






在第一次打卡之后,我们大致了解了Baseline是啥以及如何跑通Baseline。
学习打卡(第一次打卡)
但这是最最基本的,这一次我们将从数据分析与可视化、模型交叉验证、特征工程三方面进一步研究
一、数据分析与可视化
数据探索性分析,是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法,从而帮助我们后期更好地进行特征工程和建立模型,是机器学习中十分重要的一步。
实践步骤:
1. 导入必要的库,特别是画图库。
2. 计算特征与标签之间的相关性,展示热力图。
3. 展示特征与标签分组统计tu。
在了解何为数据分析后,废话不多说,直接上代码:
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 读取训练集和测试集文件
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
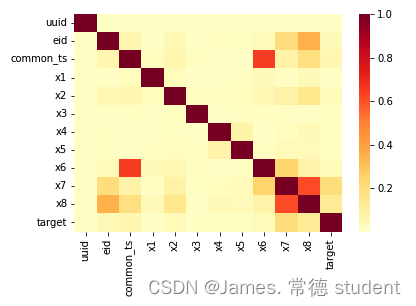
# 相关性热力图
sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')
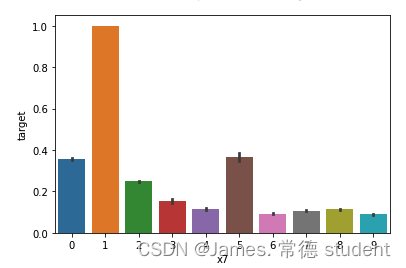
# x7分组下标签均值
sns.barplot(x='x7', y='target', data=train_data)
运行结果:
上述的代码是比较的简单的,具体有以下几个问题需要解答:
- 字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字 段的取值分析,那些字段为数值类型?那些字段为类别类型?
- 对于数值类型的字段,考虑绘制在标签分组下的箱线图。
- 从common_ts中提取小时,绘制每小时下标签分布的变化。
- 对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
其中直方图如下:
二、模型交叉验证
交叉验证(Cross-Validation)是机器学习中常用的一种模型评估方法,用于评估模型的性能和泛化能力。它的主要目的是在有限的数据集上,尽可能充分地利用数据来评估模型,避免过拟合或欠拟合,并提供对模型性能的更稳健的估计。
交叉验证的基本思想是将原始的训练数据划分为多个子集(也称为折叠),然后将模型训练和验证进行多次循环。在每一次循环中,使用其中一个子集作为验证集,其他子集作为训练集。这样可以多次计算模型的性能指标,并取这些指标的平均值作为最终的模型性能评估结果。
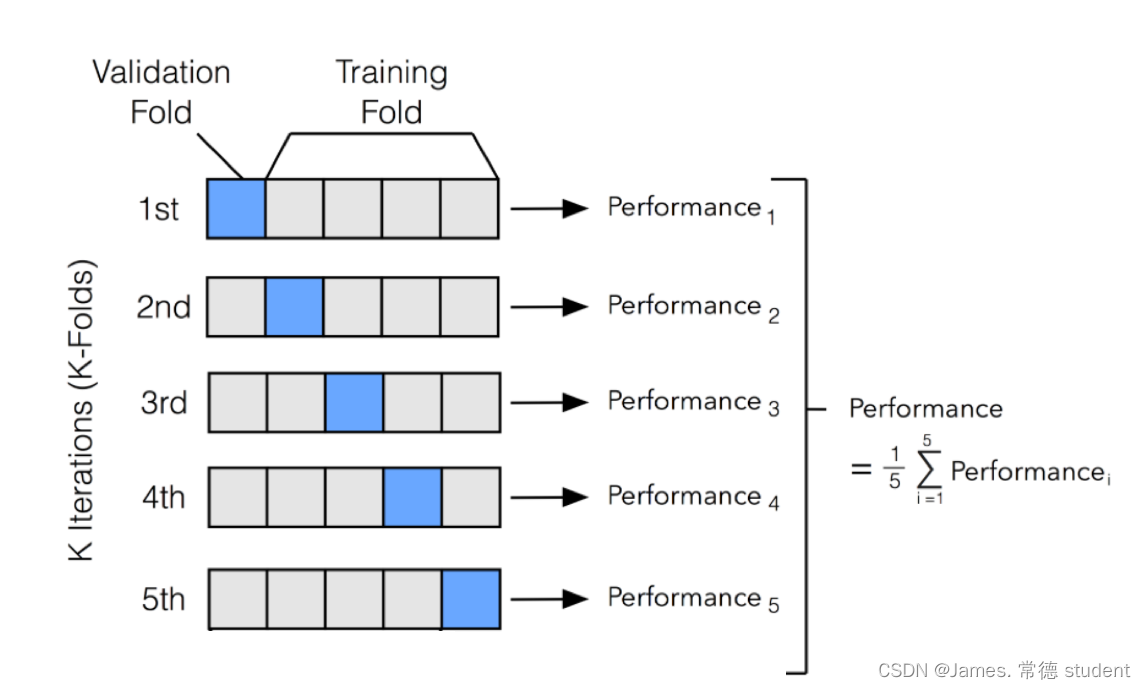
我们将按照以下步骤进行实操:
1. 加载数据集,并对数据进行编码
2. 导入多个模型进行交叉验证
3. 比较模型的F1精度
老规矩,先上代码:
# 导入库
import pandas as pd
import numpy as np
# 读取训练集和测试集文件
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
# 提取udmap特征,人工进行onehot
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d)
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 编码udmap是否为空
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# udmap特征和原始数据拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 提取eid的频次特征
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 提取eid的标签特征
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 提取时间戳
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 导入模型
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
# 导入交叉验证和评价指标
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
# 训练并验证SGDClassifier
pred = cross_val_predict(
SGDClassifier(max_iter=10),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(
DecisionTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
# 训练并验证MultinomialNB
pred = cross_val_predict(
MultinomialNB(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
# 训练并验证RandomForestClassifier
pred = cross_val_predict(
RandomForestClassifier(n_estimators=5),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
同样,代码是比较的简单的,还是有以下的问题急需解决:
1、在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
2、使用树模型训练,然后对特征重要性进行可视化;
3、再加入3个模型训练,对比模型精度;
三、特征工程
特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。
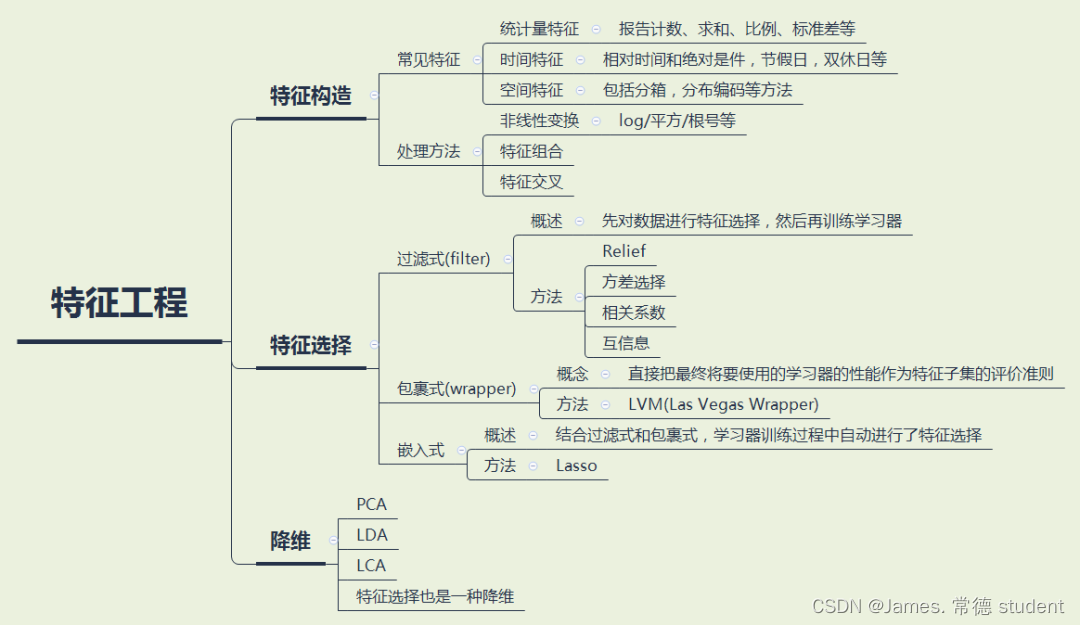
实操步骤:
1. common_ts_day 特征:从时间戳 common_ts 中提取出日期部分的天数,以创建一个新的特征表示访问日期。
2. x1_freq 和 x1_mean 特征:计算特征 x1 在训练集中的频次(出现次数)以及在训练集中对应的目标列 target 的均值。这些特征可以捕捉 x1 特征的重要性和与目标的关系。
3. 类似地,对于其他 x2、x3、x4、x6、x7 和 x8 特征,进行了类似的操作,分别计算它们在训练集中的频次和均值。
相应代码如下:
train_data['common_ts_day'] = train_data['common_ts'].dt.day
test_data['common_ts_day'] = test_data['common_ts'].dt.day
train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts())
train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean())
train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts())
train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean())
train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts())
test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts())
train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts())
test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts())
train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts())
train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean())
train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts())
train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean())
train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts())
train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean())
有以下的问题需要解决:
1、 加入特征之后模型的精度有什么变化?
2、思考并加入3个额外的特征,并观测模型精度的变化
四、总结
这是我自主学习第二次打卡了,相较于第一次,我没有了之前的迷惘与不知所措,多了对于机器学习的了解。
当然,我知道我所掌握的还远远不够,但是我会不断的学习的,争取了解到机器学习的本质。














 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









