






7-1 sdut-ASCII码排序 分数 10
输入N个字符后,按各字符的ASCII码从小到大的顺序输出这N个字符。
输入格式:
输入数据有多组,每组占一行,有N个字符组成。
输出格式:
对于每组输入数据,输出一行,字符中间用一个空格分开。
输入样例:
Input1231
qwe1321
asddsfadsfadsf
zxc1321132dsfa
abcABCDFdefgDEFGHIJhijakfdsadsf;dsa
输出样例:
1 1 2 3 I n p t u
1 1 2 3 e q w
a a a d d d d f f f s s s s
1 1 1 2 2 3 3 a c d f s x z
; A B C D D E F F G H I J a a a a b c d d d d e f f f g h i j k s s swhile True:
try:
s=input()
ls=list(s)
ls.sort()
print(" ".join(i for i in ls))
except:
break7-2 sdut-数据逆序 分数 10
一行输入N个整数,按逆序输出数值。
输入格式:
输入有多行。
每行有若干个整数,用空格分隔。
输出格式:
对于每行输入,将数值逆序输出,数值以空格隔开。
输入样例:
1 3 5 9 7 6 8 2 4 0 234 656 2223
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-3 -43 23 435 -5667 231 100 2002 2035
输出样例:
在这里给出相应的输出。例如:
2223 656 234 0 4 2 8 6 7 9 5 3 1
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
2035 2002 100 231 -5667 435 23 -43 -3while True:
try:
ls=[]
ls=list(map(int,input().split()))
ls.reverse()
for i in range(len(ls)-1):
print(ls[i],end=' ')
print(ls[(len(ls)-1)])
except:
break7-4 sdut-统计身高超过平均值的学生 分数 10
中小学生每个学期都要体检,量身高,因为身高可以反映孩子的生长状况。
现在,一个班的身高已经量好了,请输出其中超过平均身高的那些学生的身高。
输入格式:
输入为一行数据,以空格分隔,每个数据都是一个正整数。
输出格式:
输出超过身高平均数的学生的身高数值,每个数后面有一个空格。
输出的顺序和输入的相同。
输入样例:
143 174 119 127 117 164 110 128
输出样例:
在这里给出相应的输出。例如:
143 174 164 ls=list(map(int,input().split()))
sum = sum(ls)
ave = sum/(len(ls))
for i in ls:
if i >ave:
print(i,end=' ')7-5 sdut-求整数的位数及各位数字之和 分数 10
对于给定的正整数N,求它的位数及其各位数字之和。
(用Python实现提示:把整数转换成字符串,列表,用sum和len函数)
输入格式:
输入在一行中给出一个正整数N。
输出格式:
在一行中输出N的位数及其各位数字之和,中间用一个空格隔开。
输入样例:
456
输出样例:
3 15n=int(input())
s=str(n)
print(len(s),end=" ")
a=0
for i in range(len(s)):
a+=int(s[i])
print(a)7-6 sdut-字母替换 分数 10
编写程序,将输入字符串中的大写英文字母按以下对应规则替换,其他字符不变。
(Python实现提示:转换表用元组实现)
原字母 对应字母
A Z
B Y
C X
D W
... ...
X C
Y B
Z A
输入格式:
在一行中输入字符串。
输出格式:
在一行中给出替换完成后的字符串。
输入样例:
This is a pen.
输出样例:
在这里给出相应的输出。例如:
Ghis is a pen.str=input()
s=""
for i in range(len(str)):
if str[i].isupper():
s+=chr(155-ord(str[i]))
else:
s+=str[i]
print(s)7-7 sdut-输出字母在字符串中位置索引 分数 10
输入一个字符串,再输入两个字符,求这两个字符在字符串中的索引。
输入格式:
第一行输入字符串;
第二行输入两个字符,用空格分开。
输出格式:
从右向左输出字符和索引(中间有一个空格)。下标最大的字符最先输出。每行一个。
输入样例:
pmispsissippi
s p
输出样例:
11 p
10 p
8 s
7 s
5 s
4 p
3 s
0 ps=input()
a,b=map(str,input().split())
for i in range(len(s)-1,-1,-1):
if(s[i]==a):
print(i,a)
elif (s[i]==b):
print(i,b)7-8 sdut- 输出10个不重复的英文字母 分数 10
输入一个字符串,把最左边的10个不重复的英文字母(不区分大小写)挑选出来进行输出
如没有10个英文字母,显示信息“not found”。
输入格式:
在一行中输入字符串。
输出格式:
在一行中输出最左边的10个不重复的英文字母;或者显示信息:“not found"
输入样例1:
poemp134567
输出样例1:
not found
输入样例2:
This 156is a test example
输出样例2:
Thisaexmplst=input()
c=0
s=""
for i in range(len(st)):
if(st[i].isalpha()):
if(c<10 and st[i].upper() not in s and st[i].lower() not in s):
c+=1
s+=st[i]
if(c<10):
print("not found")
else:
print(s)7-9 sdut-判断两个字符串是否为变位词 分数 10
如果一个字符串是另一个字符串的重新排列组合,那么这两个字符串互为变位词。
比如,"heart" 与 "earth" 互为变位词,"Mary" 与 "arMy" 也互为变位词。“Hello world"与“worldHello"不是变位词。
输入格式:
第一行输入第一个字符串;
第二行输入第二个字符串。
输出格式:
若是变位词,输出:yes;否则,输出:no。
输入样例1:
Mary
arMy
输出样例1:
yes
输入样例2:
hello world
world hello
输出样例2:
yes
输入样例3:
I am very good.
verygood I am.
输出样例3:
nos=input()
s=list(s)
t=input()
t=list(t)
s.sort()
t.sort()
if s==t:
print("yes")
else:
print("no")7-10 sdut-猴子选大王 分数 10
一群猴子要选新猴王。新猴王的选择方法是:
让N只候选猴子围成一圈,从某位置起顺序编号为1~N号。从第1号开始报数,每轮从1报到3,凡报到3的猴子即退出圈子,接着又从紧邻的下一只猴子开始同样的报数。如此不断循环,最后剩下的一只猴子就选为猴王。
请问是原来第几号猴子当选猴王?
输入格式:
在一行中给一个正整数N(≤1000)。
输出格式:
在一行中输出当选猴王的编号。
输入样例:
11
输出样例:
在这里给出相应的输出。例如:
7n=int(input())
p=0
for i in range(2,n+1):
p=(p+3)%i
print(p+1)7-11 sdut-找出两组数据中非公共元素 分数 10
给定两行输入,每行代表一组元素。求两组中非公共的元素。
输入格式:
在两行中给出两组元素,每行的元素间用空格分开。在一行中元素可能会有重复值。
输出格式:
在一行中按照元素的输入顺序输出不是两组共有的元素,以空格分隔。(题目保证至少存在一个这样的元素)
输入样例:
10 3 -5 2 8 0 5 -15 9 100
10 6 4 8 2 -5 9 0 100 1
输出样例:
在这里给出相应的输出。例如:
3 5 -15 6 4 1l1=list(input().split())
l2=list(input().split())
l=[]
for i in l1:
if i not in l2:
l.append(i)
for i in l2:
if i not in l1:
l.append(i)
print(*l,sep=" ")7-13 sdut-矩阵行、列、对角线和的最大值 分数 10
求一个3*3矩阵每行、每列及对角线和的最大值。
输入格式:
在一行输入9个整数。
输出格式:
在一行输出每行、每列及对角线和的最大值。
输入样例:
3 6 5 9 8 2 1 4 5
输出样例:
19num=list(map(int,input().split()))
l=[]
l.append(num[0]+num[4]+num[8])
l.append(num[2]+num[4]+num[6])
for i in range(0,6,3):
l.append(num[i]+num[i+1]+num[i+2])
for j in range(0,3):
l.append(num[j]+num[j+3]+num[j+6])
print(max(l))7-15 sdut-打印显示直角字母图形 分数 10
给定行数,输出指定行数的字母组成的图形。
输入格式:
在一行内给出行数n,1<=n<=10。
输出格式:
输出由大小字母组成的直角图形。
输入样例1:
2
输出样例1:
A
AB
输入样例2:
7
输出样例2:
A
AB
ABC
ABCD
ABCDE
ABCDEF
ABCDEFGs="ABCDEFGHIJ"
n=int(input())
for i in range(n):
for j in range(i+1):
print(s[j],end='')
print()7-17 sdut-array2-5 打印“杨辉三角“ 品中国数学史 增民族自豪感(2) 分数 10
背景介绍:
北宋人贾宪约1050年首先使用“贾宪三角”进行高次开方运算。
南宋数学家杨辉在《详解九章算法》(1261年)记载并保存了“贾宪三角”,故称杨辉三角。杨辉三角是中国数学史上的一个伟大成就。
杨辉三角,是中国古代数学的杰出研究成果之一,它把二项式系数图形化,把组合数内在的一些代数性质直观地从图形中体现出来,是一种离散型的数与形的结合。
中国南宋数学家杨辉1261年所著的《详解九章算法》一书中出现。在欧洲,帕斯卡(1623----1662)在1654年发现这一规律,所以这个表又叫做帕斯卡三角形。帕斯卡的发现比杨辉要迟393年,比贾宪迟600年。
杨辉三角数字的特点为:
(1)在三角形的首列和对角线上,数值均为1;
(2)其余数据为:每个数字等于上一行的左右两个数字之和,第n+1行的第i个数等于第n行的第i-1个数和第i个数之和,用公式表示为: C(n+1,i)=C(n,i)+C(n,i-1)。
图示为:
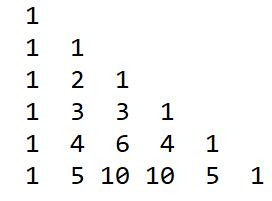
杨辉三角的应用:(a+b)的n次方,展开式中的各项系数依次对应杨辉三角的第(n+1)行中的每一项。
输入格式:
欲打印杨辉三角的行数n(1<=n<=13)。
输出格式:
(1)输出的数据为等腰三角形样式;
(2)每个数字占据4个字符的位置,数字左对齐,数字不足4位的右边留出空格;
(3)最后一行的数值“1”顶格,前面无空格。
提示:以n=5,分析行首空格数为:
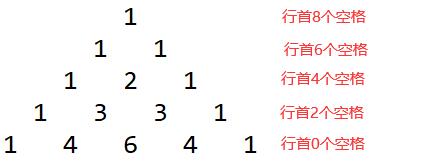
输入样例1:
5
输出样例:
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
输入样例2:
6
输出样例:
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1 n=int(input())
ls=[[1]]
for i in range(1,n):
row=[1]
for j in range(1,i):
row.append(ls[i-1][j]+ls[i-1][j-1])
row.append(1)
ls.append(row)
c=n*2-2
for i in range(n):
print(' '*c,end='')
for j in range(i+1):
print("%-4d"%ls[i][j],end='')
print()
c-=27-18 sdut-列表去重 分数 10
输入一个列表,去掉列表中重复的数字,按原来次序输出!
输入格式:
在一行中输入列表。
输出格式:
在一行中输出不重复的列表元素。
输入样例1:
[4,7,5,6,8,6,9,5]
输出样例1:
4 7 5 6 8 9
输入样例2:
[1,2,3,"abcd","hello",1,2,3,4,5,6]
输出样例2:
1 2 3 abcd hello 4 5 6ls1=eval(input())
ls2=sorted(set(ls1),key=ls1.index)
print(*ls2,sep=' ')7-19 sdut-期末考试之排名次 分数 10
期末考试结束了,童鞋们的成绩也出来的了,可是为了排名次可忙坏了老师,因为学生太多了。这时,老师把这个任务交给了你,希望你能帮老师完成。作为IT人,你当然不能用笨笨的人工方法了,编程解决才是好办法。
共有三门课,语文、数学和英语,要求根据学生的各科成绩计算出其总成绩,并根据总成绩从高到低排序.
输入格式:
第一行一个整数N(N<=100),代表学生的人数。
接下来的N行数据,每行有三个整数,C,M,E分别代表一个学生语文、数学和英语的成绩.
输出格式:
一共N行,每行一个数,从大到小,分别代表各个学生的总成绩.
输入样例:
3
70 80 90
59 59 59
100 100 100
输出样例:
300
240
177n=int(input())
ls=[]
for i in range(n):
ls.append(sum(map(int,input().split())))
ls.sort(reverse=True)
for it in ls:
print(it)7-20 sdut- 矩阵转置(II) 分数 10
从键盘输入一个m(2<=m<=6)*n(2<=n<=6)阶的矩阵,编程输出它的转置矩阵。
输入格式:
在第一行输入矩阵的行数m和列数n的值;
在第二行按照矩阵格式输入矩阵的数据,同行数据之间用空格隔开。
输出格式:
矩阵格式输出,同行数据之间用一个空格隔开。
输入样例:
3 5
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
输出样例:
1 1 1
2 2 2
3 3 3
4 4 4
5 5 5n,m=map(int,input().split())
ls=[]
for i in range(n):
ls.append(list(map(int,input().split())))
ls_re=list(zip(*ls))
for i in range(m):
print(*ls_re[i],sep=' ')7-23 sdut-对称矩阵的判定 分数 10
输入矩阵的行数,再依次输入矩阵的每行元素,判断该矩阵是否为对称矩阵,若矩阵对称输出“yes”,不对称输出“no”。
输入格式:
输入有多组,每一组第一行输入一个正整数N(N<=20),表示矩阵的行数(若N=0,表示输入结束)。
下面依次输入N行数据。
输出格式:
若矩阵对称输出“yes",不对称输出“no”。
输入样例:
3
6 3 12
3 18 8
12 8 7
3
6 9 12
3 5 8
12 6 3
0
输出样例:
yes
nowhile True:
n= int(input())
if n == 0:
break
else:
ls,flag=[],1
for i in range(0,n):
ls.append(list(input().split()))
for i in range(n):
for j in range(n):
if ls[i][j] != ls[j][i]:
flag = 0
if flag == 0:
print("no")
else:
print("yes")7-18 sdut-查验身份证 分数 10
一个合法的身份证号码由17位地区、日期编号和顺序编号加1位校验码组成。校验码的计算规则如下:
首先对前17位数字加权求和,权重分配为:{7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2};然后将计算的和对11取模得到值Z;最后按照以下关系对应Z值与校验码M的值:
Z:0 1 2 3 4 5 6 7 8 9 10
M:1 0 X 9 8 7 6 5 4 3 2
现在给定一些身份证号码,请你验证校验码的有效性,并输出有问题的号码。
验证身份证合法性的规则:(1)前17位是否全为数字;(2)最后1位校验码计算准确。
输入格式:
输入第一行给出正整数N(≤100)表示:输入的身份证号码的个数。
随后N行,每行给出1个18位身份证号码。
输出格式:
按照输入的顺序每行输出1个有问题的身份证号码。
如果所有号码都正常,则输出All passed。
输入样例1:
4
320124198808240056
12010X198901011234
110108196711301866
37070419881216001X
输出样例1:
12010X198901011234
110108196711301866
37070419881216001X
输入样例2:
2
320124198808240056
110108196711301862
输出样例2:
All passedlis=[7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
M=[1,0,"X",9,8,7,6,5,4,3,2]
n=int(input())
al=0
for i in range(n):
sum=0
lt=input()
if lt[:-1].isdigit():
ans=list(map(int,lt[:-1]))
for i in range(len(ans)):
sum+=lis[i]*ans[i]
sum=sum%11
if str(M[sum])!=lt[-1]:
print(lt)
else:
al+=1
else:
print(lt)
if al==n:
print("All passed")7-19 sdut-统计两个字符串中相同的字符个数
分数 10
输入字符串A、字符串B,求在字符串A、字符串B中相同的字符个数。
输入格式:
第一行输入,表示字符串A。
第二行输入,表示字符串B。
输出格式:
在一行内,输出字符串A、B中相同字符的个数。
输入样例:
AEIOU
HELLO World!
输出样例:
在这里给出相应的输出。例如:
2a=input()
b=input()
sum=0
for i in set(a):
if i in set(b):
sum+=1
print(sum)7-20 sdut-分析每队活动投票情况 分数 10
利用集合分析活动投票情况。
第一小队有五名队员,序号是1,2,3,4,5; 第二小队也有五名队员,序号6,7,8,9,10。
输入一个得票队员的编号的字符串,求第一、二小队没有得票的队员。在一行中输入得票的队员的序列号,用逗号隔开。
输入格式:
在一行中输入得票的队员的序列号,用逗号隔开。
输出格式:
在第一行中输出第一小队没有得票的队员序号,用空格分开;
在第二行中输出第二小队没有得票的队员序号,用空格分开。
输入样例:
1,5,9,3,9,1,1,7,5,7,7,3,3,1,5,7,4,4,5,4,9,5,10,9
输出样例:
2
6 8l=list(map(int,input().split(',')))
s=[]
q=[]
for j in range(1,6):
if j not in l:
q.append(j)
print(*q,sep=' ')
for i in range(6,11):
if i not in l:
s.append(i)
print(*s,sep=' ')7-21 sdut-统计字符在字符串中出现的次数 分数 10
统计并输出某给定字符在给定字符串中出现的次数。
输入格式:
第一行给出一个以回车结束的字符串(一行少于80个字符);
第二行输入一个字符。
输出格式:
在一行中输出给定字符在给定字符串中出现的次数。(如果未出现,则输出0)
输入样例:
programming is More fun!
m
输出样例:
2s=input()
t=input()
print(s.count(t))7-22 sdut-四则运算(用字典实现) 分数 10
根据输入信息进行四则运算(用字典实现)。
(与c语言的switch语句相比较。)
输入格式:
第1行中输入一个数字a;
第2行中输入一个四则运算符(+ , - , * , / ) op,
在第3行中输入一个数字b。
输出格式:
在一行中输出 a op b 的运算结果(保留2位小数)。
输入样例1:
7
/
3
输出样例1:
2.33
输入样例2:
10
/
0
输出样例2:
divided by zeroa=float(input())
op=input()
b=float(input())
d={'+':a+b,'-':a-b,'*':a*b,'/':a/b if b != 0 else "divided by zero"}
res = d[op]
if type(res)==float:
print("%.2f"%res)
else:
print(res)7-23 sdut-统计工龄 分数 10
给定公司N名员工的工龄,按工龄增序输出每个工龄段有多少员工。
输入格式:
首先给出正整数N(≤105 ),即员工总人数;随后给出N个整数,即每个员工的工龄,范围在[0, 50]。
输出格式:
按工龄的递增顺序输出每个工龄的员工个数,格式为:“工龄:人数”。
每项占一行。
输入样例:
8
10 2 0 5 7 2 5 2
输出样例:
在这里给出相应的输出。例如:
0:1
2:3
5:2
7:1
10:1n=int(input())
ls1 = list(map(int,input().split()))
dic = {}
for it in ls1:
dic[it]=dic.get(it,0)+1
ls2 = sorted(dic.keys())
for i in ls2:
print("%d:%d"%(i,dic[i]))7-24 sdut-字典合并 分数 10
输入用字符串表示两个字典,输出合并后的字典。字典的键用一个字母或数字表示。
注意:1和‘1’是不同的关键字!
输入格式:
在第一行中输入第一个字典字符串;
在第二行中输入第二个字典字符串。
输出格式:
在一行中输出合并的字典,输出按字典序。
"1" 的 ASCII 码为 49,大于 1,排序时 1 在前,"1" 在后。其它的字符同理。
输入样例1:
{1:3,2:5}
{1:5,3:7}
输出样例1:
1:8
2:5
3:7
输入样例2:
{"1":3,1:4}
{"a":5,"1":6}
输出样例2:
1:4
'1':9
'a':5dict1 = dict(eval(input()))
dict2 = dict(eval(input()))
list1 = []
for i in dict1:
if i in dict2:
dict2[i] += dict1[i]
else:
dict2[i] = dict1[i]
for i in dict2:
list1.append(i)
list2 = list(set(list1))
list3 = []
list4 = []
for i in list2:
if isinstance(i, str):
list3.append(i)
list4.append(ord(i))
else:
list4.append(i)
dict3 = {}
for i in dict2:
if isinstance(i, str):
dict3[ord(i)] = dict2[i]
else:
dict3[i] = dict2[i]
for i in sorted(list4):
if chr(i) not in list3:
print("%s:%s" % (i, dict3[i]))
else:
print("'%s':%s" % (chr(i), dict3[i]))7-25 sdut-集合相等问题 分数 10
给定2 个集合S和T,试设计一个判定S和T是否相等的蒙特卡罗算法。
设计一个拉斯维加斯算法,对于给定的集合S和T,判定其是否相等。
输入格式:
输入数据的第一行有1 个正整数n(n≤10000),表示集合的大小。
接下来的2行,每行有n个正整数,分别表示集合S和T中的元素。
输出格式:
将计算结论输出。集合S和T相等,则输出:YES,否则输出:NO。
输入样例:
3
2 3 7
7 2 3
输出样例:
YESn=int(input())
a=list(map(int,input().split()))
b=list(map(int,input().split()))
a.sort()
b.sort()
a=set(a)
b=set(b)
if a==b:
print("YES")
else:
print("NO")7-26 sdut-植物与颜色 分数 10
请定义具有red, orange, yellow, green, blue, violet六种颜色的变量color。
根据输入的颜色名称,输出以下六种植物花朵的颜色:
Rose(red), Poppies(orange), Sunflower(yellow), Grass(green), Bluebells(blue), Violets(violet)。
如果输入的颜色名称不在变量color中,例如,输入:purple,请输出:I don't know about the color purple.
输入格式:
第1行为颜色的数量n。
接下来有n行字符串每行有一个字符串代表颜色名称,颜色名称最多30个字符。
输出格式:
输出对应颜色的植物名称,例如:Bluebells are blue.
如果输入的颜色名称不在color变量中,例如purple, 请输出I don't know about the color purple.
输入样例:
3
blue
yellow
purple
输出样例:
Bluebells are blue.
Sunflower are yellow.
I don't know about the color purple.ls1=['red','orange','yellow','green','blue','violet']
ls2=['Rose','Poppies','Sunflower','Grass','Bluebells','Violets']
dic=dict(zip(ls1,ls2))
n=int(input())
for i in range(n):
col = input()
if col in ls1:
print("%s are %s."%(dic[col],col))
else:
print("I don't know about the color %s."%col)7-27 sdut-众数 分数 10
众数是指在一组数据中,出现次数最多的数。例如:1, 1, 3 中出现次数最多的数为 1,则众数为 1。
给定一组数,你能求出众数吗?
输入格式:
输入数据有多组(数据组数不超过 50)。对于每组数据:
第 1 行输入一个整数 n (1 <= n <= 10000),表示数的个数。
第 2 行输入 n 个用空格隔开的整数 Ai (0 <= Ai <= 100000),依次表示每一个数。
输出格式:
对于每组数据,在一行中输出众数以及它出的次数,中间用空格分隔。
数据保证有唯一的众数。
输入样例:
3
1 1 3
5
0 2 3 1 2
输出样例:
1 2
2 2while True:
try:
n=int(input())
ls=list(map(int,input().split()))
num=max(ls,key=ls.count)
print(num,ls.count(num))
except EOFError:
break
















 1540
1540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









