






前言:在信息时代,数据越来越成为了一种宝贵的资源。而要获取这些宝贵的数据,爬虫就成为了一种不可或缺的工具。爬虫能够自动化地从互联网上爬取数据,并将这些数据整理成结构化的信息,为我们提供了便捷、高效的数据来源。而在这个数字化的世界,爬虫的应用广泛,不仅能够用于学术研究、商业分析等领域,还能够用于搜索引擎优化、媒体舆情监控和大数据分析等行业。
但同时,爬虫也存在着一些不可忽视的问题。比如,不恰当的爬虫可能会给网络资源造成过大的压力和损害,进而影响到正常的网络使用。因此,我们需要遵守相应的爬虫规范和法律法规,保证我们的爬虫行为合法、合规,不给网络资源和他人带来不良影响。
总之,爬虫是一项非常有价值的技术,但它需要我们以负责任的态度去运用和探索,才能发挥它的最大价值。
然后今天刚好教玻璃球新生们一些爬虫的知识。
这里作者也不赘述爬虫原理、合法性的一些知识。默认大家已经有所了解。
一、安装写爬虫需要的库
1.1安装request库
win+r 输入cmd 在终端输入pip install requests,如果下载慢的话加个 -i 清华镜像源。
pip install requests这个库用于对网页发起post 个 get请求,这里的内容在下面会讲的。
1.2安装lxml库
win+r 输入cmd 在终端输入pip install requests,如果下载慢的话加个 -i 清华镜像源。
pip install lxml 下载这个库是为了接下来我们用xpath解析。
二、学会适用开发者工具
我们在想要的页面下按下右键 -->检查,即可打开开发者工具,或使用ctrl+shift+i 打开。这里我们就直接以csdn官网首页为例子
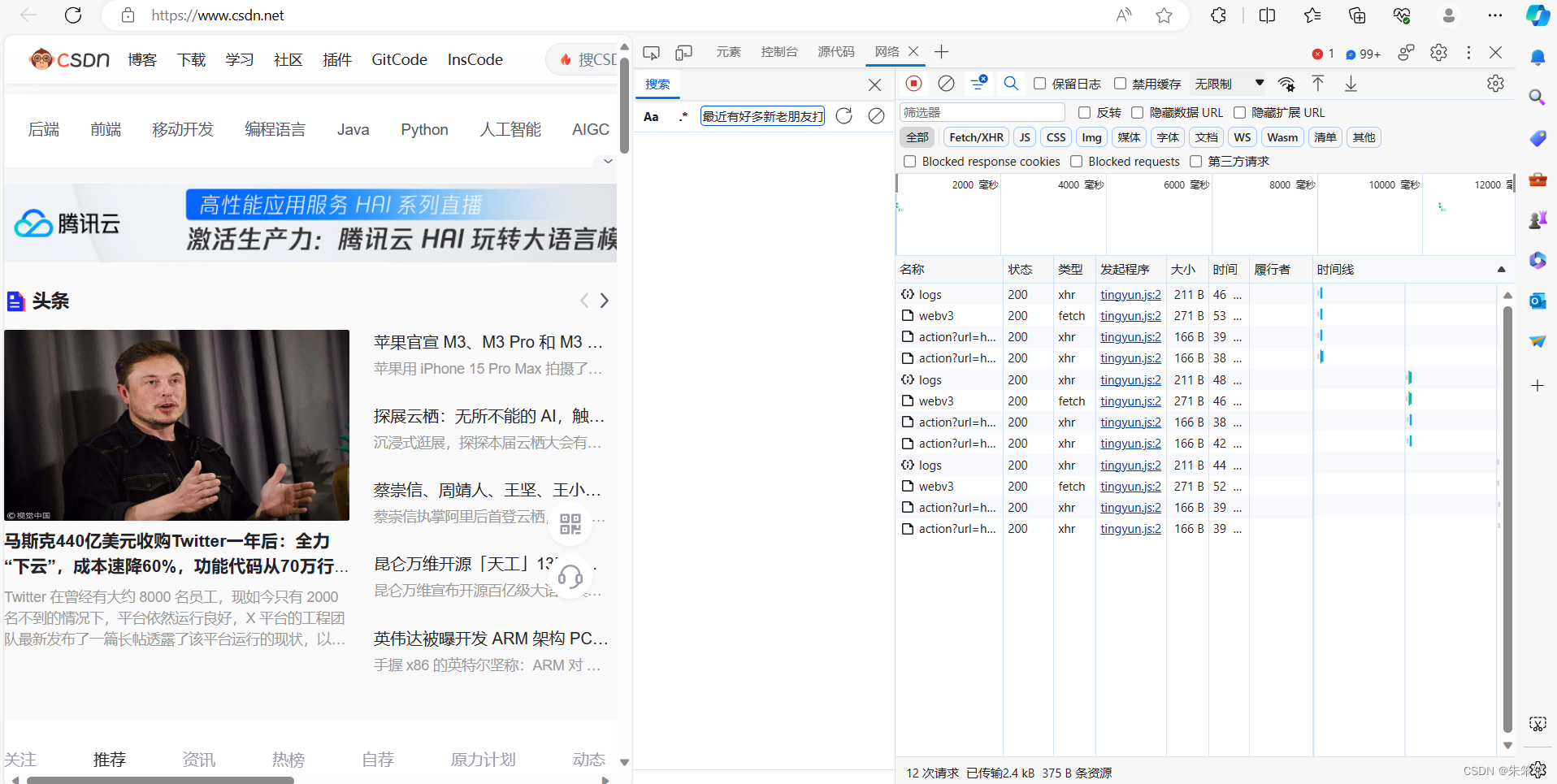
我们需要关注的就是右边那些一行行的,我们简称他们为包。而我们对网络进行操作的目的其实就是在对网页数据进行抓包,我们需要的数据就在这些包里。一般来说我们会先进行以此刷新,快捷键是ctrl+r,刷新后一些动态数据就会加载(比如js产生的数据)。
我们要明确:
如下图Fetch/XHR基本放的是ajax请求得到的数据包,一般的动态数据都是在文档那个位置,这里面一般有html代码。
![]()
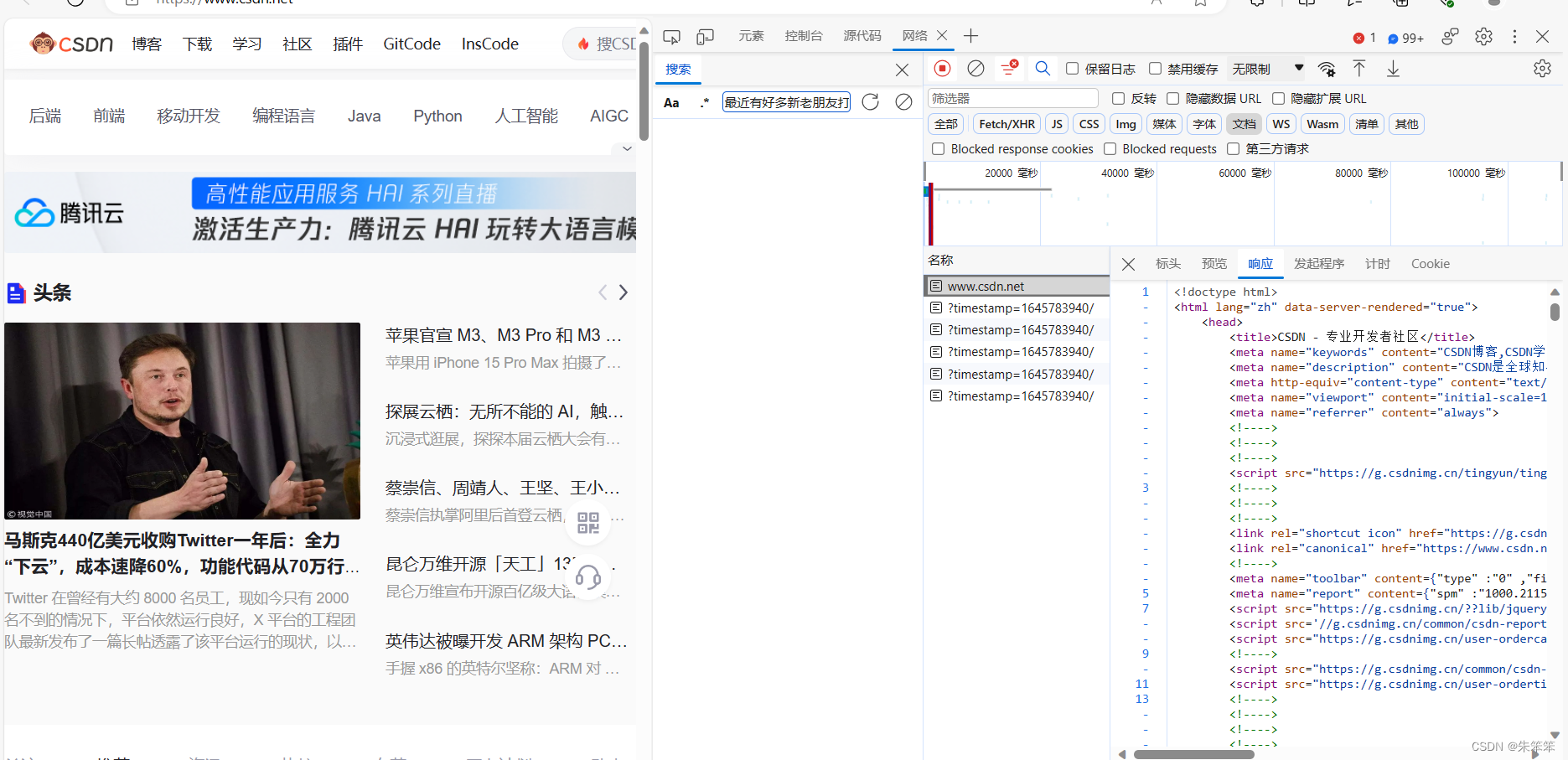
我们只要明确我们想要的数据在哪个API接口(包)中,然后对这个包发起请求就行了。
三、构建请求
一般来说请求分为post和get请求,前者是需要夹带参数才能发起,后者不用。
我们需要打开找到的数据包下的标头这个位置。
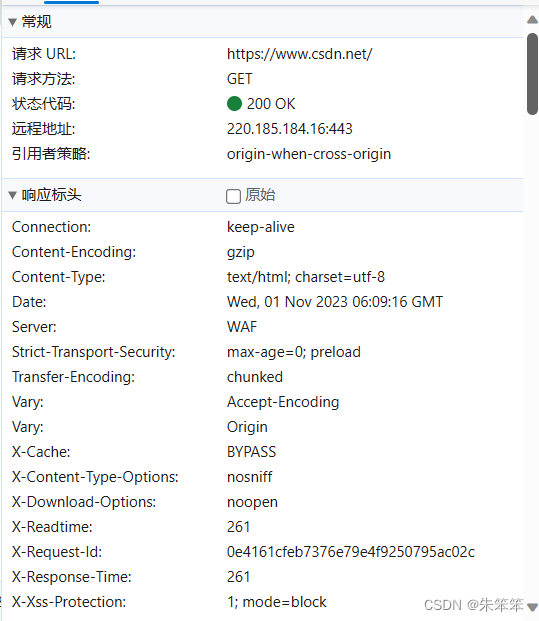
先看到常规里 。这里用的是get方法,也就是说咱不用去为参数的事情烦恼。然后请求数据包的url也在里面。看相应标头,这边又content-type类型为 txt/html,说明我们直接返回text的属性就可以拿到里面的代码,以用于解析。
然后比较重要的就是下面的请求标头
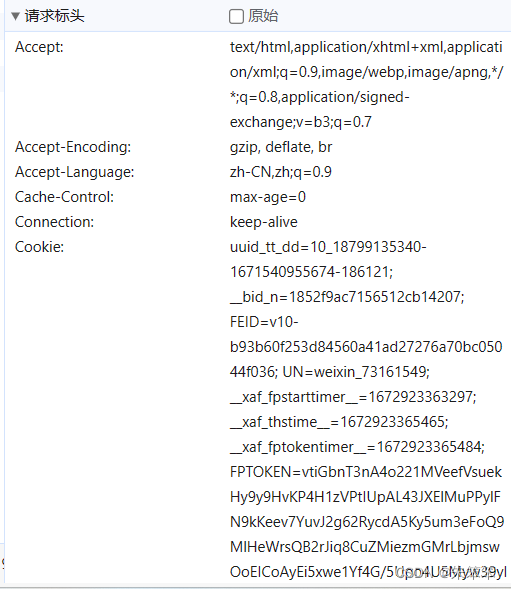
请求标头中比较重要的是cookie和UA头
UA头则代表你发起请求夹带的主机信息,表示是一个人来访问的。这边通常要拿下来
Cookie是浏览器中存储的一小段文本信息,它通常由服务器在HTTP响应头中发送给浏览器,浏览器则会在之后的请求中将该文本信息发送给服务器。Cookies 主要有如下作用:
-
会话状态管理:当用户在网站上进行登录操作时,服务器会在响应中包含一个cookie,这个cookie中包含了会话ID,服务器就可以根据这个会话ID识别用户,并保持用户的登录状态,从而实现了会话状态管理。
-
个性化设置:服务器可以将用户个性化设置保存在cookie中,如用户的语言偏好、字体大小偏好等,这样用户打开页面时就可以自动按照个性化设置展示页面,提高用户体验。
-
购物车管理:当用户在电商网站中添加商品到购物车时,服务器会将购物车信息保存在cookie中,这样当用户离开网站并重新打开时,购物车信息还能保留。
-
浏览历史记录:当用户在浏览网站中的文章、商品、资讯等内容时,服务器可以将浏览历史记录保存在cookie中,这样用户下次打开网站时就能看到之前浏览过的内容。
总之,Cookie是通过在浏览器和服务器之间交换信息来实现一些常用的功能,从而提高用户体验和网站性能。
四、介绍xptah
XPath(XML Path Language)是一种在XML(eXtensible Markup Language)文档中查找信息的语言,它可以帮助我们快速地定位XML文档中的某个节点或一组节点,以便对其进行操作。XPath的语法基于路径表达式和操作符,下面是一些常用的XPath写法:
-
选择元素节点:使用标签名来选取元素节点,例如:
/bookstore/book。 -
选择所有节点:使用通配符“*”来选取所有节点,例如:
//*。 -
选取父节点:使用“..”来选取父节点,例如:
/bookstore/book/title/..。 -
选取子节点:使用“/”来选取子节点,例如:
/bookstore/book/title。 -
选取属性:使用“@”来选取属性,例如:
/bookstore/book/@category。 -
选取特定属性的元素:使用“[]”来选取拥有特定属性的元素,例如:
/bookstore/book[@category='children']。 -
选取位置:使用“[]”和数字来选取某个位置的元素,例如:
/bookstore/book[1]。 -
选取最后一个元素:使用“last()”来选取最后一个元素,例如:
/bookstore/book[last()]。 -
选取前面的元素:使用“position()”来选取前面的元素,例如:
/bookstore/book[position()<3]。
上述只是XPath的一些常用写法,XPath还提供了一些函数,如数值函数、字符串函数、逻辑函数等。掌握XPath语法对于爬取数据是非常重要。
刚才我们实战中的xpath就是这样的,从html一层层下来就行,只要这里写的没问题就可以拿到我们想要的数据。
src = tree.xpath('//ul[@class="clearfix"]/li/a/img/@src')
name = tree.xpath('//ul[@class="clearfix"]/li/a/b/text()')五、实战(爬取图片保存在img文件夹中)
url为https://pic.netbian.com/4kdongman/
先抓包找到数据位置
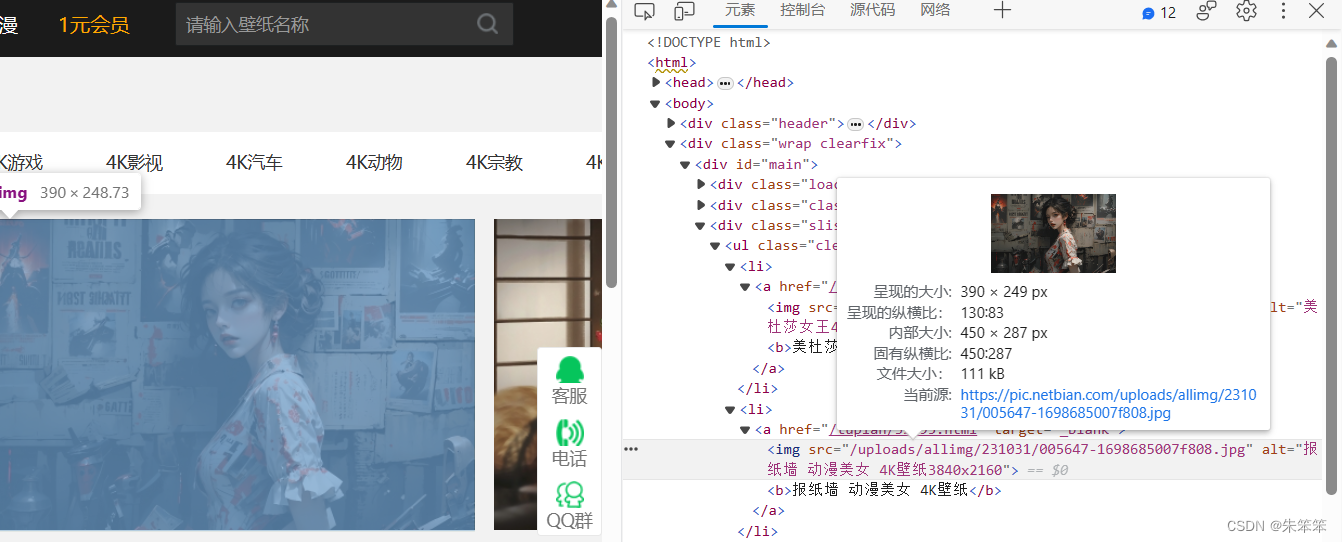
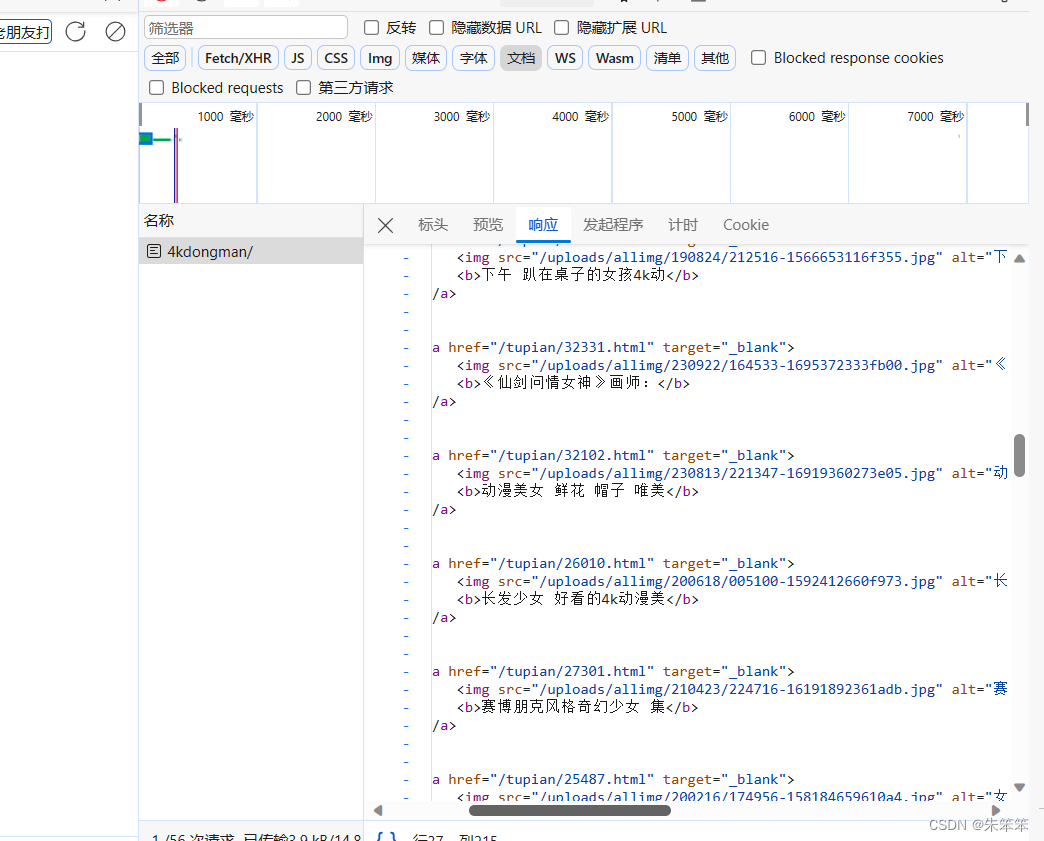
我们需要的东西很简单,就是img的src和图片名字。然后我们只要拿到src并转码就可以保存到我们本地。
import requests
from lxml import etree
import os
if not os.path.exists('img'):#判断是否存在文件夹
os.mkdir('img')#创建文件夹
# if not os.path.exists("1111"):
# os.mkdir()
url = "https://pic.netbian.com/4kdongman/"#网址
# UA伪装
headers = {
'User-Agent':"",#UA给你们删了,防止有人拿来做坏事嘿嘿
}
r = requests.get(url = url , headers = headers).text
tree = etree.HTML(r)
src = tree.xpath('//ul[@class="clearfix"]/li/a/img/@src')
name = tree.xpath('//ul[@class="clearfix"]/li/a/b/text()')
for i in range(len(src)):
img_url = "https://pic.netbian.com"+src[i]#图片网址补充前缀
img_name = name[i].encode('iso-8859-1').decode('gbk')#图片名字,编码转换,图片数据中一般是二进制数据。
r = requests.get(url=img_url,headers=headers).content#图片内容
with open("./img/"+img_name+'.jpg','wb+') as f:#保存图片
f.write(r)#写入图片
print(img_name+"保存成功")

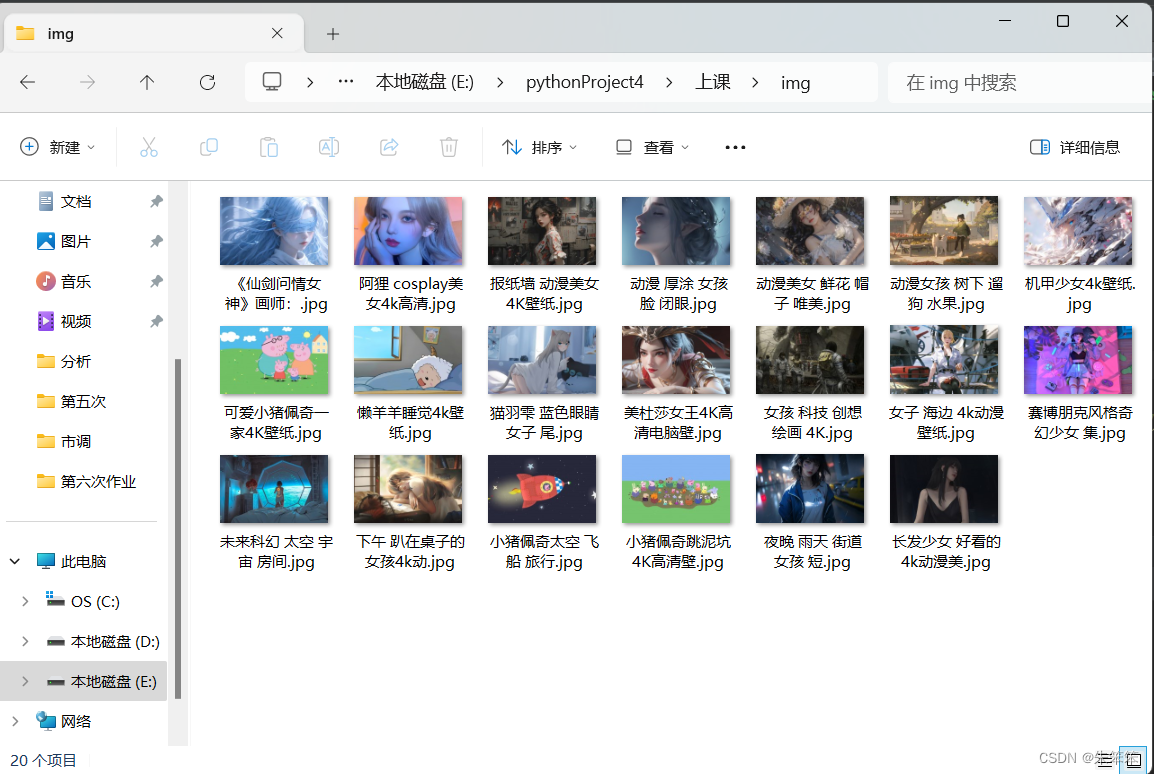
运行后图片会存在本地的img文件夹数据中,img这个文件夹我是用os新建的,所以会在文件同一目录
六、结语
爬虫还得自己多写,多访问几个不同的网站,多去熟悉一些防爬,夺取碰壁,爬虫功力就会增长。作者现在苦于js逆向逆不出来所以只能写写基础的没有反爬的爬虫给大家看看。
这篇文章还没介绍UA池、IP池、休眠反爬、逆向……只讲了最基础的访问与解析,希望能帮助到入门的小伙伴们。
















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











