






概述:本人新手大一升大二小白,在有一点点python基础上被课题组老师要求看论文写笔记,所以要通过csdn来记录自己的所学,第一次这么干难免有疏漏,还希望大家提醒。
开始阅读:
论文标题:
MELINDA: A Multimodal Datase for Biomedical Experiment Method Classification
MELINDA:便是由加粗的字母简写过来Multimodal biomEdicaL experImeNt methoD clAssification
摘要(abstract):
本文引入了一个新的多模态生物医学实验方法分类数据集MELINDA。数据集以完全自动化的远程监督方式收集,其中标签从现有的管理数据库中获得,实际内容从与数据库中每个记录相关的论文中提取。我们对各种最先进的NLP和计算机视觉模型进行了基准测试,包括仅将标题文本或图像作为输入的单模态模型,以及多模态模型。大量的实验和分析表明,尽管多模态模型优于单模态模型,但仍然需要改进,特别是在较少监督的方式下,将视觉概念与语言结合起来,以及更好地转移到低资源领域。我们发布了我们的数据集和基准,以促进未来在多模态学习方面的研究,特别是在科学领域的应用中激励有针对性的改进。
ps:多模态与单模态的区别https://wenku.csdn.net/answer/17d8a9520af74161a517d78a644dc40f
简单来说就是:单模态需要一个特征来识别,多模态需要多个因此需要的时间就相应的更长
1 介绍(introduction):
其实读论文,要全部读懂,对于没有相当基础的同学来说是无法全部读懂的 ,所以要抓住论文的重点。
Introduction的重点就是:
- 虽然科学家可以非常准确地完成这项任务,但专家手动标记的要求阻碍了该过程的可扩展性。因此,开发先进的语言和计算机视觉多模态工具来帮助加速上述科学发现过程是势在必行的。
- 为了促进这一领域的研究,我们介绍了MELINDA,这是一个通过全自动远程监督过程创建的多模式生物医学实验方法分类数据集(Mintz et al . 2009)。具体而言,我们利用现有的生物医学数据库IntAct2 (Orchard et al . 2013)获取实验方法标签,然后从完整记录所指向的论文中适当提取实际内容,与获得的标签配对。
自己的话总结一下:手动获取生物实验方法太慢了,所以利用现有的数据集中的图像文字,通过多模态的训练与相应论文中的标签相匹配,从而获得新的数据集。
ps:如果具体了解的话,就看原文章吧,推荐几个免费阅读英文文献的软件:知云和小绿鲸,这个也是学长说的,如果 有更好的,欢迎大家补充。
2 The MELINDA Dataset:
MELINDA中数据的基本结构由一个图、与一个或多个子图相关联的子标题以及每个图顶部显示的一组精心策划的实验方法标签组成。
2.1 Data Collection Pipeline:
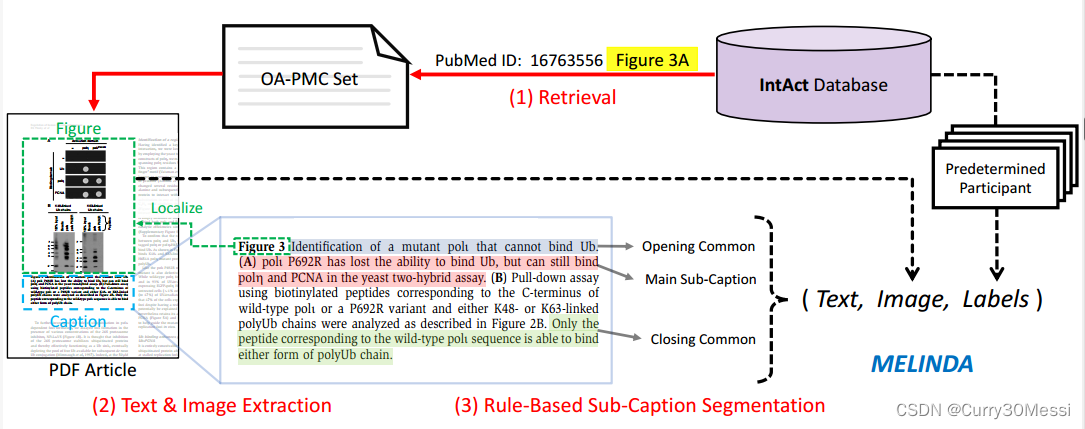
我们的收集管道是远程监督和完全自动化的。它包括三个主要步骤:(1)从完整数据库中使用PubMed id检索OA-PMC集中的PDF文章。(2)使用内部PDF解释器提取标题块,并对附近相应的图形进行定位。(3)将字幕块分割成子字幕。将所有三个步骤与成对的标签结合起来,在MELINDA数据集中得到单个数据记录。
文本和图像提取:
文本和图像内容是使用内部PDF解释器提取的,它利用每个页面上的空间索引来支持内容提取。我们在文章中提取连续的词块,并通过检测关键字“Fig”或“figure”来定位图标题。
通过在标题附近搜索具有低文本密度的大矩形区域,可以裁剪出相应的图形。请注意,尽管分类任务涉及子图,但我们没有进一步将图分割为子图,因为我们期望模型具有处理给定标题的正确子图的能力。此外,有些标题交叉引用了多个子图,因此应保留完整的图。
2.2 Data Quality Assessment
由于我们的数据集是由来自完好无损的远程监督创建的,因此如果我们将标签与相应的图形和字幕完美配对,那么专家的人类表现应该保持在100%左右。因此,数据实例的质量依赖于内容提取和配对的质量。为了估计提取内容的质量,我们随机抽取100个实例进行人工检查。在提供了相应的原始论文后,我们要求三位非领域专家注释者主要根据图像裁剪的好坏和标题提取的准确性来评估质量(结果通过多数投票计算)。以下结果的注释者间协议Fleiss’Kappa对图像的评估为0.804,对标题的评估为0.676。
2.3 Dataset Details
我们将整个数据集分成三个子集:训练集、验证集和测试集,比例为80%−10%−10%。
3 Benchmark Models
ps:benchmark一般是和同行中比较牛的算法比较,比牛算法还好,那你可以考虑发好一点的会议/期刊;baseline一般是自己算法优化和调参过程中自己和自己比较,目标是越来越好,当性能超过benchmark时,可以发表了,当性能甚至超过SOTA时,恭喜你,考虑投顶会顶刊啦。
具体来说,我们考虑单模态模型,它要么接受图像(仅图像),要么接受标题(仅字幕)作为输入,以及多模态模型,两者都接受。
3.1 Unimodal Models(单峰模型)
确实没看懂写的啥
3.2 Multimodal Models
嘻嘻,also没看懂
3.3 Training Details.
每个模型的超参数都是针对我们的数据集手动调整的,用于评估的训练模型检查点是由验证集中表现最好的模型检查点选择的。对于每种方法类型,所有模型都是独立训练的
4 Experiments and Analysis
单峰模型的注意力往往更分散,而多峰模型的显著性地图则更集中
5 Related Works
由于这些工作集中在更一般的领域,我们的工作提供了一个数据集,希望能激励那些经常需要专业知识来标记的领域的研究,比如生物医学。
在MELINDA数据集中,我们提出提取与标题文本连接的视觉信息,并收集更大规模的数据集。
数据集以及数据收集工具,进一步促进自动化生物定位的研究。我们对各种单模态和多模态模型进行了基准测试,并分析了它们的优势,提出了潜在的改进建议。
6 Conclusions and Future Work
在这项工作中,我们引入了一个新的多模态数据集MELINDA,用于生物医学实验方法分类。我们的数据集包括提取的图像标题对和相关的实验方法标签。由于我们的数据是以完全自动化的远程监督方式收集的,因此数据集易于扩展。
我们将提出的数据集与各种基线模型进行基准测试,包括最先进的视觉模型、语言模型和多模态(视觉语言学)模型。
结果表明,尽管多模态模型通常表现出优异的性能,但当前的视觉语言学基础范式仍有很大的改进空间,特别是对于特定领域的数据。
因此,我们希望这项工作能够推动未来多模态模型的发展,主要是:(1)低资源领域和更好的迁移学习。(2)少监督多模态接地方法,减少对鲁棒预训练目标检测器的依赖。
结语:
论文大概到这里就结束了,之后还有A More on The MELINDA Dataset
A , B More Details on Experiments 感兴趣的小伙伴可以自己看,主要是太多了,和论文没太大关系就没有放上来,可能后面部分感觉有点水,但是真的没看懂,我也是刚开始看论文,所以大家多包涵。
有侵权,联系我删,应该是没啥
看完论文的整体感悟:
主要贡献:
引入了一个新的多模态数据集MELINDA,用于生物医学实验方法分类。我们的数据集包括提取的图像标题对和相关的实验方法标签。由于我们的数据是以完全自动化的远程监督方式收集的
缺点:
多模态训练时间较长,繁琐,准确率虽然相对较高,但还是有待提升。
改进思路:
肯定是在图像与图像标题和相应标签的匹配、分离之中下功夫,maybe可以使用更好一点的模型,提高匹配的准确度,同时让图像标题的关键词提取更加nice,
wwwwwww,目前还想不到有什么特别创新的,就到这里吧,之后有,我会补充的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









