






🌟更多文章推荐:
邂逅蓝耘元生代:ComfyUI 工作流与服务器虚拟化的诗意交织-CSDN博客
探秘蓝耘元生代:ComfyUI 工作流创建与网络安全的奇妙羁绊-CSDN博客
工作流 x 深度学习:揭秘蓝耘元生代如何用 ComfyUI 玩转 AI 开发-CSDN博客
探索元生代:ComfyUI 工作流与计算机视觉的奇妙邂逅-CSDN博客
目录
一、初遇 “拦路虎”:啥是 MaaS 平台和服务器虚拟化?
前言
家人们谁懂啊!本来以为自己学了三年计算机,API 调用、服务器部署这些都算是 “手拿把掐” 了,结果上学期搞课程设计的时候,碰到蓝耘元生代 MaaS 平台和服务器虚拟化,直接给我整不会了!在实验室熬了好几个大夜,掉了一大把头发,总算是把这俩玩意儿摸透了。今天就把我的 “血泪经验” 分享出来,全是干货,手把手教你玩转蓝耘元生代 MaaS 平台和服务器虚拟化!
一、初遇 “拦路虎”:啥是 MaaS 平台和服务器虚拟化?
刚开始看到课程设计题目,要求基于蓝耘元生代 MaaS 平台开发应用,还要结合服务器虚拟化技术优化部署,我直接懵圈。MaaS 平台?服务器虚拟化?这都是啥?赶紧翻书、查资料,总算是弄明白了个大概。
MaaS,也就是 “模型即服务”,蓝耘元生代 MaaS 平台就像一个超大型的 AI “武器库”,里面有各种各样的人工智能模型,什么自然语言处理模型、图像识别模型都有。我们不用自己从零开始搭建这些复杂的模型,直接调用平台的 API,就像从武器库里拿武器一样方便,能快速开发出各种智能应用。
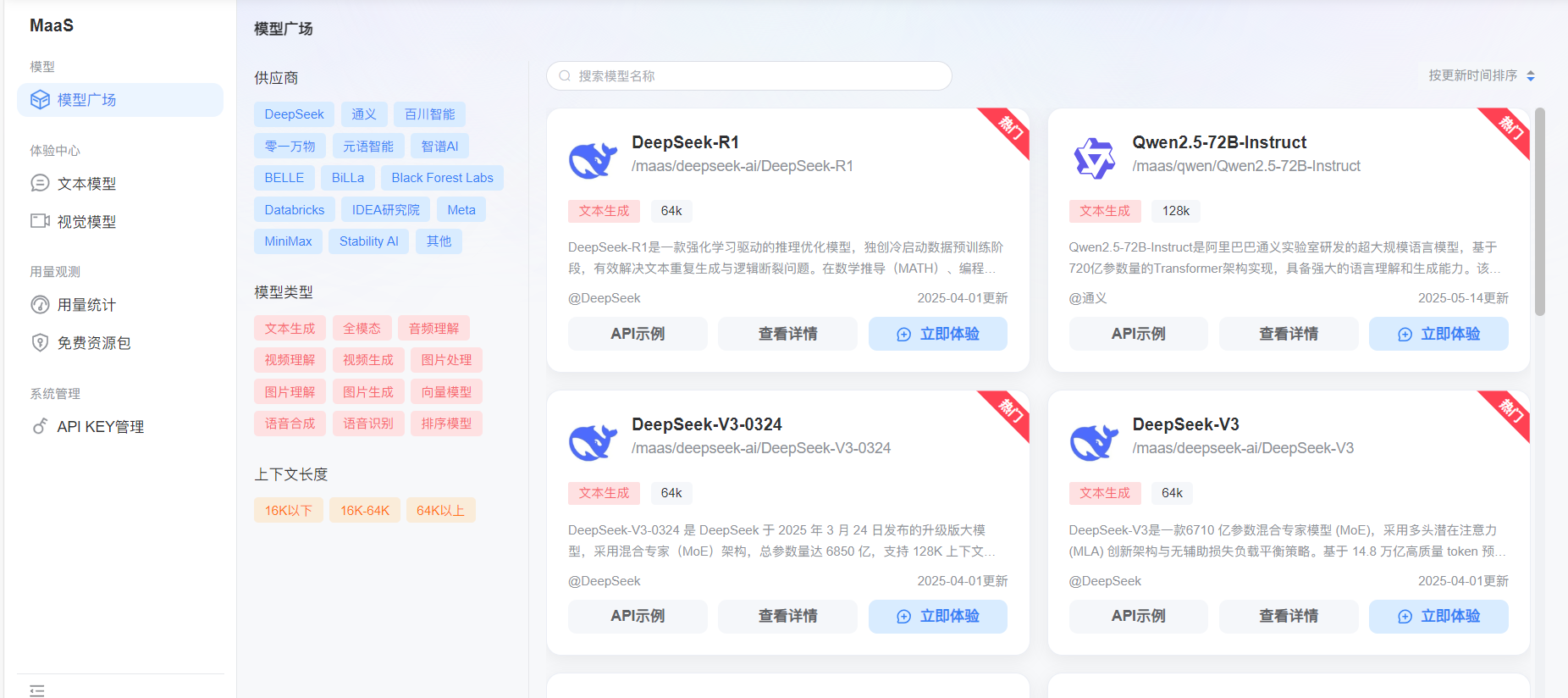
服务器虚拟化呢,简单来说,就是把一台物理服务器变成好多台 “虚拟” 的服务器。就好比你有一套大房子,然后用墙把它隔成一个个小房间,每个小房间都能独立使用,互不干扰。这样可以充分利用服务器的资源,提高利用率,还能方便地进行管理和维护。
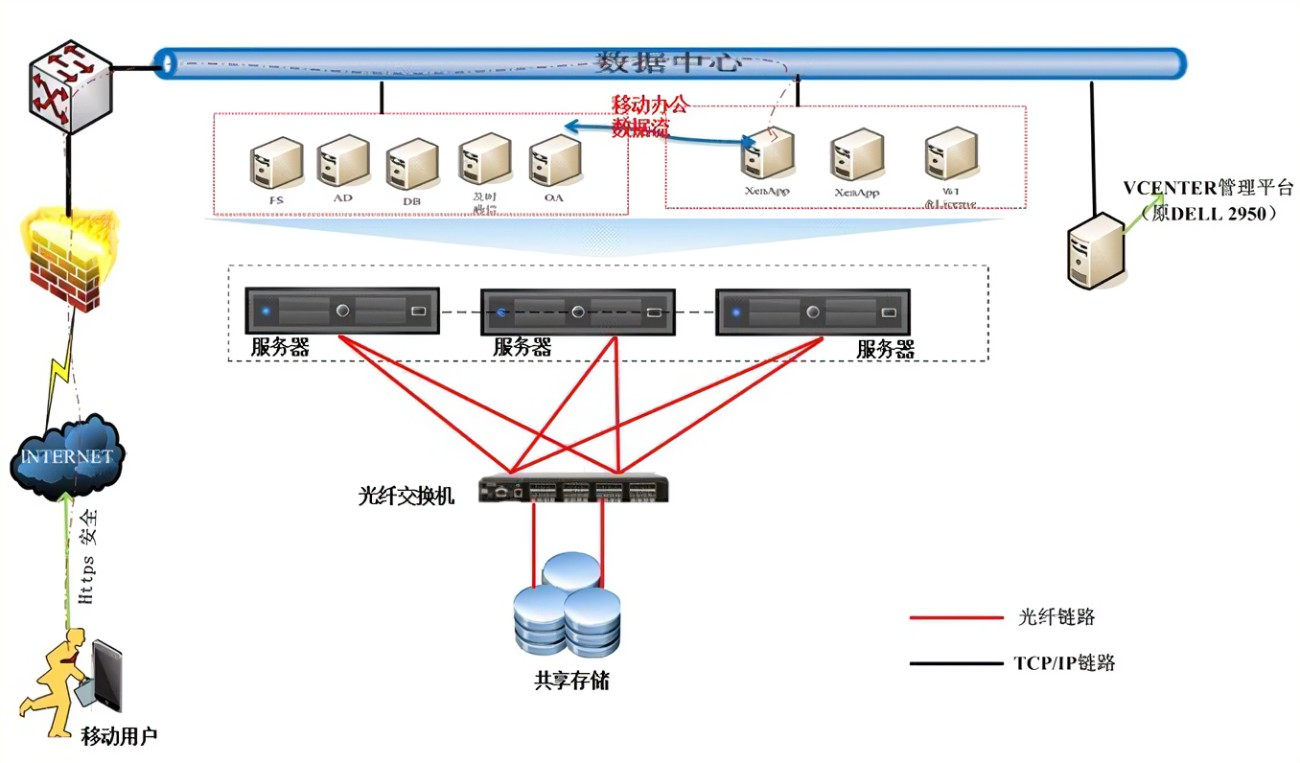
虽然知道了概念,但真正要把这俩结合起来用,那可真是困难重重。
二、初探蓝耘元生代 MaaS 平台:从 “抓瞎” 到入门
平台注册与 API 密钥获取
要想用蓝耘元生代 MaaS 平台,第一步当然是注册账号。打开平台官网,填好各种信息,一顿操作猛如虎,总算是注册成功了。然后就是获取 API 密钥,这玩意儿就相当于进入平台 API 世界的 “钥匙”,没有它,啥都干不了。
登录与注册:打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。
在平台的开发者中心,找到 API 密钥管理页面,点击生成密钥,就拿到了属于自己的 “钥匙”。不过这里要注意,密钥一定要保管好,就像银行卡密码一样,要是泄露了,别人可能就会乱用你的 API 调用权限,产生一堆费用不说,还可能造成数据泄露。
第一个 API 调用:迈出艰难的第一步
拿到密钥后,我迫不及待地想试试调用 API。按照文档示例,我打算先调用一个简单的文本分类 API。文档上的代码示例看着挺简单,用 Python 写的,我直接复制到自己的代码编辑器里:
import requests
url = "https://api.lanyun.com/nlp/text-classification"
headers = {
"Authorization": "Bearer 你的API密钥",
"Content-Type": "application/json"
}
data = {
"text": "这款手机拍照效果很好",
"model": "default_text_classification_model"
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
result = response.json()
print("分类结果:", result)
else:
print("API调用失败:", response.text)结果运行的时候,直接报错!说我鉴权失败,我反复检查 API 密钥,确认没填错啊,折腾了好久才发现,原来是请求头里的Authorization字段格式写错了,正确的格式应该是Bearer (注意 Bearer 后面有个空格)加上 API 密钥,我少加了那个空格,怪不得一直鉴权失败。改过来之后,终于成功得到了分类结果,当时别提多激动了,感觉自己迈出了一大步!
部分请求体示例:
| 参数名称 | 类型 | 是否必填 | 默认值 | 描述 | 示例值 |
|---|---|---|---|---|---|
| model | String | 是 | - | 本次请求使用模型的API调用模型名,即Model ID | /maas/deepseek-ai/DeepSeek-R1 |
| messages | Array of MessageParam | 是 | - | 由目前为止的对话组成的消息列表 当指定了 tools 参数以使用模型的 function call 能力时,请确保 messages 列表内的消息满足如下要求:如果 message 列表中前文出现了带有 n 个 tool_calls 的 Assistant Message,则后文必须有连续 n 个分别和每个 tool_call_id 相对应的 Tool Message,来回应 tool_calls 的信息要求 | - |
| stream | Boolean | 否 | FALSE | 响应内容是否流式返回false:模型生成完所有内容后一次性返回结果true:按 SSE 协议逐块返回模型生成内容,并以一条 data: [DONE] 消息结束 | FALSE |
| stream_options | Object of StreamOptionsParam | 否 | - | 流式响应的选项。仅当 stream: true 时可以设置 stream_options 参数。 | - |
| max_tokens | Integer | 否 | 4096 | 注意模型回复最大长度(单位 token),取值范围各个模型不同,详细见支持的大模型。输入 token 和输出 token 的总长度还受模型的上下文长度限制。 | 4096 |
| stop | String or Array | 否 | - | 模型遇到 stop 字段所指定的字符串时将停止继续生成,这个词语本身不会输出。最多支持 4 个字符串。 | ["你好", "天气"] |
| frequency_penalty | Float | 否 | 0 | 频率惩罚系数。如果值为正,会根据新 token 在文本中的出现频率对其进行惩罚,从而降低模型逐字重复的可能性。取值范围为 [-2.0, 2.0]。 | 1 |
| presence_penalty | Float | 否 | 0 | 存在惩罚系数。如果值为正,会根据新 token 到目前为止是否出现在文本中对其进行惩罚,从而增加模型谈论新主题的可能性。取值范围为 [-2.0, 2.0]。 | 1 |
深入探索:模型调用与参数调整
成功调用一次 API 后,我开始尝试调用更多不同类型的模型。比如调用图像识别模型,识别图片里的物体。这时候又遇到了新问题,文档里虽然有代码示例,但模型的参数怎么调才能得到更好的效果,却没说太清楚。
就拿图像识别模型的confidence_threshold(置信度阈值)参数来说,这个参数决定了模型认为识别结果可靠的程度。我一开始用默认值,结果识别出来一堆不靠谱的结果,把小猫认成小狗的情况都有。后来我就自己做实验,把这个参数从 0.5 调到 0.6、0.7,一点点试,观察识别结果的变化。经过好多次尝试,终于找到了一个比较合适的值,识别准确率提高了不少。
三、服务器虚拟化:搭建属于自己的 “虚拟王国”
选择虚拟化技术:Hyper-V 还是 VMware?
了解完蓝耘元生代 MaaS 平台,接下来就要研究服务器虚拟化了。市面上有好多虚拟化技术,像 Windows 自带的 Hyper-V,还有 VMware Workstation,选哪个好呢?我在网上查了好多资料,还在技术论坛上问学长学姐。
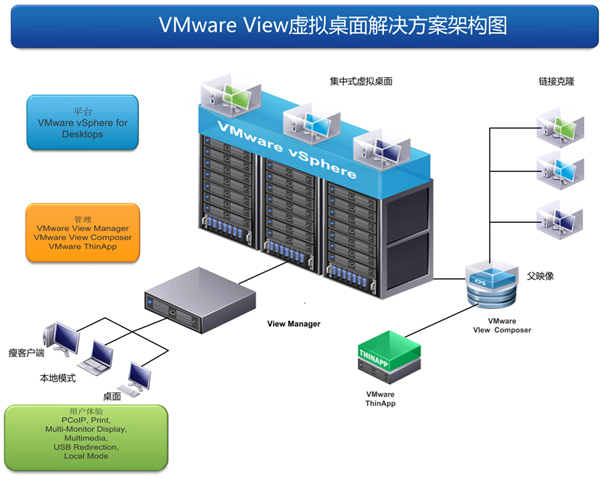
Hyper-V 是 Windows 系统原生的虚拟化技术,和 Windows 系统兼容性好,占用资源相对较少,操作也比较简单,适合初学者。VMware Workstation 功能更强大,支持的操作系统种类更多,有很多高级的管理功能,但配置相对复杂一些。

考虑到我只是做课程设计,对功能要求不是特别高,而且我用的是 Windows 系统,最后决定选择 Hyper-V。
安装与配置 Hyper-V:踩坑无数
在 Windows 系统里启用 Hyper-V 还算比较顺利,在控制面板的 “程序和功能” 里,找到 “Hyper-V” 选项,勾选启用,然后重启电脑就安装好了。
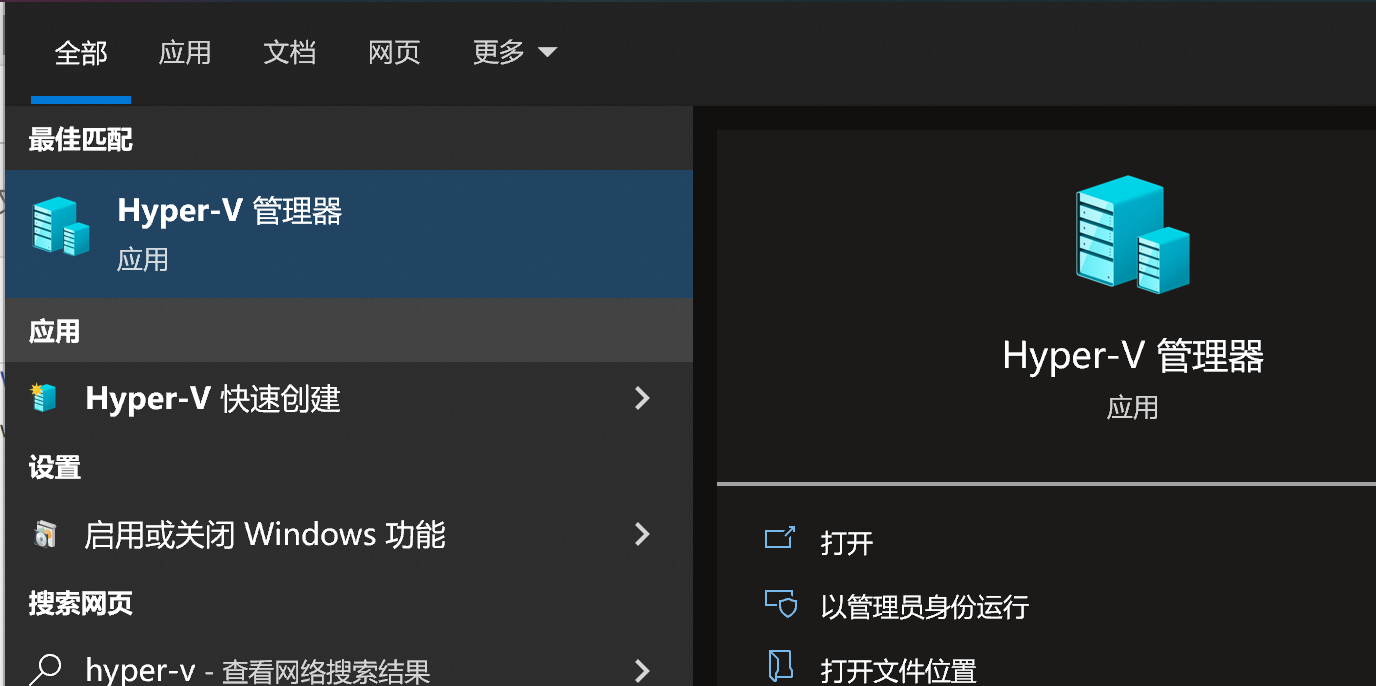
但是创建虚拟机的时候,问题就来了。一开始,我按照网上的教程创建虚拟机,分配内存和硬盘空间,结果创建完之后,虚拟机根本启动不了,提示各种错误。我仔细检查发现,原来是内存分配不合理,分配的内存太小,虚拟机根本跑不起来。还有硬盘空间,如果分配得过小,后面安装操作系统和部署应用的时候就会空间不足。
经过多次调整,我终于成功创建了一个能正常启动的虚拟机。接下来就是在虚拟机里安装操作系统,我选择了比较常用的 Ubuntu 系统。安装过程也不是一帆风顺,在选择安装源的时候,因为网络问题,一直下载不了安装包。后来我换成了国内的镜像源,才顺利完成了安装。
在虚拟机中部署应用:从 “崩溃” 到 “淡定”
虚拟机和操作系统都搞定了,接下来就是在虚拟机里部署基于蓝耘元生代 MaaS 平台开发的应用。我先在虚拟机里安装了 Python 环境,然后把之前写好的调用 MaaS 平台 API 的代码传进去。
结果运行代码的时候,又报错了!说连接不上 MaaS 平台的 API 地址。我一开始以为是代码问题,反复检查了好久,后来才发现,是虚拟机的网络配置有问题。虚拟机默认的网络模式是 “专用网络”,这种模式下虚拟机和外部网络是隔离的,所以连不上 API 地址。我把网络模式改成 “桥接模式”,让虚拟机和物理机处于同一个网络环境,这才解决了网络连接问题。
还有一次,我在虚拟机里部署了一个调用 MaaS 平台图像识别模型的应用,结果运行起来特别卡。我查看虚拟机的资源使用情况,发现 CPU 和内存占用都很高。原来是我给虚拟机分配的资源太少了,根本不够运行这个应用。我重新调整了虚拟机的资源分配,给它多分配了一些内存和 CPU 核心,应用运行就流畅多了。
四、当 MaaS 平台遇上服务器虚拟化:奇妙的化学反应
资源优化:1 + 1 > 2 的效果
把基于蓝耘元生代 MaaS 平台开发的应用部署在虚拟化的服务器上,最大的好处就是资源优化。以前如果直接在物理服务器上部署应用,要是遇到访问量突然增大,或者应用对资源需求较高的情况,很容易出现资源不足的问题。而且不同的应用之间还可能会互相干扰,一个应用占用资源过多,就会影响其他应用的正常运行。
但是用了服务器虚拟化之后,就可以根据每个应用的实际需求,灵活地分配资源。比如我有一个调用 MaaS 平台自然语言处理模型的智能客服应用,和一个调用图像识别模型的图片处理应用。我可以给智能客服应用分配相对较少的内存和 CPU 资源,因为它平时的资源需求不是特别高;而给图片处理应用分配更多的资源,因为它处理图片的时候对计算能力要求比较高。这样一来,两个应用都能稳定运行,资源利用率也大大提高了,真正实现了 1 + 1 > 2 的效果。
多环境部署:开发、测试、生产互不干扰

服务器虚拟化还有一个超实用的功能,就是方便进行多环境部署。在开发基于 MaaS 平台的应用时,我们通常需要有开发环境、测试环境和生产环境。
在开发环境里,我可以随意地修改代码、测试新功能,不用担心会影响到正式的应用。在测试环境里,我可以模拟各种真实的使用场景,对应用进行全面的测试,确保应用的稳定性和准确性。而生产环境就是正式对外提供服务的环境了。
通过服务器虚拟化,我可以创建多个虚拟机,分别作为开发环境、测试环境和生产环境。每个环境都是独立的,互不干扰。比如我在开发环境里对调用 MaaS 平台 API 的代码进行了修改,想测试一下效果,直接在开发环境的虚拟机里运行测试就好了,不会影响到生产环境里正在运行的正式应用。而且如果某个环境出现了问题,也可以快速地进行恢复和重建,大大提高了开发和运维的效率。
MaaS平台与虚拟化的完美结合
蓝耘元生代MaaS平台最酷的地方在于,它把虚拟化技术对用户完全隐藏了。作为使用者,我们根本不需要关心底层是KVM还是Docker,只需要专注于模型训练和推理。但从技术角度来看,这种抽象背后其实做了大量工作。
我特别研究了他们的资源调度算法,发现他们实现了一种动态资源分配机制。当你的模型需要更多计算资源时,平台会自动在后台启动更多虚拟机实例,等计算完成后再优雅地释放资源。这种按需分配的方式既高效又节省成本。
# 模拟动态资源分配的简化代码
class ResourceScheduler:
def __init__(self):
self.active_vms = []
self.max_vms = 10
def request_resources(self, task):
required_vms = ceil(task.complexity / 10)
available = self.max_vms - len(self.active_vms)
if required_vms > available:
raise Exception("资源不足")
new_vms = [VM() for _ in range(required_vms)]
self.active_vms.extend(new_vms)
try:
result = task.run_on_vms(new_vms)
return result
finally:
for vm in new_vms:
vm.release()
self.active_vms = [vm for vm in self.active_vms if not vm.released]上面这个简化版的资源调度器类展示了大致的逻辑。虽然真实平台的实现要复杂得多,但核心思想是一样的:按需分配,及时释放。
代码示例:在虚拟化环境中调用 MaaS 平台 API
下面给大家分享一段在虚拟机环境中调用蓝耘元生代 MaaS 平台 API 的完整代码,以及相关的配置过程。
首先,确保虚拟机已经安装好了 Python 环境,并且安装了requests库(用于发送 HTTP 请求)。如果没有安装,可以使用以下命令安装:
pip install requests然后,创建一个 Python 脚本,比如maas_api_call.py,代码如下:
import requests
import json
# MaaS平台API地址
url = "https://api.lanyun.com/nlp/text-classification"
# API密钥,记得替换成你自己的密钥
headers = {
"Authorization": "Bearer 你的API密钥",
"Content-Type": "application/json"
}
data = {
"text": "这家餐厅的菜品味道很棒",
"model": "default_text_classification_model"
}
try:
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
result = response.json()
print("分类结果:", result)
else:
print("API调用失败,状态码:", response.status_code)
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print("请求发生异常:", e)在虚拟机中运行这个脚本,就可以调用 MaaS 平台的文本分类 API 了。如果遇到问题,可以按照前面提到的方法,检查网络配置、API 密钥等是否正确。
五、实战项目:基于 MaaS 平台和虚拟化的智能客服系统
项目需求分析
课程设计的最终目标是开发一个基于蓝耘元生代 MaaS 平台和服务器虚拟化的智能客服系统。这个智能客服系统要能够回答用户关于产品的各种问题,比如产品功能、使用方法、售后服务等。
为了实现这个目标,我们需要调用 MaaS 平台的自然语言处理模型,对用户的问题进行理解和分析,然后从知识库中找到对应的答案返回给用户。同时,为了保证系统的稳定性和可扩展性,我们要利用服务器虚拟化技术,合理分配资源,搭建开发、测试和生产环境。
知识库搭建
在搭建知识库之前,需要先收集和整理产品相关的信息,包括产品说明书、常见问题解答等。然后对这些信息进行处理,比如去除重复内容、规范格式等。
我用 Python 写了一个简单的脚本,用于读取和处理文本文件,将其整理成适合存入知识库的格式:
def process_text_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
# 去除换行符和多余空格
text = text.replace('\n', '').replace('\r', '').strip()
# 这里可以添加更多的处理逻辑,比如分割成问题和答案
return text
file_path = "product_faq.txt"
processed_text = process_text_file(file_path)
print(processed_text)整理好数据后,就可以通过蓝耘元生代 MaaS 平台提供的 API,将数据存入知识库了。具体的 API 调用方法和前面介绍的类似,这里就不再赘述了。
智能客服核心代码实现
智能客服的核心功能就是接收用户的问题,调用 MaaS 平台的自然语言处理模型进行分析,然后从知识库中查找答案并返回。下面是智能客服的核心代码:
import requests
import json
def get_answer(question):
# 调用MaaS平台的文本理解API,对问题进行分析
nlp_url = "https://api.lanyun.com/nlp/text-understanding"
nlp_headers = {
"Authorization": "Bearer 你的API密钥",
"Content-Type": "application/json"
}
nlp_data = {
"text": question,
"model": "default_text_understanding_model"
}
nlp_response = requests.post(nlp_url, headers=nlp_headers, data=json.dumps(nlp_data))
if nlp_response.status_code == 200:
analyzed_result = nlp_response.json()
# 根据分析结果,在知识库中查找答案
kb_url = "https://api.lanyun.com/knowledgebase/search"
kb_headers = {
"Authorization": "Bearer 你的API密钥",
"Content-Type": "application/json"
}
kb_data = {
"query": analyzed_result["keywords"], # 假设提取出关键词用于查询
"limit": 1
}
kb_response = requests.post(kb_url, headers=kb_headers, data=json.dumps(kb_data))
if kb_response.status_code == 200:
kb_result = kb_response.json()
if kb_result["data"]:
return kb_result["data"][0]["answer"]
return "很抱歉,没有找到相关答案"
# 测试
question = "产品的保修期是多久?"
answer = get_answer(question)
print(answer)在虚拟化环境中部署项目
把智能客服系统的代码开发好之后,就要部署到虚拟化的服务器上了。我在虚拟机里安装了 Web 服务器软件,比如 Nginx,用于接收用户的请求,并将请求转发给智能客服的后端代码。
配置 Nginx 的过程也挺复杂的,需要修改配置文件,指定服务器的端口、请求转发规则等。比如,我在 Nginx 的配置文件中添加了以下内容,将 80 端口的请求转发到后端的 Python 应用:
server {
listen 80;
server_name your_server_name;
location / {
proxy_pass http://127.0.0.1:8000; # 假设后端应用运行在8000端口
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}配置好 Nginx 后,启动 Nginx 服务,然后启动智能客服的后端 Python 应用,这样智能客服系统就可以在虚拟化环境中正常运行了。
六、总结:痛并快乐着的学习之旅
回顾这段学习和实践的过程,真的是充满了挑战和困难。从一开始对蓝耘元生代 MaaS 平台和服务器虚拟化一无所知,到最后成功开发出智能客服系统,每一步都走得不容易。
在这个过程中,我遇到了各种各样的问题,有 API 调用失败的无奈,有服务器配置错误的崩溃,也有代码调试不通过的抓狂。但是每次克服一个问题,都让我感觉自己又成长了不少。
通过这次实践,我不仅学会了如何使用蓝耘元生代 MaaS 平台开发智能应用,掌握了服务器虚拟化技术的安装、配置和应用部署,更重要的是,我锻炼了解决实际问题的能力,对计算机技术的应用有了更深刻的理解。
如果你也在学习这方面的知识,或者正在做类似的项目,希望我的经验能对你有所帮助。遇到问题不要怕,多查资料、多尝试,相信你也能成功!要是你在实践过程中有什么新发现,欢迎在评论区交流,咱们一起把这些技术玩得更溜!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











