1 集成算法
- 集成学习 非常流行的机器学习算法,通过在数据上构建多个模型,集成所有模型的结果。
- 多个模型集成成为的模型叫做集成评估器,其中的每个模型叫做基评估器。通常来说,有三类集成算法:袋装法(Bagging)、提升法(Boosting)、stacking。
- Bagging:构建多个独立平行的评估器,对其预测进行平均或多数表决原则来决定结果。
- Boosting:基评估器是相关的,按顺序一一建造的。
2 RandomForestClassifier 随机森林
- n_estimators:
森林中树木的数量。
越大,模型效果往往最好,需要的计算量内存也越大,达到一定程度之后,随机森林的精确性往往不再上升或者停止波动。
from sklearn.tree import RandomForestClassifier
rfc = RandomForestClassfier()
rfc = rfc.fit(X_train, Y_train)
result = rfc.score(X_test,Y_test)
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
wine=load_wine()
"""
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target, test_size = 0.3)
#单个决策树
clf = DecisionTreeClassifier(random_state = 0) # random_state 随机种子 确定固定值
clf = clf.fit(X_train,Y_train)
score_c = clf.score(X_test,Y_test)
#随机森林
rfc = RandomForestClassifier(random_state = 0)
rfc = rfc.fit(X_train,Y_train)
score_r = rfc.score(X_test,Y_test)
"""
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc, wine.data, wine.target, cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf, wine.data, wine.target, cv=10).mean()
clf_l.append(clf_s)
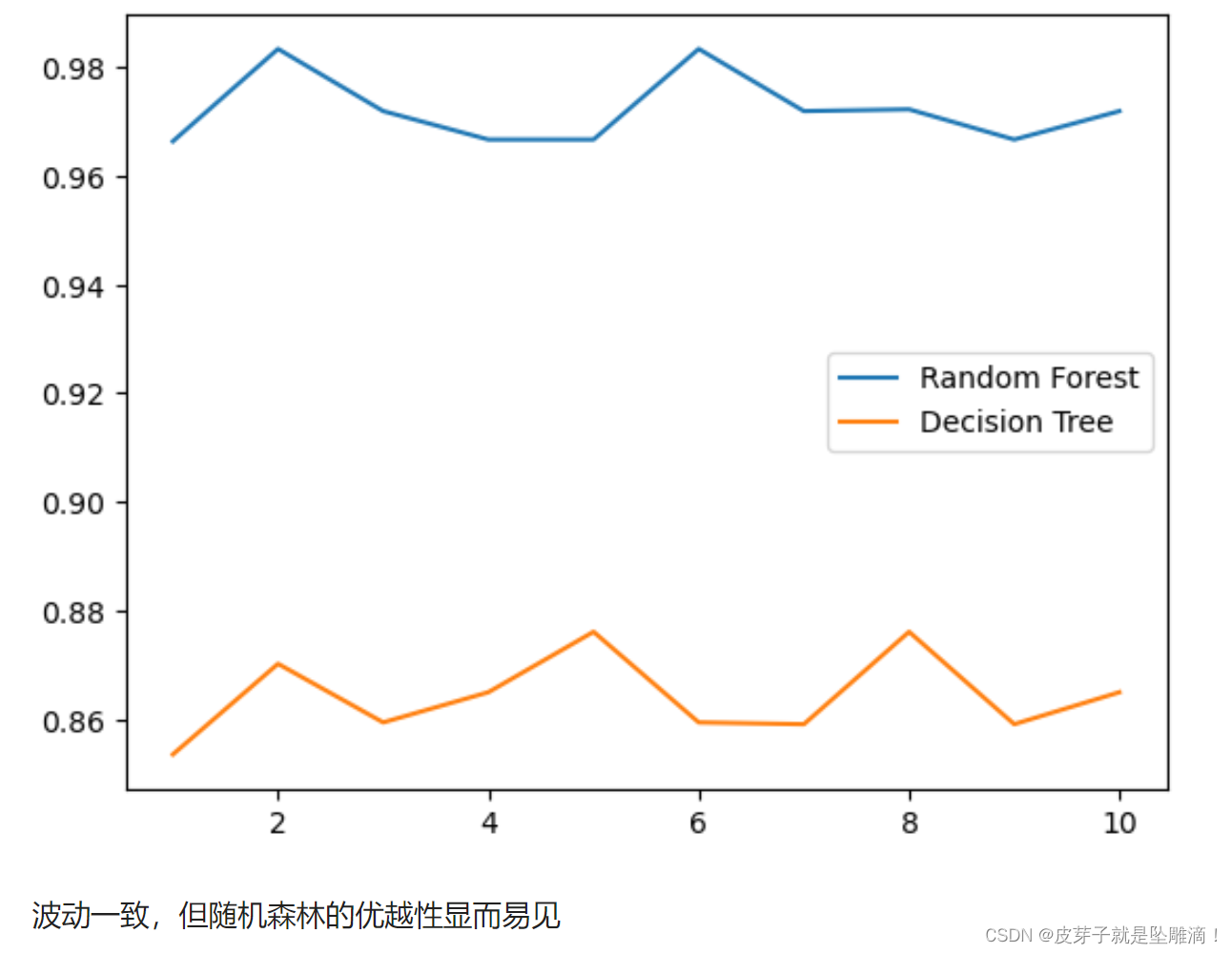
plt.plot(range(1,11), rfc_l, label = "Random Forest")
plt.plot(range(1,11), clf_l, label = "Decision Tree")
plt.legend()
plt.show()
.estimators
.oob_score_
- 袋外得分。对训练集放回抽样不断组成新的训练集时总有一些数据从来没有被随机挑选到,称为“袋外数据”,sklearn可以用他们来测试模型,测试的结果就用“
obb_score_”来导出
.feature_importance_
apply, fit, predict, score 以及 predict_proba 五个接口
- apply返回每个测试样本所在的叶子节点的索引;
- predict返回每个测试样本的分类/回归结果;
- predict_proba返回每个测试样本对应的被分到每一类标签的概率,标签有几个分类就返回几个概率。





















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









