







人工神经网络特点:
1.非线性
2.非局限性(例子:联想记忆)
3.非常定性 (自适应,自学习能力,自组织)
4.非凸性(有多个极值-多个稳定的平衡态-系统演化的多样性)
激活(励)函数(非线性映射):
为了增加整个网络的表达能力
1.sigmod函数

sigmoid 函数的作用原理很简单:将所有数限制在 0 ~ 1 范围内
Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化;
用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适;
梯度平滑,避免「跳跃」的输出值;
函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率;
明确的预测,即非常接近 1 或 0。
Sigmoid 激活函数有哪些缺点?
倾向于梯度消失;
函数输出不是以 0 为中心的,这会降低权重更新的效率;
Sigmoid 函数执行指数运算,计算机运行得较慢。
2.Tanh / 双曲正切激活函数

在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
3. ReLU 激活函数

神经网络的结构:
激活函数选用sigmoid函数
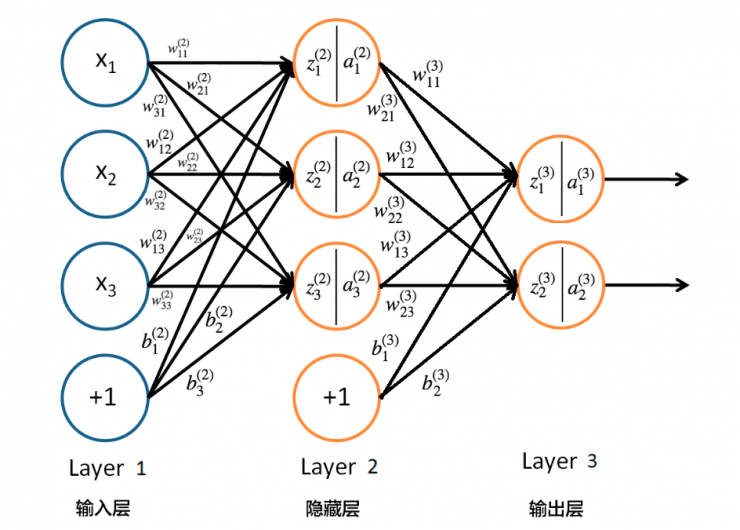
x表示输入,w表示权重,b表示偏置,z表示某一层的输入,经过激活函数作用后输出a,并作为下一层的输入。
权重表示信号的重要程度,偏质(bias)控制神经元被激活的难易程度
则:
其中,公式里面的变量 l 和 j 表示的是第 l 层的第 j 个神经元,ij 则表示从第 i 个神经元到第 j 个神经元之间的连线
正向传播:

h1的输入输出:
o1的输入输出:
......
反向传播:
反向传递主要用于通过调整神经网络中的参数来最小化损失函数。在训练神经网络时,通过将输入数据送入网络,得到输出数据;将输出数据与真实标签进行比较,计算损失函数。而反向传递算法则通过计算损失函数对每个参数的偏导数,来调整参数以最小化损失函数。
反向传递算法的基本思想是利用链式法则,逐层计算每个参数对于损失函数的偏导数。从输出层开始,将输出数据与真实标签进行比较,计算损失函数。然后通过链式法则计算损失函数对于每个参数的偏导数。
总误差,人为设定目标
。
示例:求w5对Etotal产生的影响


当前向传播所得出的输出值对应的均方差损失函数大于预期值时进行反向传播进行更新权重,
也即是梯度下降。
1.首先求偏导:(链式法则)
2.分布求出每一个偏导即可
其中
3.更新w5
4.不断更新达到一定次数或者损失趋于稳定。
隐含层:

代码:
import math
def s(x):
y = 1 / (1 + math.exp(-x))
return y
i1, i2 = 0.05, 0.1
target1, target2 = 0.01, 0.99
w1, w2, w3, w4, w5, w6, w7, w8 = 0.15, 0.20, 0.25, 0.30, 0.40, 0.45, 0.50, 0.55
out_h1 = s(i1 * w1 + i2 * w2)
out_h2 = s(i1 * w3 + i2 * w4)
out_o1 = s(out_h1 * w5 + out_h2 * w6)
out_o2 = s(out_h1 * w7 + out_h2 * w8)
E = 0.5 * ((out_o1 - target1) ** 2 + (out_o2 - target2) ** 2)
# 计算输出层的误差信号
delta_o1 = (out_o1 - target1) * out_o1 * (1 - out_o1)
delta_o2 = (out_o2 - target2) * out_o2 * (1 - out_o2)
# 计算隐藏层到输出层的权重的梯度
dw5 = delta_o1 * out_h1
dw6 = delta_o1 * out_h2
dw7 = delta_o2 * out_h1
dw8 = delta_o2 * out_h2
# 计算隐藏层的误差信号
delta_h1 = (delta_o1 * w5 + delta_o2 * w7) * out_h1 * (1 - out_h1)
delta_h2 = (delta_o1 * w6 + delta_o2 * w8) * out_h2 * (1 - out_h2)
# 计算输入层到隐藏层的权重的梯度
dw1 = delta_h1 * i1
dw2 = delta_h1 * i2
dw3 = delta_h2 * i1
dw4 = delta_h2 * i2
# 更新权重
learning_rate = 0.5
w1 -= learning_rate * dw1
w2 -= learning_rate * dw2
w3 -= learning_rate * dw3
w4 -= learning_rate * dw4
w5 -= learning_rate * dw5
w6 -= learning_rate * dw6
w7 -= learning_rate * dw7
w8 -= learning_rate * dw8为了使结果更加准确可以第一步对权重进行随机赋值














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









