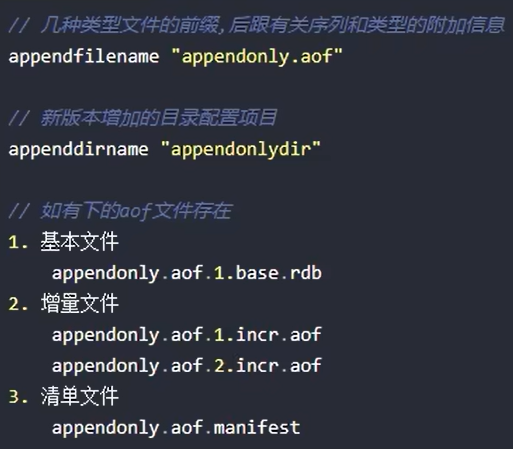
正常恢复情况
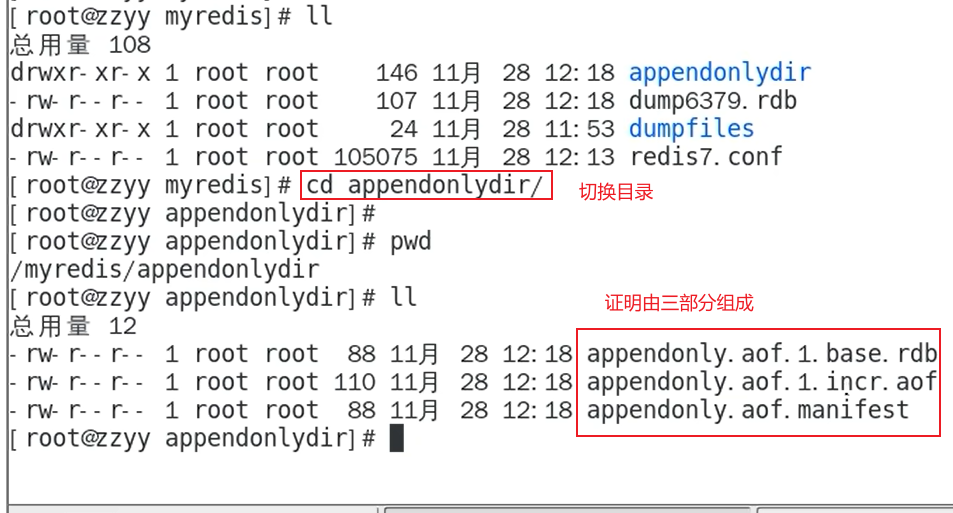

异常修复命令
命令后接.incr.aof文件 进行修复

优缺点
- 优点
更好的保护数据不丢失,性能高,可做紧急恢复
- 缺点

相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb
aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
AOF重写机制
是什么?

默认配置
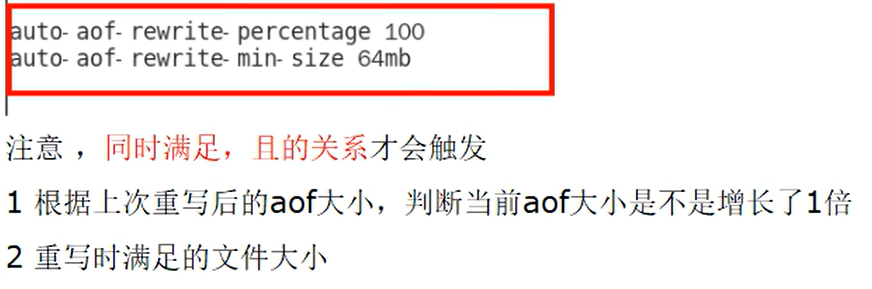
客户端向服务端发送bgrewriteaof命令手动触发
举例

结论

配置文件总结
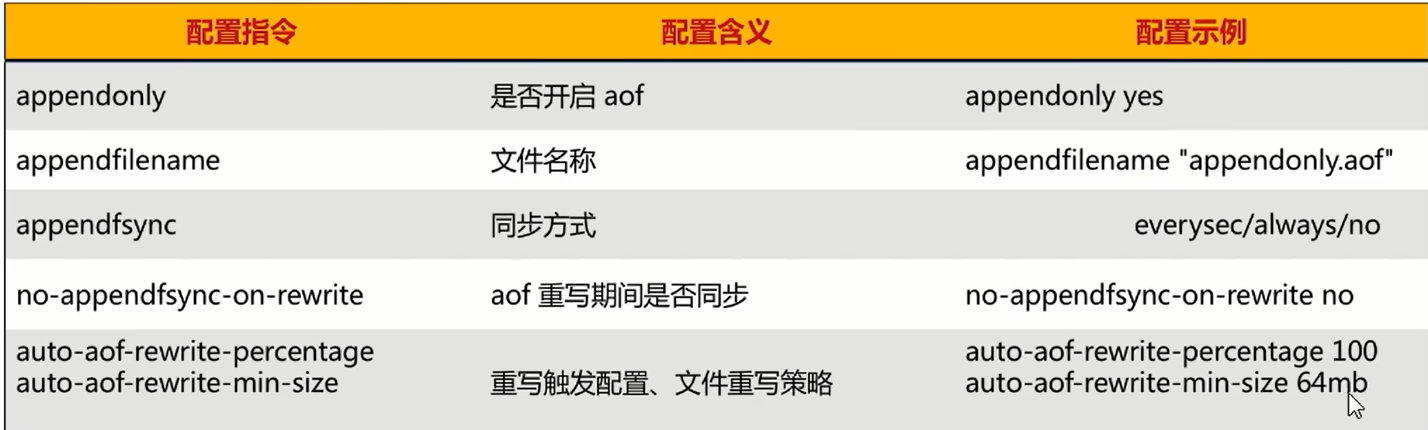
RDB-AOF混合持久化使用
rdb和aof能够共存,在同时开启rdb和aof持久化时,重启时只会加载aof文件,不会加载rdb文件
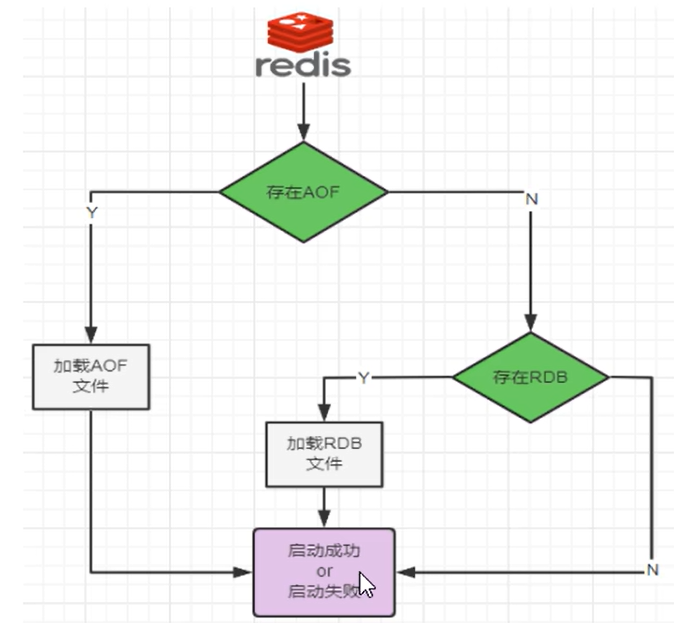
推荐使用RDB和AOF混合使用,既能快速加载又能避免丢失过多的数据

纯缓存模式
同时关闭RDB+AOF,redis只做缓存功能,不做备份功能
相关操作

事务
是什么?

能干嘛?
一个队列中,一次性,顺序性,排他性的执行一系列命令
Redis事务与数据库事务的对比

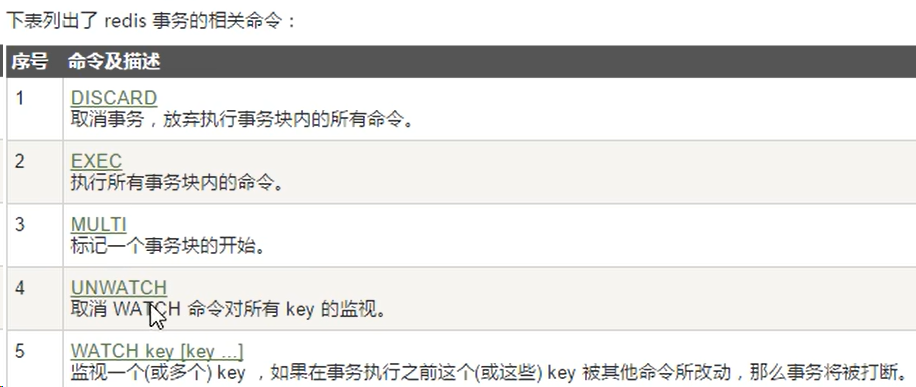
相关操作
Redis事务命令
正常执行

事务放弃
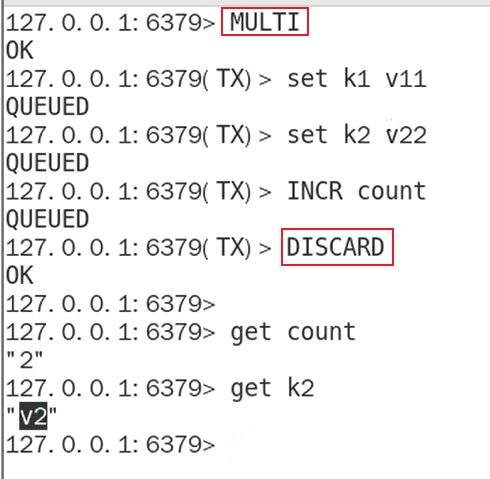
全体连坐
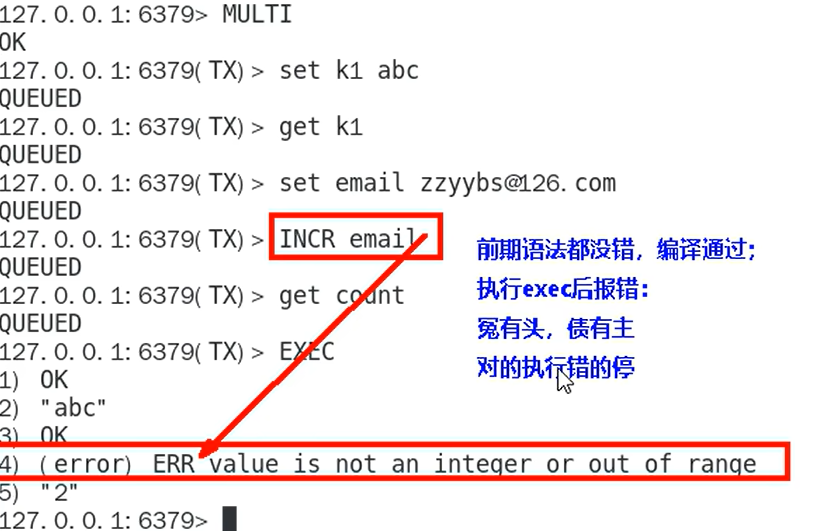
在执行前出现错误命令,事务中的所有命令都不会执行

怨头债主
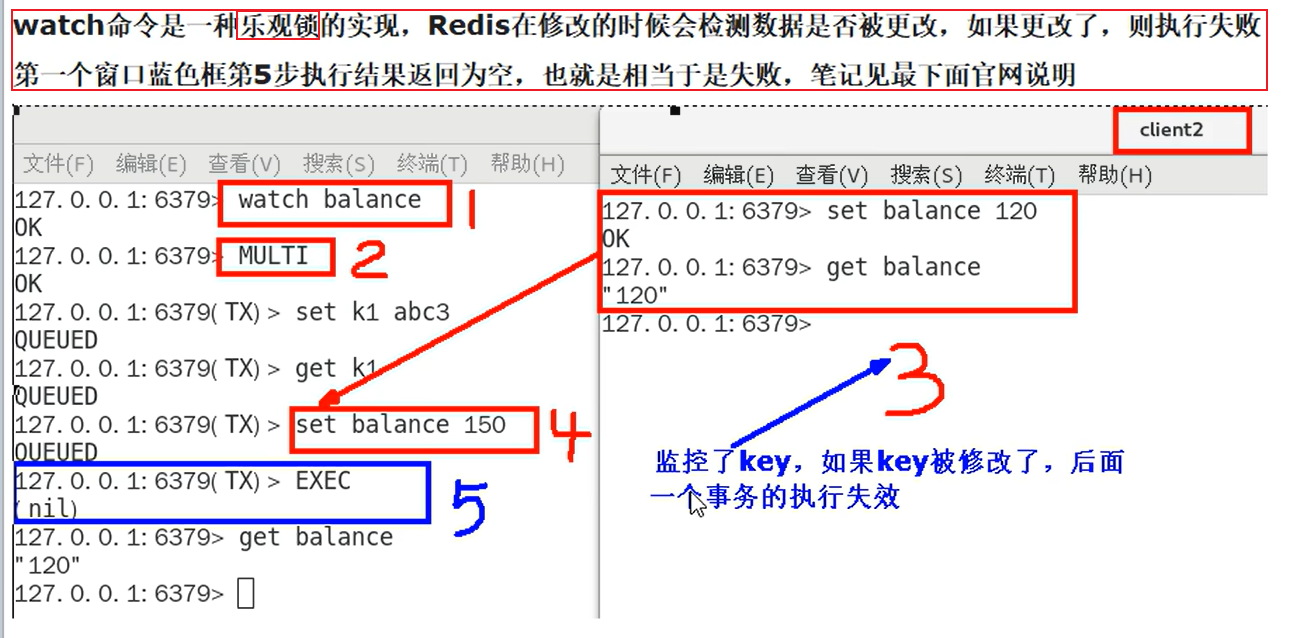
watch监控
如果被监控的key在执行EXEC命令之前被修改,整个事务将被废除
unwatch
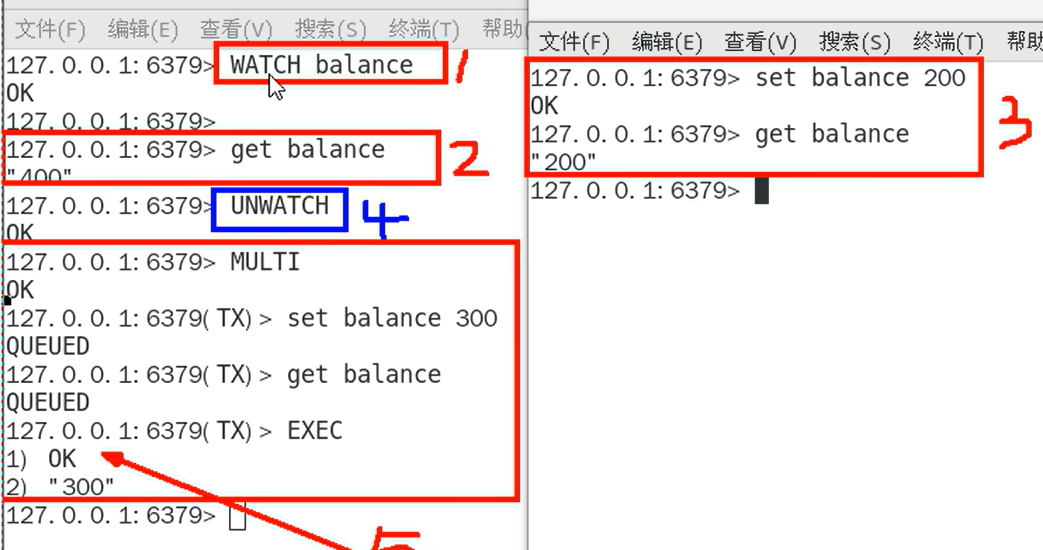
注意

流程总结

Redis pipelining(管道)
为什么需要使用管道技术?


是什么?
Pipeline是为了解决RTT往返时,仅仅是将命令打包一次性发送,对整个Redis的执行不造成其他影响
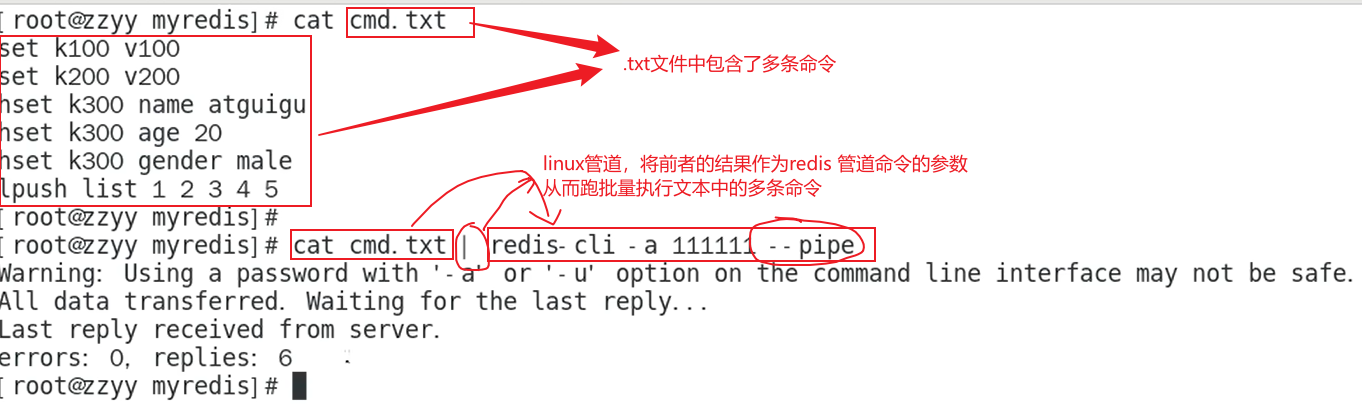
redis 管道技术解决问题的思路


实操案例
总结
Pipeline与原生批量命令对比

与事务的对比

注意事项

Redis Pub/Sub(发布订阅 )
了解即可
Redis主从复制(replica)
是什么?

能干嘛?
- 读写分离
- 容灾备份
- 数据备份
- 水平扩容支撑高并发
怎么玩
- 配从库不配主库
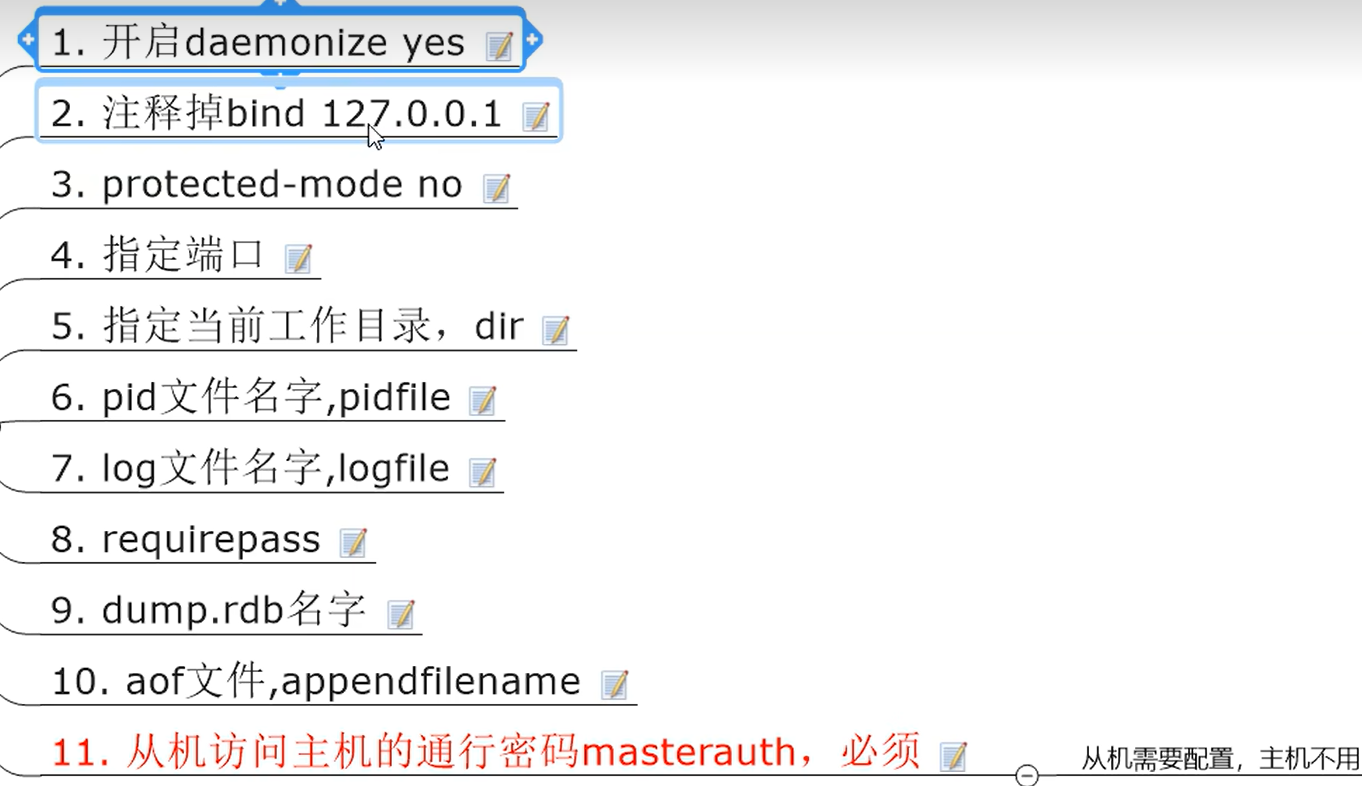
- 权限细节

基本操作命令
- info replication
可以查看复制节点的主从关系和配置信息
-
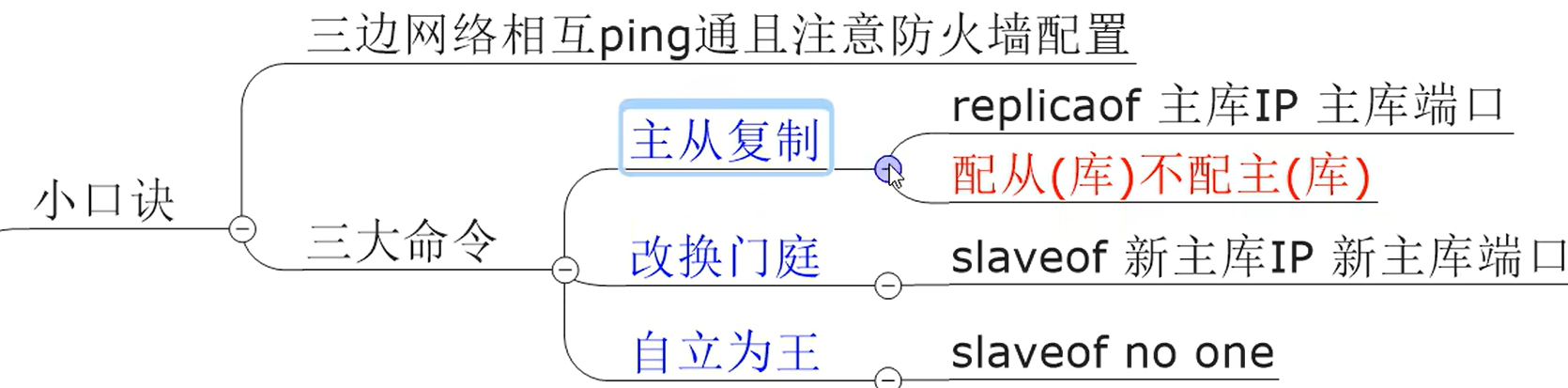
replicaof 主库IP 主库端口
配置当前主机成为那台主机的从机
一般写入redis.conf 配置文件
- slave 主库IP 主库端口
修改自己的主机

- slaveof no none
使当前数据库停止与其他数据库的同步,转成主数据库,自立为王
案例实操
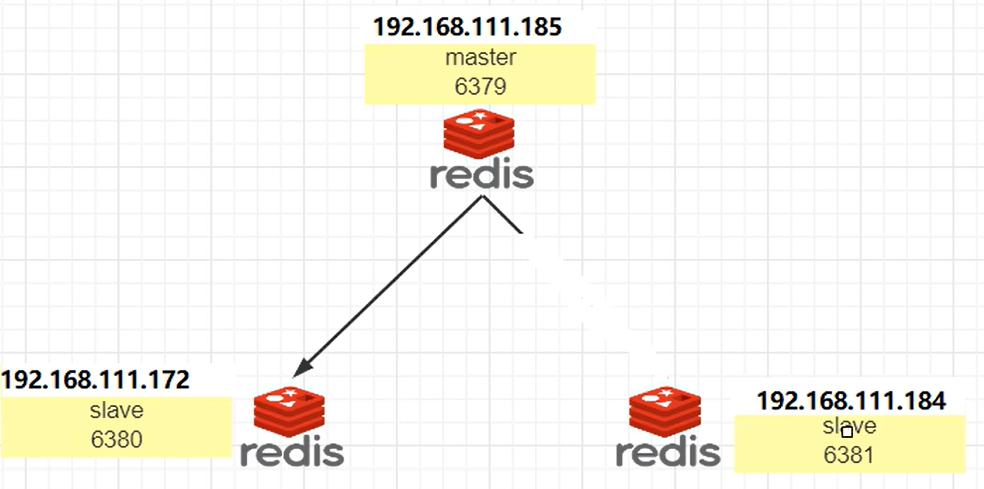
三边网络互通指的是其中的任意一台redis服务器能ping通另外两台redis服务器
配置文件修改
从机配置

相关问题
- 从机可以执行写命令吗?
从机只可以读取主机的写操作,不可以执行写操作
- 从机切入点问题
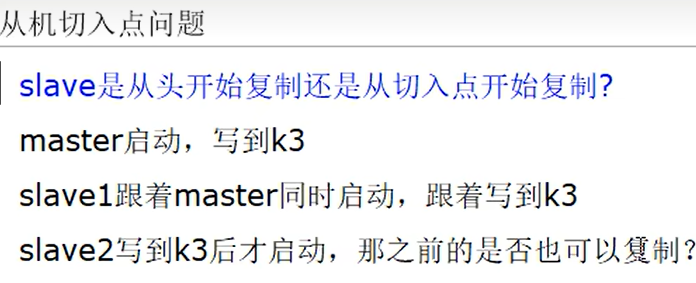
可以复制,首次跟随了主机,后续即使从机关闭了也会继续跟随,master写,slave跟
- 主机shutdown后,从机会不会上位
从机不动,原地待命,从机数据可以正常使用,等待主机重启动归来
- 主机shutdown后,重启后主从关系还在吗?,从机还能否顺利复制
关系还在,还能顺利复制
手动指定主从关系

用命令使用的话,2台从机重启后,关系还在吗?
不在,使用命令指定的主从关系是临时的,要想永久存在这种关系,需要在配置文件中添加
薪火相传

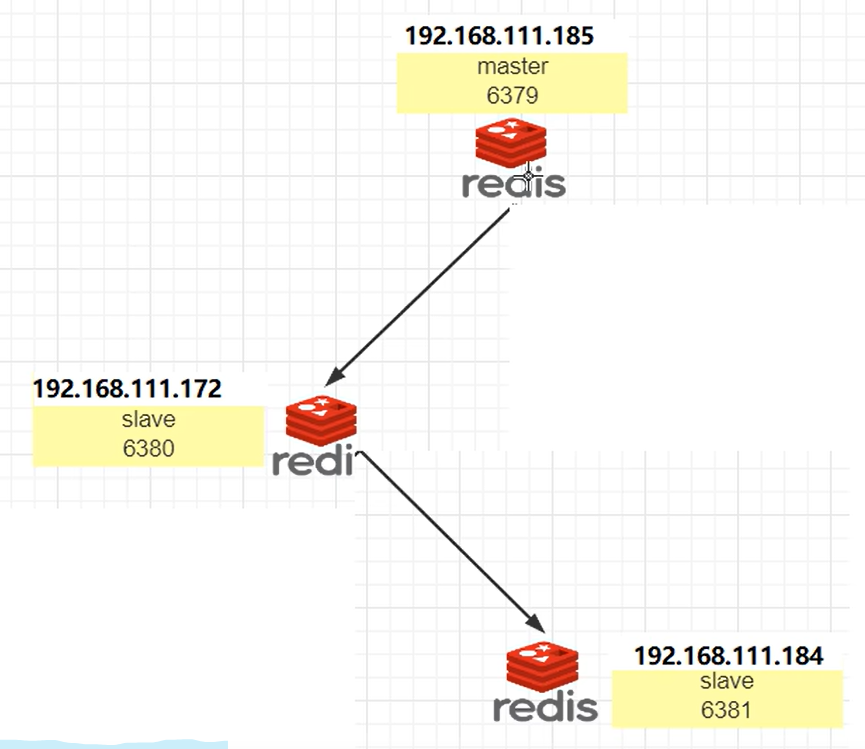
中间的6380 虽然是6381的主机,但是依然不能进行写操作
反客为主
SLAVEOF no one
使当前数据库变成主数据库
总结
sync同步





痛点和改进需求
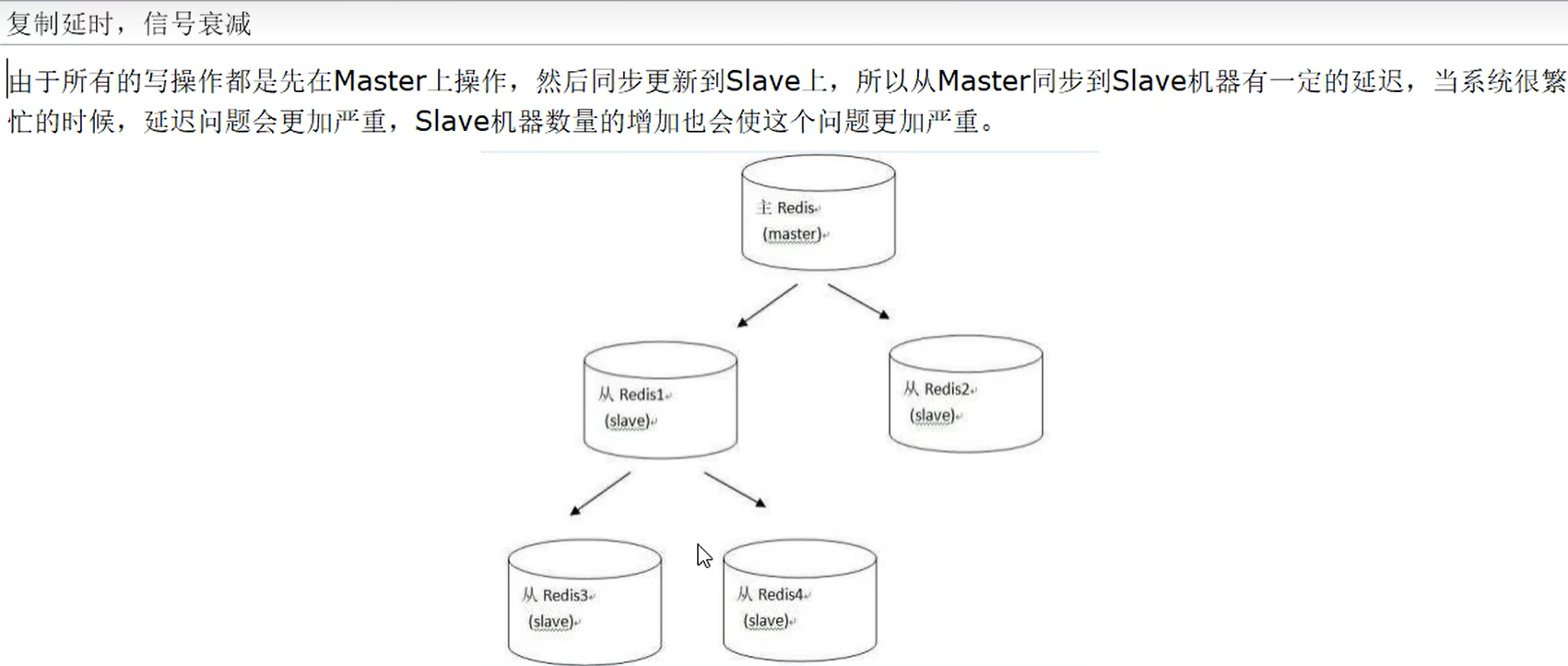
master主机挂了怎么办

Redis 哨兵
是什么?

作用

能干嘛?

哨兵自动监控和维护集群,不存在读写操作
操作
- 哨兵配置文件操作

- 设置要监控的master服务器

quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数


- 启动哨兵
redis-sentinel sentinel26379.conf --sentinel
没报错表示启动成功


- Broken Pipe错误
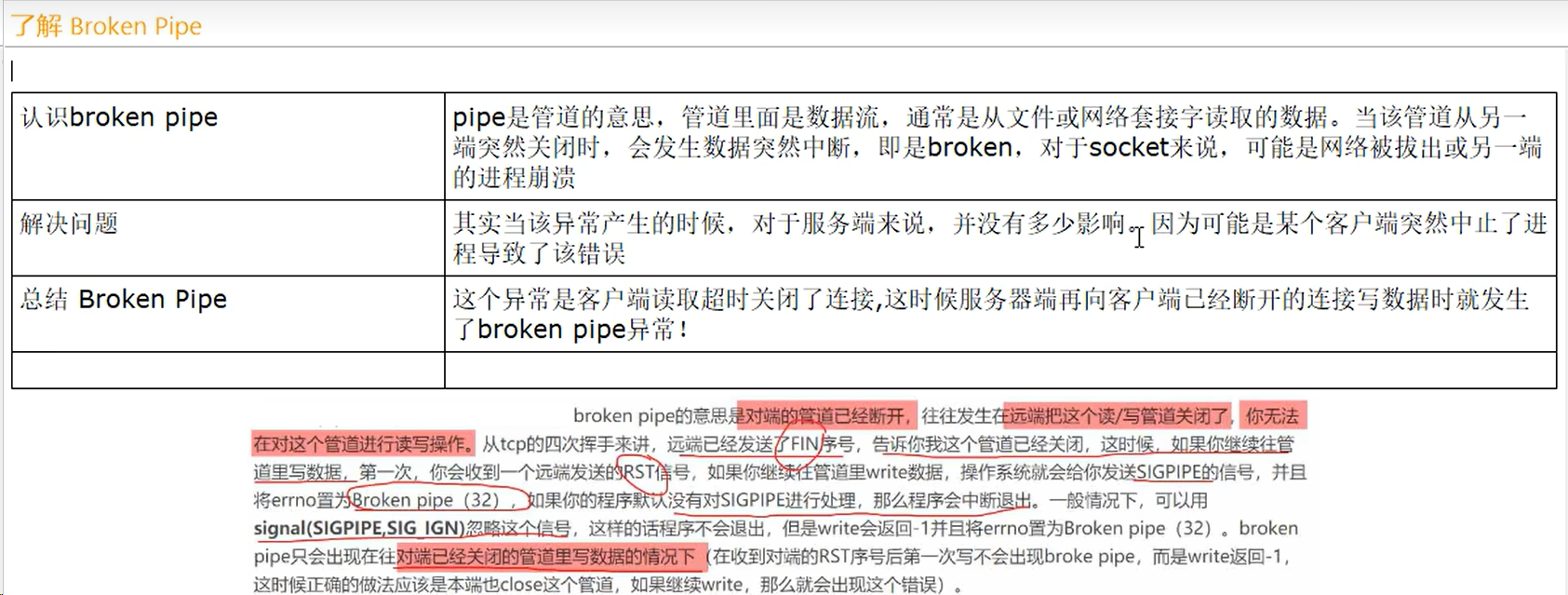
- 预先设定masterauth项的访问密码为111111

哨兵的运行流程和选举原理
- SDown主观下线(Subjectively Down)

- ODown客观下线(Objectively Down)


- Raft算法
选举领导者哨兵节点的算法

新master选举算法
- 选新的master

- 其他slave认可新master

sentinel自己能独自完成,无需人工干预
哨兵的使用建议

Redis集群(cluster)
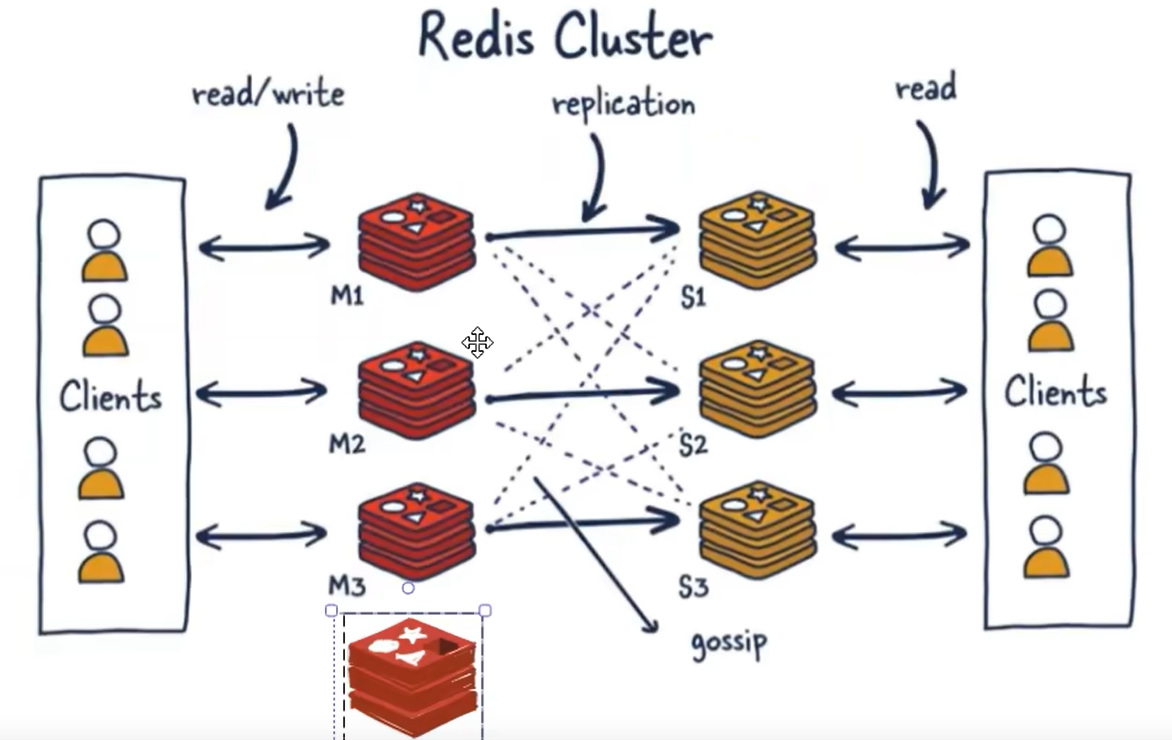
定义
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只复制存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集
能干嘛?

集群算法-分片-槽位slot



分片
定义
使用Redis’集群时我们会将存储的数据分散到多台redis机器上,这称为分片,简言之,集群中的每个Redis实例都被认为是整个数据的一个分片
如何找到给定key的分片

槽位和分片的优点
方便扩容缩容和数据分派查找

slot槽位映射算法
哈希取余算法

缺点
redis机器数量变化,会导致数据的位置发生变化(可能不在原来的redis机器上),会造成数据混乱
一致性哈希算法
分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了
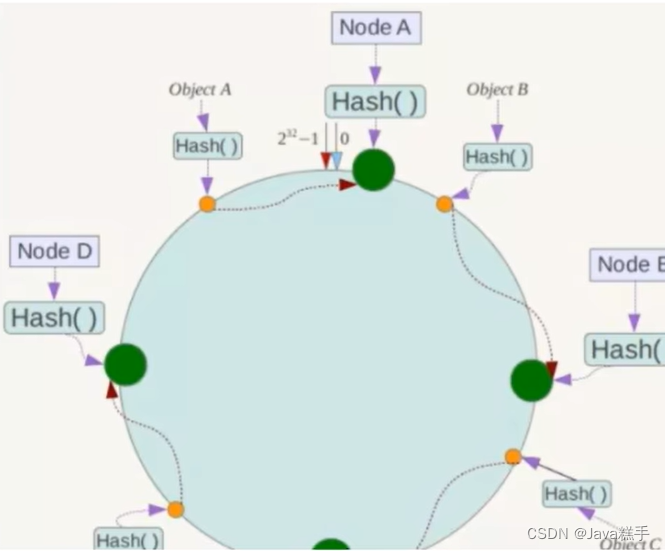
- 一致性哈希环

- 节点映射

- key落到服务器的落键规则

优点
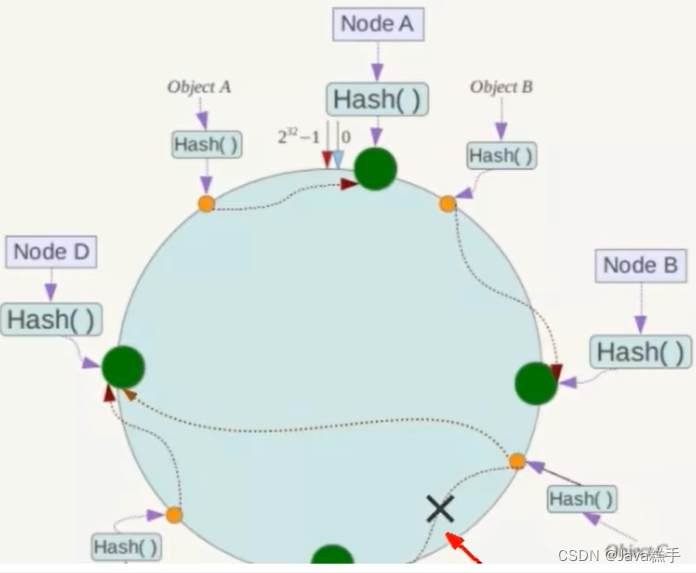
容错性

扩展性
缺点
哈希槽算法
为什么会出现?
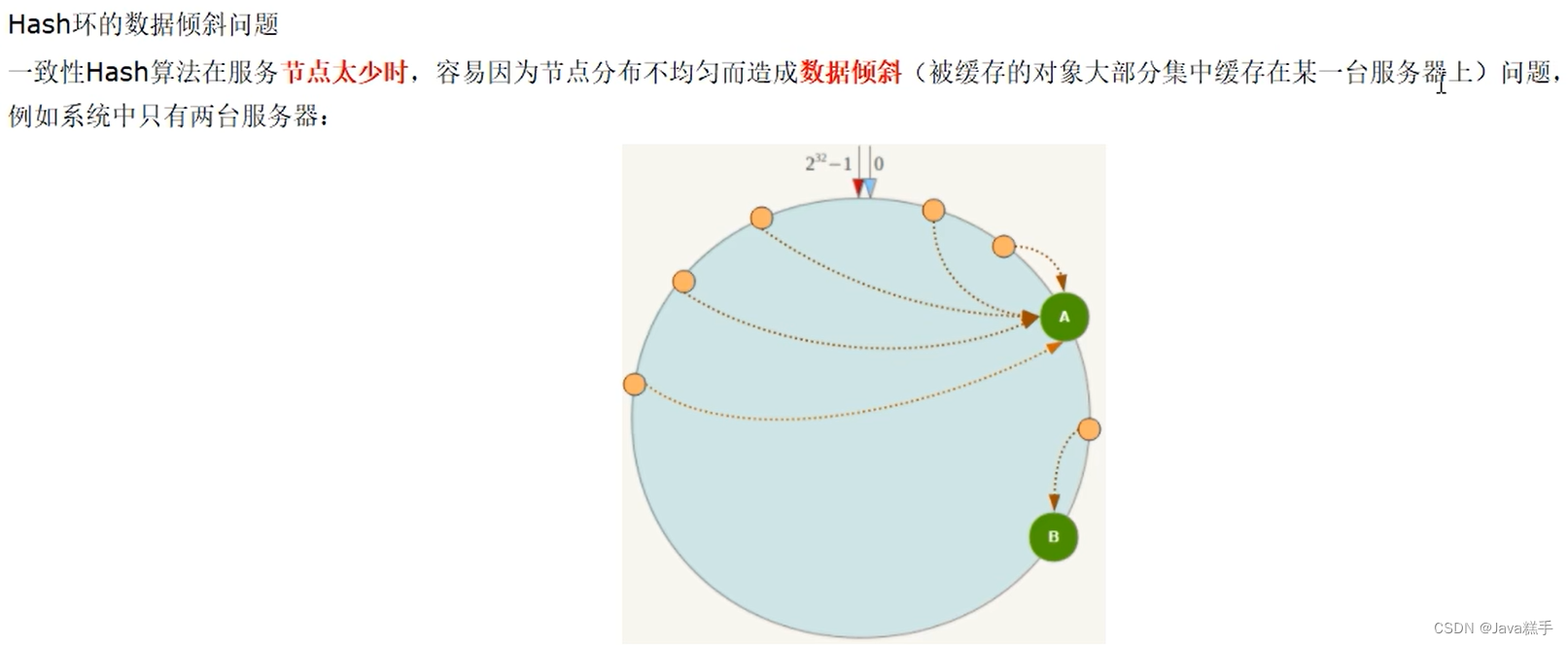
一致性哈希算法的数据倾斜问题
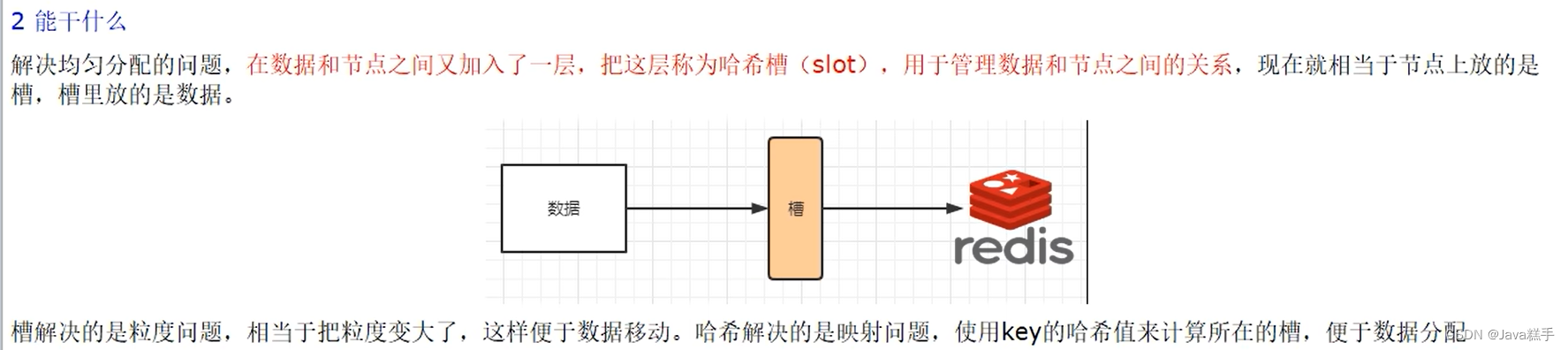
哈希槽实质就是一个数组,数组[0,2^14-1]形成hash slot空间
2^14=16384
能干什么?


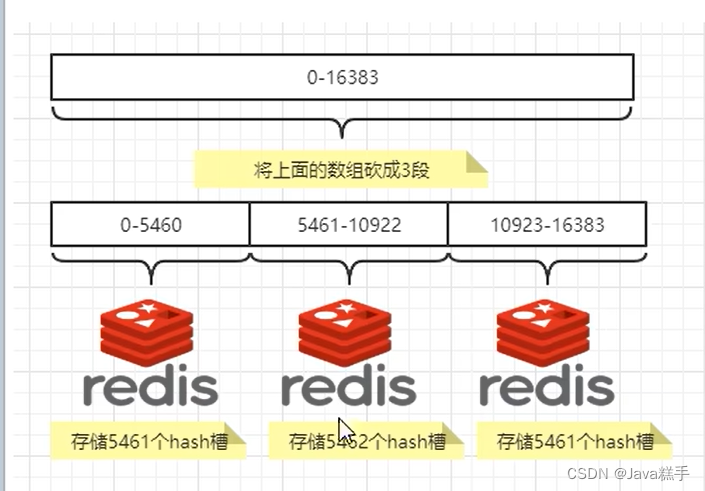
为什么redis集群的最大槽数是16384个



另外一个问题

命令
info replication
当前redis机器的主从关系
cluster nodes
集群节点关系
-c通过路由将redis集群中的redis机器连接起来,防止键值没有落到本机器的数据不能正确写入

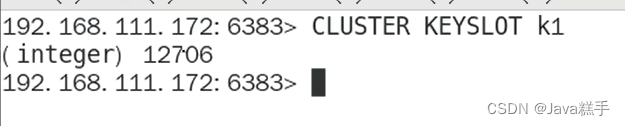
查看键的槽位号
cluster keyslot k1
CLUSTER FAILOVER
用于切换主从机之间的身份
通识占位符{}

cluster-require-full-coverage yes/no

SpringBoot 整合Redis
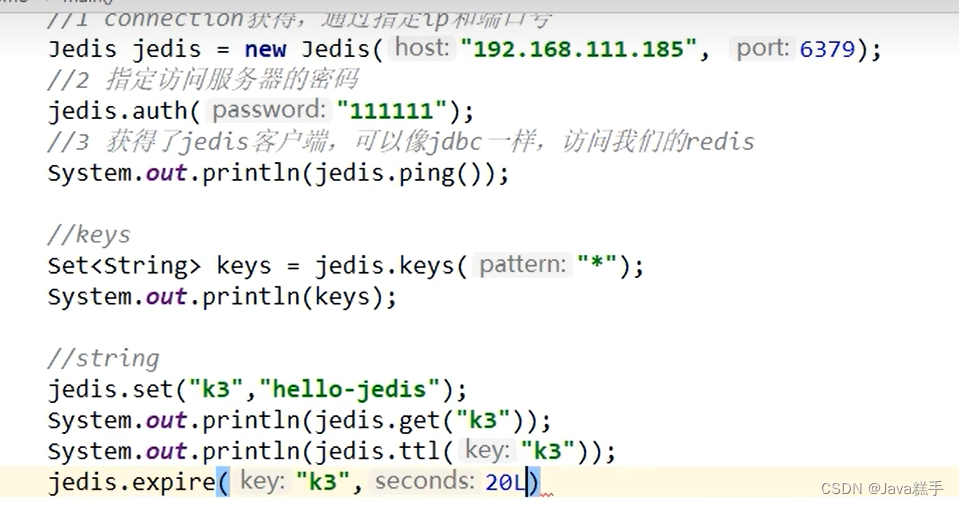
Jedis
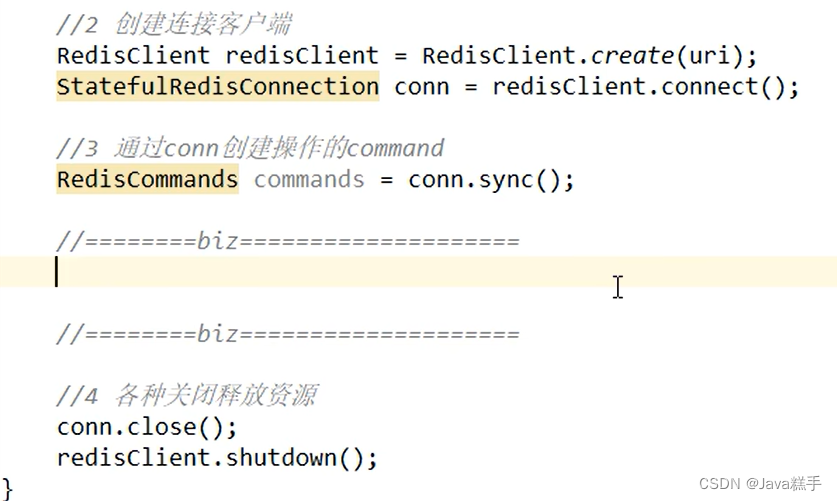
集成lettuce


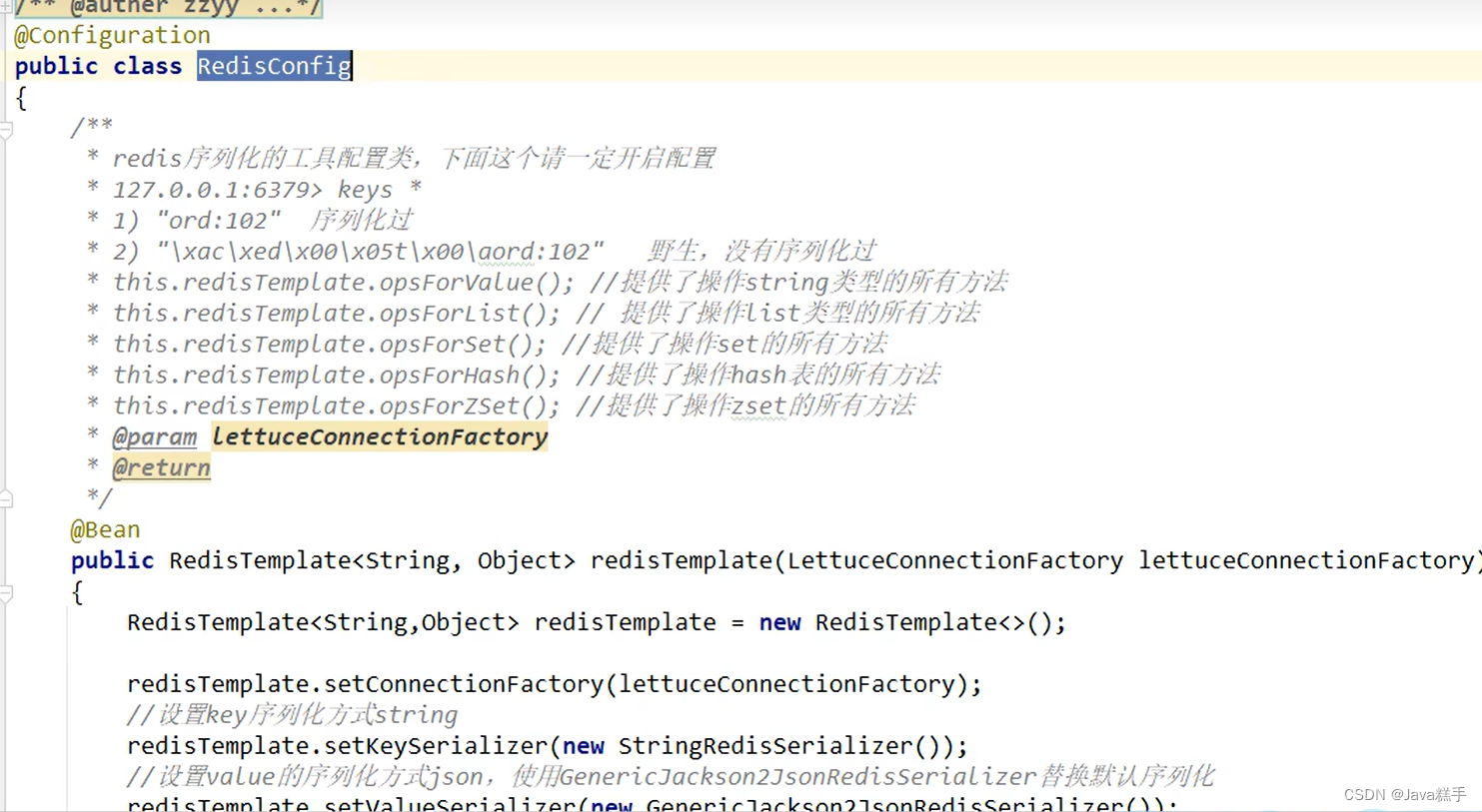
集成RedisTemplate
依赖配置

连接Redis单机
application properties文件配置
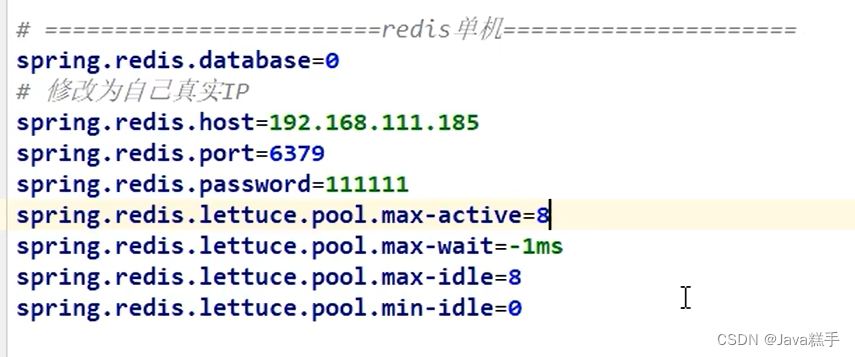

原因以及解决
使用StringRedisTemplate的默认序列化(StringRedisSerializer)就不会产生其他的不明的字符

redis客户端查询value出现乱码的解决方法

如果使用RedisTemplate就需要在配置中加一个StringRedisSerializer序列化器
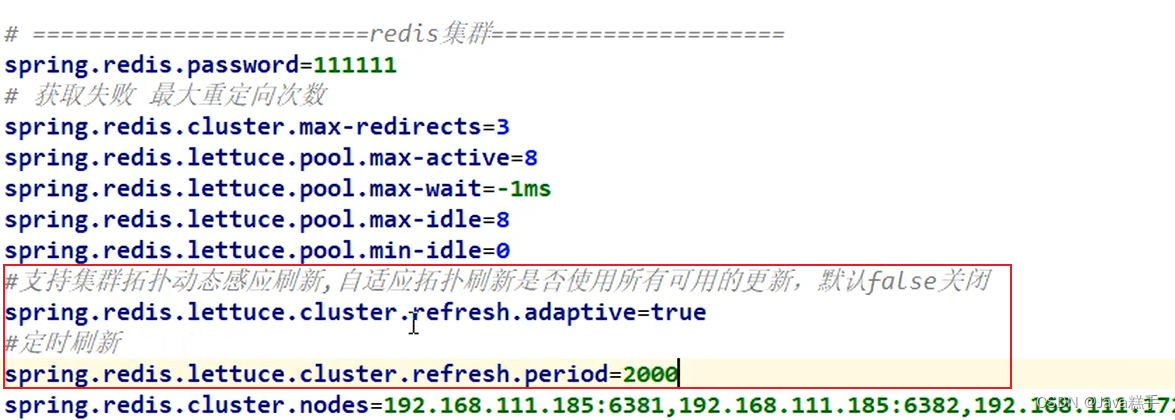
连接Redis集群

解决redis集群内部发生变化后,不能实时更新数据问题
在文件中开启动态感应刷新
结语
纯属刷课,学了点redis基本的东西,后面面试的造火箭内容,有空再来吧 😄















 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









