







架构篇
1.采集项目和数据仓库项目的区别
采集项目和数据仓库项目是企业中数据管理平台中的两个核心模块,两者具有独立性。
功能上,采集项目以数据的采集、传输为主,数仓项目以数据的计算为主,同时也能存储数据。
技术上,采集项目:flume、kafka、datax、maxwell,数仓项目:mysql、HDFS、Spark
2.数据库和数据仓库概念区分
名称上,数据库:database(基础、核心的数据)数据仓库:data warehouse
数据来源上,数据库:企业中基础核心的业务数据 数据仓库:数据库中的数据
数据存储上,数据库:核心作用就是查找业务数据(行式存储、索引、不能存储海量数据)数据太多查询性能下降 数据仓库:核心作用就是统计分析(列示存储、存储海量数据)数据量够多角度够多统计分析才准确
数据价值上,数据库:保证全企业全业务的正常运行 数据仓库:将数据的统计结果为企业的经营决策提供数据支撑
PS:数据仓库不是数据流转的终点,需要将统计结果通过可视化图表展现给客户。
3.数据流转的过程
(不完整,只记录涉及到的)
客户端——业务服务器(业务数据,用户行为数据)——数据存储(业务数据库,用户行为日志)——数据的统计分析(数据仓库)—— 数据可视化(可视化平台,图表)
4.数据仓库技术选择(Hive)
数据仓库:核心功能统计分析
可选计算框架:Spark(scala), MapReduce, Flink(实时)
本次是做离线数仓,故排除Flink。
Spark框架通常情况下比MapReduce性能更优
1. 内存计算优势
- Spark:Spark 支持将数据加载到内存中进行计算,形成弹性分布式数据集(RDD),后续的计算任务可以直接基于内存中的数据进行,避免了频繁的磁盘 I/O 操作。例如,在迭代计算场景中,如机器学习算法(如迭代式的梯度下降算法),每次迭代的数据可以在内存中快速传递和处理,大大提高了计算速度。
- MapReduce:MapReduce 是基于磁盘的计算框架,每一轮计算的中间结果都需要写入磁盘,下一轮计算时再从磁盘读取,磁盘 I/O 操作非常耗时,严重影响了整体性能。
2. 任务调度效率
- Spark:Spark 的任务调度更为高效,它采用 DAG(有向无环图)调度器,能够对整个作业的依赖关系进行分析,将多个连续的操作合并成一个任务集,减少了任务启动和调度的开销。例如,在一个复杂的数据分析流程中,Spark 可以将多个转换操作(如过滤、映射、聚合等)优化成一个任务链,一次性完成处理。
- MapReduce:MapReduce 的任务调度相对简单,每个 Map 任务和 Reduce 任务都需要单独进行调度和启动,增加了额外的时间开销,尤其是在处理复杂任务时,效率较低。
3. 数据处理速度
- Spark:提供了丰富的高级算子,如 map、filter、reduceByKey 等,这些算子可以在内存中高效地对数据进行处理。同时,Spark 还支持多种数据格式和数据源,能够快速地进行数据读取和转换。例如,在处理实时流数据时,Spark Streaming 可以以毫秒级的延迟处理数据。
- MapReduce:由于其基于磁盘的特性和相对简单的编程模型,在数据处理速度上明显不如 Spark。它需要编写复杂的 Map 和 Reduce 函数,并且在处理大规模数据时,磁盘 I/O 成为性能瓶颈。
如果直接用spark框架要学习scala,开发成本高,通过SQL方式实现比较好。
两种SQL实现Spark方式区别:谁解析SQL谁放前面
1. Spark On Hive Spark解析SQL
2. Hive On Spark Hive解析SQL
实际开发中其实两种方式都会选择,因为Hive基于Hadoop,国内开发用Hive On Spark的多一些,所以本项目采用Hive完成数仓的开发。
两种技术路线的比较:
- Spark on Hive
- Hive 角色:Hive 主要提供数据存储和元数据管理功能。它将数据存储在 HDFS 等分布式文件系统中,并通过元数据存储来记录表结构、数据位置等信息。
- Spark 角色:Spark 负责 SQL 解析、优化和执行。Spark SQL 通过加载 Hive 的配置文件获取元数据信息,然后可以操作 Hive 表中的数据,底层基于 Spark RDD 进行计算。
- Hive on Spark
- Hive 角色:Hive 既负责数据的存储和管理,也负责 SQL 的解析、优化和编译。用户提交的 Hive SQL 语句由 Hive 进行处理,将其转换为可执行的任务。
- Spark 角色:Spark 作为执行引擎,接收 Hive 解析优化后的任务并执行,将 Hive 查询作为 Spark 任务提交到 Spark 集群上进行计算。
执行流程
- Spark on Hive
- 用户使用 Spark SQL 编写代码或执行 SQL 语句来操作 Hive 数据。
- Spark SQL 加载 Hive 配置,获取元数据,确定要操作的数据位置和表结构等12。
- Spark 根据 SQL 语句进行逻辑规划和物理规划,将其转化为 RDD 操作并在 Spark 集群上执行。
- Hive on Spark
- 用户通过 Hive 客户端(如 Hive CLI、Hue 等)提交 Hive SQL 语句3。
- Hive 对 SQL 语句进行解析、词法分析、语法分析、语义分析等,生成逻辑执行计划,再进行优化生成物理执行计划。
- 将物理执行计划转换为 Spark 任务,提交到 Spark 集群上由 Spark 执行引擎执行。
性能特点
- Spark on Hive
- 由于 Spark 的优化器和执行引擎更先进,对于复杂的 SQL 查询和大规模数据处理,能更高效地利用内存和并行计算资源,性能通常较好。
- 可以充分发挥 Spark 的分布式计算能力,对数据进行更灵活的处理和分析。
- Hive on Spark
- 相比 Hive 默认的 MapReduce 执行引擎,性能有显著提升,因为减少了中间结果写入磁盘的次数,更多地在内存中进行计算。
- 但由于 Hive 自身的 SQL 解析和优化机制可能存在一定的局限性,整体性能可能略低于 Spark on Hive2。
使用场景
- Spark on Hive
- 适用于以 Spark 为主要开发框架,需要对 Hive 中的数据进行复杂分析、机器学习等任务的场景。
- 当数据处理需求不断变化,需要更灵活的编程接口和强大的计算能力时,Spark on Hive 可以让开发者使用 Spark 的各种 API 进行数据处理。
- Hive on Spark
- 适合已经有大量 Hive SQL 脚本和任务,希望在不改变太多代码和操作习惯的前提下,提升执行效率的场景。
- 对于一些传统的数据仓库任务,如定期的报表生成、数据 ETL 等,Hive on Spark 可以在 Hive 的生态下利用 Spark 的性能优势。
部署与配置难度
- Spark on Hive
- 部署相对简单,只需在 Spark 环境中配置好 Hive 的元数据连接信息等,即可使用 Spark 操作 Hive 数据。
- Hive on Spark
- 配置相对复杂,需要确保 Hive 和 Spark 的版本兼容,可能还需要额外的配置和调整,比如指定 Spark 相关的 JAR 包路径等。
5.统计分析的基本步骤
数据源——对接并加工数据——统计数据——分析数据
数据仓库也遵循这个步骤:
数据存储—— ——数据可视化
——数据可视化
6.数据仓库的数据源问题
如果将数据库直接作为数据仓库的数据源会出现的问题:
1.业务数据库为行式存储,而数据仓库是列式存储,数据不能直接对接——需要把行式数据转化为列式数据。
2.业务数据库中存储的数据不是海量,但数仓要求海量,所以直接对接数据量不够。
3.数据库不是为了数据仓库服务的,访问会对数据库造成性能影响。
所以数据仓库应该设计一个自己的数据源,为了代替和补充数据库。数据存储应和数据库是同步的。
7.数仓开发前的数据处理
数据仓库的开发用SQL语言进行处理,那么数据的处理步骤应该采用什么方法?
思考过程:
1.数据处理需要将服务器中的数据转化为结构数据——表,且每一步(数据源、加工、统计、分析)都有表(应对多需求,类似缓存:某些表可以在不同需求中复用、无需每次从0到1开始加载。)
2.数据仓库的数据源数据需要从数据库中周期性同步,一般将这个同步过程称之为采集。
若数据采集时,如果想要将数据同步到数据仓库的数据源,那么就必须知道表结构。
那么采集项目和数据仓库项目就会存在耦合性,但二者应有独立性。
所以实际开发中,需要将采集项目和数仓项目解耦合(添加中间件),由于数仓采用Hive开发,故解耦合使用HDFS。
数据存储—— HDFS(解耦合)——数据仓库数据源
原理:Data&File——HDFS(File)—— Hive(Table)(Hive将磁盘文件管理成表)
PS:如果数仓开发不选择Hive,解耦合用HDFS就未必合适
具体过程:(见下图)
数据存储(MySQL)—— 数据采集(DataX、Maxwell(Data—File),Flume(File—File))——HDFS(解耦合)——数据仓库数据源;
数据仓库(Hive)— MySQL (解耦合)— 数据可视化
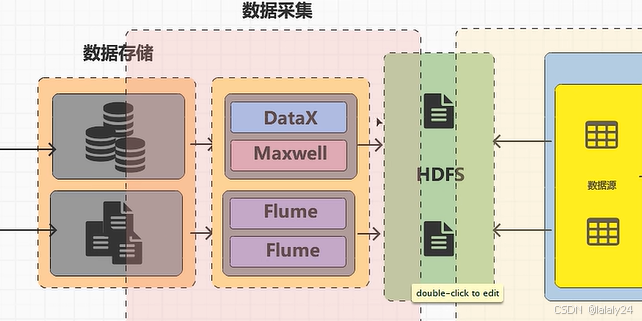
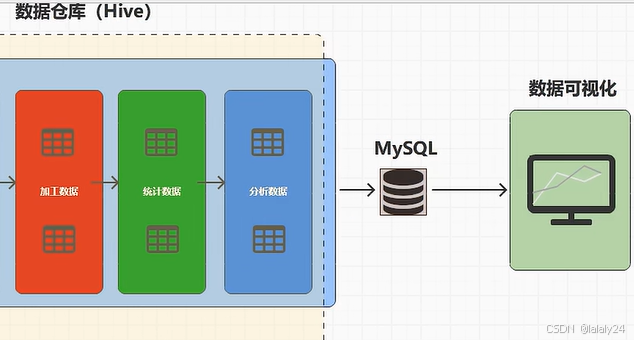
8.数据同步的两种方式
1.全量数据同步(DataX):表的全部数据
2.增量数据同步(Maxwell):表的新增及变化的数据
收集数据的目的是为了后续的统计分析做准备。
比如后期可能会遇到不同的需求:
当前电商网站所有注册用户的数量(更适合全量数据同步方式)
当前电商网站7天内新增注册用户的数量(更适合增量数据同步方式,性能更高)
采集篇
第1章 数据仓库概念
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等。
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
在计算机系统中,特别是在数据库管理中,事务是指一组操作,这些操作被视为一个不可分割的工作单元。要么所有操作都成功执行,要么所有操作都不执行,以确保数据的一致性和完整性。比如在电商的下单支付过程中,从扣除库存、生成订单到更新用户账户余额等一系列操作就构成了一个事务。如果其中任何一个操作失败,整个事务都会回滚,即撤销之前已经执行的操作,以避免数据出现不一致的情况,如商品已经扣除库存但订单却未生成,或者用户账户余额已扣除但商品仍在库存中。
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
“埋点” 是收集用户行为数据的关键技术手段。简单来说,埋点就是在产品的代码中插入特定的代码片段(埋点代码),用于捕捉用户的特定行为。当用户执行了这些被埋点的操作时,埋点代码就会被触发,收集相应的行为数据,并将其发送到服务器进行记录和分析。比如在一个新闻 APP 中,开发人员会在文章详情页的点赞按钮、评论输入框等位置埋点,当用户点击点赞按钮或发表评论时,埋点代码就会收集相关信息,如点赞时间、评论内容等,并上传到服务器。通过合理的埋点设计和数据收集,可以全面、准确地了解用户在产品中的行为轨迹和偏好,为产品优化、运营决策等提供有力的数据支持。
爬虫数据:通常是通过技术手段获取其他公司网站的数据。不建议这样去做。
第2章 项目框架(需求分析及架构设计)
2.1需求分析
2.1.1 采集平台
(1)用户行为数据采集平台搭建
(2)业务数据采集平台搭建
2.1.2 离线需求
电商离线指标体系
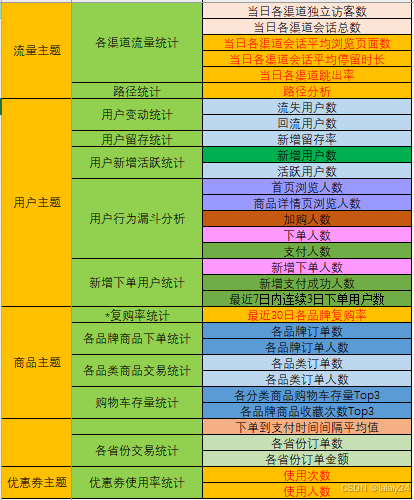
2.2架构设计
架构设计,需要思考:
(1)项目技术如何选型?
(2)框架版本如何选型(Apache、CDH、HDP)
(3)服务器使用物理机还是云主机?
(4)如何确认集群规模?(假设每台服务器16T硬盘)
2.2.1 技术选型
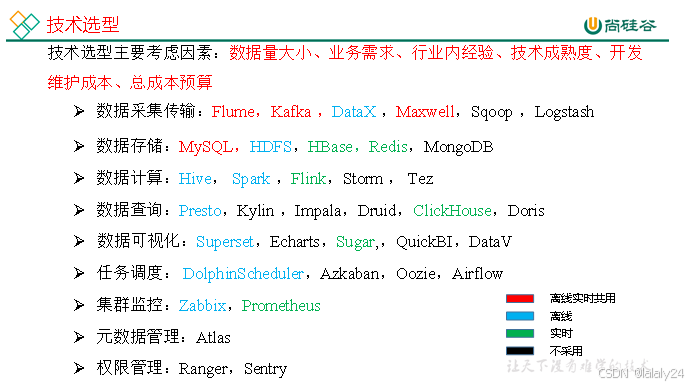
2.2.2 系统数据流程设计
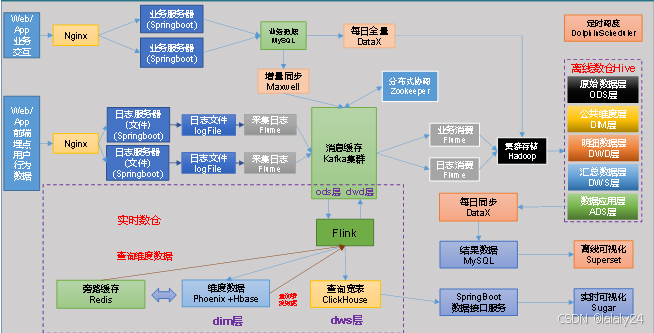
数据输入
- 业务交互数据:Web 或 App 业务交互数据经 Nginx 转发到业务服务器(Springboot),业务数据存储在 MySQL 中,通过 DataX 进行每日全量同步,通过 Maxwell 进行增量同步。
- 用户行为数据:Web 或 App 前端埋点的用户行为数据,经 Nginx 到达日志服务器(Springboot)生成日志文件,由 Flume 采集后发送到 Kafka 集群进行消息缓存。
数据存储与处理
- 实时数仓:Kafka 集群中的数据流入 Flink,Flink 处理后数据一部分存入 Phoenix + HBase 组成的维度数据存储中,一部分存入 ClickHouse 形成查询宽表。
- 离线数仓:Kafka 集群的数据也会通过业务消费和日志消费的 Flume,进入 Hadoop 集群存储。数据在 Hive 中分为原始数据层(ODS 层)、公共维度层(DM 层)等多层结构,经过处理后通过 DataX 每日同步到结果数据 MySQL 中。
数据缓存与查询
- 旁路缓存:使用 Redis 作为旁路缓存,加速数据查询。
- 数据查询:Phoenix + HBase 提供维度数据查询,ClickHouse 用于查询宽表数据,通过 Spring Boot 数据接口服务提供对外数据访问。
数据可视化
- 离线可视化:Hive 数仓处理后的数据通过 Superset 进行离线可视化展示。
- 实时可视化:Flink 处
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1903
1903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









