







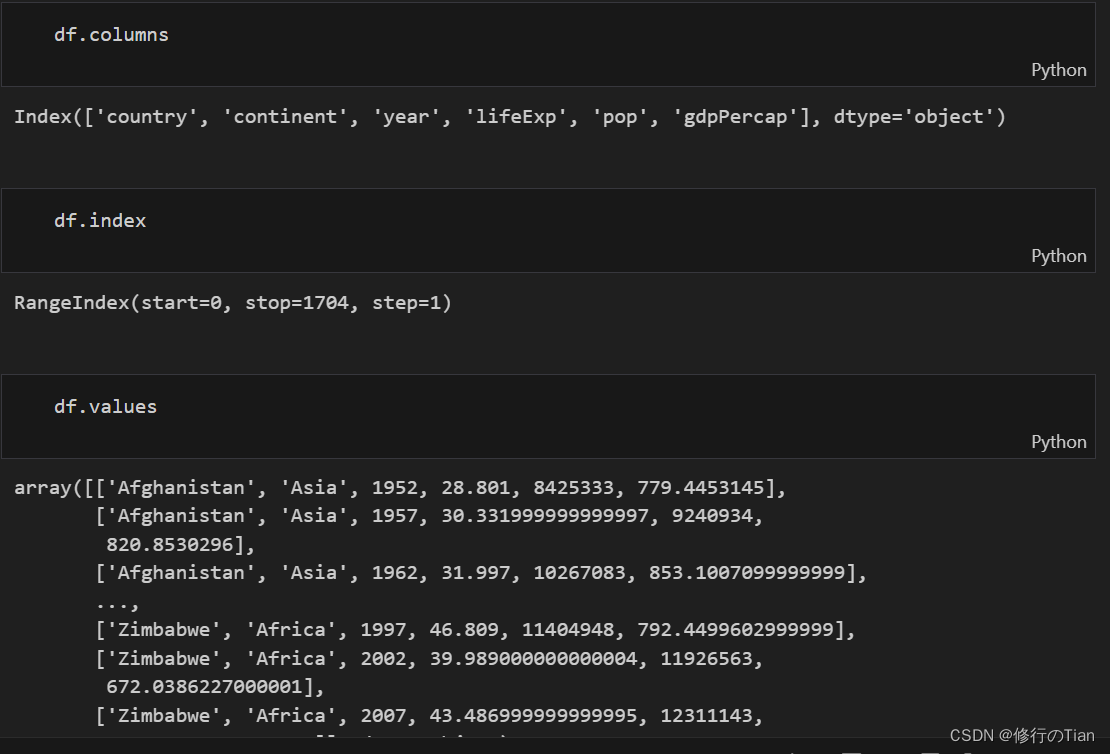
简介
pandas是一个用于数据分析的开源python库,通过引入Series和DataFrame实现了数据加载、操作、对齐、合并等功能。查看数据集最简单的方法是检查特定的行和列,并对他们取子集。
加载数据集
由于Pandas不是Python标准库的一部分,所以需要导入
import pandas as pd那么,现在可以开始调用read_csv函数来加载CSV数据文件了。
默认情况下,read_csv函数是读取‘,’分隔文件的。而我们采用的Gapminder数据使用制表符分隔,即将参数sep设置为'\t'
df=pd.read_csv('data/gapminder.tsv',sep='\t')
详细的内容的可以在pandas官网查看

接下来我们可以调用shape查看文件属性,该属性指明DataFrame行数和列数,注意,shape是DataFrame的属性,调用时后面不需要加()。
文件的基本属性
获取文件的子集
如果是想查看文件的多列,可以通过名称、位置索引、范围来指定
如果文件量过大的话,全部输出耗时耗力,一般采用head来查看前五行(默认,可以自己修改),tail来查看尾几行。
subset=df[['country','continent','year']]\
print(subset.head())
print(subset.head(n=10))
print(subset.tail())
print(subset.tail(n=10))示例如下
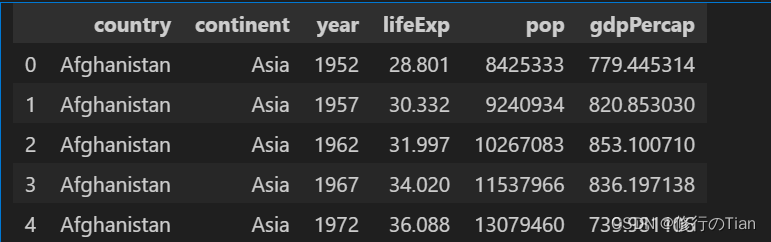
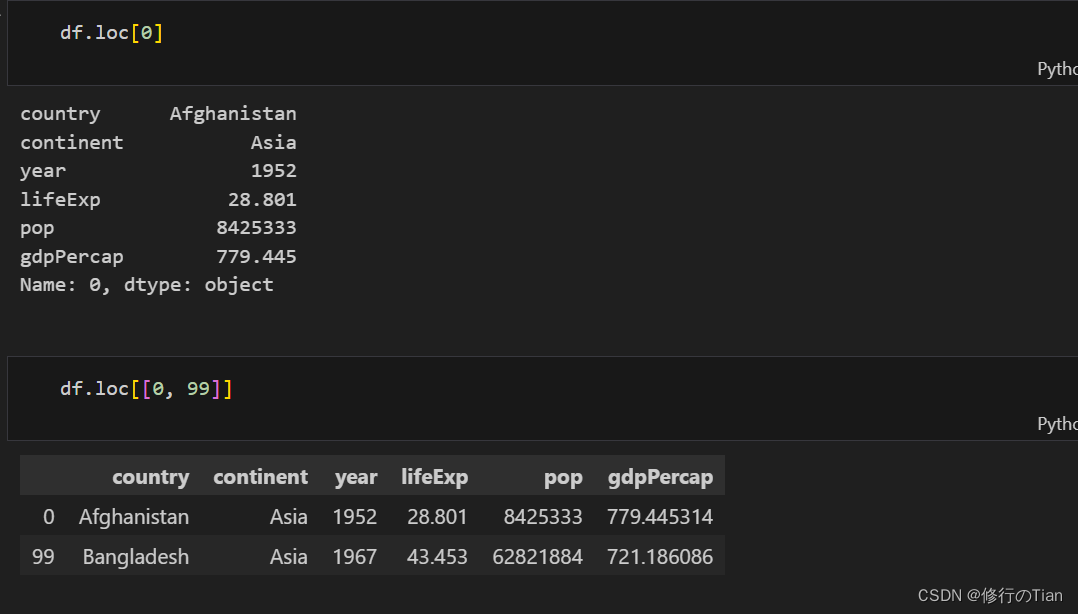
如果是想查看文件的行子集的话,可以通过行名或者行索引。
DataFrame的loc是基于索引标签获取行子集
需要注意的是,传入-1会报错
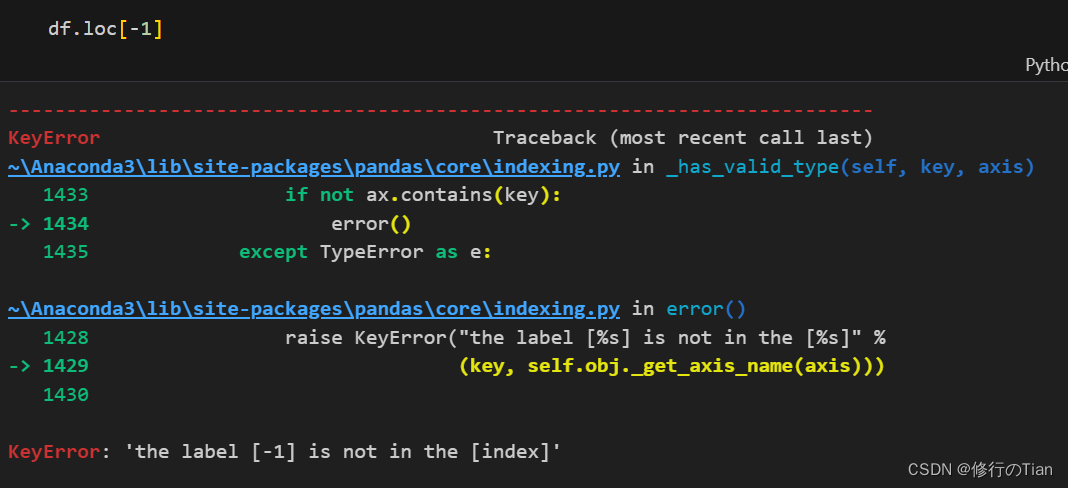 查看最后一行
查看最后一行
print(df.tail(n=1))
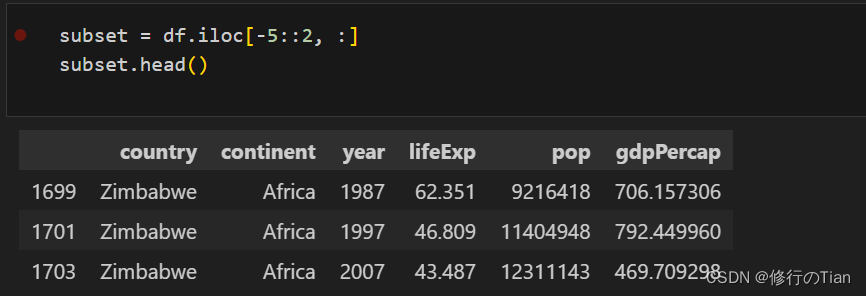
iloc是基于行索引号来获取行,且可以直接传入-1调用最后一行
混合使用
df.loc[[行],[列]]或者df.iloc[[行],[列]] 支持切片法!
使用loc和iloc来获取列子集 ,前者使用索引标签,后者使用整数
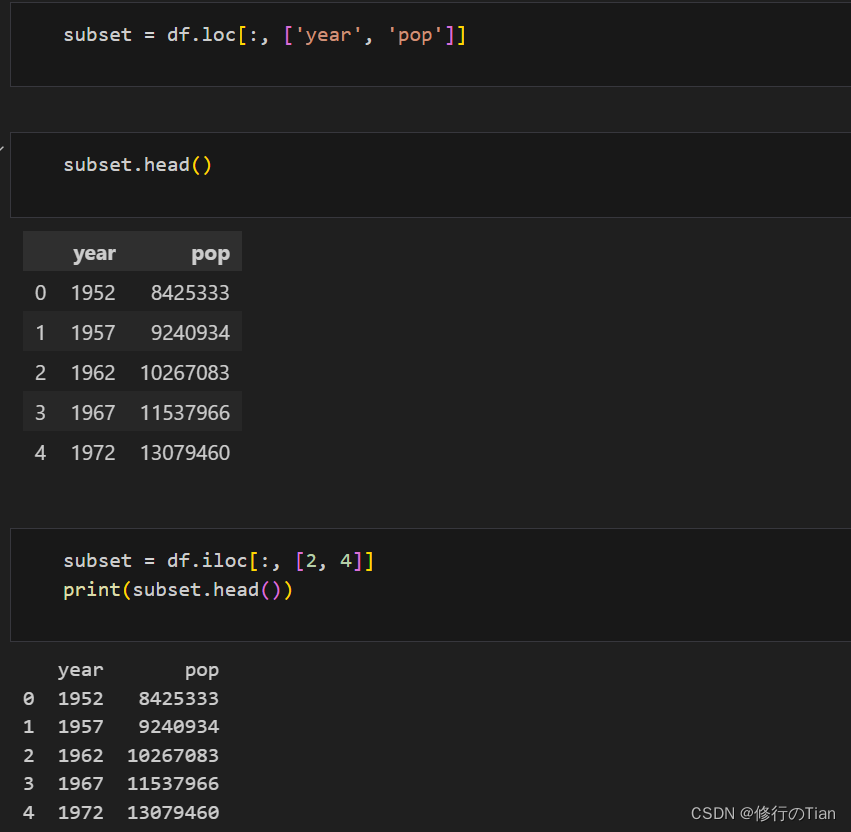 显然,iloc获取列子集也可以使用切片
显然,iloc获取列子集也可以使用切片
 但是从数据处理的角度来讲,还是使用loc、传入实际的列名更好,因为这样可以提高代码可读性,且避免列顺序发生改变
但是从数据处理的角度来讲,还是使用loc、传入实际的列名更好,因为这样可以提高代码可读性,且避免列顺序发生改变
分组计算
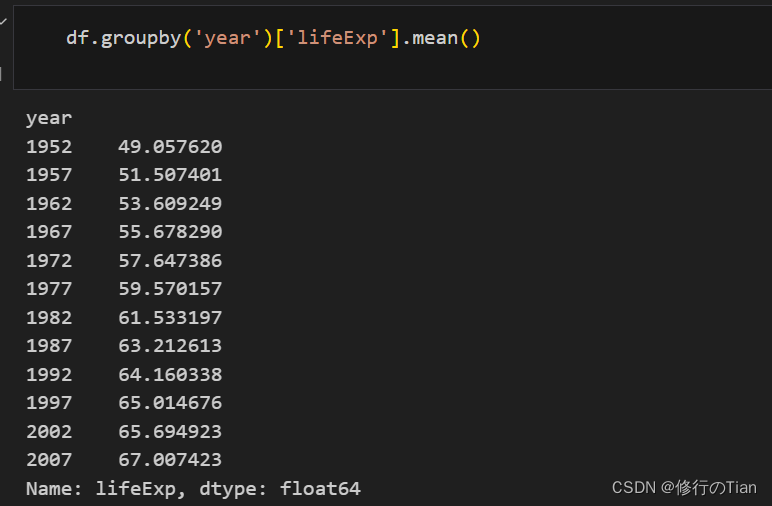
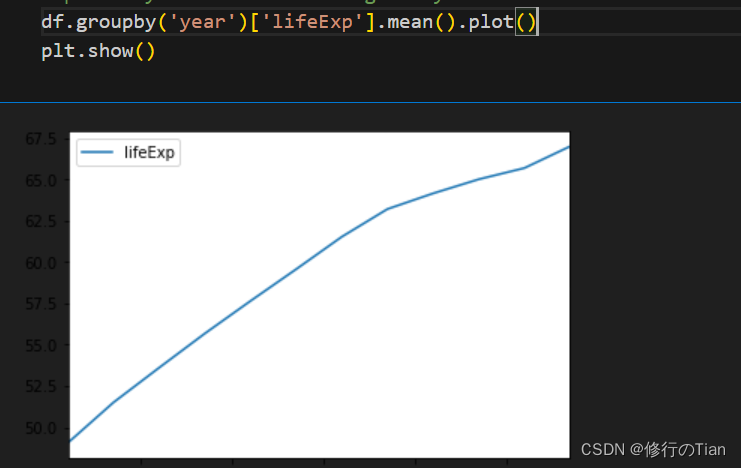
如问,数据中每年的平均预期寿命是多少?则需要使用DataFrame的groupby方法完成分组/聚合计算。下列代码表示的是,先对数据按照年份分割,然后获取其lifeExp列,计算平均值
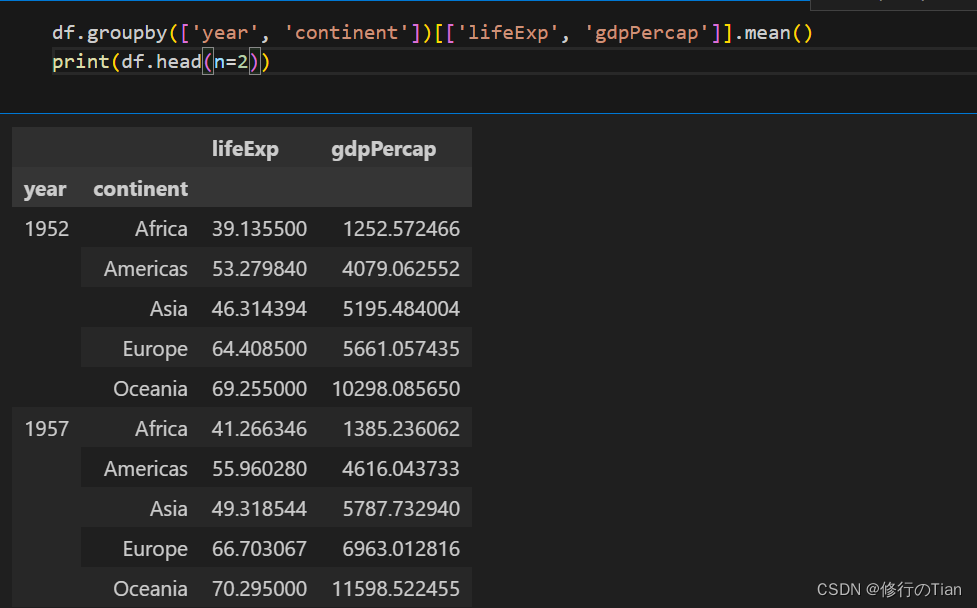
 多列计算(个人不推荐)
多列计算(个人不推荐)
 分组频率计数
分组频率计数
可以使用nunique方法或者value_counts()方法来获取唯一值和频率计数(很方便)
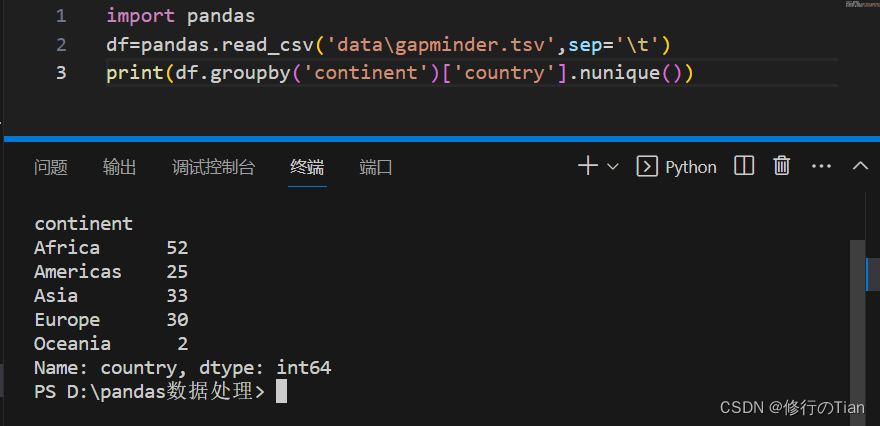 基本绘图
基本绘图















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









