






目录
5.1定义一个ZodiacDataset class类 进行对照片集的处理
本篇仅为个人学习总结,有兴趣的朋友可以参考下面链接,fork其项目
#项目来源#
【深度学习项目三】ResNet50多分类任务【十二生肖分类】 - 飞桨AI Studio星河社区
1、ResNet50介绍
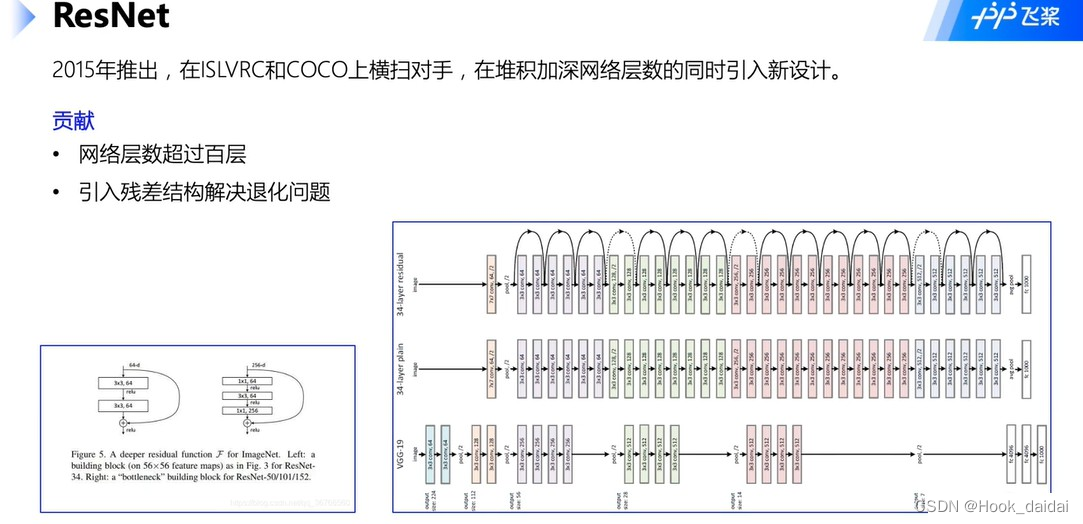
- 残差结构解决梯度消失问题,多个路径前向传播。
- 层数改变如图左下角,主要是为了减少计算开销,既减少参数。
2、数据集介绍
一共12种动物照片
训练样本量| 7,096张
验证样本量| 639张
测试样本量| 656张
加载使用方式|自定义数据集
├── test|train|valid │
├── dog │
├── dragon │
├── goat │
├── horse │
├── monkey │
├── ox │
├── pig │
├── rabbit │
├── ratt │
├── rooster │
├── snake │
└── tiger
处理后为十二类文件夹,各个文件夹对应各自的数据集
3、导入必要的库
import io
import os
import paddle
import numpy as np
from PIL import Image
from config import get
from dataset import ZodiacDataset
import matplotlib.pyplot as plt
from paddle.static import InputSpec
import paddle.vision.transforms as T4、索引字典
__all__ = ['CONFIG', 'get']
CONFIG = {
'model_save_dir': r"....\ResNet50\work\output\zodiac", # 模型保存的目录路径
'num_classes': 12, # 分类问题中的类别数量
'total_images': 7096, # 总共的图像数量
'epochs': 20, # 训练的轮次数量
'batch_size': 32, # 批处理大小
'image_shape': [3, 224, 224], # 图像的形状(通道数、高度、宽度)
'LEARNING_RATE': {
'params': {
'lr': 0.00375
}
}, # 学习率设置
'OPTIMIZER': {
'params': {
'momentum': 0.9
},
'regularizer': {
'function': 'L2',
'factor': 0.000001
}
}, # 优化器设置,包括动量和正则化
'LABEL_MAP': [
"ratt",
"ox",
"tiger",
"rabbit",
"dragon",
"snake",
"horse",
"goat",
"monkey",
"rooster",
"dog",
"pig",
]
} # 标签映射,用于将类别索引映射到类别名称
CONFIG为总字典,其中: model_save_dir 为 模型保存的目录路径 (此处用目标路径的绝对路径) num_classes 为 分类问题的类别数量 total_images 为 图像的总数 epochs 为 训练的次数 (可自定义) batch-size 为 批处理大小
1、小批量(Mini-Batch): 小批量训练使用相对较小的批处理大小,例如 32、64、128 等。这种方法通常在训练过程中能够提供一定程度的随机性,有助于模型收敛到较好的局部最小值。同时,小批量训练可以利用硬件加速(如GPU)来并行处理多个样本,从而提高训练效率。
2、批量梯度下降(Batch Gradient Descent): 批量梯度下降使用整个训练数据集来计算每个梯度更新,批处理大小等于训练集的大小。这意味着每个训练迭代都使用了全部数据,通常会导致更稳定的收敛,但计算成本也更高,特别是对于大型数据集。
3、随机梯度下降(Stochastic Gradient Descent): 随机梯度下降使用批处理大小为 1,每次只使用一个样本来计算梯度更新。这种方法具有很高的随机性,但也更快地收敛到局部最小值。然而,它可能会导致训练过程中的抖动。
选择合适的批处理大小通常取决于数据集的大小、可用的计算资源以及模型的架构。较大的批处理大小可以加速训练,但可能需要更多的内存和计算能力。较小的批处理大小可以增加训练的随机性,有助于避免局部最小值,但可能需要更多的训练迭代来达到收敛。
image_shape 为 图像的形状(通道数,高度,宽度) 一般为[3,224,224]
LEARNING_RATE 为 学习率
学习率是一个控制模型在每次训练迭代中更新权重的步长或幅度的超参数。具体来说,学习率决定了模型在每次迭代中沿着梯度方向更新权重的幅度。较小的学习率会导致权重更新缓慢,但通常会更稳定;较大的学习率会导致权重更新快速,但可能会不稳定。
OPTIMIZER 为 优化器 其中 momentum 为 动量
动量(momentum)是一种优化算法的参数,用于加速模型的训练过程,通常设置在0到1之间。较大的动量值使模型在更新权重时更具惯性,有助于克服局部极小值问题,从而加速收敛。
regularizer 是正则化的设置
用来指定正则化的设置。正则化是一种用于控制模型复杂度和防止过拟合的技术。
正则化的类型被设置为
'L2',表示使用L2正则化(也称为权重衰减)。
'factor'参数被设置为0.000001,这是正则化的超参数,控制正则化的强度。L2正则化会在损失函数中添加一个惩罚项,使权重趋向于较小的值,从而降低模型的复杂度,有助于防止过拟合。
LABEL_MAP 为 总标签
4.1、字典索引函数
def get(full_path):
for id, name in enumerate(full_path.split('.')):
if id == 0:
config = CONFIG
config = config[name]
return config通过对路径的处理,读取full_path的 id 和 后缀 ,并返回 读取字典中对应的值
5、图像处理
__all__ = ['ZodiacDataset']
# 定义图像的大小
image_shape = get('image_shape')
IMAGE_SIZE = (image_shape[1], image_shape[2])
class ZodiacDataset(paddle.io.Dataset):
"""
十二生肖数据集类的定义
"""
def __init__(self, mode='train'):
"""
初始化函数
"""
# 具体来说,这行代码的作用是检查变量 mode 是否包含在列表 ['train', 'test', 'valid'] 中。
# 如果 mode 的值不是这三个字符串之一,就会引发 AssertionError 异常,
# 其中包含指定的错误消息 'mode is one of train, test, valid.'。
assert mode in ['train', 'test', 'valid'], 'mode is one of train, test, valid.'
self.data = []
with open(r'E:\paddle_LeNet\ResNet50_try\data_animal\signs\{}.txt'.format(mode)) as f:
for line in f.readlines():
info = line.strip().split('\t')
if len(info) > 0:
self.data.append([info[0].strip(), info[1].strip()])
if mode == 'train':
self.transforms = T.Compose([
T.RandomResizedCrop(IMAGE_SIZE), # 随机裁剪大小
T.RandomHorizontalFlip(0.5), # 随机水平翻转
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
else:
self.transforms = T.Compose([
T.Resize(256), # 图像大小修改
T.RandomCrop(IMAGE_SIZE), # 随机裁剪
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
def __getitem__(self, index):
"""
根据索引获取单个样本
"""
image_file, label = self.data[index]
image = Image.open(image_file)
if image.mode != 'RGB':
image = image.convert('RGB')
image = self.transforms(image)
return image, np.array(label, dtype='int64')
def __len__(self):
"""
获取样本总数
"""
return len(self.data)5.1定义一个ZodiacDataset class类 进行对照片集的处理
区分train和test、valid的照片处理
if mode == 'train':
self.transforms = T.Compose([
T.RandomResizedCrop(IMAGE_SIZE), # 随机裁剪大小
T.RandomHorizontalFlip(0.5), # 随机水平翻转
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
else:
self.transforms = T.Compose([
T.Resize(256), # 图像大小修改
T.RandomCrop(IMAGE_SIZE), # 随机裁剪
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
如果
mode是 'train',表示当前处于训练模式,将执行以下数据预处理操作:
T.RandomResizedCrop(IMAGE_SIZE): 随机裁剪图像到指定的尺寸IMAGE_SIZE,以增加数据的多样性。T.RandomHorizontalFlip(0.5): 以50%的概率随机水平翻转图像,也是为了增加数据的多样性。T.ToTensor(): 将图像数据转换为张量(tensor)格式,通常深度学习模型需要输入张量格式的数据。T.Normalize(): 对图像进行标准化,即对图像的每个通道进行归一化,以使均值为[0.485, 0.456, 0.406],标准差为[0.229, 0.224, 0.225]。如果
mode不是 'train',表示当前处于测试模式,将执行以下数据预处理操作:
T.Resize(256): 调整图像大小到指定的尺寸,这里是将图像的较短边调整为256像素,保持纵横比不变。T.RandomCrop(IMAGE_SIZE): 对图像进行随机裁剪到指定的尺寸IMAGE_SIZE,也是为了增加数据的多样性。T.ToTensor(): 同样将图像数据转换为张量格式。T.Normalize(): 对图像进行标准化,与训练模式下相同。
对每一个照片以及标签相应处理
标签变成NumPy数组,数据类型为 'int64',通常表示整数类型。
def __getitem__(self, index):
"""
根据索引获取单个样本
"""
image_file, label = self.data[index]
image = Image.open(image_file)
if image.mode != 'RGB':
image = image.convert('RGB')
image = self.transforms(image)
return image, np.array(label, dtype='int64')
从数据集的
self.data中根据索引index获取单个样本的文件路径image_file和标签label。使用Pillow库中的
Image.open(image_file)打开图像文件,将图像加载到内存中。检查图像的模式是否为 'RGB',如果不是 'RGB' 模式,则使用
image.convert('RGB')将图像转换为 'RGB' 模式。这是因为深度学习模型通常要求输入图像为 'RGB' 彩色模式。接下来,将图像传递给之前在构造函数中定义的数据预处理变换
self.transforms,以进行图像的预处理。根据不同的模式(训练模式或测试模式),self.transforms可以是不同的预处理操作,如调整大小、裁剪、归一化等。最后,将经过预处理的图像
image和标签label返回。图像通常被转换为张量格式,而标签通常被转换为NumPy数组,并指定数据类型为 'int64',以适应深度学习模型的要求。
6、进行训练
6.1、训练准备
先定义数据集的目录以及标签的列表,以便后续的引用
# 数据集根目录
DATA_ROOT = r'E:\paddle_LeNet\ResNet50_try\data_animal\signs'
# 标签List
LABEL_MAP = get('LABEL_MAP')6.1.1、数据集定义
引用ZodiacDataset类 将 train 和 valid 数据集分开,生成train_dataset和valid_dataset两组数据
train_dataset = ZodiacDataset(mode='train')
valid_dataset = ZodiacDataset(mode='valid') 6.1.2、项目选择和开发
network = paddle.vision.models.resnet50(num_classes=get('num_classes'), pretrained=True)
#pretrained=True使用别人已经训练好的预训练模型进行训练网络
model = paddle.Model(network)
model.summary((-1, ) + tuple(get('image_shape')))
network = paddle.vision.models.resnet50(num_classes=get('num_classes'), pretrained=True):paddle.vision.models.resnet50是PaddlePaddle中内置的ResNet-50模型的构建函数,用于创建一个ResNet-50神经网络模型。
num_classes=get('num_classes')设置模型的输出类别数,通常用于分类任务。get('num_classes')可能是一个从配置中获取的值,它决定了模型的最终输出类别数。pretrained=True表示使用预训练的权重参数来初始化模型。这意味着你将使用已经在大型数据集上预训练过的模型,然后可以在该基础上进行微调或迁移学习。这行代码创建了一个
model = paddle.Model(network):paddle.Model对象,它用于封装神经网络模型并提供训练、评估和推理等功能。
model.summary((-1, ) + tuple(get('image_shape'))):
model.summary方法用于显示模型的摘要信息,包括模型的结构和参数数量。(-1, ) + tuple(get('image_shape'))是传递给model.summary方法的参数,它指定了输入张量的形状。这里的get('image_shape')可能是从配置中获取的输入图像的形状,tuple(get('image_shape'))将其转换为一个元组。-1是一个通用的占位符,表示该维度可以是任何值。这样,你可以在摘要中查看模型在不同批次大小和输入图像尺寸下的表现。
6.2、开始训练
6.2.1、定义训练函数
EPOCHS = get('epochs')
BATCH_SIZE = get('batch_size')
def create_optim(parameters):
step_each_epoch = get('total_images') // get('batch_size')
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=get('LEARNING_RATE.params.lr'),
T_max=step_each_epoch * EPOCHS)
return paddle.optimizer.Momentum(learning_rate=lr,
parameters=parameters,
weight_decay=paddle.regularizer.L2Decay(get('OPTIMIZER.regularizer.factor'))) #正则化来提升精度
EPOCHS = get('epochs')和BATCH_SIZE = get('batch_size'):这两行代码用于从配置中获取训练的总轮数(EPOCHS)和批处理大小(BATCH_SIZE)。
def create_optim(parameters)::这是一个函数定义,它接受一个参数parameters,该参数通常是模型的参数(例如权重和偏置)。
step_each_epoch = get('total_images') // get('batch_size'):这行代码计算了每个训练周期(epoch)中的步数。它通过将总训练图像数除以批处理大小来计算,以确定每个周期需要多少个步骤。
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=get('LEARNING_RATE.params.lr'), T_max=step_each_epoch * EPOCHS):这行代码定义了学习率(learning rate)。它使用了余弦退火调度(Cosine Annealing Decay),其中get('LEARNING_RATE.params.lr')获取了学习率的初始值,T_max设置为总步数(step_each_epoch * EPOCHS),表示余弦退火的周期。
return paddle.optimizer.Momentum(learning_rate=lr,parameters=parameters, weight_decay=paddle.regularizer.L2Decay(get('OPTIMIZER.regularizer.factor'))):
- 这行代码返回一个动量(Momentum)优化器的实例,用于训练模型。
learning_rate=lr:指定了学习率,使用了上面定义的余弦退火学习率。parameters=parameters:指定了需要优化的模型参数,这通常是模型的权重和偏置。weight_decay=paddle.regularizer.L2Decay(get('OPTIMIZER.regularizer.factor')):指定了正则化项,这里使用了L2正则化,通过get('OPTIMIZER.regularizer.factor')获取正则化的系数。L2正则化有助于控制模型的复杂度并防止过拟合。
6.2.2、训练配置
# 模型训练配置
model.prepare(create_optim(network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy(topk=(1, 5))) # 评估指标
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
valid_dataset, # 评估数据集
epochs=EPOCHS, # 总的训练轮次
batch_size=BATCH_SIZE, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
save_dir='./chk_points/', # 分阶段的训练模型存储路径
callbacks=[visualdl]) # 回调函数使用
model.prepare(create_optim(network.parameters()), paddle.nn.CrossEntropyLoss(), paddle.metric.Accuracy(topk=(1, 5))):
model.prepare方法用于准备模型训练的各种配置。create_optim(network.parameters()):指定了优化器,通常是前面定义的创建优化器的函数,它使用了模型的参数network.parameters()。paddle.nn.CrossEntropyLoss():指定了损失函数,通常是交叉熵损失,用于计算模型预测与实际标签之间的差异。paddle.metric.Accuracy(topk=(1, 5)):指定了评估指标,通常是准确度(Accuracy),同时也计算了top-5准确度。这些指标将在训练过程中用于评估模型性能。
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log'):
- 这行代码创建了一个用于可视化训练过程的VisualDL回调函数,它将训练过程中的指标和日志信息记录到指定的日志目录
visualdl_log中。
model.fit(...):
model.fit方法用于启动模型的全流程训练。train_dataset和valid_dataset是训练数据集和评估数据集,用于训练和验证模型。epochs=EPOCHS指定了总的训练轮次,通常使用前面定义的EPOCHS变量。batch_size=BATCH_SIZE指定了批次计算的样本量大小,通常使用前面定义的BATCH_SIZE变量。shuffle=True表示是否在每个训练轮次之前打乱样本集,以增加训练的随机性。verbose=1控制训练日志的展示格式,通常将其设置为1以显示训练进度和指标信息。save_dir='./chk_points/'指定了分阶段的训练模型存储路径,训练过程中的模型参数将被保存到这个目录。callbacks=[visualdl]指定了回调函数,这里使用了VisualDL回调来记录训练过程中的信息。
6.2.3、模型储存
# 模型存储
model.save(get('model_save_dir'))将模型储存为pdparams格式的模型 # zodiac.pdparams
7、进行预测
# 测试数据集
predict_dataset = ZodiacDataset(mode='test')
# 执行预测
# 网络结构示例化
network = paddle.vision.models.resnet50(num_classes=get('num_classes'))
# 模型封装
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')])
# 训练好的模型加载
model_2.load(get('model_save_dir'))
# 模型配置
model_2.prepare()
# 执行预测
result = model_2.predict(predict_dataset)
predict_dataset = ZodiacDataset(mode='test'):
- 这行代码创建了一个名为
predict_dataset的数据集对象,用于存储测试数据集。它使用了一个名为ZodiacDataset的数据集类,并通过mode='test'指定了数据集的模式为测试模式,这通常意味着它包含用于模型推理的测试样本。
network = paddle.vision.models.resnet50(num_classes=get('num_classes')):
- 这行代码创建了一个新的ResNet-50网络模型,但没有加载预训练的权重。它使用了与训练时相同的模型结构,并且
num_classes与训练时一致,以确保输出层的类别数与训练时一致。
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')]):
- 这行代码创建了一个名为
model_2的PaddlePaddle模型对象。它使用了前面创建的网络模型network,并指定了输入的形状和数据类型,以确保与测试数据集匹配。
model_2.load(get('model_save_dir')):
- 这行代码加载了之前训练好的模型参数,通过
get('model_save_dir')指定了模型参数的路径。
model_2.prepare():
- 这行代码准备模型以进行预测。它配置了模型以接收输入数据并执行推理。
result = model_2.predict(predict_dataset):
- 这行代码执行了模型的预测操作,使用了测试数据集
predict_dataset作为输入。模型会对测试数据集中的样本进行预测,并将结果存储在result变量中。
7.1、样本映射
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(LABEL_MAP[predict_label]))
image_file, label = predict_dataset.data[idx]
image = Image.open(image_file)
plt.imshow(image)
plt.show()
# 随机取样本展示
indexs = [50,150 , 250, 350, 450, 00]
for idx in indexs:
predict_label = np.argmax(result[0][idx])
real_label = predict_dataset[idx][1]
show_img(real_label,predict_label)
print('样本ID:{}, 真实标签:{}, 预测值:{}'.format(idx, LABEL_MAP[real_label], LABEL_MAP[predict_label]))用matplotlib库进行对样本输出的可视化
def show_img(img, predict)::这是一个函数定义,用于展示图像和模型的预测结果。
img是传递给函数的图像数据,通常是一个图像对象或数组。predict是模型的预测结果,通常是一个表示类别或标签的值。
plt.figure():这行代码创建一个新的图形窗口。
plt.title('predict: {}'.format(LABEL_MAP[predict_label])):这行代码设置图形的标题,显示了模型的预测结果。
image_file, label = predict_dataset.data[idx]:这行代码从测试数据集中获取指定索引idx处的图像文件路径image_file和真实标签label。
image = Image.open(image_file):这行代码使用Pillow库打开图像文件,将其加载为图像对象。
plt.imshow(image):这行代码将加载的图像显示在图形窗口中。
plt.show():这行代码显示图形窗口,展示图像和预测结果。
indexs = [50, 150, 250, 350, 450, 0]:这是一个包含要展示的样本索引的列表,其中包括了要展示的测试样本的索引。
for idx in indexs::这是一个循环,遍历indexs列表中的每个索引。
predict_label = np.argmax(result[0][idx]):这行代码从模型的预测结果中获取指定索引idx处的样本的预测标签,使用np.argmax函数找到具有最高概率的类别。
real_label = predict_dataset[idx][1]:这行代码从测试数据集中获取指定索引idx处的样本的真实标签。
show_img(real_label, predict_label):这行代码调用了show_img函数来展示真实图像和模型的预测结果。
print('样本ID:{}, 真实标签:{}, 预测值:{}'.format(idx, LABEL_MAP[real_label], LABEL_MAP[predict_label])):这行代码打印了样本的索引、真实标签和模型的预测结果。
8、模型保存
model_2.save('infer/zodiac', training=False)
'infer/zodiac'是保存模型的目标路径,模型的参数和结构信息将被保存在该路径下。你可以根据需要修改路径。training=False表示在保存模型时不保存训练状态,这通常意味着只保存模型的权重参数和结构信息,而不保存训练过程中的优化器状态、学习率等信息。这对于模型的推理和预测阶段通常是合适的。
9、Gradio可视化
# 导入必要的库
import paddle
import os
import gradio as gr
import numpy as np
import tempfile
import paddle.vision.transforms as T
from paddle.static import InputSpec
from ResNet50_try.work.config import get
import matplotlib.pyplot as plt
LABEL_MAP = get('LABEL_MAP')
image_shape = get('image_shape')
IMAGE_SIZE = (image_shape[1], image_shape[2])
network = paddle.vision.models.resnet50(num_classes=get('num_classes'), pretrained=True)
#pretrained=True使用别人已经训练好的预训练模型进行训练网络
model = paddle.Model(network)
model.summary((-1, ) + tuple(get('image_shape')))
# 模型预测结果
def serve_chicken(images):
transforms = T.Compose([
T.Resize(256), # 图像大小修改
T.RandomCrop(IMAGE_SIZE), # 随机裁剪
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
image = transforms(images)
# 添加批处理维度,将维度从 [C, H, W] 更改为 [1, C, H, W]
image = paddle.unsqueeze(image, axis=0)
image = paddle.unsqueeze(image, axis=0)
# 执行预测
# 网络结构示例化
network = paddle.vision.models.resnet50(num_classes=get('num_classes'))
# 模型封装
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')])
# 训练好的模型加载
model_2.load(get('model_save_dir'))
# 模型配置
model_2.prepare()
# 执行预测
result = model_2.predict(image)
# 返回预测结果
predict_label = np.argmax(result[0][0])
plt_path = show_img(images, predict_label)
return LABEL_MAP[predict_label], plt_path
# gradio
# 样例展示图片上传
def get_img_list():
path = r'E:\paddle_LeNet\ResNet50_try\Gradio_class\animal_12'
img_extensions = ['.jpg'] # 可以根据需要添加更多图像文件扩展名
img_list = []
for file_name in os.listdir(path):
if any(file_name.endswith(ext) for ext in img_extensions):
img_list.append(os.path.join(path, file_name))
return img_list
def get_selected_image(state_image_list, evt: gr.SelectData):
return state_image_list[evt.index]
def show_img(image, predict_label):
plt.figure()
plt.title('predict: {}'.format(LABEL_MAP[predict_label]))
plt.imshow(image)
# 创建临时文件夹用于保存图像
temp_dir = tempfile.mkdtemp()
temp_image_path = os.path.join(temp_dir, "output_image.jpg")
# 保存图形为图像文件
plt.savefig(temp_image_path, format='jpg')
plt.close() # 关闭图形以释放资源
# 返回保存的图像文件路径或图像数据
return temp_image_path
def class_animal():
with gr.Blocks(theme=gr.themes.Soft()) as demo:
image_result_list = get_img_list() # 样例图展示
state_image_list = gr.State(value=image_result_list) # 样例图展示
with gr.Row(equal_height=False):
with gr.Column(variant='panel'):
gr.Markdown('''"dog",'pig','ratt','ox','tiger','rabbit','monkey','rooster','horse','goat','snake',"dragon"''')
image_results = gr.Gallery(value=image_result_list, label='样例图', allow_preview=False,
columns=6, height=250)
inputs = gr.Image(type='pil', label="传入需要预测的图片")
# gr.components.Dropdown(choices=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
# label="选择输出多少个动物的概率")]
text_button_img = gr.Button("确定上传")
outputs = gr.Textbox(label='上传的动物的图片的预测结果为')
with gr.Column(variant='panel'):
with gr.Box():
with gr.Row():
gr.Markdown("预测结果可视化")
image_output = gr.Image()
image_results.select(get_selected_image, state_image_list, queue=False) # 样例图展示
text_button_img.click(fn=serve_chicken, inputs=inputs, outputs=[outputs,image_output])
return demo
if __name__ == "__main__":
# resnet_model = load_pretrained_resnet()
# print("ResNet模型已加载!")
# result = serve_chicken(r"D:\桌面\cat12\cat_12_train\0bpPevGiKaR4JUFlThw7y5BQLr6jDnuA.jpg")
# print(f"这个猫的种类是【{result}】!")
with gr.Blocks(css='style.css') as demo:
gr.Markdown(
"# <center> \N{fire} 基于ResNet50的十二生肖分类 </center>")
with gr.Tabs():
with gr.TabItem('\N{clapper board} 十二生肖分类预测'):
class_animal()
demo.launch()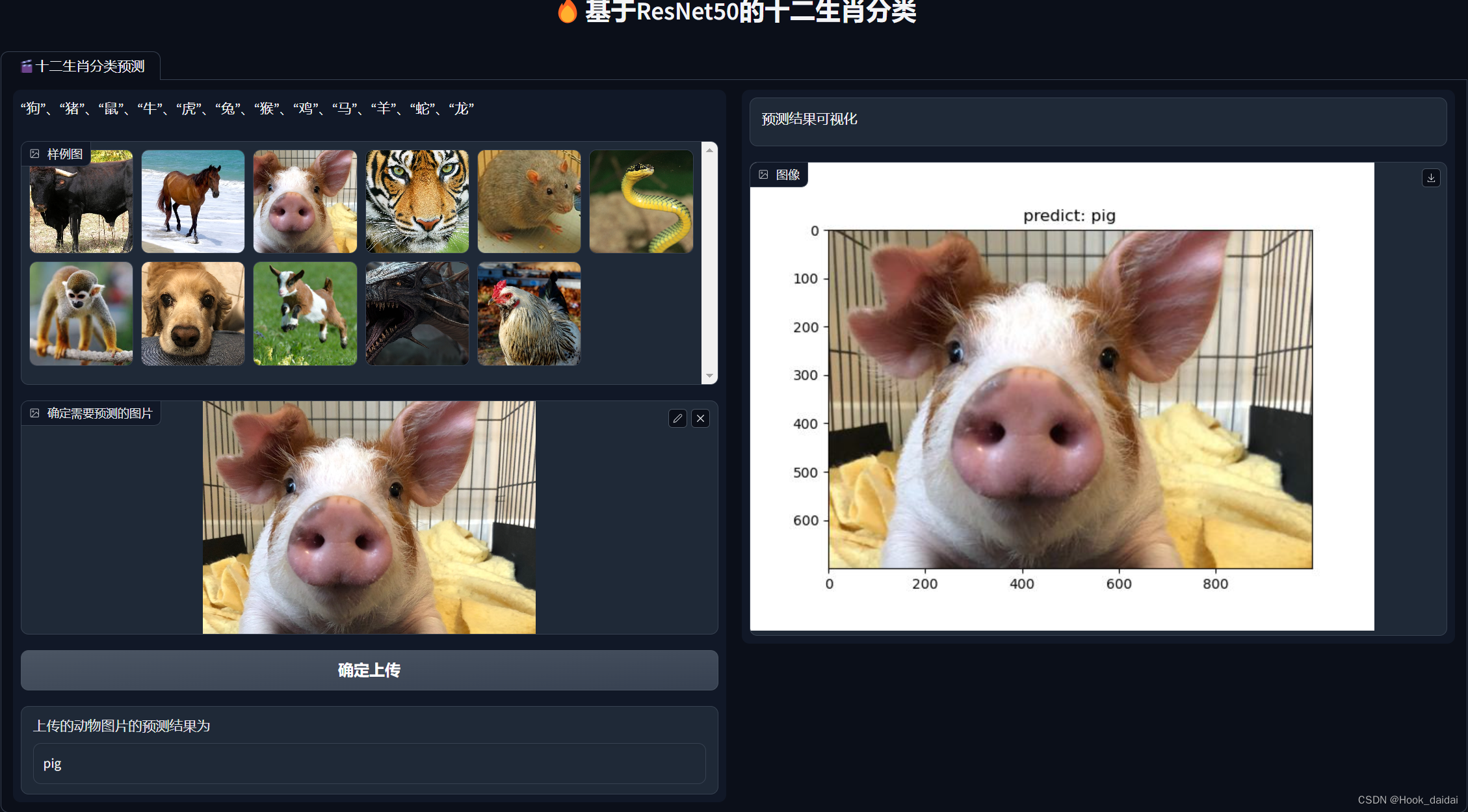
10、总结
10.1、字典的索引
通过写一个CONFIG的字典,列举了整个模型训练及预测的一些变量具体的值
10.2、对数据的处理
主要是对图像的大小形状,数据的格式转换和标准化 HWC => CHW 等等的处理,对模型训练提升效率,以及在gradio中对单个照片的维度修改,都影响着训练和预测的工作
10.3、训练模型的参数
对于一个模型的训练好坏,其参数也起着重要的作用,比如学习率、优化器、损失函数等等。
通过修改这些参数,可以更加完善模型的训练,结果更加理想。
10.4、结果的输出
标签的准确率受着模型的影响,好的网架结构,对于训练就更加准确,因此也可以使用不同的网架结构,进行修改。
gradio的可视化,通过matplotlib库,对图片的可视化,可以更加直观地观察其结果。

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









