






源码文件:
链接: https://pan.baidu.com/s/1j4ny5voep7tUpz7u2gSl_Q?pwd=2hmg 提取码: 2hmg
系列合集:
人工智能原理基础——仅用中学数学知识就能看懂(上篇)
- 上篇:代价函数、梯度下降、前向/反向传播、激活函数、keras、深度学习入门
- 中篇:卷积神经网络及实战
- 下篇:循环神经网络及实战
十、卷积神经网络(上)
打破图像识别的瓶颈
原理
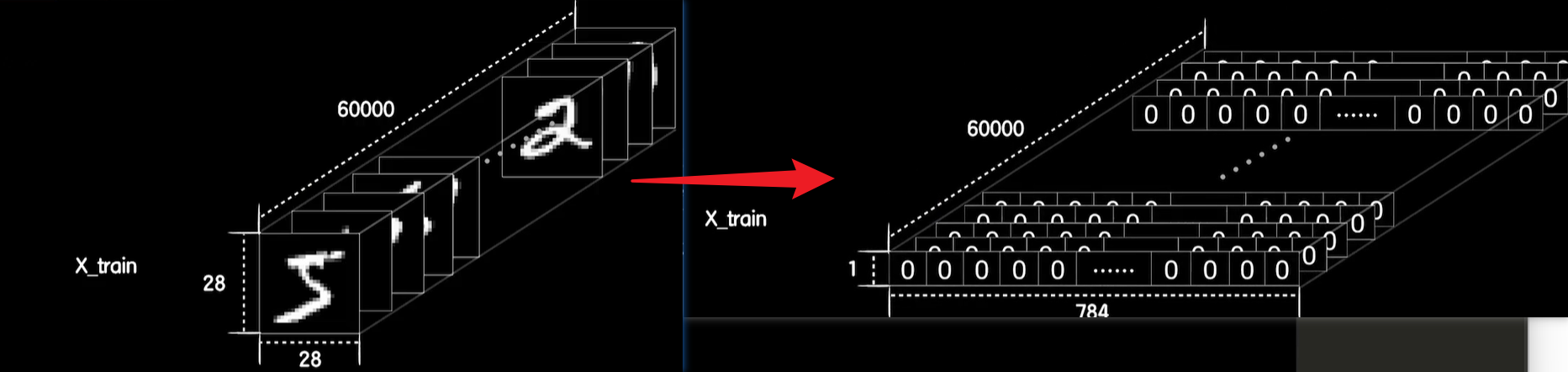
1、在机器学习神经网络领域,对于不想过多了解底层原理的初学者而言,其实有一个应用层面一般意义上的经典hello word,那就是手写体识别,因为其场景和问题都很简单明确,更有经典的数据集mnist成为了众多入门者必备的实践项目。mnist的数据集的图片采用的是28×28的灰度图。灰度图显示图像的原理是这样的:一行有28个像素点,一共有28行,每个像素用一个字节的无符号数表示它的等级,如果是0那就是最暗纯黑色,如果是一个字节的最大值255,那么就是最亮的纯白色,如果是中间的值,那就是介于两者之间的灰色,我们通过让不同像素点的灰度值不同而达到显示的效果。

比如显示在屏幕上的规规矩矩的数字“5”,数字“3”,无趣的是,如果用键盘输入这些数字图像,那么判断起来没有任何的难度,因为精确的计算机在显示同一个字符的时候,每一次每个像素点的灰度值都是一样的,但人毕竟不同于精准,但呆板的计算机,比如我们拿一支手写笔在28×28的屏幕上手写,数字5第一次可能和下一次写的不一样,甚至每一次都不太一样,这时候也就没有什么确定的规则去根据这些像素的灰度值判断是什么数字了。换句话说,这不再是一个适用于计算机机械逻辑做判断的问题,我们需要用有一定容错能力的系统来做这件事情,很明显神经网络是一个很好的选择,我们已经知道如何搭建一个神经网络,现在唯一的问题是如何把这些图片送入其中,神经网络的输入是一个多维的向量或者说一个数组,而图片是一个方形的像素灰度值的集合。
没错,我们把这些像素从头到尾一行一行的依次拉出来就好,mnist的数据集每张图片的尺寸是28×28,所以这张拉出784个像素,每个像素都是一个灰度值,所以这将形成一个784维的向量,或者说一个有784个元素的数组,我们只需要把mnist的数据集中每个手写体的图片都变成这样的784个元素的数组,依次送进一个神经网络进行训练就好。最开始人们利用深度全连接神经网络取得了不错的效果,但并不十分的好。在机器学习的工作流程中,我们在训练时使用的数据集称之为训练集,当然我们希望在训练集上的准确率很高,这意味着模型拟合的效果很棒,但我们会在训练之后,在训练集数据之外,拿一些新的数据进行预测,看看这些新的数据在模型上的准确率如何,这些用来测试的样本数据称之为测试集,我们希望在测试集上的准确率也很高,实际上我们在考量一个模型好坏的时候,更倾向于它在测试集上的表现。因为在测试集上的高准确率意味着模型在遇到训练中没有遇到过的新问题时,也能很准确的进行预测,换句话说这个模型有足够的泛化能力,而模型在训练集和测试集上的不同表现,也就导致了机器学习中三种常见的现象:
-
第一,如果在训练集上的准确率都很低,这个模型多半是废了,这种现象称之为欠拟合,可能是因为模型太过简单,比如我们之前说过用一个神经元试图拟合弯曲分布的数据,这是行不通的。
-
第二,如果在训练集上的准确率很高,而且在测试集上的准确率也很高,并且相差不大,那说明这个模型通过训练又有了很好的泛化能力去解决新的问题。
-
第三,如果在训练集上的准确率很高,但是在测试集上的准确率却出现了明显的下降,说明这个模型的泛化能力不行,也就很难推而广之的进行实际应用,这种现象我们称之为过拟合。
-
导致过拟合的原因有很多,比如我们用一个过分复杂的模型去拟合一些实则比较简单的问题,我们以豆豆的数据集举个例子这是训练集,这是测试集,我们在训练集上反复的训练,最后得到下图结果,这时候在训练集上的准确率已经相当的高了,几乎百分之百,但遗憾的是,当我们把这个模型应用到测试集上,准确率就出现了明显的下降,直观上我们能看出来,正是因为在训练集上追求过分精确的拟合,导致模型在新的问题中表现反倒没有那么的好。
-
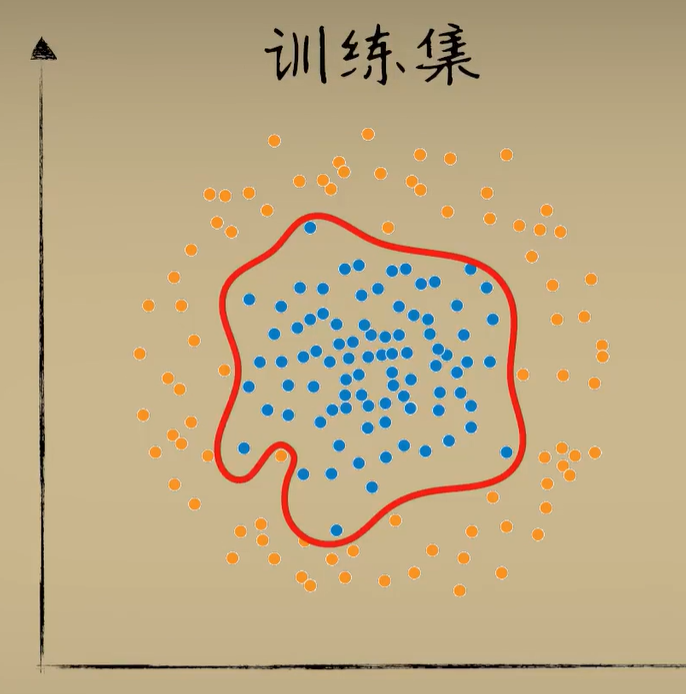
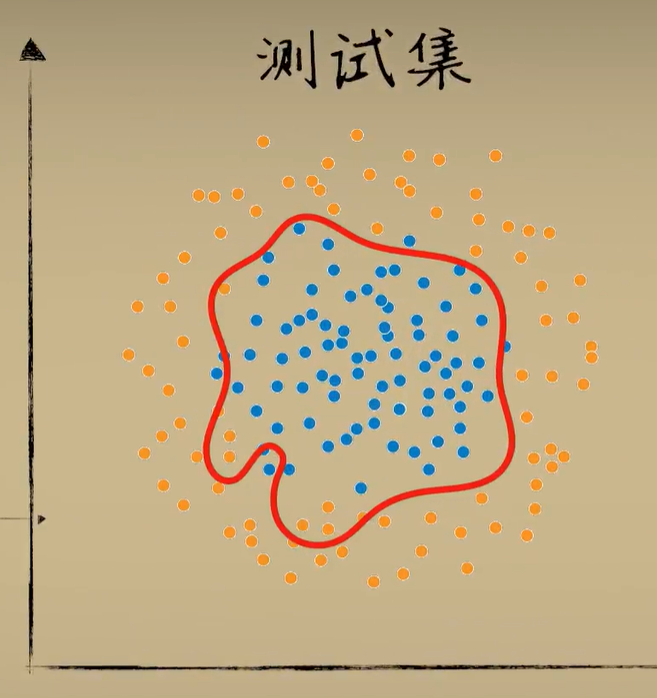
-
如果类比到人类的学习过程的话,这种学习效果很像在习题中死记硬背,而不是理解问题,或者说钻牛角尖想多了,而测试题就像考试就出现了平时习题没少写,结果考试成绩并不理想的情况,因为模型不够泛化,或者说没有很好的把握事物的主要矛盾,解决神经网络中过拟合的现象也有很多方式,比如调整神经网络的结构,L二正则化,节点失活正则化等等。
-
调整神经网络的结构:过拟合往往发生在模型过于复杂时(例如层数过多、神经元过多),导致模型“记住”了训练数据中的噪声而非学习通用模式。 通过简化网络结构,可以降低模型的容量,从而减少过拟合。
-
L2正则化:通过在损失函数中添加权重参数的平方和惩罚项(λ∑w^2),限制模型权重过大,从而防止模型过于复杂,减少对训练数据噪声的过度拟合。
-
节点失活正则化:是一种在训练过程中随机“丢弃”(失活)一部分神经元的技术,迫使网络不依赖特定的神经元,从而提高泛化能力。 测试时所有神经元都参与计算,但输出会按失活比例缩放。
-
-
-
第四,训练集的准确率很低,但测试集的准确率却很高,从概率上来说,这种见鬼的情况几乎不存在。
mnist的数据集有6万个训练集样本和1万个测试集样本,而人们发现在用全连接神经网络做mnist的数据集识别以及其他图像识别的时候,尽管我们已经把网络堆叠的越来越深,神经元的数量也越来越多,也用尽了各种防止过拟合的方法,但网络的泛化能力仍然越来越难有所突破。
2、打败神经网络能力陷入内卷的方式是另外一种卷法——卷积,即使是早在1998年就被提出的经典的卷积神经网络LeNet-5也让测试集的准确率达到了99.2%,而2012年更是把准确率提高到了99.77%,为什么卷积有这么好的效果?首先,我们需要知道,卷积是怎样工作的。
请问这是什么?请问这又是什么?
你不知道也没有人知道,这实际上是把一个图像的像素变成数组之后的样子,而当我们还原之后没有人不知道这是一个茶杯,这是一个口罩,所以作为人我们在识别一个图片内容的时候,如果看到的是一个个像素连接起来的数组,那是很难作出判断的,当然也不是完全不可能比如死记硬背的记住这些数据的样子。

但这又是什么?

不错,这还是茶杯,但是你还是很难作出判断。

实际上我们人在识别一个图像的时候,往往会不由自主的提取,比如轮廓、颜色、花纹这样的元素,也就是说图像作为一个二维的物体,在二维平面相邻像素之间是存在关联的,我们强行把它降到一维,也就破坏了这些观点,失去了它重要的特征。也就是说这些特征对提高模型的泛化能力有很大的作用,基于这种想法,人们把卷积运算引入到了神经网络。
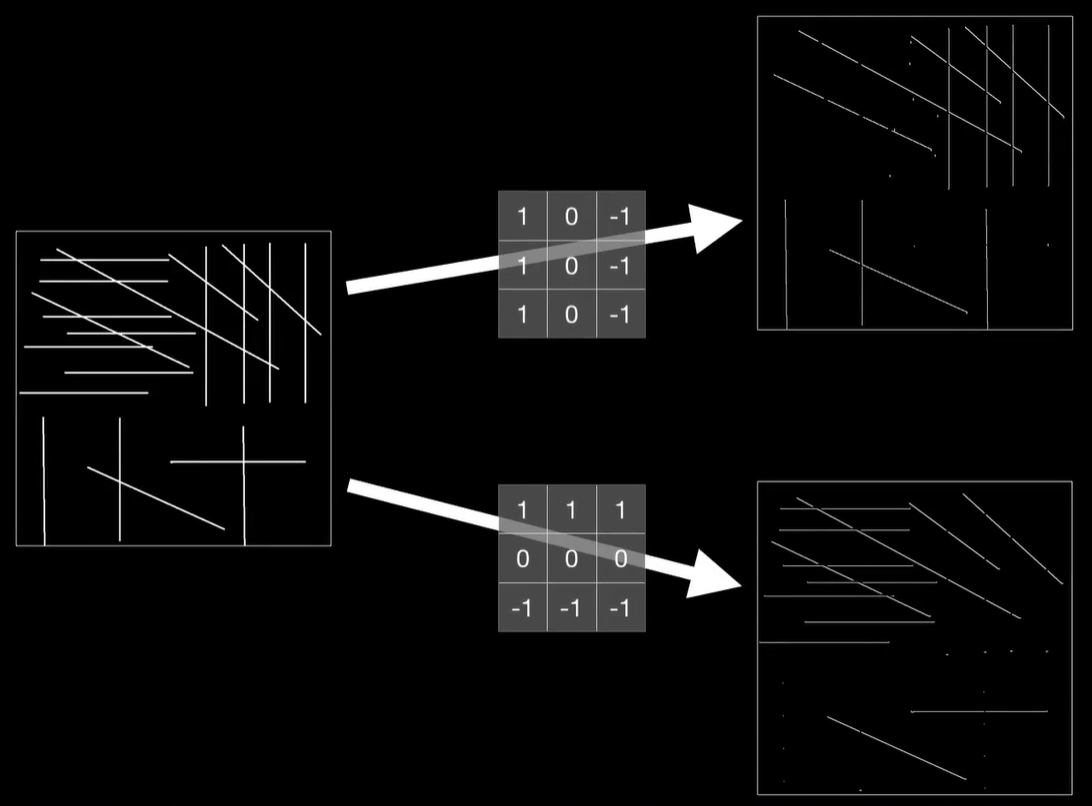
卷积运算的过程是这样的,我们使用8×8的矩阵,然后我们手动构建一个3×3的小矩阵,然后从左上角开始把这个小的罩在大的上面,把对应的元素相乘,结果再加到一起得到一个新的值,完成以后把这个小的向右挪一个同样和大的对应的元素相乘,结果相加又得到一个值,再向右挪动,重复这个过程直到顶到头。我们再回到最左边向下挪动一个,从左到右再来一遍,直至罩完整个原始图像。当然一个像素的灰度值是一个自己的最大值255,所以如果我们想要把卷积的结果显示成图片的话,需要把超过255的像素点都处理成255,这就是8×8的原始灰度图卷积之后的样子。而这个3×3的小矩阵也就是卷积核有时候也被称之为过滤器。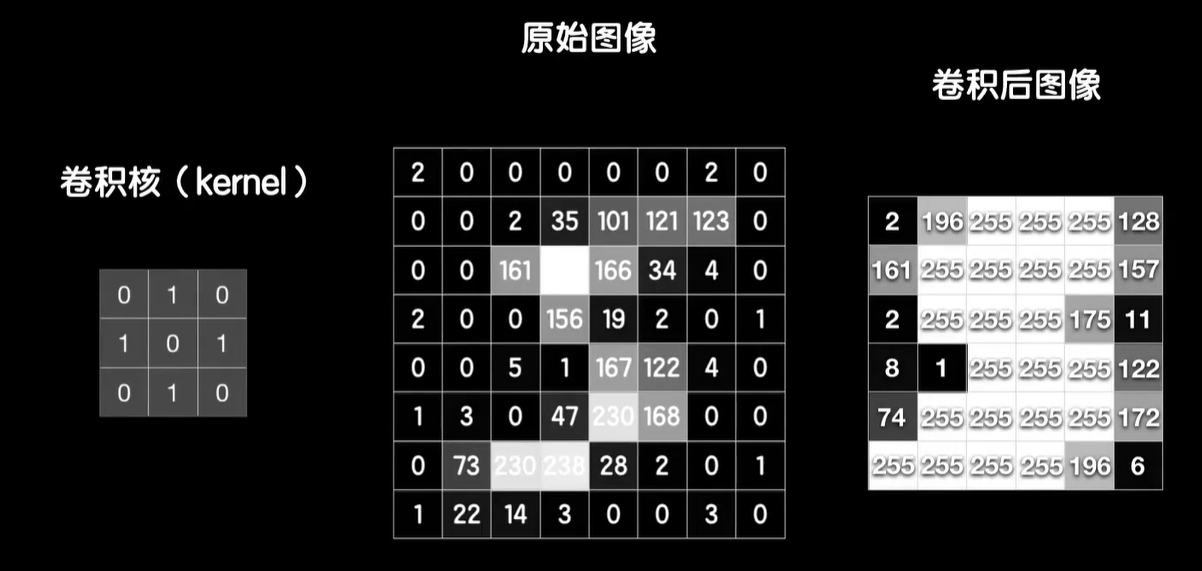
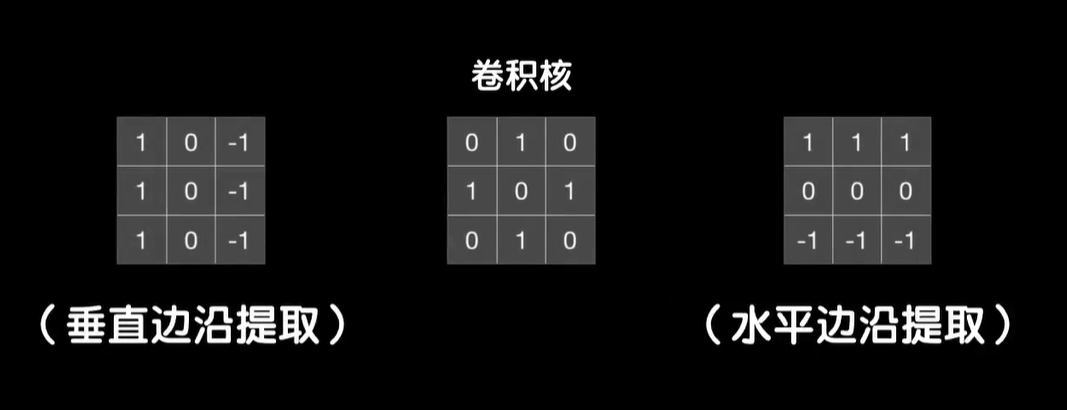
我们的图像是这样的,用卷积核卷完之后,把垂直的边缘给提取出来了,卷积核的作用实际上是用来做垂直边缘的提取。

这个大图比较麻烦,我们用两张8×8的小图来看一下细节,这是他们用卷积核卷积的结果,你会发现结果图片都开始显现,垂直条纹的特征。
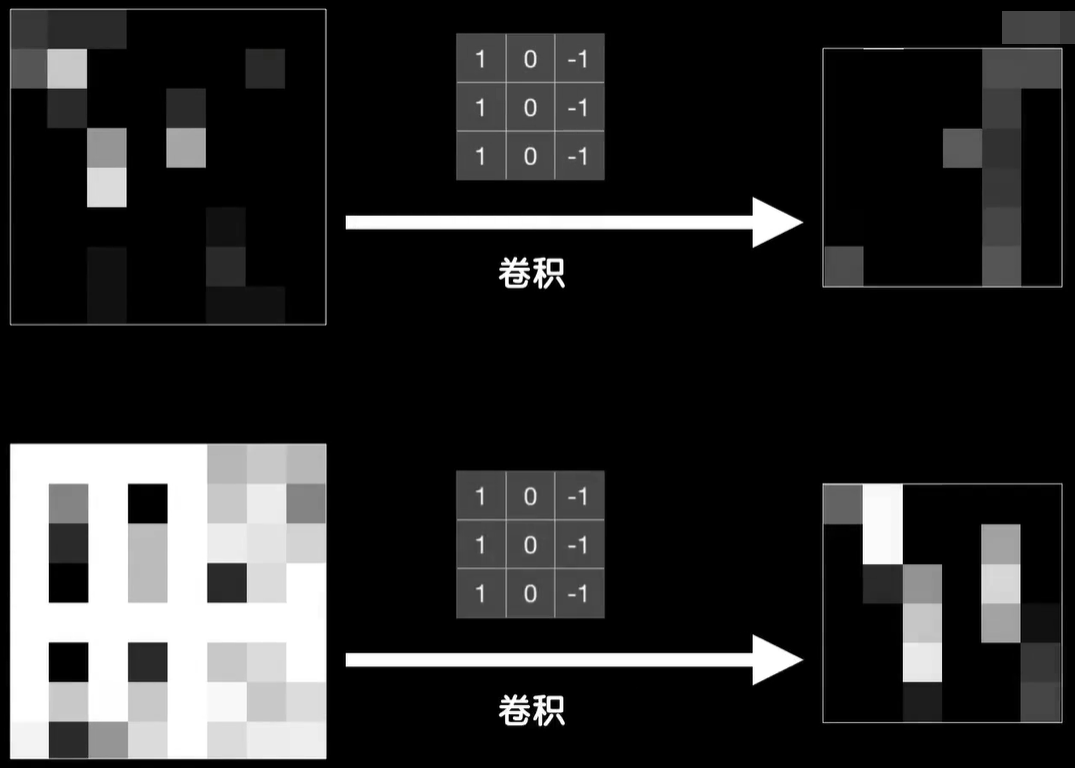
为了让事情更加简单,我们再搞一张极端情况的图片,这张小图中间部分很明显是图像的一个垂直边界,比如一个杯子的边缘部分。
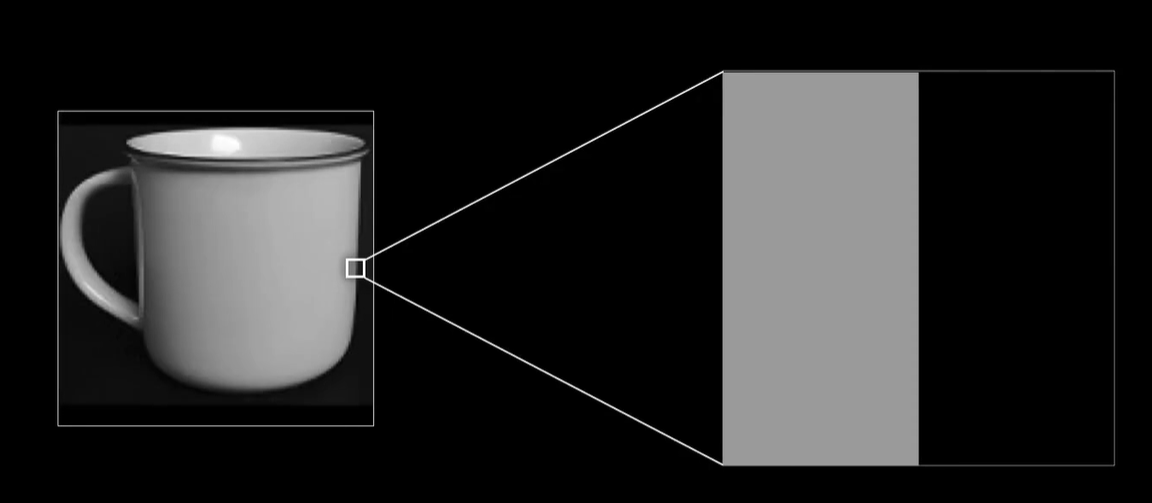
那么在卷积的时候你会发现因为图像左侧的像素灰度值都是60,而卷积核的左侧一列是1,右侧一列是-1,中间一列是0,元素相乘再相加后就变成了0,所以这个图像左侧部分卷出来的结果都是0,很黑。
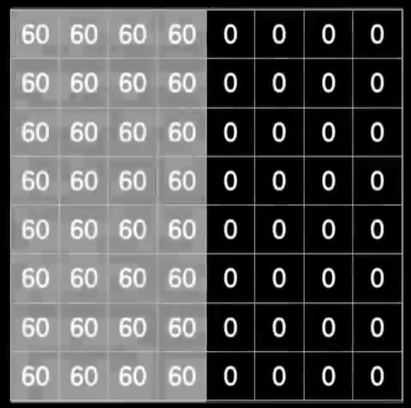
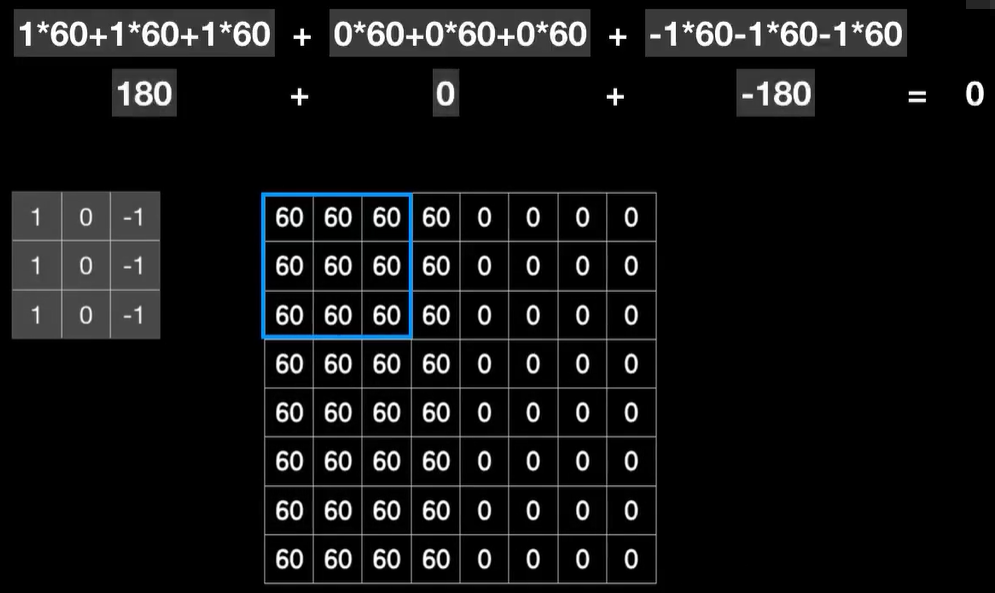
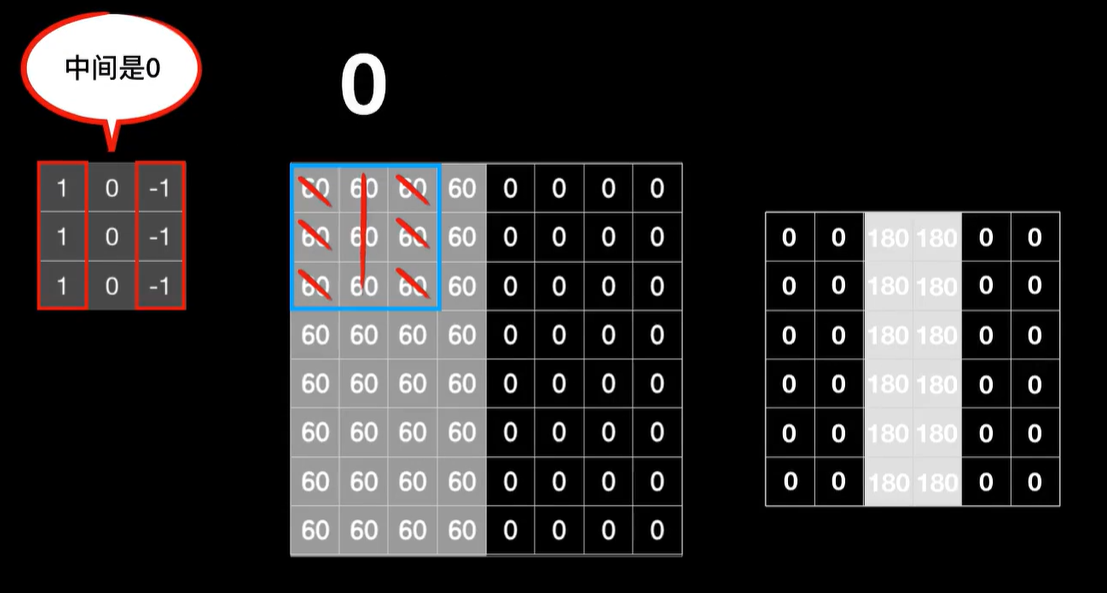
而在右边像素灰度值都是0,卷出来的结果也都是0也很黑,只有在中间部分,比如这里这三个60×1相加得到180,中间的结果是0,右边的结果也是0,所以结果就是180,这一列下来都是180,还有右边这一列结果也都是180

如果我们把卷积的结果画出来,那么就是这样一个明亮的垂直边界,实际上如果我们仔细的观察卷积核,你就会发现因为它们在垂直方向上左右对称的两列值都是相反数,所以遇到图像中灰度值相近的3×3的像素块,它们就会在左右1正1负之间相互抵消,最后的结果变为了0,也就是说,很黑;而对于像中间部分左侧大右侧小的3×3的像素块,这是典型的垂直边缘特征。你会发现这种左大右小的不对称导致抵消作用降低,而像这种右侧全是0的情况,右侧的负值完全没有抵消左侧正值的作用。不仅如此,因为卷积核左侧一列是三个1,加起来之后,结果把这个值变得很大,换句话说边缘的特征被凸显了出来。
同样的道理,我们还可以用这样的一个卷积核做出水平提取的效果,你可以使用这样只有横线和竖线的图片去测试,结果将非常的明显,垂直检测的卷积核把水平线弄没了,而水平检测的卷积核把垂直线弄没了。
实际上卷积是一种在图像处理领域非常常见的操作,现在很多图像处理软件中都会利用到卷积运算给图片加上效果。
编程实验
1、本次编程实验我们就用Keras搭建一个深度神经网络,来尝试一下经典的mnist的数据集,关于卷积神经网络的使用,我们在下一节完整的讲述卷积神经网络的细节之后再来实现。
下面的代码表示keras会从数据集中寻找mnist,如果你的电脑没有(c盘用户文件夹下.datasets文件夹下),那么keras就回去自动下载
from keras.datasets import mnist
X_train就是训练集的图像数据, Y_train就是图像的分类标签数据。同样X_test和Y_test等于是测试级的图像数据和分类标签数据,这4个数据都是numpy的ndarray类型,现在我们用它的shape函数打印一下这些数据的形状。
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
print("X_train.shape: "+str(X_train.shape))
print("Y_train.shape: "+str(Y_train.shape))
print("X_test.shape: "+str(X_test.shape))
print("Y_test.shape: "+str(Y_test.shape))
# X_train.shape: (60000, 28, 28)
# Y_train.shape: (60000,)
# X_test.shape: (10000, 28, 28)
# Y_test.shape: (10000,)
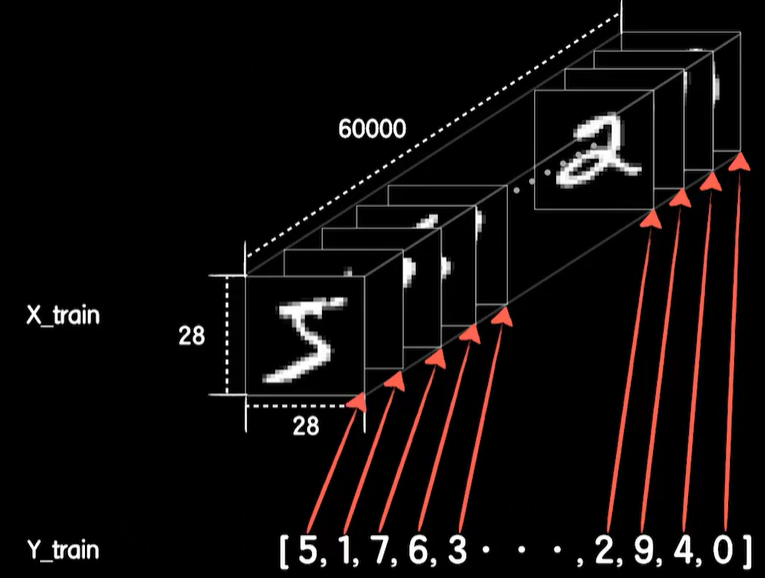
你会发现X_train是一个6万×28×28的数据,我们说过mnist中的每个图片都是28×28的,一共有6万个图片,所以6万就代表有多少张图片,而后面的两个28就表示一个图片的宽和高,这样的一个形状的三维张量就代表了6万张28×28的训练数据,Y_train是一个有6万个元素的数组,每个元素的值就代表着外圈中对应位置图像的类别,在mnist共有0~9,这10个数字也也就是说一共10类,所以每个值都是0~9中的一个数字。
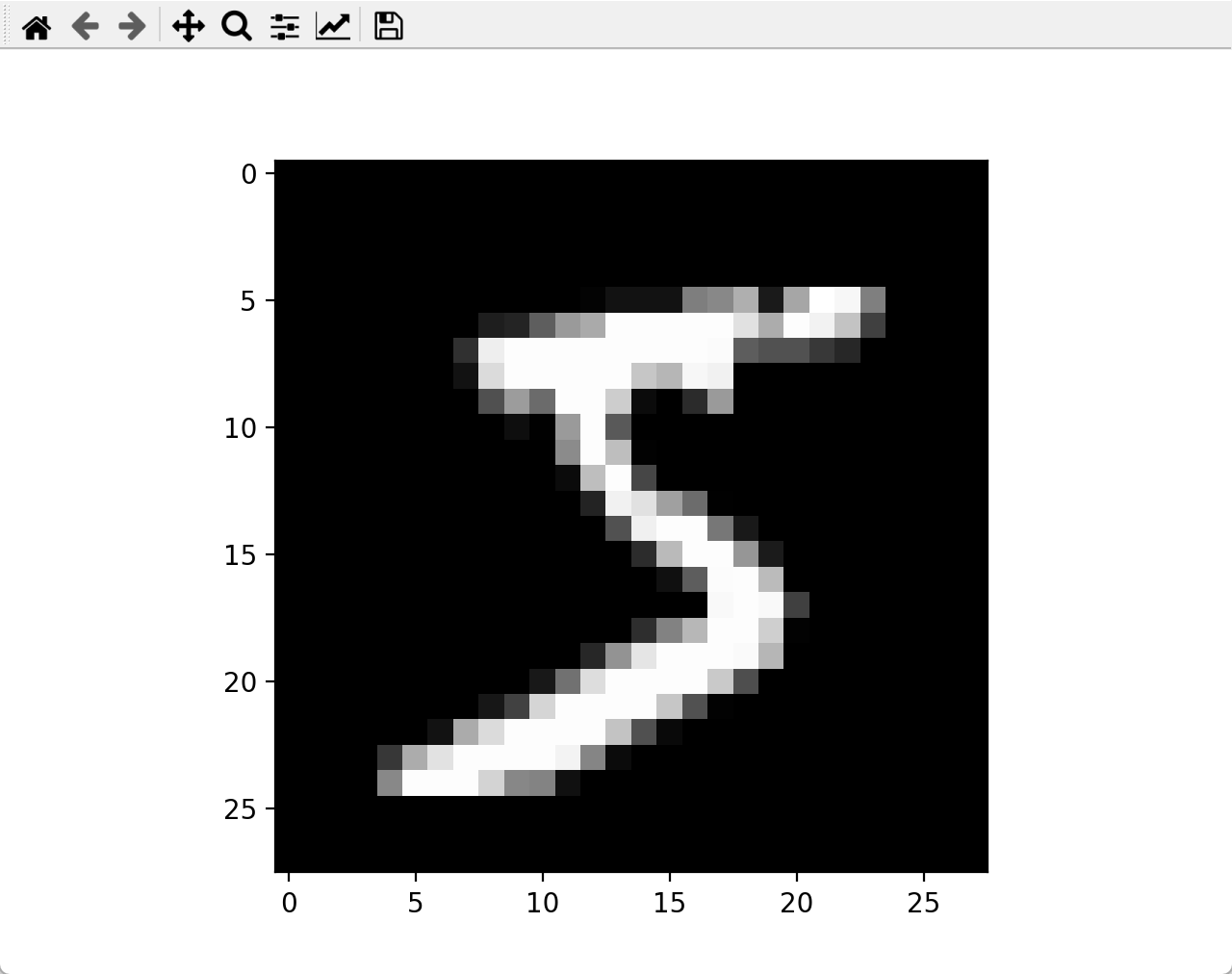
我们来看一下数据集的样子
import matplotlib.pyplot as plt
...
print(Y_train[0]) #打印标签,结果是5
plt.imshow(X_train[0], cmap='gray') # X_train[0]表示训练集的第一个样本数据,cmap='gray'表示绘图模式为灰度图
plt.show()
如果要把一个图片送入神经网络中,那么你就需要把一个图片都扯出来形成一个数组,numpy的ndarray有一个reshape函数可以改变数据的形状,X_train本来是6万×28×28的,那么用reshape函数就把形状变成了6万×724,那么不就相当于把每个28×28的二维数组变成了长度为784的一维数组了吗?同样我们把测试集也这样处理一下,不过注意一点,测试集只有1万个样本,所以我们要把它reshape为1万×784的形状
X_train = X_train.reshape(60000,784)
X_test = X_test.reshape(10000,784)
首先,因为我们的手写体数据是一个28×28的图片被拉扯出来,形成一个784的数组,那么1第一层的input_dim就需要被改为784;然后我们mnist数据集和之前的豆豆数据集还不一样,豆豆问题是一个二分类问题,这种情况下我们的分类标签就使用一个数字就好,1代表一类,0代表另外一类,那输出层用一个神经元就好了,如果输出神经元采用Sigmoid激活函数,那么在输出大于0.5的时候,就是第一类1,小于0.5就是第二类0。
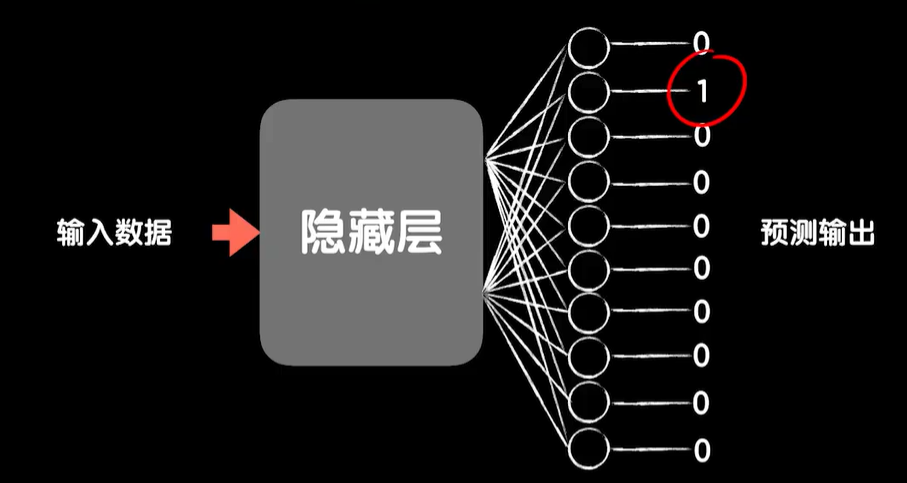
但是面对10个分类的输出,首先我们的输出层用1个神经元就无法表示这种10种情况,所以我们需要这样改一下,把输出层改成10个神经元,那标签数据我们采用1种叫做one-hot的编码方式,是这样的,我们用一个10位数,如果第一位是1,其他是0就表示第一类,第二位是1,其他是0就表示第二类,一直到最后第十位为一,其他为0就表示第十类。但是我们的mnist的数据集给的分类标签数据是0~9这样的数字,所以我们现在的想法是把这些0~9的数值转化成one-hot编码的样子。
keras有一个函数可以很方便的把一个数字变成one-hot的编码,这样就把y券从数字变成了one-hot的编码。举例如下:如果Y_train是[0,4,1,5,9],那么这行代码的输出结果Y_train就会变成下面的样子:

from keras.utils import to_categorical
...
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
最后还有一点,输出层现在有10个神经元,每个神经元的输出都代表了一类,如果我们还采用Sigmoid激活函数会有一点问题,对于分类问题我们曾经简单的说过,最终的输出预测值实际上是一个概率值。
在二分类问题中,如果输出值大于0.5,实际的含义是预测的一类概率大于0.5,如果是有10个分类的问题,我们最终的输出也应该是一个概率值。但是如果使用Sigmoid的激活函数,最后的10个输出的总概率值可能会大于1,但是概率值我们知道最大值就是1,必然事件的概率就是1,所以我们需要一种函数让这10个输出的概率相 n加等于1,这个函数就是softmax,所以一般输出层我们使用softmax激活函数。softmax函数是这样的,你可以自己研究一下下图这个函数式子的含义,那简单来说它的效果就是这10个输出层的神经元的10个输出概率有大有小,最大的就意味着预测的结果是这一类,而且这10个输出概率的值加起来它总是等于1。
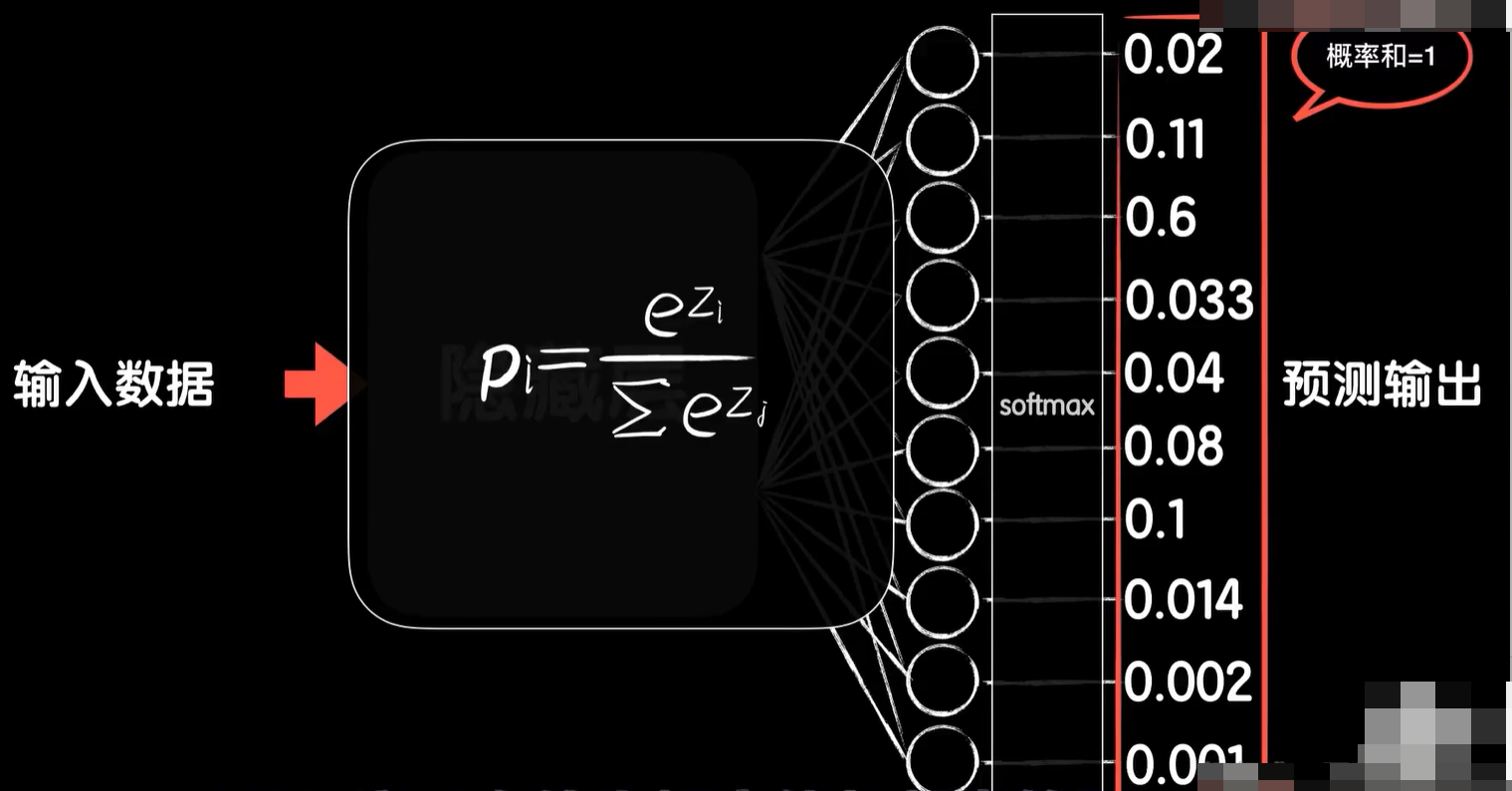
实际上我们从这个角度来看,one-hot的编码的标签数据就很合理了,因为它只有一位是1,其他是0,也就表示这一类的概率是百分百,其他类的概率是0%,因为是标注答案的标签数据,所以肯定是一个能百%确定分类的值。实际上从数学表达式上你可以看出来, softmax是sigmoid向多输出的一个扩展,所以使用它之后前向传播和反向传播的过程,可以尝试推导一下,不是很复杂,当然不想了解这些细节也可以,我们就直接把输出层的激活函数改成 softmax就好了,keras会帮我们处理好这一切,好的,现在我们就把处理好的X_train和Y_train送入训练。
开始训练,不过我们发现训练半天准确率还是卡在一个比较低的值上不去。
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
import matplotlib.pyplot as plt
from keras.utils import to_categorical
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" # Disable GPU
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
print("X_train.shape: "+str(X_train.shape))
print("Y_train.shape: "+str(Y_train.shape))
print("X_test.shape: "+str(X_test.shape))
print("Y_test.shape: "+str(Y_test.shape))
print(Y_train[0])
plt.imshow(X_train[0], cmap='gray') # X_train[0]表示训练集的第一个样本数据,cmap='gray'表示绘图模式为灰度图
plt.show()
X_train = X_train.reshape(60000,784)
X_test = X_test.reshape(10000,784)
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
model = Sequential()
# 当前层神经元的数量为10,激活函数类型:relu,输入数据特征维度:784
model.add(Dense(units=8, activation='relu', input_dim=784))
model.add(Dense(units=8, activation='relu'))
model.add(Dense(units=8, activation='relu'))
# 因为最后一层要输出类别的概率,十类数据概率和要等于1,所以使用softmax函数作为激活函数
model.add(Dense(units=10, activation='softmax'))
# # loss(损失函数、代价函数):mean_squared_error均方误差;
# # optimizer(优化器):sgd(随机梯度下降算法);
# # metrics(评估标准):accuracy(准确度);
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.05), metrics=['accuracy'])
# # epochs:回合数(全部样本完成一次训练)、batch_size:批数量(一次训练使用多少个样本)
model.fit(X_train, Y_train, epochs=5000, batch_size=4096)
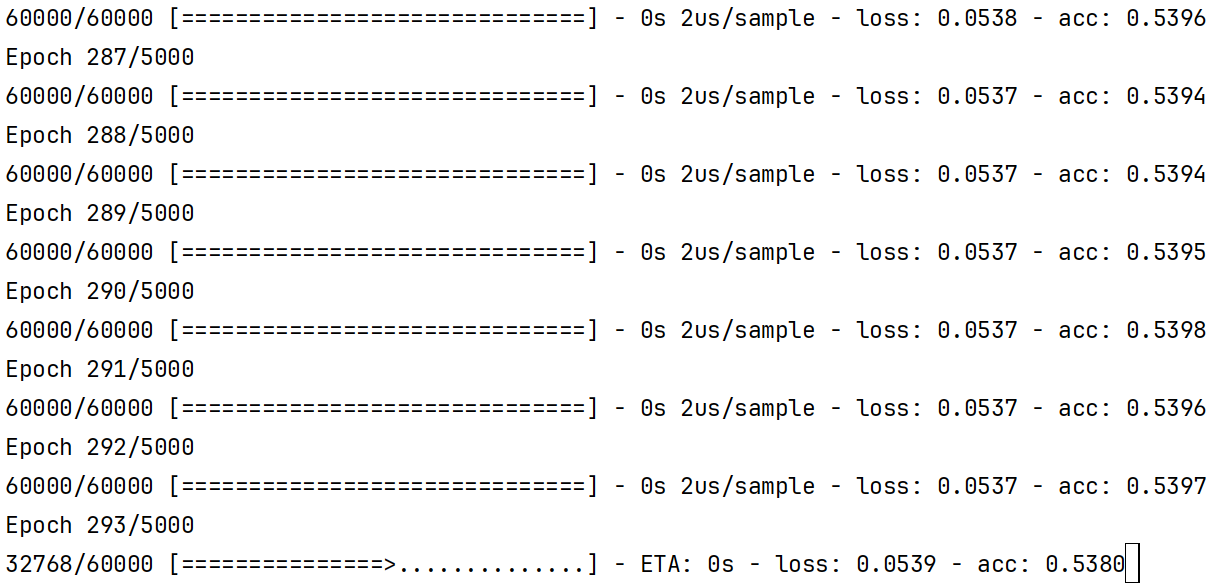
那我们开始使用神经网络的相关知识进行调参,首先第一感觉是网络规模有点小了,我们的3个隐藏层每层只有8个神经元, mnist的数据,一个样本有784个特征维度,虽然不是特别复杂的问题,但是也不简单,所以我们需要把网络规模搞得大一点,我们把每一层的神经元数量改成256,当然同学们也可以去试试其他的数量,现在这个准确率就上去了,但是似乎也不是特别高,零点八几的样子,
我们继续挑战,这里有个问题,我们说MS的图片是灰度图,像素的灰度值在0~255之间,实际上我们需要把这些灰度值缩放到0~1之间,这就是所谓的归一化操作。
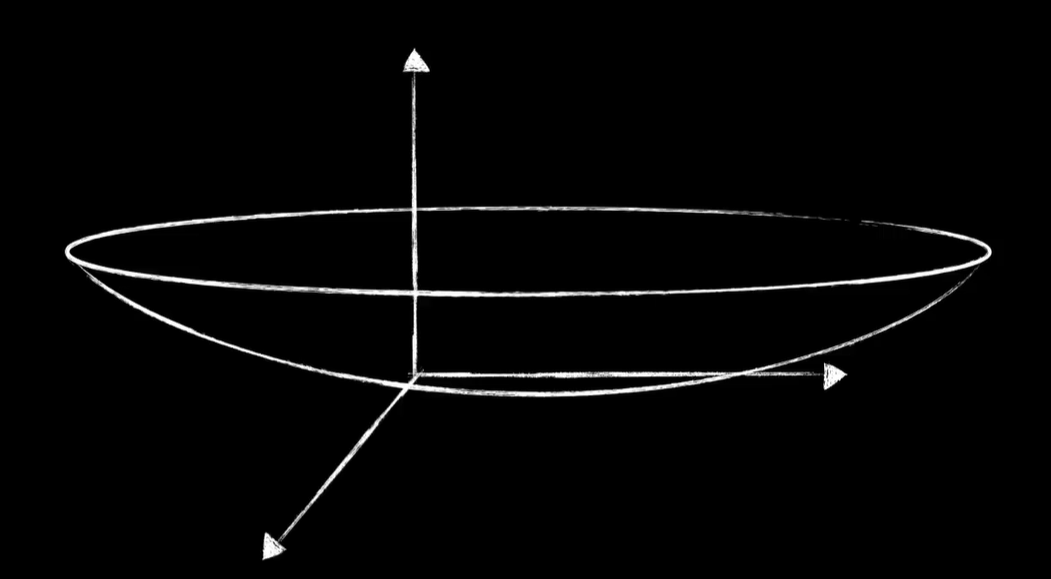
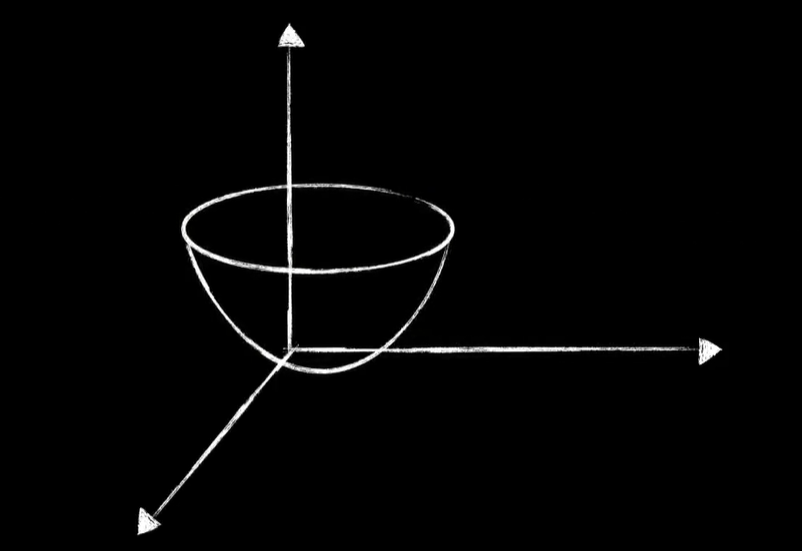
为什么需要把输入数据做归一化操作?我们简单的说明一下,因为输入数据的灰度值范围在0~255之间,这意味着某些黑暗的像素的值很小,比如只有1~5之间,而某些明亮的像素值很大,比如200多这样的数据就导致我们的代价函数很不友好,虽然我们画不出来700多维的代价函数,但是我们可以用一个三维的代价函数。举个例子,我们之前说代价函数是一个碗状,如果输入数据差距过大,将会导致这个碗非常的狭窄,而进行梯度下降的时候就会变得非常困难,而如果我们把输入数据变成0~1之间,这样差距不大的值的时候,代价函数将会变得比较均匀,这样就比较利于梯度下降的进行。
所以我们让输入数据除以灰度的最大值255.0,这里因为输入数据是一个numpy的数组,所以有广播机制,相当于把所有的数据都从0~255倍缩放到了0~1之间的话,额外说一句,除了输入数据可以做归一化操作,其实神经网络的每一层的输出,因为它作为下一层的输入都可以做这个操作,当然这需要根据实际的效果决定做不做。我们再运行一下
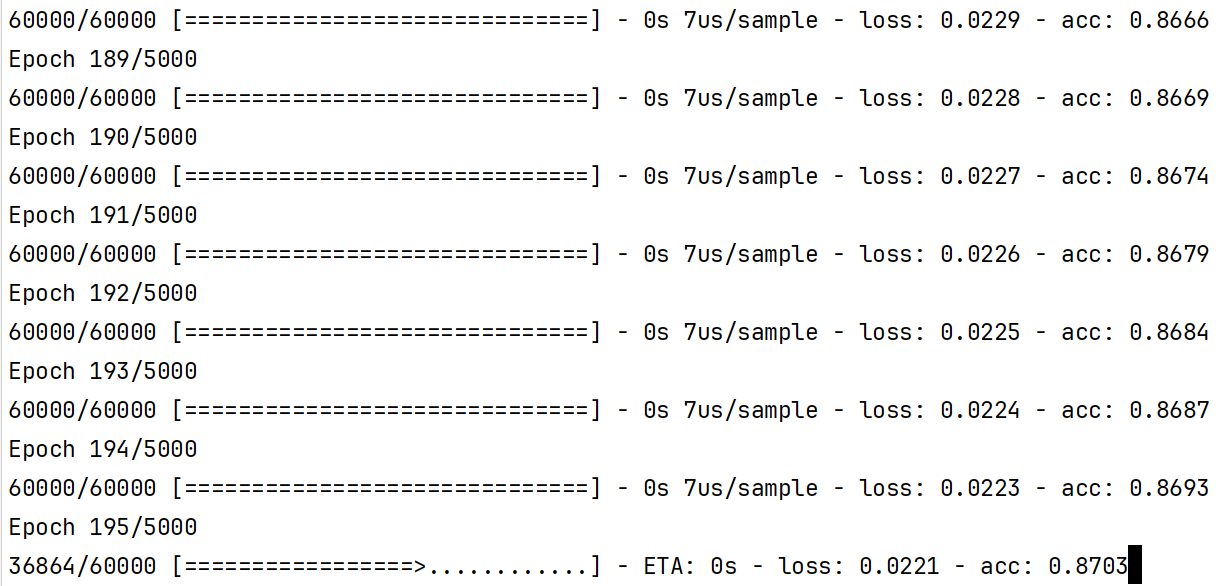
过了一会儿虽然准确率又有所提高,有零点九几了,不过貌似也不是特别的好。实际上我们的代价函数一直在沿用线性回归问题中的均方误差代价函数,这个代价函数其实对于分类问题不太适合,我们把它改成交叉熵代价函数categorical_crossentropy,可以暂时简单的做个记忆,关于多分类的输出,我们就使用这个交叉熵代价函数效果总是不错的。
交叉熵损失函数:交叉熵损失函数常用于分类问题,尤其是二分类和多分类问题。在分类任务中,模型的输出通常是一个概率分布,表示每个类别的预测概率。交叉熵损失函数度量了预测的概率分布与真实标签之间的差异。
-
公式:对于二分类问题,交叉熵损失可以表示为:
L = − [ y ⋅ log ( y ^ ) + ( 1 − y ) ⋅ log ( 1 − y ^ ) ] L=-[y\cdot\log(\hat{y})+(1-y)\cdot\log(1-\hat{y})] L=−[y⋅log(y^)+(1−y)⋅log(1−y^)]
其中:-
y y y 是真实标签,取值为 0 或 1。
-
y i ^ \hat{y_i} yi^是模型预测的概率(0 到 1之间的数)。
-
对于多分类问题,交叉熵损失是通过计算每个类别的预测概率和真实类别概率的差异来得到的,公式为:
L = − ∑ i = 1 C y i log ( y i ^ ) L=-\sum_{i=1}^Cy_i\log(\hat{y_i}) L=−i=1∑Cyilog(yi^)
其中:
- C C C是类别数。
- y i y_i yi是真实标签的 one-hot 编码(对于正确类别,值为 1;其他类别为 0)。
- y i ^ \hat{y_i} yi^ 是模型对第 iii 类的预测概率。
-
我们再运行一下
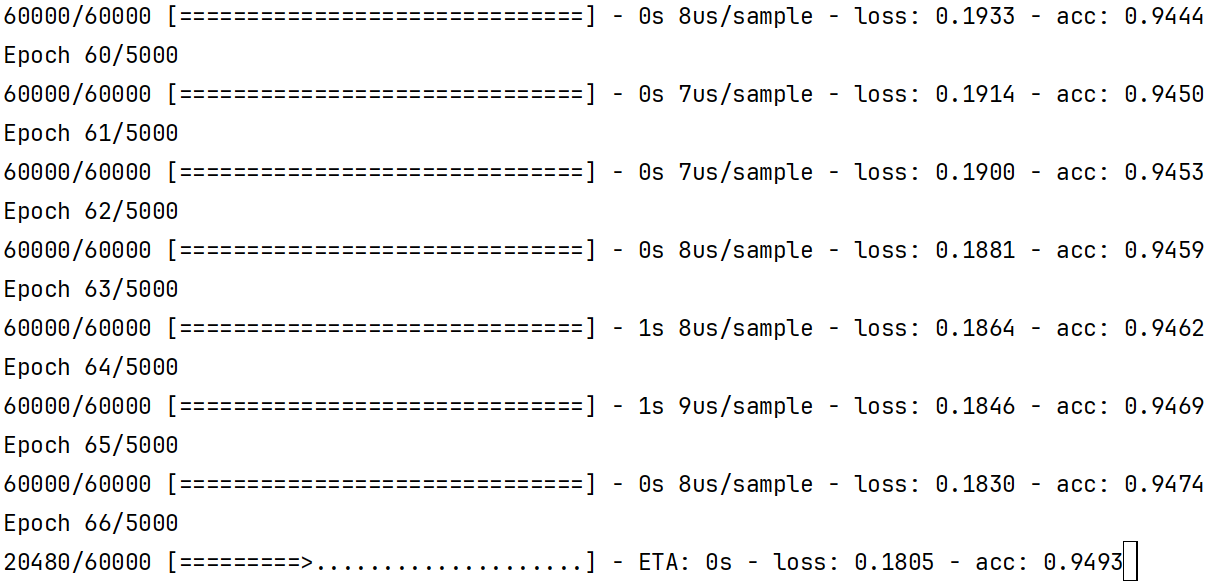
这次的结果很不错,我们需要在训练之后,再拿一些测试数据来测试一下模型的泛化能力
loss, accuracy = model.evaluate(X_test, Y_test) # 返回代价和精确度
print("loss: "+str(loss))
print("accuracy: "+str(accuracy))
经过5000个回合的训练之后,我们最后训练的准确率将近100%,测试集的准确率有97%,实际上我们还可以用一些正则化的手段让测试集的准确率更接近训练集,也就是减少过拟合。
完整代码:
# mnist_recognizer.py
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
import matplotlib.pyplot as plt
from keras.utils import to_categorical
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" # Disable GPU
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
print("X_train.shape: "+str(X_train.shape))
print("Y_train.shape: "+str(Y_train.shape))
print("X_test.shape: "+str(X_test.shape))
print("Y_test.shape: "+str(Y_test.shape))
print(Y_train[0])
plt.imshow(X_train[0], cmap='gray') # X_train[0]表示训练集的第一个样本数据,cmap='gray'表示绘图模式为灰度图
plt.show()
X_train = X_train.reshape(60000,784)/255.0
X_test = X_test.reshape(10000,784)/255.0
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
model = Sequential()
# 当前层神经元的数量为10,激活函数类型:relu,输入数据特征维度:784
model.add(Dense(units=256, activation='relu', input_dim=784))
model.add(Dense(units=256, activation='relu'))
model.add(Dense(units=256, activation='relu'))
# 因为最后一层要输出类别的概率,十类数据概率和要等于1,所以使用softmax函数作为激活函数
model.add(Dense(units=10, activation='softmax'))
# # loss(损失函数、代价函数):mean_squared_error均方误差;
# # optimizer(优化器):sgd(随机梯度下降算法);
# # metrics(评估标准):accuracy(准确度);
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.05), metrics=['accuracy'])
# # epochs:回合数(全部样本完成一次训练)、batch_size:批数量(一次训练使用多少个样本)
model.fit(X_train, Y_train, epochs=5000, batch_size=4096)
loss, accuracy = model.evaluate(X_test, Y_test) # 返回代价和精确度
print("loss: "+str(loss))
print("accuracy: "+str(accuracy))
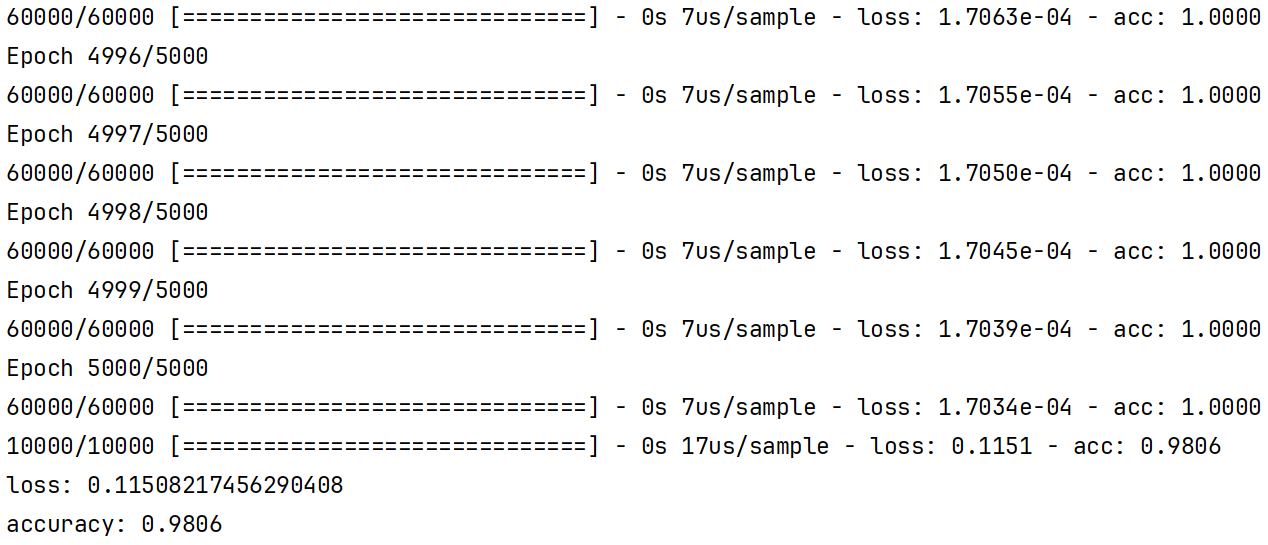
我们说过这种图像识别的问题,我们一般使用卷积神经网络,那在下一节的编程实验中,我们就试试用卷积神经网络的效果。
十一、卷积神经网络(下)
图像识别实战
原理
上一节我们已经了解到卷积操作是怎么一回事,接下来我们就看看如何把卷积运算融入到我们的神经网络之中。这是一张8×8的灰度图,用一个3×3的卷积核对它进行卷积输出,一个6×6的结果,我们把这个做卷积运算的一层称之为卷积层。
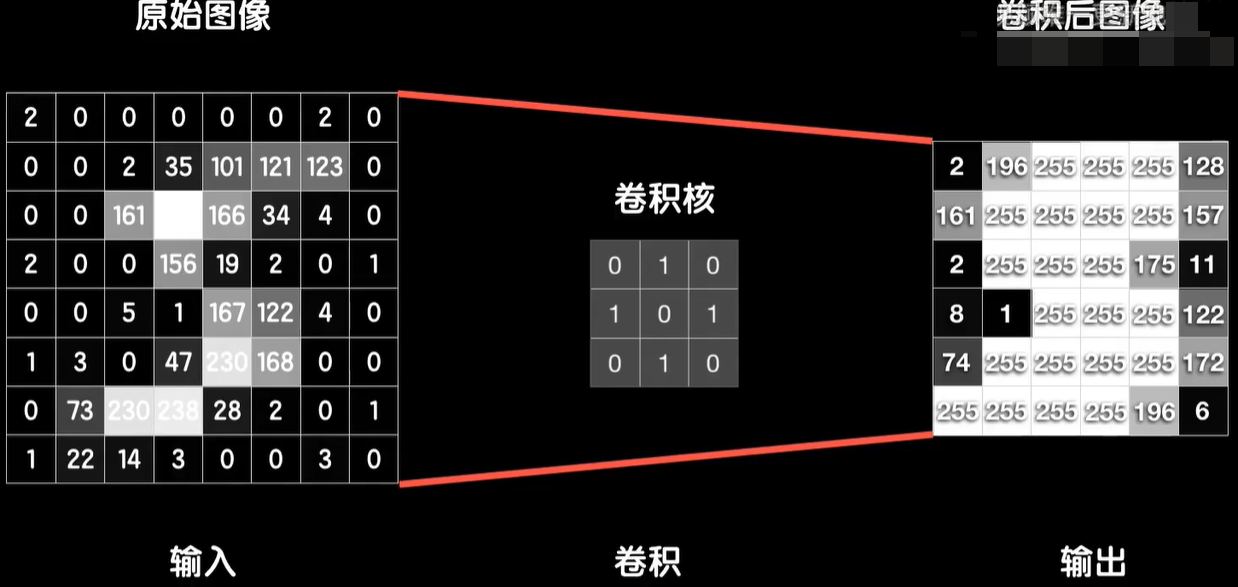
卷完以后我们就可以把结果拆成一个数组送入到后面的全连接层神经网络之中。
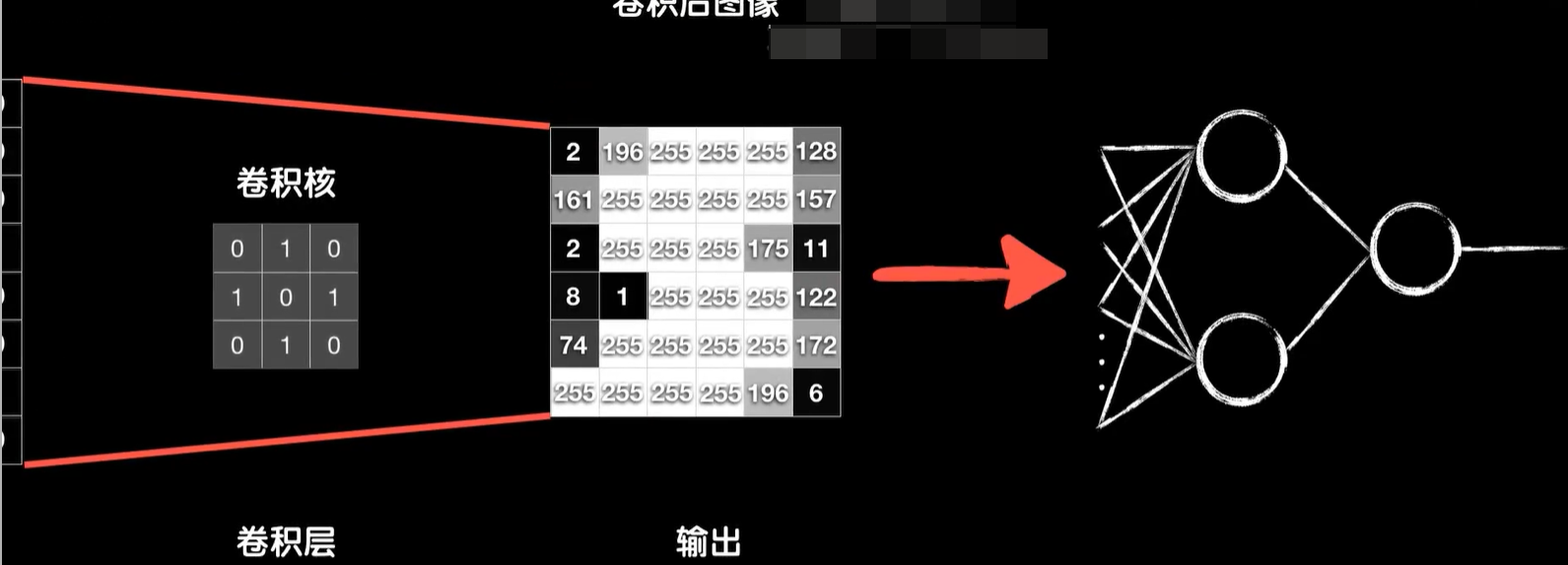
但是你肯定会有一个疑问,卷积核中的各个值是多少?是这样垂直边缘检测的和还是这样水平,边缘检测的和还是其他的核?
实际上我们不必管它,随机初始化这些值就好,卷积核的值也是通过训练学习而来的。换句话说,通过训练找到合适的卷积核去提取不同的特征。我们卷积核中的参数又是怎么学习来的?还是像全连接层的普通神经元那样通过反向传播和梯度下降吗?是的,从某种角度来看,卷积层除了对数据的提取方式不同以外,其他部分和一个全连接层也没有什么区别。
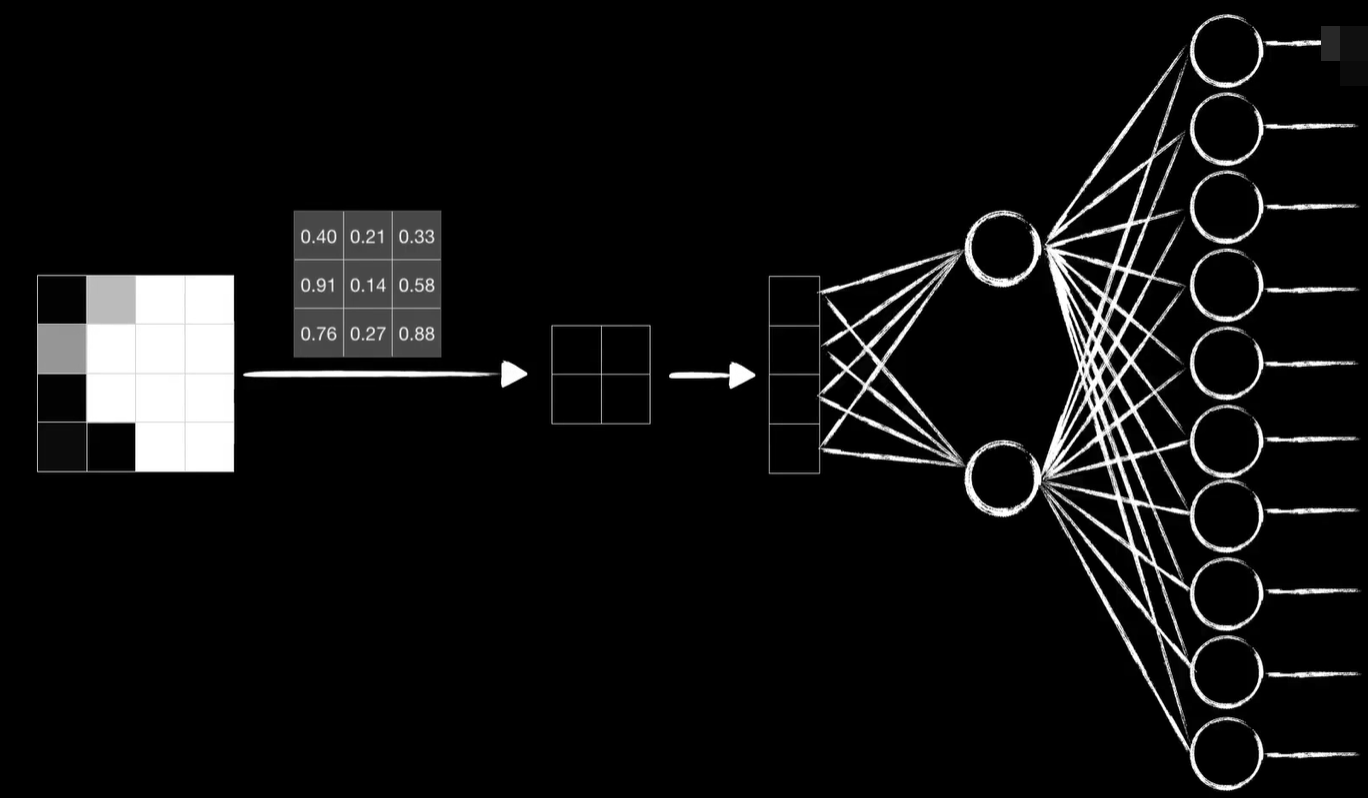
按照最简单的讲解原则,假设我们的原始图像的大小只有4×4,用一个3×3的卷积盒去卷,它得到一个2×2的矩阵,卷完以后我们再送入一层全连接层中,简单起见假设只有两个神经元,再经过输出层,mnist的数据集是10分类的问题,所以输出层有10个神经元,最后得到预测结果,这是目前前向传播的过程。
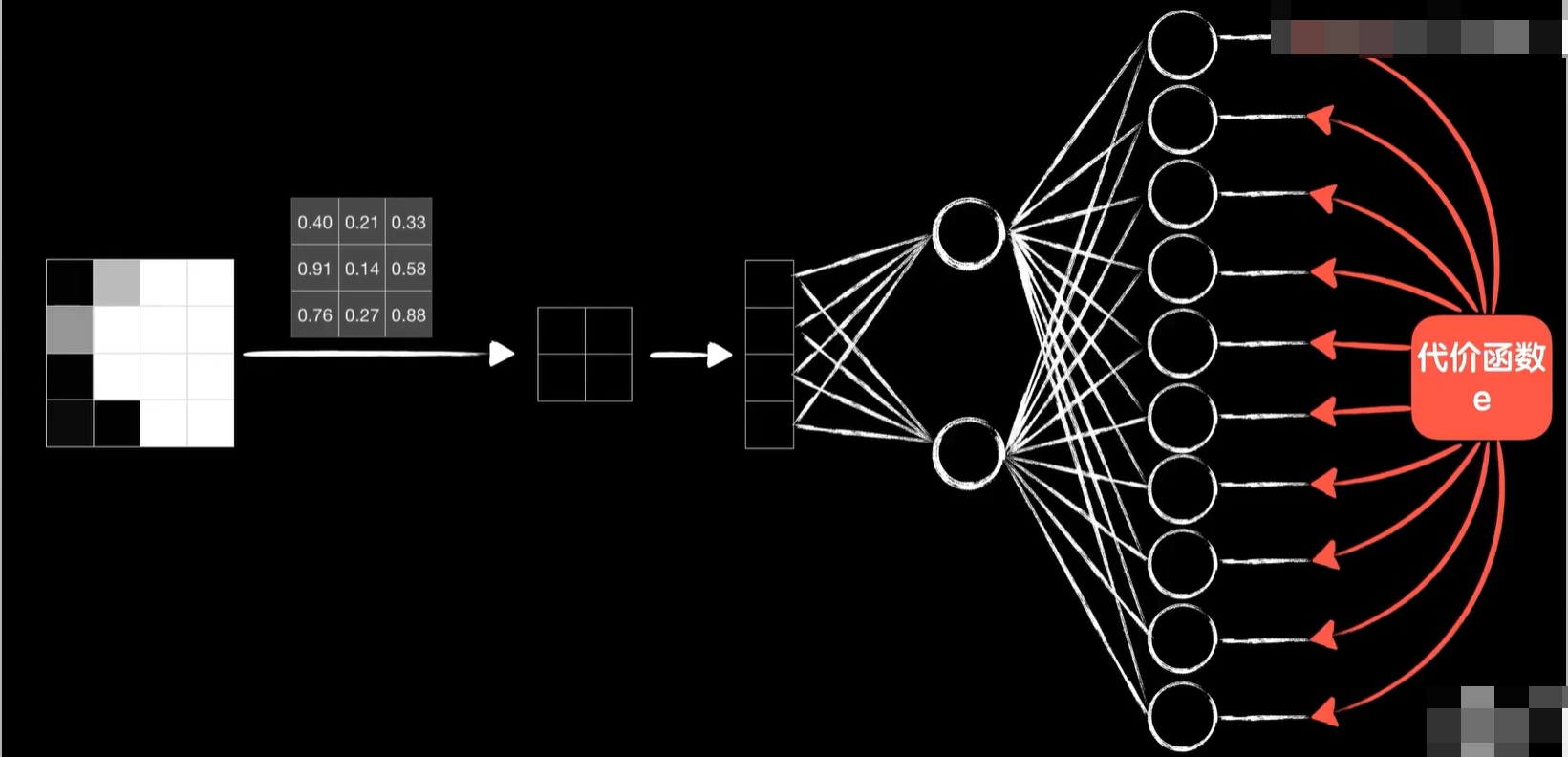
那么反向传播的过程就是这样,后面两层和以前一样很简单,先求代价函数,然后利用链式法则把误差代价传播到这两层的各个权值和偏置参数上到这里,接下来该怎样呢?我们的误差代价如何传播到卷积层,好像不能按照普通神经元的方式继续下去了。
我们知道卷积的过程就是卷积核依次和这些小图对应的元素相乘再相加得到一个值,比如卷积,的第一步是卷积核和左上角的第一个3×3的小图,对里的元素相乘之后再相加,你看这像不像一个普通神经元的工作模式?3×3的小图的每个像素点就是输入数据,卷积核上的值可以看作是对应输入数据的权值参数w那么对应元素相乘之后再相加,所以这不就是一个9个输入和一个输出的普通神经元的线性运算部分吗?
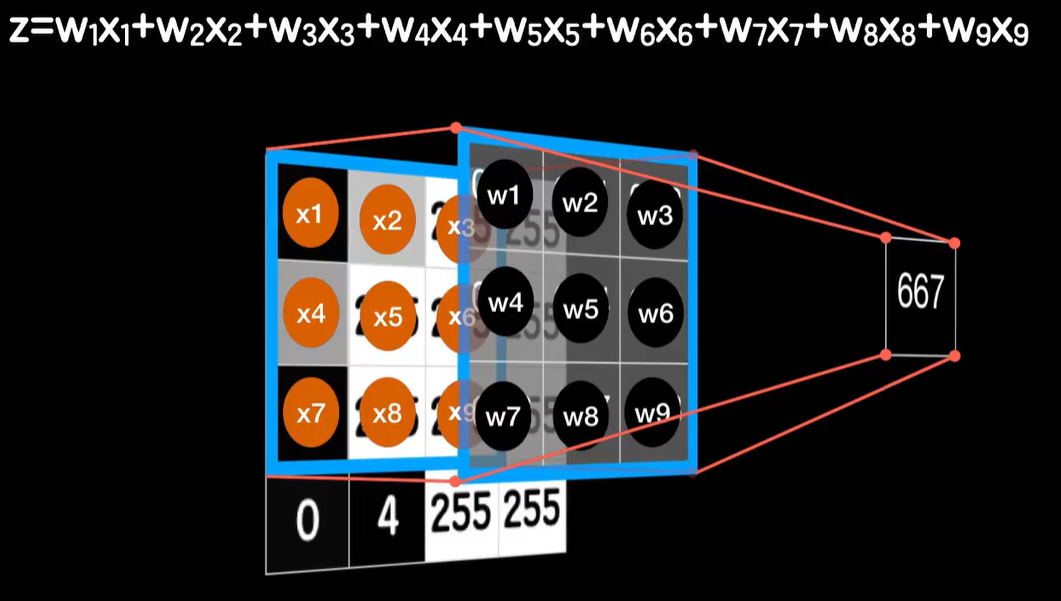
同样第二个3×3的小图通过同样的方式得到第二个结果,这又可以用一个普通的神经元来表示,第三个小图也对应一个普通的神经元,第四个小图也对应一个普通的神经元,当然神经元的线性函数一般还需要加一个偏置项b所以我们实际上会让卷积的结果再加上一个b这样就真的和之前的普通神经元的线性运算部分一样的,当然如果想要和一个普通神经元彻底一样,我们还需要在线性运算之后也通过激活函数进行非线性运算,这才是卷积层的最终输出,这样我们就把1个卷积层拆成了4个普通的神经元,既然如此,我们就可以像之前在普通神经元中那样很轻松的继续把误差代价反向传播下去。
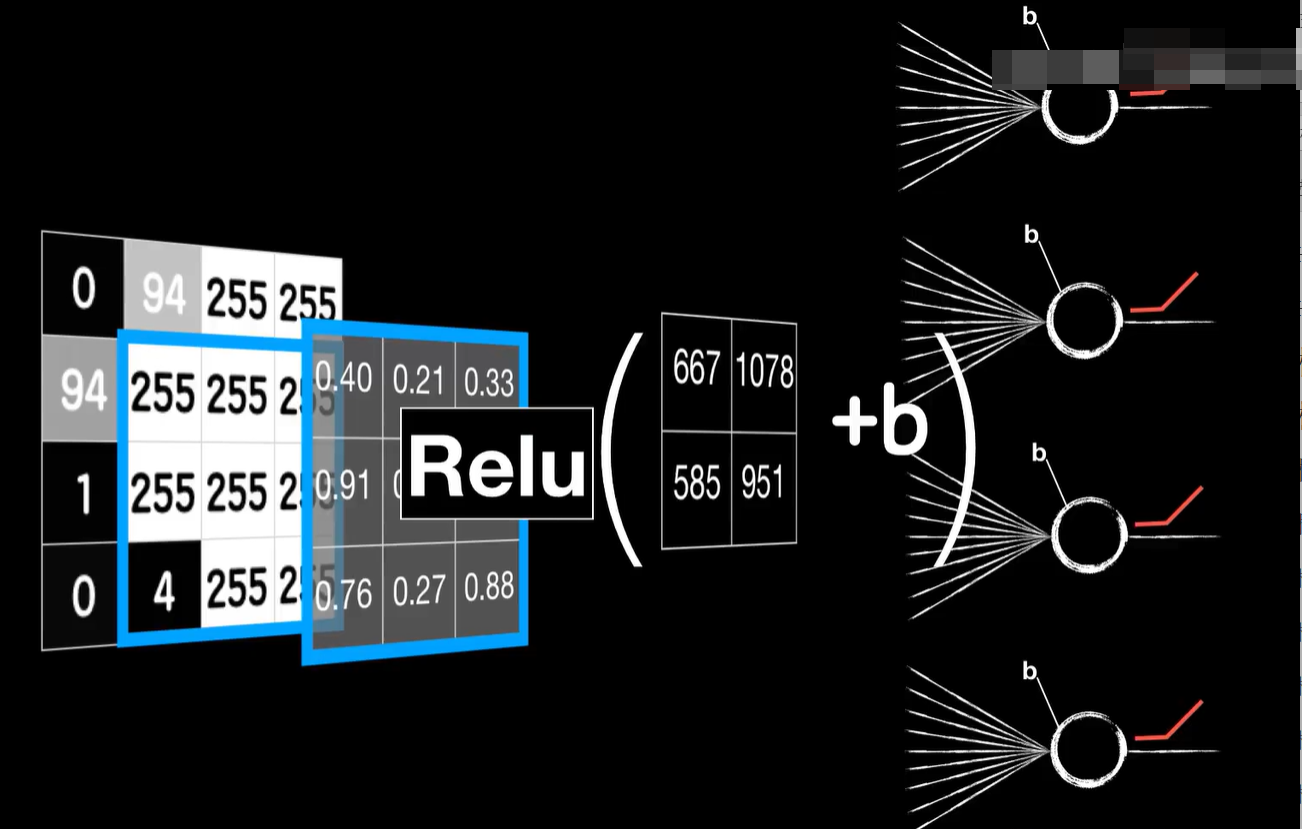
当然这4个神经元和普通的神经元相比还是有几个细节不太一样。首先这4个神经元的输出是根据卷积的过程排列而成的二维结构,而不是这样的平铺,当然在送入后面的全连接层的时候,我们需要手动把它平铺开,然后这4个神经元的输入并不相同,实际上是同1个图片的不同区域,最后也是最重要的一点,这4个神经元的权值参数并不是独立的,因为我们把卷积核的值看作是权值参数,而这4个神经元的权值参数都来自于同1个卷积核,所以实际上它们的权值参数是一样的,我们只是把1个东西强行拆开平铺,铺成了4个,也就是说这4个神经元复用了同一套权重参数,这就是所谓的参数共享,这是卷积层的优势之一
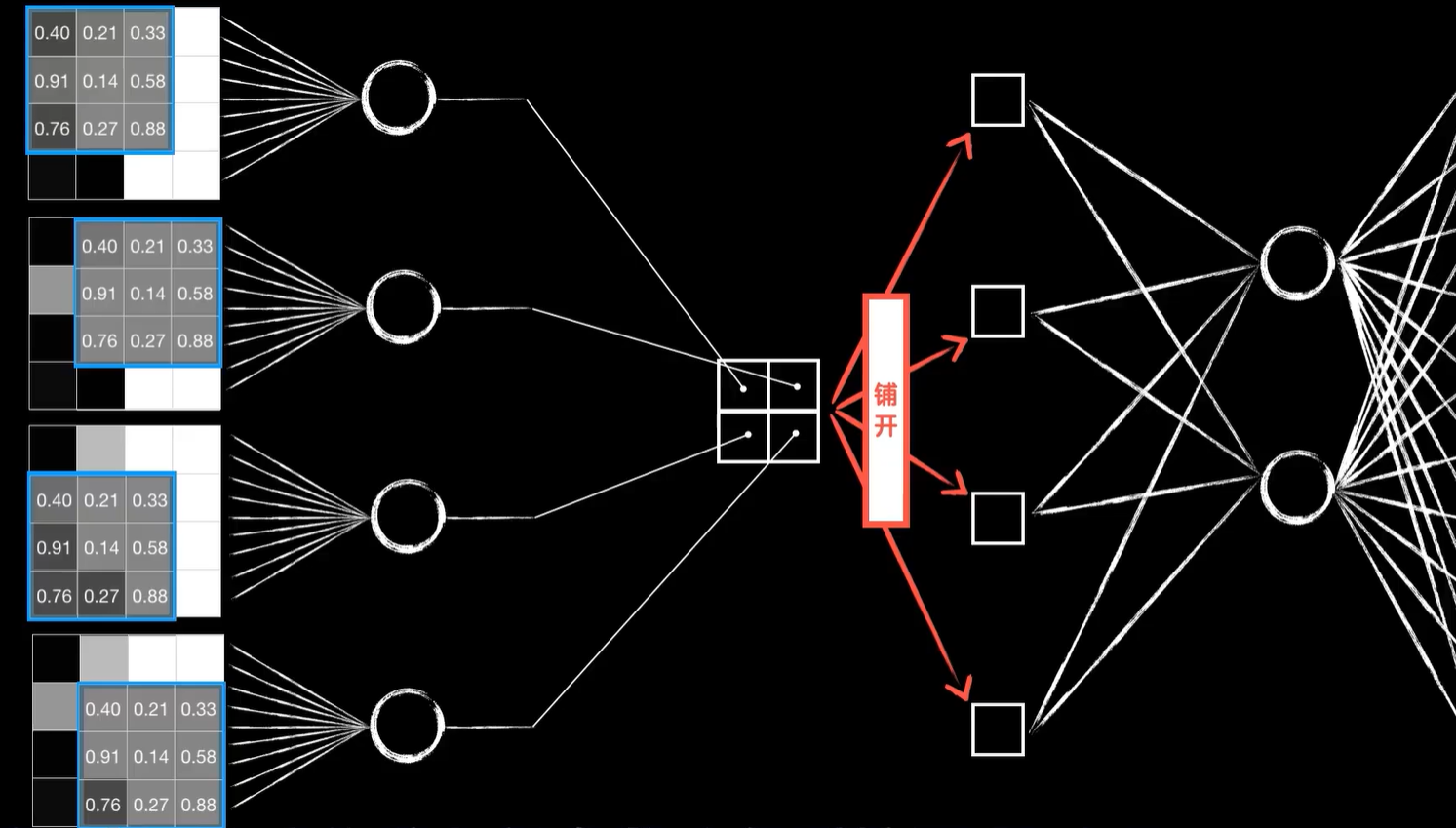
相比之下,如果我们使用全连接层4×4的图像数据就需要变成16维的向量,那么就会有16个权重参数和一个偏置参数,一共是17个参数,那要像卷积层一样得到4个输出,就需要4个神经元,这样的1个全连接层就需要17×4=68个参数,而卷积层因为共享的参数只有3×3=9个参数,再加1个偏置参数b是10个。
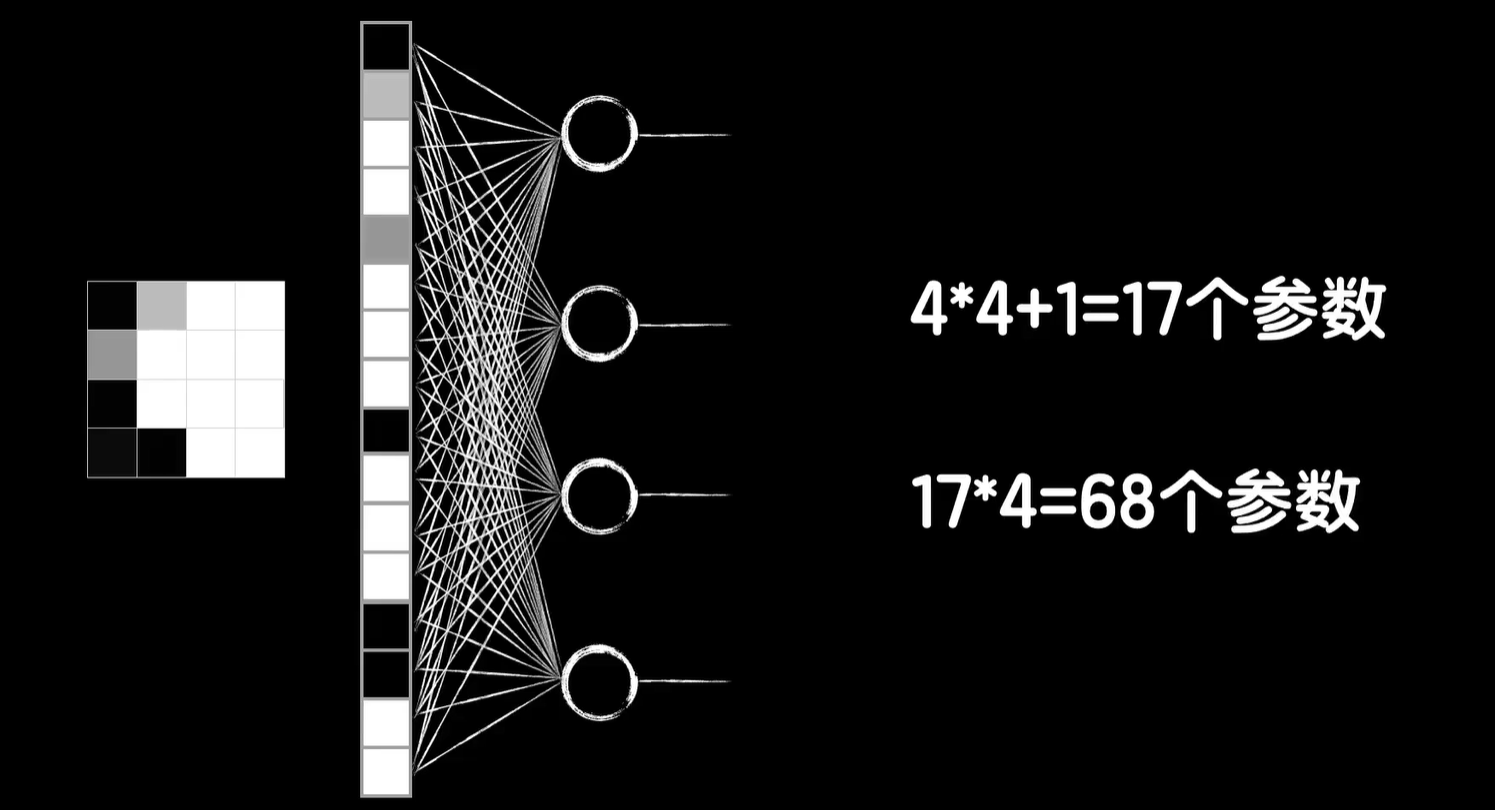
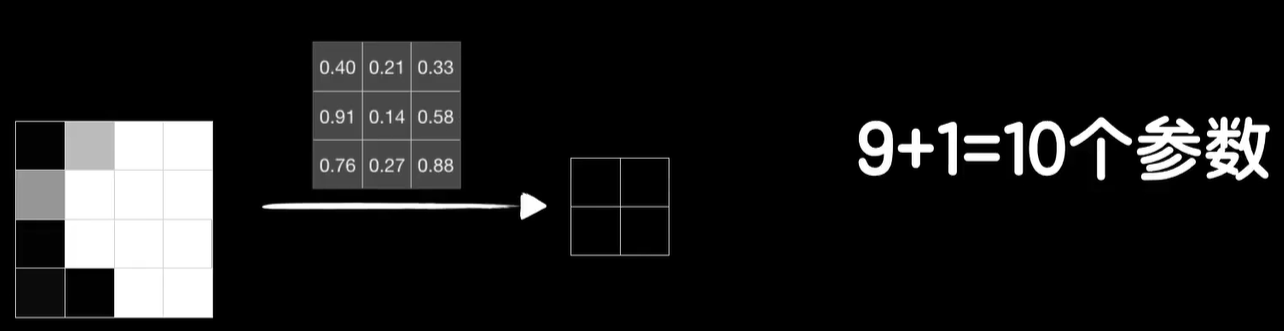
这是4×4的图像,实际上真实的图片往往比较大,比如8×8的图片,为了得到4个输出,这样的一个全连接层需要260个参数,但如果还是使用3×3的卷积和的卷,基层那么还是只有10个参数,再比如我们的mnist的数据集是28×28的图片,需要3140个参数,而如果是我们拍摄的高清大图,这个参数将变得很大,而网络参数越多也就意味着训练将变得困难和缓慢,但使用3×3卷积核的卷积层还是只需要10个参数,但为什么共享参数它就行得通,这就回到了一开始的那个问题,卷积到底是在提取什么呢?
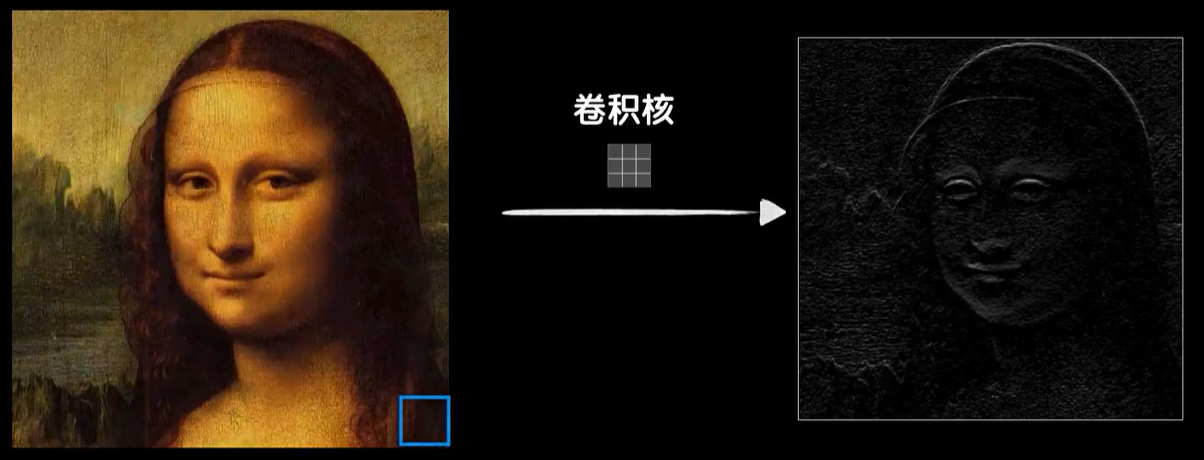
我们已经说过利用卷积可以提取比如轮廓纹理这样的特征,假如通过训练之后卷积核变成了一个提取垂直边缘的卷积核,那么一个图像不无论是在左上角还是在右下角,还是在其他什么地方提取垂直边缘的方式都是一样的,所以我们的权值参数可以共享,所以说卷积核的参数并不是我们事先设置好的,而是像普通神经元的权重参数一样通过训练学习而来。
但是一个卷积核训练的结果是提取图像的一种特征,这还不够,我们需要提取图像更多的特征方法也很简单,那就是再搞一个卷积核提取第二种特征,再搞一个提取,第三种,实际上你想要提取多少特征就搞多少个卷积核就可以。
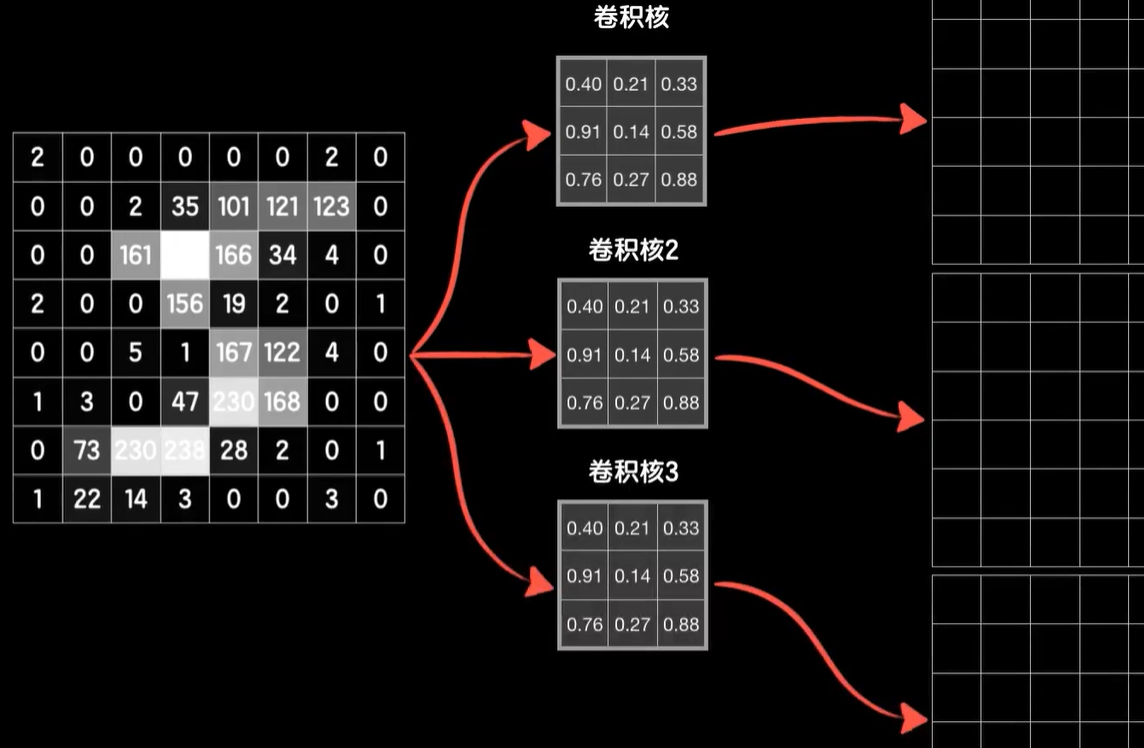
而这三个卷积核卷出来的三个结果就是一个三维的张量,我们可以把三维张量中的数据铺开成为一个一维的向量,然后在后面构造全连接层神经网络,把这个铺平的向量作为数据输入其中,然后该干嘛干嘛,但在送入全连接层之前,我们还能不能继续去卷6×6×3的数据?
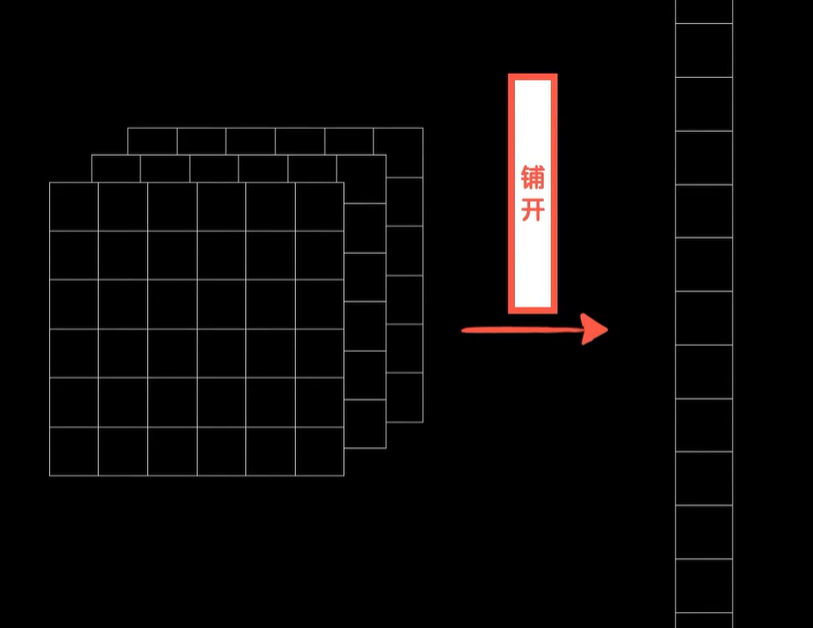
当然可以,比如在卷积神经网络发展的早期,深度学习领域,巨头人物Lecun在1999年就提出了一种经典的卷积神经网络结构,LeNet-5网络中就卷了两次之后再送入全连接层。

但我们怎么去卷6×6×3的三维数据,实际上卷卷积运算不仅可以在二维上进行,同样也可以在三维数据上进行。
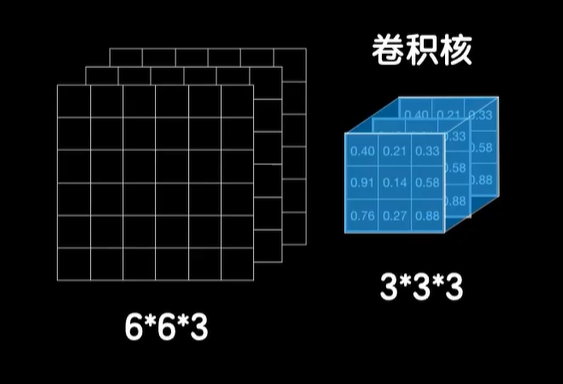
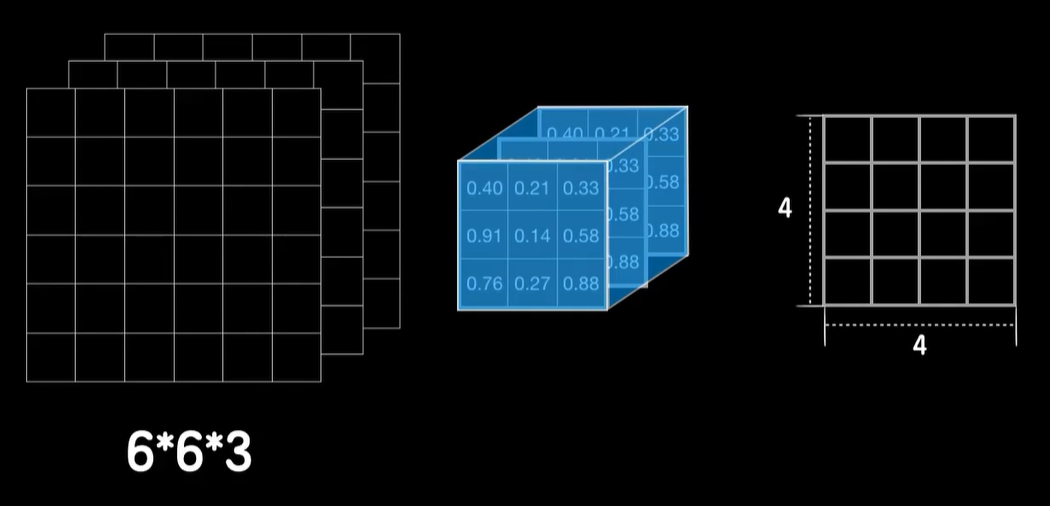
我们在二维数据上使用的是一个二维的卷积核,自然,在三维数据上我们使用三维的卷积核,我们使用一个3×3×3的三维卷积核去卷上一个卷积层输出的6×6×3的数据,三维卷积的方式和二维几乎一模一样,二维卷积是把卷积核罩在二维数据上,找到对应位置相乘,然后加起来三维卷积同样是找到数据和卷积立方块对应的位置的元素相乘,然后加起来得到一个结果,过程一模一样,只不过从二维变成了三维,当然最后还要让卷积的结果加上偏置,再经过激活函数做非线性运算得到最后的输出,这样一趟卷下来就变成了4×4的输出。
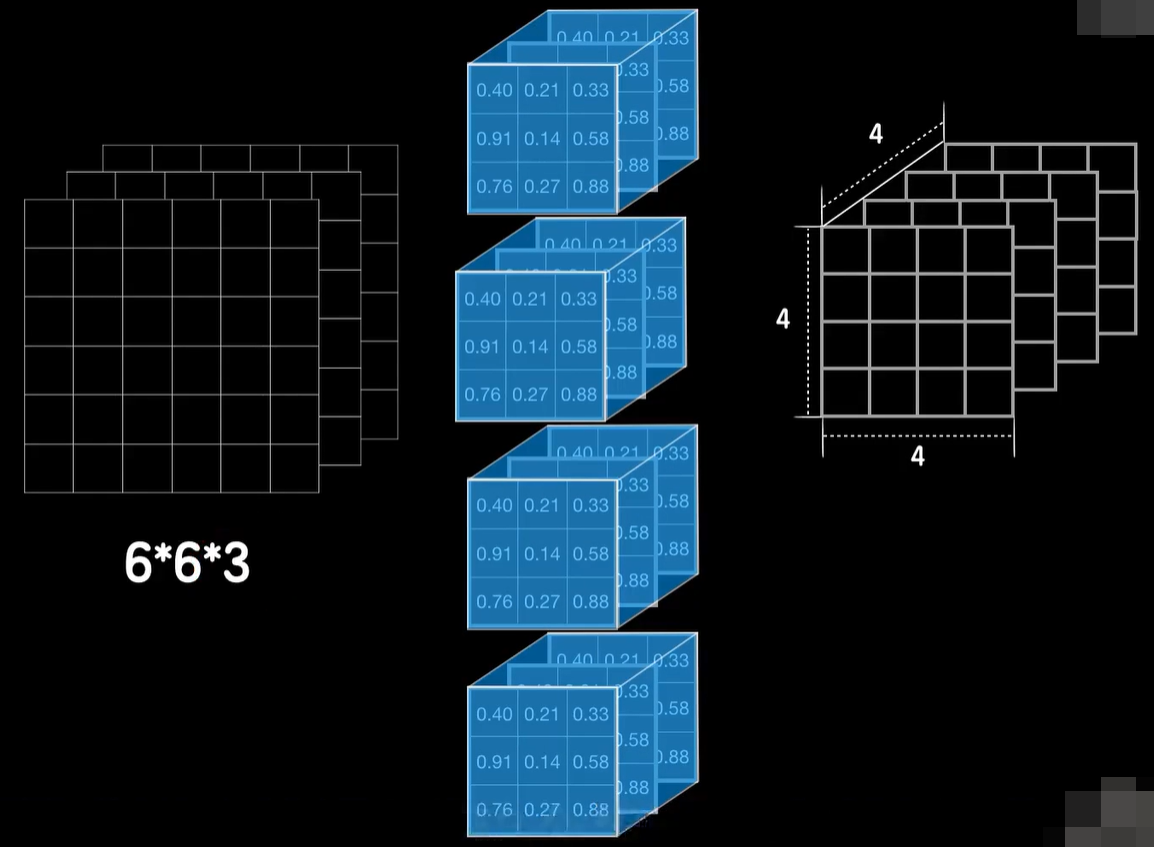
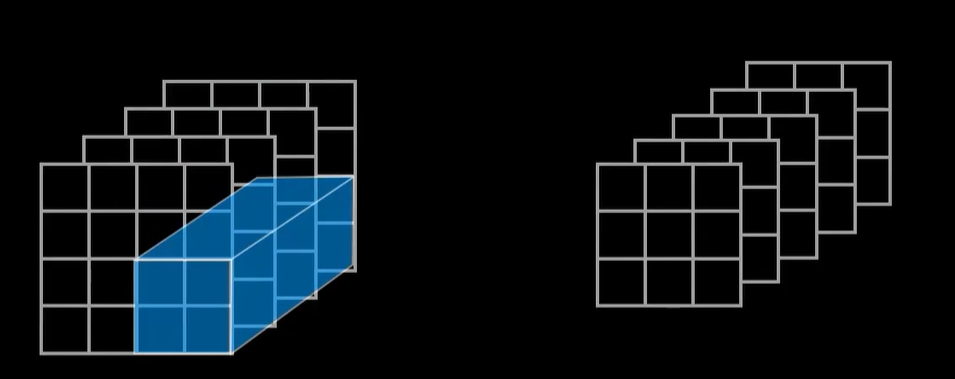
当然第二层卷积层我们也可以使用多个三维的卷积核,比如我们搞4个三维的卷积核,这样输出的结果就变成了4×4×4,这又是一个三维的张量数据,被卷积核卷积的数据的第三个维度值,也就是所谓的通道数(注意不是卷积核的数量或者维度,指的是输入数据的维度)。
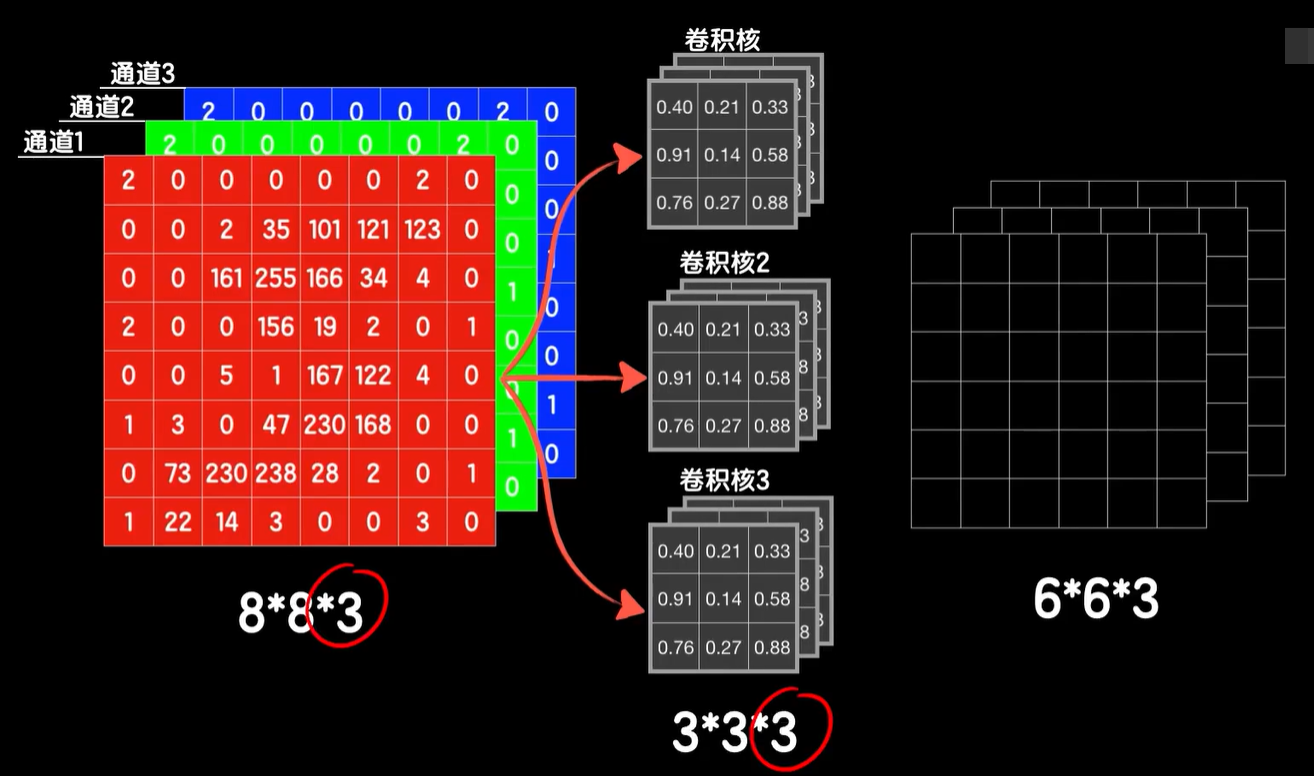
我们来看第一个卷积层,如果我们的图像是彩色的,这个名字就相当合理了,我们说灰度图像的数据是二维的,而彩色的图片只有RGB三个通道,所以我们的输入是一个三通道的图像,那么自然就是一个长×宽×3的三维数据,你看第3个维度的大小3就表示有三个通道,所以我们把数据的第三个维度的值也就称之为通道的数量,要对这样的数据进行卷积,卷积核也必须是三维的,而且第三个维度的值也必须和数据的通道数一样,不然罩不住。
那么思考一下,如果我们还想把第二个卷积层的输出结果继续卷,那需要什么样的卷积核?没错,为了让卷积核能够罩得住数据,卷积核的第三个维度只需要和数据的通道数一样,我们可以使用3×3×4的卷积核,当然3×3可以换成其他的大小,但是为了能够罩住输入数据,这个4是不能换的。
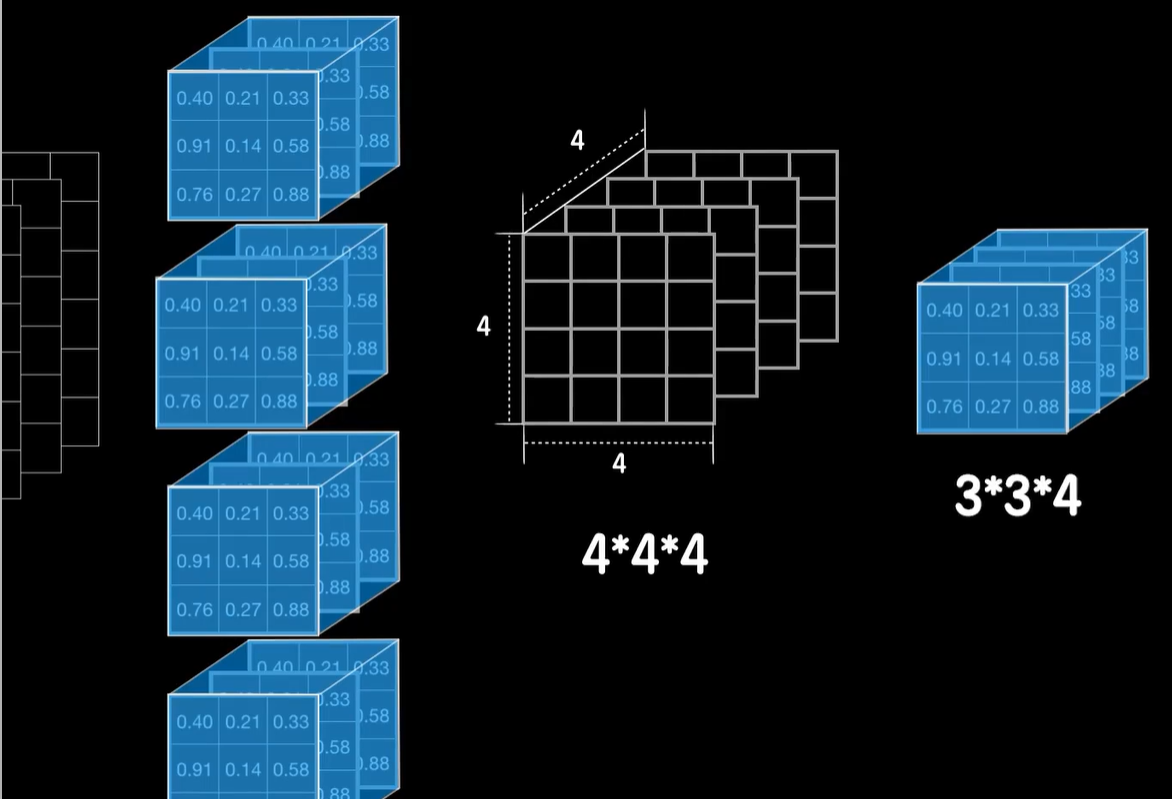
同样如果是用5个3×3×4卷积核,那么这一卷积层的最后输出就是一个2×2×5的张量数据。
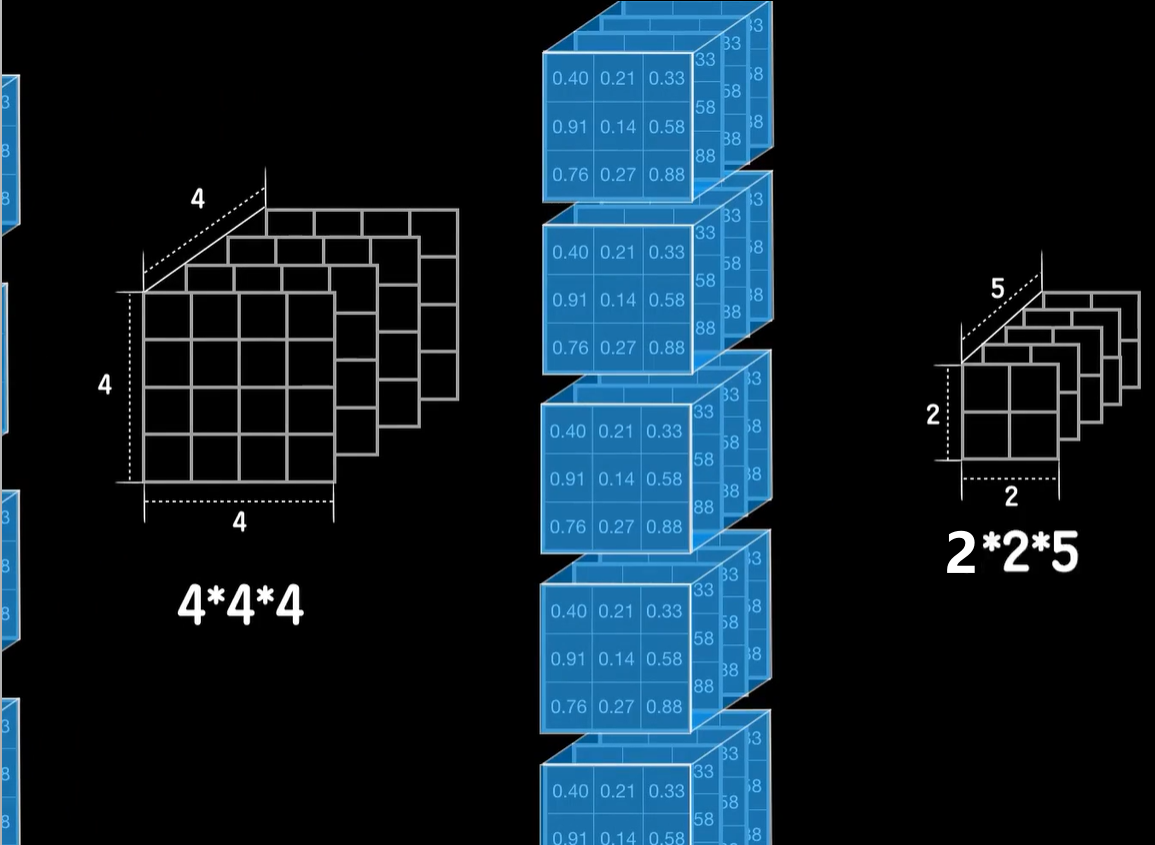
好的,我们已经说完了如何把卷积操作应用到神经网络结构中,变成卷积神经网络。但我们刚才提到的经典的LeNet-5卷积神经网络中,除了我们熟悉的这两个卷积层和后面的全连接层以外,还多出了两个立方块,这是何物,这两个立方块就所谓的池化层。
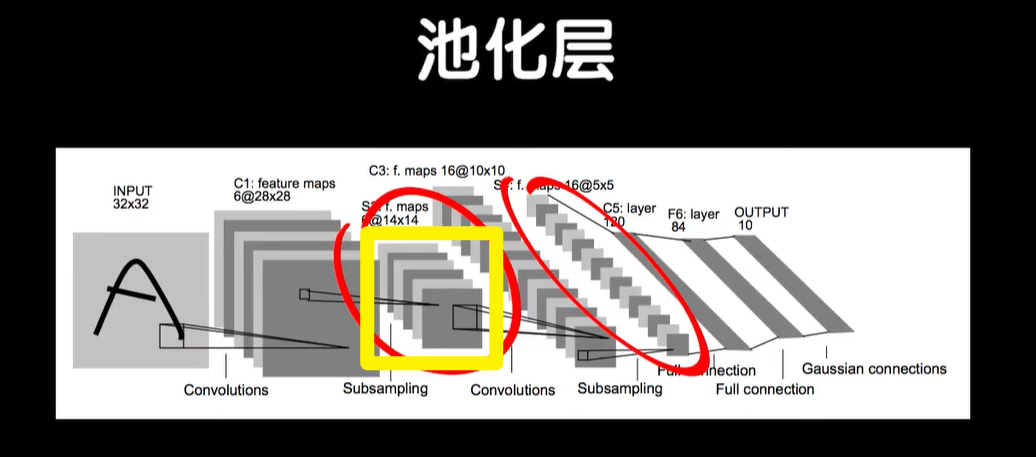
先看是什么,再说为什么?
简单起见,我们还是以单个卷积核卷二维数据为例,比如经过第一层卷积层8×8的数据被3×3的卷积核卷成了6×6的输出,这个输出接下来就进入池化层进行池化操作,是这样的。我们从这个数据的左上角开始框出一个比如2×2的区域,当然不一定非得是2×2,然后求出这2×2的数据的平均值得到一个结果,然后像卷积操作那样向后移动一步,再求出2×2数据的平均值得到第二个结果,然后一直顶到最右边,再向下移动一个像素换到下一行,重新从左到右的得到这些2×2数据的平均值,这个操作就是池化,右边就是池化得到的结果。
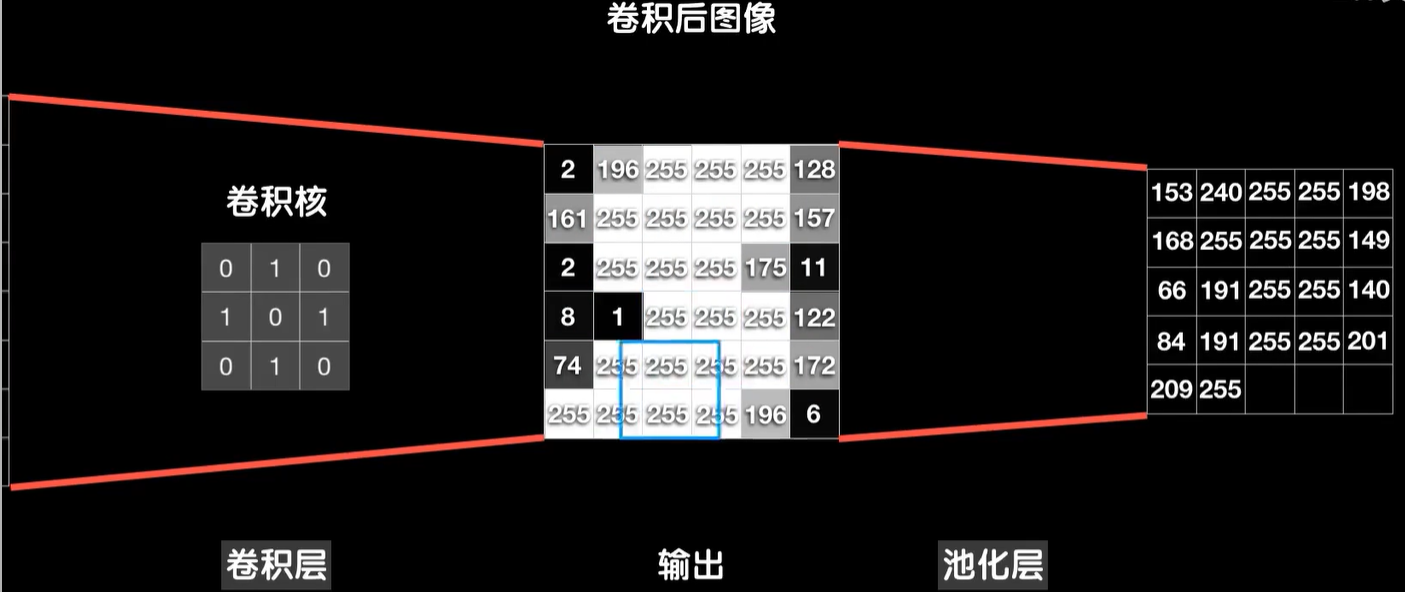
当然我们不仅可以采用平均值的方式,还有一种常见的方法是取最大值,这种取最大值的方式也叫maxpooling,最大池化,前面取平均值的方式也叫AveragePooling,平均池化,
而对于多通道的三维数据,其实简单的不行,比如用最大池化,那么我们就在每个通道上都这么操作就好了,结果还是和卷积层输出的通道数一样的一个立方块,不过经过池化之后变细了而已。
好了说完是什么?说为什么?虽然人们关于池化层有一些看似很有道理的分析,比如最大池化层让最大的值被筛选了出来,能很好的提取主要特征,但是我个人的看法这只是一个工程上的trick,原因就是人们发现加入池化层之后往往效果不错,所以虽然在很多经典的卷积神经网络中,往往都会在卷基层之后加上池化层,但这并不是必须的。还有一点,池化操作因为是固定的套路,所以在反向传播中它并没有任何需要学习的参数,
编程实验
复现一个早期经典的卷积神经网络LeNet-5,这个过程中我们细化一些卷积神经网络的一些微操作
我们继续使用上一节的代码。这里关于输入数据X_train和X_test,我们说明一下,我们上节因为送入的是一个全连接层,所以需要把每个28×28的二维数据扯成一个784的一维数据,所以我们用reshape把X_train和X_test从60000×28×28和10000×28×28,分别变成了60000×784和10000×784。但是对于本节的卷积神经网络,因为我们的数据直接送入卷积层,那卷积核直接在这个图像上做数据提取,所以是不需要把数据扯平的,当然也不是完全不用处理。
我们说过灰度图只有一个通道的数据,而RGB彩色图像有三个通道,卷积核的第三个维度值必须和他所讲的数据的通道数一样,所以我们必须明确数据的通道数,这样开始才能够根据这个通道数构建合适的卷积核,我们这里的输入数据因为是灰度图只有一个通道,所以一个图像的数据是28×28的,实际上这是因为只有一个通道,所以第三个通道维度值1被省略了,实际上每个图像数据的形状应该是28×28×1。那么在送入卷积层之前,我们应该把输入数据的通道数变得明确,所以我们把60000×28×28的数据都reshape成6万×28×28×1,你看这样我们就明确的指定了图像到底有几个通道,虽然只有一个通道,对我们来说其实不写的,我们也知道是咋回事,但是对于死板的机器来说,你不写它就不知道区别还是挺大的。当然我们说过要对数据进行归一化操作,所以除以255还是要保留,同样我们把测试集也这么处理一下,这样我们的数据集就准备好了。
# LeNet-5
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
import matplotlib.pyplot as plt
from keras.utils import to_categorical
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" # Disable GPU
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train = X_train.reshape(60000,28,28,1)/255.0
X_test = X_test.reshape(10000,28,28,1)/255.0
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
我们对照架构图一点点的来实现它
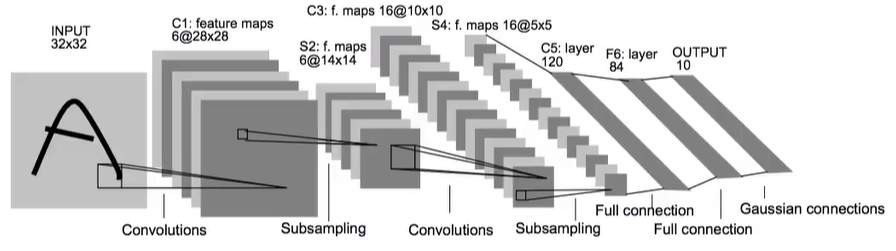
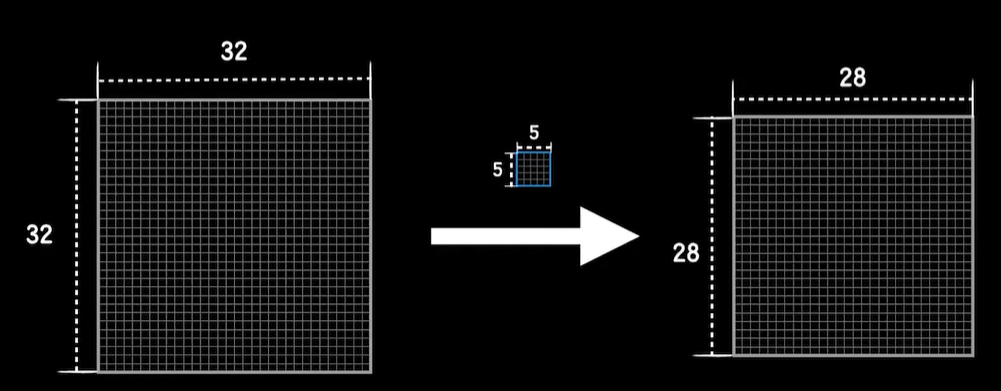
输入是一个32×32的灰度图,当然我们的mnist的数据集是28×28的,所以一会我们实现的时候把这里稍微改一下,通过第一层卷积层之后变成了28×28×6,从32卷成28×28的,所以实际上LeNet5的这一层使用的是一个5×5的卷积核。
最后这个6就是我们刚刚说的用6个卷积核,所以结果的通道数就是6,在keras中实现一个卷积层,很方便,我们导入keras中的Conv2D卷积层,这个Conv2D就是一个二维的卷积层,我们把它堆叠到我们的虚拟模型中。

我们来说明一下这几个参数的意思:
- filter就是表示卷积核的数量,我们刚才说使用了6个卷积核
- kernel_size就表示卷积核的尺寸,这一层的卷积盒是5×5的
- strides表示步长,我们在卷积的时候,我们说向右依次挪动一步,到最右边之后回到最左边向下挪动一步,实际上也可以不挪动。比如我们向右挪动2步3步或者4步,这就是步长的意思,在LeNet-5的网络中向右和向下的步长都是1,所以我们设置strides等于1
- input_shape输入形状,我们之前说一个普通的全连接层神经网络,我们指定input_dim就可以,因为普通的神经元的输入是一个向量,所以我们只需要指定向量的维度就好,但是在卷积层里输入数据是一个多维的张量,我们需要指定数据的具体形状,这样keras能根据数据的形状构建合适的卷积核。灰度图的话就是28×28×1,卷积核就是5×5×1的,如果是彩色图 input_shape就是28×28×3,keras就会根据第三个通道数构建一个5×5×3的卷积核,因为我们说过卷积核的第三个维度值必须和数据的通道数一样,这样才能够罩得住
- 然后是padding=‘valid’,这是卷积的时候数据填充的方式。因为你会发现一个问题,我们的原始图像是28×28的被5×5的卷积核卷完之后就变成24×24的变小了,实际上我们知道在深度神经网络中往往有很多层,后面我们发现卷积层也会有很多层,这就意味着原始图像会越卷越小越卷越小,随之而来的就是卷完之后信息损失越来越多。所以人们提出了一种填充的方案,在卷积之前根据卷积核的大小,先在原始图像的4周填充几圈全是0的像素点,比如卷积盒是5×5,那么就填充两圈,这样原始图片就从28×28被填充成为了32×32,被5×5的卷积核卷完之后,仍然是28×28形状保持不变。这种卷积模式就是Same模式,它的名字就说明了一切卷积后和之前是一样的;而之前不加填充的模式也称为valid模式,它的名字也说明了一切,这种模式比填充一圈像素看起来似乎更有根据一些。而这两种模式目前都比较常用,根据具体的问题自行选择。LeNet-5使用的是valid的模式,也就是越卷越小
- 最后是**activation=‘relu’**无需多言,那就是表示卷积层使用的是relu激活函数。
在第一层卷积层之后,我们把结果送入到下一层池化层,LeNet-5使用的是窗口尺寸为2×2的平均池化层,我们导入keras.layers.AveragePooling2D平均池化层,LeNet-5中把池化操作写成了subsampling,翻译过来就是下采样/子采样,因为取平均值池化后的数据变细了,keras中池化操作的步长如果不指定,默认和pool_size一样,这里的步长也就默认是(2,2)。
接下来又是一个卷积层,这个卷积层使用的是16个5×5的卷积核,把14×14×6的数据卷成10×10×16的结果,这一层我们不再需要指定input_shape,凯瑞斯会自动的推断出来,当然我们这里mnist的数据集因为是28×28的第一层卷积,层卷出的结果是24×24×6,那在经过第一个池化层之后,变成了12×12×6,所以第二层卷积层卷出来的是8×8×16,我们在后面再接一层,池化层输出4×4×16,然后后面就是全连接层了,我们需要把最后池化层的输出平铺,keras也提供了很方便的API,我们导入keras.layers中的Flatten()
再后面就是我们之前课程中说的全连接层了,先是一个120个神经元的隐藏层,再接一个84个神经元的隐藏层,最后再接一个10输出的输出层,当然我们说过输出层使用的是softmax激活函数做多分类,这样我们就把LeNet-5网络给搭建好了。现在我们就把mnist的训练集的数据送入训练。
# LeNet-5.py
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
import matplotlib.pyplot as plt
from keras.layers import Conv2D
from keras.utils import to_categorical
from keras.layers import AveragePooling2D
from keras.layers import Flatten
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" # Disable GPU
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train = X_train.reshape(60000,28,28,1)/255.0
X_test = X_test.reshape(10000,28,28,1)/255.0
Y_train = to_categorical(Y_train, 10)
Y_test = to_categorical(Y_test, 10)
model = Sequential()
# 卷积层
model.add(Conv2D(filters=6,kernel_size=(5,5),strides=(1,1),input_shape=(28,28,1),padding='valid',activation='relu'))
# 池化层
model.add(AveragePooling2D(pool_size=(2,2)))
# 卷积层
model.add(Conv2D(filters=16,kernel_size=(5,5),strides=(1,1),padding='valid',activation='relu')) # input_shape不用指定,keras会自动判断
# 池化层
model.add(AveragePooling2D(pool_size=(2,2)))
# 需要把上层结果变成数组交给下层的全连接层
model.add(Flatten())
# 全连接层:先是一个120个神经元的隐藏层,后是一个84个神经元的隐藏层
model.add(Dense(units=120, activation='relu'))
model.add(Dense(units=84, activation='relu'))
# 10个神经元的输出层
model.add(Dense(units=10, activation='softmax')) # 输出层使用spftmax激活函数
# 送入训练
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.05), metrics=['accuracy'])
model.fit(X_train, Y_train, epochs=5000, batch_size=4096)
# 评估测试集
loss, accuracy = model.evaluate(X_test, Y_test) # 返回代价和精确度
print("loss: "+str(loss))
print("accuracy: "+str(accuracy))
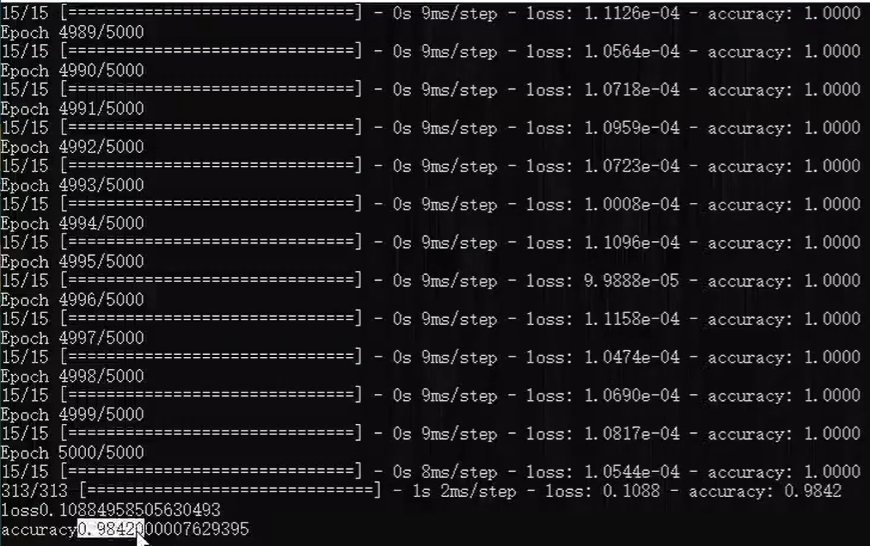
最后我们的LeNet-5卷积神经网络在mnist的测试计算准确率达到了98.4%,比上节课的97%要高,而且相比于上节课三层隐藏层每层256个神经元的全连接神经网络,你可以简单的算一下卷积神经网络的参数实际上要少很多。当然这还是一个最早期的卷积神经网络结构,在后期出现了更加复杂的卷积网络,比如AlexNet、VGG等在图像识别领域中的效果也越来越好好的
AlexNet(Hinton的学生Alex Krizhevsky设计,在2012年的ILSVRC竞赛取得第一名。)
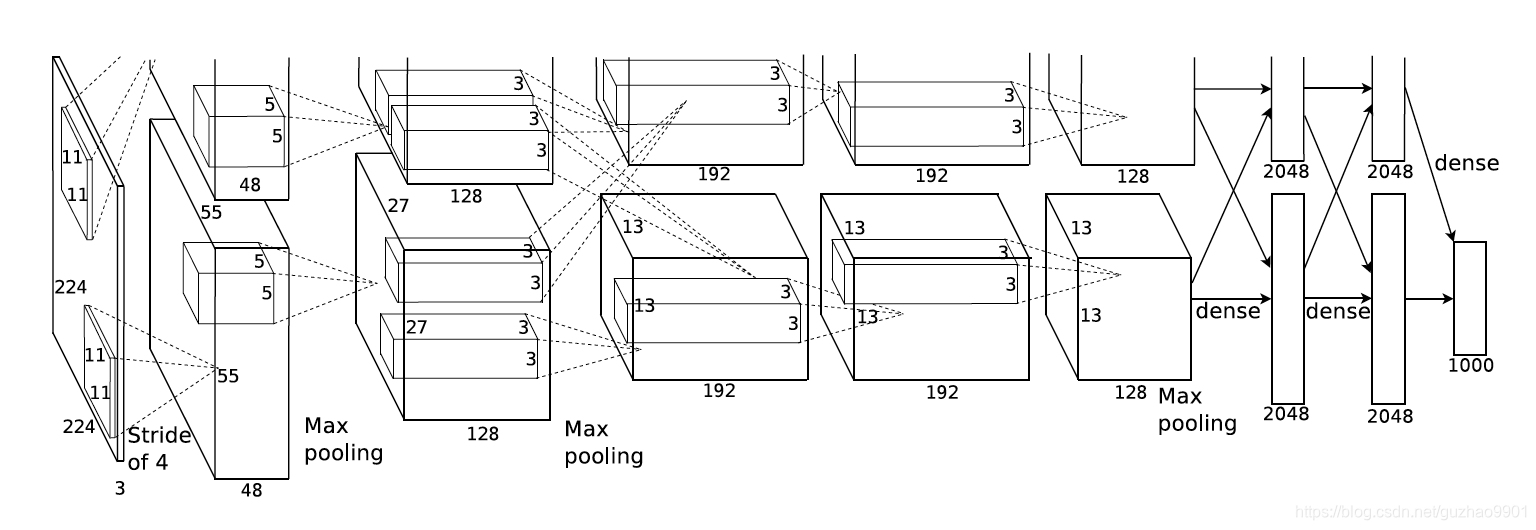
VGG(牛津大学的Visual Geometry Group(视觉几何组)在2014年提出,并在当年的ImageNet挑战赛中取得了优异的成绩。)
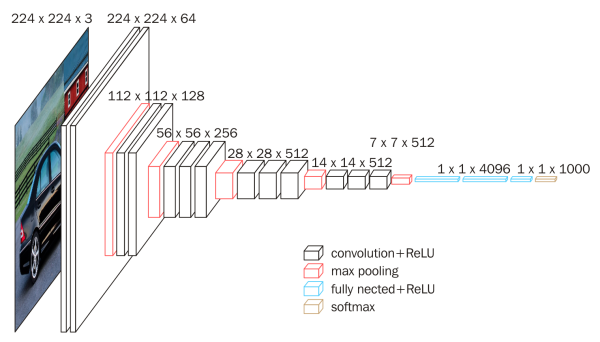
下一节我们讲解循环神经网络。
十二、循环:序列依赖问题
原理
前面两节我们已经学习了卷积神经网络的基本原理和应用,仔细想想之所以使用卷积运算,那是因为我们观察到一个图像数据在空间上有着不可分割的关联性。再想一下数据除了在空间上可能出现关联性以外,也可能在时间上如此,比如气温、数据、股票数据等等,当然最典型的就是我们人类的语言,如果是语音,声波随着时间依次传入我们的耳朵,进入大脑,一句完整的音波输入之后才知道对方在说什么,如果是文字、字或者单词随着时间逐个通过眼睛进入大脑,读完之后才知道这句话在表达什么,所以面对这样的时间上有关联性的数据,神经网络该如何去识别和处理。
我们以文字举例,假如这些是某个视频评论区中的评论,现在想让神经网络识别出这些评论中哪些是正面的,哪些是负面的,自然就像我们第一次面对图片数据那样。

首先我们要想个办法把评论文字转成计算机能够识别的数字,我们的第一反应可能是字符的编码值,比如英文我们可以使用英文字符的ASCII值,把这句话转化为数字。

但在自然语言处理中最小的单位往往是词,而不是单个的字母,比如单词adopt和adapt在字母层面上很像,但却是两个意思完全不同的词,中文可能好一点,但单个汉字的价值也远远不如词。

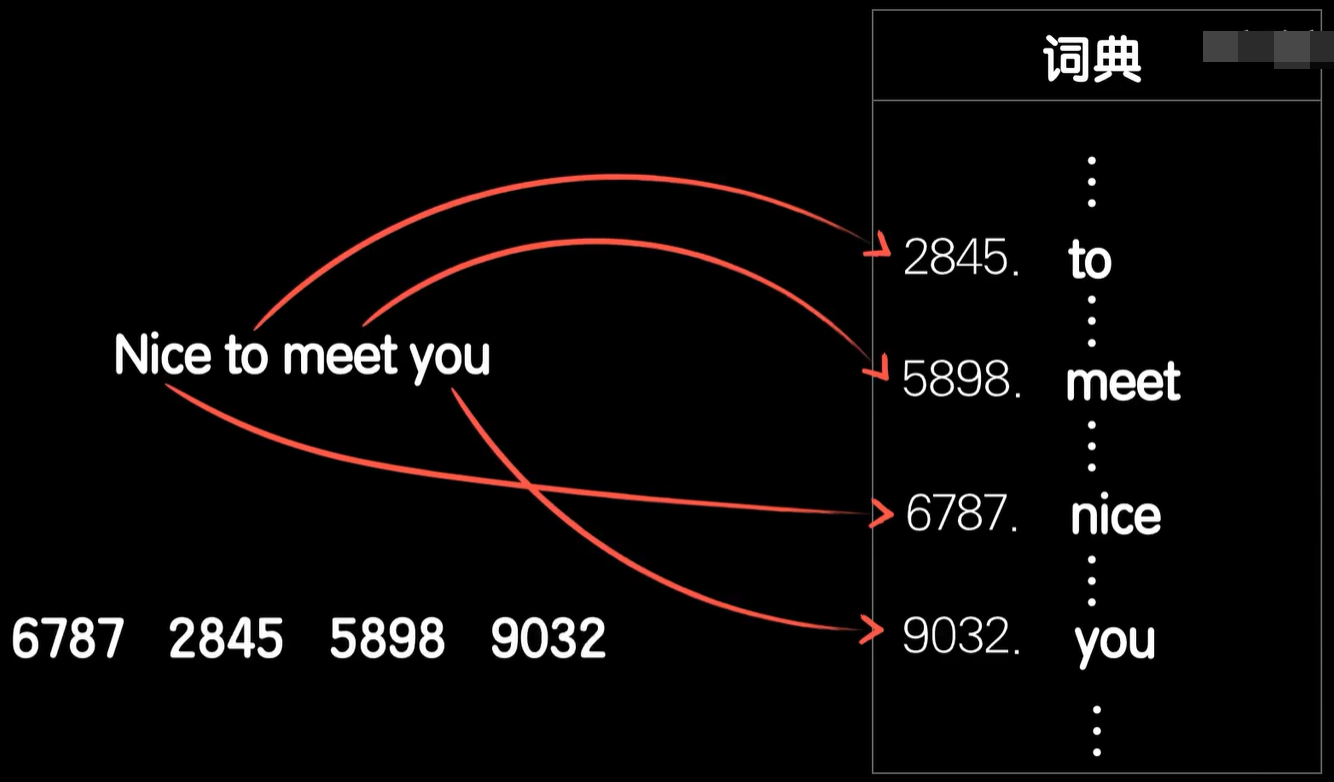
所以我们一般把词作为自然语言处理中最最基本的单位,那么如何把一个词转化成一个数字?——查词典,打开一本英文词典,分别找到nice to meet和you在词典中出现的位置。比如nice是第6787,to是第2845,meet是第5898,又是第9032,那么我们就可以把这句话中所有的单词转化成数字,从而把这句话转化成一个向量,然后就可以送入到神经网络之中了。
中文也是这个思路,不过不像英文那样可以自然的通过空格切割一个句子的单词,中文要麻烦一点,需要先进行分词操作,比如“这个视频非常精彩”,这句话就可以分词为这个、视频、非常、精彩4个词,分好词之后和之前一样在中文词典中找到出现的位置,把它们转化成数字,从而把这句话转化成一个向量。
当然这样处理会有一个问题,比如如果是一个有1万个词汇的词典,假如开除和开心两个词,因为第一个字读音的关系在词典中出现的位置很接近,比如分别在第4098和第4099,那么这两个词在数据上看来就很相似,如果我们再把它们进行归一化操作,那么就是0.4098和0.4099这两个数值差异极小,但遗憾的是开心和开除两个词指代的概念完全不同,这样的数据就会给我们的预测模型带来不必要的麻烦。

所以在自然语言处理领域,我们需要对词汇的表示方法做进一步的处理,使用one hot编码方式对词汇进行编码似乎是个好主意,如果我们使用一个有1万个词汇的词典,那么我们把每个词都处理成为一个one-hot编码,这样第一个词编码后就是第一个元素是一,其他元素是零的1万倍的向量,第二个词编码后是第二个元素是1,其他是0的向量,以此类推。

但问题是我们严格把每个词都变得完全不一样的同时也丢失了词汇之间的关联性,比如猫和狗这两个词在数据上应该更加接近,苹果和西瓜更加接近,而猫和苹果的差距应该更大,但呆板的one-hot的编码却无法体现这一点,因为这种人为的随意且呆板的词表示方法完全不能体现语言中词语的特点,而特征提取不当的数据会让神经网络变得难以训练和泛化。

再者one-hot的编码会让输入数据非常的大,比如我们使用一个有10000个词的词典,这样每个词的one-hot的编码都是10000维的向量,那么一个有4个词的句子,那么输入数据就是40000个元素,所以人们提出了词向量的方法,当然这属于NLP领域的知识,与我们的神经网络本身没有什么关系。
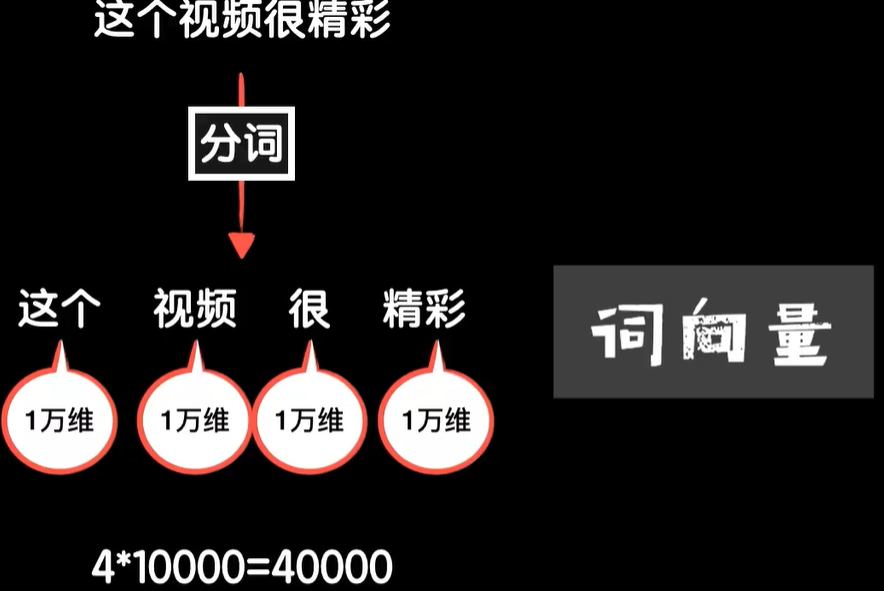
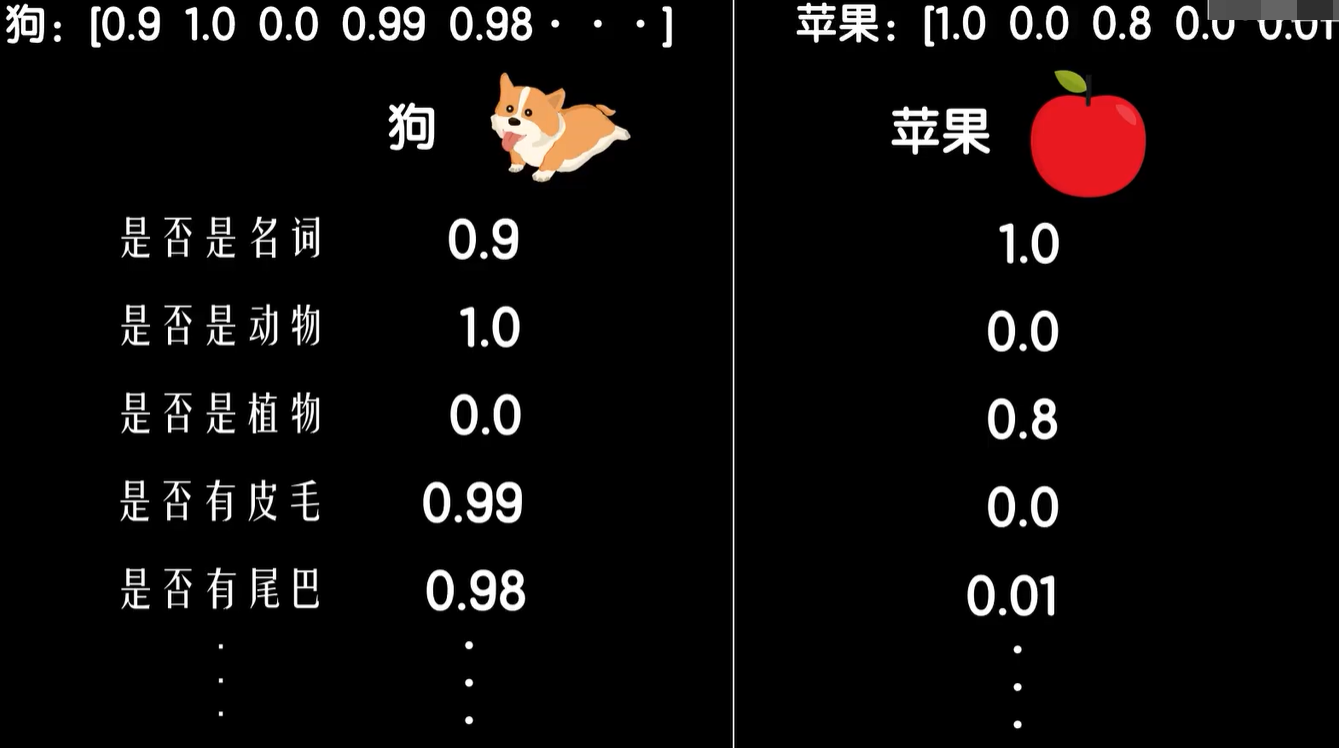
我们简单了解一下词向量,在介绍多维数据的时候,我们说过每个维度实际上是一个事物多个角度的特征,比如豆豆数据中我们可以收集大小、颜色、深浅、硬度等等豆豆的特征,构成一个输入的销量数据,那么对于一个词汇是否也可以如此,当然语言本身就是对现实世界的描述,词汇本来也是用来指代一个事物的,比如狗这个词,从语言学的角度来看它是一个名词,当然在当前的语言环境中它也有一点形容词的成分,所以这个特征值可能是0.9大概率是个名词,而从它所指代的事物上来看是动物不是植物,然后我们还可以提取像有没有皮毛,有没有尾巴等等这样的特征。这样我们就通过提取出一个词汇的多个特征值形成了一个词向量,对于这些特征,苹果这个词的特征值分别是名词,不是动物是植物,当然也不一定就是植物,比如它也可以指代一个手机的品牌,所以这个值可能是0.8,八成是个植物,没有皮毛,没有尾巴等等词语的这种表示方法十分美妙。不仅可以表示出不同的词,甚至具备了一定的推理能力。
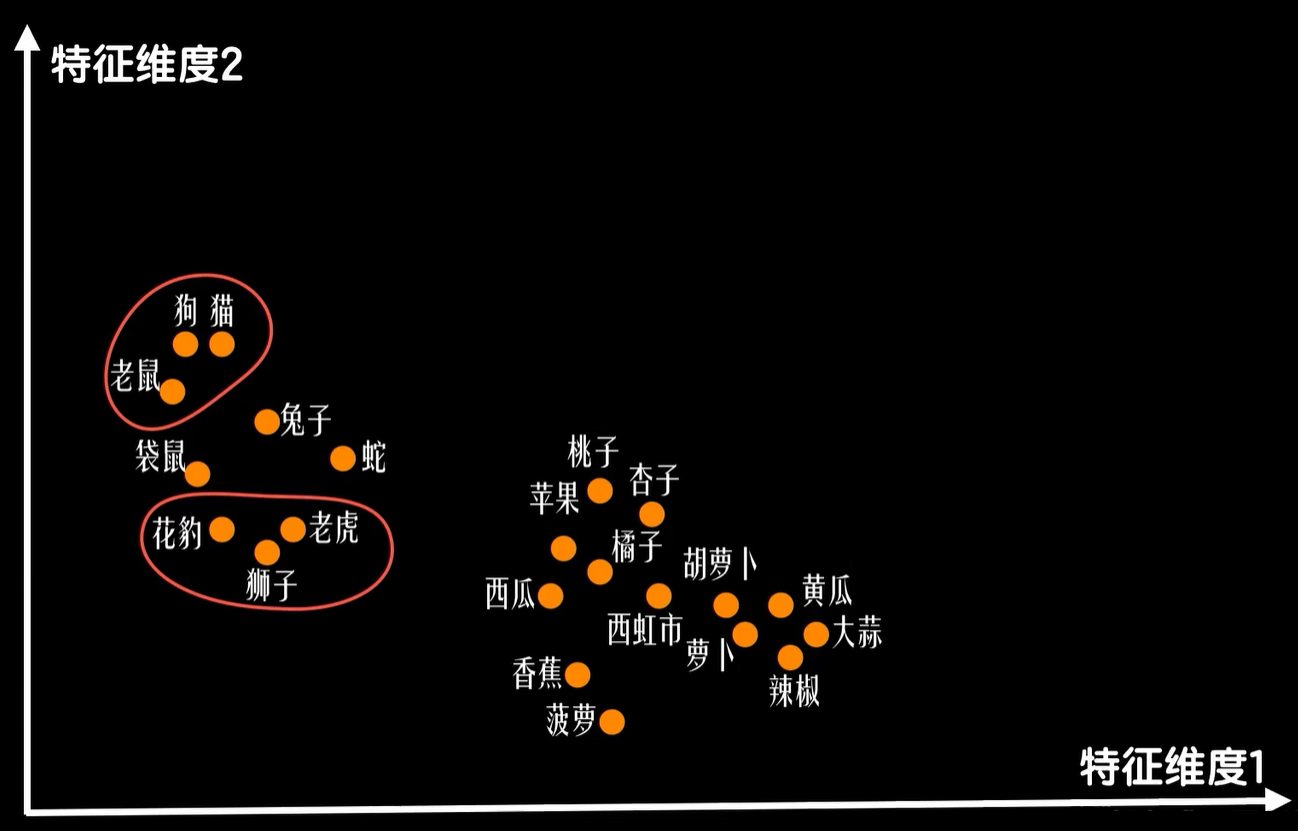
为了作图方便,假设我们只提取词的两个特征,也就是说用一个二维的词向量表示一个词,那么我们把一个特征提取合适的词向量集合在二维空间上画出来,最后会是这样。词义更加接近的词在向量空间中更加接近,反之词义无关的词距离很远,比如动物词汇聚集在了一起,植物词汇聚集在了一起,而动物中猫狗这种家养宠物和野生的豺狼虎豹相比距离又更近一些,植物里水果和蔬菜又各自聚集,而动植物之间的距离和像手机电脑这样的非生物相比又要近一些。
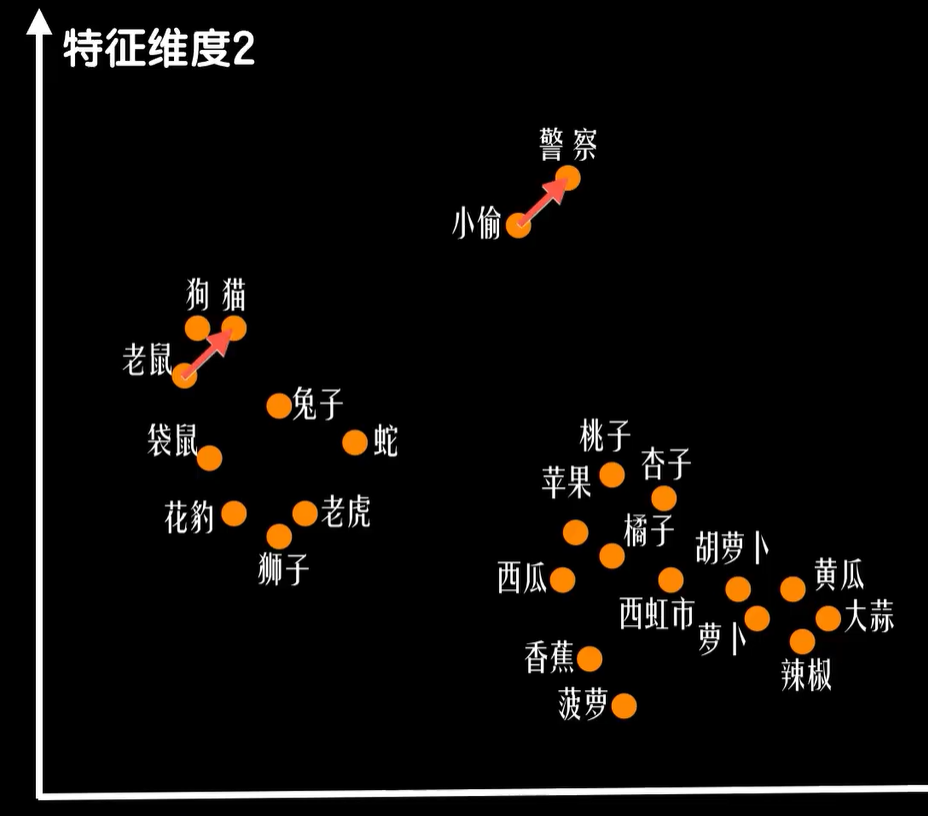
而有趣的是在一个特征提取适当的词向量集合中,如果我们用警察这个词的词向量去减去小偷这个词的词向量得到的结果向量和猫这个词的词向量减去老鼠,这个的词向量的结果向量非常的接近,这意味着警察和小偷的关系和猫和老鼠的关系十分相似。所以使用这样的数据会让我们的模型更容易训练,也更容易泛化,这个技术在NLP中称之为词嵌入,把词嵌入到一个特征向量空间。
那么问题来了,我们该如何提取一个词的特征,从而得到合适的词向量必然不是像我这样通过揣测,然后手工编写来看一下具体的细节,简单起见,假设我们要处理的文本中只有猫狗、苹果、西瓜这4个词,我们需要得到这4个词的词向量,而且我们希望词向量有10个特征,那么我们就构造1个10×4的词嵌入矩阵,并随机初始化矩阵的初始值。
这样这个矩阵的每一列就分别表示这4个词的十维词向量,接下来我们需要想个办法在嵌入矩阵上把某个词的词向量给提取出来,非常简单,我们还是依靠one-hot的编码来做这件事情,我们先给4个词做one-hot的编码,这样我们用嵌入矩阵点乘1个词的one-hot的编码值,比如苹果这个词,那么根据矩阵的点乘性质,由于苹果的one-hot的编码只有第三个元素是1,其他是0,所以把嵌入矩阵的第三列给提取了出来,同样用嵌入矩阵点乘其他词的one-hot的编码,就可以提取出各自的词向量。
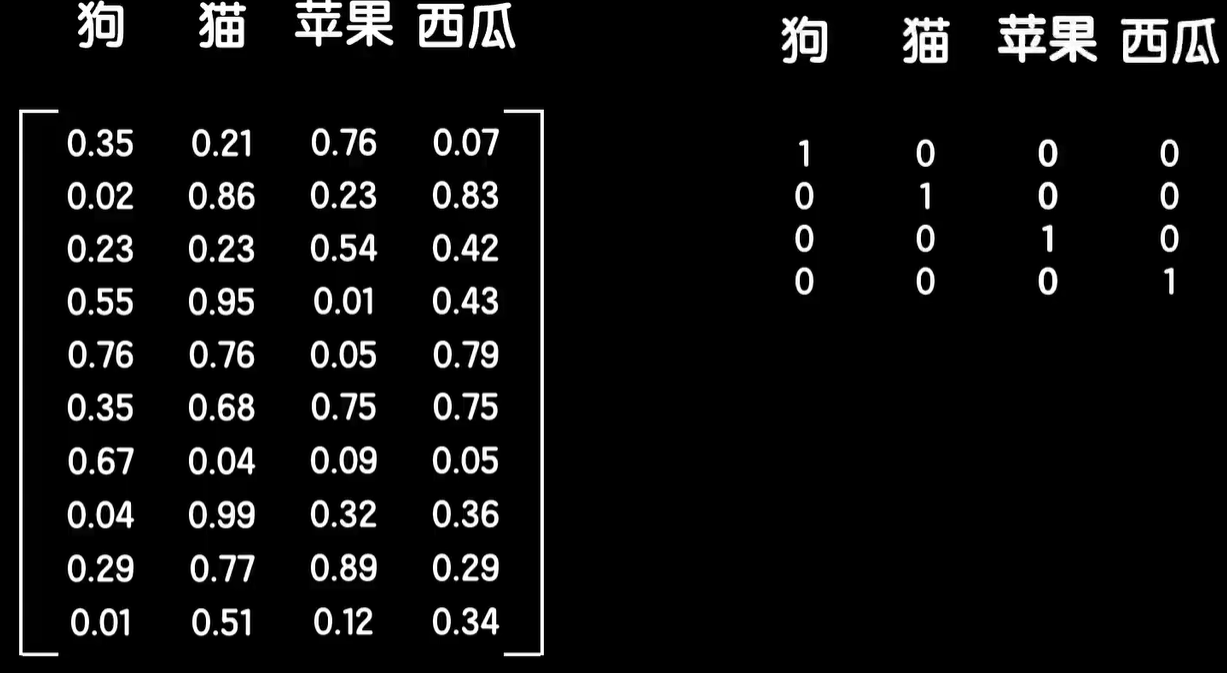
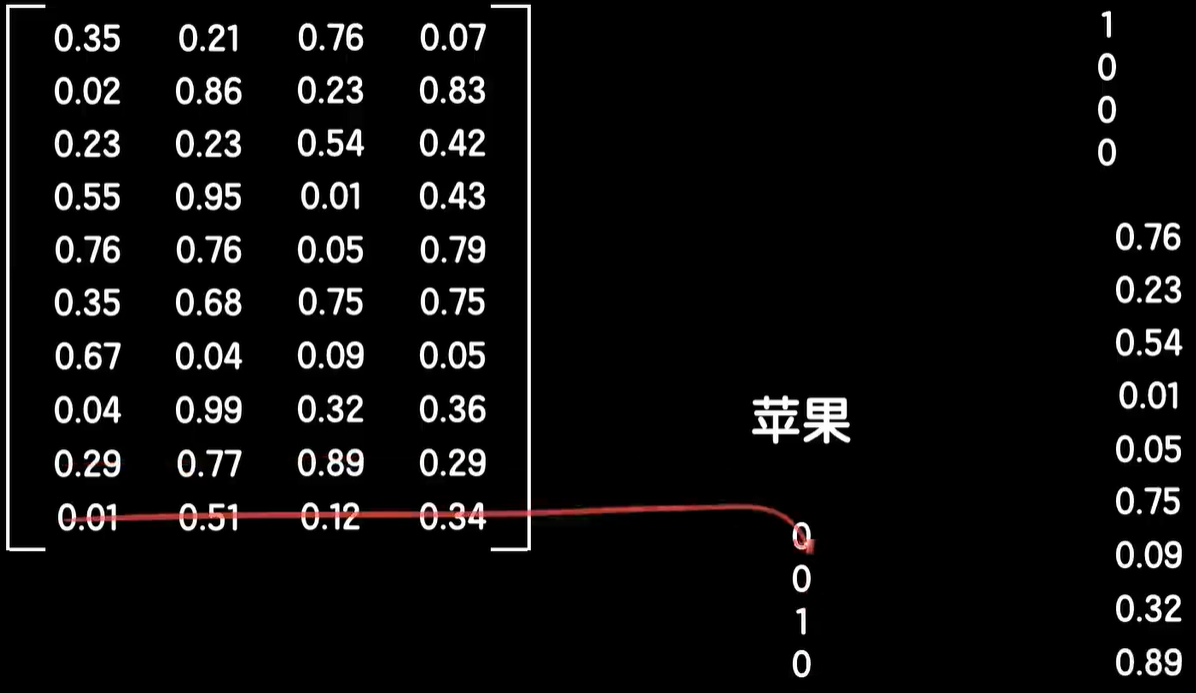
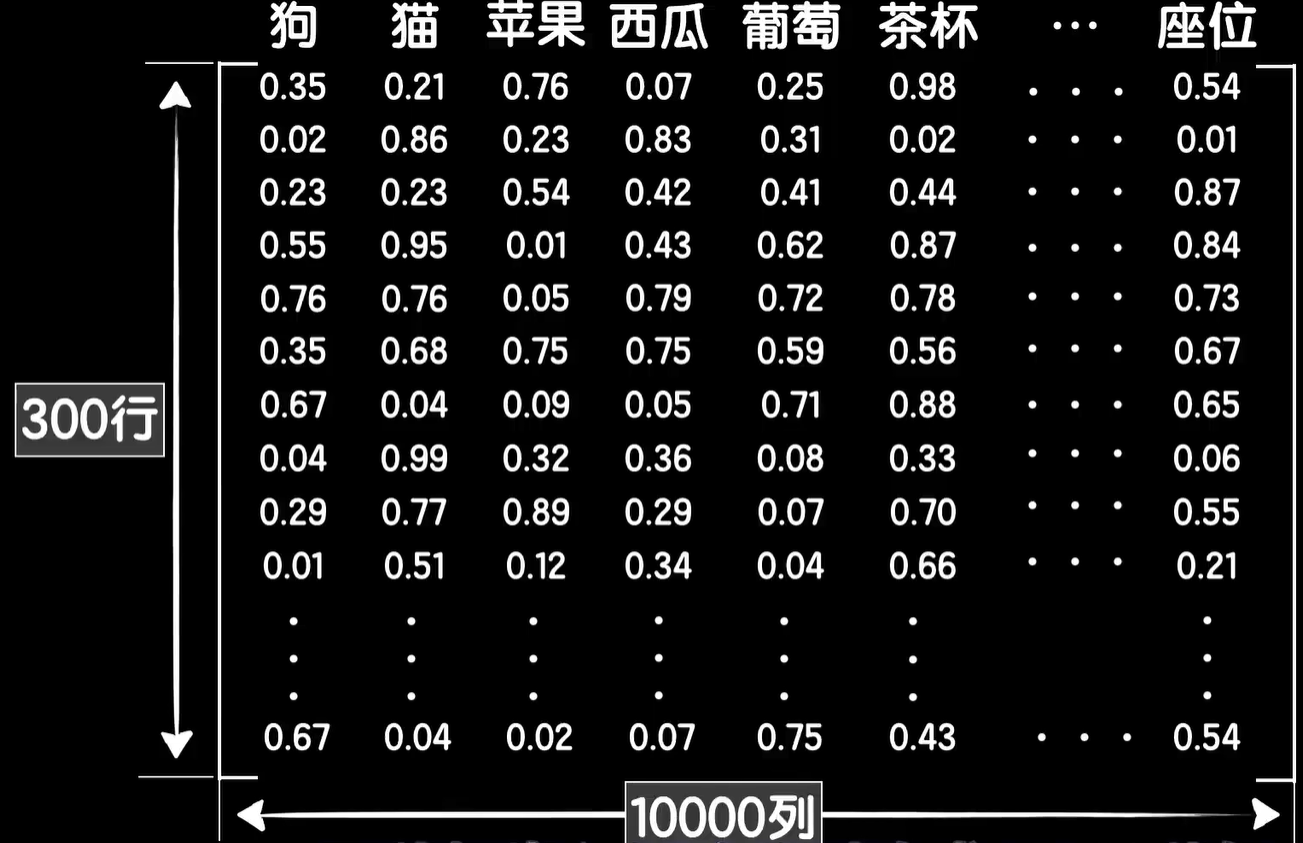
当然我们也可以让词向量的维度更多,换句话说提取更加丰富的特征,比如300个,那么我们就把嵌入矩阵改成300行就好,同时通常我们所处理的文本语料中所包含的词汇量肯定不会是4个这么少,比如有10000个词,那么就把嵌入矩阵的列改成10000就好,这时候每个词对应一个10000维的one-hot的编码向量,同样可以提取出各自的300维词向量,有了这个嵌入矩阵,我们就可以把一句话中所有的词转化为词向量。
为了展示上的清晰,假设全部语料只有2句话:

首先我们用全部词汇构建1个词嵌入矩阵,然后给所有的词做one-hot的编码,要把第一句话中的词都转化成词向量,首先我们需要把这句话中4个词的one-hot的编码向量合成1个矩阵,这样让嵌入矩阵点乘这个one-hot的矩阵,就把这个句子变成了1个词向量矩阵,每一列都是句子中对应词的词向量
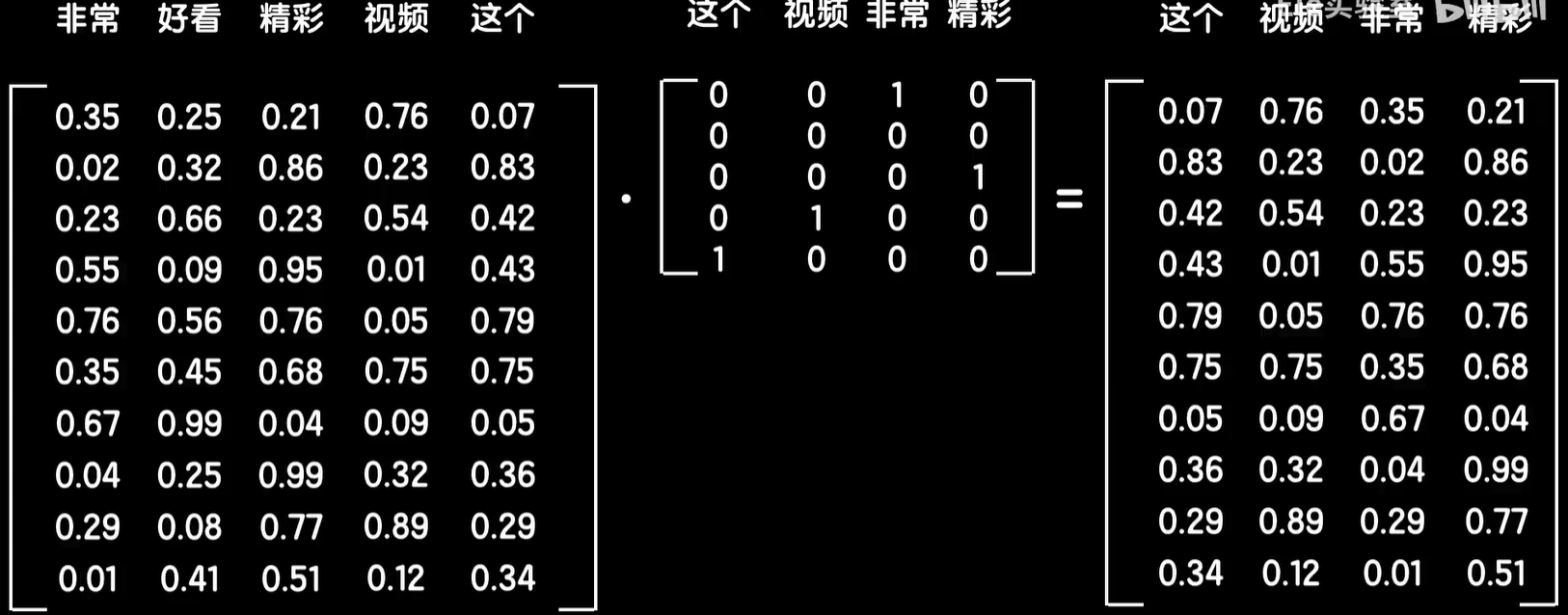
如果后面接的是普通的全连接神经网络,那么就把这些词向量铺开作为输入,然后进行前向传播,最后得到输出的预测值。
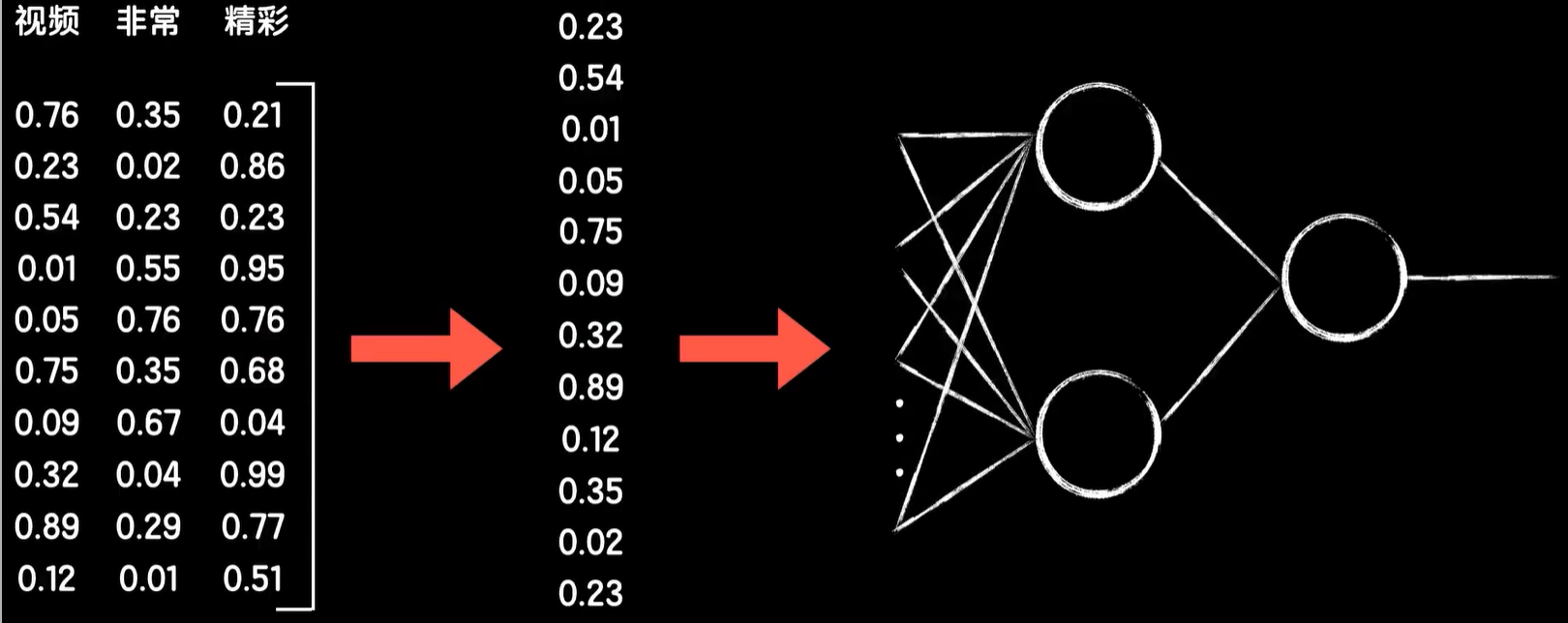
而在反向传播的时候,因为句子词向量提取的运算形式是我们用嵌入矩阵点乘one-hot的编码矩阵,这和一个普通的全连接层的线性运算部分一样,我们把它称之为嵌入层,就像普通的全连接层中的反向传播,把误差传递到权重矩阵并更新它一样,对于嵌入层,误差通过反向传播可以继续传递到这个词嵌入矩阵,更新它,而如我们所说,嵌入矩阵就是词汇表的词向量集合,所以我们的词向量就可以像卷积神经网络中的卷积核那样,在训练的时候不断学习,最后自己学习到合适的词向量表示。
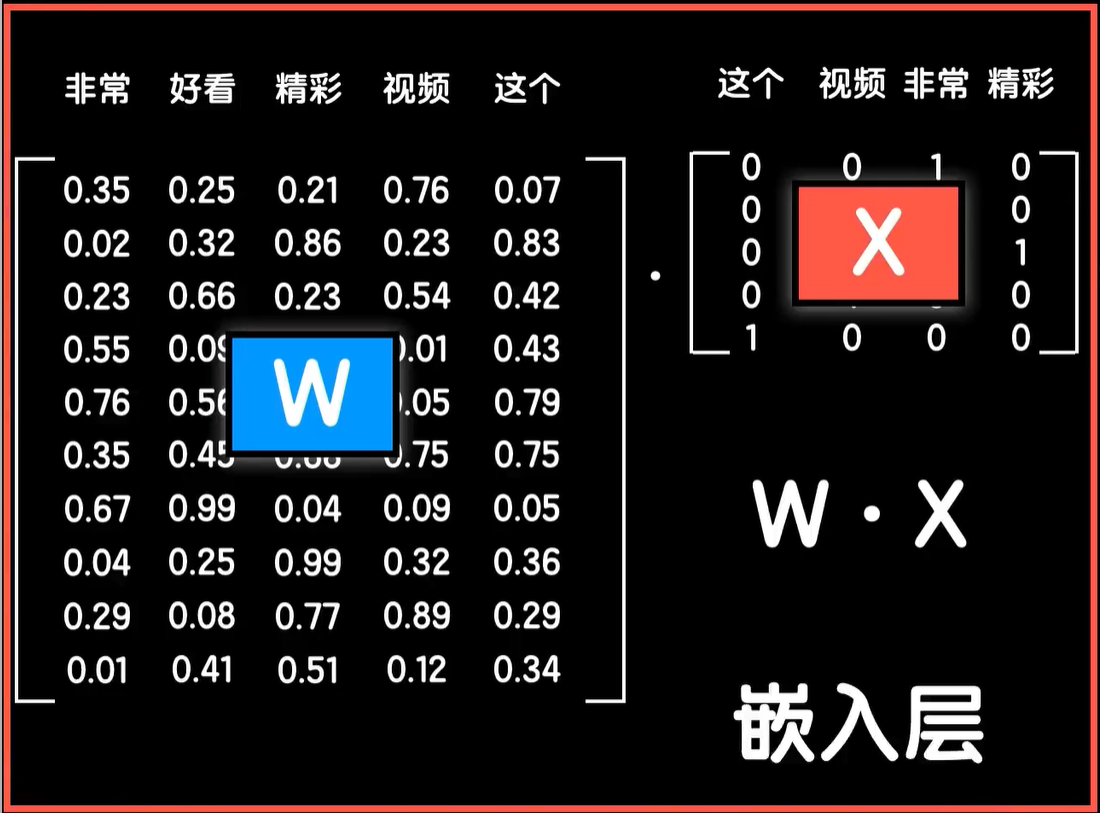
如果“这个视频非常好看”这句话和“这个视频非常精彩”这句话属于同一类,那么在训练的激励下,好看和精彩这两个词的词向量数据最后必然会很接近。
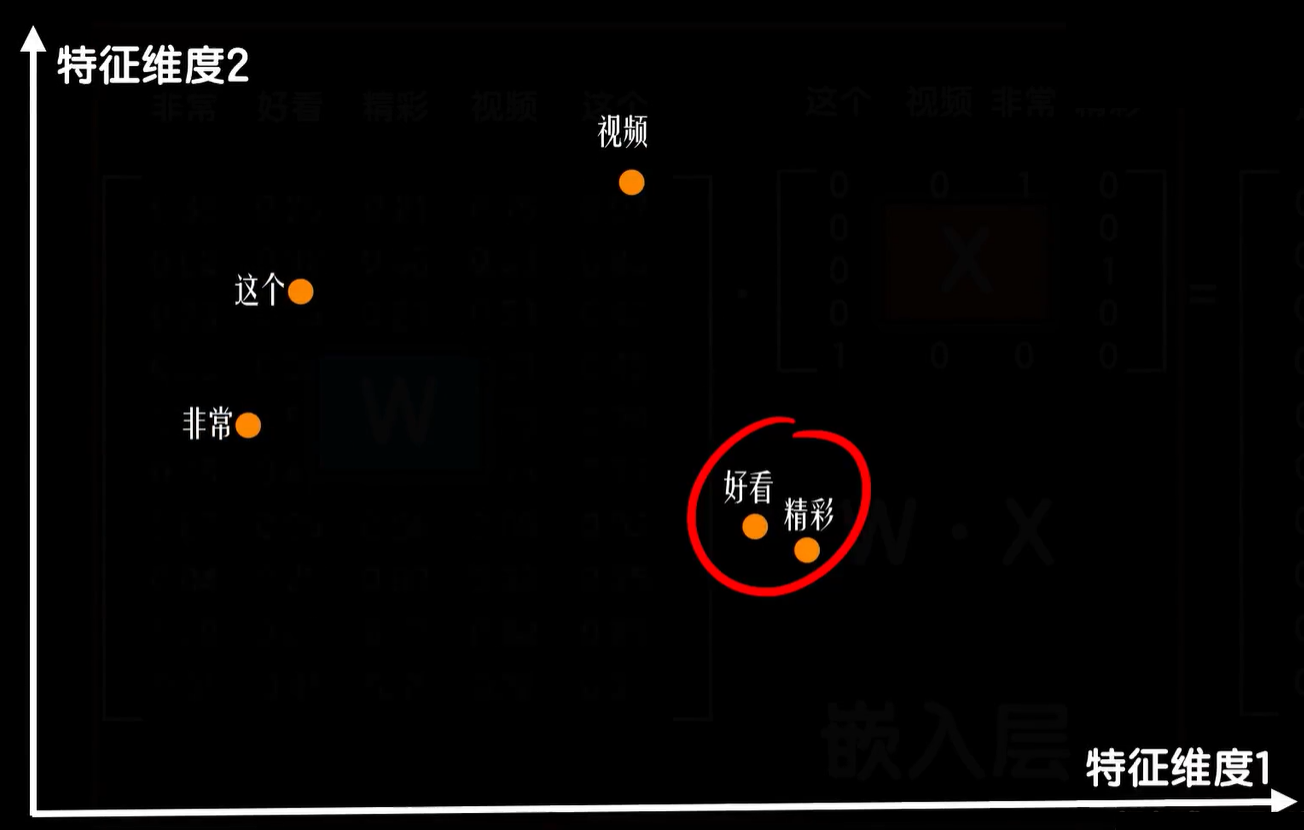
当然额外说一点这10个维度中每个维度的含义,虽然我们前面说可能是是不是名词,是不是动物,是不是植物,有没有皮毛等等,但只是举个例子,实际上每个维度值是什么?其实通过后续的训练已经很抽象了,我们可能无法明确每个特征到底是什么含义,就像卷积神经网络中最后训练出的卷积核在提取什么已经很抽象了,可能是边沿,可能是轮廓,也可能不是,但我们知道他肯定捕捉到了一些特征。

在训练的时候顺便训练词嵌入矩阵是一种方法,但词向量矩阵要训练的恰当合理,显而易见的是需要海量的文本和词汇,但如果我们去构建一个具体应用时,比如我们开头说判断一个评论区评论的感情,我们可能只能得到并不多的文本,几百条或者几千条的样子,但转念一想语言这东西是有共性的,比如狗这个词是名词,是动物有尾巴有皮毛,这件事情正常来说在哪里都是这样。
所以更加常见的做法是去使用别人在海量数据上训练好的词向量数据应用到我们自己的过程中,而不是自己在这些少量的数据集上训练词向量,常见的词向量训练算法,有word2vec和glove,我们只需要知道它们都是在自然语言处理领域流行的词向量训练算法就好,所以我们可以去网上下载他人利用这些算法训练好的数据,然后把我们自己的词嵌入矩阵给替换掉,同时在训练的时候冻结嵌入层(在训练时候冻结这一层的嵌入矩阵参数),让它在我们的训练中不再更新,这是一种迁移学习的手段,这种站在巨人肩膀上的想法在软件过程中十分常用。
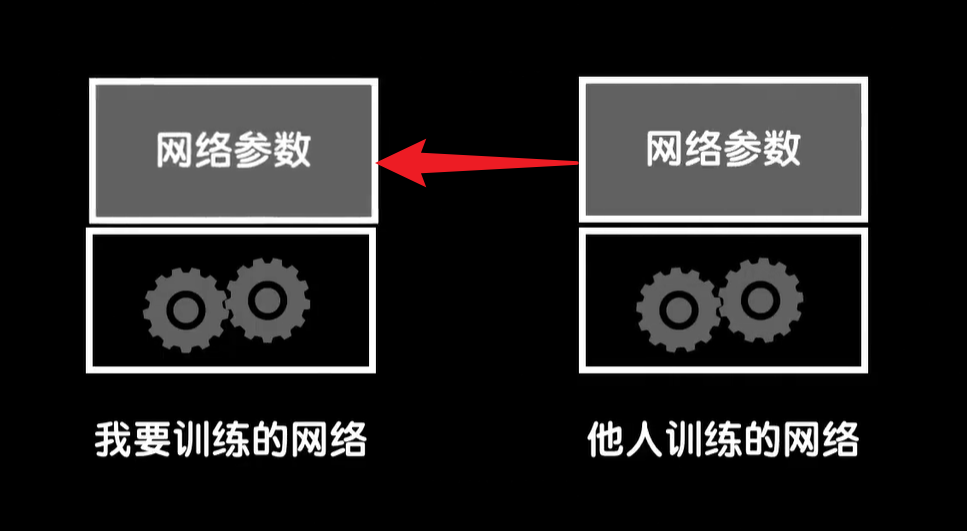
回过头来想想我们在做图像识别的时候,因为对图像特征提取的方式也具备可迁移性,所以我们可以把别人训练好的参数直接迁移到自己的工程上,然后简单的处理一些细节问题,这要比我们在只有少量数据集的情况下,从零开始训练要高效许多。
以上就是我们在神经网络中进行自然语言处理时,对数据进行的预处理和组织的一般方法,把一句话转化成词向量矩阵之后可以把它平铺开,然后送入一个全连接层中进行训练预测这句话是正面还是反面。
但正如我们开始说的那样,这种语言序列类型的数据在时间上有关联性,比如通过训练我们知道这个视频非常好看,是一个正向的评论,但如果在测试集上遇到这样的一个评论,视频非常不好看,因为有非常好看这样正面的词汇,所以神经网络很容易就把它判定为一个正面的评论,但因为有不这个词的修饰,所以意思就发生了完全的反转。

我们不能忽视语言数据在时间上的关联性,所以我们的神经网络必须要有处理这种关联性的能力,下节我们会用卷积操作把一个神经网络改造成为适合图像数据的卷积神经网络一样,我们把神经网络改造成为适合序列数据的结构。
编程实验
文本情感分类任务
csv文件中的内容是在网络上找到的一个数据集,是别人在各大网购平台上爬取的网购评论数据,一共有6万多条评论,每条数据有三个部分,第一个是它的商品分类,我们这次的任务用不上。第二个是他的情感标签数据,一代表正面评价,0是负面评价,第三个就是他的评论文本。我们就让神经网络识别出哪些评论是正面的,哪些是负面的。
# 数据集导入工具代码
import os
import keras
import numpy as np
import keras.preprocessing.text as text
import re
import jieba
import random
def load_data():
xs = []
ys = []
with open(os.path.dirname(os.path.abspath(__file__))+'/online_shopping_10_cats.csv','r',encoding='utf-8') as f:
line=f.readline()#escape first line"label review"
while line:
line=f.readline()
if not line:
break
contents = line.split(',')
# if contents[0]=="书籍":
# continue
label = int(contents[1])
review = contents[2]
if len(review)>20:
continue
xs.append(review)
ys.append(label)
xs = np.array(xs)
ys = np.array(ys)
#打乱数据集
indies = [i for i in range(len(xs))]
random.seed(666)
random.shuffle(indies)
xs = xs[indies]
ys = ys[indies]
m = len(xs)
cutpoint = int(m*4/5)
x_train = xs[:cutpoint]
y_train = ys[:cutpoint]
x_test = xs[cutpoint:]
y_test = ys[cutpoint:]
print('总样本数量:%d' % (len(xs)))
print('训练集数量:%d' % (len(x_train)))
print('测试集数量:%d' % (len(x_test)))
return x_train,y_train,x_test,y_test
def createWordIndex(x_train,x_test):
x_all = np.concatenate((x_train,x_test),axis=0)
#建立词索引
tokenizer = text.Tokenizer()
#create word index
word_dic = {}
voca = []
for sentence in x_all:
# 去掉标点
sentence = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", sentence)
# 结巴分词
cut = jieba.cut(sentence)
#cut_list = [ i for i in cut ]
for word in cut:
if not (word in word_dic):
word_dic[word]=0
else:
word_dic[word] +=1
voca.append(word)
word_dic = sorted(word_dic.items(), key = lambda kv:kv[1],reverse=True)
voca = [v[0] for v in word_dic]
tokenizer.fit_on_texts(voca)
print("voca:"+str(len(voca)))
return len(voca),tokenizer.word_index
def word2Index(words,word_index):
vecs = []
for sentence in words:
# 去掉标点
sentence = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", sentence)
# 结巴分词
cut = jieba.cut(sentence)
#cut_list = [ i for i in cut ]
index=[]
for word in cut:
if word in word_index:
index.append(float(word_index[word]))
# if len(index)>25:
# index = index[0:25]
vecs.append(np.array(index))
return np.array(vecs)
# comments_recognizer.py
import shopping_data
x_train, y_train, x_test, y_test = shopping_data.load_data()
print('x_train.shape', x_train.shape)
print('y_train.shape', y_train.shape)
print('x_test.shape', x_test.shape)
print('y_test.shape', y_test.shape)
print(x_train[0])
print(y_train[0])

你看序列集一共有13,276个,测试集有3319个,不是说一共有6万多个数据吗?那是因为我在shopping_data中做数据读取的时候,把特别长的评论给过滤掉了,这样对我们实验的模型要友好一点,再者数据量少一点,训练也能快一点,然后训练集的第一个数据是一个评论文本,标签数据是一确实这句话是一个正面的评论。
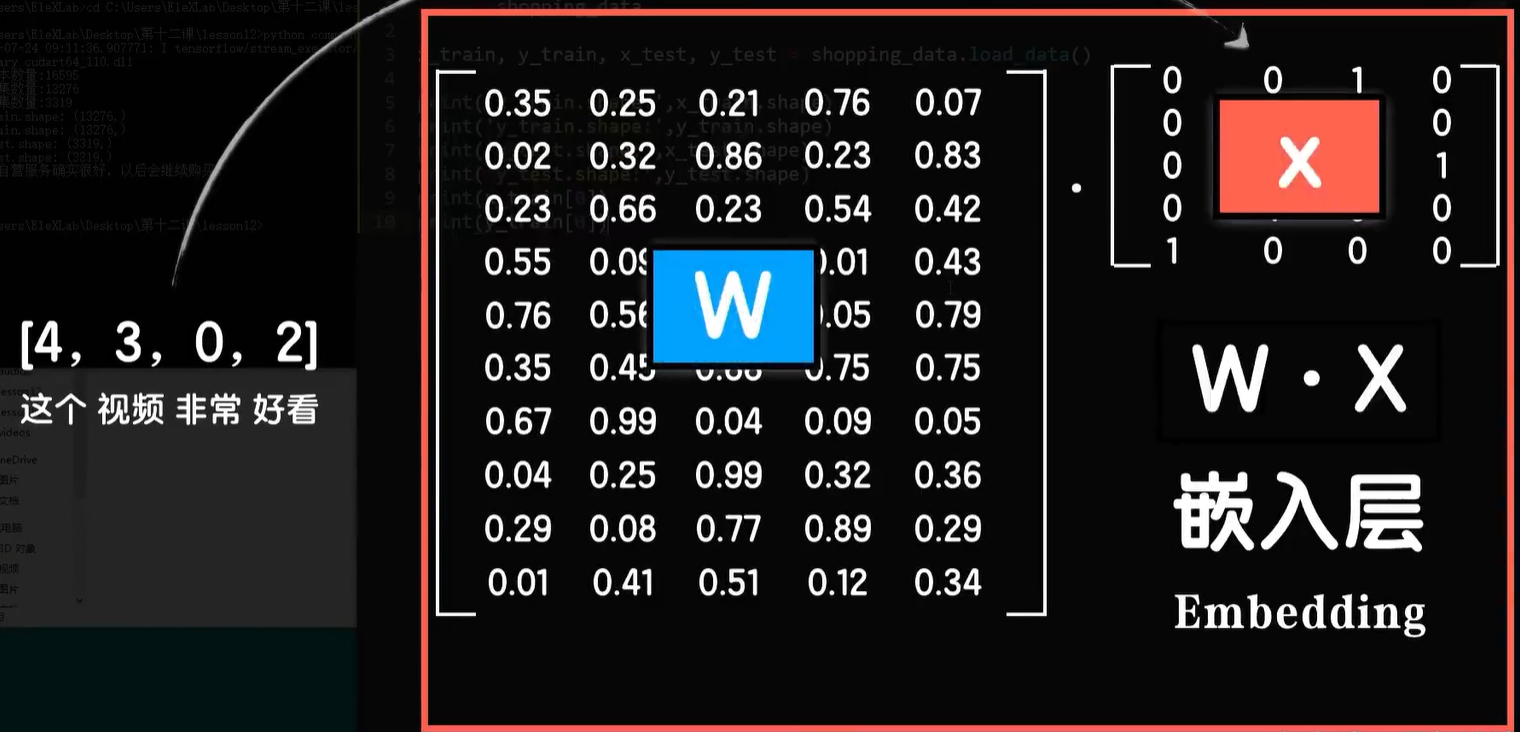
按照我们课上说的,我们需要统计一下全体文本中的词汇来构建一个词嵌入矩阵,然后给每个词做one-hot的编码,这样让词嵌入矩阵点成一句话的one-hot的编码矩阵,就能把这句话转化成一个词向量矩阵,不过这个过程其实并不需要我们手动操作,keras有个叫做Embedding层的专门来做这件事情。
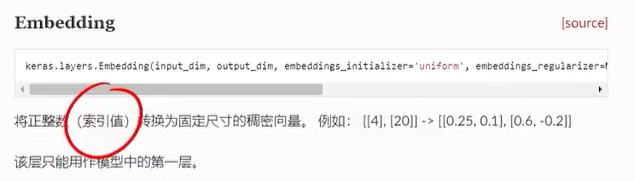
首先它把所有的词都做了onehot的编码,然后embedding内置了一个权重矩阵,也就是我们说的词嵌入矩阵,然后他再让嵌入矩阵点乘一句话的one-hot的矩阵,就得到这句话的词向量矩阵,比如这里的索引值4和20,如果是一个句子中两个词的索引值,最后就转化成为了两个词向量。
所以第一步把数据集中所有的文本转化为词典的索引值,这件事情需要我们自己来做,我们需要一个词典,不过不是真的去找一本词典,词典的构造过程一般是这样,我们用程序去遍历语料中的句子,如果是中文就进行分词,在这个过程中统计全体语料上所有的词语比如是5000个,那么就可以把这5000个词放在Python的一个数组或者字典的结构中,你可以通过读音对它们进行排序,当然你可以不排序就使用随机的顺序,反正不论怎样,每个词就会在数组或者字典里有一个位置的索引。
利用shopping_data中的createWordIndex函数进行构造词典
vocalen, word_index = shopping_data.createWordIndex(x_train, x_test)
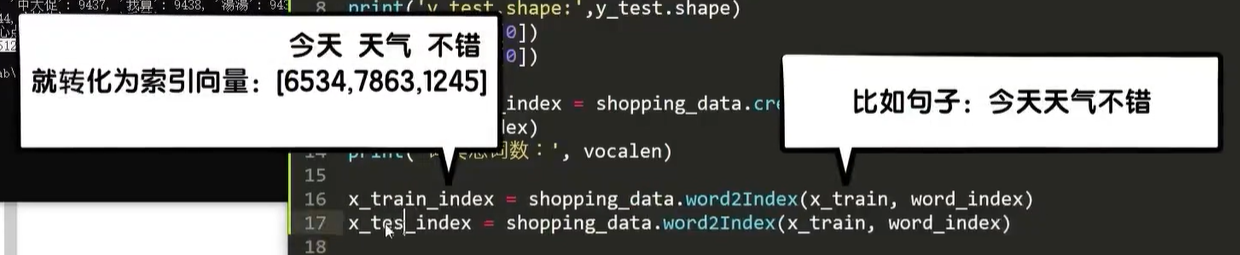
shopping_data中的word2Index寻找训练集和测试集中的语句中的词语,与字典对应,并将每一句话转化为索引向量
x_test_index = shopping_data.word2Index(x_test, word_index)
接下来还有1个问题需要处理一下,因为我们的评论数据每句话的长短它都不一样,有的句子是5个词,有的句子是6个词或者7个词8个词等等,这样最后得到的每句话的索引向量的长短就不一样,我们在全部训练集上就无法形成一个整齐的张量,所以我们需要让这些句子做一个对齐的操作。

keras的preprocessing中有一个sequence,其中的方法pad_sequencs可以进行按照最大长度的数据对齐,这样的长度不足25的句子就会被零补齐为25,而对于长度超过25的句子就会被截断为25。把索引表示的训练集传入这个函数并且指定最大长度25,这样我们就完成了文本数据的预处理。
# 数据对齐
maxlen = 25
x_train_index = sequence.pad_sequences(x_test_index, maxlen)
x_test_index = sequence.pad_sequences(x_test_index, maxlen)
下面是Embedding层,现在送入的数据是词索引,Embedding层就会自动把他们转化为词向量,我们说明一下参数:
- input_dim:输入维度,也就是我们词典中所有词汇的数量
- output_dim:输出维度,是我们希望的每个向量的特征维度
- Embedding层知道上述两个参数之后才能知道要构造一个什么样子的嵌入矩阵
- input_length:表示一个句子序列的长度,我们知道我们把每个句子都做了按照最大值25对齐的处理,所以每句话的长度都是25。
- trainable:这个参数不光Embedding层有,其它层也可以有。它的意思就是是否让这一层在训练的时候更新参数,那就像我们课上说的那样,Embedding中的参数矩阵就是全体词汇的词向量集合,而当我们给它配置为False不训练的时候,这些词向量不会随着训练而更新,而当我们把它配置为True的时候,词嵌入矩阵就会随着训练一起更新,按照我们刚才说的,显然随着训练一起更新的词嵌入矩阵的效果要好一些,我们这里先配置为不训练,一会我们再打开做一个对比。
model.add(Embedding(trainable=False, input_dim=vocalen, output_dim=300, input_length=maxlen))
# 代价函数是一个适用于二分类问题的交叉熵代价函数,优化器我们使用的是adam而不是sgd,因为序列问题一般都比较难以训练,所以我们使用这个更快的优化器
# adam是一种使用动量的自适应优化器,比普通的sgd要快,效果更好
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
完整代码:
import shopping_data
from keras.preprocessing import sequence
from keras.layers import Dense, Embedding, Flatten
from keras.models import Sequential
x_train, y_train, x_test, y_test = shopping_data.load_data()
print('x_train.shape', x_train.shape)
print('y_train.shape', y_train.shape)
print('x_test.shape', x_test.shape)
print('y_test.shape', y_test.shape)
print(x_train[0])
print(y_train[0])
# 传入训练集和测试集的文本
# vocalen返回这个词典的词汇数量
# word_index返回在全部语料中的索引词典
vocalen, word_index = shopping_data.createWordIndex(x_train, x_test)
print(vocalen)
print(word_index)
# 传入训练集x_train和词典word_index就得到了训练数据的索引表示
x_train_index = shopping_data.word2Index(x_train, word_index)
x_test_index = shopping_data.word2Index(x_test, word_index)
# 数据对齐
maxlen = 25
x_train_index = sequence.pad_sequences(x_train_index, maxlen)
x_test_index = sequence.pad_sequences(x_test_index, maxlen)
# 构造神经网络
model = Sequential()
model.add(Embedding(trainable=False, input_dim=vocalen, output_dim=300, input_length=maxlen))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(256, activation='relu'))
# 因为是二分类问题,所以输出层单个神经元
model.add(Dense(1, activation='sigmoid'))
# 代价函数是一个适用于二分类问题的交叉熵代价函数,优化器我们使用的是adam而不是sgd,因为序列问题一般都比较难以训练,所以我们使用这个更快的优化器
# adam是一种使用动量的自适应优化器,比普通的sgd要快,效果更好
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 开始训练
model.fit(x_train_index, y_train, epochs=200, batch_size=512)
# 测试
score, acc = model.evaluate(x_test_index, y_test)
print('Test Score:',score)
print('Test Accuracy', acc)
trainable=false时候的结果(准确率是78%):

trainable=true时候的结果(准确率是85%):

我们之前说,如果我们从网上下载别人在海量数据上使用一些词向量训练算法(word2vec或者glove)训练好的词向量,而不是用自己这些少量的数据顺便训练效果会更好,我们就在下篇讲说完循环神经网络结构之后,把它们在数据集上的表现做一个详细的对比。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









