






原文:“HuaTuo (华驼): Tuning LLaMA Model with Chinese Medical Knowledge”
开始阅读:
摘要:
大型语言模型(llms),如LLaMA模型,已经证明了它们在各种通用领域自然语言处理(NLP)任务中的有效性。尽管如此,llms尚未在生物医学领域的任务中执行最佳,因为需要医学专业知识的响应。为了应对这一挑战,我们提出了HuaTuo(华驼),这是一个基于llama的模型,它已经通过生成的QA(问答)实例进行了监督微调。实验结果表明,华托生成的响应具有更可靠的医学知识。
ps:之后翻译中如果出现法学硕士 ,就是代指llms ,这个翻译器不太灵敏
介绍:
以ChatGPT(OpenAI, 2022)为代表的指令跟随大型语言模型(llm)的出现,由于其在理解指令和生成类似人类的反应方面的卓越表现,引起了人们的极大兴趣。与较小的模型相比,llm在各种自然语言处理(NLP)任务中表现出强大的泛化能力,并具有解决未见或复杂任务的独特应急能力。尽管ChatGPT处于非开源状态,但开源社区已经提供了几种替代方案,例如LLaMa(Touvron et al, 2023),培训成本相对较低。这将llm定位为需要沟通和推理的现实世界场景的潜在解决方案。
然而,尽管法学硕士有很多优点,但它们并不是专门为医学领域设计的。在处理这些专业领域时,他们的一般领域知识往往不足,在这些领域中,准确和特定于领域的专家知识是至关重要的。
解决这一问题的努力很少,现有的方法主要侧重于向法学硕士提供从对话中检索的医疗信息,而在对话中可能更频繁地发生人为错误。此外,法学硕士通常接受英语培训,这限制了他们对与英语有很大差异的语言(如汉语)的理解和反应能力,使得他们在中国环境中的直接应用不太理想。
在本文中,我们提出了华佗(华人驼)模型,这是一个为生物医学领域量身定制的法学硕士,专注于中文。通过基于CMeKG的医学知识生成多样化的指令数据,我们强调确保模型响应中事实的正确性,这在生物医学领域至关重要。通过这个过程,我们收集了超过8000个指令数据用于监督微调。我们的模型建立在开源的LLaMa-7B基础模型的基础上,集成了中国医学知识图谱(CMeKG)中的结构化和非结构化医学知识,并采用基于知识的指导数据进行微调。
有关cmekg的介绍:中文医学知识图谱 Chinese Medical Knowledge GraphCMeKG代码解读(以项目为导向从零开始学习知识图谱)(一)_chen_nnn的博客-CSDN博客
综上所述,我们的贡献可以总结如下:
•引入华佗模型,这是中国首个基于知识的生物医学法学硕士开源模型;
•我们整合了来自CMeKG的结构化和非结构化医学知识,确保我们的模型具有准确和特定领域的知识;
•我们提出了SUS,这是一种评估生物医学领域LMs的新指标,考虑了安全性、可用性和平滑性。
在机器学习中,LMS代表最小均方算法(Least Mean Square Algorithm)。
最小均方算法是一种用于自适应滤波和在线学习的迭代优化算法。它是一种基于梯度下降的算法,通常用于解决线性回归问题。
LMS算法的基本思想是通过减小预测输出与实际输出之间的均方误差来调整模型的参数。具体而言,它根据当前输入样本的预测输出与实际输出之间的误差,以及一个称为学习率的参数,更新模型的权重。通过迭代地应用这个更新步骤,LMS算法使模型逐渐收敛到能够更好地拟合数据的最佳权重。
LMS算法的计算速度较快且易于实现,特别适用于处理大规模数据集和在线学习的场景。然而,由于其是一种基于梯度下降的算法,可能会受到局部最小值和收敛速度慢等问题的影响。因此,在实际应用中,可以结合其他技术来进一步提高算法的性能和稳定性。
相关工作
大型语言模型
OpenAI对ChatGPT和GPT-4的开发彻底改变了人们对llm的看法。尽管这些模型表现出色,但OpenAI尚未透露有关其训练策略或权重参数的细节。
LLaMa作为GPT的开源替代方案,其大小范围从70亿个到650亿个参数。Taori等人基于指令调优的LLaMa训练羊驼。
虽然性能与GPT-3.5相当,但由于LLaMa的训练数据主要限于英语语料库,因此在中文任务上的表现低于标准。为了解决中国特定的应用,杜等人;Zeng等人介绍了GLM,这是一个具有多个训练目标的1300亿个参数的自回归预训练模型。ChatGLM进一步整合了代码训练,并通过监督微调与人类意图保持一致,为中国环境提供量身定制的解决方案。
生物医学领域的预训练模型
尽管大型语言模型(llm)在一般领域表现出卓越的性能,但它们缺乏特定领域的知识,导致在需要专业知识的领域(如生物医学)表现不佳。生物医学领域的固有性质要求模型拥有相关查询的全面知识库,特别是当应用于患者寻求健康和医疗建议的现实情况时。已经做出了一些努力,使法学硕士适应生物医学领域。
现有的方法主要使用ChatGPT进行数据辅助,并使用其提炼或翻译的知识训练较小的模型。Chatdoctor(Li et al ., 2023)首次尝试利用ChatGPT合成的对话演示对LLaMa进行微调,使llm适应生物医学领域。DoctorGLM(Xiong et al .)利用ChatGLM-6B作为基本模型,并使用ChatGPT获得的ChatDoctor数据集的中文翻译对其进行微调。此外,Chen等人在他们的法学硕士集合中开发了一个中文和医学增强语言模型。总的来说,这些作品说明了llm在生物医学领域成功应用的潜力。
华佗模型
基本模型
LLaMA (Touvron et al ., 2023)是一个多语言基模型集合,参数范围在70亿到650亿之间,对研究界开放源代码。在这里,我们采用了LLaMA-7B模型,以便更方便地进行训练。
医学知识
医学知识种类繁多,一般包括(1)结构化的医学知识,如医学知识图谱;(2)非结构化的医学知识,如医学指南。
我们使用了中国医学知识图谱CMeKG (Odmaa et al ., 2019),该图谱还提供了检索到的关于疾病、药物、症状等医学知识。表1显示了CMeKG知识库中的几个知识用例
基于知识的教学数据
在机器学习中,指令调优(Hyperparameter Tuning)是一种通过调整模型的超参数来优化模型性能的过程。
超参数是在训练机器学习模型之前需要设置的参数,它们决定了模型的结构和学习过程。与模型参数不同,超参数不能通过训练数据直接学习,而是由人为设置的。常见的超参数包括学习率、正则化参数、决策树的深度、神经网络的隐藏层节点数等。
指令调优的目标是通过尝试不同的超参数组合来找到最佳的超参数配置,以获得最好的模型性能。通常,指令调优涉及以下步骤:
定义超参数空间:确定每个超参数的可选值范围或离散选项。
选择搜索方法:选择一种搜索方法来遍历超参数空间。常见的搜索方法包括网格搜索(Grid Search)、随机搜索(Random Search)和贝叶斯优化等。
评估指标选择:选择适当的评估指标来衡量不同超参数配置下模型的性能,例如准确率、F1值、均方根误差等。
超参数搜索:使用选定的搜索方法在超参数空间中迭代搜索,并根据选择的评估指标对每个超参数组合进行评估。
选择最佳配置:根据评估指标的结果,选择具有最佳性能的超参数组合作为最终配置。
指令调优是一个重要的步骤,可以显著提高机器学习模型的性能和泛化能力。通过系统地搜索超参数空间,并根据评估指标进行比较,可以找到最佳的超参数配置,从而得到更好的模型表现。
ps:大家在机器学习领域遇到不明白的关键词,可以不用求助于搜索网站,因为给出的回答都是长篇大论的文章,很难去再仔细吃透,所以可以尝试有cahtgpt去解答,一般都会得到你满意的答案
指令调优已被证明可以有效地调优大型语言模型(Wei et al, 2022;欧阳等人,2022),这有助于模型在零射击场景下以足够的注释指令为代价取得令人满意的表现。受指令的自动构建以及实例(输入和输出)的启发(Wang et al ., 2022;Taori et al ., 2023),我们基于上述医学知识生成我们的指令数据。
如表2所示,指令调优涉及对训练实例和用自然语言描述任务的指令进行监督微调。然而,对于医学对话的大型语言模型,输入大多以问题的形式陈述,指令都是“回答下面的问题”。因此,我们处理指令,只保留华佗的输入。
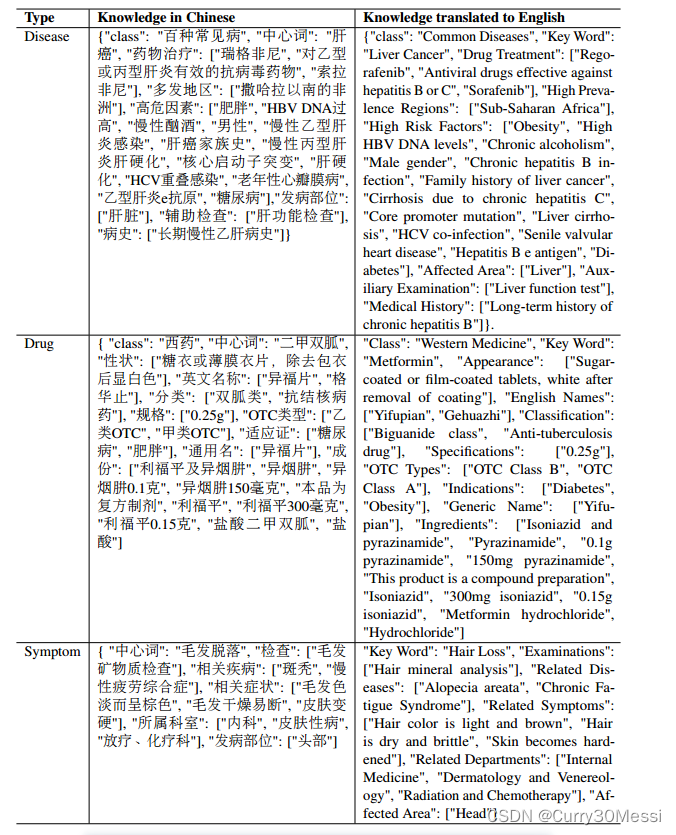
在生物医学领域,来自大型语言模型的响应中事实的正确性更受关注(Gilson et al, 2023)。因此,我们首先从知识图中采样知识实例,然后使用OpenAI API生成基于特定知识的实例(OpenAI, 2022)。最后,我们收集了超过8000个指令数据,如表3中的示例,作为监督微调的训练实例。
实验
基线
了证明华拓的优越性能,我们用四个基线模型进行了对比分析。
•LLaMA (Touvron et al ., 2023)是我们华佗的基础模型。特别是,我们采用LLaMA-7B,因为与其他基线相比,它相对公平,而且易于训练。
•Alpaca (Taori et al, 2023)是LLaMA的一个指令调优版本,在一般域中生成了超过80,000个实例。
•ChatGLM (Zeng et al ., 2023)是专门为中文聊天场景设计的优化对话模型。在我们的分析中,我们将华拓的性能与ChatGLM-6B进行了比较。
度量
对于一般领域的生成任务,使用Bleu和Rouge等评估指标来确定生成模型是否可以产生类似于地面事实的响应。
然而,对于医疗QA任务,即(1)安全性,(2)可用性,(3)流畅性。安全性决定了响应是否包含任何可能会误导使用者进入危险,比如错误的药物建议。可用性反映了特定响应的医学专业知识。平滑度表示作为语言模型的能力
结果
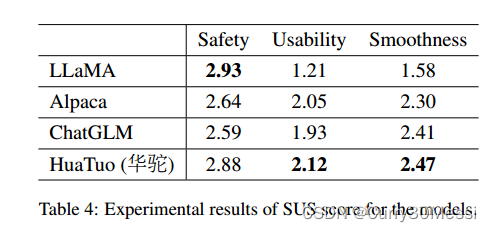
在本研究中,我们构建了中文对话场景中潜在问题的测试集,并将我们的华佗模型生成的响应与其他三个基线模型进行了比较。为了评估模型的性能,我们招募了五名具有医学背景的注释者,他们使用安全性、可用性和平滑性(SUS)的每个维度的三分制来评估模型的随机混合反应。SUS的范围从1(不可接受)到3(良好),2表示可接受的反应。平均SUS分数如表4所示。虽然LLaMA获得了最高的安全得分,但它的回答往往缺乏信息,而且问题的措辞也不准确,导致可用性得分很低。另一方面,我们的华佗模型在不影响安全性的情况下显著提高了知识可用性。
道德声明
华拓计划主要致力于研究,不打算提供医疗建议。
本研究使用的医学信息来源于一个开放获取的医学知识图谱。重要的是要注意,由大型语言模型生成的响应的准确性不能被保证。其中使用的医学知识不应被解释为替代专业医疗建议。如果遇到任何不适或痛苦,强烈建议寻求合格的医疗专业人员的指导。
自己的感想
emmmm,感觉看了有6.7篇论文了,大部分论文都是在现有的论文上进行改进,比如结合另一个论文(要么提高准确度,要么提高速度,要么提供数据集),或者把论文在某一方面研究的很深,出一个专门应用于这方面的模型(找到这方面专门的数据集),自己想出来一个全新的idea很少很少















 1531
1531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









