







目录
1.进程
1.1.进程的基本概念
*课本概念:程序的一个执行实例,正在执行的程序等
*内核观点:担当分配系统资源(CPU时间,内存)的实体。
我们在实际使用计算机的场景中,操作系统会同时运行多个程序,也就是拥有多个进程,我们从操作系统的思想“先描述再组织”中可以知道,为了便于管理,就需要描述个体程序,然后用数据结构串联,这里也就是进程和程序的差别。

用人话来说:进程是 可执行程序 加上 内核数据结构(PCB)
1.2.进程控制块(PCB)
*进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
*课本上称之为PCB(process control block),Linux操作系统下的PCB是: task_struct

并且我们知道操作系统是c语言实现的,那么我们可以大致建模task_struct
// 对进程的描述
struct task_stcuct
{
// ... 标识符、状态、优先级
// ... 下一个进程的地址
// ... 进程对应代码、数据的虚拟地址
// ... 等等
};管理进程的时候对该进程没关系,而只关乎进程的信息。进程对应的PCB作为操作系统便于管理的一个个体单位。
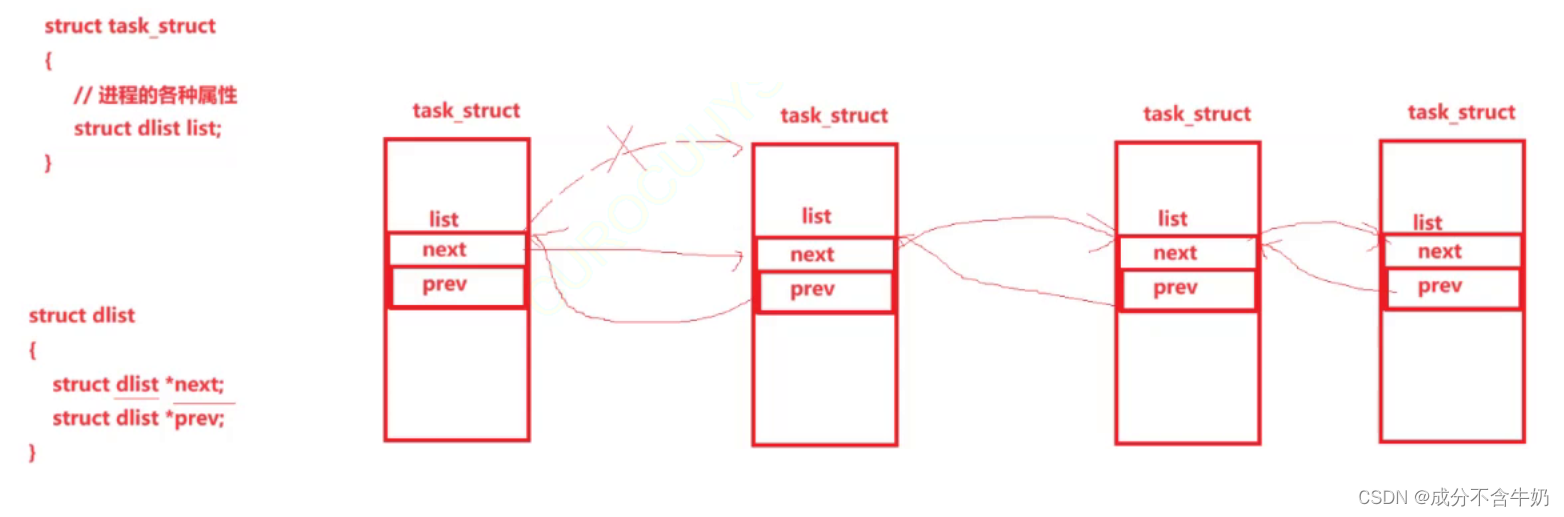
task_struct的串联
如图PCB的串联并不是直接用PCB设置内部指针来实现的,而是通过套上一个list结构体,在通过list里面的指针来进行连接,这样子会不会显得比较麻烦?但是我们想了想,如果只用内部指针,就如同一个一维的链表一样,即某个PCB只在一条链表上。实际场景中,某个PCB可能在多个链表中,甚至队列中、各种其他结构中!
那么如何找到task_struct的首地址呢?答:通过偏移量的计算来查找,对于上图就是
task_struct_current = (task_struct*)(int)&list - (int)&(task_struct*)0->list
1.3.进程与PCB
我们已经大概知道了进程与PCB,那么在实际上进程和PCB是如何配合的呢?接下来我们用一个程序的场景来描述一下。
当我们在运行多个程序时,即需要往内存中加载多个进程,就需要有多个PCB来对应各自的进程这样子能够有序的管理,并且操作系统会形成PCB链表。
那么最终我们发现CPU在运算时,直接读取PCB的信息找到进程再进行程序的运行。然后通过PCB链表进行下一个程序的运算,所以对于进程的管理最终变成了对链表的增删查改

1.4.进程的其他知识
1.4.1.进程与父进程
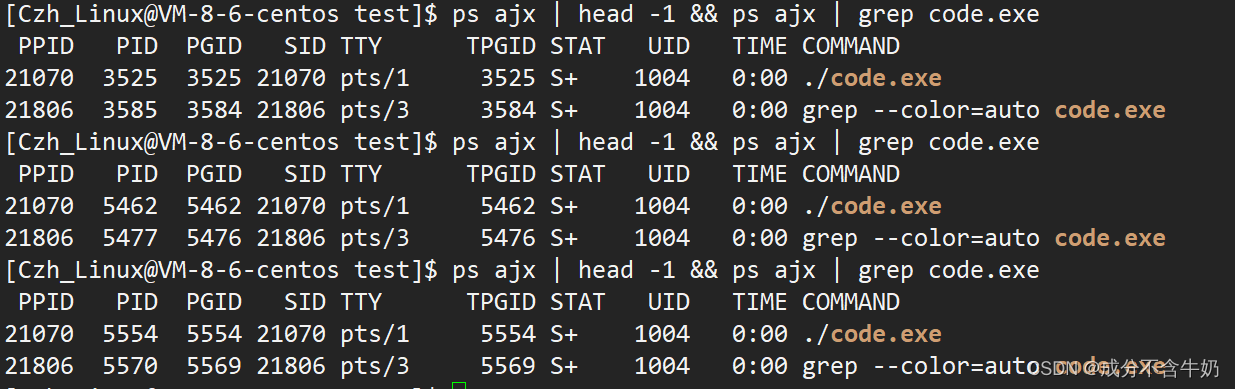
如图,我们知道PID是当前进程的代号,PPID是当前进程父进程的代号,当我们在命令行中不断地终止再启用某个进程,会发现PID会改变,PPID却不变,这是为什么呢?首先进程是动态的,所以不同时间片下进程的代号分配会不一致,但是命令行的进程的父进程是固定的,我们通过过滤可以查看进程21070下
发现这个进程是bash,即为命令行解释器,那么有bash是命令行进程的父亲

1.4.2.Linux中进程的创建方式
创建一个进程的,就是想操作系统中申请内存,保持当前进程的可执行程序和task_struct对象,并将tast_struct对象添加到进程列表中。
1.命令行中直接启动进程 ---通过bash手动创建
2.通过代码来进行进程创建 ---通过fork()函数自动创建
!!!另外启动进程,本质上是创建进程,一般是由父进程来创建。
!!! 通过系统调用创建进程---fork()函数
fork()函数作用:创造一个子进程
*fork有两个返回值,给子进程返回0,给父进程返回进程PID
*父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
int main()
{
int ret = fork();
while(1)
{
if(ret < 0)
{
perror("fork");
return 1;
}
else if(ret == 0)
{ //child
printf("I am child, pid: %d, ppid: %d, ret: %d\n", getpid(), getppid(), ret);
}
else
{ //father
printf("I am father, pid: %d, ppid: %d ret: %d\n", getpid(), getppid(),ret);
}
sleep(1);
}
sleep(1);
return 0;
}这里当我们打印分别打印父子进程的&id会有一个地址对应两个值,这里我们在后续的进程地址空间会解释,就不在这用大篇幅说了!
这份代码体现了fork()函数能够创建两个进程,通过先创好的父进程,再创建子进程
我们在通过Linux的指令查看进程信息,发现一个fork()确实可以实现两个进程。
总结:
*子进程可以有多个,父进程只能有一个!父进程通过子进程标识来控制子进程。
*fork()函数前的代码由父进程执行,fork()后的代码由父子进程各自执行,也就是实现分流!

这时我们开始思考为什么要创建子进程?试想一个场景,当我们在看视频时本质上就是加载数据,也就是需要边下载边播放,那么这个就是两部分操作独立进行,而通过fork()函数后,父子进程独立执行分流向各自的代码块进行操作。那么不就可以实现我们生活中的一些场景吗?
再结合我们进程会有相应的PCB,那么创建子进程后会以父进程为模版,为子进程创建PCB,并且和父进程共享代码和数据(当数据修改时,需要进行写时拷贝,各自拥有一份,防止破坏进程之间的独立性),并且在不同的时间片各自被CPU调度,继续往后执行,这里也体现了进程的独立性。
因为fork()中拥有两个进程,所以最后也return两个值,即fork()拥有两个返回值

1.4.3.进程详细信息查看
当我们运行进程时,通过PID我们可以找到该进程的临时文件夹,可以看到里面的信息
这里我们可以看到进程对应的exe文件的位置,就在跟code所在的文件夹test中,也就是在cwd中。那么cwd是什么呢?cwd是当前工作目录,因为进程启动时会找到当前工作目录,默认情况下的路径。这时我们联想到当初C语言学习中,文件操作相关函数,当没有文件时,fopen()会创建一个文件,恰好在当前工作目录下。
当我们杀掉这个进程时,PID为13954对应的临时文件夹就被释放了



讲到这里对于进程的概念我们也了解了差不多了,
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









