







JUC并发编程系列文章
http://t.csdn.cn/UgzQi
文章目录
前言
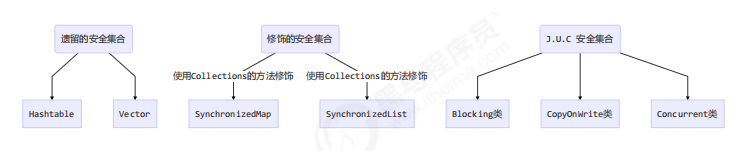
7、线程安全集合类概述



8、ConcurrentHashMap

创建文件
import lombok.extern.slf4j.Slf4j;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
@Slf4j(topic = "c.testThread31")
public class testThread31 {
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz";
public static void main(String[] args) {
int length = ALPHA.length();
int count = 200;
List<String> list = new ArrayList<>(length * count);
for (int i = 0; i < length; i++) {
char ch = ALPHA.charAt(i);
for (int j = 0; j < count; j++) {
list.add(String.valueOf(ch));
}
}
Collections.shuffle(list);
for (int i = 0; i < 26; i++) {
try (PrintWriter out = new PrintWriter(
new OutputStreamWriter(
new FileOutputStream("threadTest/" + (i+1) + ".txt")))) {
String collect = list.subList(i * count, (i + 1) * count).stream()
.collect(Collectors.joining("\n"));
out.print(collect);
} catch (IOException e) {
}
}
}
}
模版代码,模版代码中封装了多线程读取文件的代码
import lombok.extern.slf4j.Slf4j;
import java.io.*;
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.LongAdder;
import java.util.function.BiConsumer;
import java.util.function.Supplier;
import java.util.stream.Collectors;
@Slf4j(topic = "c.testThread31")
public class testThread31 {
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz";
public static void main(String[] args) {
/**
* {a=200, b=200, c=200, d=200, e=200, f=200, g=200, h=200, i=200, j=200, k=200,
* l=200, m=200, n=200, o=200, p=200, q=200, r=200, s=200, t=200, u=200, v=200, w=200, x=200, y=200, z=200}
*
* 进程已结束,退出代码为 0
*/
demo(
()-> new ConcurrentHashMap<String, LongAdder>(),
(map,words)->{
for (String word :words){
LongAdder value = map.computeIfAbsent(word, (key) -> new LongAdder());
//原子累加
value.increment();
}
}
);
// demo(
// // 创建 map 集合
// // 创建 ConcurrentHashMap 对不对?
// () -> new HashMap<String, Integer>(),
// // 进行计数
// (map, words) -> {
// for (String word : words) {
// //这里的getter和setter无法保证原子性
// //判断 key 是否已经存在
// Integer counter = map.get(word);
// //是否为空,为空计数加一,后续直接在原基础上加一
// int newValue = counter == null ? 1 : counter + 1;
// //将 map 更新
// map.put(word, newValue);
// }
// }
// );
}
private static <V> void demo(Supplier<Map<String,V>> supplier,
BiConsumer<Map<String,V>,List<String>> consumer) {
Map<String, V> counterMap = supplier.get();
List<Thread> ts = new ArrayList<>();
for (int i = 1; i <= 26; i++) {
int idx = i;
Thread thread = new Thread(() -> {
List<String> words = readFromFile(idx);
consumer.accept(counterMap, words);
});
ts.add(thread);
}
ts.forEach(t->t.start());
ts.forEach(t-> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(counterMap);
}
public static List<String> readFromFile(int i) {
ArrayList<String> words = new ArrayList<>();
try (BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream("threadTest/"+ i +".txt")))) {
while(true) {
String word = in.readLine();
if(word == null) {
break;
}
words.add(word);
}
return words;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void testTXT(){
int length = ALPHA.length();
int count = 200;
List<String> list = new ArrayList<>(length * count);
for (int i = 0; i < length; i++) {
char ch = ALPHA.charAt(i);
for (int j = 0; j < count; j++) {
list.add(String.valueOf(ch));
}
}
Collections.shuffle(list);
for (int i = 0; i < 26; i++) {
try (PrintWriter out = new PrintWriter(
new OutputStreamWriter(
new FileOutputStream("threadTest/" + (i+1) + ".txt")))) {
String collect = list.subList(i * count, (i + 1) * count).stream()
.collect(Collectors.joining("\n"));
out.print(collect);
} catch (IOException e) {
}
}
}
}
JDK 7 HashMap 并发死链
JDK 7 已经没有人用了,没必要学了

JDK 8 ConcurrentHashMap
内部属性和常用方法
内部属性
// 默认为 0
// 当初始化时, 为 -1
// 当扩容时, 为 -(1 + 扩容线程数)
// 当初始化或扩容完成后,为 下一次的扩容的阈值大小
private transient volatile int sizeCtl;
// 整个 ConcurrentHashMap 就是一个 Node[]
static class Node<K,V> implements Map.Entry<K,V> {}
// hash 表
transient volatile Node<K,V>[] table;
// 扩容时的 新 hash 表
private transient volatile Node<K,V>[] nextTable;
// 扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点
static final class ForwardingNode<K,V> extends Node<K,V> {}
// 用在 compute 以及 computeIfAbsent 时, 用来占位, 计算完成后替换为普通 Node
static final class ReservationNode<K,V> extends Node<K,V> {}
// 作为 treebin 的头节点, 存储 root 和 first
static final class TreeBin<K,V> extends Node<K,V> {}
// 作为 treebin 的节点, 存储 parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {}
常用方法
// 获取 Node[] 中第 i 个 Node
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i)
// cas 修改 Node[] 中第 i 个 Node 的值, c 为旧值, v 为新值
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v)
// 直接修改 Node[] 中第 i 个 Node 的值, v 为新值
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
构造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
分析: 可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建,如果没有往map添加元素不会正在创建相关的内存空间,懒惰初始化
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
判断传入的数据是否合法
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
判断初始容量是否大于并发度,如果小于并发度,将并发度赋值给初始容量
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
计算扩数组长度,但是需要是 2的 n 次方,所以传入的 initialCapacity,也并不会是真正的长度
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// tableSizeFor 仍然是保证计算的大小是 2^n, 即 16,32,64 ...
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
get 方法

public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// spread 方法能确保返回结果是正数
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果头结点已经是要查找的 key
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// hash 为负数表示该 bin 在扩容中或是 treebin, 这时调用 find 方法来查找,从数组的最后往前找
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 正常遍历链表, 用 equals 比较
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
put 流程
以下数组简称(table),链表简称(bin)
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 其中 spread 方法会综合高位低位, 具有更好的 hash 性
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f 是链表头节点
// fh 是链表头结点的 hash
// i 是链表在 table 中的下标
Node<K,V> f; int n, i, fh;
// 要创建 table
if (tab == null || (n = tab.length) == 0)
// 初始化 table 使用了 cas, 无需 synchronized 创建成功, 进入下一轮循环
tab = initTable();
// 要创建链表头节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 添加链表头使用了 cas, 无需 synchronized
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// 帮忙扩容
else if ((fh = f.hash) == MOVED)
// 帮忙之后, 进入下一轮循环
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 锁住链表头节点
synchronized (f) {
// 再次确认链表头节点没有被移动
if (tabAt(tab, i) == f) {
// 链表
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同的 key
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
// 更新
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 已经是最后的节点了, 新增 Node, 追加至链表尾
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// putTreeVal 会看 key 是否已经在树中, 是, 则返回对应的 TreeNode
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
// 释放链表头节点的锁
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
// 如果链表长度 >= 树化阈值(8), 进行链表转为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 增加 size 计数
addCount(1L, binCount);
return null;
}
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield();
// 尝试将 sizeCtl 设置为 -1(表示初始化 table)
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// 获得锁, 创建 table, 这时其它线程会在 while() 循环中 yield 直至 table 创建
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
// check 是之前 binCount 的个数
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if (
// 已经有了 counterCells, 向 cell 累加
(as = counterCells) != null ||
// 还没有, 向 baseCount 累加
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)
) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (
// 还没有 counterCells
as == null || (m = as.length - 1) < 0 ||
// 还没有 cell
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
// cell cas 增加计数失败
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
) {
// 创建累加单元数组和cell, 累加重试
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// 获取元素个数
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// newtable 已经创建了,帮忙扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 需要扩容,这时 newtable 未创建
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
size 计算流程

public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
// 将 baseCount 计数与所有 cell 计数累加
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}

源码分析 http://www.importnew.com/28263.html
其它实现 Cliffff Click’s high scale lib
java 7 ConcurrentHashMap: 没人用了,不写了
LinkedBlockingQueue 阻塞队列原理
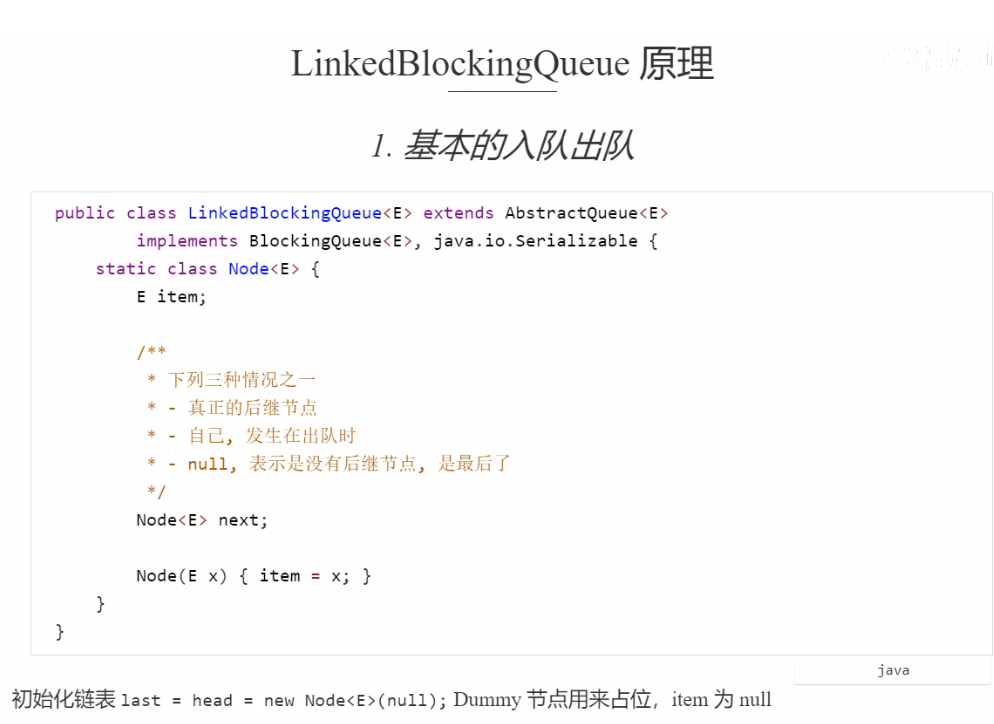

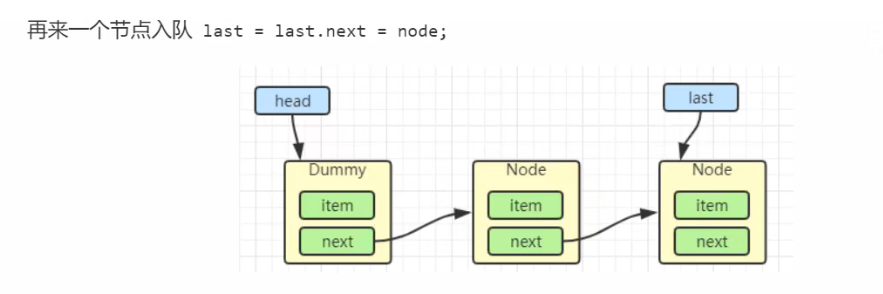

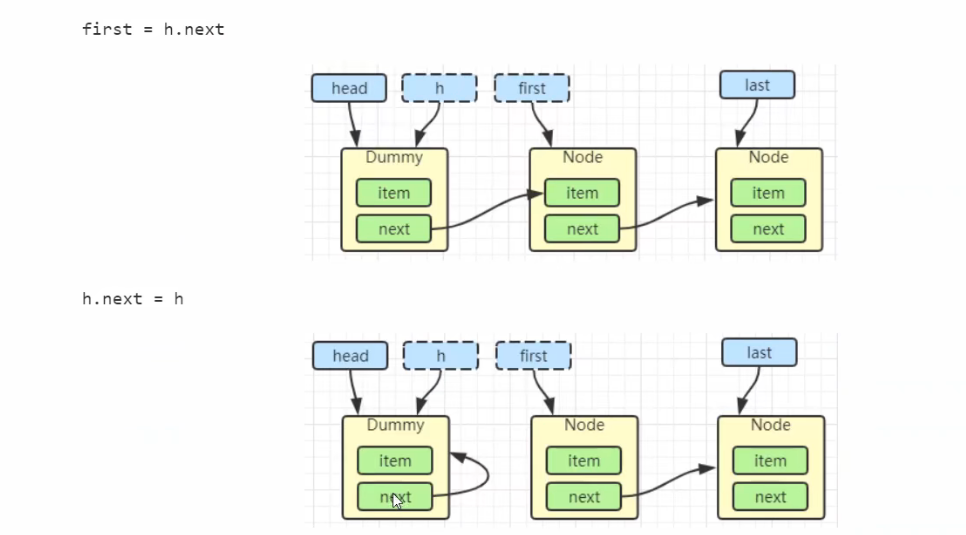
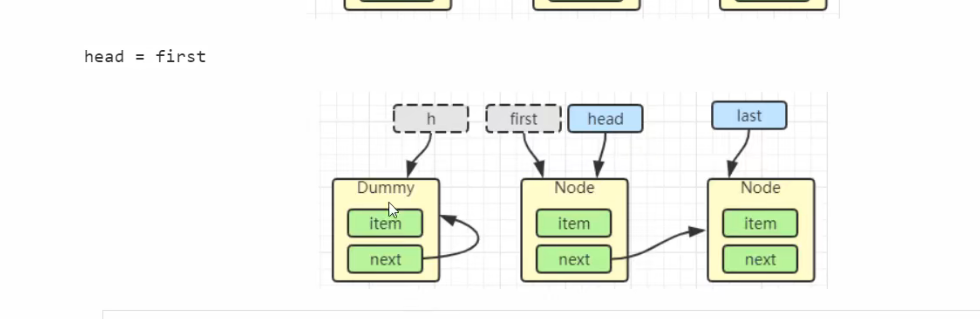
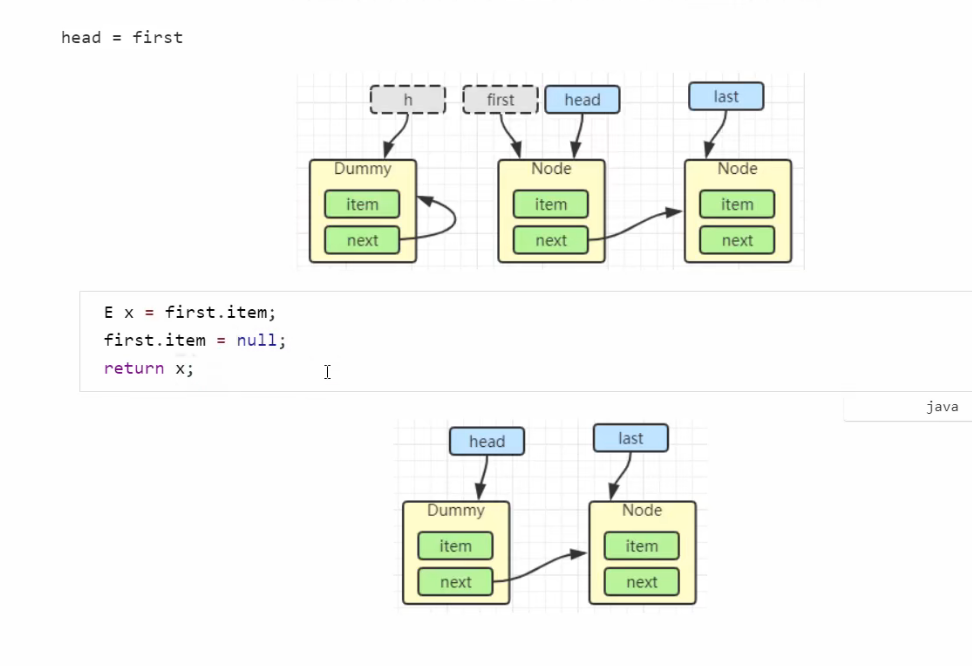
加锁分析

put 操作
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
// count 用来维护元素计数
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// 满了等待
while (count.get() == capacity) {
// 倒过来读就好: 等待 notFull
notFull.await();
}
// 有空位, 入队且计数加一
enqueue(node);
c = count.getAndIncrement();
// 除了自己 put 以外, 队列还有空位, 由自己叫醒其他 put 线程
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 如果队列中有一个元素, 叫醒 take 线程
if (c == 0)
// 这里调用的是 notEmpty.signal() 而不是 notEmpty.signalAll() 是为了减少竞争
signalNotEmpty();
}
take 操作
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 如果队列中只有一个空位时, 叫醒 put 线程
// 如果有多个线程进行出队, 第一个线程满足 c == capacity, 但后续线程 c < capacity
if (c == capacity)
// 这里调用的是 notFull.signal() 而不是 notFull.signalAll() 是为了减少竞争
signalNotFull()
return x;
}
由 put 唤醒 put 是为了避免信号不足
性能比较

ConcurrentLinkedQueue 并发队列
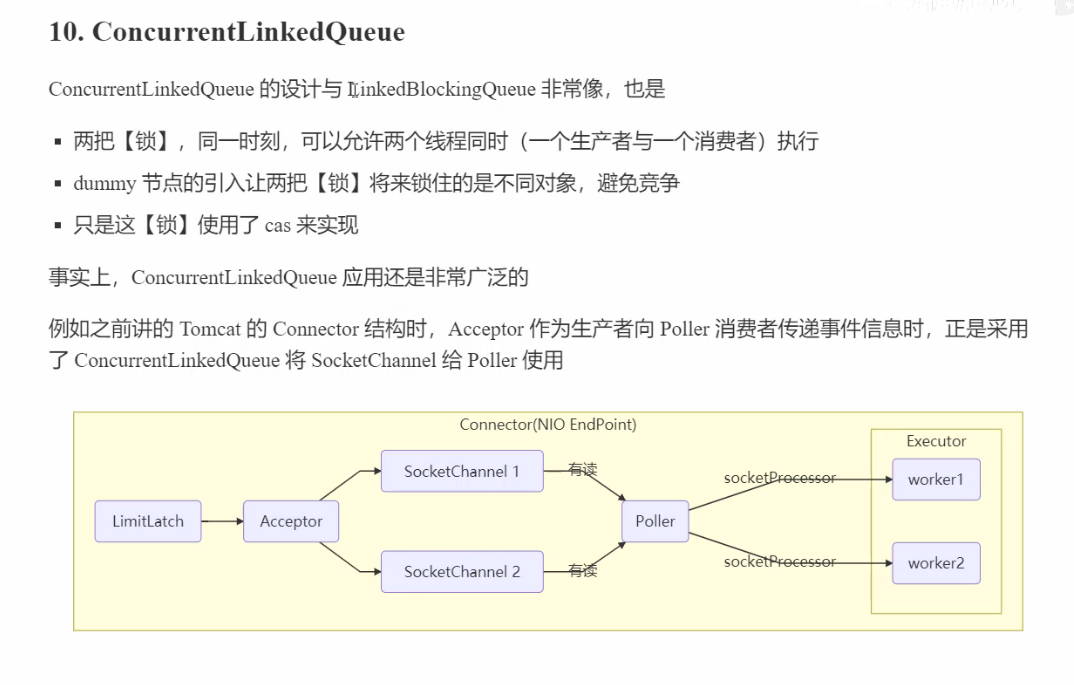
模仿 ConcurrentLinkedQueue
初始代码
package cn.itcast.concurrent.thirdpart.test;
import java.util.Collection;
import java.util.Iterator;
import java.util.Queue;
import java.util.concurrent.atomic.AtomicReference;
public class Test3 {
public static void main(String[] args) {
MyQueue<String> queue = new MyQueue<>();
queue.offer("1");
queue.offer("2");
queue.offer("3");
System.out.println(queue);
}
}
class MyQueue<E> implements Queue<E> {
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (Node<E> p = head; p != null; p = p.next.get()) {
E item = p.item;
if (item != null) {
sb.append(item).append("->");
}
}
sb.append("null");
return sb.toString();
}
@Override
public int size() {
return 0;
}
@Override
public boolean isEmpty() {
return false;
}
@Override
public boolean contains(Object o) {
return false;
}
@Override
public Iterator<E> iterator() {
return null;
}
@Override
public Object[] toArray() {
return new Object[0];
}
@Override
public <T> T[] toArray(T[] a) {
return null;
}
@Override
public boolean add(E e) {
return false;
}
@Override
public boolean remove(Object o) {
return false;
}
@Override
public boolean containsAll(Collection<?> c) {
return false;
}
@Override
public boolean addAll(Collection<? extends E> c) {
return false;
}
@Override
public boolean removeAll(Collection<?> c) {
return false;
}
@Override
public boolean retainAll(Collection<?> c) {
return false;
}
@Override
public void clear() {
}
@Override
public E remove() {
return null;
}
@Override
public E element() {
return null;
}
@Override
public E peek() {
return null;
}
public MyQueue() {
head = last = new Node<>(null, null);
}
private volatile Node<E> last;
private volatile Node<E> head;
private E dequeue() {
/*Node<E> h = head;
Node<E> first = h.next;
h.next = h;
head = first;
E x = first.item;
first.item = null;
return x;*/
return null;
}
@Override
public E poll() {
return null;
}
@Override
public boolean offer(E e) {
return true;
}
static class Node<E> {
volatile E item;
public Node(E item, Node<E> next) {
this.item = item;
this.next = new AtomicReference<>(next);
}
AtomicReference<Node<E>> next;
}
}
offer方法
public boolean offer(E e) {
Node<E> n = new Node<>(e, null);
while(true) {
// 获取尾节点
AtomicReference<Node<E>> next = last.next;
// S1: 真正尾节点的 next 是 null, cas 从 null 到新节点
if(next.compareAndSet(null, n)) {
// 这时的 last 已经是倒数第二, next 不为空了, 其它线程的 cas 肯定失败
// S2: 更新 last 为倒数第一的节点
last = n;
return true;
}
}
}
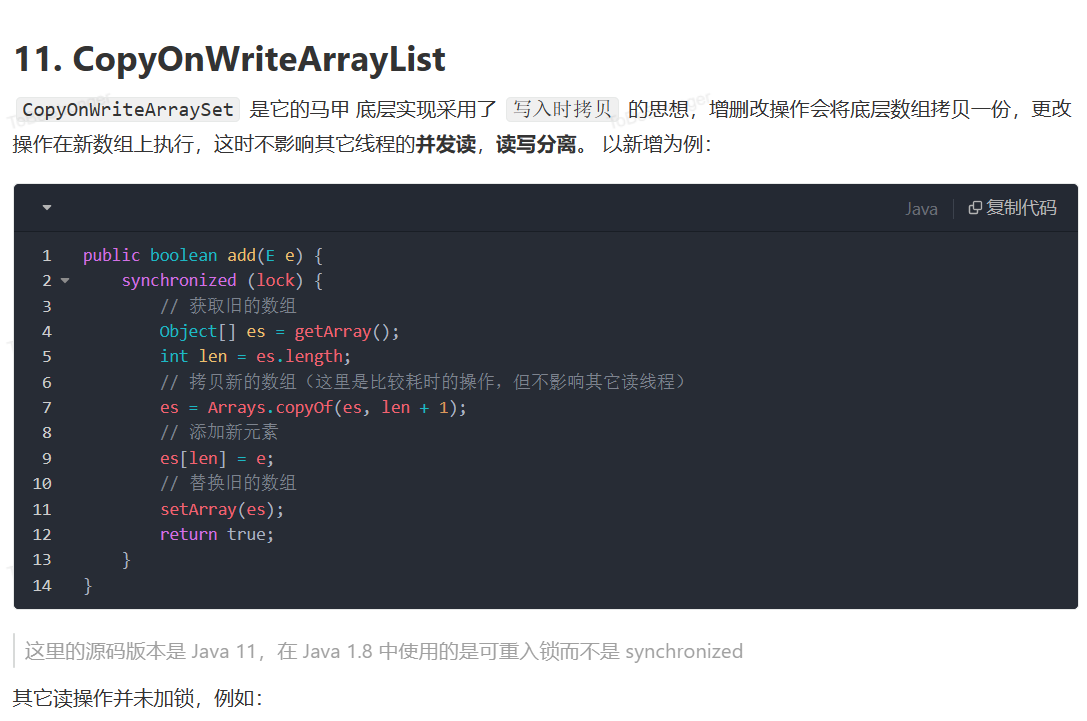
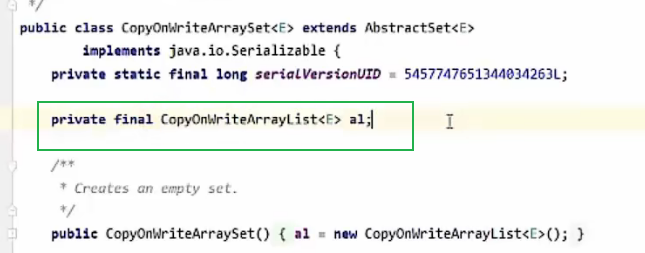
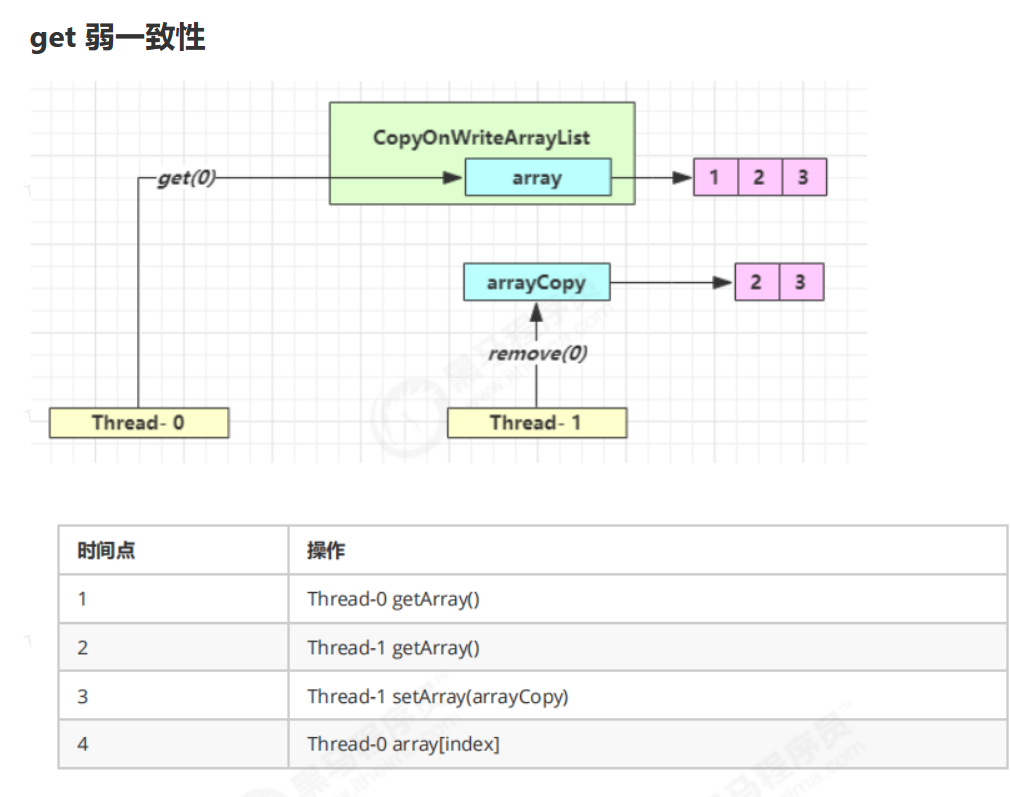
CopyOnWriteArrayList

















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









