







Large Language Models are Visual Reasoning Coordinators
摘要
视觉推理需要多模态感知和对世界的常识认知。最近,人们提出了多种视觉语言模型(VLM),在各个领域都具有出色的常识推理能力。然而,如何利用这些互补的 VLM 的集体力量却很少被探讨。像集成这样的现有方法仍然难以将这些模型与所需的高阶通信聚合起来。在这项工作中,我们提出了 Cola,这是一种协调多个 VLM 进行视觉推理的新颖范式。我们的主要见解是,大型语言模型 (LLM) 可以通过促进利用其独特且互补的功能的自然语言通信来有效地协调多个 VLM。大量实验表明,我们的指令调优变体 Cola-FT 在视觉问答 (VQA)、外部知识 VQA、视觉蕴涵和视觉空间推理任务上实现了最先进的性能。此外,我们还表明,我们的上下文学习变体 Cola-Zero 在zero-shot和few-shot设置中表现出有竞争力的性能,无需进行微调。通过系统的消融研究和可视化,我们验证了LLM cordinator确实理解了指令提示以及 VLM 的单独功能;然后它协调它们以实现令人印象深刻的视觉推理能力

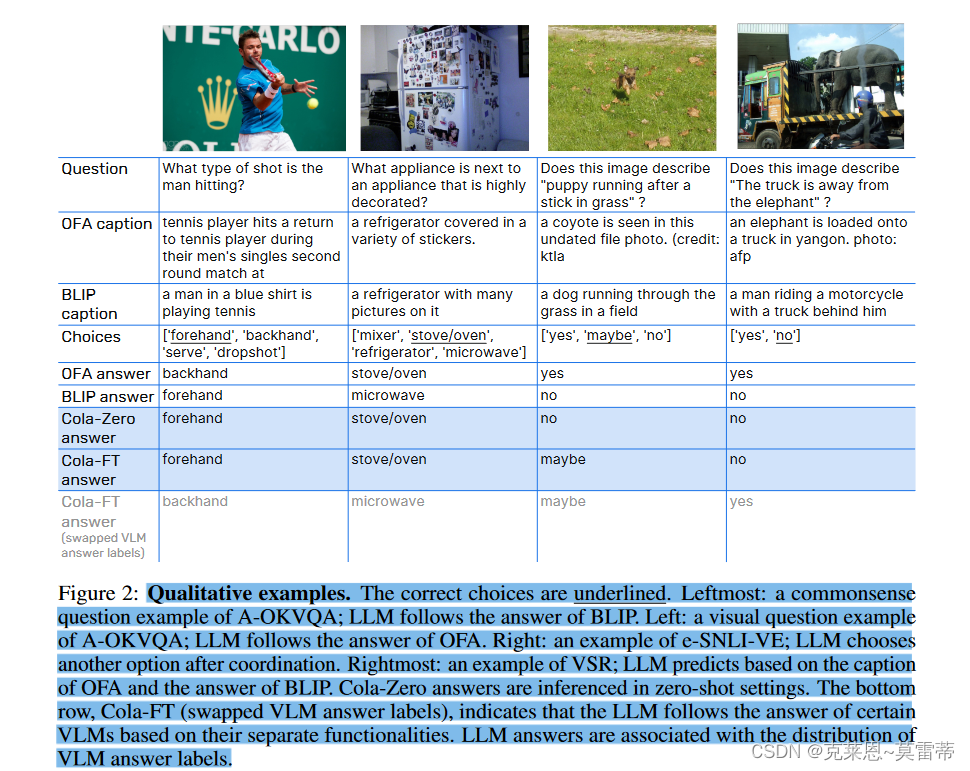
图片是cola的简介,非常直观明了
贡献
总之,我们的贡献如下:
- Cola:一种新颖的范式,利用语言模型作为多个视觉语言模型之间的协调器,以整合它们各自的优势进行视觉推理
- 最先进的性能:Cola 在一系列具有挑战性的多样化视觉推理任务和数据集上达到了顶峰。
- 系统分析:我们的实验揭示了Cola 如何理解指令提示,然后协调它们以捕获令人印象深刻的视觉推理能力
方法
VLM选择 1、OFA 2、BLIP
Cola 的概述如图 1c 所示。我们使用 OFA [104] 和 BLIP [52] 作为 VLM。 LLM 包括编码器-解码器(FLAN-T5 [16])和仅解码器(Vicuna1.5 [125]、Mistral [39])变压器。我们首先提示每个 VLM 独立输出标题和合理的答案。然后,我们将指令提示、带有选择的问题、标题和合理的答案连接起来,以融合法学硕士的所有上下文,以进行推理、协调和回答。
- caption 图像字幕提供了重要的视觉背景以供推理。我们首先使用第i个VLM分别描述每个图像以获得视觉描述
- answer VLM 对问题的回答提供了 VLM 的线索和模式,供 LM 考虑和协调。与caption类似,我们使用图像-问题对提示每个 VLM,以获得合理的答案 a i ( v , q ) a_i(v, q) ai(v,q)。我们使用 ofa-large 表示 OFA,使用 blip-vqa-base 表示 BLIP。遵循 OFA,我们的提示模板因任务类别而异。对于 VQA 任务,我们保留原始问题不变。对于视觉蕴涵和视觉空间推理任务,我们的提示模板是“图像是否描述了”<文本前提>”?
- template

cola-FT
指令调优

cola-zero
in-context learning
通过给出k个示例(prompt)

zero则是不给出示例,只是给一句话要求LLM这样做
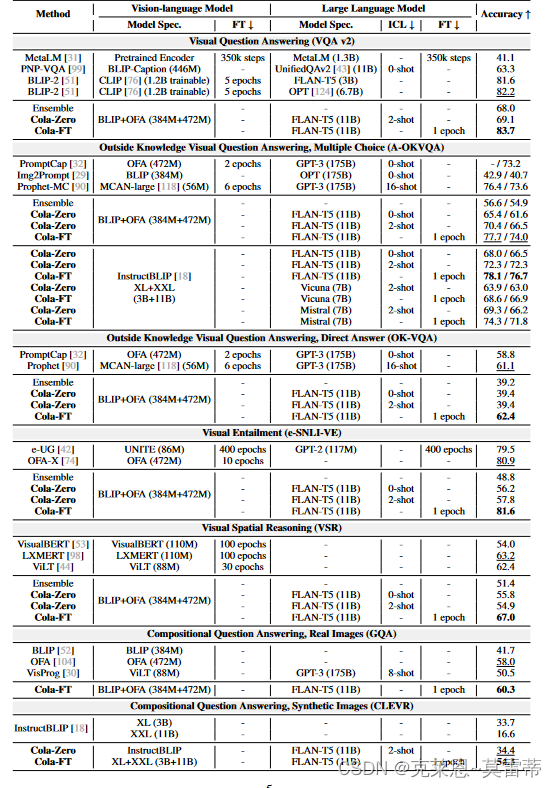
实验结果
暗色的是benchmark和问题任务
最左是方法
第二列是VLM选择
第三列是对VLM的指令调优
第四列是LLM
第五列是prompt个数
第六列是对LLM的指令调优
我们首先观察到,Cola-FT 在四个数据集(A-OKVQA、OK-VQA、e-SNLI-VE、VSR)上实现了最先进的(SOTA)性能,仅需要 1 轮指令调整和一个介质大小的语言模型。相比之下,许多以前的 SOTA 方法比 Cola-FT 需要微调更多的 epoch(例如,VLC-BERT、A-OKVQA 上的 PromptCap)。有些还使用更大的语言模型,例如 GPT-3 (175B) [8] 和 OPT (175B) [124]。 Cola-FT 在 e-SNLI-VE 上的表现优于 OFA-X,尽管后者在更多相关任务和数据上进行了微调(参见表 2:总体性能。模型规格表示规范,其中我们总结了每个模型中采用的详细 VLM 和 LM) FT 和 ICT 分别表示微调和上下文学习,表明 FT 和 ICT 越少效率越高。在 A-OKVQA 中,我们报告了 val/test。 VQA v2、OK-VQA、e-SNLI-VE、GQA 和 CLEVR 中的精度和 val 精度;VSR 中的测试(零样本分割)精度。我们用 标记每个数据集的最佳性能。粗体字体和带有下划线的次佳字体。















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









