






简介
在数据库开发过程往往由于业务的不断更新,数据库在配置、架构上不断更新生成了许多冗余代码,在没有在优化语句的情况下,可能会在数据库运行中,未知情况下产生执行时间较长的SQL语句。此时就需要我们通过捕捉慢SQL,定向优化语句,缩短工时,维持数据库高可用属性。
关于高频SQL。在一个WX群中有人问到一个问题,由于在一个很短时间内,一个SQL的高频执行,占用数据库较高资源,引起了数据库性能波动导致故障,但是由于执行时间较短,没有记录日志。所以无法知道是什么语句。定时抓pg_stat_Activty也有一个问题,由于执行时间较短,如果抓取时间设置也很短,同样也会占用较高数据库资源,无异于杀鸡取卵。抓取pg_stat_Activty时间设置过长就无法抓取到高频执行的SQL。以下文章为大家解读如何找出慢SQL和高频SQL。

pg_stat_statements
本文基于 PostgreSQL 15.3 on x86_64-pc-linux-gnu版本为大家解读
postgresql自带了pg_stat_statements拓展,提供了一种跟踪服务器执行的所有 SQL 语句的计划和执行统计信息的方法。
该拓展必须通过在postgresql.conf的配置shared_preload_libraries=‘pg_stat_statements’来载入,因为它需要额外的共享内存。这意味着增加或移除该模块需要一次服务器重启。
安装pg_stat_statements拓展
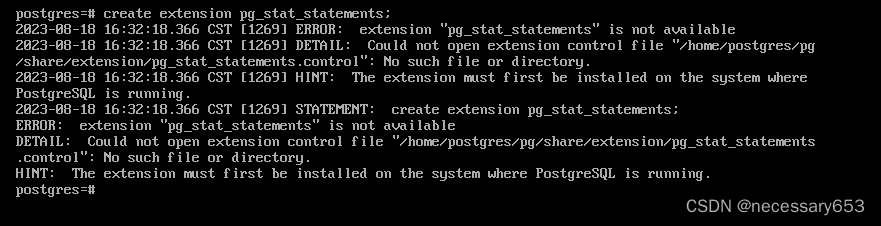
create extension pg_stat_statements;

指定 配置文件中指定shared_preload_libraries参数的值,为插件分配共享缓存区。

如果创建显示没有此拓展的控制文件,需要进入安装包的contrib目录 进行make && make install 重新构建一下

在此目录内进行进行make && make install构建操作

然后回到psql客户端再次创建pg_stat_statements拓展便可。
pg_stat_statements拓展提供了一个视图和两个函数;
pg_stat_statements视图
| 列名 | 注释 |
| userid | 执行该语句的用户的 OID |
| dbid | 在其中执行该语句的数据库的 OID |
| queryid | 内部哈希码,从语句的解析树计算得来 |
| query | 语句的文本形式 |
| plans | 计划语句的次数(如果启用了pg_stat_statements.track_planning,否则为零) |
| total_plan_time | 计划语句所花费的总时间,以毫秒为单位(如果启用了pg_stat_statements.track_planning,否则为零) |
| min_plan_time | 计划语句所花费的最短时间,以毫秒为单位(如果启用了pg_stat_statements.track_planning,否则为零) |
| max_plan_time | 计划语句所花费的最长时间,以毫秒为单位(如果启用了pg_stat_statements.track_planning,否则为零) |
| mean_plan_time | 计划语句所花费的平均时间,以毫秒为单位(如果启用了pg_stat_statements.track_planning,否则为零) |
| stddev_plan_time | 计划语句花费的时间的总体标准偏差,以毫秒为单位(如果启用了pg_stat_statements.track_planning,否则为零) |
| calls | 语句被执行的次数 |
| total_exec_time | 执行语句所花费的总时间,以毫秒为单位 |
| min_exec_time | 执行语句所花费的最短时间,以毫秒为单位 |
| max_exec_time | 执行语句所花费的最长时间,以毫秒为单位 |
| mean_exec_time | 执行语句的平均时间,以毫秒为单位 |
| stddev_exec_time | 执行语句花费的时间的总体标准偏差,以毫秒为单位 |
| rows | 语句检索或影响的总行数 |
| shared_blks_hit | 语句的共享块缓存命中总数 |
| shared_blks_read | 语句读取的共享块总数 |
| shared_blks_dirtied | 被语句弄脏的共享块总数 |
| shared_blks_written | 语句写入的共享块总数local_blks_hit语句的本地块缓存命中总数 |
| local_blks_read | 语句读取的本地块总数 |
| local_blks_dirtied | 被语句弄脏的本地块总数 |
| local_blks_written | 语句写入的本地块总数 |
| temp_blks_read | 语句读取的临时块总数 |
| temp_blks_written | 语句写入的临时块总数 |
| blk_read_time | 语句读取块所花费的总时间,以毫秒为单位(如果启用了track_io_timing,否则为零) |
| blk_write_time | 语句写入块所花费的总时间,以毫秒为单位(如果启用了track_io_timing,否则为零) |
| wal_records | 语句生成的 WAL 记录总数 |
| wal_fpi | 语句生成的 WAL 整页图像总数 |
| wal_bytes | 语句生成的 WAL 字节总数 |
在官网对以上视图的注释中涉及到两个参数(pg_stat_statements.track_planning、track_io_timing)的配置,才可显示对应的列值。开启这两个参数,会对数据库性能产生明显的压力。并且该拓展要求与pg_stat_statements.max成比例的额外共享内存。注意只要该模块被载入就会消耗这么多的内存,即便pg_stat_statements.track被设置为none。
pg_stat_statements涉及参数
均需配置在postgresql.conf文件中
| 参数 | 注释 |
| pg_stat_statements.max (integer) | 由该拓展跟踪的语句的最大数量(即pg_stat_statements视图中行的最大数量)。默认值为 5000。这个参数只能在服务器启动时设置。 |
| pg_stat_statements.track (enum) | 控制哪些语句会被该拓展计数。指定top可以跟踪顶层语句(那些直接由客户端发出的语句),指定all还可以跟踪嵌套的语句(例如在函数中调用的语句),指定none可以禁用语句统计信息收集。默认值是top。 只有超级用户能够改变这个设置。 |
| pg_stat_statements.track_utility (boolean) | 控制该拓展是否会跟踪工具命令。工具命令是除了SELECT、INSERT、 UPDATE和DELETE之外所有的其他命令。默认值是on。 只有超级用户能够改变这个设置。 |
| pg_stat_statements.track_planning (boolean) | 控制拓展是否跟踪计划操作和持续时间。 启用此参数可能会导致明显的性能损失,尤其是在许多并发连接上执行较少种类的查询时。 默认值为off。只有超级用户才能更改此设置。 |
| pg_stat_statements.save (boolean) | 指定是否在服务器关闭之后还保存语句统计信息。如果被设置为off,那么关闭后不保存统计信息并且在服务器启动时也不会重新载入统计信息。默认值为on。这个参数只能在postgresql.conf文件中或者在服务器命令行上设置。 |
| track_io_timing(boolean) | 启用对系统 I/O 调用的计时。这个参数默认为关闭,因为它将重复地向操作系统查询当前时间,这会在某些平台上导致显著的负荷。 你可以使用pg_test_timing工具来度量你的系统中计时的开销。 I/O 计时信息被显示在 pg_stat_database中,当BUFFERS选项被使用时的EXPLAIN输出中以及pg_stat_statements中。只有超级用户可以更改这个设置。 |
拓展关联函数
安装完pg_stat_statements拓展后,还有两个函数也会随着载入pg_stat_statements_reset,pg_stat_statements
pg_stat_statements_reset函数
pg_stat_statements视图中的指标值是一个累计值,可以执行此函数,使得视图的指标值重新开始计数。
pg_stat_statements(boolean)函数
使用select pg_stat_statements(false); pg_stat_statements视图query列的值展示为空值。
捕捉慢SQL示例
捕捉数据库中的慢SQL ,一般用在集体调度作业的时候。
方法1
使用插件pg_stat_statments;
create extension pg_stat_statments;--创建插件
配置postgresql.conf参数shared_preload_libraries=‘pg_stat_statements’
编辑捕捉程序
--创建表结构
create table pg_text_maxtime as select * from pg_stat_statements;
--创建函数
CREATE OR REPLACE FUNCTION sp_pg_text_maxtime()
RETURNS varchar
AS
$$
declare
return_value varchar;
begin
return_value :='执行完成';
insert into pg_text_maxtime
(userid
,dbid
,toplevel
,queryid
,query
,plans
,total_plan_time
,min_plan_time
,max_plan_time
,mean_plan_time
,stddev_plan_time
,calls
,total_exec_time
,min_exec_time
,max_exec_time
,mean_exec_time
,stddev_exec_time
,rows
,shared_blks_hit
,shared_blks_read
,shared_blks_dirtied
,shared_blks_written
,local_blks_hit
,local_blks_read
,local_blks_dirtied
,local_blks_written
,temp_blks_read
,temp_blks_written
,blk_read_time
,blk_write_time
,temp_blk_read_time
,temp_blk_write_time
,wal_records
,wal_fpi
,wal_bytes
,jit_functions
,jit_generation_time
,jit_inlining_count
,jit_inlining_time
,jit_optimization_count
,jit_optimization_time
,jit_emission_count
,jit_emission_time)
select * from pg_stat_statements where max_exec_time>600000 ----(过滤出10分钟以上SQL)
and not exists (select 1 from pg_text_maxtime a where a.query=query ); --(过滤重复语句,如果执行时长超过10分钟甚至更长时间,记录的执行时间就可能不是最新最长的。可以忽略本条件。)
RETURN return_value;
end;
$$
LANGUAGE plpgsql;定时捕捉
select sp_pg_text_maxtime();\watch 700 --7分钟执行一次,新建一个窗口插入测试代码
select pg_stat_statements_reset(); --重置pg_stat_statements视图的指标值,这里刷新了之后,视图会从此刻重新计算。
select pg_sleep(801);待睡眠结束后,最近的一次函数执行后可以查看结果表。
select * from pg_text_maxtime;
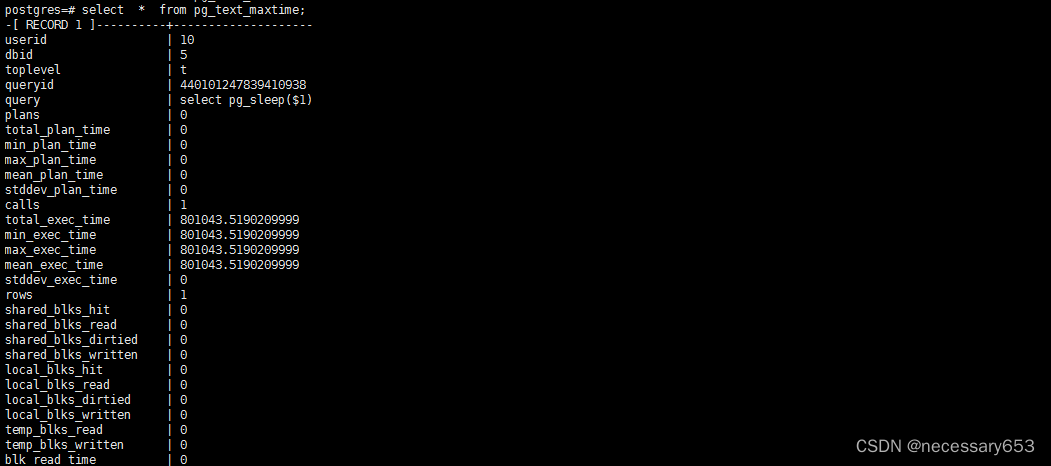
测试代码已经被记录。
方法2
也可以开启日志收集器,
配置log_min_duration_statement=60000 。如果指定值时没有单位,则以毫秒为单位。将这个参数设置为零将打印所有语句的执行时间。 设置为 -1(默认值)将停止记录语句持续时间;
记录会被记录在log_directory参数配置的路径中,文件名由log_filename参数定义,文件格式由log_destination 定义。捕捉语句类型由log_statement 参数定义在postgresql抓取数据库的DML DDL语句文章对这个参数有做介绍,本文不再累述。
log_directory='log/'
logging_collector=on
log_destination='csvlog'
log_filename='log'
log_min_duration_statement=60000 --记录时长超过一分钟的SQL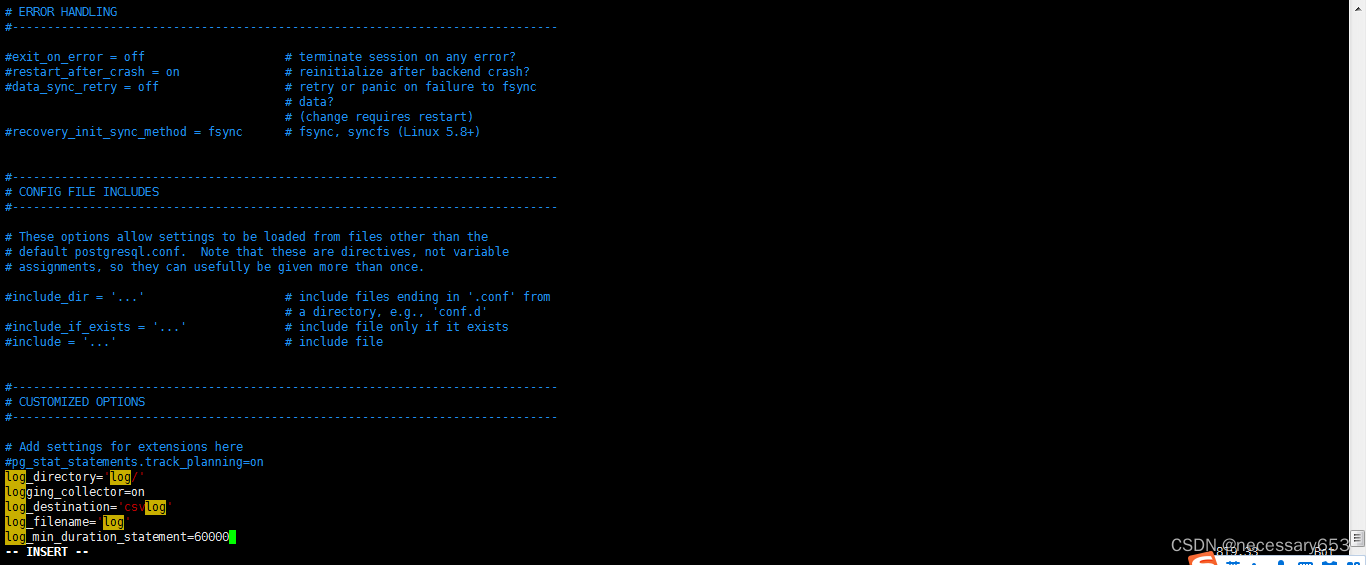
执行测试代码
select pg_sleep(60);此时日志文件就已经记录测试代码。
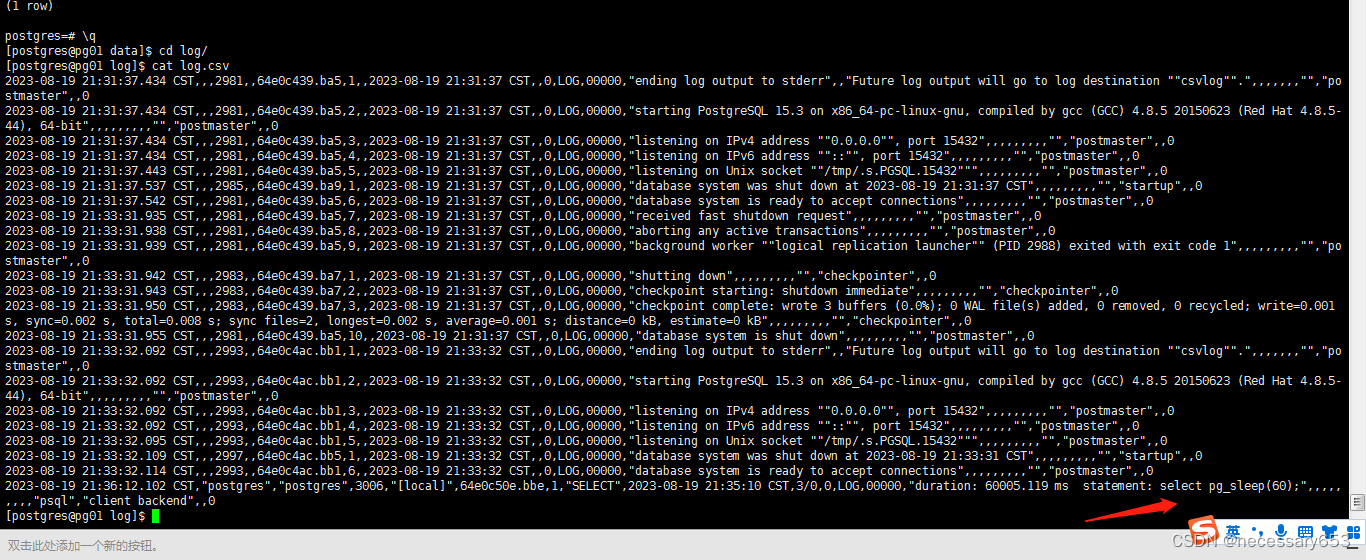
捕捉高频SQL示例
在简介中介绍了关于高频SQL 的问题。
使用pg_stat_statements插件;
配置参数shared_preload_libraries = 'pg_stat_statements' 分配内存空间;

配置pg_stat_statements.track=all(函数中执行的语句一并抓取)
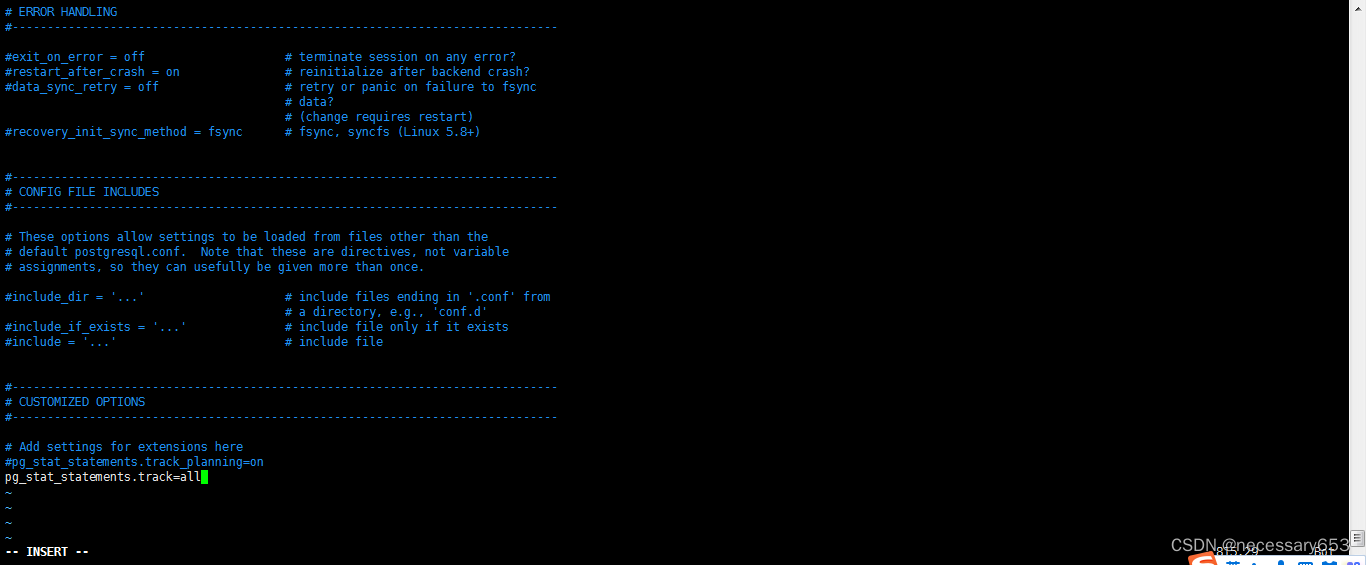
此处增加使用select pg_stat_statements_reset();函数 对视图的各项指标清零
--创建表结构
create table pg_text_maxtime as select * from pg_stat_statements where 1=2;
alter table pg_text_maxtime add column ct_calss integer; --增加一列计算SQL总共的执行次数
--创建函数
CREATE OR REPLACE FUNCTION sp_pg_text_maxtime()
RETURNS varchar
AS
$$
declare
return_value varchar;
begin
return_value :='执行完成';
insert into pg_text_maxtime
(userid
,dbid
,toplevel
,queryid
,query
,plans
,total_plan_time
,min_plan_time
,max_plan_time
,mean_plan_time
,stddev_plan_time
,calls
,total_exec_time
,min_exec_time
,max_exec_time
,mean_exec_time
,stddev_exec_time
,rows
,shared_blks_hit
,shared_blks_read
,shared_blks_dirtied
,shared_blks_written
,local_blks_hit
,local_blks_read
,local_blks_dirtied
,local_blks_written
,temp_blks_read
,temp_blks_written
,blk_read_time
,blk_write_time
,temp_blk_read_time
,temp_blk_write_time
,wal_records
,wal_fpi
,wal_bytes
,jit_functions
,jit_generation_time
,jit_inlining_count
,jit_inlining_time
,jit_optimization_count
,jit_optimization_time
,jit_emission_count
,jit_emission_time
,ct_calss --增加一列计算SQL总共的执行次数
)
select a.*,sum(a.calls)over(partition by a.queryid) as ct_calss from pg_stat_statements a where calls>10 ; ----(过滤出10次以上SQL)
PERFORM pg_stat_statements_reset();--单位时间内统计完后,各项指标清零。重新计数
RETURN return_value;
end;
$$
LANGUAGE plpgsql;这里同一句SQL 不同的人执行虽然queryid不会变,但是执行的用户不同 会导致calls会分开统计。这里增加一个开窗函数,用于统计单位时间内同一句SQL执行的总次数。
开启捕捉监控
select sp_pg_text_maxtime();\watch 10新建窗口执行测试代码
DO $$
DECLARE
v_ct INTEGER := 0;
BEGIN
WHILE v_ct < 50 LOOP
EXECUTE 'SELECT current_date; SELECT now();';
v_ct := v_ct + 1;
END LOOP;
END;
$$;查看目标表已经捕捉到对应的高频SQL

此方法只针对,单一SQL的高频执行有效果 ,嵌套在存储过程中的SQL也可以捕捉到。对于不同的SQL高频执行,便无法捕捉。
操作过程中有不了解的,欢迎私信提问。
















 2723
2723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









