







感知机( perceptron )是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1 和-1二值。感知机对应输入空间(特征空间)中将实例划分为正负两类的分离超平面,是一种判别模型。感知机是神经网络与支持向量机的基础
感知机学习旨在求出将训练数据进行线性划分的分离超平面。
感知机学习思路:
1.导入基于误分类的损失函数
2.利用梯度下降法对损失函数进行极小化
3.代入参数得到感知机模型。
感知机学习算法分类:
原始形式、对偶形式。
感知机算法原始形式例题及详解
例1 训练数据集如图所示,正实例点为,
,负实例点为
,试用感知机算法原始形式求感知机模型,令
,

解答:
(1)建模最优化问题:
(2)取初值,
(3)按顺序,对
,
,则
为误分类点。更新
:
,
得到线性模型:
(4)重新选取,对,
,则均为正确分类点,不更新
;
对,
,则
为误分类点,更新
:
,
得到线性模型:
(5)由此不断迭代
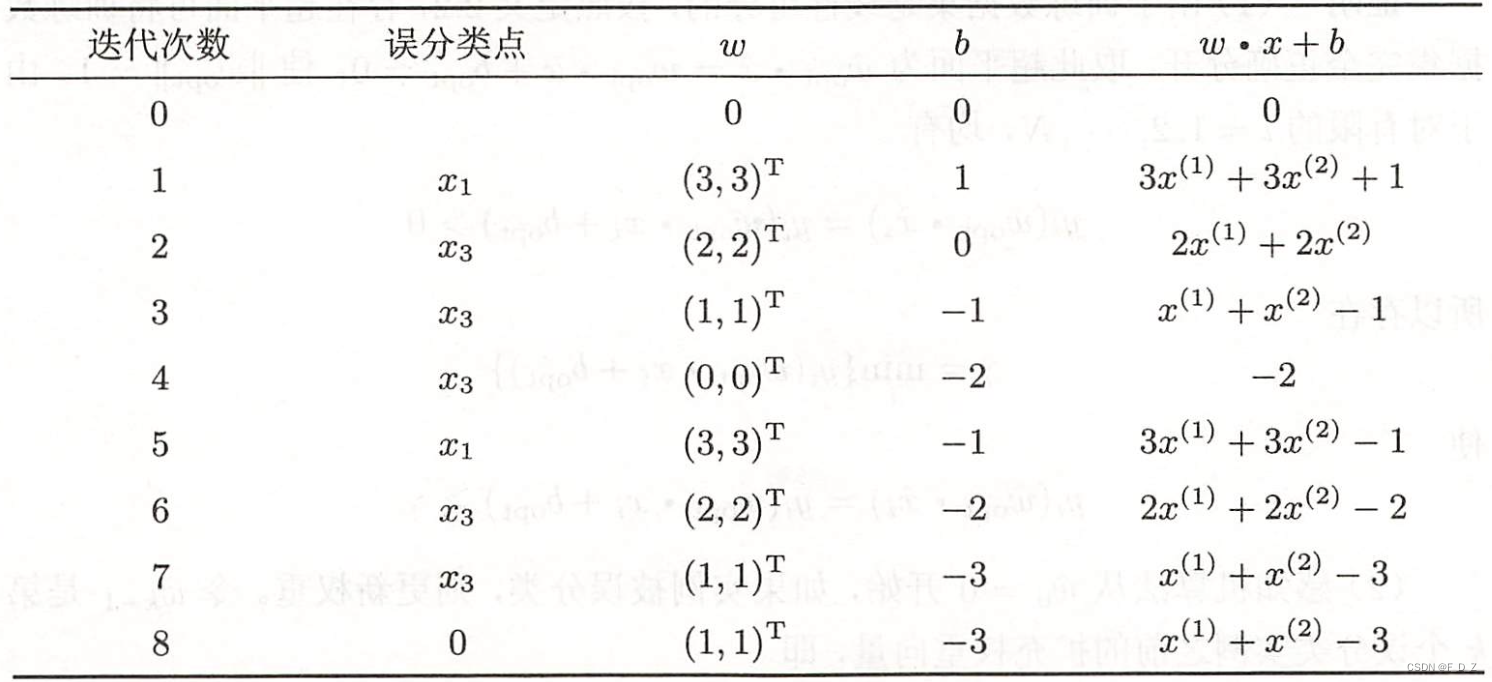
(6)直到,
线性模型:
对所有数据点,则确定分离超平面:
感知机模型
分离超平面
是按照
的取点顺序得到的
例1如果更换取点顺序为
,得到的分离超平面为:
由此,可知结论:感知机算法采用不同的初值或选取不同的误分类点顺序,解可以不同
感知机算法对偶形式例题及详解
例2 训练数据集如图所示,正实例点为,
,负实例点为
,试用感知机算法对偶形式求感知机模型,令
,
解答:
(1)取;
(2)计算Gram矩阵
(3)误分条件
(4)参数更新
(5)迭代
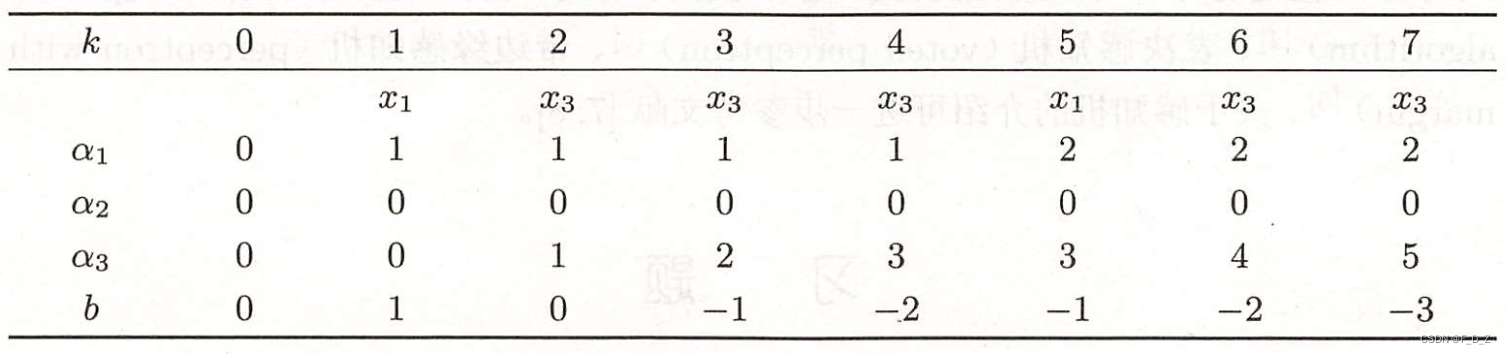
(6)最终得到
则,分离超平面:
感知机模型:
与原始形式一致,感知机学习算法的对偶形式迭代收敛,且存在多个解















 3979
3979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











