







Java源码系列:下方连接
http://t.csdn.cn/Nwzed
前言
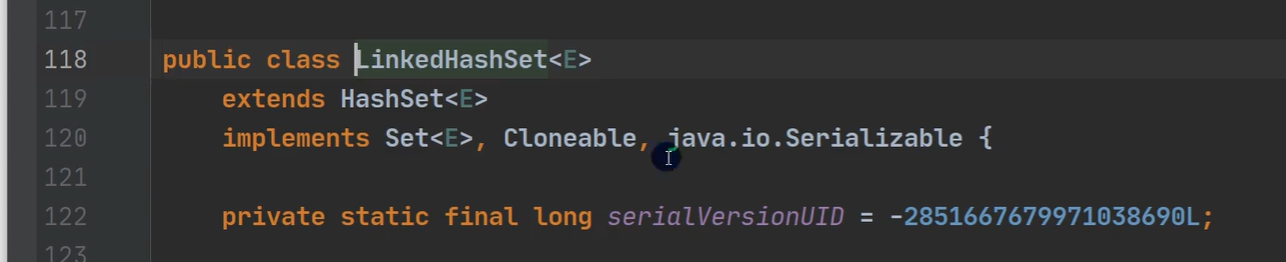
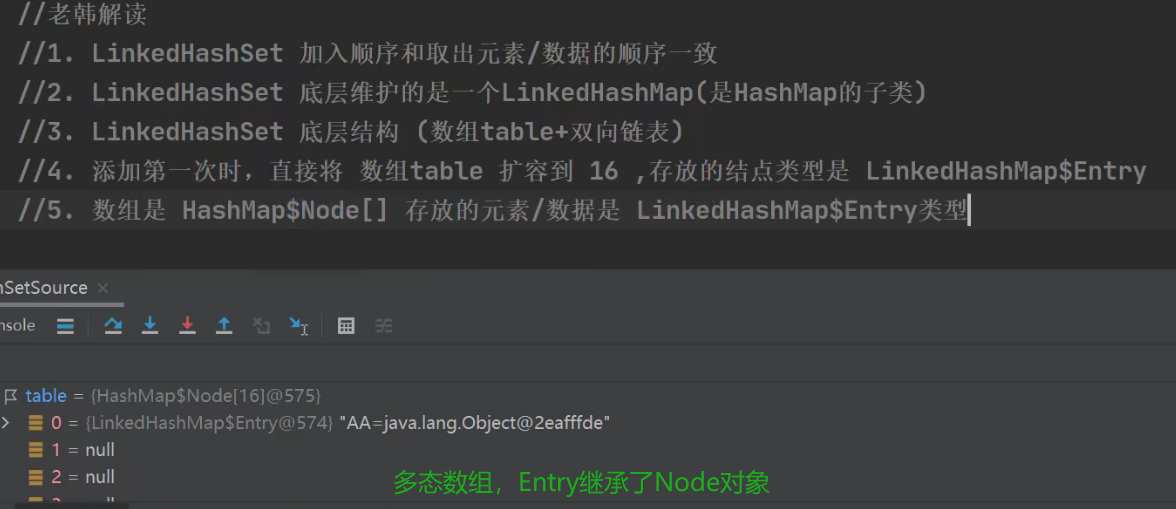
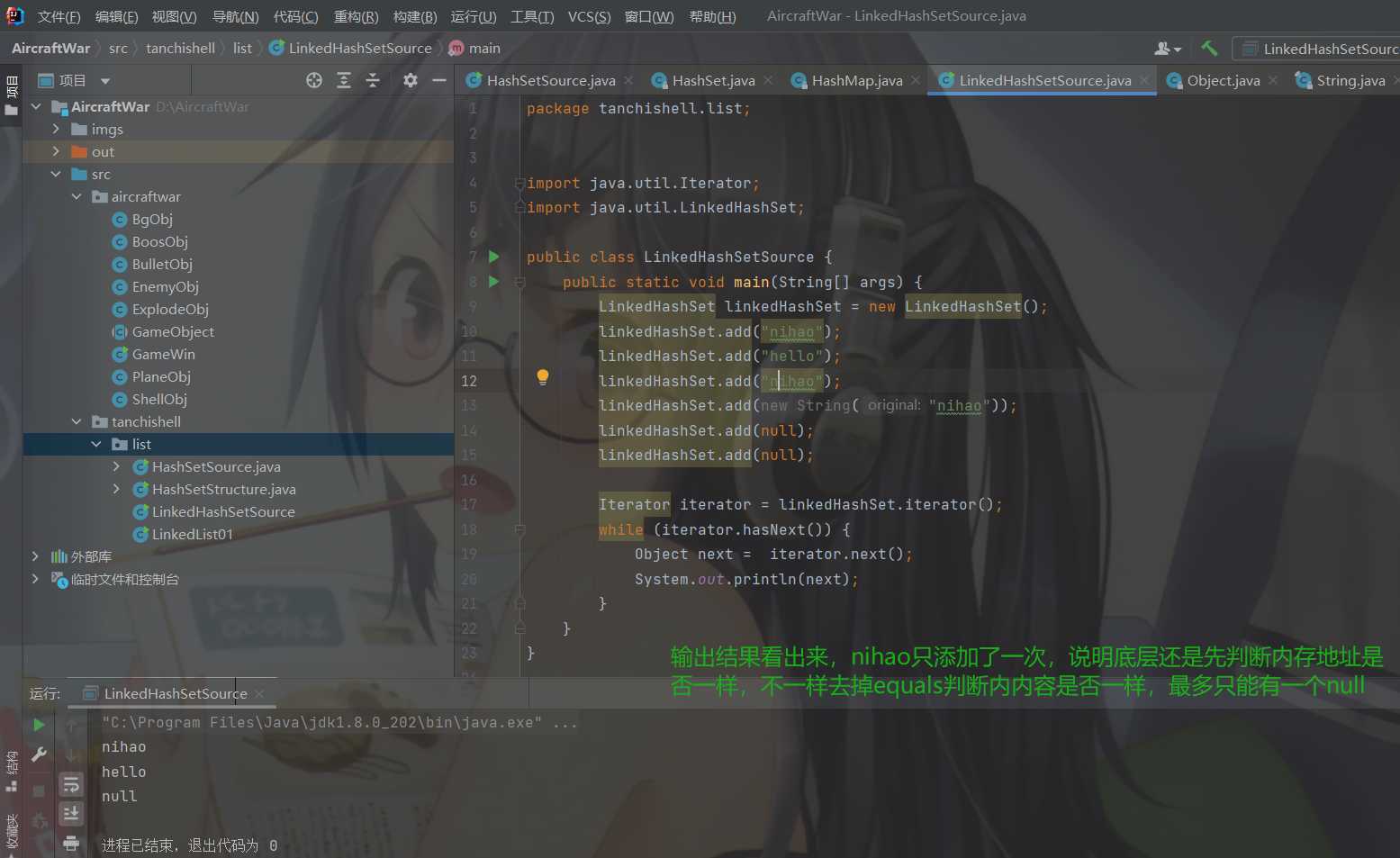
LinkedHashSet是HashSet的子类,LinkedHashSet底层是一个LinkedHashMap,底层维护了一个数组➕双向链表,存取顺序一致,(HashSet存取无序)。LinkedHashSet也是根据元素的HashCode值来决定元素的存储位置,同时使用双向链表维护元素的次序,这使得元素看起来是有序的。LinkedHashSet不允许添加重复的元素,所以做多保存一个null。
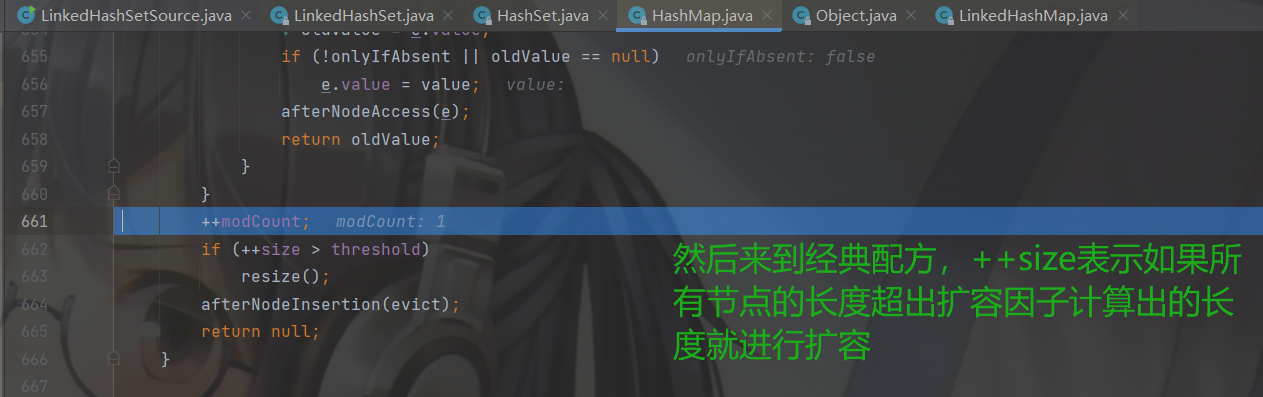
LinkedHashSet的无参构造里面调用了父类HashSet的有参构造创建了16长度的数组扩容因子是0.75f,数组和双向链表的size满足扩容因子计算的长度就会进行二倍扩容,并不是数组的长度大于扩容因子计算的长度。
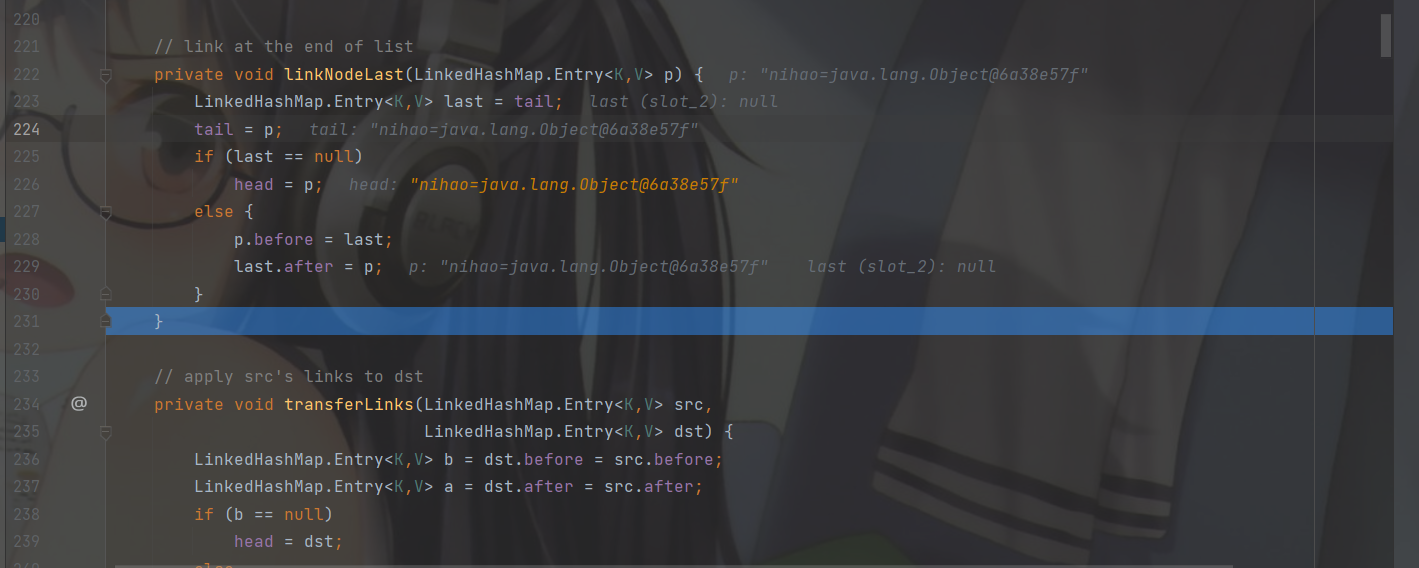
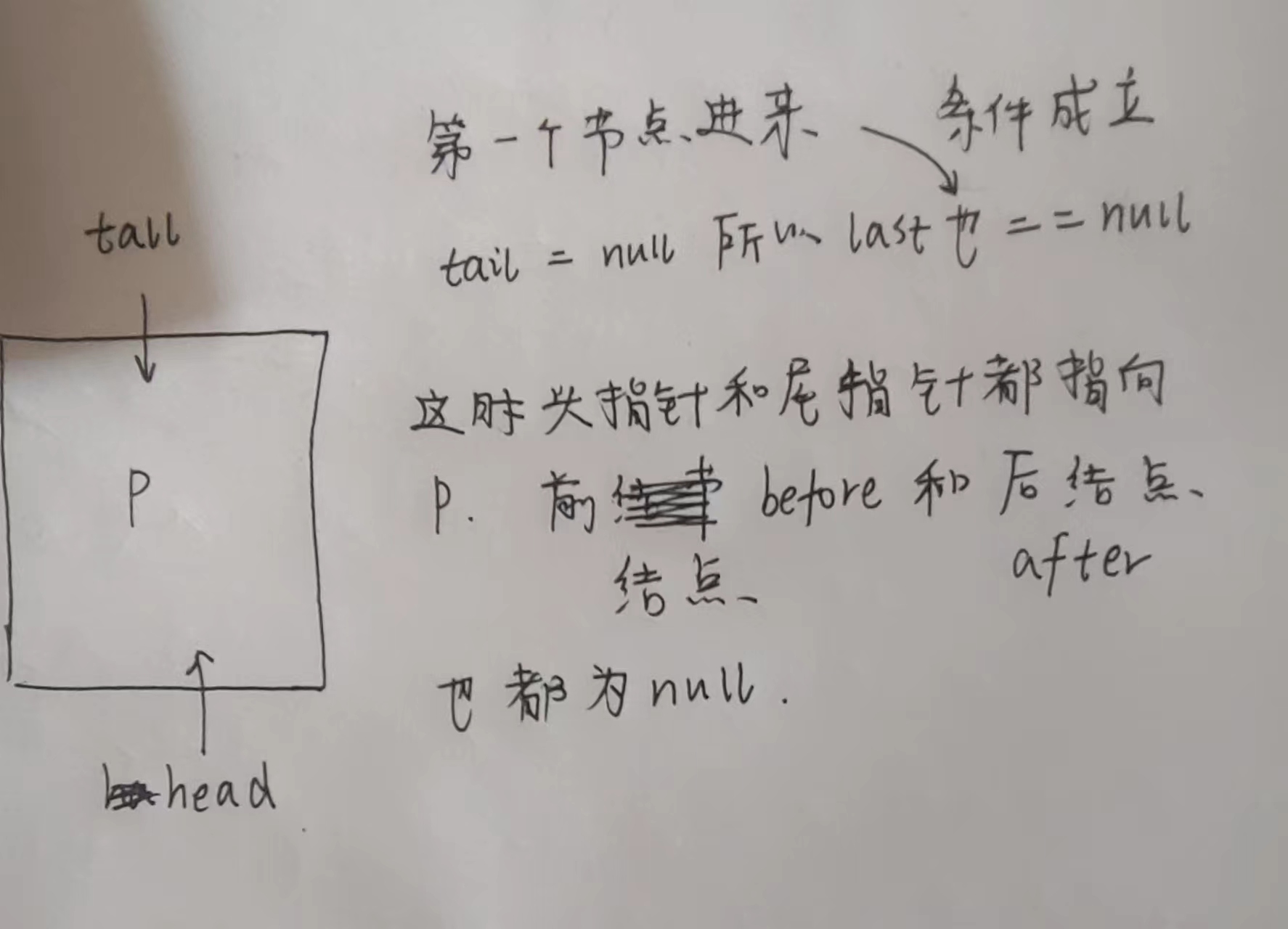
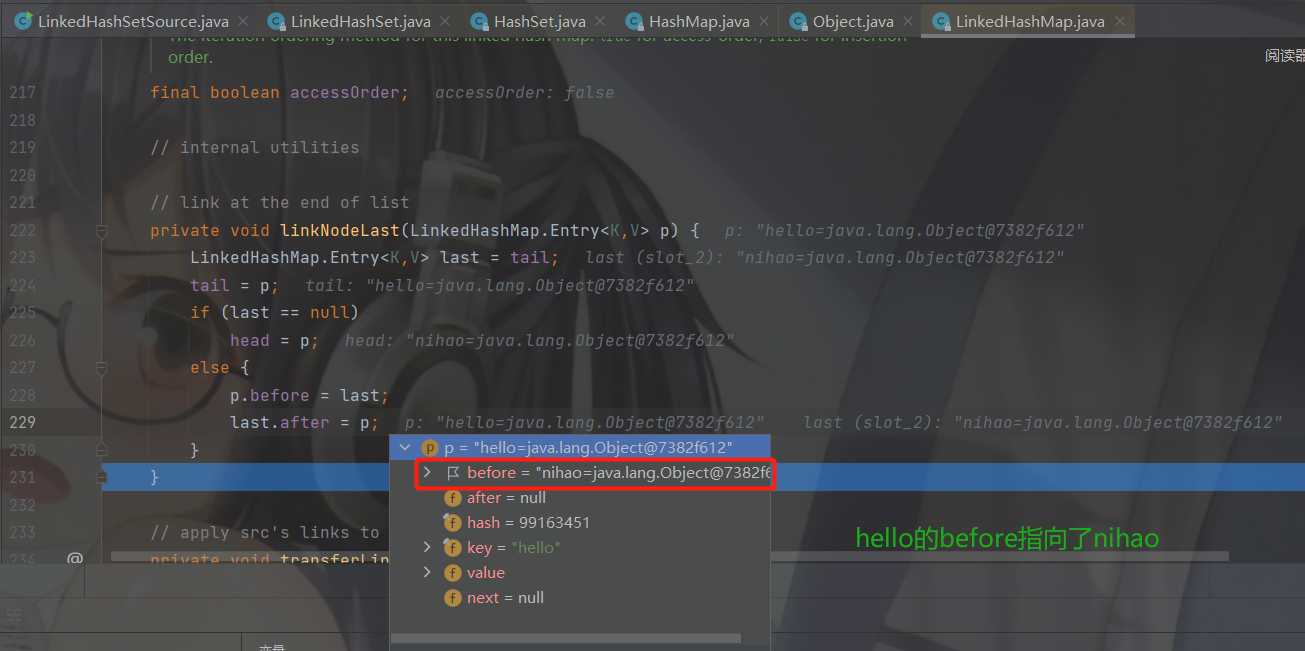
数组➕双向链表,并不是数组元素下面挂载的是一个双向链表,而是当数组一旦存有元素就会将头指针和尾指针都执向这一个元素,当后面有元素根据下表落点的计算添加到数组别的下标后就会让第一个元素的后指针指向添加的元素,尾指针也不在指向第一个元素,而是新添加的元素,新添加的元素的前指针指向第一个元素。
如果添加的元素和第一个元素,计算出的下标落点一样,就进行挂载到元素的后面,形成双向链表,再让尾指针指向添加的元素,如果原来的第一个元素的后指针有节点,就让新添加的节点的前指针指向第一个元素后指针指向原本指向的节点,也就是双向链表的节点新增。
提示:以下是本篇文章正文内容,下面案例可供参考
一、LinkedHashSet简介

LinkedHashSet是HashSet的实现子类,HashSet是数组加单向链表,LinkedHashSet是数组加双向链表,但是LinkedHashSet底层是一个LinkedHashMap。HashSet存入数据顺序和取出的顺序不一样,但每次遍历取出元素的顺序都是一样的。而LinkedHashSet存入和取出的顺序都是一样的。
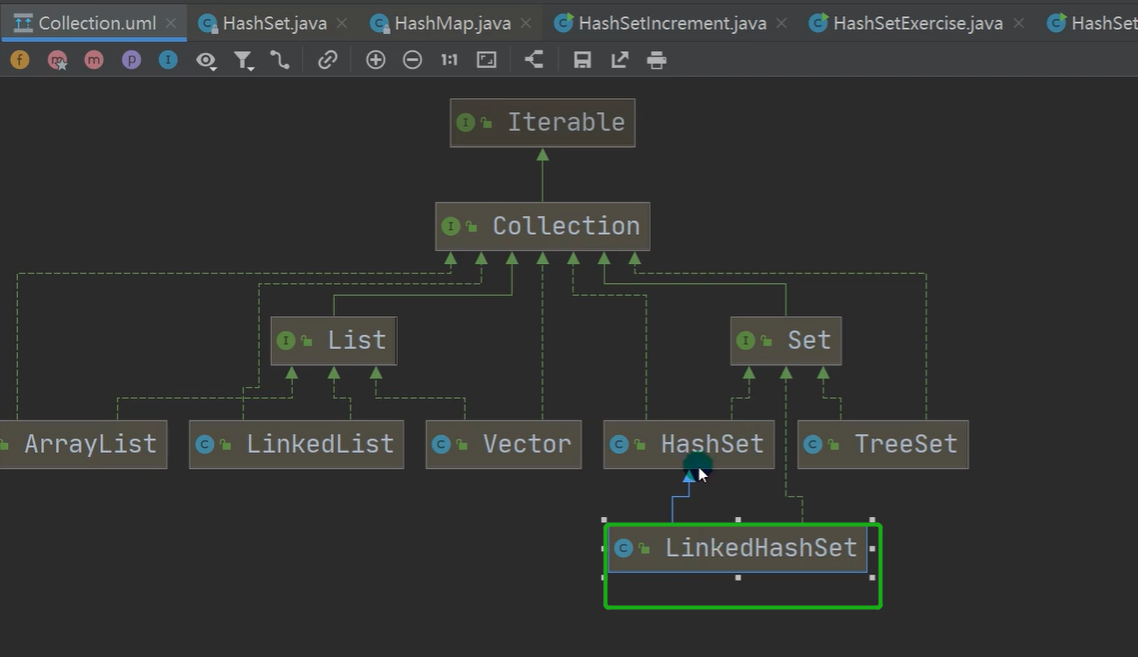

二、LinkedHashSet.add( )方法底层解析
第一次添加元素
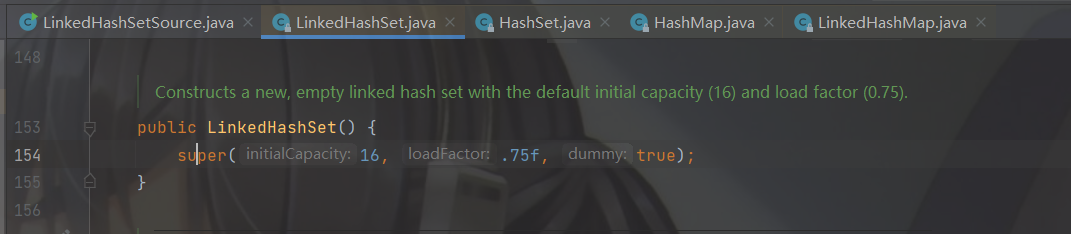
先进入无参构造,调用super父类方法。
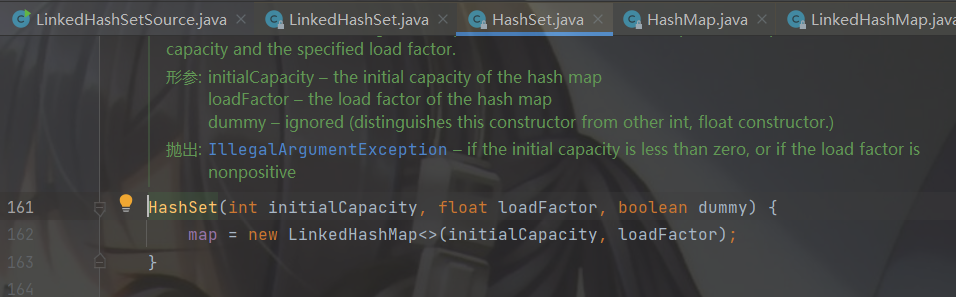
继续跟入父类HashSet,new 了一个 LinkedHashMap 所以LinkedHashSet底层是一个LinkedHashMap,并且指定了长度为 16,扩容因子为 0.75f 。到这里我们直接步出就ok了。
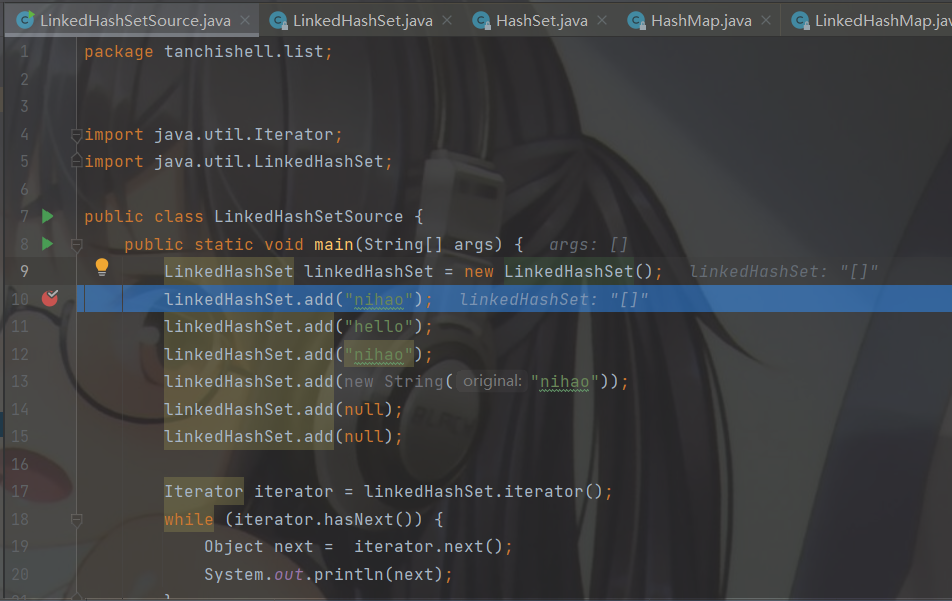
准备步入 add 方法。
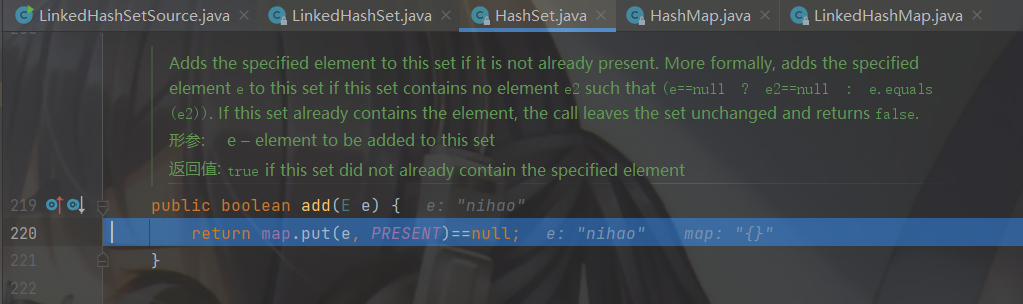
会先来到父类 HashSet 的 add 方法,继续步入
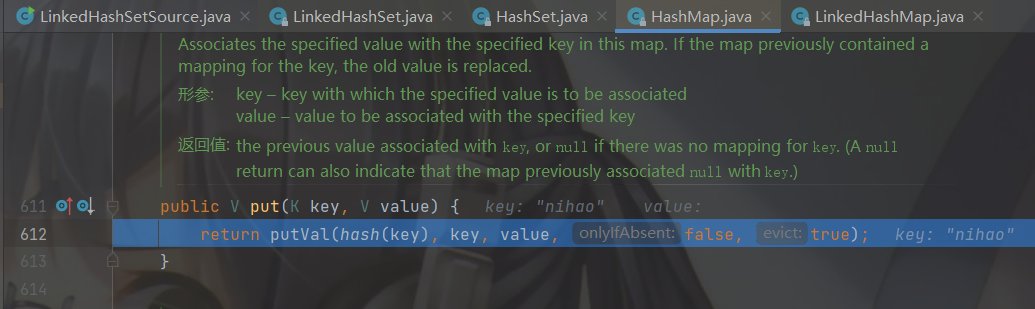
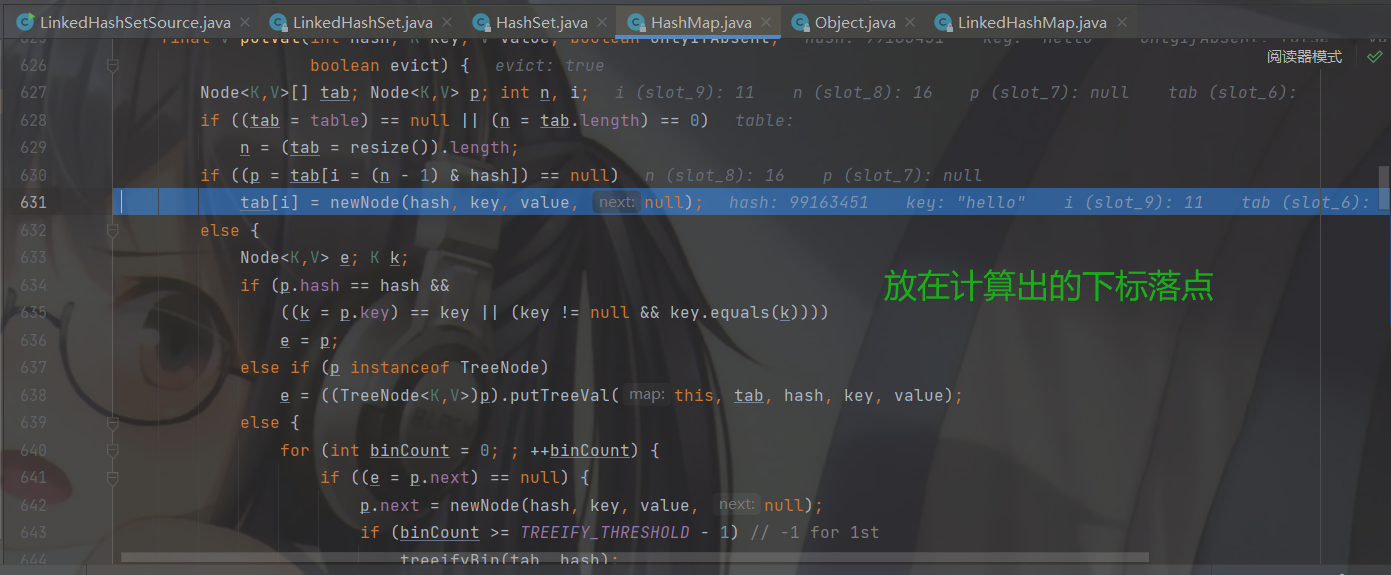
步入进去会到 HashMap的 putVal方法,先去调用 hash(key) 通过hashCode获取hash值
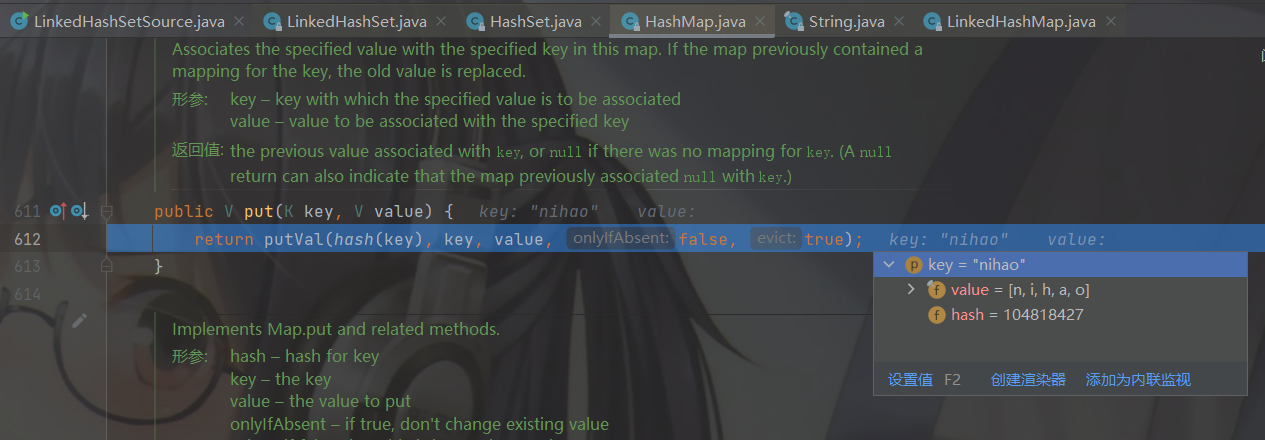
从 hash(key) 出来后就有了 hash值
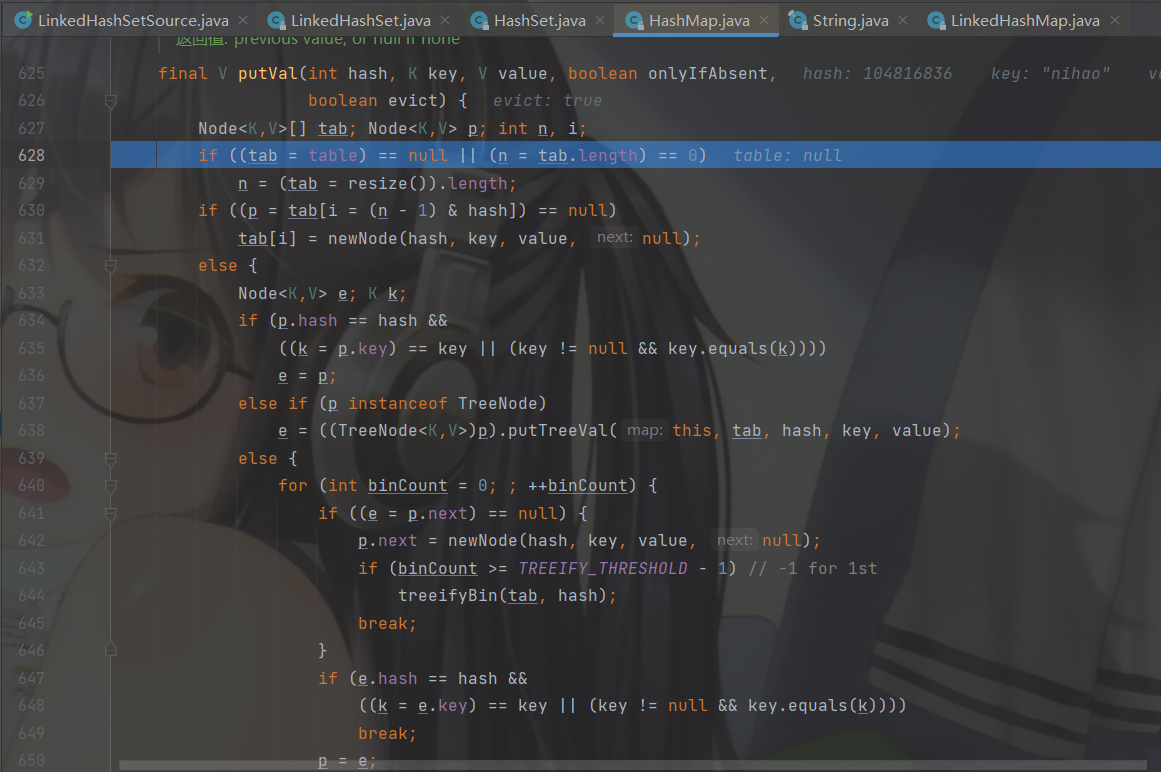
这部分就和上一章HashSet一样了,这里不过多赘述,可以去上一章HashSet集合底层源码分析转一圈再回来。
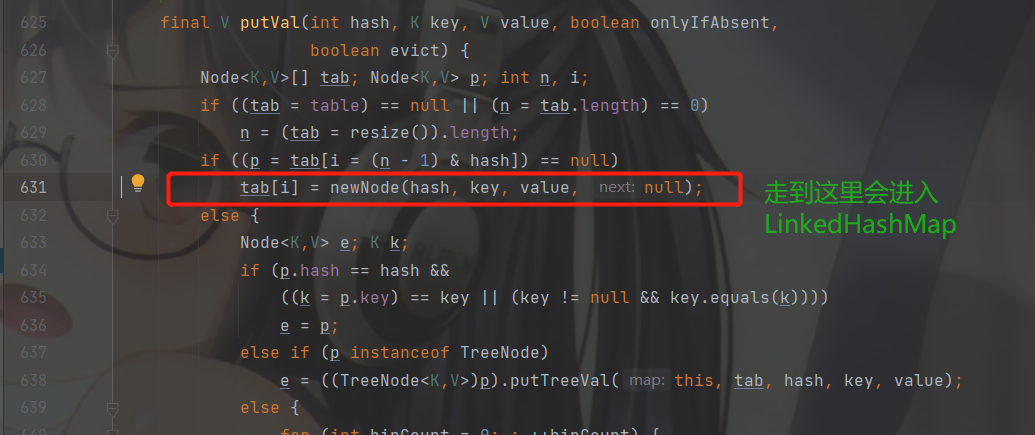
返回 p 之前还会调用 linkNodeLast( p )方法。
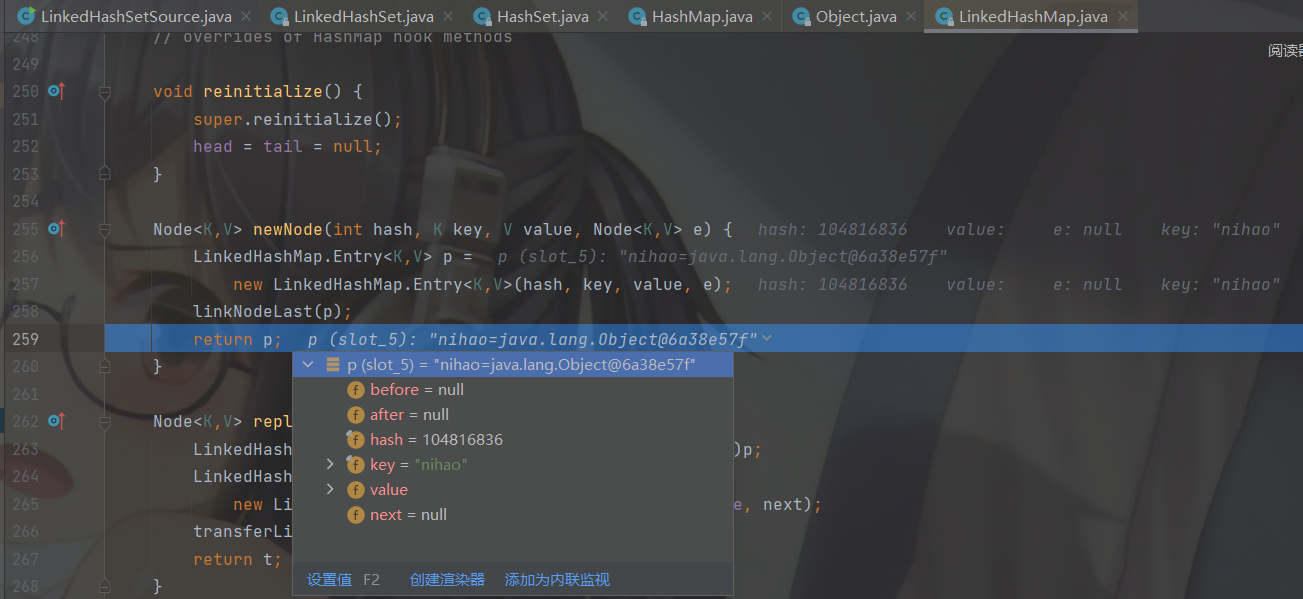
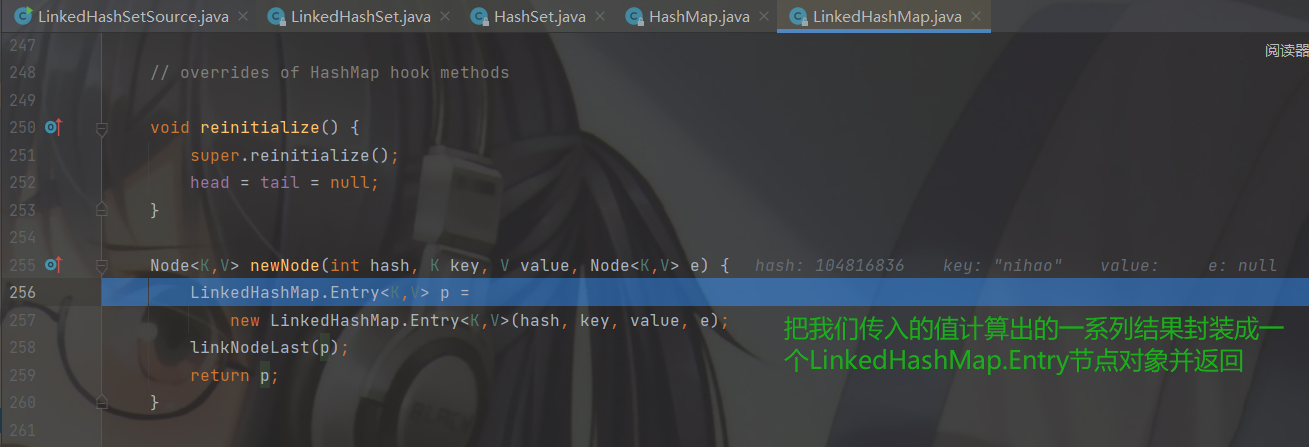
调用完 linkNodeLast( p )方法回到 newNode( )。
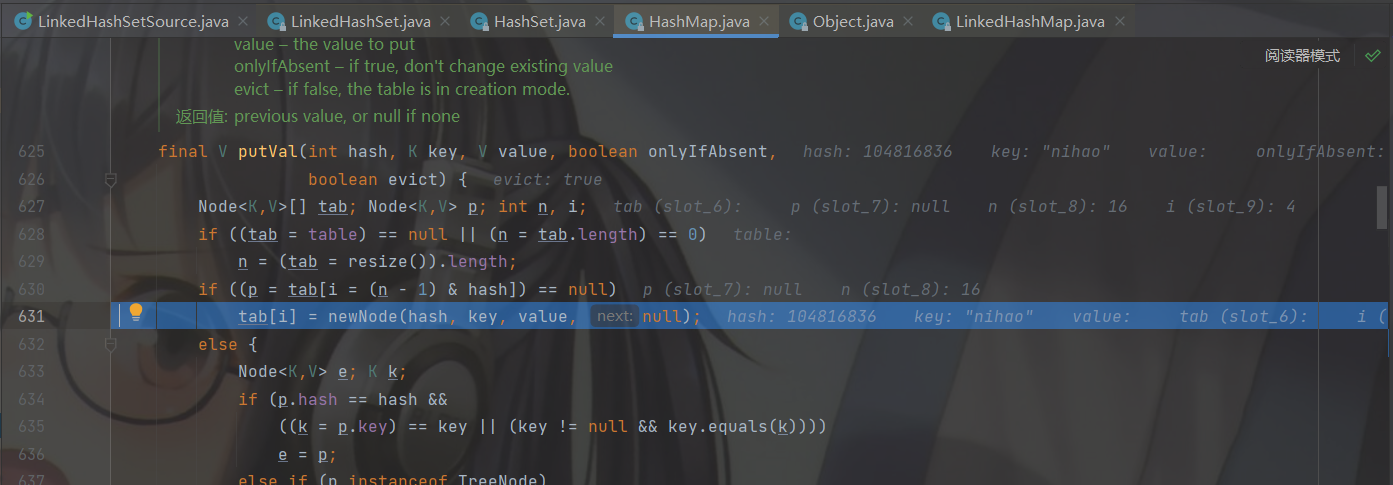
再回到 putVal( )。
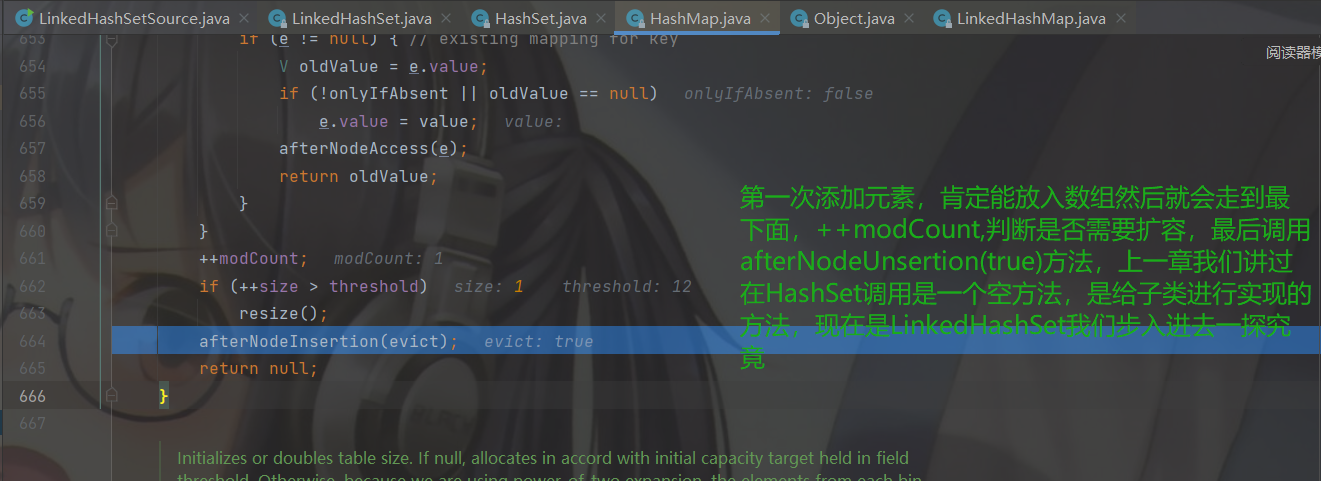
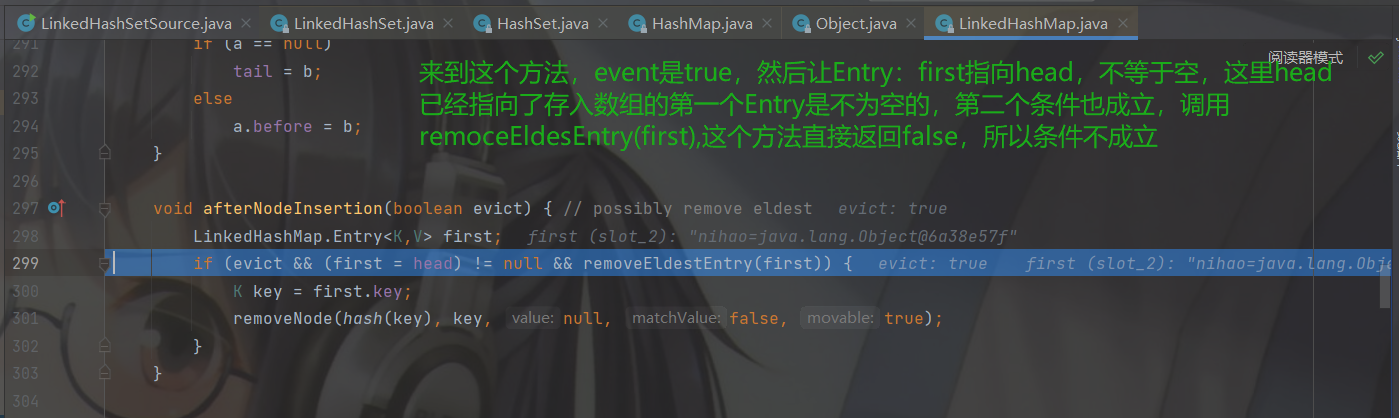
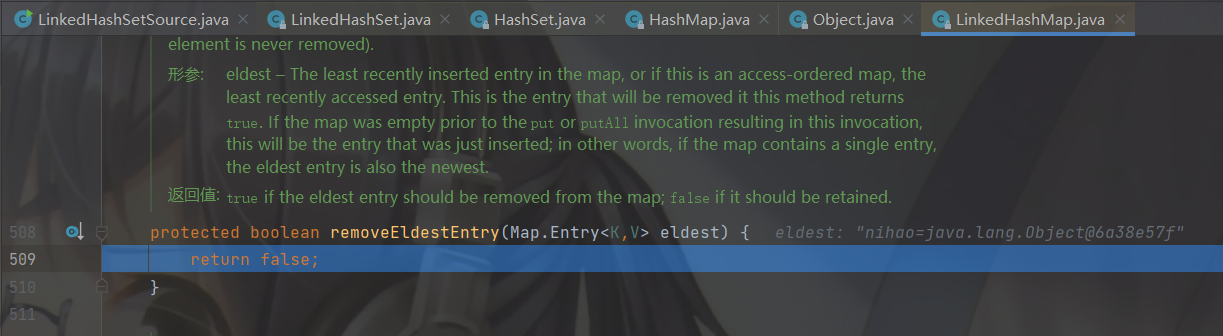
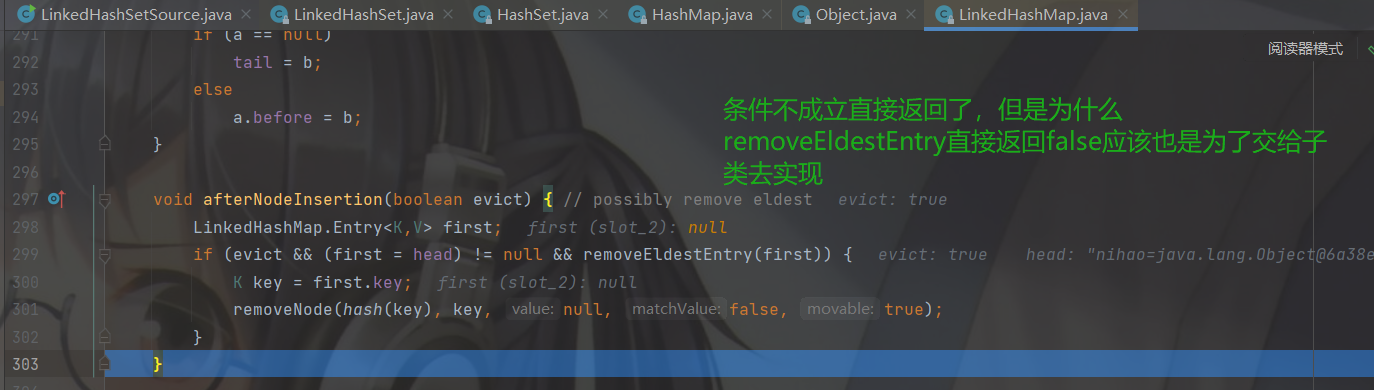
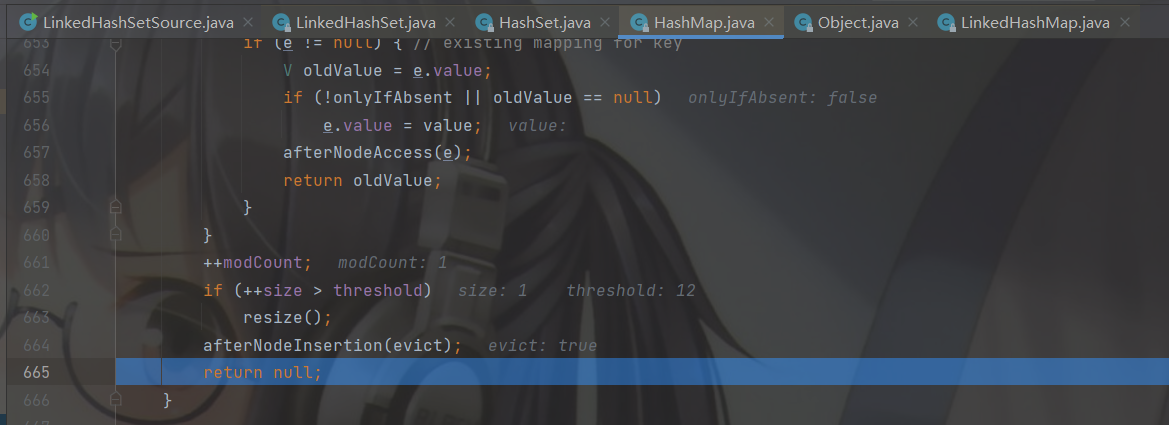
然后return一个空,判断 null == null条件成立,添加成功。
第二次添加元素

步入第二次添加元素,添加 hello字符串。
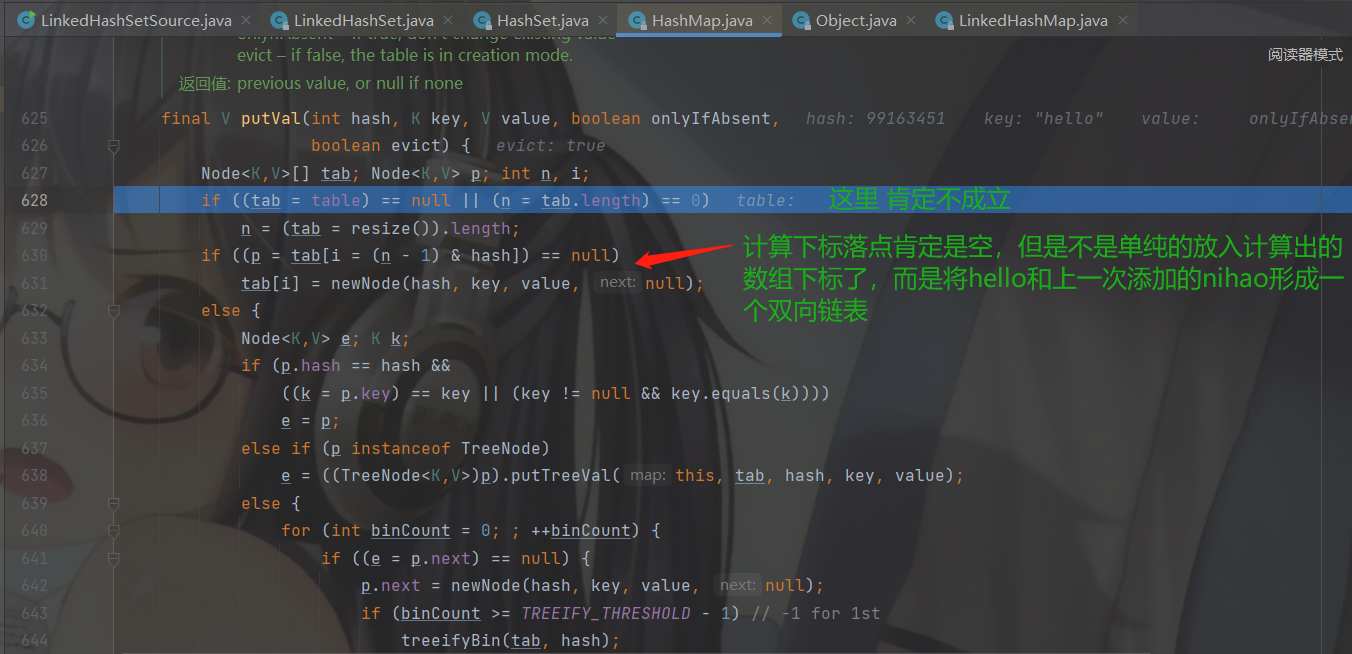
不再bb那么多了都是重复步骤,直接来到 putVal 方法。
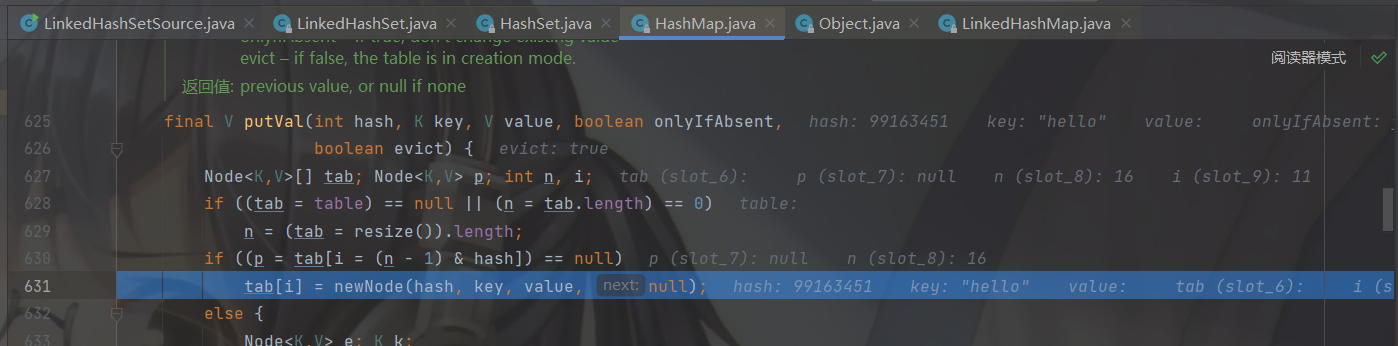
步入 newNode 会去 LinedHashSet的 newNode方法。
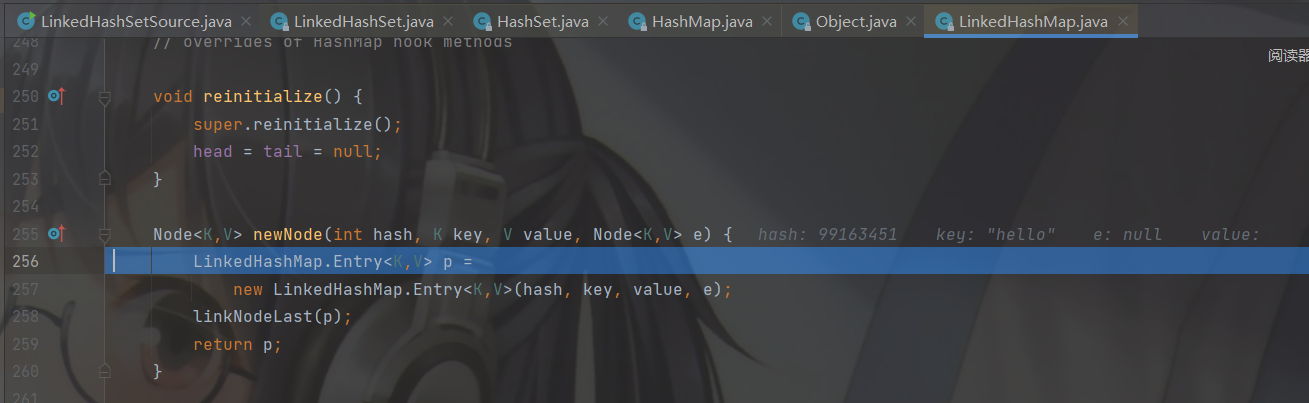
熟悉的配方熟悉的味道,还是把传入的数据定义了一个临时节点 p 。然后调用 linkedNodeLast( )方法。
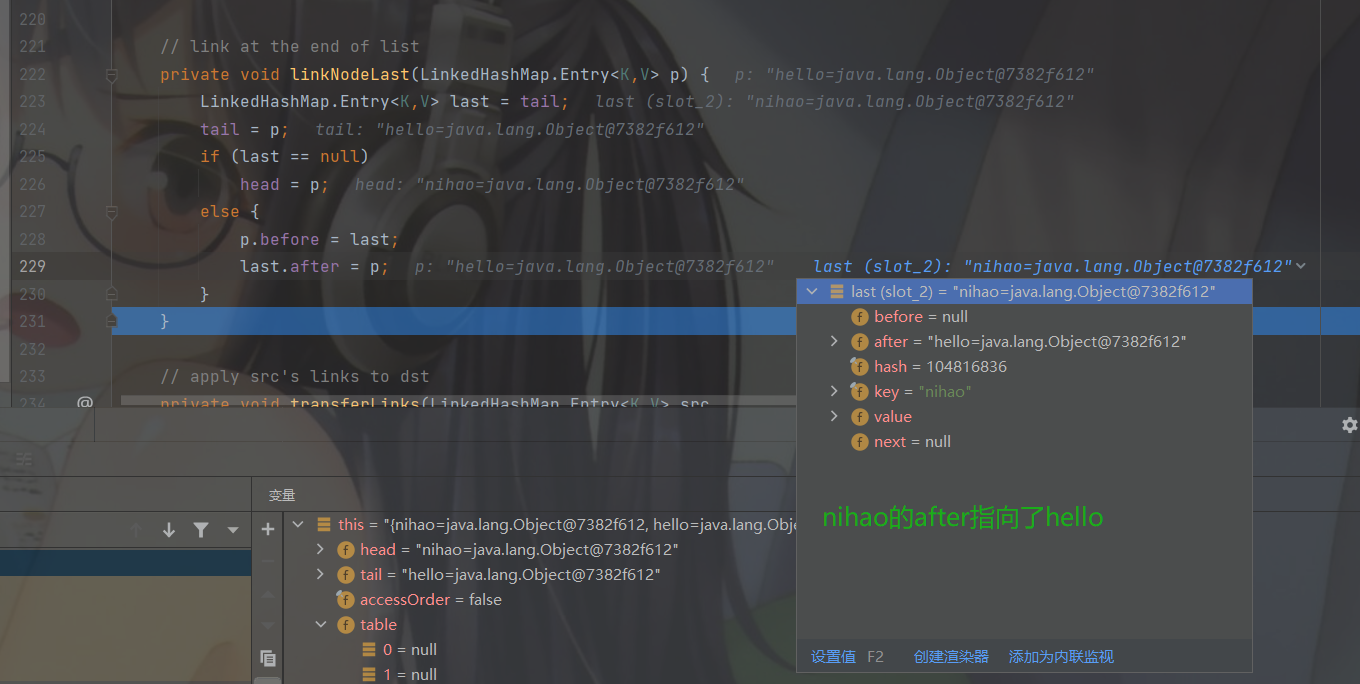
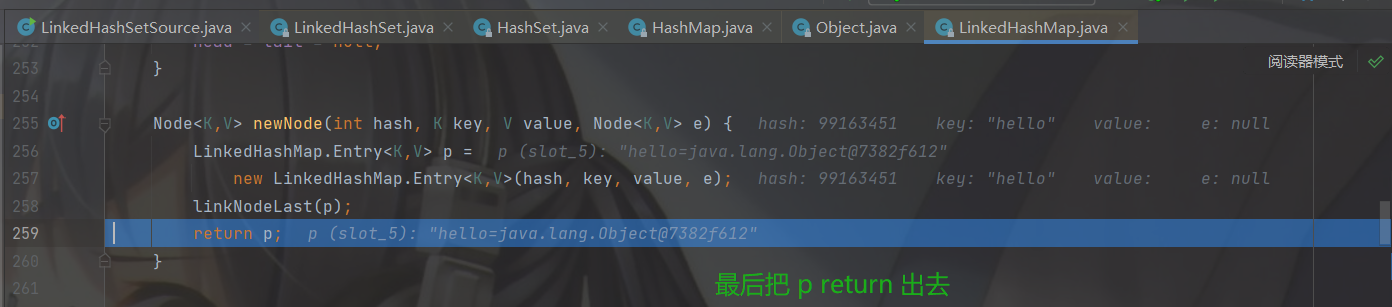
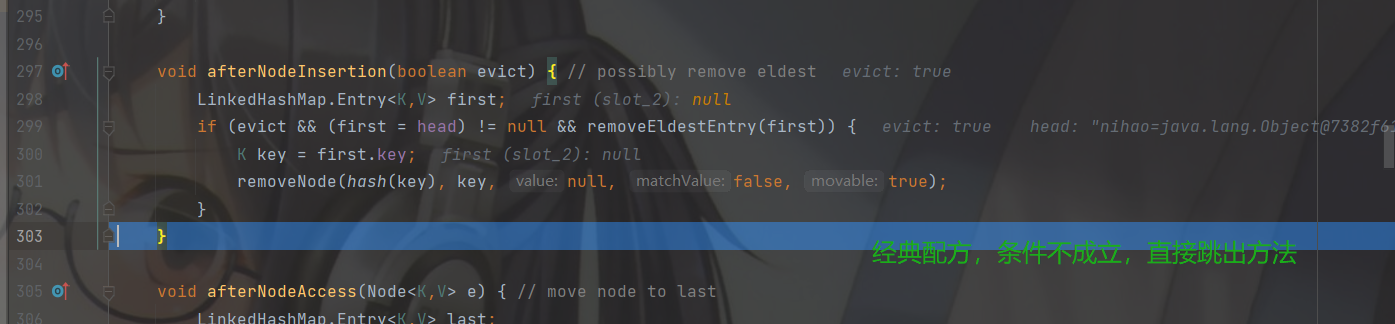

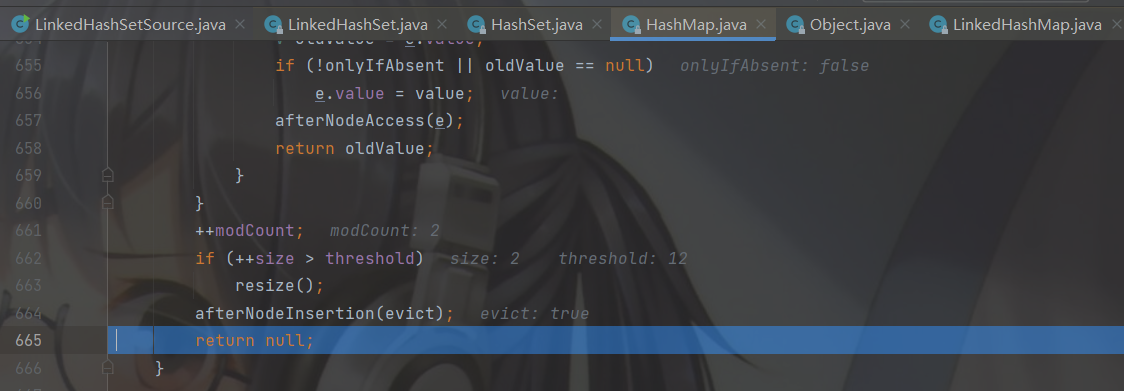
最后返回空表示添加成功。
添加元素重复元素
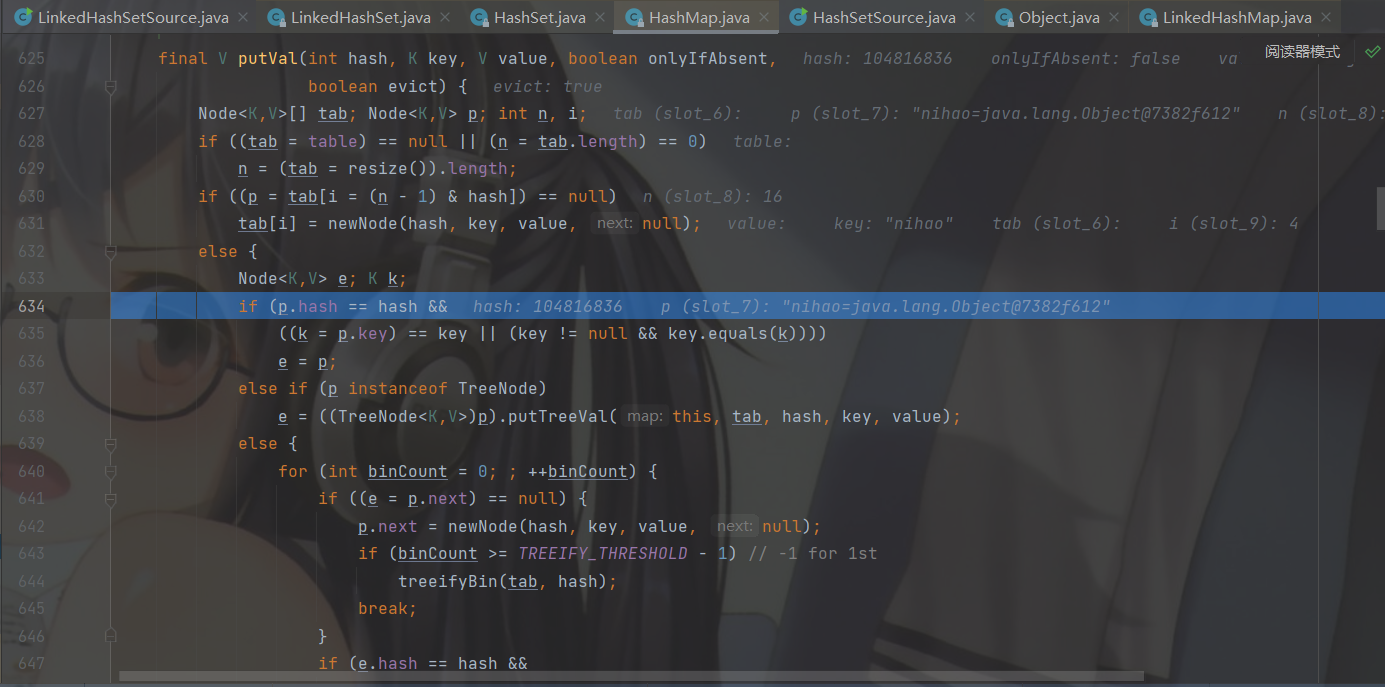
重复元素的添加,还是经典的换汤不换药,所有直接来到判断,根据hash值和数组长度计算出下标落点后,如果发现该下标已经挂载了节点的存在就比较两个节点的hash和内存地址,如果内存地址一样再调用 equals 比较存储的内容,如果条件成立将当前节点赋值给 e 最后返回 e的value(PRESENT对象),返回一个对象add方法的布尔条件就不会成立,添加失败。如果比较两个对象的条件不成立就去把新加入的节点挂载到当前数组节点的后面,再让尾指针指向新挂载的节点,这样也就添加到了对应节点,并且是双向链表的最后。
总结
提示:这里对文章进行总结:















 2710
2710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









