






引言
随着各类自媒体平台的兴起,数据挖掘和分析变得尤为重要。推特作为全球最大的自媒体平台,越来越来越多的人需要通过爬取其内容进行分析。然后自从马斯克接手推特之后,推特api不可再用,推特的反爬力度也在逐渐增强。今天小编就分享一个推特爬虫的教程。
更新:逆向部分见尾
描述
这篇文章主要通过关键词爬取帖子内容信息以及帖子作者主页相关信息,用户也可根据自己需要的时间段进行筛选。推特可支持筛选多种语言,我这里先展示中文和英文的。
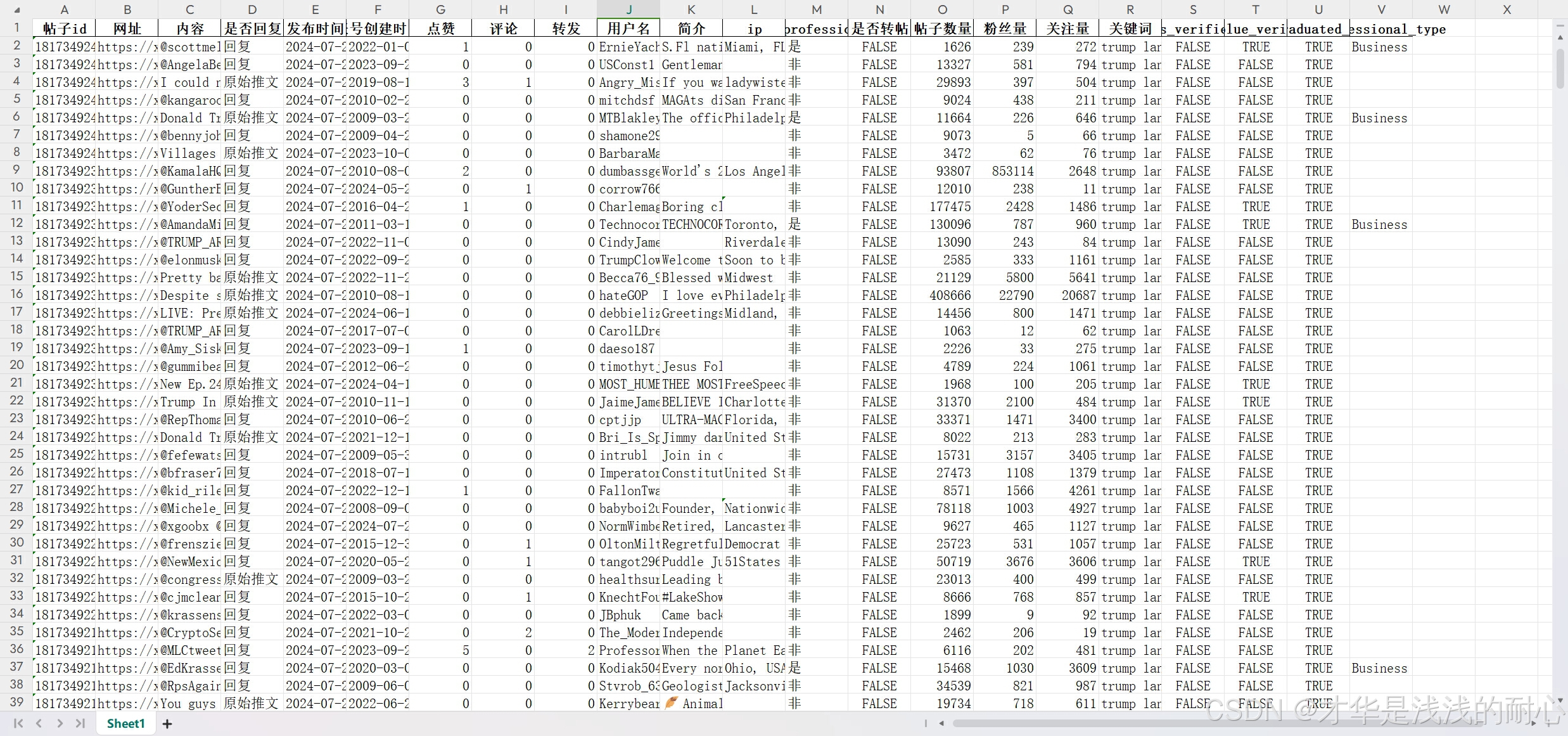
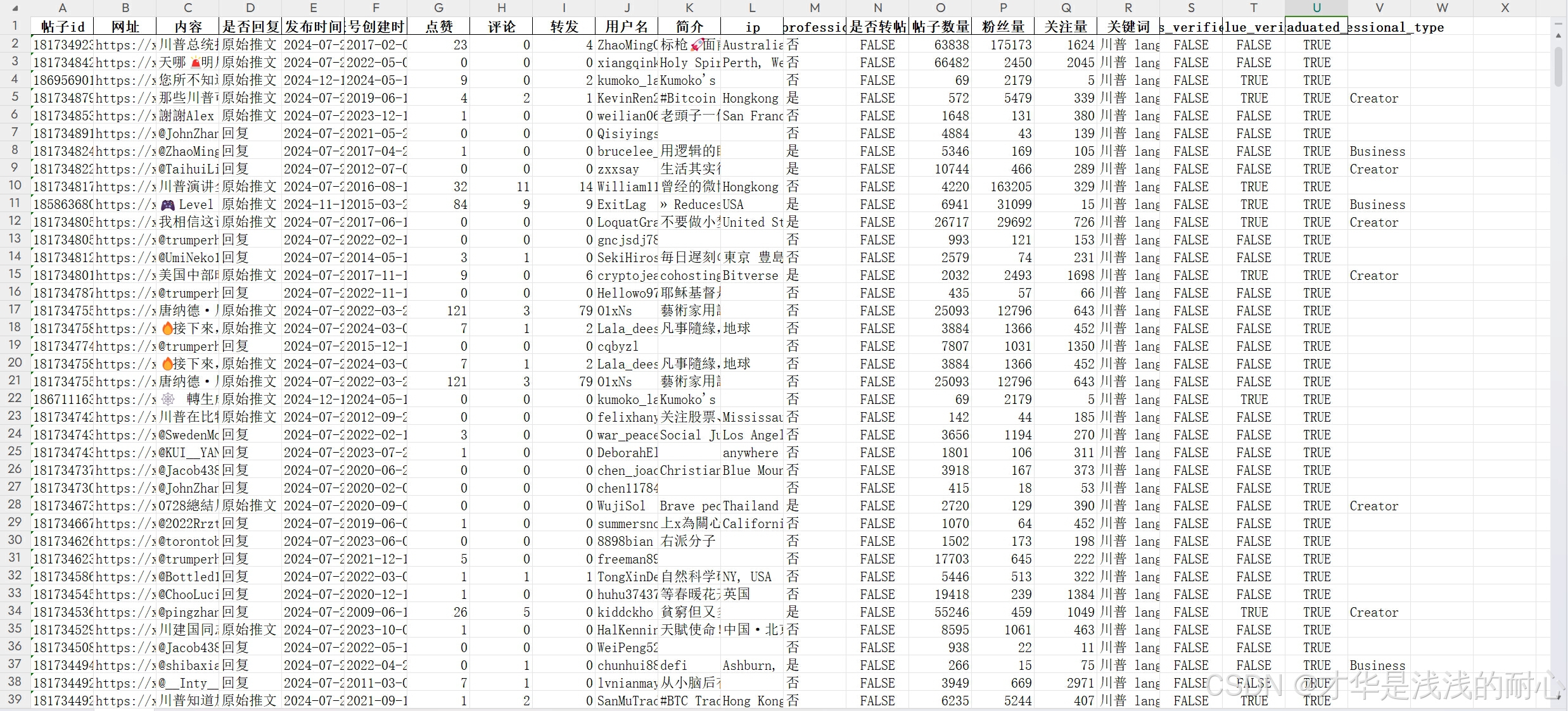
字段解释:
帖子id:推特帖子id;
网址:帖子网址,点击可直接导航到帖子页面;
内容:帖子内容;
是否回复:判断该帖子是原创还是回复某个人的;
发布时间:帖子发布时间;
创建时间;发帖人账号创建的时间;
其它字段包括:转赞评,用户名,用户简介,用户ip,用户贴子数,关注量,粉丝数,账号认证情况,账号类型等。
代码
接下来就是重要的代码部分了,我将从参数设置,数据获取,数据解析这几个方面介绍。
1.导包
导入爬虫所需要的包,如下图所示,不会的小伙伴在命令行输入 pip install 包名
import json import os import time import requests import datetime import pandas as pd
2.设置header参数
class CsxqTwitterKeywordSearch:
def __init__(self,saveFileName,cookie_str):
self.saveFileName = saveFileName
self.searchCondition = None
self.headers = {
'headers对应的参数'
}
self.cookies = self.cookie_str_to_dict(cookie_str)
我们定义一个 CsxqTwitterkeywordSearch 的主类,然后初始化headers参数,这里参数我没有写,大家自己上推特官网复制自己的就行。
3.参数获取
这里我们主要通过网站里面的cursor,获取我们的请求参数
def get_params(self,cursor):
if cursor == "":
variables = {"rawQuery": self.searchCondition, "count": 20,"querySource": "typed_query", "product": "Latest"}
params = {
"variables": json.dumps(variables,separators=(",",":")),
"features": ""
}
else:
variables = {"rawQuery": self.searchCondition, "count": 20, "cursor": cursor, "querySource": "typed_query", "product": "Latest"}
params = {
"variables": json.dumps(variables,separators=(",",":")),
"features": ""
}
return params
4.获取数据
通过刚才获取的参数对接口进行访问,返回json数据
def get(self,cursor):
self.headers["x-csrf-token"] = self.cookies['ct0']
url = "https://x.com/i/api/graphql/6uoFezW1o4e-n-VI5vfksA/SearchTimeline"
params = self.get_params(cursor)
while True:
try:
response = requests.get(url,
headers=self.headers,
cookies=self.cookies,
params=params,
timeout=(3,10))
if response.status_code == 429:
time.sleep(60*20)
if response.status_code == 200:
data = response.json()
return data
except Exception as e:
print("搜索接口发生错误:%s" % e)
5.解析数据
获取完成数据后就可以解析数据啦,一下是完整的解析数据代码。
def parse_data(self,entries):
resultList = []
def transTime(dd):
GMT_FORMAT = '%a %b %d %H:%M:%S +0000 %Y'
timeArray = datetime.datetime.strptime(dd, GMT_FORMAT)
return timeArray.strftime("%Y-%m-%d %H:%M:%S")
contentList = []
for index, ent in enumerate(entries):
try:
entryId = ent.get('entryId', "")
if 'tweet' in entryId:
l_result = ent['content']['itemContent']['tweet_results']['result'] if ent['content'].get(
'itemContent') else None
if l_result:
contentList.append(l_result)
elif "profile-conversation" in entryId:
items = ent['content']['items']
for i in items:
l_result = i['item']['itemContent']['tweet_results']['result'] if i['item'].get(
'itemContent') else None
if l_result:
contentList.append(l_result)
except:
pass
for l in contentList:
try:
result = l.get('tweet') if l.get('tweet') else l
legacy = result['legacy']
core = result['core']
created_at = transTime(legacy.get('created_at'))
full_text = legacy.get('full_text')
note_tweet = result.get('note_tweet')
favorite_count = legacy.get('favorite_count') # 点赞
reply_count = legacy.get('reply_count') # 回复
retweet_count = legacy.get('retweet_count', 0)
quote_count = legacy.get('quote_count', 0)
retweet_count = retweet_count + quote_count
if note_tweet:
try:
full_text = note_tweet['note_tweet_results']['result']['text']
except:
pass
u_legacy = core['user_results']['result']['legacy']
hash_uname = u_legacy.get('screen_name')
description = u_legacy['description']
friends_count = u_legacy['friends_count']
followers_count = u_legacy.get('followers_count')
item = {"内容":full_text,"时间": created_at,"点赞":favorite_count,"评论":reply_count,"转发":retweet_count,"用户名": hash_uname,"简介": description,\
"粉丝量":followers_count,"关注量":friends_count}
print("数据->",item)
resultList.append(item)
except:
pass
self.save_data(resultList)
6.数据保存
def save_data(self, resultList):
if resultList:
df = pd.DataFrame(resultList)
if not os.path.exists(f'./{self.saveFileName}.csv'):
df.to_csv(f'./{self.saveFileName}.csv', index=False, mode='a', sep=",", encoding="utf_8_sig")
else:
df.to_csv(f'./{self.saveFileName}.csv', index=False, mode='a', sep=",", encoding="utf_8_sig",
header=False)
self.resultList = []
print("保存成功")
7.定义一个main函数
def run(self,word):
cursor = ""
page = 1
while True:
# if page > 2:
# break
print("正在爬取的页数:%s,cursor:%s"%(page,cursor))
resqJson = self.get(cursor)
if not resqJson:
break
cursor,entries = self.get_cursor(resqJson)
if entries:
self.parse_data(entries)
page += 1
else:
break
def main(self,fromDate,endDate):
wordList = ["climate change"]
start = 0
for index,word in enumerate(wordList[start:],start):
self.searchCondition = f"{word} lang:en until:{endDate} since:{fromDate}"
print("搜索条件:",self.searchCondition)
self.run(word)
8.主函数
if __name__ == '__main__':
cookie_str = '改成你自己的cookies'
fromDate = "2024-08-10"
endDate = "2024-10-13"
saveFileName= "Tim_Cook"
ctks = CsxqTwitterKeywordSearch(saveFileName,cookie_str)
ctks.main(fromDate,endDate)
cookies参数设置为自己的cookie参数,根据自己的需求设置开始时间段和截止时间段。
更新
关于推特的更新,推特官方在4月份添加了请求速率限制以及逆向的限制;

主要是xClientTransactionId的生成,id的核心部分由前端的Gd生成
url = "https://twitter.com"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
response = bs4.BeautifulSoup(resp.content, "lxml")
method = "POST"
path = "/1.1/jot/client_event.json"
ctreq = ClientTransaction(home_page_response=response)
xClientTransactionId = ctreq.generate_transaction_id(method="GET",
path="/i/api/graphql/AIdc203rPpK_k_2KWSdm7g/SearchTimeline")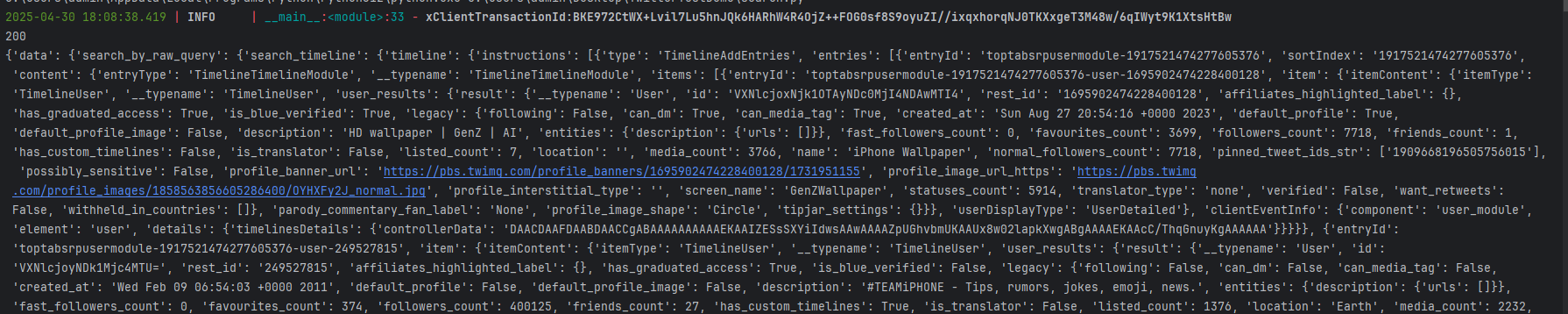
认为博主写得还可以的话,可以一键三连哦,后续还会撰写fb ins yt等平台的爬虫代码
其它需求可以联系本人 zx_luckfe。
如需根据博主ID爬取博主帖子可参考另一篇博客:CSDN![]() https://mp.csdn.net/mp_blog/creation/editor/144536978
https://mp.csdn.net/mp_blog/creation/editor/144536978



















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











