







之前并没有学习bfs,所以在做搜索题的时候,都是用dfs写的。在解决最优解或者最少步数问题时,本人都是dfs把全部的可能找出来,然后在里面找最优。
比如马的遍历https://www.luogu.com.cn/problem/P1443
题目描述
有一个 n×m 的棋盘,在某个点 (x, y)上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步。
输入格式
输入只有一行四个整数,分别为n,m,x,y。
输出格式
一个 n×m 的矩阵,代表马到达某个点最少要走几步(不能到达则输出 -1−1)。
输入输出样例
输入
3 3 1 1输出
0 3 2
3 -1 1
2 1 4 说明/提示
数据规模与约定
对于全部的测试点,保证 1≤x≤n≤400,1≤y≤m≤400。
错误:我一开始是打算从第一个点开始遍历,以遍历到的这一个点为终点,调用dfs函数,求起点到这一个点的所有的可能性,然后找到里面的最小值。十分简单粗暴的想法。确实能求出来,但是如果我找某一个点到另一个点所有的走法,那好像还行,可是如果我要通过这样的思路去做的话,有多少个点我就要求多少次所有的走法。这是很费时间的。
#include<bits/stdc++.h>
using namespace std;
int board[402][402];
int n,m,x,y;
int dx[8]={1,2,2,1,-1,-2,-2,-1};//顺时针搜索
int dy[8]={2,1,-1,-2,-2,-1,1,2};
int ans;
void dfs(int sx,int sy,int fx,int fy,int step)
{
if(sx==fx&&sy==fy)
{
ans=(step<ans?step:ans);//如果这一种可能性步数比较少,赋给ans
return;
}
int tx,ty;
for(int i=0;i<8;i++)
{
tx=sx+dx[i];
ty=sy+dy[i];
if(tx>=1&&tx<=n&&ty>=1&&ty<=m)
{
if(board[tx][ty]==0)
{
board[tx][ty]=1;
dfs(tx,ty,fx,fy,step+1);
board[tx][ty]=0;
}
}
}
return;
}
int main()
{
scanf("%d%d%d%d",&n,&m,&x,&y);
board[x][y]=1;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
if(i==x&&j==y)
{
printf("0 ");
}
else
{
ans=Max;
dfs(x,y,i,j,0);//通过dfs找起点到这一个点所有的可能性
if(ans==Max) printf("-1 ");
else printf("%d ",ans);
}
}
printf("\n");
}
return 0;
}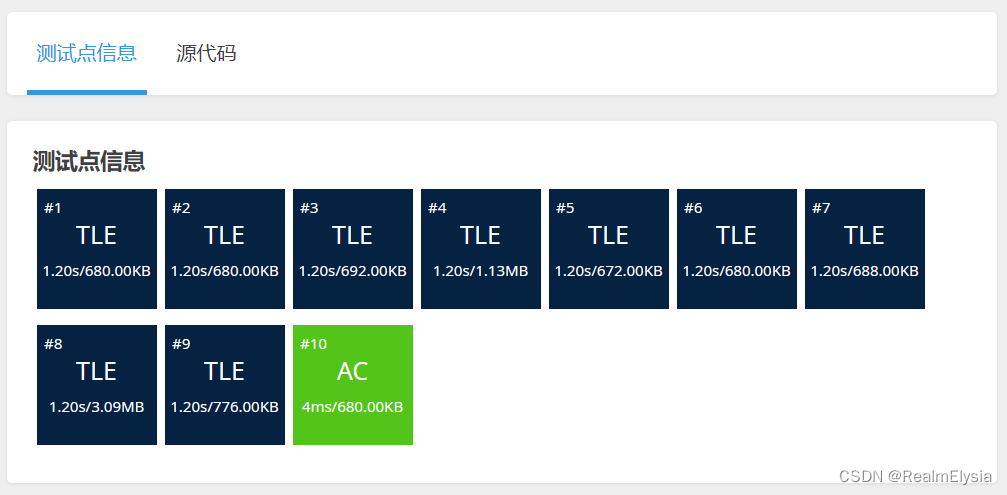
结果是时间超限。( 想想也是,哈哈)
然后,我就去学习了早已久仰其大名的bfs。
通过队列,来实现搜索。
#include<bits/stdc++.h>
using namespace std;
int board[402][402];
int n,m,x,y;
int dx[8]={1,2,2,1,-1,-2,-2,-1};//顺时针搜索
int dy[8]={2,1,-1,-2,-2,-1,1,2};
int ans[402][402];
struct point{
int x;
int y;
int step;
};
void bfs(int sx,int sy)
{
queue<point>r;
point s;
s.x=sx;s.y=sy;s.step=0;
r.push(s);
int tx,ty;
while(!r.empty())
{
int x=r.front().x,y=r.front().y;
for(int i=0;i<8;i++)
{
tx=x+dx[i];
ty=y+dy[i];
if(tx>=1&&tx<=n&&ty>=1&&ty<=m)
{
if(board[tx][ty]==0)
{
point temp;
temp.x=tx;
temp.y=ty;
temp.step=r.front().step+1;
ans[tx][ty]=temp.step;
r.push(temp);
board[tx][ty]=1;
}
}
}
r.pop();
}
}
int main()
{
scanf("%d%d%d%d",&n,&m,&x,&y);
memset(ans,-1,sizeof(ans));
ans[x][y]=0;
board[x][y]=1;
bfs(x,y);
for (int i=1;i<=n;i++)
{
for (int j=1;j<=m;j++)
{
printf("%-5d", ans[i][j]);
}
printf("\n");
}
return 0;
}AC了
dfs是一条路搜索完了,再去尝试另外一条路。与dfs不同,bfs更像是所有的路一起走,哪条路先到,哪条路就最快。由起点出发, 将与它相邻的所有的点都搜索一次,这些搜索出来的点是同级的,在由这些点出发去搜索与它们相邻的未被访问过的点。之所以不用去搜索已经访问过的点,是因为,已经访问过的点是上一级的或者更上一级的,既然已经有更快到那的路,为什么还要找稍远一点的呢。这就相当于由起点出发,开始扩散,扩散速度一致,先到的,就是最快的。















 1852
1852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









