







C++小白的逆袭之路——初阶(第八章:string类的相关接口)
前言
在今后的学习中,我们要经常借助一个网站cpluscplus来辅助学习。这是一个C/C++学习的资料网站,上面有各种库,函数的信息。有些时候难免会忘记某些函数的用法,这时我们就可以通过这个网站来进行查询,学习。
还有一点,我们要慢慢养成看文档的习惯(看英文文档),提升自己的自学能力。
1.为什么要学习string类?
C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP(面相对象编程)的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
在OJ中,有关字符串的题目基本以string类的形式出现,而且在常规工作中,为了简单、方便、快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数。
2.标准库中的string类
2.1string的文档
先带着大家从上到下过一遍文档,知道哪一部分都是些什么内容。链接在此:https://cplusplus.com/reference/string/string/?kw=string
1.类的声明:

string是一个管理字符顺序表类型的对象。它在命名空间std中。string本质上其实是一个模版,它的原生类型是basic_string<char>,被typedef成了string。
2.内部成员进行的一些typedef:
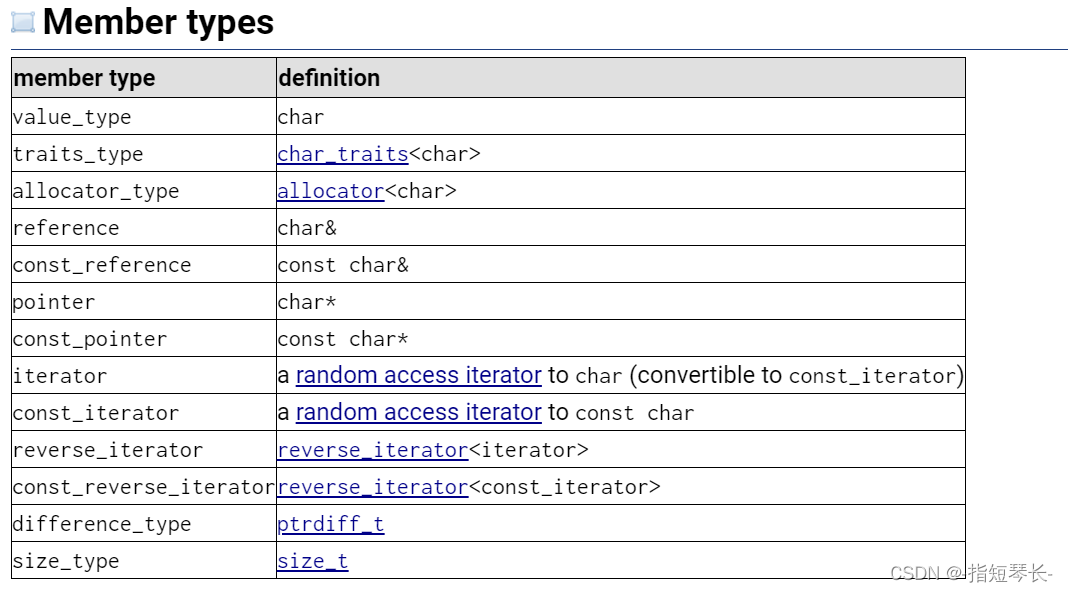
这一块后续再详细介绍。
3.成员函数:

点进去可以看到详细的成员函数介绍。
4.迭代器:

5.容量相关的接口:

6.元素访问操作:

7.一些修改操作:

这些接口会让大家很方便的去进行一些字符串的操作,一些以前在C语言中头疼的问题,现在都能解决了,爽的起飞。
8.还支持流插入和流提取的重载:

9.还有剩下的一些七七八八的东西,之后用到的时候都会详细介绍。
string总体而言设计了100多个函数,不得不说string设计的确实是有点过分复杂了。因为string出现的时候,STL规定还没有出现,相当于摸着石头过河,有些东西写着写着就写的有点多了,变得复杂了。
2.2string的常用接口说明——上
先带大家浅浅的感受一下,到后面的学习中我会带着大家具体实现。
2.2.1构造函数
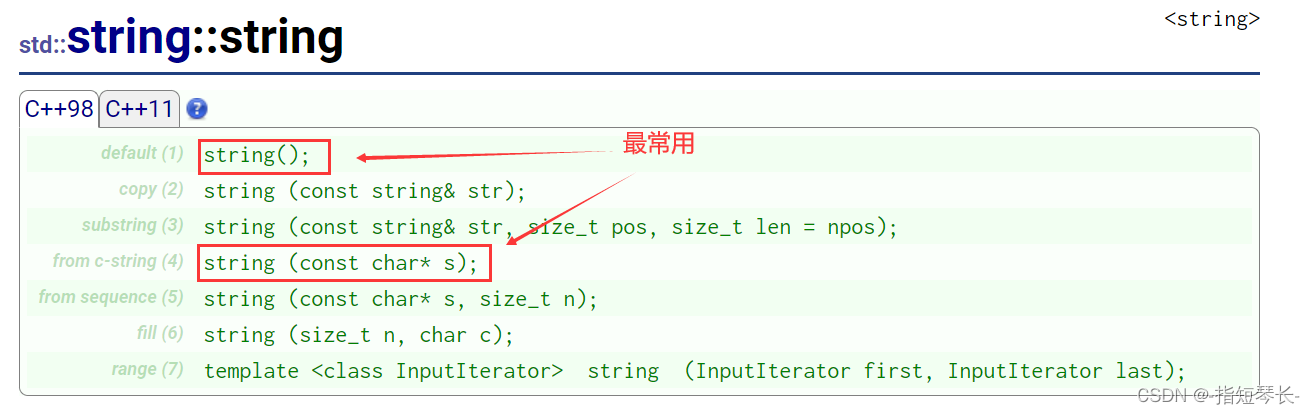
void test_string1()
{
string s1;
string s2("hello world"); // 用常量字符串初始化
string s3 = "hello world"; // 单参数的构造函数,支持隐式类型转换
}
其中,用常量字符串给string类初始化,最常用。
2.2.2流插入和流提取的重载
void test_string1()
{
// 流插入和流提取的重载
cin >> s1; // 输入
cout << s1 << endl; // 输出
}
2.2.3拼接字符串

void test_string2()
{
string s1 = "hello";
string s2 = " world";
string ret = s1 + s2; // 和string类型数据拼接
cout << ret << endl;
string ret2 = s1 + " world"; // 和常量字符串拼接
cout << ret2 << endl;
}
输出:
hello world
hello world
+这个重载,能少用就少用,因为它的开销是很大的,我们在这里先模拟实现一下:(而且这个+的重载,还被定义为了一个全局函数)
string operator+(const string& lhs, const string& rhs)
{
string ret = lhs;
ret += rhs; // 这个+=也是一个重载的函数
return ret; // 值返回
}
可以看到,由于+的逻辑是不能改变原有数据,所以就只能用传值返回,会先调用拷贝构造,让ret给到一个临时变量,再调用一次拷贝构造,将这个临时变量的值给出去,开销很大。
这里又可以体现编译器优化的好处。在编译器的优化下,连续多次的拷贝构造会被合并成一次,会直接调用一次拷贝构造,将ret的值给出去,也就是在函数还没有结束时,先将ret的值给出去。体现了编译器优化的价值。
我个人认为,其实将+重载成成员函数也并不是不可以,反而更加合适,因为符合程序设计一惯的逻辑。
2.2.4operator[]

遍历一个字符串:
void test_string3()
{
string s1 = "hello world";
// 读
for (size_t i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
cout << endl;
// 写
for (size_t i = 0; i < s1.size(); i++)
{
s1[i]++;
cout << s1[i] << " ";
}
}
输出:
h e l l o w o r l d
i f m m p ! x p s m e
这段代码中,我们还用到了一个函数:s1.size()。这个函数可以直接计算出字符串的大小(不含\0)。
2.2.5迭代器(begin()/end())
每个类有自己的迭代器类型,用的时候需要加上类域。也就是说,在string类中还有一个内部类,是迭代器类型。
使用迭代器也可以遍历字符串,我们先记住这个遍历的写法:
void test_string4()
{
string s = "hello world";
// 读
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 写
it = s.begin();
while (it != s.end())
{
*it = 'a';
++it;
}
cout << s << endl;
}
string::iterator是一个类型,it是用这个类型定义的变量(变量名取什么都可以)。迭代器的感觉跟指针类似,begin()指向字符串第一个字符,end()指向\0的位置。
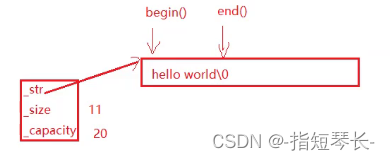
while( it != s.end())这段代码可以用小于吗?这里是可以的,但是不要这样用。
void test_string5()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
list<int>::iterator lit = lt.begin();
while (lit < lt.end()) // 报错
{
cout << *lit << " ";
++lit;
}
cout << endl;
}
使用list的迭代器时,用<就报错了。其实,迭代器的底层就是指针。在string中能用<,是因为存储string的是一块连续的空间。而list是一个双向链表,它的存储空间不连续,所以不能使用<。
迭代器,是一种通用的遍历手段,它在大多数数据结构中都可以使用,而且形式相同,!=才是通用写法,不要修改。
我们可以发现,迭代器屏蔽了底层的实现细节,大大简化了代码。以前程序员想遍历一个数据结构,必须要知道它的实现细节,现在一个迭代器就搞定了,难搞的活全交给了编译器。这也体现了C++的封装。
2.2.6反向迭代器(rbegin()/rend())
void test_string6()
{
string s = "hello world";
// 这里可以用auto,因为类型名太长了,这也是auto爽的一点
string::reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << " ";
++rit;
}
cout << endl;
}
输出:
d l r o w o l l e h
实现了反向遍历。
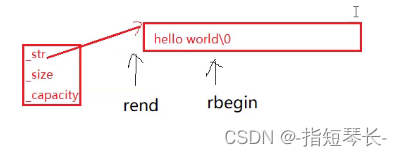
它的rbegin()指向\0的前一个字符,rend()指向第一个字符的前一个位置。
2.2.7还可以用范围for遍历
void test_string7()
{
string s = "hello world";
// 编译时编译器替换为迭代器
for (auto ch : s)
{
cout << ch << " ";
}
cout << endl;
}
范围for和模版类似,本来该你干的活,交给编译器去干了。范围for的底层就是迭代器。
2.2.8cbegin()和cend()
来看一个场景:
void func(const string& s)
{
string::iterator it = s.begin(); // 报错
while (it != s.end())
{
// *it = 'a' // 这句代码能跑吗
cout << *it << " ";
++it;
}
cout << endl;
}
这个string类型用const修饰了,后面那几段代码就编不过了,这是为什么?设想一下,如果string::iterator it = s.begin();这段代码能跑,那是不是意味着我们可以通过*it来改变s,这是一个明显的权限放大,显然不被允许。
为了应对这种情况,C++设计了cbegin()/crbegin()和cend()/crend()。这时string::iterator it = s.begin();这段代码就要变一变了,变成string::const_iterator it = s.cbegin();,迭代器的类型变成了const_iterator。
虽然说了那么多,但是其实,cbegin()一类的写法根本就没必要,C++还为begin()设计了重载:

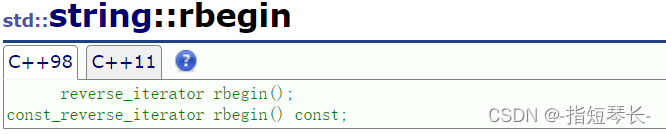
string::iterator it = s.begin();编不过的原因只是因为it的类型不对,将it的类型改成const_iterator就可以了。rbegin()也是同理。这里,又再一次体现了auto的价值,这么长的类型名,直接用一个auto就可以了。
2.2.9拷贝构造
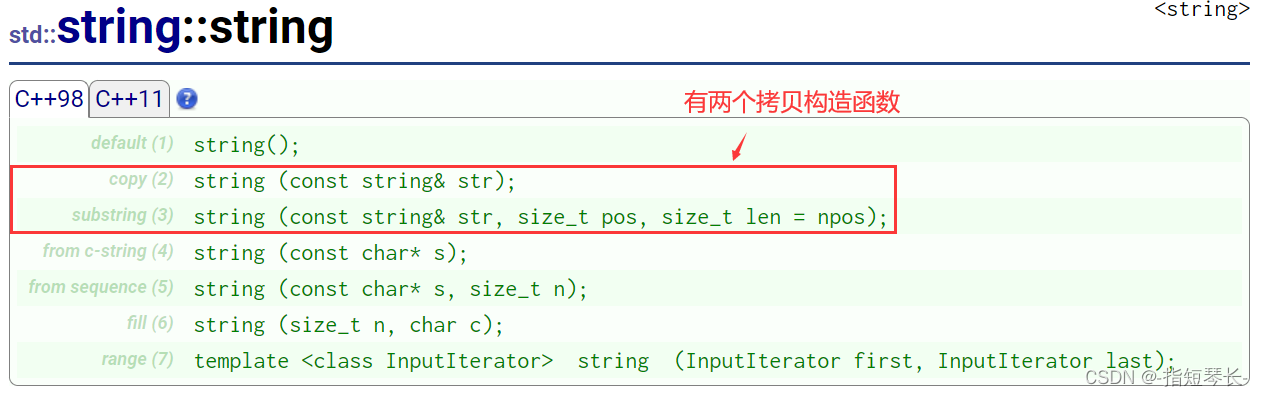
第一个我们都再清楚不过了,我们向下拉看看第二个的介绍:
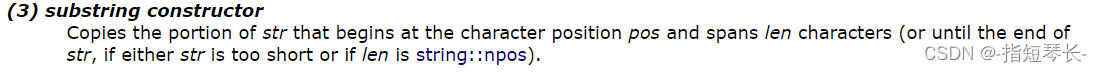
意思就是从pos位置开始,拷贝len长度的数据。如果str太短,或者len = npos,就直接拷贝到str的末尾。我们再看一下npos:

npos 的值是-1,但是我们注意看,npos的类型是size_t,是无符号整型的最大值。而-1是有符号整型,它的补码为32位全1,强转成无符号整型就是无符号整型中的最大值。这个最大值大概为42亿九千万,还没有哪个字符串能长到这种地步。
void test_string8()
{
string s1 = "hello worldxxxxxxxxxxxxxxxxxxxxxxxxyyyyyyyyyyyyyyyy";
string s2(s1); // 普通的构造函数
cout << s2 << endl;
string s3(s1, 6, 5); // 从6位置开始,拷贝5个长度的字符
cout << s3 << endl;
string s4(s1, 6, 3); // 从6位置开始,拷贝三个长度的字符
cout << s4 << endl;
string s5(s1, 6); // 从6位置开始,直接拷贝到字符串末尾
cout << s5 << endl;
// 想要直接拷贝到字符串末尾还可以这样写
// string s6(s1, s1.size() - 6);
}
输出结果:
hello worldxxxxxxxxxxxxxxxxxxxxxxxxyyyyyyyyyyyyyyyy
world
wor
worldxxxxxxxxxxxxxxxxxxxxxxxxyyyyyyyyyyyyyyyy
2.2.10再来看看其他的几个初始化函数
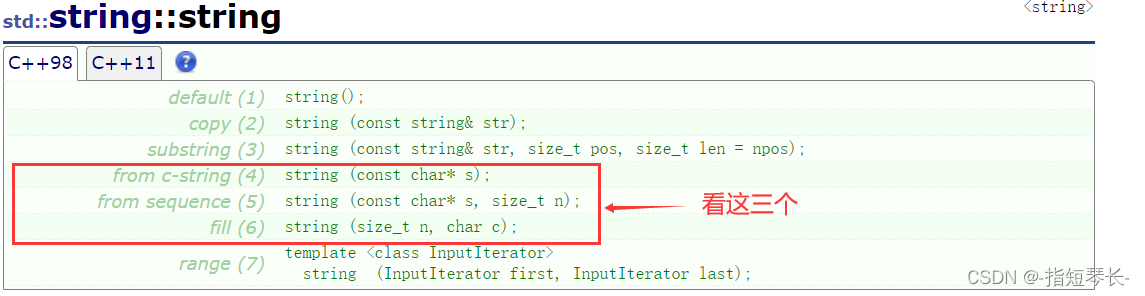
这里不再啰嗦的讲了,大家可以自行去看文档,看看他们都是些什么用途,直接上实例:
void test_string9()
{
string s1("hello world");
cout << s1 << endl;
string s2("hello world", 6); // 只给字符串常量的前6个字符
cout << s2 << endl;
string s3(10, 'a'); // 给10个'a'
cout << s3 << endl;
string s4(s1.begin(), s1.endl()); // 用迭代器区间初始化
cout << s4 << endl;
// 还可以去头去尾
string s5(++s1.begin(), --s1.end());
cout << s5 << endl;
}
输出:
hello world
hello
aaaaaaaaaa
hello world
ello worl
2.3string的常用接口说明——中
2.3.1赋值重载函数

string s1 = "hello world";
string s2;
s2 = s1;
s2 = "xxx";
s2 = 'y';
2.3.2size()和length()

string s = "hello world";
cout << s.size() << endl; // 打印11
cout << s.length() << endl; // 打印11
size()和length()的用法完全相同,且都不计算\0那么为什么要弄两个函数呢,这不是多次一举吗?因为string要比STL产生的早,计算一个字符串的大小,肯定是用长度来衡量比较好。后来STL标准产生后,就统一用size()来计算数据的多少了。
思考一个问题:问什么string的最后要放\0?因为C++要兼容C语言,C语言中的字符串是以\0结尾的,所以C++的字符串string也要以\0结尾。
2.3.3clear()和max_size()
clear()只会清空数据,不会释放空间。max_size()这个函数非常无用,早期是用来计算string这个类最大能开多少空间的,但是这个数据不准,而且如果你的内存本来就不够,这个max_size()再大也没有用。
string s1 = "hello world";
cout << s1 << endl;
s1.clear();
cout << s1.size() << endl;
cout << s1.capacity() << endl; // 显示当前容量
cout << s1.max_size() << endl;
输出
hello world
0
15
9223372036854775807
2.3.4c_str()

返回const char*类型的指针,指向第一个字符。
思考一个场景:如何用fopen()函数打开一个文件?
fopen()的第一个参数是字符类型的指针,我们肯定不能直接传string类型的参数,这时我们就需要去底层,找到string这个自定义类型中的一个成员变量,它存的就是指向第一个字符的指针。每个版本的C++库中,这个成员变量的命名都有所不同,而且成员变量是私有的,无法直接访问。为了解决这个问题,C++提供了一个函数c_str(),专门返回这个指针。
string filename;
cin >> filename;
FILE* fout = fopen(filename.c_str(), "r");
2.3.5reserve()
浅看一下string的扩容机制(测试环境VS2022):
string s;
size_t old = s.capacity();
cout << "初始" << s.capacity() << endl;
for (size_t i = 0; i < 100; i++)
{
s.push_back('x');
if (s.capacity() != old)
{
cout << "扩容" << s.capacity() << endl;
old = s.capacity();
}
}
VS2022的扩容机制:
初始15
扩容31
扩容47
扩容70
扩容105
第一次扩容两倍,后面都是接近1.5倍扩容。不同的编译器中,扩容的机制都不尽相同,没有必要深究。还有一个点要注意,初始时capacity()返回的值是15,但它其实开辟了16个字节的空间,因为还要存\0,容量的含义是可存储的有效数据的数量,\0不是有效数据。
使用函数reserve(),可以给string的容量一个初始值,比如我们知道这个字符串需要100个空间,我们就直接reserve(100)即可,这样就省去了扩容的开销。
string s;
s.reserve(100);
size_t old = s.capacity();
cout << "初始" << s.capacity() << endl;
for (size_t i = 0; i < 100; i++)
{
s.push_back('x');
if (s.capacity() != old)
{
cout << "扩容" << s.capacity() << endl;
old = s.capacity();
}
}
VS上的测试结果:
111
开辟了112个字节的空间,而在Linux环境下,它会恰好开辟101字节的空间。不同的编译器上,这个现象不尽相同,只需知道一点,编译器开辟空间,绝对够用,只会多,不会少。VS这里开辟的空间多一点,是因为它底层的对齐机制。
reserve()不会缩容,但是reserve()还可以用来扩容。它是一个异地扩容,传参直接传想扩到的容量大小即可。比如此时有一个字符串s的容量是5,不够,想扩容到10,直接s.reserve(10)即可。
2.3.6resize()
resize()的作用就是改变有效数据size(),它也可以插入数据,并且如果原有的容量不够,它还会执行扩容。
string s1("hello world");
cout << s1 << endl;
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << "---------------------" << endl;
// reserve(n),n大于size小于capacity的情况
s1.resize(s1.size() + 2, 'x'); // 直接在后面加上字符`x`
cout << s1 << endl;
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << "---------------------" << endl;
// reserve(n),n大于capacity的情况
s1.resize(20); // 容量不够,扩容
cout << s1 << endl; // 不给字符,默认全填`\0`
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << "---------------------" << endl;
// reserve(n),n小于size的情况
s1.reserve(5); // 充当删除作用,只保留前五个字符
cout << s1.size() << endl;
cout << s1.capacity() << endl;
cout << "---------------------" << endl;
输出:
hello world
11
15
---------------------
hello worldxx
13
15
---------------------
hello worldxx
20
31
---------------------
hello
5
31
在string中,resize()用的并不多,在vector中才会用的比较多。
2.3.7at()

string s = "hello world";
s[0]++;
s.at(1)++;
cout << s << endl;
输出:
ifllo world
at和[]的区别是,遇到越界,at会抛异常,而[]会直接终止掉程序。日常使用中,还是[]用的更多,因为它更符合使用习惯。
2.3.8插入
1.push_back和append(两个尾插)
1)push_back

它的作用就是在字符串的尾部插入单个字符(尾插)。
2)append
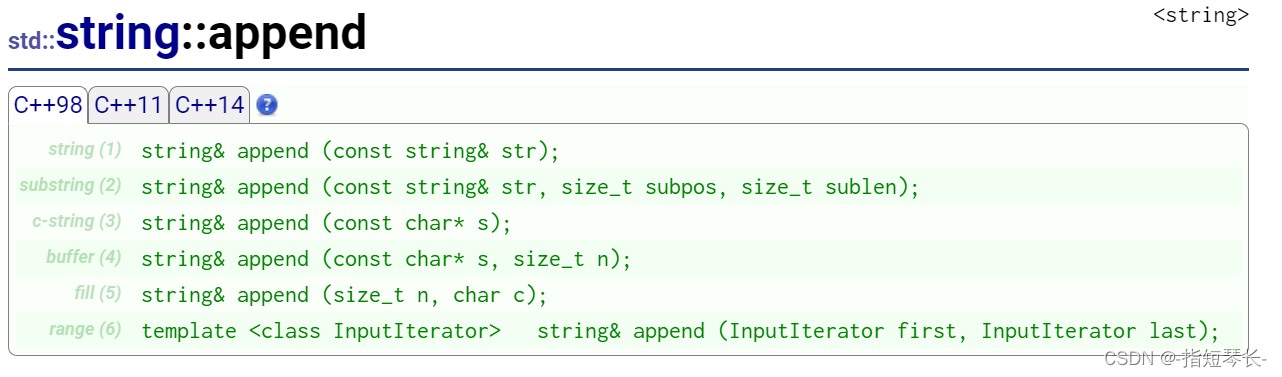
虽然C++在这里写了很多重载,但是我们最常用的还是第一个和第三个。第一个的作用就是向字符串尾部,插入一个string类型字符串;第二个的作用是向字符串尾部,插入一个常量字符串。
但是
push_back和append其实用的也不多,我们最喜欢用的还是+=。
+=囊括了最长用的三种对字符串的尾插,后期我们也会具体实现。

3)上代码:
string ss = "hello world";
string s = "hello world";
s.push_back('!');
cout << s << endl;
s.append("#####");
cout << s << endl;
s.append(ss);
cout << s << endl;
cout << "----------------------------------" << endl;
ss += '!';
ss += "xxxxxxxx";
ss += string("hhhh");
cout << ss << endl;
输出:
hello world!
hello world!#####
hello world!#####hello world
----------------------------------
hello world!xxxxxxxxhhhh
2.insert

这个函数的作用是在指定位置插入数据。
string str("hello world");
// 头插的两种写法
str.insert(0, 1, 'x'); // 在0位置插入1个字符,插入几个可以自己给,但不能不给
str.insert(str.begin(), 'x');
// str.insert(0, 'x'); // 错误写法
cout << str << endl;
// 在任意位置插入
str.insert(5, "xx");
cout << str << endl;
输出:
xxhello world
xxhelxxlo world
insert()涉及移动数据,开销大,能不用就不用。
2.3.9assign
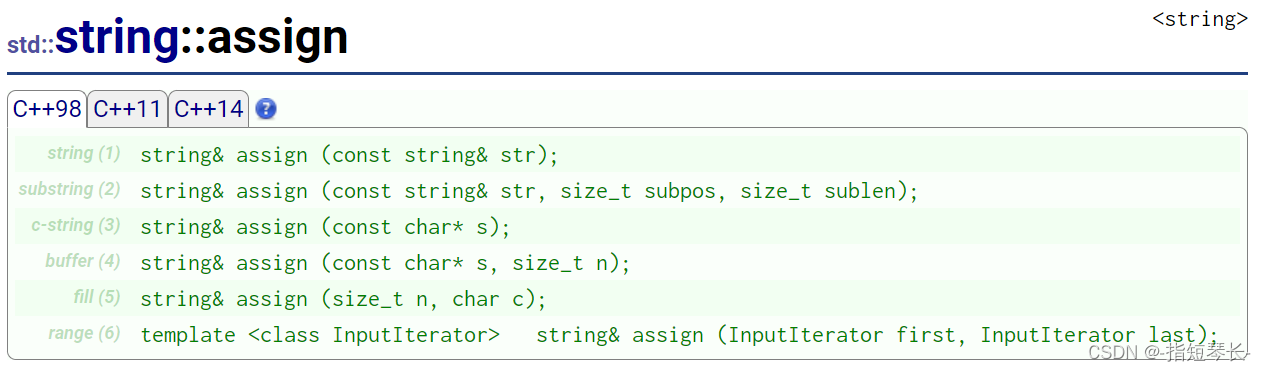
这个函数,其实就是一个赋值的作用,设计的非常多余。大家可以发现,这些成员函数设计的都非常有相似性。
string str("xxxxxxxxxx");
string base = "hello world";
str.assign(base);
cout << str << '\n';
str.assign(base, 5, 10); // 从第5个位置开始(不包括第五个),取十个字符
cout << str << '\n';
输出:
hello world
world
2.3.10erase

这个函数的作用是删除指定位置的数据。最常用的是第一个重载,它可以删除pos位置及pos以后(这里的pos是数组的下标),长度为len的数据。如果len太大(也就是字符串太短)或者len = npos,它就会删除pos位置后的所有数据。如果不给pos,pos的值默认为0。
string str("hello world");
str.erase(5, 1); // 删除第5位置后的一个数据
cout << str << endl;
str.erase(5); // 删除5位置后的所有数据
cout << str << endl;
输出:
helloworld
hello
erase()也涉及数据的挪动,能不用就不用。
2.3.11replace

以第一个重载为例,它的作用就是将pos位置及以后,长度为len的数据,替换为str。还是不建议使用replace(),相比insert()和erase()效率更低。
string str = "hello world";
// 将第5个位置后,长度为1的数据,替换为%%
str.replace(5, 1, "%%");
cout << str << endl;
输出:
hello%%world
2.4string的常见接口说明——下
2.4.1swap
如何实现字符串的交换呢?有同学可能想到了模版,但是模版在这里效率很低。string类设计了两个swap()函数,一个是成员函数,一个是全局函数。
1.模版swap()
template <class T>void swap(T& a, T& b)
{
T c(a); a = b; b = c;
}
一共执行了一次拷贝构造和两次赋值重载,开销很大。
2.成员函数swap()

它的内部实现就相对简单很多,只需要交换两个指针,和成员函数即可。
string类中,有一个成员变量就是一个字符类型的指针,指向开辟的字符串空间。交换两个string,只需要让这两个指针交换一下,然后让彼此的成员变量交换一下即可。
我们来验证一下:
string s1 = "hello";
string s2 = "world";
printf("s1:%p\n", s1.c_str());
printf("s2:%p\n", s2.c_str());
s1.swap(s2); // 交换
printf("s1:%p\n", s1.c_str());
printf("s2:%p\n", s2.c_str());
cout << s1 << endl;
cout << s2 << endl;
输出:
s1:0000001E2A0FF5C0
s2:0000001E2A0FF600
s1:0000001E2A0FF600
s2:0000001E2A0FF5C0
world
hello
发现指针互换了。
3.非成员函数swap()

C++还提供了一个非成员函数的swap(),它的效果和成员函数的效果是一样的,也是互换指针,效率很高。根据模版的特性,有现成的函数会直接去调现成的函数,不会再去走模版,所以,string类型的字符串永远无法调到模版swap()。
2.4.2pop_back

pop_back只起到一个尾删的作用。
string s1 = "hello";
s1.pop_back(); // 尾删,删除o
cout << s1 << endl;
输出:
hell
2.4.3substr

它的作用是取出pos位置及以后,长度为len的字符。和之前的函数类似,这里就不再过多讲解npos了,只需要记住,如果不给len,它会直接从pos位置取到字符串末尾。substr也是左闭右开。
string s = "hello world";
cout << s.substr(5) << endl;
输出:
world
2.4.4find系列
1.find

设想一个场景,如何取出test.cpp这个文件的后缀?
string s("test.cpp");
size_t i = s.find('.'); // 默认是从前向后查找
string s2 = s.substr(i);
cout << s2 << endl;
输出:
.cpp
2.rfind

如果文件名是test.cpp.tar.zip呢?.zip才是文件真正的后缀,这时就需要我们rfind出场,从后向前查找了。
string s("test.cpp.tar.zip");
size_t i = s.rfind('.');
string s2 = s.substr(i);
cout << s2 << endl;
输出:
.zip
做一个小实验:取出一个网址的协议、域名、资源名。以https://blog.csdn.net/weixin_73870552?spm=1000.2115.3001.5343为例,https是协议名,blog.csdn.net是域名,weixin_73870552?spm=1000.2115.3001.5343是资源名。
string s = "https://blog.csdn.net/weixin_73870552?spm=1000.2115.3001.5343";
string sub1, sub2, sub3;
size_t i1 = s.find(':');
if (i1 != string::npos) // 如果find函数找不到目标字符,就会返回npos
sub1 = s.substr(0, i1);
else
cout << "':'no found" << endl;
size_t i2 = s.find('/', i1 + 3); // 从i1 + 3的位置开始查找
if (i2 != string::npos)
sub2 = s.substr(i1 + 3, i2 - (i1 + 3)); // 左闭右开,右开减左闭就是数据个数
else
cout << "'/'no found" << endl;
sub3 = s.substr(i2 + 1);
cout << sub1 << endl;
cout << sub2 << endl;
cout << sub3 << endl;
输出:
https
blog.csdn.net
weixin_73870552?spm=1000.2115.3001.5343
3.find_first_of
大家先看一段代码,猜一下它有什么作用:
void test_string13()
{
string str = "Please, replace the vowels in this sentence by asterisks.";
size_t found = str.find_first_of("aeiou");
while (found != string::npos)
{
str[found] = '*';
found = str.find_first_of("aeiou", found + 1);
}
cout << str << endl;
}
输出:
Pl**s*, r*pl*c* th* v*w*ls *n th*s s*nt*nc* by *st*r*sks.
可以发现,字符串中,所有的aeiou,都被修改成了*。所以,find_first_of的作用就是从前往后找到所有在子字符串中出现的字符。
4.find_last_of
从后往前倒着找,找到所有在子字符串中出现的字符。
5.find_first_not_of和find_last_not_of
就是从前往后和从后往前找到所有不在子字符串中出现的字符。
void test_string13()
{
string str = "Please, replace the vowels in this sentence by asterisks.";
size_t found = str.find_first_not_of("aeiou");
while (found != string::npos)
{
str[found] = '*';
found = str.find_first_not_of("aeiou", found + 1);
}
cout << str << endl;
}
输出:
**ea*e***e**a*e***e**o*e***i****i***e**e**e****a**e*i****
这些东西看起来nb,但是实际没什么用。对于find_first_of系列的函数,子串越长,开销就越大,因为在主串中每遇到一个字符,就要遍历子串,时间复杂度就太坑了。如果想让find_first_of系列函数时间复杂度优化成O(n),可以使用哈希表。
2.4.5reverse
reverse的作用是逆置,它是一个通用的函数,很多容器都可以使用。
void test_string14()
{
string s = "hello world";
reverse(s.begin(), s.end()); // 传迭代器
cout << s << endl;
}
输出:
dlrow olleh

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











