






任务描述: 数据集中包含带时间戳的用户对电影的评分信息,我们假设其以数据流的形式随时间增量式获取。 你需要设计并实现空间占用尽量小的数据结构实现如下功能:(1)成员查询:对给定查询时间戳和电影id,查询该电影在该时间戳及之前是否曾被评分过;(2)频度查询:对于给定查询时间戳和电影id,查询该电影在该时间戳及之前被评分的总次数;(3)Top-k查询:对给定正整数k和查询时间戳,查询在该时间戳及之前被评分次数最多的前k个电影。在实验报告中,请展示所实现数据结构的关键性能指标,例如查询精度,构建与更新时间,查询时间和空间占用等。
任务分析
拿到这次的任务描述后,我和同学进行了激烈的讨论,对这个任务进行了一个简要的分析。
我们讨论认为该任务假设在数据流完全输入完成后再给定功能里面需要的参数进行查询
首先我们可以发现的是,该任务不同于正常的数据流任务,该任务希望我们带有时间戳进行流量统计,我们首先利用pandas查看一下所用的数据集
import pandas as pd
df=pd.read_csv('ml-25m//ratings.csv')
print(df.head())
print(df.info())
print(df.describe())结果如下
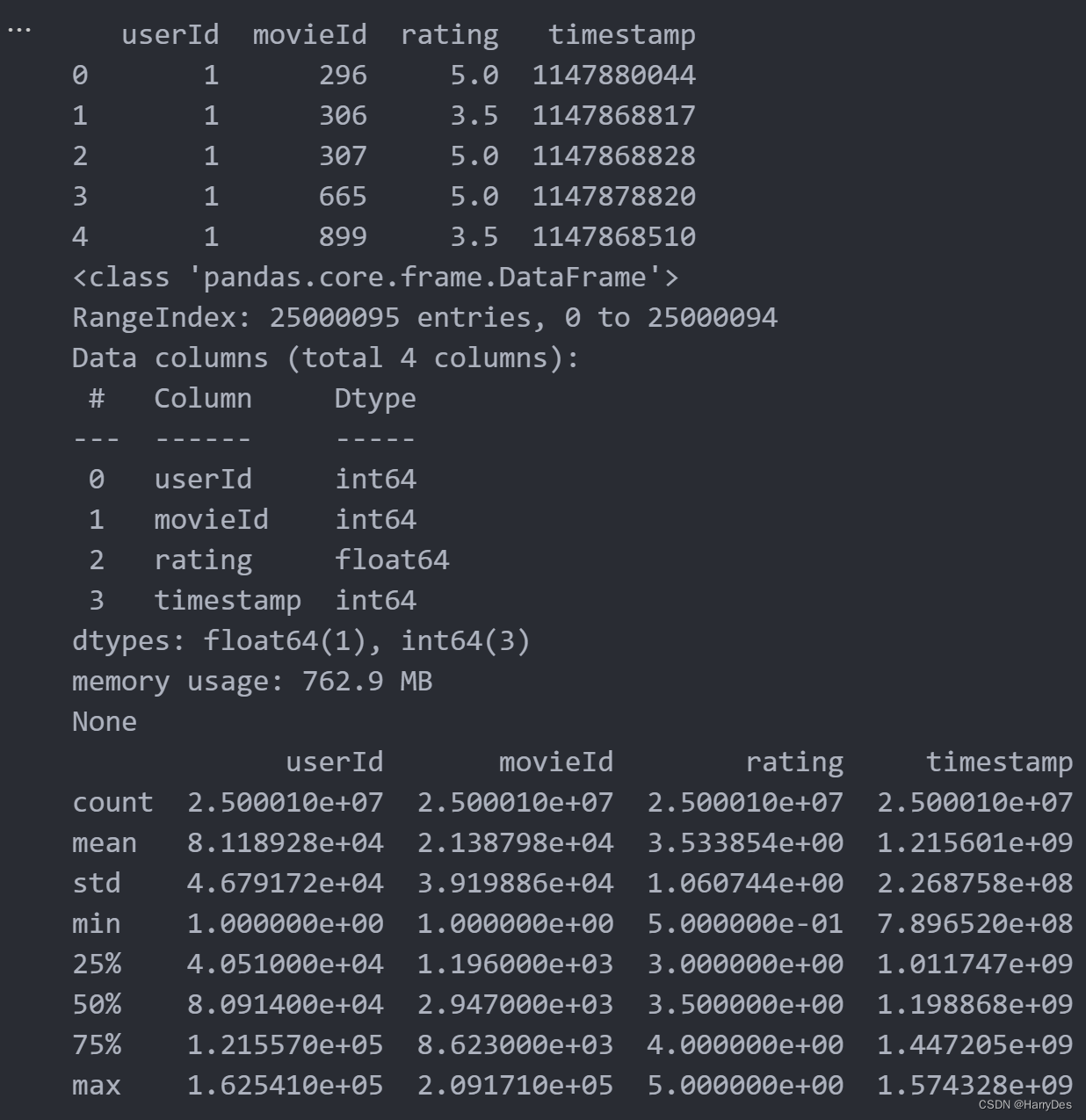
事实上我们结合任务的要求可以发现,对我们任务有用的数据是有两列,即movieId和timestamp。根据课堂的所学,对于功能一和二这种数据流统计某一元素的频率,我们可以采用sketch算法,这里我们想要采用Count-Min-Sketch算法作为底层算法。而第三个功能的top-k我们先暂时搁置。
Count-Min-Sketch算法介绍
CMS算法依赖的数据结构是一个宽度为w、深度为d的计数器数组,另外我们有d个两两独立的哈希函数。
将计数器初始化为0后,我们对于输入的数据流中的数据经过d个哈希函数的运算将结果填入计数器。
当要查询一个元素的频率估计时,我们返回该元素哈希后对应计数器位置中数值最小的一个。
因此我们可以发现CMS算法的结果大于等于真实值。
具体的算法证明这里不过多赘述(其实笔者也没有搞得很明白qwq)
Count-Min-Sketch算法与本次任务的结合
时间戳分析
CMS算法可以很好地帮助我们对数据流进行分析,但是本次实验的数据流带有时间戳,并且需要的功能也对时间有严格的要求,我们首先分析以下数据中的时间戳
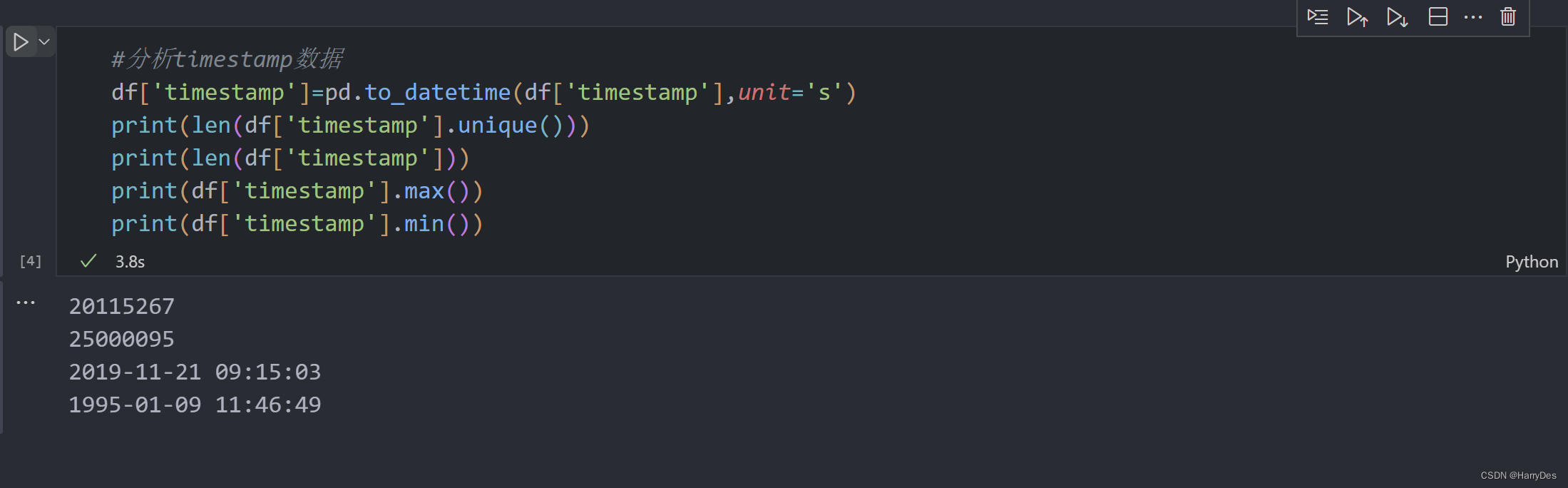
可以看到,数据中的timestamp的跨度很大,共有25000095条,不同的timestamp有20115267条,看到这里,我和同学讨论认为,我们可以对时间戳进行一个简单的合并,即我们仅仅保留日期,不保留小时、分钟和,秒,这样我们牺牲一定的精确度来换取时间与空间。我们可以计算一下有多少不同的天。
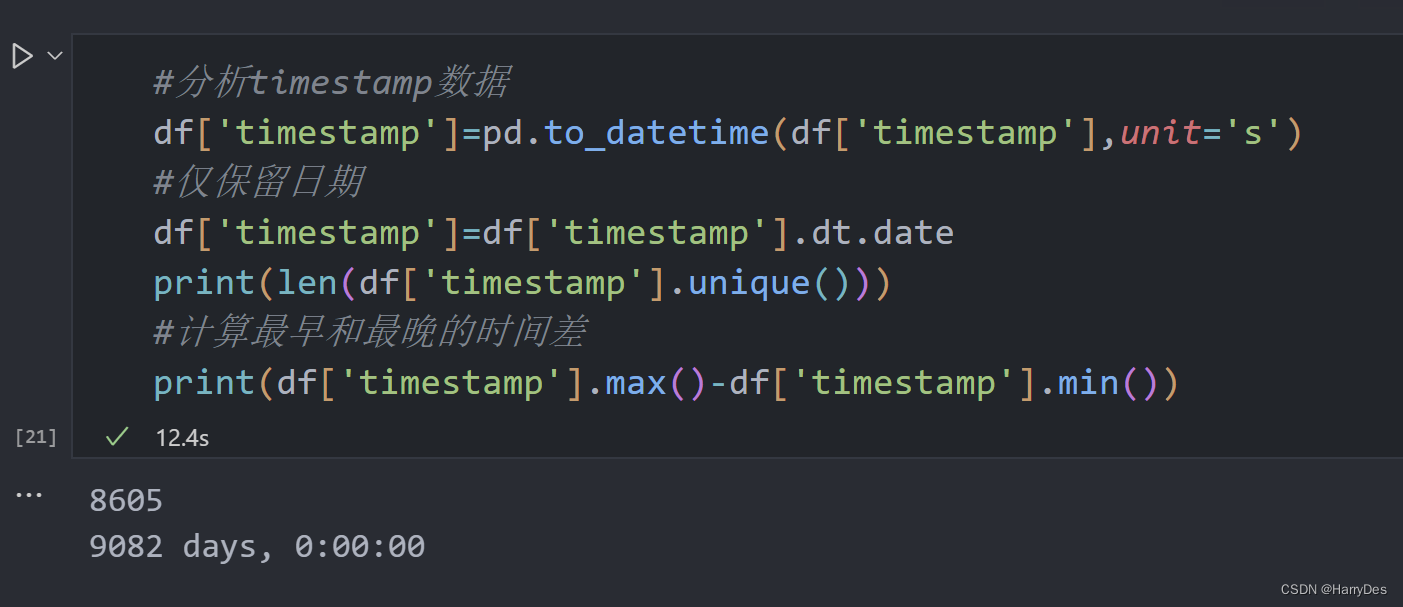
可以看到,最早最晚一共差了9082天,并且只有8605不同的天。这样我们对于时间的准确性的降低极大程度地降低了我们时间处理的开销。
但是这样仍然还是有问题的,我们不能保证评分的信息是否会集中在某一天,因此我们可以绘制直方图来观察一下
df['timestamp']=pd.to_datetime(df['timestamp'],unit='s')
df['timestamp'].hist(bins=8000)
plt.show()我们得到的结果如下
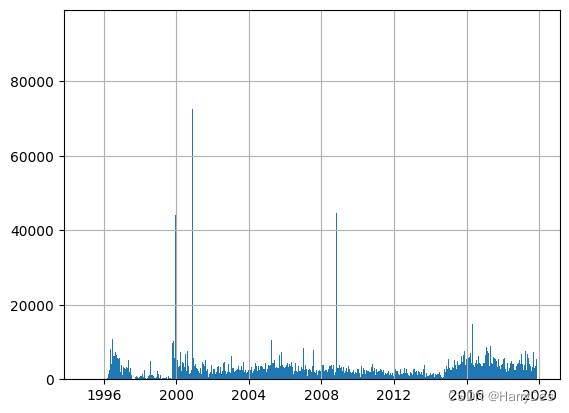
我们可以发现直方图的分布目测较为均匀,但是存在一些数值极高的柱,这可能对我们后续的处理会有影响。
数据集结构设计
通过如上的分析,我和同学讨论认为,我们可以将原本CMS算法增加一维,这一维用于存储时间信息,我们设定该维度的长度为h,即不同的日期数8605。为了后续方便表达,我们暂定该算法为CMSWT(Count-Min-Sketch-With-Timestamp)。CMSWT算法的计数器的是一个d*w*h大小的三维数组,这样当我们数据流传入时,首先我们根据timestamp计算得到该数据在h维度上的位置,然后将数据movieId进行d次哈希填入该h维度下的d*w大小的计数器。按照最初的想法我们在数据流走完后,我们要计算某一movieId频率时,我们沿着h维度将给定的时间之前的所有计数器相加,取所有哈希里面最小的数值作为估值,这时我同学提出一个想法,即将沿着h维度将给定时间之前的每个计数器内对应哈希位置的最小值相加,即先取最小再相加。天才!
这样我们就将数据结构和基本的运算流程讨论清楚了,下面我们完成代码。
CMSWT代码实现
我们首先导入所需要的库和一些global变量,这里的d,w的数值计算可自己百度,具体方法不过多赘述
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mmh3
global width, depth,height
import heapq
from datetime import datetime
width = 800
depth = 3
height = 9083接下来我们来完成我们的CMSWT类
哈希函数部分我们选用了mmh3,因为CMS的结果准确性是高度依赖哈希函数的性能的,mmh3是个不错选择
def hash_function(self, movieId, i):
return mmh3.hash(str(movieId), seed=i,signed=False) % width更新CMSWT计数器
def update(self, movieId, time):
for i in range(depth):
self.table[i][self.hash_function(movieId, i)][time] += 1查询频率
def query(self, movieId, time):
count=0
hash_value = [self.hash_function(movieId, i) for i in range(depth)]
for i in range(time+1):
count+=min([self.table[j][hash_value[j]][i] for j in range(depth)])
return count最终如下
class countMinSketchWithTimestamp:
def __init__(self):
self.table = np.zeros((depth, width, height))
def hash_function(self, movieId, i):
return mmh3.hash(str(movieId), seed=i,signed=False) % width
def update(self, movieId, time):
for i in range(depth):
self.table[i][self.hash_function(movieId, i)][time] += 1
def query(self, movieId, time):
count=0
hash_value = [self.hash_function(movieId, i) for i in range(depth)]
for i in range(time+1):
count+=min([self.table[j][hash_value[j]][i] for j in range(depth)])
return count完成类的构建后我们可以取主函数中尝试构建调用了
首先我们读入数据
df=pd.read_csv('ml-25m//ratings.csv')
df_date=df['timestamp']
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='s')
df['date_only'] = df['timestamp'].dt.date接下来我们需要为h维的时间做处理,首先我们定义起始时间和终止时间,并且初始化一个CMSWT实例,同时我们需要将输入的数据对的时间戳只保留日期,并且根据起始时间计算其在h维对应的位置,接下来调用cmswt的更新函数更新计数器。、
同时注意,由于这个csv文件很大,更新计数器的时间实在是太久了,我这里只选取了前10w条数据进行测试。
start_date=datetime.strptime('1995-01-09','%Y-%m-%d').date()
end_date=datetime.strptime('2019-11-21','%Y-%m-%d').date()
cmswt = countMinSketchWithTimestamp()
for i in range(0,100000):
movieId = df['movieId'][i]
time = (df['date_only'][i]-start_date).days
cmswt.update(movieId, time)
print("successfully updated "+str(count)+' '+str(movieId)+" "+str(time))
count+=1
print("successfully updated")更新后我们就可以调用查询了,但是到这里我们可以发现我们一直忽略了一个功能即Top-k
Top-K
Top-K算法有很多,通常可以通过堆来实现,但是我们需要注意的是这里的Top-K功能是带有时间限制的,并且如果我们根据CMSWT的思想来根据时间戳构建堆的话,空间占用会出奇得大,并且我们希望尽量少使用多余的数据结构,因此我们可以在数据流写入时可以维护一个二维数组,一维存储movieId,对应的第二维度存储movieId对应的最早出现时间。这样当我们接收到一个时间戳后,我们可以根据时间戳找到有哪些movieId需要参与到我们的Top-K计算,接下来就可以正常地使用建堆的操作来计算了。
所以我们要添加一些实现Top-K的代码
首先是CMSWT类中添加Top-K操作
注意这里的59047是不同的电影id的个数,同时这里的代码计数方式采用的是调用查询函数(这样非常慢,后面需要改成先求和再取最小值,这样比较快),且堆的实现方式不符合实验的要求,后续应该修改成自己搓一个堆(其实是笔者太懒了,最近写代码写得有点憔悴TWT)
def top_k(self, k, time,movieId_time,time_date):
movieId_time[1]=movieId_time[1]-time
index=0
for i in range(0,59047):
if movieId_time[1][i]>1.1:
print(movieId_time[1][i])
break
index+=1
count = np.zeros((2,index))
for i in range(0,index):
count[0][i]=movieId_time[0][i]
count[1][i]=self.query(int(movieId_time[0][i]),time_date)
#根据count进行降序排序
result = count[:,count[1].argsort()[::-1]]
print(result[0][0:k])同理我们需要完成调用,我们初始化一个二维np数组,接下来修改计数器更新的循环,同时更新我们的movieId_time数组
#准备一个np二维数组一行存放无冲突的movieId,下一行存对应的最早出现时间
movieId_time = np.zeros((2,59047))
movieId_unique=df['movieId'].unique()
for i in range(0,59047):
movieId_time[0][i]=movieId_unique[i]
for i in range(0,100000):
movieId = df['movieId'][i]
time = (df['date_only'][i]-start_date).days
if movieId in movieId_time[0]:
index = np.where(movieId_time[0] == movieId)
if time < movieId_time[1][index]:
movieId_time[1][index] = time
cmswt.update(movieId, time)
print("successfully updated "+str(count)+' '+str(movieId)+" "+str(time))
count+=1
#把movieId_time数组根据第二行进行升序排序
movieId_time=movieId_time[:,movieId_time[1].argsort()]
print("successfully updated")封装测试
接下来我们就可以对我们的代码进行封装测试了
while(True):
print("输入要进行的操作:1 查询某个movieId在某个时间点的count 2 查询某个时间点前频率最高的的k个movieId 3 退出")
operation=input()
if operation=='1':
print("输入movieId")
movieId=input()
print("输入时间点")
time=int(input())
time_int=time
time=datetime.fromtimestamp(time)
dateonly=time.strftime('%Y-%m-%d')
time=time.strftime('%Y-%m-%d %H:%M:%S')
dateonly=datetime.strptime(dateonly,'%Y-%m-%d').date()
time=(dateonly-start_date).days
count=cmswt.query(int(movieId), time)
sub_df=df.head(100000)
count_exact=sub_df[(df['movieId']==int(movieId)) & (df_date<time_int)]
print("准确值为"+str(len(count_exact))+" CMSWT估计值为"+str(count))
elif operation=='2':
print("输入时间点")
time=int(input())
time_date=datetime.fromtimestamp(time)
dateonly=time.strftime('%Y-%m-%d')
dateonly=datetime.strptime(dateonly,'%Y-%m-%d').date()
time=(dateonly-start_date).days
cmswt.top_k(10,int(time),movieId_time,int(time_date))
elif operation=='3':
break
else:
print("输入有误,请重新输入")查询测试,可以看到结果还是非常不错的

Top-K
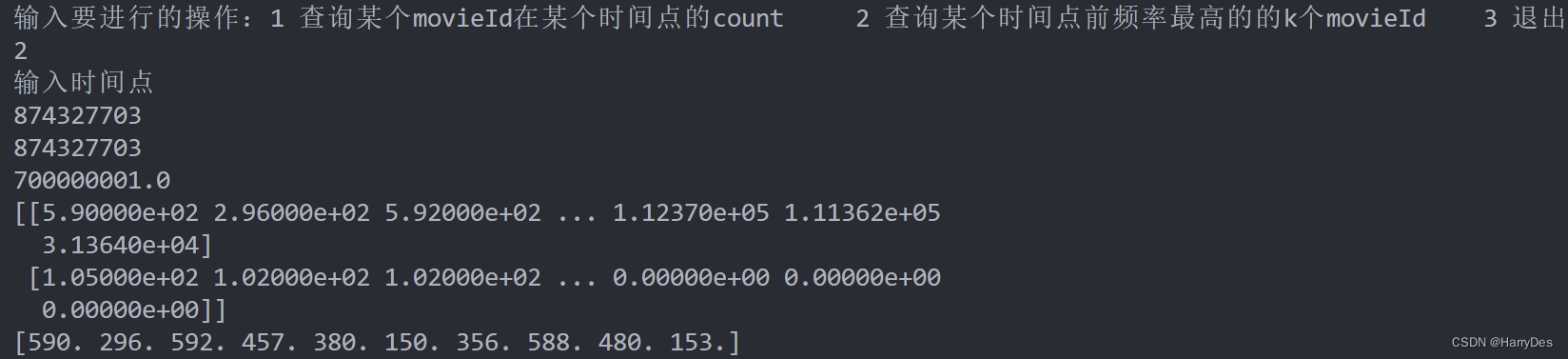
(topk这个思路还是非常抽象的O.o,后面需要换方案)
最后刚刚得知可以预先根据时间戳对数据进行处理,小丑是我自己TWT。















 1817
1817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









