






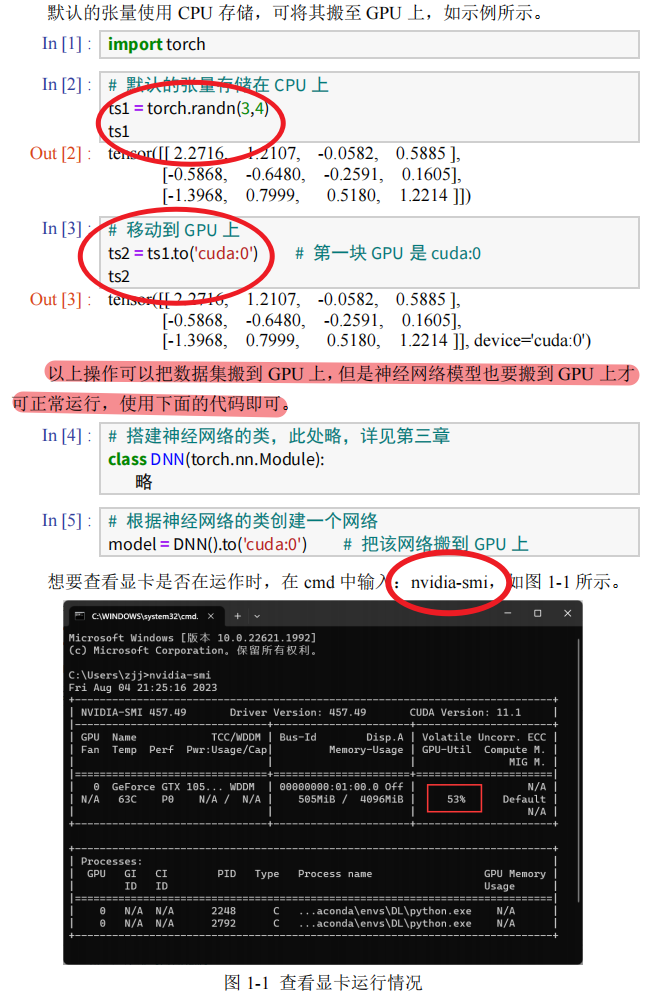
一.张量
数组与张量

从数组到张量

用GPU存储张量
二.DNN的原理
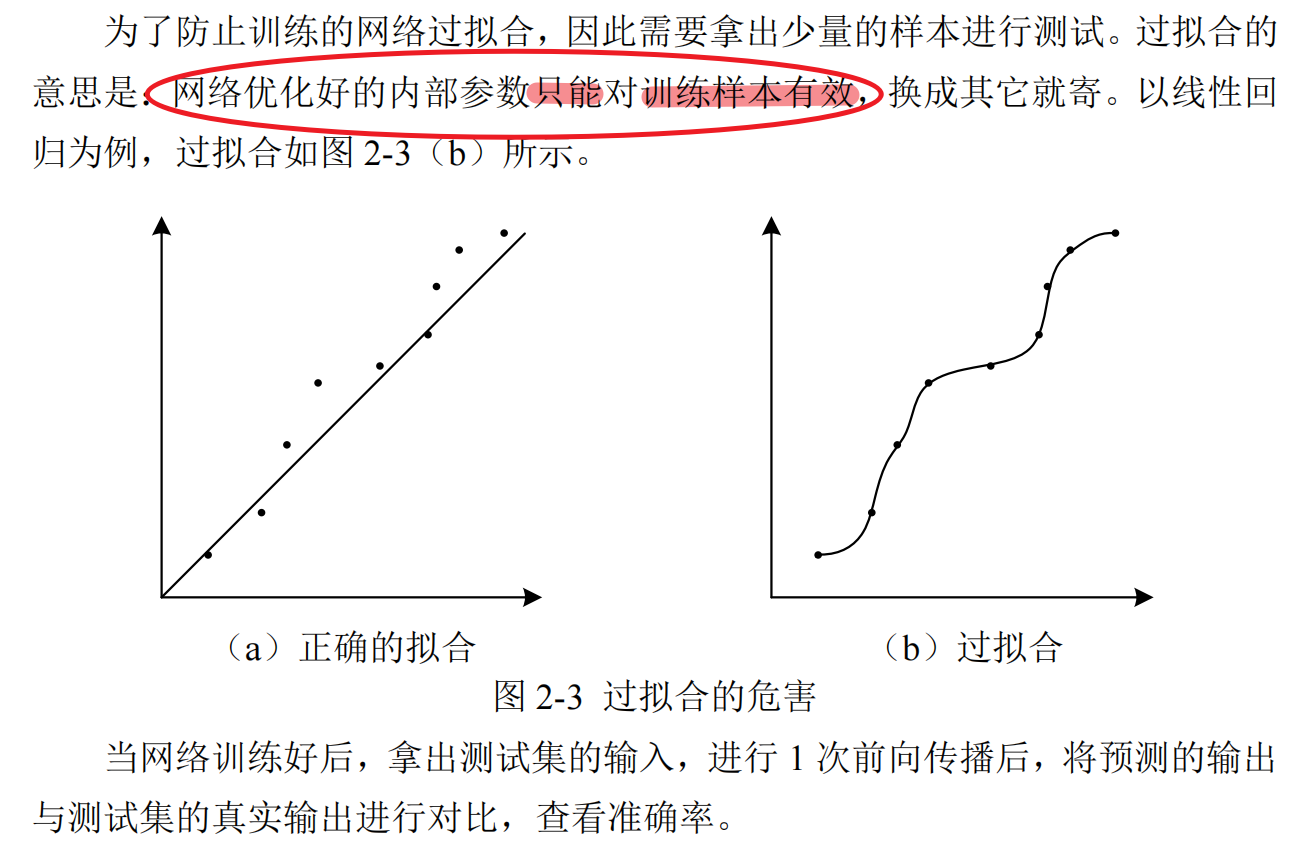
神经网络通过学习大量样本的输入与输出特征之间的关系,以拟合出输入与输出之间的方程,学习完成之后,只给他输入特征,他便会可以给出输出特征
神经网络可以分为这么几步:划分数据集、训练网络、测试网络、使用网络
划分数据集
数据集里每个样本必须包含输入与输出,将数据集按一定的比例划分为训练集与测试集,分别用于训练网络与测试网络,如表 2-1 所示。
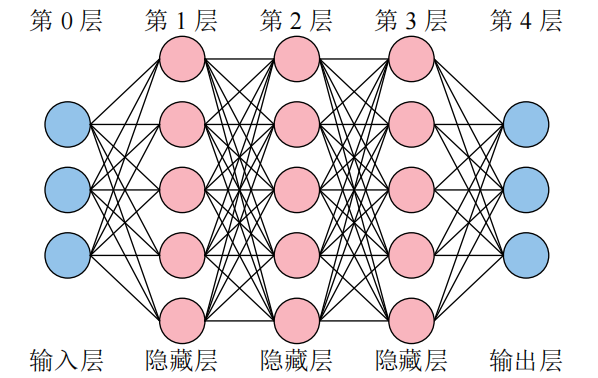
我们说下面的神经网络一共有4层
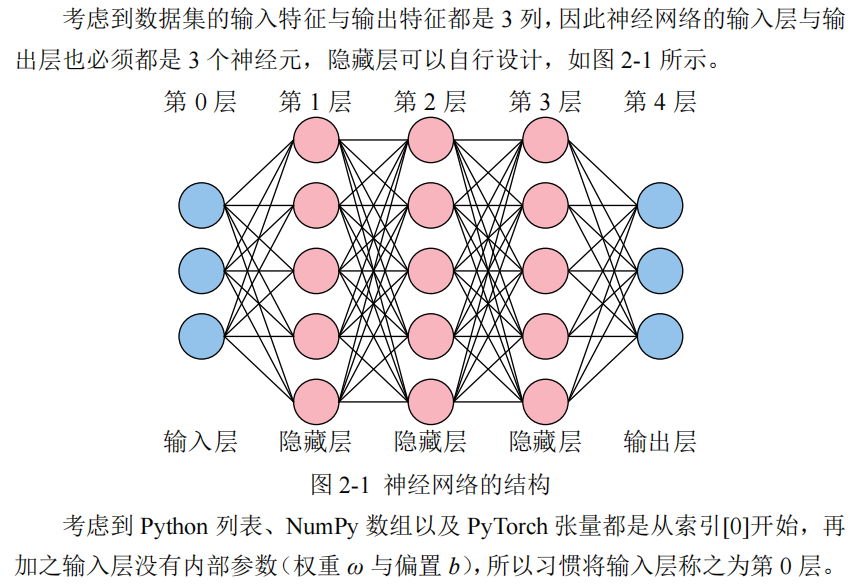
- 注意输入层是没有内部参数的
训练网络
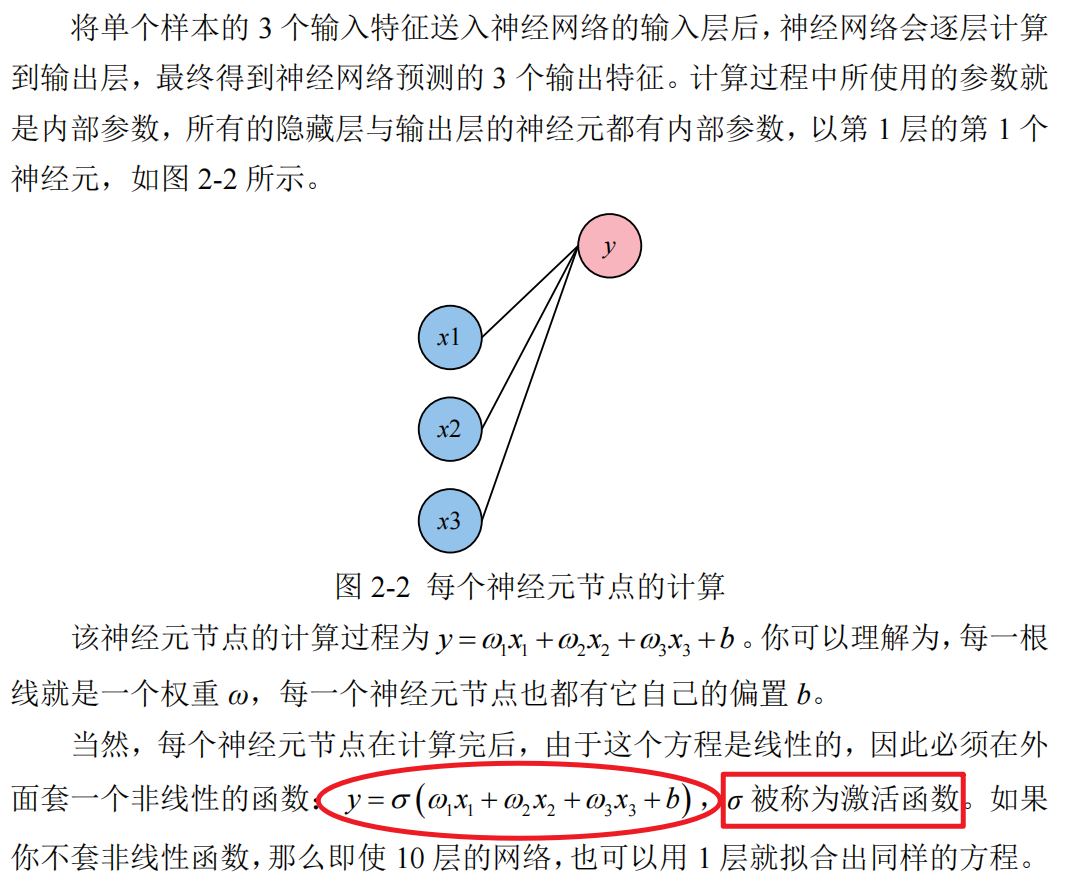
- 神经网络训练的目的就是为了优化内部参数
神经网络的训练过程,就是经过很多次前向传播与反向传播的轮回,最终不断调整其内部参数(权重 ω 与偏置 b),以拟合任意复杂函数的过程。内部参数一开始是随机的(如 Xavier 初始值、He 初始值),最终会不断优化到最佳。
还有一些训练网络前就要设好的外部参数:网络的层数、每个隐藏层的节点数、每个节点的激活函数类型、学习率、轮回次数、每次轮回的样本数等等。业界习惯把内部参数称为参数,外部参数称为超参数。
单向传播
反向传播
补充:梯度下降算法
梯度下降算法:计算损失函数最小值
随机梯度下降算法:在山谷模型当中,可能会在山谷中来回震荡陷入循环
动量:为了让点的移动更加平滑,需要保留上次的梯度(梯度是一种力)
自适应学习:自适应学习率,帮助快速收敛




以下知识只是做了解
batch_size
- 每一批的样本数量

epochs
- 英文释义(代)

测试网络
使用网络

三.DNN的实现
制作数据集
下面划分训练集和数据集的代码是固定的,可能只是名字不同

One-Hot编码
One-Hot 编码(独热编码)是一种常用于表示分类数据的编码方式。它将每个类别映射为一个向量,其中只有一个元素为 1,其余元素为 0。这个元素的位置表示类别的索引。这种编码方式主要用于机器学习和深度学习中的分类任务,其中模型需要接收数值型输入。
举个例子来说,假设有一个包含三个类别的数据集:A、B、C。对这个数据集进行 One-Hot 编码,可能会得到以下表示:
- 类别 A:[1, 0, 0]
- 类别 B:[0, 1, 0]
- 类别 C:[0, 0, 1]
每个类别对应于向量中的一个位置,而在该位置上的元素为 1,其他位置上的元素为 0。这样的表示方式使得模型能够更好地理解和处理分类信息,而不会引入不必要的数值大小关系。
在深度学习中,One-Hot 编码常常用于表示标签或目标变量。例如,在图像分类任务中,如果有三个类别(猫、狗、鸟),对应的标签可以通过 One-Hot 编码表示,便于神经网络模型的训练和预测。
In[3]负责生成数据集,并且整合数据集,把数据集搬到cuda上面

- 注意In[4]的代码属于通用性代码,用于手动分隔训练集和测试集
搭建神经网络
- 张量可以自动计算梯度,不需要出现反向传播算法(指的是在DNN函数(就是一个实现训练的函数,自己起名字为DNN)当中)

-
class DNN(nn.Module)继承父类nn.Module,self.net后面会用到,nn.Sequential()就是按照顺序搭建各层的含义
-
nn.Linear(3,5)叫做线性层,也就是全连接层,他的意思是上一层是3个结点,这一层是5个结点
-
nn.ReLu()是激活函数,激活函数一般有
- ReLu():Rectified Linear Unit 线性修正单元
- Sigmoid()
- Tanh()


网络的内部参数

神经网络结构
DNN()实例

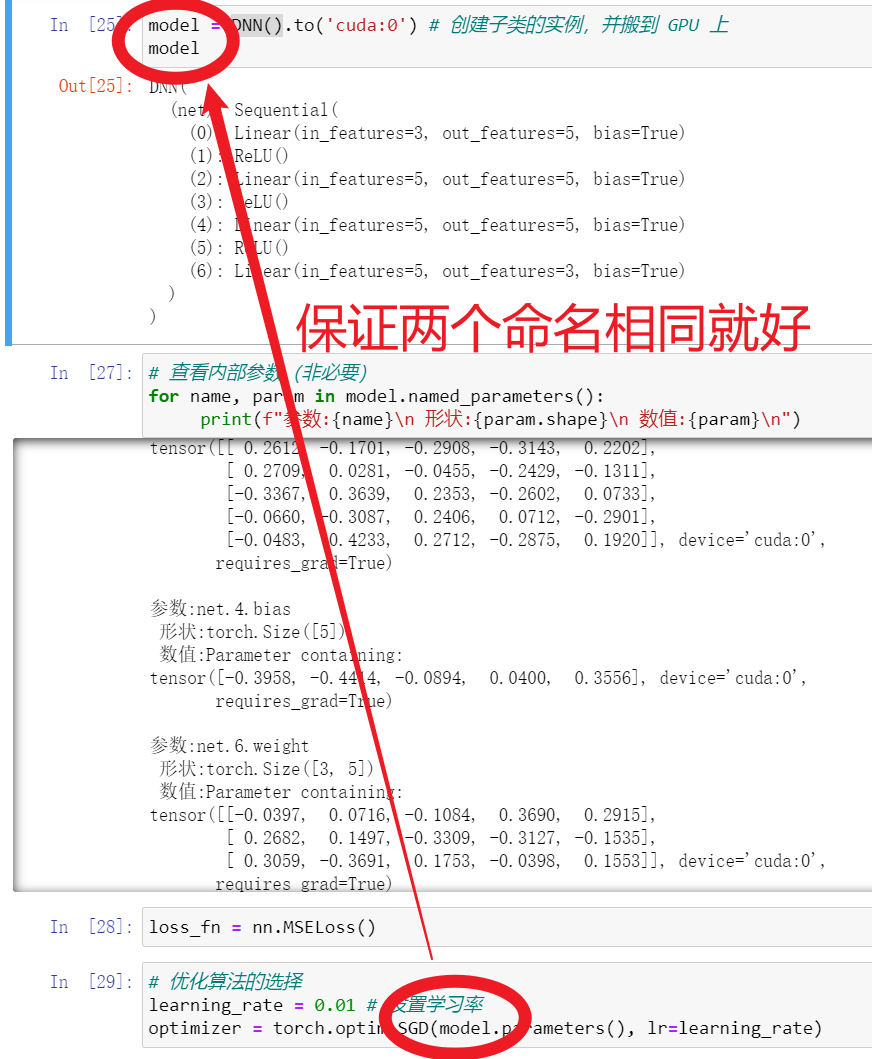
# 查看内部参数(非必要)
for name, param in model.named_parameters():
print(f"参数:{name}\n 形状:{param.shape}\n 数值:{param}\n")
参数:net.0.weight
形状:torch.Size([5, 3]) #说明net.0.weight这个参数有五行三列
数值:Parameter containing:
tensor([[ 0.3487, 0.0031, -0.4867],
[-0.1128, 0.0894, 0.2482],
[ 0.3332, -0.0184, -0.4869],
[ 0.3095, 0.2844, 0.4761],
[ 0.5366, 0.5117, -0.4424]], device='cuda:0', requires_grad=True)
参数:net.0.bias
形状:torch.Size([5]) #说明net.0.bias 这个参数有五个
数值:Parameter containing:
tensor([-0.4645, 0.2543, 0.3377, 0.1286, 0.2811], device='cuda:0',
requires_grad=True)
参数:net.2.weight
形状:torch.Size([5, 5])
数值:Parameter containing:
tensor([[ 0.1670, -0.1228, -0.1247, 0.1910, 0.2468],
[-0.2924, -0.0738, 0.1773, 0.0482, 0.1916],
[-0.1906, -0.3884, 0.2374, 0.2316, -0.0608],
[-0.1414, 0.1924, -0.3110, -0.3546, 0.0166],
[ 0.0716, 0.0218, -0.2343, -0.2540, -0.1128]], device='cuda:0',
requires_grad=True)
参数:net.2.bias
形状:torch.Size([5])
数值:Parameter containing:
tensor([ 0.4347, -0.0419, 0.2639, -0.4317, 0.0743], device='cuda:0',
requires_grad=True)
参数:net.4.weight
形状:torch.Size([5, 5])
数值:Parameter containing:
tensor([[ 0.2612, -0.1701, -0.2908, -0.3143, 0.2202],
[ 0.2709, 0.0281, -0.0455, -0.2429, -0.1311],
[-0.3367, 0.3639, 0.2353, -0.2602, 0.0733],
[-0.0660, -0.3087, 0.2406, 0.0712, -0.2901],
[-0.0483, 0.4233, 0.2712, -0.2875, 0.1920]], device='cuda:0',
requires_grad=True)
参数:net.4.bias
形状:torch.Size([5])
数值:Parameter containing:
tensor([-0.3958, -0.4414, -0.0894, 0.0400, 0.3556], device='cuda:0',
requires_grad=True)
参数:net.6.weight
形状:torch.Size([3, 5])
数值:Parameter containing:
tensor([[-0.0397, 0.0716, -0.1084, 0.3690, 0.2915],
[ 0.2682, 0.1497, -0.3309, -0.3127, -0.1535],
[ 0.3059, -0.3691, 0.1753, -0.0398, 0.1553]], device='cuda:0',
requires_grad=True)
参数:net.6.bias
形状:torch.Size([3])
数值:Parameter containing:
tensor([-0.2941, -0.4139, -0.0707], device='cuda:0', requires_grad=True)
网络的外部参数

(1)激活函数
https://pytorch.org/docs/1.12/nn.html
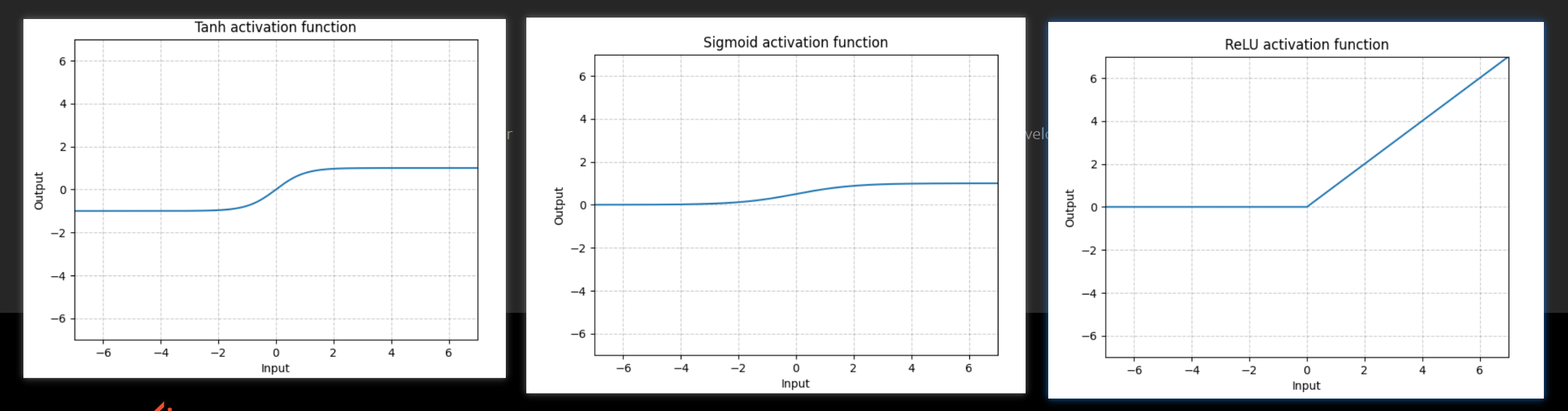
上面的地址有很多种激活函数等我们选择,不过我们一般选的都是非线性的ReLu,Sigmoid,tanh,搜索Non-linear Activations
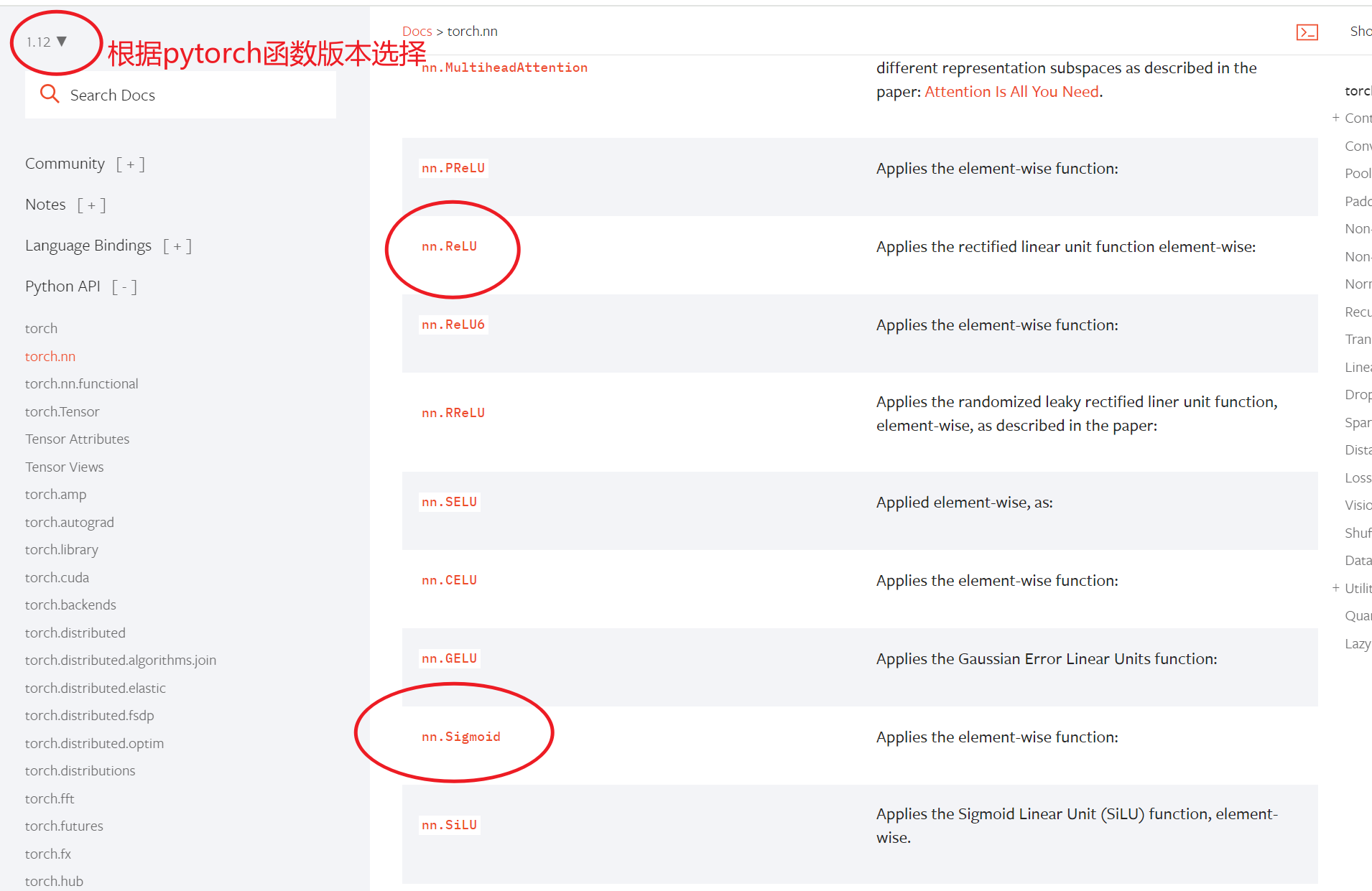
从官网上查到下面三个函数的图像分别如下
(2)损失函数
进入网址搜索Loss Function
https://pytorch.org/docs/1.12/nn.html
(3)学习率与优化算法
https://pytorch.org/docs/1.12/optim.html

训练网络
range(epochs)就是[0,1,2,3,4,5…epochs]的一个列表
下面的for循环中的代码基本是固定的
# 训练网络
epochs = 1000
losses = [] # 记录损失函数变化的列表
# 给训练集划分输入与输出
X = train_Data[ : , :3 ] # 前 3 列为输入特征
Y = train_Data[ : , -3: ] # 后 3 列为输出特征
for epoch in range(epochs):
Pred = model(X) # 一次前向传播(批量)
loss = loss_fn(Pred, Y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
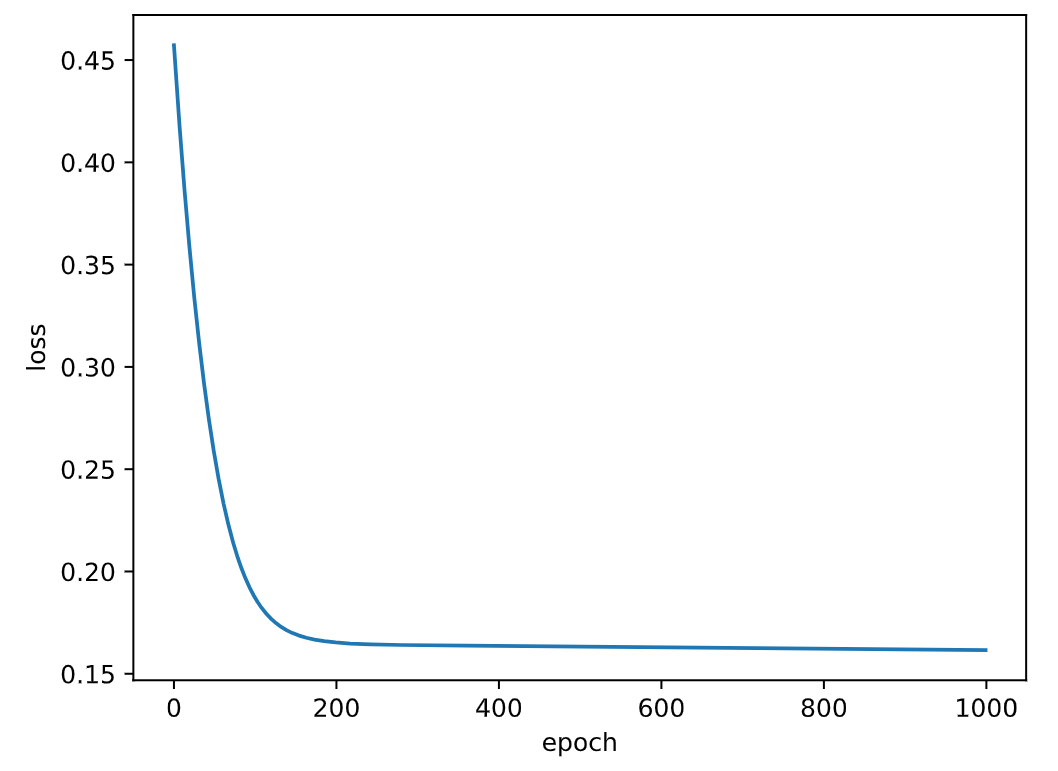
Fig = plt.figure()
plt.plot(range(epochs), losses)
plt.ylabel('loss'), plt.xlabel('epoch')
plt.show()
测试网络

# 测试网络
# 给测试集划分输入与输出
X = test_Data[:, :3] # 前 3 列为输入特征
Y = test_Data[:, -3:] # 后 3 列为输出特征
with torch.no_grad(): # 该局部关闭梯度计算功能
Pred = model(X) # 一次前向传播(批量)
Pred[:,torch.argmax(Pred, axis=1)] = 1
Pred[Pred!=1] = 0
correct = torch.sum( (Pred == Y).all(1) ) # 预测正确的样本
total = Y.size(0) # 全部的样本数量
print(f'测试集精准度: {100*correct/total}%')
保存和导入网络

(1)保存网络
通过“torch.save(模型名, ‘文件名.pth’)”命令,可将该模型完整的保存至Jupyter 的工作路径下。
# 保存网络
torch.save(model, 'model.pth')
(2)导入网络
通过“新网络 = torch.load('文件名.pth ')”命令,可将该模型完整的导入给新网络。
# 把模型赋给新网络
new_model = torch.load('model.pth')
现在,new_model 就与 model 完全一致,可以直接去跑测试集。
(3)用新模型进行测试
# 测试网络
# 给测试集划分输入与输出
X = test_Data[:, :3] # 前 3 列为输入特征
Y = test_Data[:, -3:] # 后 3 列为输出特征
with torch.no_grad(): # 该局部关闭梯度计算功能
Pred = model(X) # 一次前向传播(批量)
Pred[:,torch.argmax(Pred, axis=1)] = 1
Pred[Pred!=1] = 0
correct = torch.sum( (Pred == Y).all(1) ) # 预测正确的样本
total = Y.size(0) # 全部的样本数量
print(f'测试集精准度: {100*correct/total}%')
四.批量梯度下降
制作数据集



# 准备数据集
df = pd.read_csv('Data.csv', index_col=0) # 导入数据
arr = df.values # Pandas 对象退化为 NumPy 数组
arr = arr.astype(np.float32) # 转为 float32 类型数组
ts = torch.tensor(arr) # 数组转为张量
ts = ts.to('cuda') # 把训练集搬到 cuda 上
ts.shape
# 划分训练集与测试集
train_size = int(len(ts) * 0.7) # 训练集的样本数量
test_size = len(ts) - train_size # 测试集的样本数量
ts = ts[ torch.randperm( ts.size(0) ) , : ] # 打乱样本的顺序
train_Data = ts[ : train_size , : ] # 训练集样本
test_Data = ts[ train_size : , : ] # 测试集样本
train_Data.shape, test_Data.shape
搭建神经网络

class DNN(nn.Module):
def __init__(self):
''' 搭建神经网络各层 '''
super(DNN, self).__init__()
self.net = nn.Sequential( # 按顺序搭建各层
nn.Linear(8, 32), nn.Sigmoid(), # 第 1 层:全连接层
nn.Linear(32, 8), nn.Sigmoid(), # 第 2 层:全连接层
nn.Linear(8, 4), nn.Sigmoid(), # 第 3 层:全连接层
nn.Linear(4, 1), nn.Sigmoid() # 第 4 层:全连接层
)
def forward(self, x):
''' 前向传播 '''
y = self.net(x) # x 即输入数据
return y # y 即输出数据
model = DNN().to('cuda:0') # 创建子类的实例,并搬到 GPU 上
model
训练网络
# 损失函数的选择
loss_fn = nn.BCELoss(reduction='mean')
# 优化算法的选择
learning_rate = 0.005 # 设置学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练网络
epochs = 5000
losses = [] # 记录损失函数变化的列表
# 给训练集划分输入与输出
X = train_Data[ : , : -1 ] # 前 8 列为输入特征
Y = train_Data[ : , -1 ].reshape((-1,1)) # 后 1 列为输出特征
# 此处的.reshape((-1,1))将一阶张量升级为二阶张量
# 因为X是二阶,那么待会儿的Pred也是二阶,为了让Y与Pred的形状一致
for epoch in range(epochs):
Pred = model(X) # 一次前向传播(批量)
loss = loss_fn(Pred, Y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
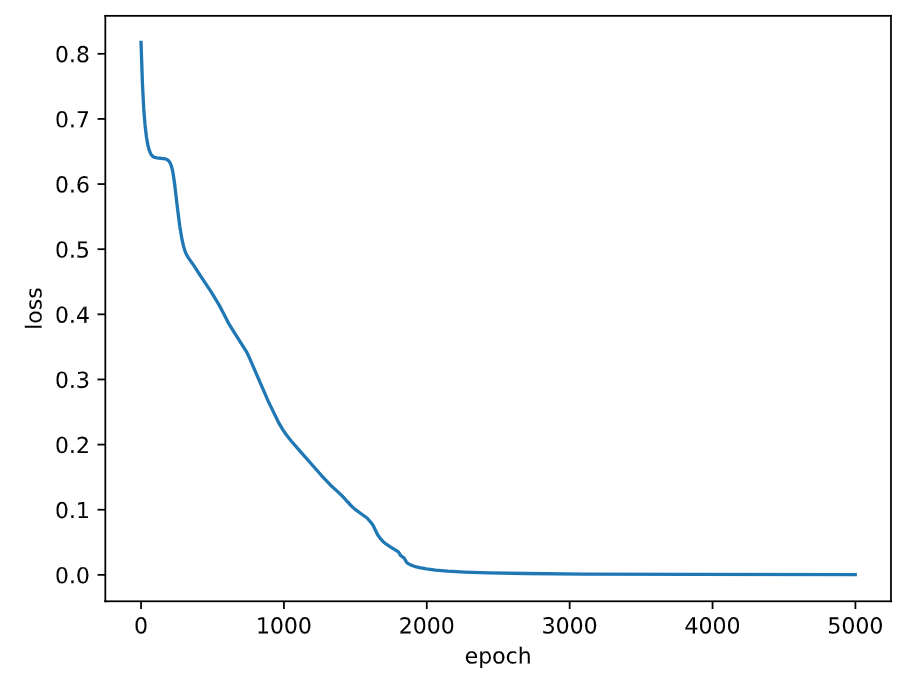
Fig = plt.figure()
plt.plot(range(epochs), losses)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
测试网络

# 测试网络
# 给测试集划分输入与输出
X = test_Data[ : , : -1 ] # 前 8 列为输入特征
Y = test_Data[ : , -1 ].reshape((-1,1)) # 后 1 列为输出特征
with torch.no_grad(): # 该局部关闭梯度计算功能
Pred = model(X) # 一次前向传播(批量)
Pred[Pred>=0.5] = 1
Pred[Pred<0.5] = 0
correct = torch.sum( (Pred == Y).all(1) ) # 预测正确的样本
total = Y.size(0) # 全部的样本数量
print(f'测试集精准度: {100*correct/total} %')
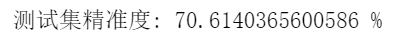
五.小批量梯度下降
- 注意下面得到三个工具

import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import random_split
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
制作数据集

# 制作数据集
class MyData(Dataset): # 继承 Dataset 类
def __init__(self, filepath):
df = pd.read_csv(filepath, index_col=0) # 导入数据
arr = df.values # 对象退化为数组
arr = arr.astype(np.float32) # 转为 float32 类型数组
ts = torch.tensor(arr) # 数组转为张量
ts = ts.to('cuda') # 把训练集搬到 cuda 上
#下面三行是为了下面的两个方法服务的
self.X = ts[:, : -1] # 前 8 列为输入特征
self.Y = ts[:, -1].reshape((-1, 1)) # 后 1 列为输出特征
self.len = ts.shape[0] # 样本的总数
def __getitem__(self, index):
# 用来获取数据索引
return self.X[index], self.Y[index]
def __len__(self):
# 用来获取数据总量
return self.len
# 划分训练集与测试集
Data = MyData('Data.csv')
train_size = int(len(Data) * 0.7) # 训练集的样本数量
test_size = len(Data) - train_size # 测试集的样本数量
train_Data, test_Data = random_split(Data, [train_size, test_size])
# 批次加载器
train_loader = DataLoader(dataset=train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(dataset=test_Data, shuffle=False, batch_size=64)

搭建神经网络
class DNN(nn.Module):
def __init__(self):
''' 搭建神经网络各层 '''
super(DNN,self).__init__()
self.net = nn.Sequential( # 按顺序搭建各层
nn.Linear(8, 32), nn.Sigmoid(), # 第 1 层:全连接层
nn.Linear(32, 8), nn.Sigmoid(), # 第 2 层:全连接层
nn.Linear(8, 4), nn.Sigmoid(), # 第 3 层:全连接层
nn.Linear(4, 1), nn.Sigmoid() # 第 4 层:全连接层
)
def forward(self, x):
''' 前向传播 '''
y = self.net(x) # x 即输入数据
return y # y 即输出数据
训练网络
# 损失函数的选择
loss_fn = nn.BCELoss(reduction='mean')
# 优化算法的选择
learning_rate = 0.005 # 设置学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练网络
epochs = 500
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):
for (x, y) in train_loader: # 获取小批次的 x 与 y
Pred = model(x) # 一次前向传播(小批量)
loss = loss_fn(Pred, y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
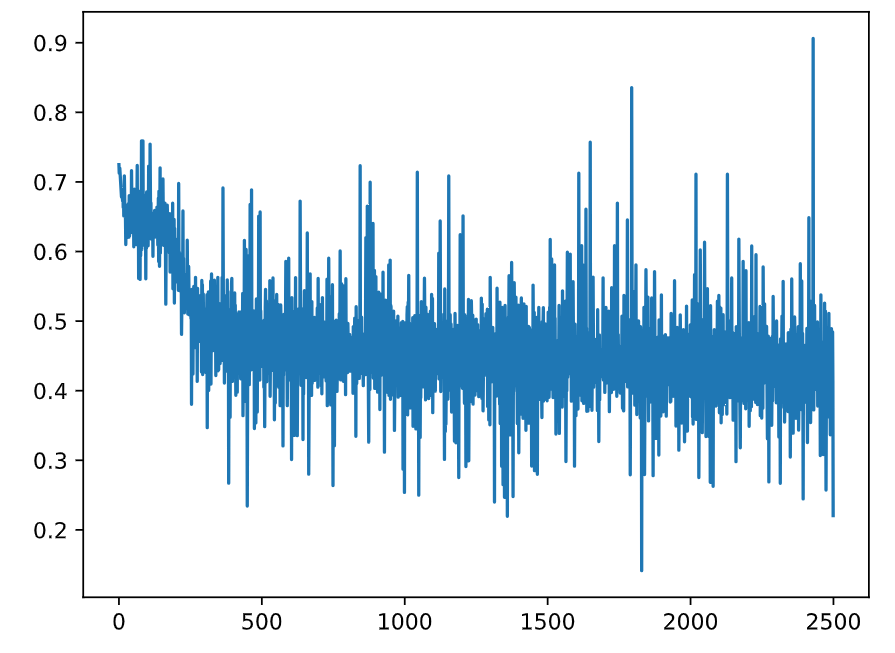
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能
for (x, y) in test_loader: # 获取小批次的 x 与 y
Pred = model(x) # 一次前向传播(小批量)
Pred[Pred>=0.5] = 1
Pred[Pred<0.5] = 0
correct += torch.sum( (Pred == y).all(1) )
total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')

六.手写数字识别
==手写数字识别数据集(MNIST)==是机器学习领域的标准数据集,它被称为机器学习领域的“Hello World”,只因任何 AI 算法都可以用此标准数据集进行验。MNIST 内的每一个样本都是一副二维的灰度图像,如图 6-1 所示。

二维是灰度图 三维就是彩图
在 MNIST 中,模型的输入是一副图像,模型的输出就是一个与图像中对应的数字(0 至 9 之间的一个整数,不是独热编码)。我们不用手动将输出转换为独热编码,PyTorch 会在整个过程中自动将数据集的输出转换为独热编码.只有在最后测试网络时,我们对比测试集的预测输出与真实输出时,才需要注意一下。某一个具体的样本如图 6-2 所示,每个图像都是形状为 28*28 的二维数组。

在这种多分类问题中,神经网络的输出层需要一个 softmax 激活函数,它可以把输出层的数据归一化到 0-1 上,且加起来为 1,这样就模拟出了概率的意思
制作数据集

import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
在下载数据集之前,要设定转换参数:transform,该参数里解决两个问题:
⚫ ToTensor:将图像数据转为张量,且调整三个维度的顺序为 CWH;C表示通道数,二维灰度图像的通道数为 1,三维 RGB 彩图的通道数为 3。
⚫ Normalize:将神经网络的输入数据转化为标准正态分布,训练更好;==根据统计计算,MNIST 训练集所有像素的均值是 0.1307、标准差是 0.3081。==将正态分布转换为标准正态分布,就是用样本减去均值除以标准差
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.MNIST(
root = 'D:/Jupyter/dataset/mnist/', # 下载路径
train = True, # 是 train 集
download = True, # 如果该路径没有该数据集,就下载
transform = transform # 数据集转换参数
)
test_Data = datasets.MNIST(
root = 'D:/Jupyter/dataset/mnist/', # 下载路径
train = False, # 是 test 集
download = True, # 如果该路径没有该数据集,就下载
transform = transform # 数据集转换参数
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=64)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=64)
搭建神经网络

class DNN(nn.Module):
def __init__(self):
''' 搭建神经网络各层 '''
super(DNN, self).__init__()
self.net = nn.Sequential( # 按顺序搭建各层
nn.Flatten(), # 把图像铺平成一维
nn.Linear(784, 512), nn.ReLU(), # 第 1 层:全连接层
nn.Linear(512, 256), nn.ReLU(), # 第 2 层:全连接层
nn.Linear(256, 128), nn.ReLU(), # 第 3 层:全连接层
nn.Linear(128, 64), nn.ReLU(), # 第 4 层:全连接层
nn.Linear(64, 10) # 第 5 层:全连接层
)
def forward(self, x):
''' 前向传播 '''
y = self.net(x) # x 即输入数据
return y # y 即输出数据
model = DNN().to('cuda:0') # 创建子类的实例,并搬到 GPU 上
model

训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.01 # 设置学习率
optimizer = torch.optim.SGD(
model.parameters(),
lr = learning_rate,
momentum = 0.5
)

# 训练网络
epochs = 5
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):
for (x, y) in train_loader: # 获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0') # 把小批次搬到GPU上
Pred = model(x) # 一次前向传播(小批量)
loss = loss_fn(Pred, y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
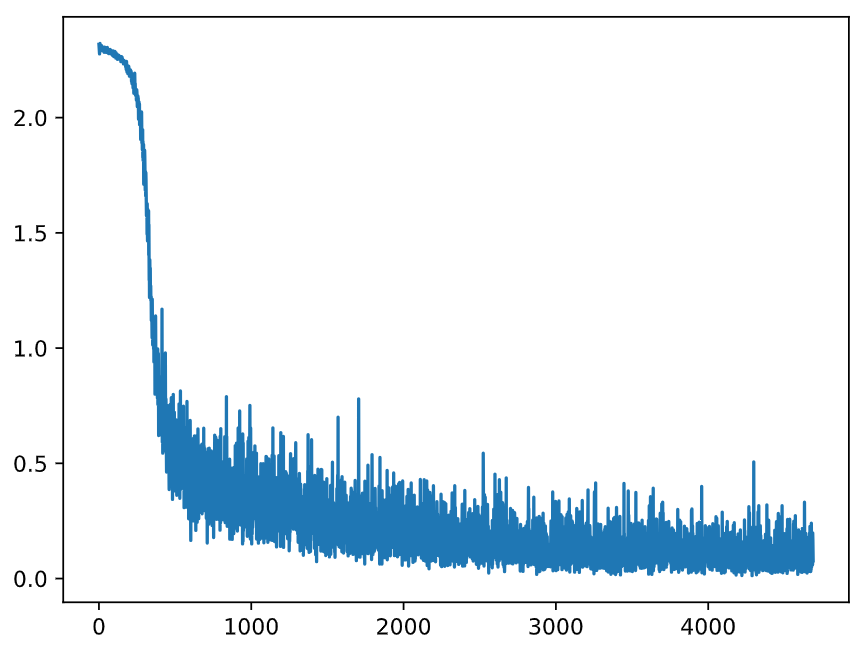
注意,由于数据集内部进不去,只能在循环的过程中取出一部分样本,就立即将之搬到 GPU 上。
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能
for (x, y) in test_loader: # 获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0') # 把小批次搬到GPU上
Pred = model(x) # 一次前向传播(小批量)
_, predicted = torch.max(Pred.data, dim=1)
correct += torch.sum( (predicted == y) )
total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')




















 7561
7561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









