







title: LLM for table reasoning
mathjax: true
date: 2024-05-11 11:44:58
tags:
Large Language Models are Versatile Decomposers Decompose Evidence and Questions for Table-based Reasoning
摘要:
表格推理:
表格推理要求结合表格和问题,表格是结构化的
原有的方法不能够完成复杂的question,并且不能够大表格
提出步骤:
1、首先用LLM去分解表格变为多个小表格
2、用LLM去分解问题。利用sql语句分解为多个小问题
3、结合上面多个表格和多个小问题求解最终答案
实验:
在TabFact, WikiTableQuestion, and FetaQA上面做
更特殊的是:
他们的方法超过了人类在TabFact dataset数据集上
除了令人印象深刻的整体性能之外,我们的方法还具有可解释性的优势,其中返回的结果在某种程度上可以通过生成的子证据和子问题来处理
引言
表格推理很重要:1、对于NLU(自然语言理解)和IR(信息检索)很重要 2、对于下游任务例如FV(基于表格的事实验证)和QA很重要
表格推理难:原因是包括了非结构化文本,半结构化表格
解决的历史过程:
1、综合执行语言和表进行交互,例如sql
不足:忽略了表格内文本块的语义
2、最近基于表格的预训练模型
不足:
1、这些模型需要对大量基于特定任务的下游数据集进行微调在处理具有未见过的推理类型的新数据集时难以获得出色的性能
2、破坏了模型的上下文能力
3、对于预训练模型,不进行微调而是上下文学习引起关注
现在LLM在文本推理上厉害,但是对表格推理还没怎么研究,但是LLM对表格推理有一下技术挑战:
1、大表格困难 原因:有很多行和列,难以直接对所有表内容进行编码,而且会有大量不相干信息。例如现在不能扩展到30行以上
2、 将复杂问题分解为更简单的子问题可以有效促进LLM的多步推理(Huang et al., 2022;Dua et al., 2022;Chen et al., 2022)。然而,利用思维链提示直接分解复杂问题(Wei et al., 2022)很容易陷入幻觉困境(Ji et al., 2022),模型可能会生成包含信息的误导性子问题(这些子问题和证据不符合)。
综上,作者提出要一个可靠的基于表格的复杂问题分解方法
所以作者提出
探索了上下文学习 来分解问题和表格的方法----DATER
具体的步骤:
S1、首先,我们利用强大的LLM将当前问题涉及的(半)结构化证据(一张大表)分解为相关的子证据(一张小表)。
我们借助强大的LLM和一些提示,通过预测行和列的索引来实现子证据提取
优点:去除干扰信息,可解释性强
S2、 其次,我们提出了一种“解析-执行-填充”策略,探索编程语言SQL将复杂的非结构化自然语言(NL)问题分解为逻辑和数值计算。
具体来说,我们通过屏蔽数值范围来生成抽象逻辑子问题,然后将抽象逻辑转换为 SQL 查询语言,在证据上执行以获得可靠的子问题。
S3、最后,我们利用分解的子证据和子问题,借助一些上下文提示示例来得到最终答案
到现在理解有点苦难吧,继续往下吧
本文主要贡献
-
我们借助强大的 LLM 和一些提示性示例,通过预测证据的行和列的相关索引,将“巨大”证据(一张巨大的表格)减少为“小”子证据(一张小表格)。我们的证据分解方法使推理者专注于与给定问题相关的基本子证据。
-
我们提出了一种新颖的“解析-执行-填充”策略,通过生成中间 SQL 作为桥梁,在强大的 LLM 的帮助下生成数字和逻辑子问题,将复杂的问题分解为更简单的逐步子问题以及一些提示性的例子。我们的问题分解方法已被证明在基于表格的推理中是有效的,而不需要大量带注释的训练数据。
-
我们对属于基于表的事实验证和基于表的问答任务的三个基准数据集进行了广泛的实验。实验结果表明,我们的 Dater 方法比基于表格的推理的竞争基线取得了明显更好的结果。特别是,Dater 在 TabFact 数据集上首次超越了人类的表现。
-
除了令人印象深刻的整体性能外,我们的 Dater 还具有可解释性的优势,返回的结果在某种程度上可以通过生成的子证据和子问题来处理
相关工作
表推理
基于表格的推理需要对自由形式的自然语言 (NL) 问题和(半)结构化表格进行推理。
传统方法生成可执行语言(例如 SQL 和 SPARQL)来访问表格数据(Date,1989;Abdelaziz 等人,2017)。然而,这些方法无法捕获表格内文本块的语义,并且无法使用表格单元格中的自由格式文本对 Web 表格进行建模。
最近,一些基于表格的推理基准被提出来帮助学习不同类型的推理,例如 TabFact(Chen 等人,2020)、WikiTableQuestion(Pasupat 和 Liang,2015)和 FetaQA(Nan 等人,2022)。
借助深度学习技术,大规模训练数据的可用性显着提高了基于表格的推理的性能(Neeraja et al., 2021;Aly et al., 2021)。
同时,提出了表预训练来对表和文本进行编码,这进一步提高了基于表的推理的性能。
受到屏蔽语言建模 (MLM) 成功的启发,TaPas(Herzig et al., 2020)通过恢复表中的屏蔽单元信息来增强对管状数据的理解。
TAPEX(Liu et al., 2021)在预训练阶段利用BART模型来模拟SQL执行器,使TAPEX获得更好的表推理能力。
ReasTAP(Zhao et al., 2022)根据基于表格的任务的推理技能设计了预训练任务,通过预训练注入推理技能。
Tabert(Yin 等人,2020)提出了内容快照来编码与输入话语最相关的表格内容子集。
PASTA(Gu et al., 2022)引入了一种表操作感知事实验证方法,该方法通过从 WikiTables 合成的句子表完形填空问题对 LM 进行预训练,使其了解常见的基于表的操作。
随后,(Chen,2022;Cheng et al.,2022)探索了LLM执行基于表格的任务的能力。

大语言模型推理
大型语言模型(LLM)已被证明可以赋予一系列推理能力,例如算术(Lewkowycz 等人,2022)、常识(Liu 等人,2022)和符号推理(Zhou 等人,2022a),随着模型参数的扩大(Brown et al., 2020)。值得注意的是,思想链(CoT)(Wei et al., 2022)利用一系列中间推理步骤,在复杂任务上实现更好的推理性能。
基于CoT,人们提出了许多高级改进,包括集成过程(Wang et al., 2022b)、迭代优化(Zelikman et al., 2022)和示例选择(Creswell et al., 2022)。
值得注意的是,ZeroCoT(Kojima 等人,2022)通过在每个答案之前简单地添加“让我们一步一步思考”来提高推理性能。
傅等人。 (Fu et al., 2022)提出的基于复杂性的提示可以为链生成更多的推理步骤,并实现显着更好的性能。
张等人。 (Zhang et al., 2022) 通过聚类自动选择上下文中的示例,无需手动编写。
尽管LLM在文本推理方面表现出色,但他们在表格任务上的推理能力仍然有限。与本文最相关的两篇著作是(Cheng et al., 2022)和(Chen, 2022),但它们都没有关注强大的LLM分解证据(表格)的能力,以及推理的可靠性。
问题分解
问题分解对于理解复杂问题至关重要。
早期的工作(Kalyanpur 等人,2012)利用了一套基于词典句法特征的分解规则来进行问题分解。基于规则的方法的缺点是需要专家手动设计规则,从而很难将规则扩展到新的任务或领域。
近年来,神经模型(Talmor and Berant,2018;Zhang et al.,2019)被提出以端到端的方式执行问题分解。
张等人。 (Zhang et al., 2019)提出了一种基于序列到序列模型的分层语义解析方法,该方法结合了问题分解器和信息提取器。
然而,这些监督方法依赖于大量带注释的训练数据,而获取这些数据需要耗费大量人力。
同时,提出了无监督分解来产生没有强监督的子问题。例如,佩雷斯等人。 (Perez 等人,2020)为每个复杂问题自动生成一个嘈杂的“伪分解”,通过无监督的序列到序列学习在爬取的数据上训练分解模型。
与之前的分解方法不同,我们将 LLM 探索为多功能分解器,借助强大的 LLM 和一些提示示例,分解大量证据和复杂问题以进行基于表格的推理
问题表述和符号
在本文中,我们重点关注两个基于表的推理任务,包括基于表的事实验证(FV)和基于表的问答(QA)。
table-based reasoning = { T ,Q ,A}
T代表table
Q代表question
A代表answer
T = v i , j ∣ i < = R o w T , j < = C o l T T = {v_{i,j}|i <= RowT , j <= ColT } T=vi,j∣i<=RowT,j<=ColT
一个表有ROWT行,colt列
v
i
,
j
v_{i,j}
vi,j代表第i行第j列的表格内容
问题 Q = < q 1 , ⋅ ⋅ ⋅ , q n > Q =< q_1, · · ·, q_n > Q=<q1,⋅⋅⋅,qn> 由 n 个token组成。
对于基于表的 FV,最终答案 A ∈ {0, 1} 是一个布尔值,用于确定输入语句的真假。对于基于表的 QA,答案是自然语言序列 A =< a1,····, an >,n个token,它回答输入语句所描述的问题。
Method
一、上下文学习
证据表Ttest和问题Qtest预测
p
(
A
t
e
s
t
∣
T
t
e
s
t
,
Q
t
e
s
t
,
C
)
p(Atest | Ttest, Qtest, C)
p(Atest∣Ttest,Qtest,C)可以得到最终答案Atest。
这里,
C
=
C
1
,
…
,
C
∣
C
∣
C = {C1, \dots , C_{|C|} }
C=C1,…,C∣C∣ 是来自手动编写的一小组上下文提示,其中每个示例
C
i
=
(
T
i
P
r
o
m
p
t
,
Q
i
p
r
o
m
p
t
,
A
i
p
r
o
m
p
t
)
C_i = (T_i Prompt, Q_iprompt, A_iprompt)
Ci=(TiPrompt,Qiprompt,Aiprompt)。

但是仅仅上下文学习不够 —> 用COT来加强 —> COT也不够,有很多的无用信息,因此需要对表格和问题都要分解
表格分解
之前表格分解的一些方法:
之前的研究利用了文本匹配等一些方法(Yin et al., 2020; Chen et al., 2020)来检索子证据,但实证结果表明这些方法往往是不完善的,并且需要大量特定领域的数据训练数据,因为证据检索过程依赖于强大的常识和领域知识,并且需要对问题和表格的共同理解和推理。
因此作者提出用LLM来分解
------------------------》
借助强大的LLM和一些提示,通过预测行和列的索引来实现子证据提取。形式上,在上下文学习阶段,
子证据的行索引 R o w t e s t = R o w 1 , R o w 2 , . . . R o w ∣ R o w ∣ Rowtest = {Row1, Row2, ...Row_{|Row|}} Rowtest=Row1,Row2,...Row∣Row∣ 和列索引 C o l t e s t = C o l 1 , C o l 2 , . . . C o l ∣ C o l ∣ Coltest = {Col1, Col2, ...Col_{|Col|}} Coltest=Col1,Col2,...Col∣Col∣
子表
T
t
e
s
t
−
{Ttest}^{-}
Ttest−
可以通过用完整证据 Ttest 和相应问题 Qtest 预测
p
(
R
o
w
t
e
s
t
,
C
o
l
t
e
s
t
∣
T
t
e
s
t
,
Q
t
e
s
t
,
C
E
D
)
p(Rowtest, Coltest | Ttest, Qtest, C^{ED})
p(Rowtest,Coltest∣Ttest,Qtest,CED) 来获得。
C E D = C 1 E D , … , C ∣ C ∣ E D C^{ED} = { C^{ED}_1 , \dots , C^{ED}_{|C|} } CED=C1ED,…,C∣C∣ED 是一小组上下文示例,
其中每个 C i E D C^{ED}_i CiED 都是示例实例( R o w i 提示、 C o l i 提示、 T i 提示、 Q i 提示 Row_i 提示、Col_i 提示、T_i 提示、Q_i提示 Rowi提示、Coli提示、Ti提示、Qi提示)。一些详细提示如提示4.2,上面那张图所示。
问题分解
将复杂问题分解为逐步的子问题可以有效促进大型模型的推理过程,这已被证明在数值和常识推理中是有效的(Huang et al., 2022;Dua et al., 2022;陈等人,2022)。然而,我们观察到,利用思维链过程直接分解复杂问题很容易陷入幻觉困境,即LLM可能无法忠实地生成与给定证据(表格)一致的内容,尤其是涉及数值。这会影响后续推理的过程,因此我们需要一种可靠的子问题生成方法。
作者提出了一种“解析执行填充”策略,通过探索编程语言 SQL 来划分逻辑步骤和数值计算,来扩展普通的思想链方法。
首先生成一个抽象逻辑子问题,使用完形填空样式屏蔽数值范围,然后将抽象逻辑转换为 SQL 查询,类似于文本到 SQL 解析。然后,对证据执行SQL语言,得到最终结果进行回填,产生可靠的子问题。
例如,如图底部所示,给出一个问题“在2007-08明尼苏达狂野赛季中,明尼苏达主场比赛的次数比客场比赛的次数多”。 ,我们首先屏蔽掉提示例子中子问题中涉及数值的跨度,剩下的部分可以看成是逻辑问题。这里,逻辑子问题是“q1:明尼苏达队在主场比赛的{…}次”。和“q2:明尼苏达队客场打了 {…} 次。”


然后用类似的方法生成sql查询语句
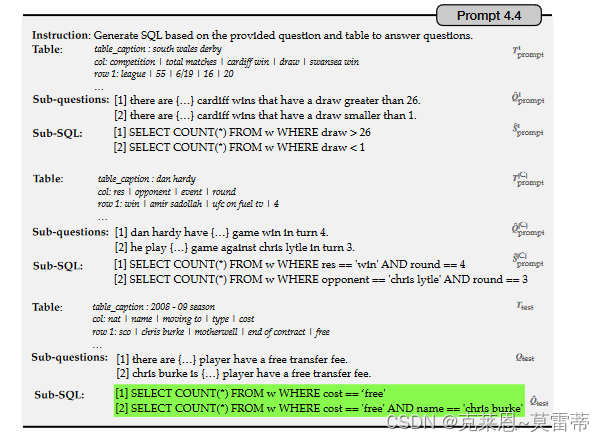
运行sql查询语句得到结果 ,把数值结果回填到sub question中得到子问题
Jointly Reasoning
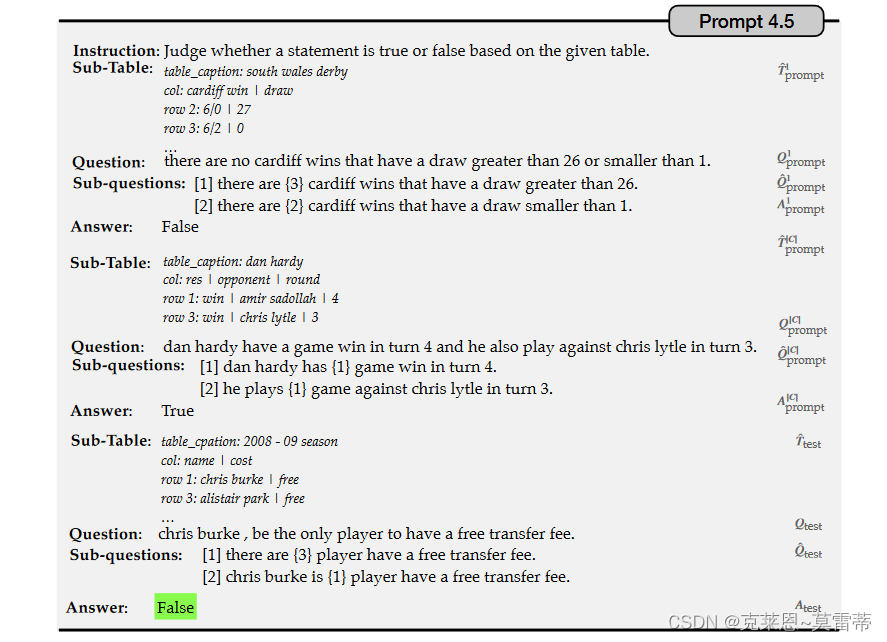
实验
数据集:LLM主要接受网络爬虫数据和代码数据的培训。由于LLM的预训练数据不包含表格数据不存在数据集泄露风险
评估标准:binary classification accuracy 针对able-based fact verification
WikiTableQuestion --------> denotation accuracy
FetaQA ------------------------> BLEU (Papineni et al., 2002) ,ROUGE-1, ROUGE-2, ROUGE-L (Lin, 2004)
在实验中采用 GPT-3 Codex (code-davinci-002) 作为大型语言模型。对于最后的上下文推理学习步骤,分别为 TabFact、WikiTableQuestion 和 FetaQA 注释了 4、2 和 6 个提示示例。为了获得一致的结果,我们使用自洽解码策略(Wang et al., 2022b)。
基线
fine-tuning based methods that require training on task-specific data:
- Table-BERT
- LogicFactChecker
- TaPas
- SAT
- SaMoE
- TAPEX
等等等等,还有很多
基于LLM的方法 对于基于情境学习的LLM方法:
- Codex(Chen et al., 2021)通过执行情境学习直接生成最终答案
- Binder(Cheng et al., 2022)生成编程语言程序并扩展编程语言解决常识性问题的能力。
实验结果
















 7476
7476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









