






2023/5/16 最近在学习数据结构,感觉知识如同流水,学了就忘。所以开此博客,来记录学习笔记。如果有错误的地方也烦请大佬指正。(就从最近在学的一章开始,前面的慢慢补
基础概念的思维导图
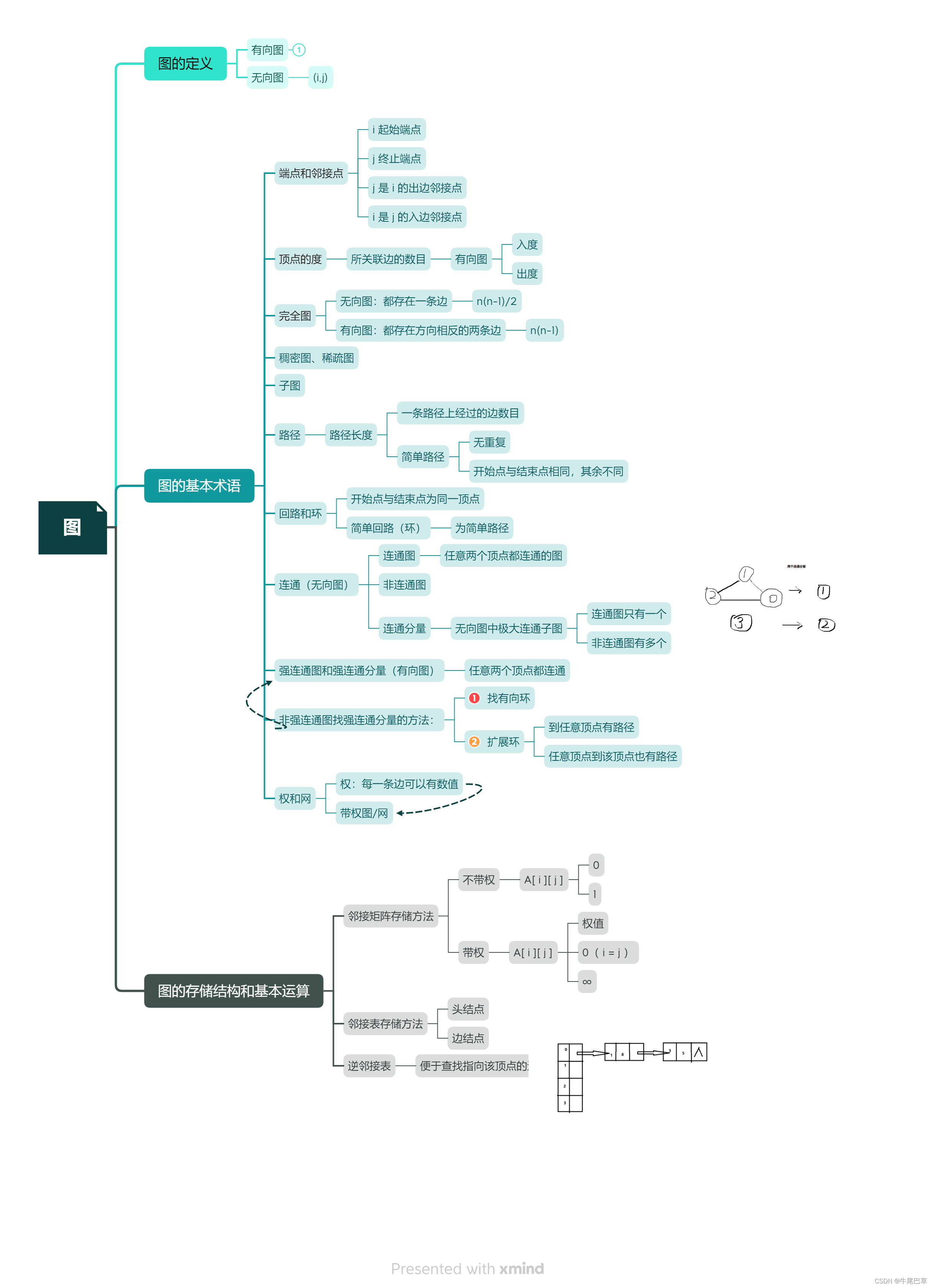
图的存储结构
下面用伪代码进行实现
一、邻接矩阵:
- 存储空间O(n2),适用于稠密图
- 无向图是对称矩阵,压缩存储
- 需要提取边权值通常采用邻接矩阵存储结构O(n2)
#define MAXV[最大顶点个数]
#define INF 32767
typedef struct
{
int no; //顶点的编号
InfoType info; //顶点其他信息
}VertexType; //顶点的类型
typedef struct
{
int edges[MAXV][MAXV]; //邻接矩阵数组
int n,e; //顶点个数,边数
VertexType vexsp[MAXV]; //顶点的信息
}MatGraph; //图邻接矩阵类型
Question1:INF 32767 为什么代表 ∞
个人理解:
整数的最大值:
16位:0111111111111111(15个1) 十六进制:0X3FFF 十进制:32767
32位:0(31个1) 十六进制:0X7F×7
网上查找:
16位 int 类型 取值范围 -32768~32767
32位 int 类型 取值范围 -2147483648~2147483647
二、邻接表:
头结点(data,firstarc)
边结点(adjvex,nextarc,weight)
- 无向图(n顶点,e边):n头结点,2e边结点
- 有向图:n头结点,e边结点
- 提取顶点的所有邻接点采用邻接表存储结构
typedef struct ANode
{
int adjvex; //边结点邻接点编号
struct ANode* nextarc; //指向下一边的指针
int weight; //权之类的
}ArcNode; //边结点
typedef struct Vnode
{
InfoType info; //顶点其他信息
AreNode *firstarc; //指向边结点
}VNode; //头结点
typedef struct
{
VNode adjlist[MAXV]; //邻接表的头结点数组
int n,e; //顶点数,边数
}AdjGraph; //图邻接表类型
图的基本运算设计(邻接表)
1.创建图
void CreateAdj(AdjGraph *&G,int A[MAXV][MAXV],int n,int e)思路:
- 为邻接表分配存储空间
- 头结点的firstarc置空
- 在邻接矩阵数组中遍历,找到有连通的路线。创立边结点(创立结点p):adjvex=j,weight为A[i][j],头插法插入第i个单链表中。
- n,e赋值
2.输出图
void DisAdj(AdjGragh *G)- 定义一个边结点指针p
- p指向头结点的指向第一个边结点,输出i
- p不为空->输出边结点内信息
- p移动
- 最后一个头结点循环结束,输出空的符号
3.销毁图
void DestroyAdj(AdjGraph *&G)- 定义,前驱指针pre,和指针p
- 一重循环
- pre指向头结点的指向第一个边结点->非空(二重循环)->让p指向后面一个边结点
- 销毁pre,pre移动到p,p移动到下一个
- 释放p
- 释放头结点
三、其他存储方式
1.十字链表(有向图)
头结点(data,firstin,firstout)
入度 出度
边结点(tailvex,headvex,hlink,tlink,weight)
起点 终点 相同起点下一个边结点 相同终点下一个边结点
2.邻接多重表(无向图)
头结点(data,firstarc)
边结点(mark,i,ilink,j,jlink,weight)
是否被搜索过 i,j 顶点 ilink(jlink) 下一依附于 i ( j )的结点
图的遍历
visited 数组 进行标记 0:未访问 1:已访问
深度优先遍历(DFS)(把一条路走到底)
递归思路:从首个开始,第一个,第一个开始,如果已经遍历过,就下一个。
邻接表O(n+e)
邻接矩阵O(n2)
//关键代码:v是起点,u是终点
p=G->adjlist[v].firstarc;
while(p!=NULL)
{
if(visited[p->adjvex]==0) //还没走过
{
DFS(G,p->adjvex);
}
p=p->nextarc;
}广度优先遍历(BFS)(所有岔道路口都检查,遍历一遍)
借用队列
队列不为空,查找队内元素邻接点,未被访问则标记加进队,继续找下一个邻接点。
邻接表O(n+e)
邻接矩阵O(n2)
非连通图遍历
需要在额外,查找是否所有元素被访问,没有就重复DFS/BFS算法。
关于图遍历算法的运用,暂时个人理解:
(1)DFS 用于找简单路径,不重复的路
(2)BFS 用于找最短路径
图的遍历的应用
一、DFS
(1)判断是否有简单路径: 遍历后,if(v==u) true
(2)输出一条简单路径:在(1)的基础上,数组path存储每条路线,if(v==u) 输出path。可以设置一个
(3)所有简单路径:在(2)的基础上,最后当p后面为NULL时候,visited[u]=0,使该顶点重新使用















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









