







引言
在数字化时代,字符编码是计算机处理和传输文本数据的关键。不同的字符编码方式,如UTF-8、ASCII等,扮演着重要的角色,影响着我们在各种应用中如何理解、存储和交流文本信息。正确的字符编码选择和处理是确保数据准确性和跨平台兼容性的关键要素。
本文将带您深入探索字符编码世界,重点关注区分UTF-8、ASCII等一系列字符表示形式的方法和原理。
ASCLL码
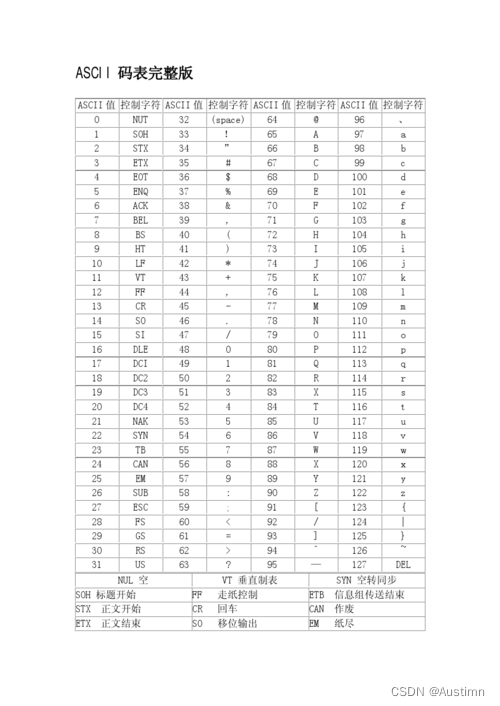
ASCII(American Standard Code for Information Interchange)是一种最早被广泛使用的字符编码,它使用7位二进制数(即128个值)来表示字符。ASCII编码最初只适用于英语字符和一些特殊符号,其中包括常见的字母、数字和标点符号。
ASCII编码采用了一种简单的映射机制,将每个字符映射到一个唯一的7位二进制值。例如,字母"A"被映射为二进制值01000001,数字"5"被映射为二进制值00110101。ASCII编码表提供了每个字符与其对应的二进制值之间的映射关系,这使得计算机能够正确地解析和显示ASCII编码的文本。
由于ASCII编码只使用7位二进制数,因此共有128个不同的字符可以表示。这意味着ASCII编码无法表示其他语言的字符,如汉字、日语假名和俄语字母等。因此,在处理多语言文本和字符集的情况下,ASCII编码显得有限。然而,ASCII编码仍然在许多场景中广泛使用,尤其是在计算机基础设施和通信协议中。由于其简单性和广泛支持,ASCII编码在早期的计算机系统中起到了重要的作用。
以下附ASCLL码表:
需要注意的是,随着计算机技术的发展,为了支持更多字符和语言,扩展的ASCII编码形式被引入,如ISO-8859系列和扩展ASCII码。这些扩展编码通过使用8位二进制数来表示字符,扩展了ASCII编码的范围,可以表示更多的字符和符号。
尽管ASCII编码的应用受到了一定的限制,但它仍然是字符编码领域的基础,并为后续的字符编码标准奠定了基础。对于英语字符和基本的文本处理,ASCII编码仍然是一个重要的概念。
Unicode编码
Unicode是一个全球性的字符编码标准,旨在涵盖世界上所有的字符和符号。它的作用和目标是为每个字符分配一个唯一的标识符,无论是拉丁字母、亚洲文字还是特殊符号,都能够在计算机系统中被准确地表示和处理。
Unicode的核心原理是为每个字符分配一个独一无二的代码点。代码点是Unicode字符集中的一个整数值,用来标识和表示一个特定的字符。这个代码点被写作U+后面跟着一组十六进制数字,例如U+0041表示拉丁字母A,U+4E2D表示中文汉字"中"。
Unicode的全球化价值体现在它能够涵盖世界上几乎所有的语言和字符集。无论是使用英语、中文、日语、阿拉伯语还是其他任何语言,都可以使用Unicode来表示和处理其中的字符。这种全球化的特性使得Unicode成为了国际化和跨文化交流的重要基础。
另一个重要的特点是Unicode字符集的扩展能力。随着不断的演进和发展,Unicode持续地扩展和添加新的字符。它的目标是能够涵盖全球范围内的所有字符和符号,包括字母、数字、标点符号、表情符号、特殊符号以及各种语言的字符。通过不断扩展字符集,Unicode确保了对于各种应用和场景的兼容性和可扩展性。
Unicode的广泛应用体现在各个领域,特别是计算机系统、操作系统、互联网和软件开发中。现代编程语言和平台通常内置对Unicode的支持,使得开发人员可以方便地处理和处理不同语言和字符集的文本数据。理解Unicode的原理和价值,对于正确处理多语言文本和字符编码有了重要意义。
UTF-8编码
UTF-8(Unicode Transformation Format-8)是Unicode最常用的编码方式之一,被广泛应用于互联网、计算机系统和软件开发中。它使用可变长度的编码方式来表示字符,根据字符所需的字节数进行编码。
UTF-8的可变长度特性使得它能够在保持兼容性的同时,有效地表示全球范围内的各种字符和符号。UTF-8的编码规则如下:
-
单字节编码:对于ASCII字符,UTF-8使用单个字节进行编码,与ASCII编码完全兼容。这意味着ASCII编码的文本在UTF-8编码下与ASCII编码完全一致,不会占用额外的空间。
-
多字节编码:对于非ASCII字符,UTF-8使用多个字节进行编码。UTF-8根据字符所需的位数来确定采用的字节数,以表示特定字符。具体的编码规则如下:
- 对于2字节编码的字符,首字节的前3位为“110”,后续字节的前2位为“10”。
- 对于3字节编码的字符,首字节的前4位为“1110”,后续字节的前2位为“10”。
- 对于4字节编码的字符,首字节的前5位为“11110”,后续字节的前2位为“10”。
UTF-8编码与ASCII编码有着紧密的关系,它保持了与ASCII编码的兼容性。对于纯英文文本或仅包含ASCII字符的文本,UTF-8编码与ASCII编码的结果是完全一致的。这是因为ASCII字符使用单个字节进行编码,并且UTF-8编码与ASCII编码表保持了一致。
因此,UTF-8编码具有ASCII兼容性,这意味着纯英文文本或仅包含ASCII字符的文本可以无缝地在ASCII和UTF-8之间进行转换,而不会引入任何数据损失或变化。
UTF-8编码的ASCII兼容性使得它成为互联网上广泛采用的字符编码方式。在现代的互联网通信和数据存储中,使用UTF-8编码来处理文本数据,既能够兼容传统的ASCII字符,又能够支持全球范围内的多语言字符和符号。UTF-8编码在实现跨语言、跨平台的文本处理和互联网通信中起到了重要的作用。
ASCII、UTF-8和Unicode的关系
ASCII、UTF-8和Unicode之间存在着密切的关系,它们在字符编码领域扮演不同的角色,同时也相互依赖和支持。
首先,UTF-8是Unicode的一种实现方式,通过可变长度的编码规则来表示Unicode字符集中的字符。Unicode是一个全球性的字符编码标准,旨在涵盖世界上所有的字符和符号。它为每个字符分配了一个唯一的标识符,使得不同语言和字符集能够在计算机系统中被准确地表示和处理。而UTF-8编码则是Unicode实现中最常用的编码方式之一。
UTF-8的编码方式具有可变长度的特性,对于ASCII字符,UTF-8使用单个字节进行编码,与ASCII编码完全兼容。这意味着纯英文文本或仅包含ASCII字符的文本在UTF-8编码下与ASCII编码的结果是完全一致的。这种兼容性使得现有的ASCII文本可以无缝地转换为UTF-8编码,同时保持数据的一致性。
另一方面,Unicode作为字符集标准,为UTF-8和其他编码提供了统一的字符表示。Unicode为每个字符分配了一个唯一的代码点,无论是拉丁字母、亚洲文字还是特殊符号,都能够在Unicode字符集中找到对应的代码点。UTF-8编码通过可变长度的方式来表示Unicode字符集中的字符,确保了对各种字符和符号的兼容性。
因此,ASCII、UTF-8和Unicode之间的关系可以概括为:UTF-8是Unicode的一种实现方式,通过可变长度的编码规则来表示Unicode字符集中的字符;UTF-8编码具有对ASCII字符与ASCII编码的兼容性,能够无缝转换ASCII编码的文本;Unicode作为字符集标准,为UTF-8和其他编码提供了统一的字符表示,使得全球范围内的字符能够在计算机系统中得到正确的处理和表示。
了解ASCII、UTF-8和Unicode之间的关系有助于我们正确处理和处理多语言文本和字符编码,确保数据的准确性和兼容性。
总结
正确理解和处理字符编码是处理文本数据的关键。在本文中,我们介绍了ASCII、Unicode和UTF-8等常见的字符编码方式。通过选择适当的字符编码方式,我们可以更好地处理和解析不同语言和字符集的文本数据。深入了解和应用字符编码将也有助于提高文本处理的准确性和效率。















 1658
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











