






简介
R语言的corrplot包提供了一种可视化相关矩阵的探索性工具,支持自动变量重排序以帮助发现变量间的隐藏模式。
corrplot非常易于使用,并提供了丰富的绘图选项,包括可视化方法、图形布局、颜色、图例、文本标签等。它还提供了p值和置信区间来帮助用户确定相关性的统计显著性。
尽管corrplot()有约50个参数,但最常用的只有几个。在大多数情况下,只需一行代码就能生成相关矩阵图。
corrplot包中有七种可视化方法(参数method):
-
circle和square:圆形或方形的面积表示相应相关系数的绝对值。
-
ellipse:椭圆的离心率根据相关值参数化缩放(来自D.J. Murdoch和E.D. Chow的工作)。
-
number:以不同颜色显示的系数数字。
-
color:具有不同颜色的相同大小的方块。
-
shade:类似于
color,但负相关系数会被阴影化(来自Michael Friendly的工作)。 -
pie:圆形对于正值顺时针填充,对于负值逆时针填充。
corrplot.mixed() 是一个混合可视化样式的封装函数,它允许您为相关矩阵的下三角和上三角部分分别设置不同的可视化方法。
有三种布局类型(由参数 type 控制):
"full":显示完整的相关矩阵"upper":仅显示矩阵的上三角部分"lower":仅显示矩阵的下三角部分
相关矩阵可以根据相关系数进行重新排序。这种重排序对于识别矩阵中隐藏的结构和模式非常重要。
基本用法
最常用的参数包括method、type、order和diag。
library(corrplot)
M = cor(mtcars)
查看一下数据M
> head(M)
# mpg cyl disp hp drat wt qsec vs
# mpg 1.0000000 -0.8521620 -0.8475514 -0.7761684 0.6811719 -0.8676594 0.41868403 0.6640389
# cyl -0.8521620 1.0000000 0.9020329 0.8324475 -0.6999381 0.7824958 -0.59124207 -0.8108118
# disp -0.8475514 0.9020329 1.0000000 0.7909486 -0.7102139 0.8879799 -0.43369788 -0.7104159
# hp -0.7761684 0.8324475 0.7909486 1.0000000 -0.4487591 0.6587479 -0.70822339 -0.7230967
# drat 0.6811719 -0.6999381 -0.7102139 -0.4487591 1.0000000 -0.7124406 0.09120476 0.4402785
# wt -0.8676594 0.7824958 0.8879799 0.6587479 -0.7124406 1.0000000 -0.17471588 -0.5549157
# am gear carb
# mpg 0.5998324 0.4802848 -0.5509251
# cyl -0.5226070 -0.4926866 0.5269883
# disp -0.5912270 -0.5555692 0.3949769
# hp -0.2432043 -0.1257043 0.7498125
# drat 0.7127111 0.6996101 -0.0907898
# wt -0.6924953 -0.5832870 0.4276059\
corrplot(M, method = 'number') # colorful number
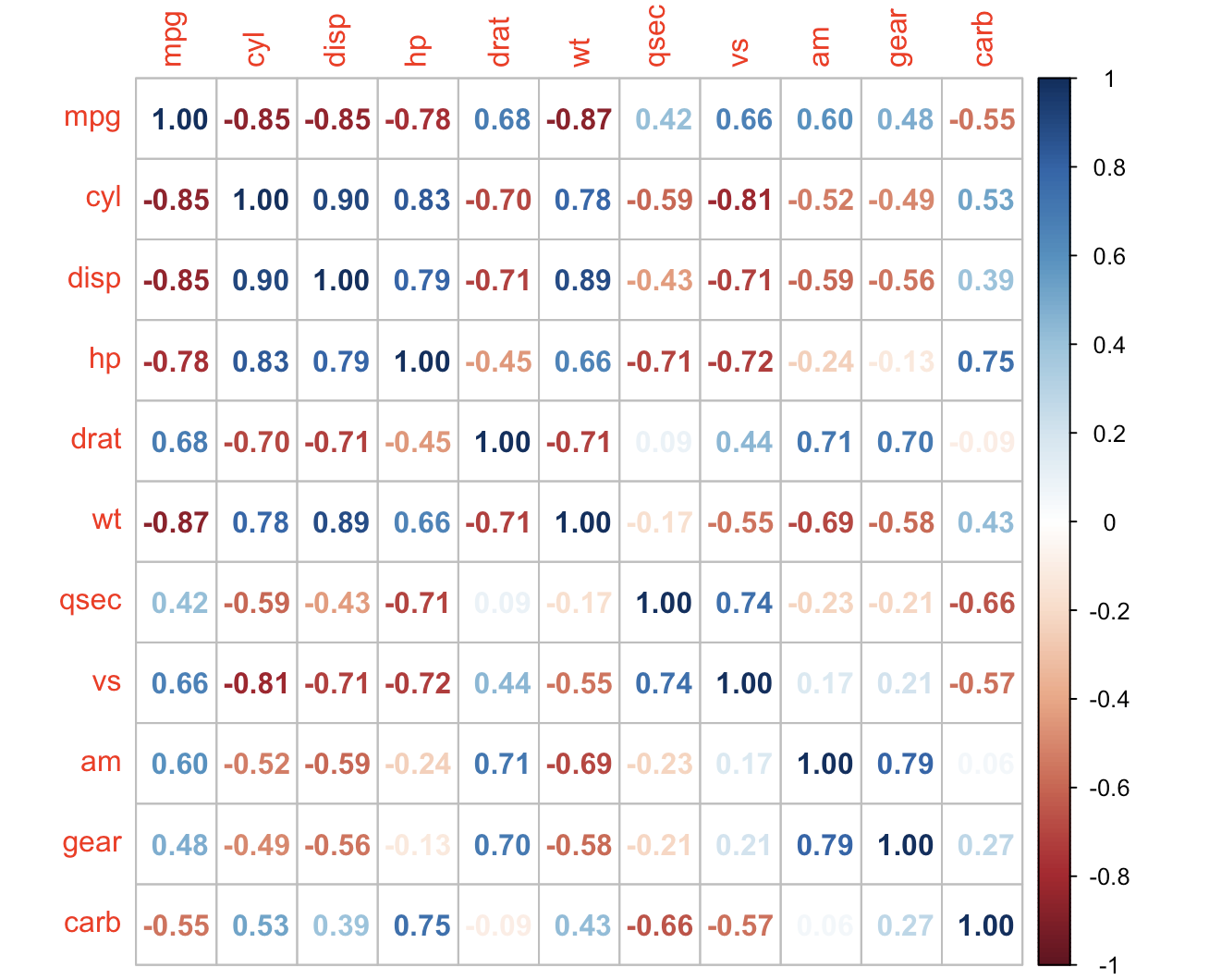
corrplot(M, method = 'color', order = 'alphabet')
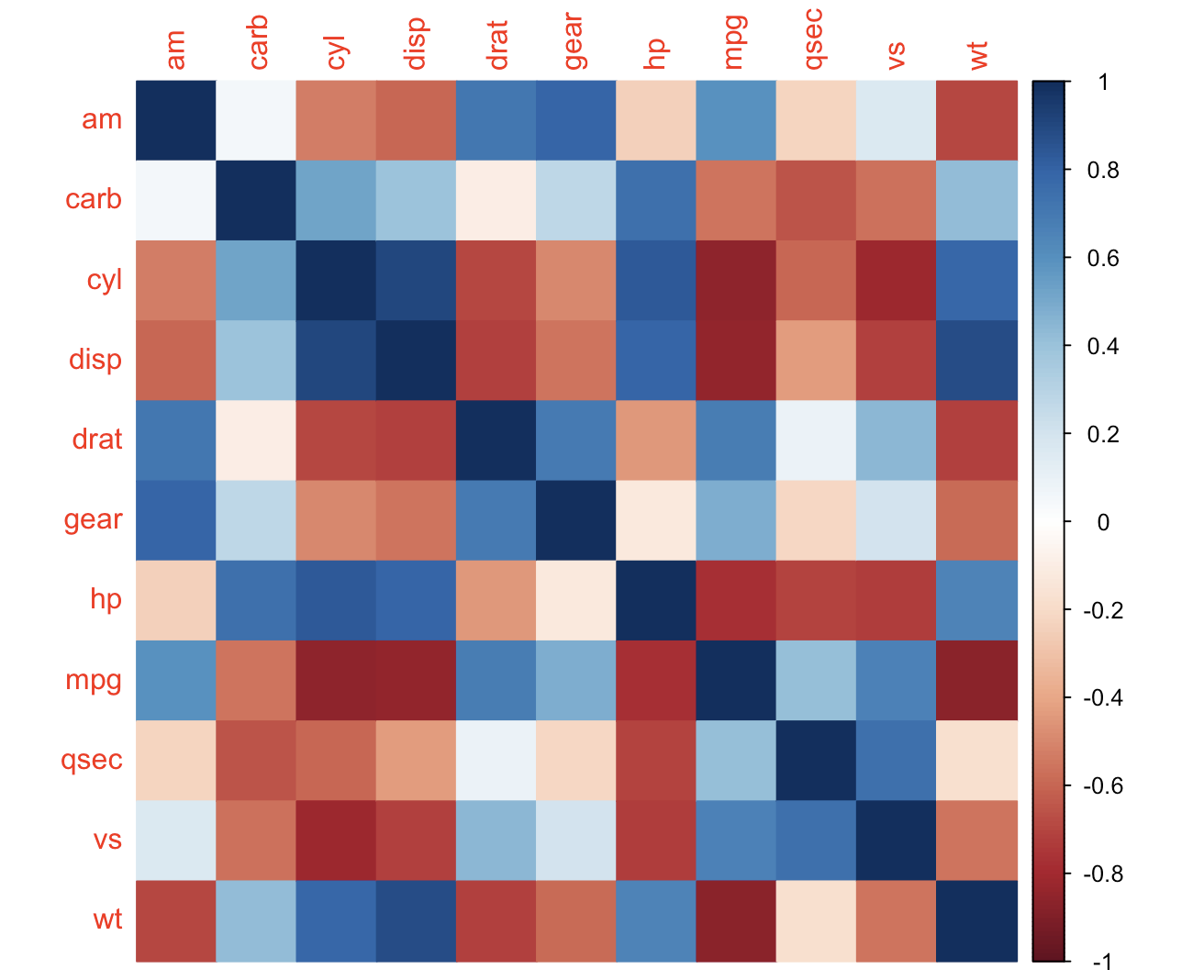
corrplot(M) # by default, method = 'circle'
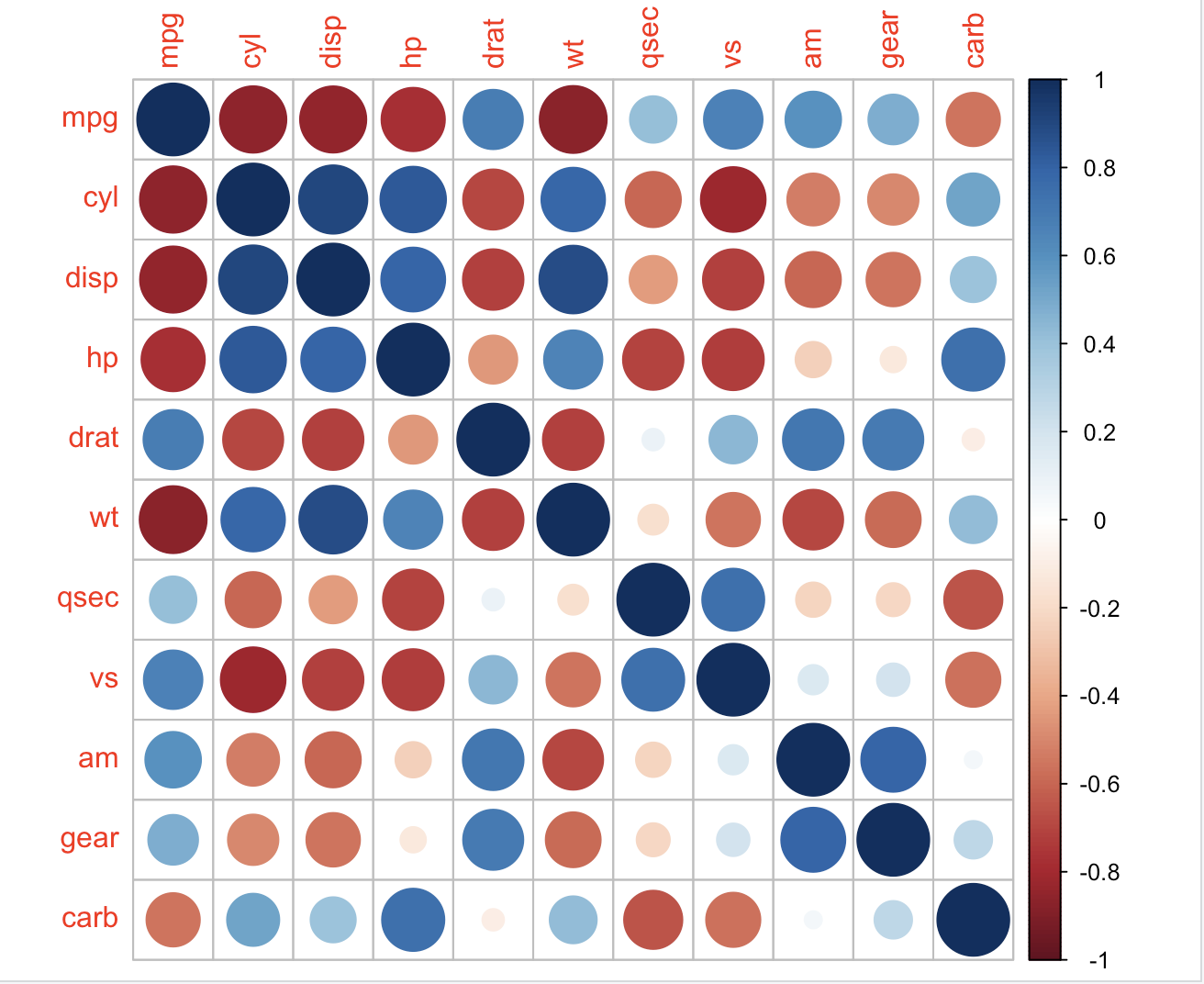
corrplot(M, order = 'AOE') # after 'AOE' reorder
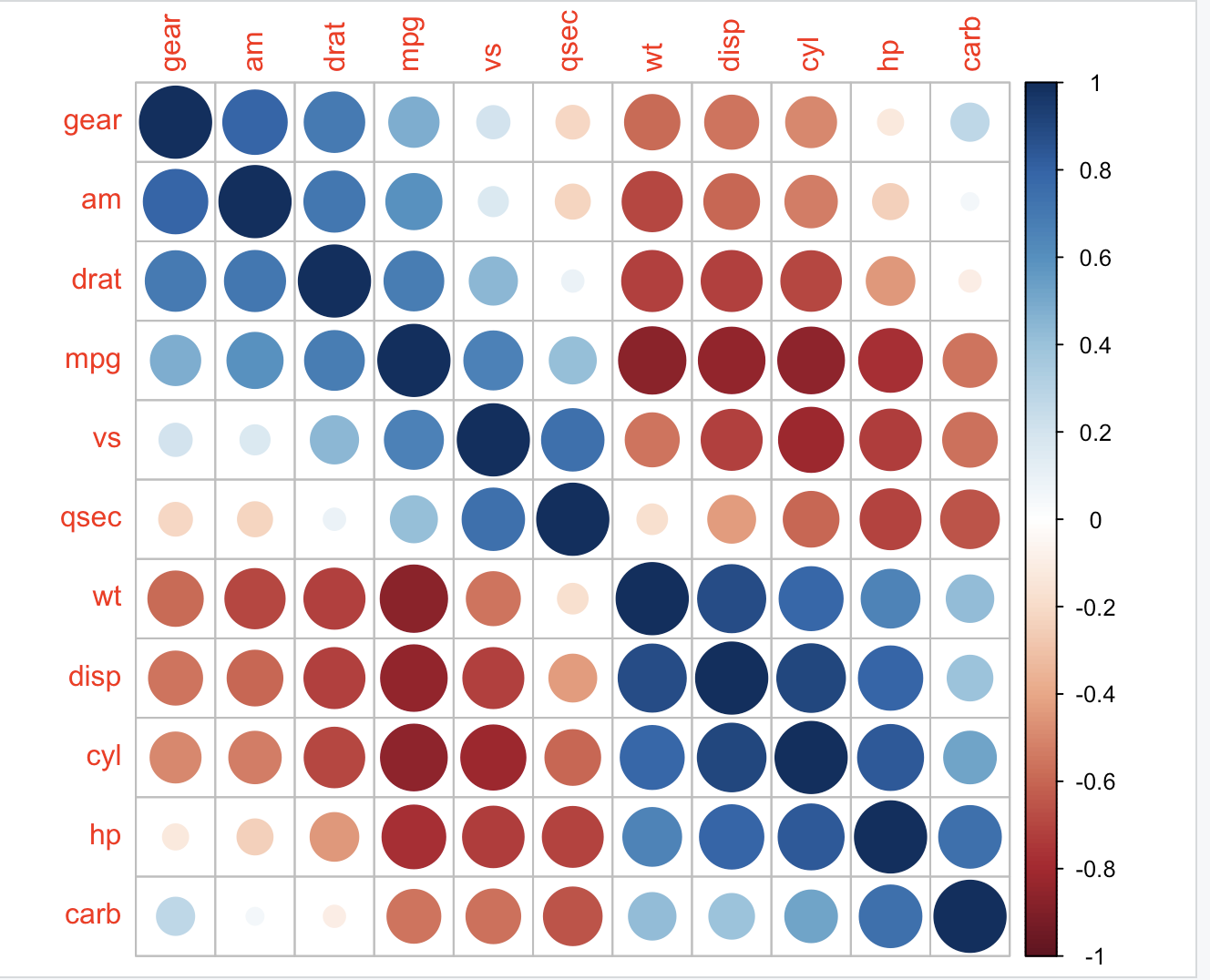
corrplot(M, method = 'shade', order = 'AOE', diag = FALSE)
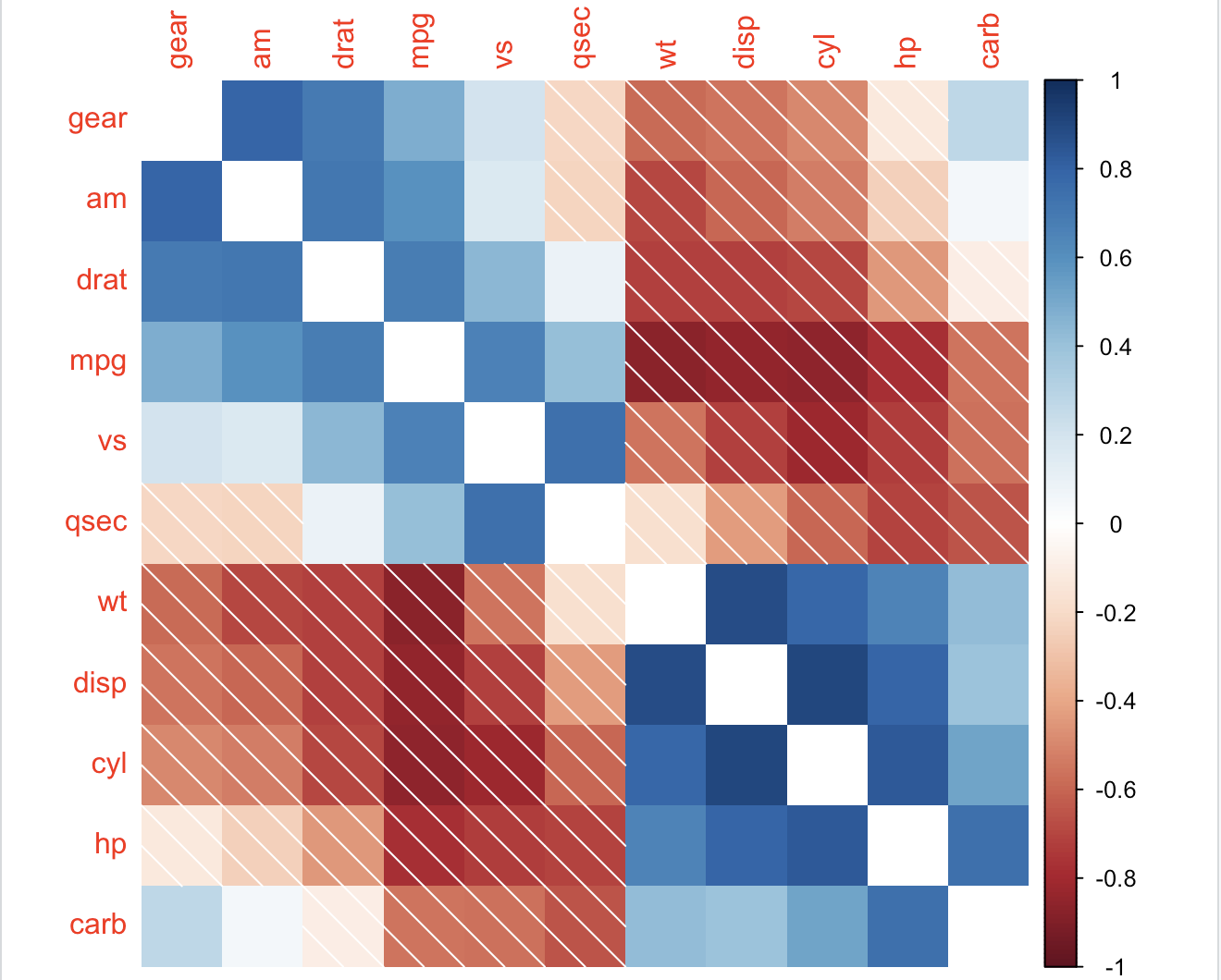
corrplot(M, method = 'square', order = 'FPC', type = 'lower', diag = FALSE)
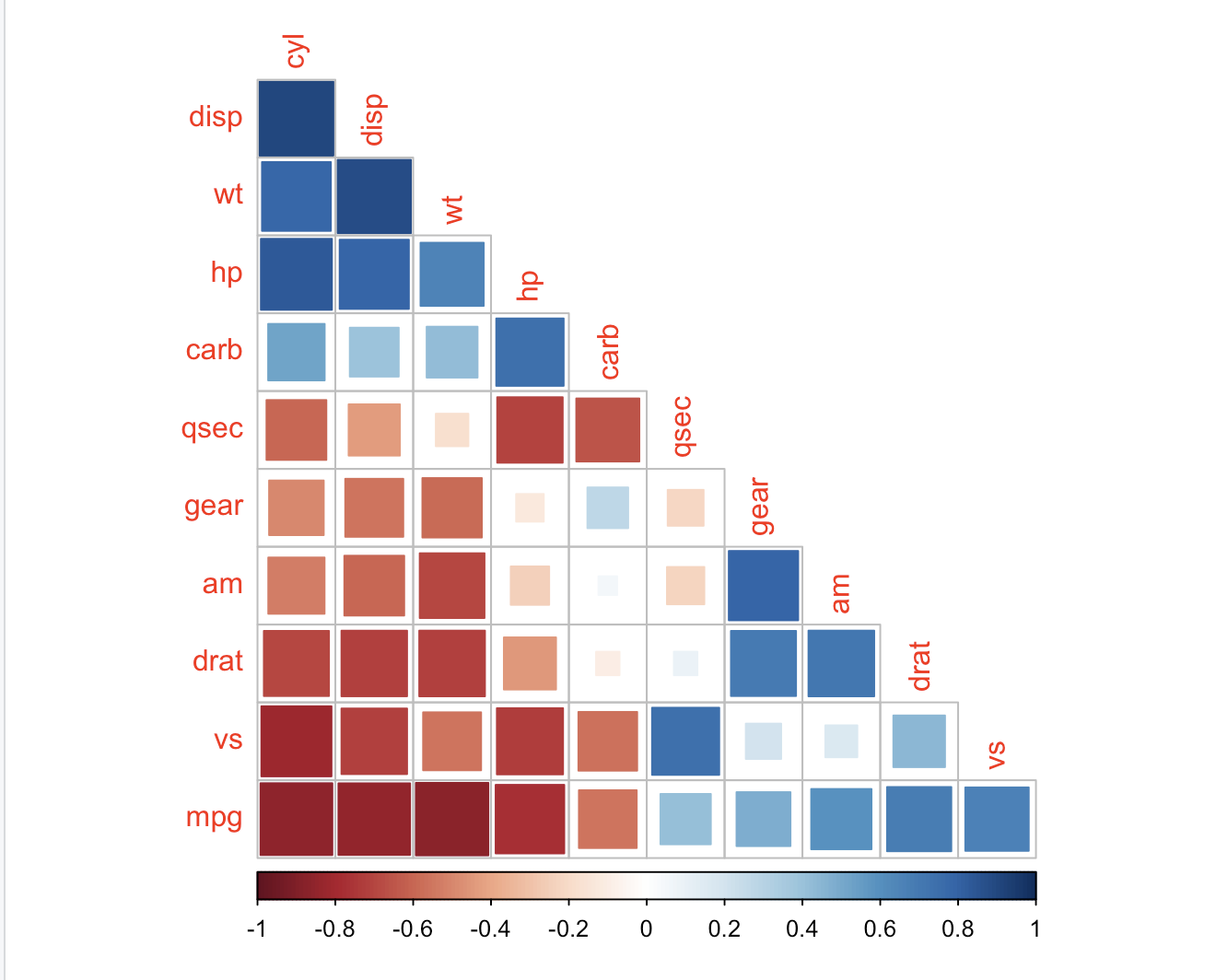
corrplot(M, method = 'ellipse', order = 'AOE', type = 'upper')
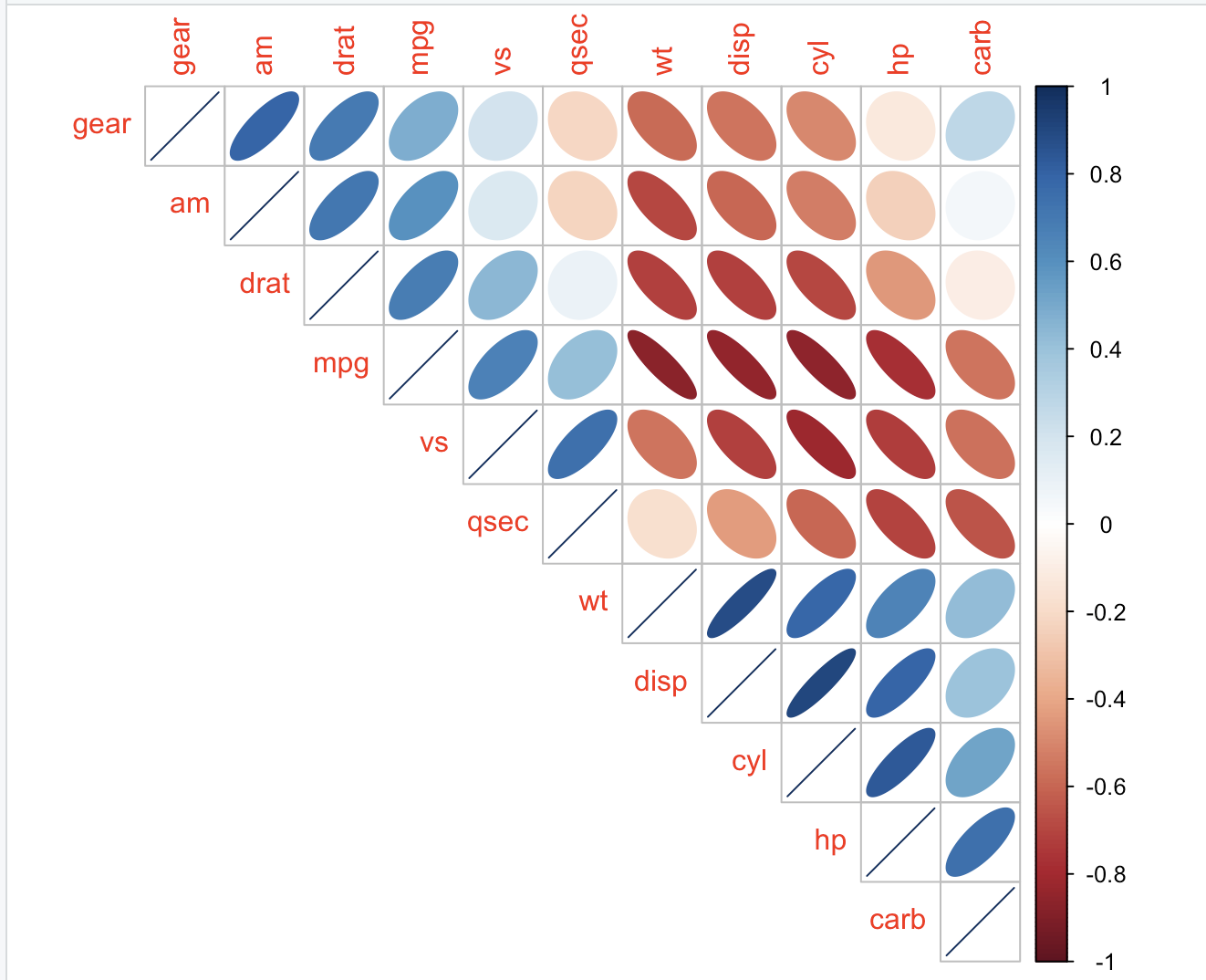
corrplot.mixed(M, order = 'AOE')
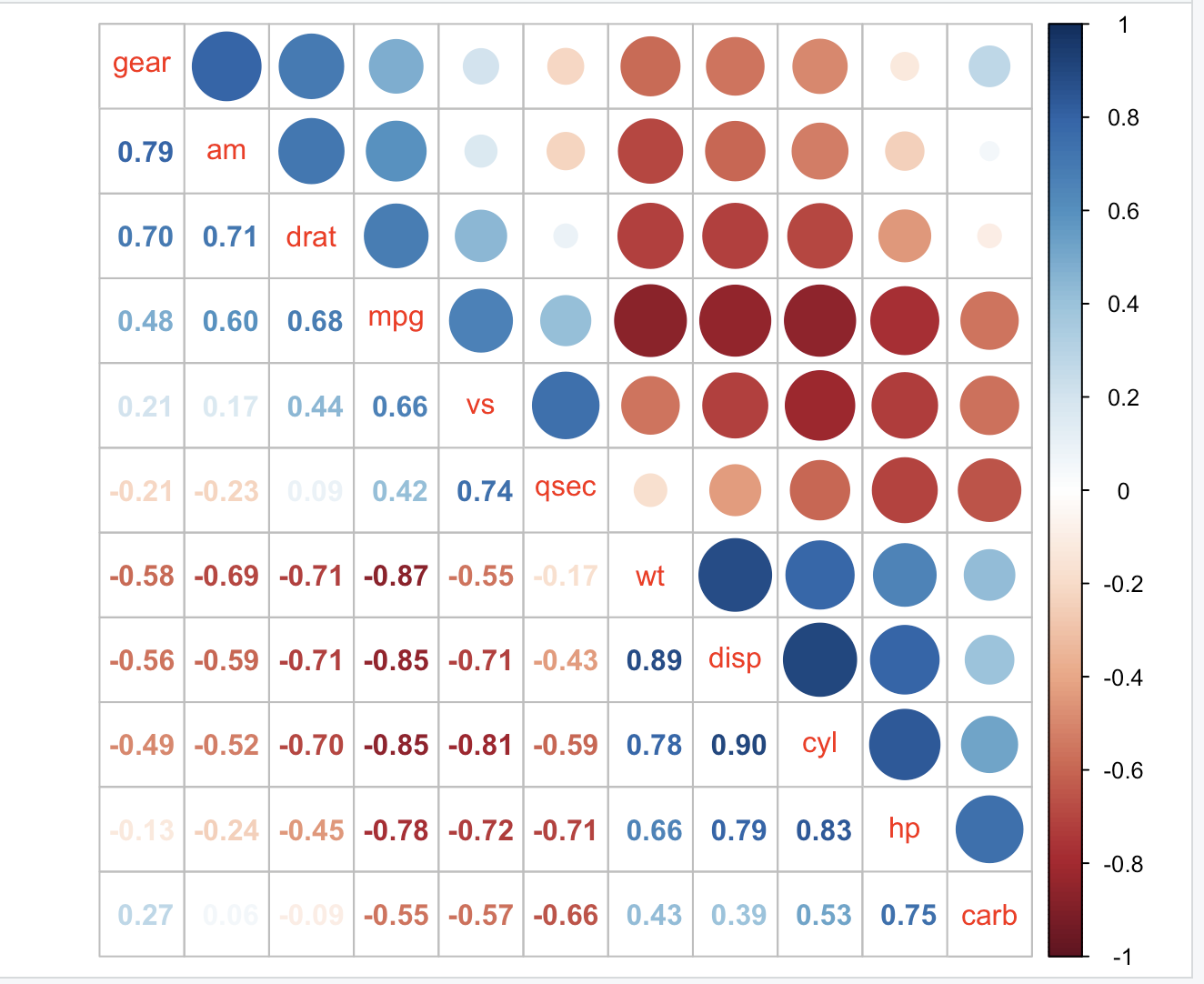
corrplot.mixed(M, lower = 'shade', upper = 'pie', order = 'hclust')
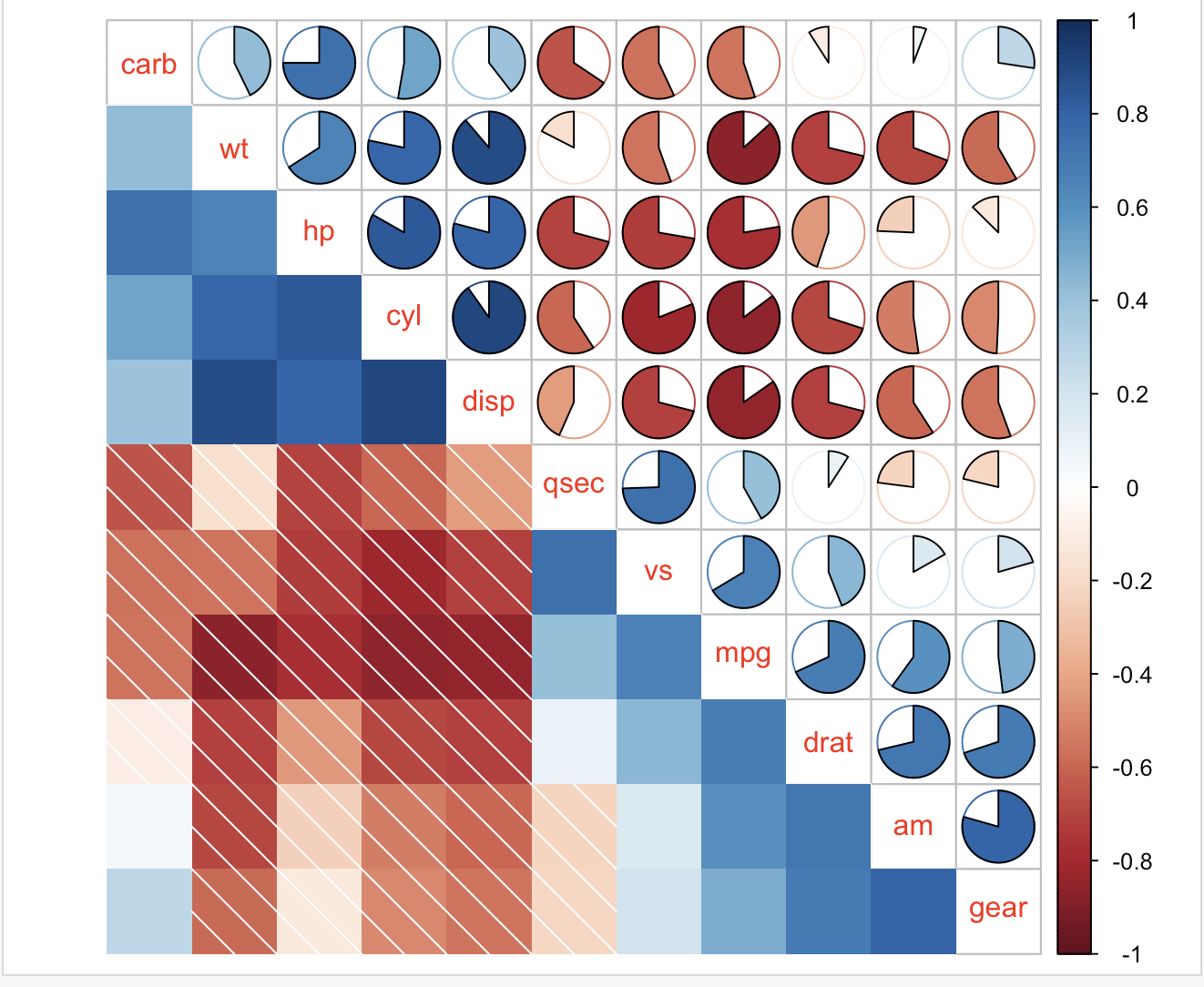
重排序相关矩阵
可以使用四种算法对相关矩阵进行重排序,分别命名为 'AOE'、'FPC'、'hclust' 和 'alphabet',详细说明如下:
-
AOE:特征向量的角度顺序。它根据角度 a_i 的顺序计算,
a_i = { arctan(e_i2/e_i1), 如果 e_i1 > 0; arctan(e_i2/e_i1) + π, 否则。 }
其中 e_1 和 e_2 是相关矩阵的最大两个特征值。详情请参见 Michael Friendly (2002)。
-
FPC:第一主成分顺序。
-
hclust:层次聚类顺序,以及要使用的聚合方法
hclust.method。hclust.method应该是以下之一:ward、ward.D、ward.D2、single、complete、average、mcquitty、median或centroid。 -
alphabet:字母顺序。
您也可以通过函数 corrMatOrder() 来"手动"重排序矩阵。
如果使用 hclust,corrplot() 可以根据层次聚类的结果在相关矩阵的图形周围绘制矩形。
使用hclust时,corrplot()可以根据层次聚类结果在图的周围绘制矩形:
corrplot(M, order = 'hclust', addrect = 2)
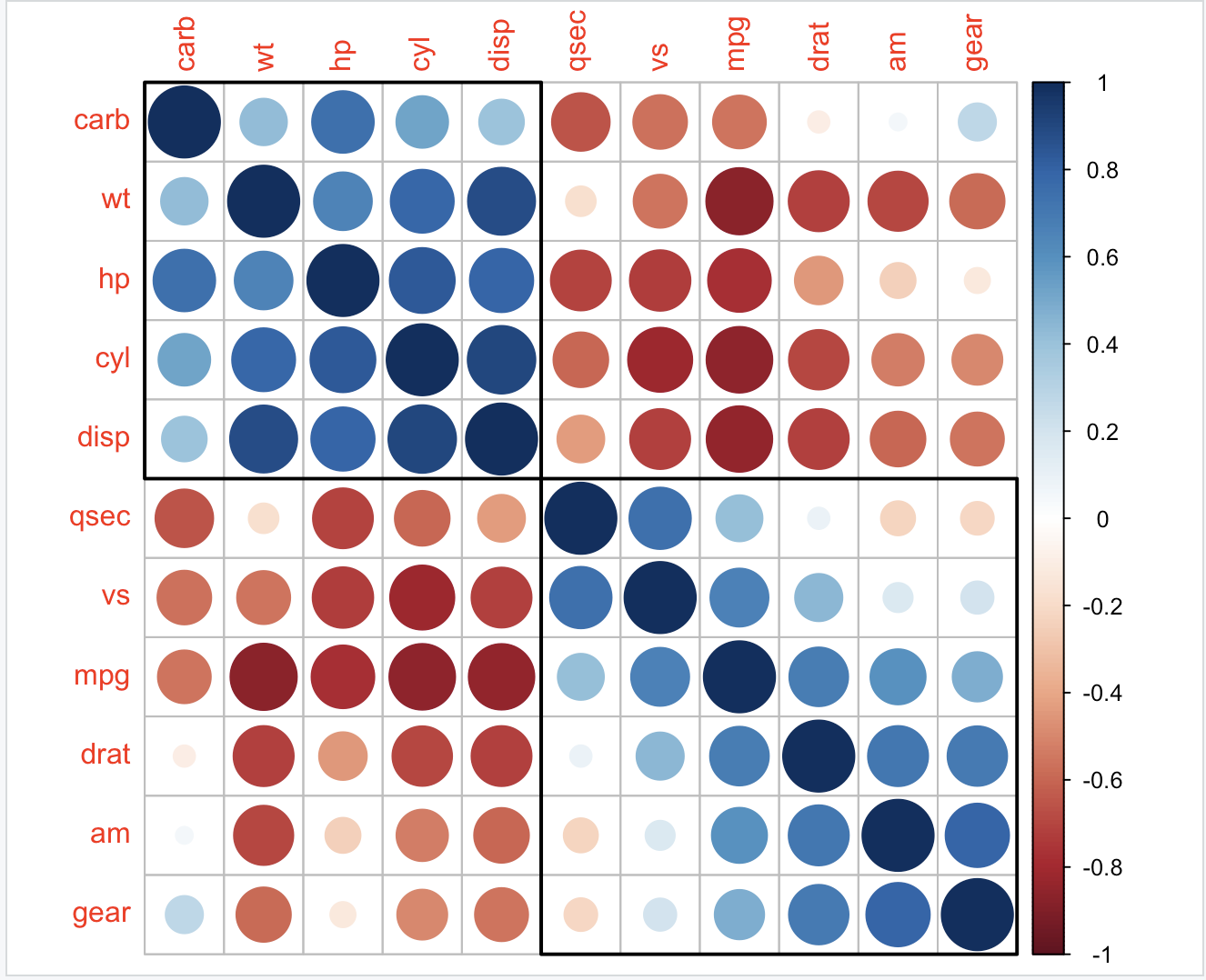
corrplot(M, method = 'square', diag = FALSE, order = 'hclust',
addrect = 3, rect.col = 'blue', rect.lwd = 3, tl.pos = 'd')
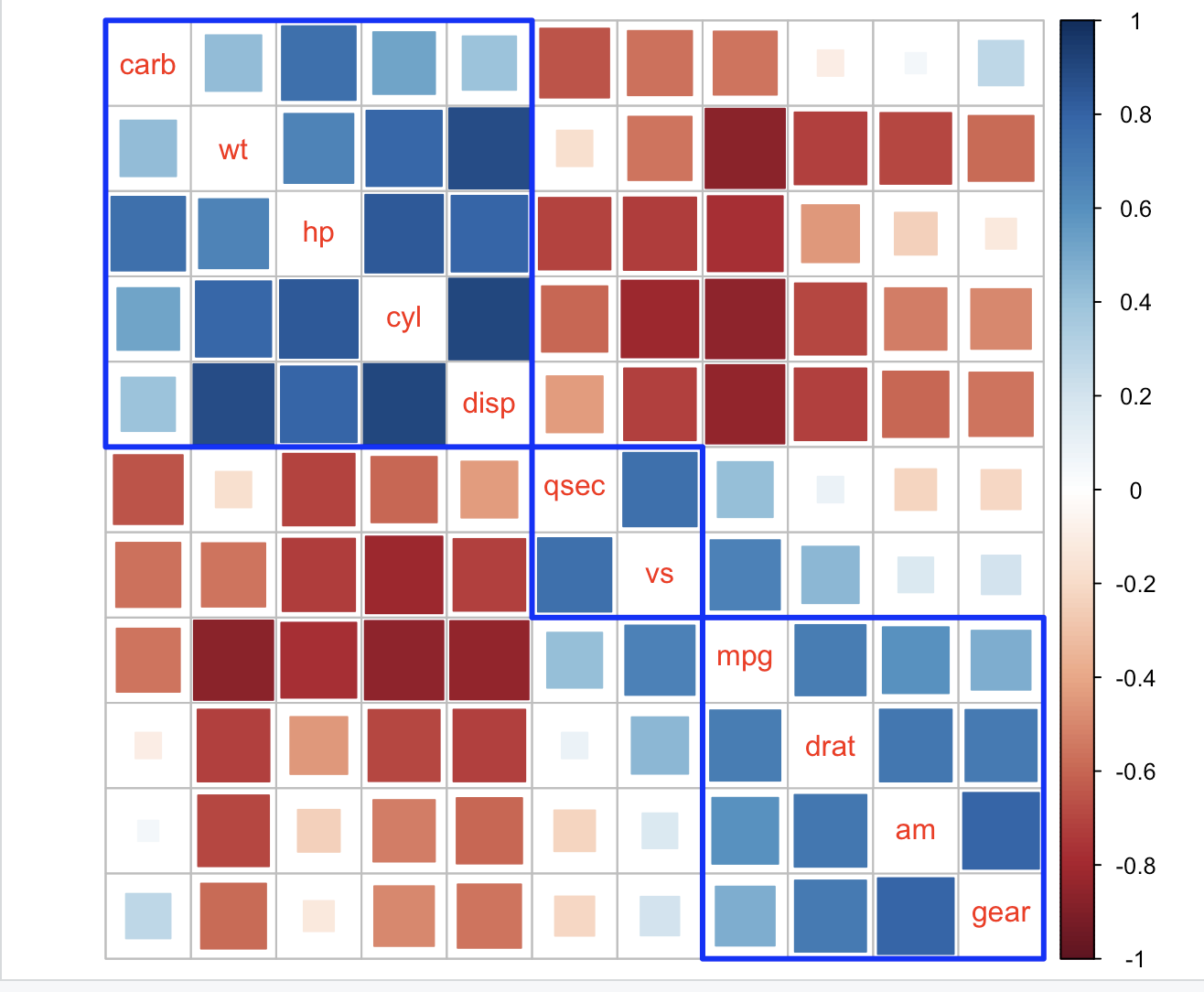
使用seriation包
R 包seriation为对象排序提供了基础设施,实现了几种序列化 / 排序 / 排序技术来重新排序矩阵、不同矩阵和树形图。有关详细信息,请参阅参考部分。我们可以通过序列化包重新排序矩阵,然后对其进行排序。这里有一些例子。
library(seriation)
list_seriation_methods('matrix')
list_seriation_methods('dist')
我们可以通过seriation包重排序矩阵,然后使用corrplot:
data(Zoo)
Z = cor(Zoo[, -c(15, 17)])
dist2order = function(corr, method, ...) {
d_corr = as.dist(1 - corr)
s = seriate(d_corr, method = method, ...)
i = get_order(s)
return(i)
}
seriation中的’PCA_angle’和’HC’方法与corrplot()和corrMatOrder()中的’AOE’和’hclust’相同。
排序后的图表示例:
# Fast Optimal Leaf Ordering for Hierarchical Clustering
i = dist2order(Z, 'OLO')
corrplot(Z[i, i], cl.pos = 'n')
# Quadratic Assignment Problem
i = dist2order(Z, 'QAP_2SUM')
corrplot(Z[i, i], cl.pos = 'n')
# Multidimensional Scaling
i = dist2order(Z, 'MDS_nonmetric')
corrplot(Z[i, i], cl.pos = 'n')
# Simulated annealing
i = dist2order(Z, 'ARSA')
corrplot(Z[i, i], cl.pos = 'n')
# TSP solver
i = dist2order(Z, 'TSP')
corrplot(Z[i, i], cl.pos = 'n')
# Spectral seriation
i = dist2order(Z, 'Spectral')
corrplot(Z[i, i], cl.pos = 'n')
corrRect()可以通过三种方式(参数index、name和namesMat)向图中添加矩形。我们可以使用管道操作符(magrittr中的%>%或R 4.1.0+中的|>)以提高便利性:
library(magrittr)
# Rank-two ellipse seriation, use index parameter
i = dist2order(Z, 'R2E')
corrplot(Z[i, i], cl.pos = 'n') %>% corrRect(c(1, 9, 15))
# Use name parameter
# Since R 4.1.0, this one-line code works:
# corrplot(M, order = 'AOE') |> corrRect(name = c('gear', 'wt', 'carb'))
corrplot(Z, order = 'AOE') %>%
corrRect(name = c('tail', 'airborne', 'venomous', 'predator'))
# Use namesMat parameter
r = rbind(c('eggs', 'catsize', 'airborne', 'milk'),
c('catsize', 'eggs', 'milk', 'airborne'))
corrplot(Z, order = 'hclust') %>% corrRect(namesMat = r)
更改颜色谱、颜色图例和文本图例
我们可以从 COL1() 和 COL2() 获取序列色和发散色。这些颜色调色板借鉴自 RColorBrewer 包。
注意:从 COL2() 获取的中间颜色固定为 ‘#FFFFFF’(白色),因此我们可以用白色来可视化值为 0 的元素。
COL1():获取序列色,适用于可视化非负或非正矩阵(例如范围在 [0, 20]、[-100, -10] 或 [100, 500] 的矩阵)。COL2():获取发散色,适用于可视化元素部分为正部分为负的矩阵(例如范围在 [-1, 1] 或 [-20, 100] 的相关矩阵)。
相关图的颜色可以通过 corrplot() 中的 col 进行自定义。它们在 col.lim 区间内均匀分布。
col:向量,图形符号的颜色。它们在col.lim区间内均匀分布。默认情况下,- 如果
is.corr为TRUE,col将为COL2('RdBu', 200) - 如果
is.corr为FALSE,- 且
corr是非负或非正矩阵,col将为COL1('YlOrBr', 200); - 否则(元素部分为正部分为负),
col将为COL2('RdBu', 200)
- 且
- 如果
col.lim:通过col分配颜色的限制区间 (x1, x2)。默认情况下,- 当
is.corr为TRUE时,col.lim将为c(-1, 1) - 当
is.corr为FALSE时,col.lim将为c(min(corr), max(corr)) - 注意:如果在
is.corr为TRUE时设置col.lim,分配的颜色仍然在 [-1, 1] 内均匀分布,它只影响颜色图例上的显示。
- 当
is.corr:逻辑值,输入矩阵是否为相关矩阵。默认值为TRUE。我们可以通过设置is.corr = FALSE来可视化非相关矩阵。
下面显示了来自 COL2() 的所有发散色和来自 COL1() 的序列色。
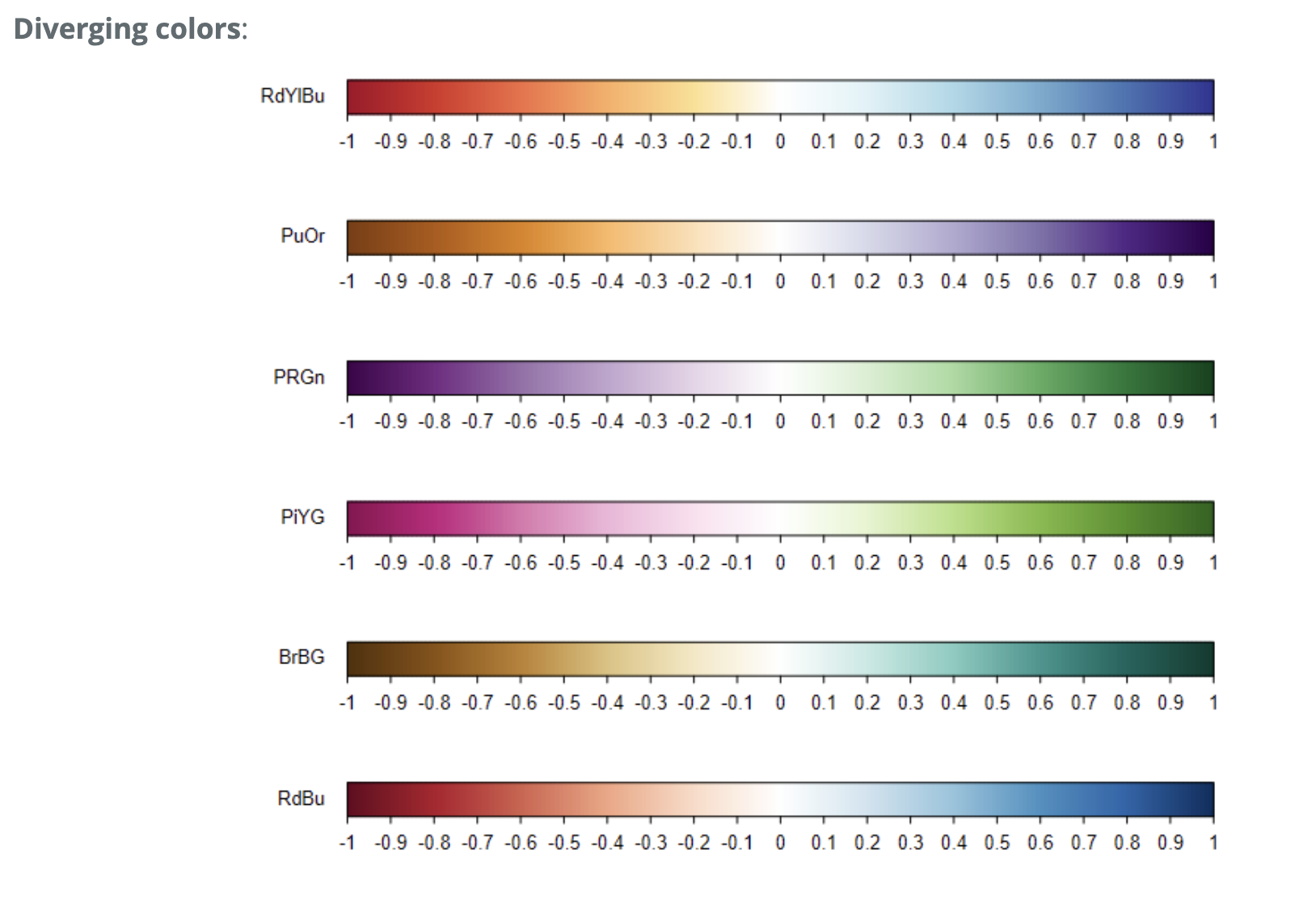
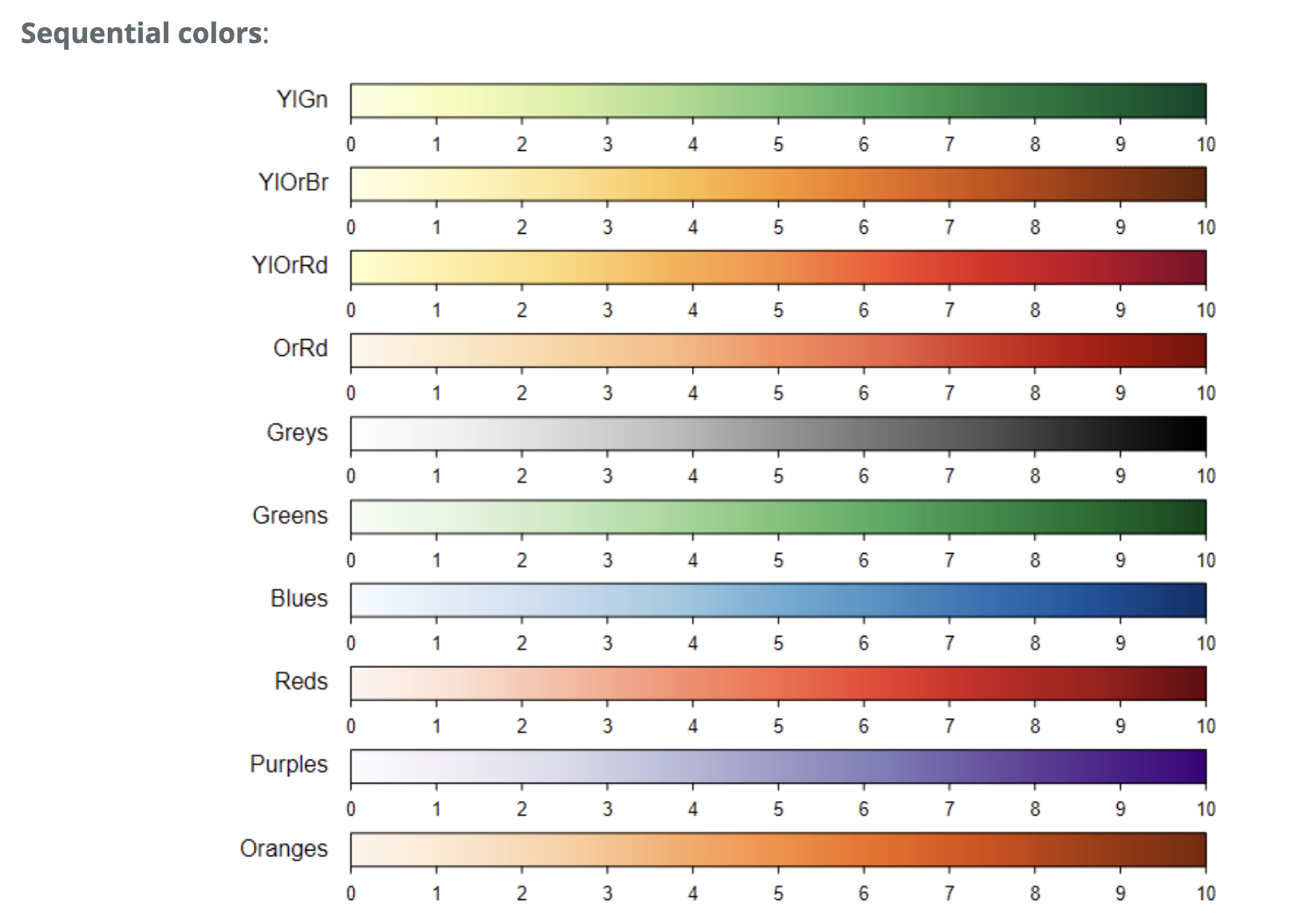
COL1() 和 COL2() 的用法:
COL1(sequential = c("Oranges", "Purples", "Reds", "Blues", "Greens",
"Greys", "OrRd", "YlOrRd", "YlOrBr", "YlGn"), n = 200)
COL2(diverging = c("RdBu", "BrBG", "PiYG", "PRGn", "PuOr", "RdYlBu"), n = 200)
此外,colorRampPalette() 函数对于生成颜色谱非常方便。
cl.* 参数组用于颜色图例。常用的有:
cl.pos用于颜色标签的位置。它是字符或逻辑值。如果是字符,它必须是以下之一:‘r’(表示右侧,当type='upper'或'full'时为默认值),‘b’(表示底部,当type='lower'时为默认值)或 ‘n’(表示不绘制颜色标签)。cl.ratio用于调整颜色图例的宽度,建议使用 0.1~0.2。
tl.* 参数组用于文本图例。常用的有:
tl.pos用于文本标签的位置。它是字符或逻辑值。如果是字符,它必须是以下之一:‘lt’、‘ld’、‘td’、‘d’、‘l’ 或 ‘n’。‘lt’(当type='full'时为默认值)表示左侧和顶部,‘ld’(当type='lower'时为默认值)表示左侧和对角线,‘td’(当type='upper'时为默认值)表示顶部和对角线(接近),‘d’ 表示对角线,‘l’ 表示左侧,‘n’ 表示不添加文本标签。tl.cex用于文本标签(变量名)的大小。tl.srt用于文本标签字符串的旋转角度(以度为单位)。
corrplot(M, order = 'AOE', col = COL2('RdBu', 10))
corrplot(M, order = 'AOE', addCoef.col = 'black', tl.pos = 'd',
cl.pos = 'n', col = COL2('PiYG'))
corrplot(M, method = 'square', order = 'AOE', addCoef.col = 'black', tl.pos = 'd',
cl.pos = 'n', col = COL2('BrBG'))
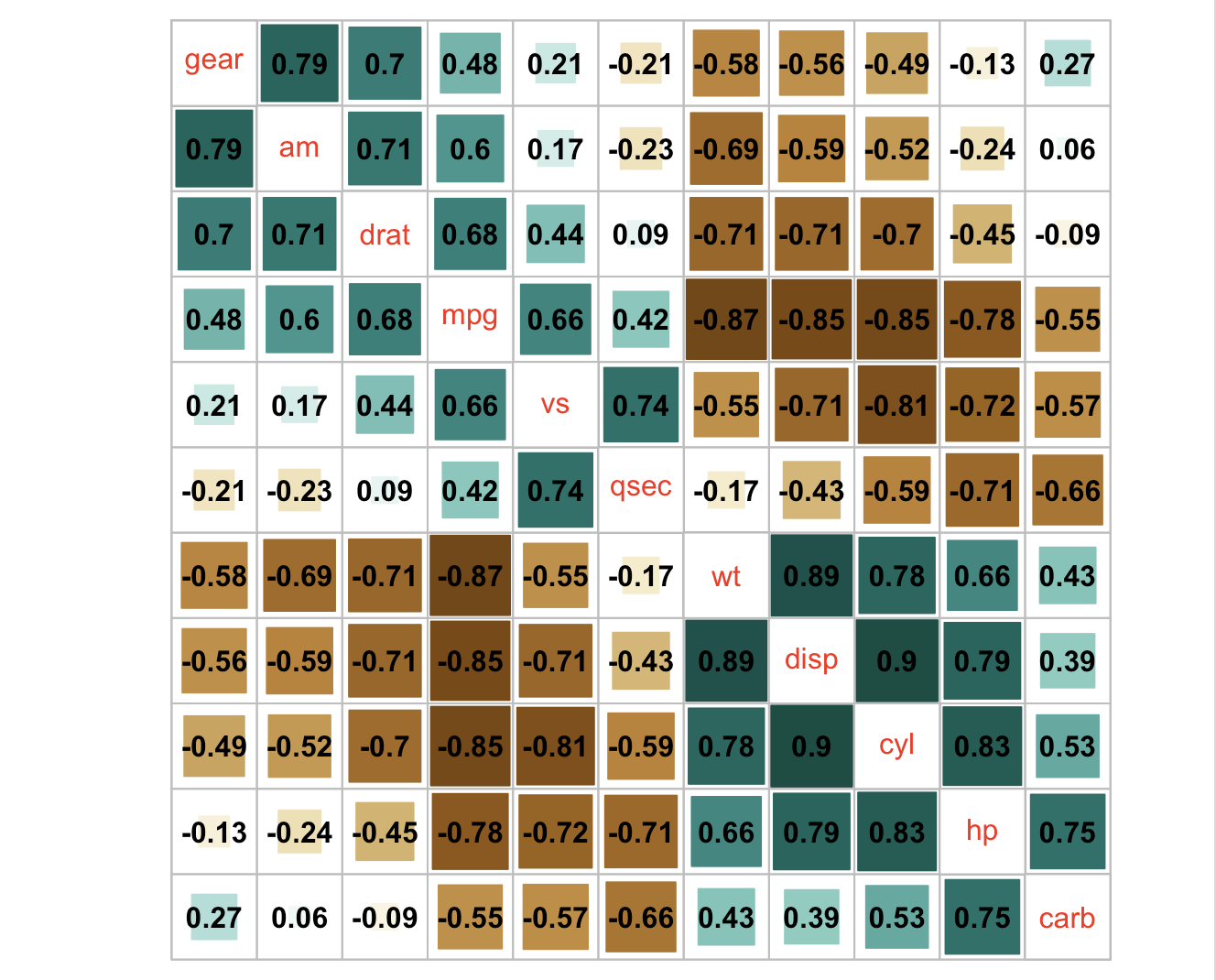
## bottom color legend, diagonal text legend, rotate text label
corrplot(M, order = 'AOE', cl.pos = 'b', tl.pos = 'd',
col = COL2('PRGn'), diag = FALSE)
## text labels rotated 45 degrees and wider color legend with numbers right aligned
corrplot(M, type = 'lower', order = 'hclust', tl.col = 'black',
cl.ratio = 0.2, tl.srt = 45, col = COL2('PuOr', 10))
## remove color legend, text legend and principal diagonal glyph
corrplot(M, order = 'AOE', cl.pos = 'n', tl.pos = 'n',
col = c('white', 'black'), bg = 'gold2')
可视化非相关矩阵、NA 值和数学标签
我们可以通过设置 is.corr=FALSE 来可视化非相关矩阵,并通过 col.lim 分配颜色。如果矩阵既有正值又有负值,矩阵转换会保持每个值的正负性。
如果您的矩阵是矩形的,您可以通过 win.asp 参数调整纵横比,使矩阵呈现为正方形。
## matrix in [20, 26], grid.col
N1 = matrix(runif(80, 20, 26), 8)
corrplot(N1, is.corr = FALSE, col.lim = c(20, 30), method = 'color', tl.pos = 'n',
col = COL1('YlGn'), cl.pos = 'b', addgrid.col = 'white', addCoef.col = 'grey50')
## matrix in [-15, 10]
N2 = matrix(runif(80, -15, 10), 8)
## using sequential colors, transKeepSign = FALSE
corrplot(N2, is.corr = FALSE, transKeepSign = FALSE, method = 'color', col.lim = c(-15, 10),
tl.pos = 'n', col = COL1('YlGn'), cl.pos = 'b', addCoef.col = 'grey50')
## using diverging colors, transKeepSign = TRUE (default)
corrplot(N2, is.corr = FALSE, col.lim = c(-15, 10),
tl.pos = 'n', col = COL2('PiYG'), cl.pos = 'b', addCoef.col = 'grey50')
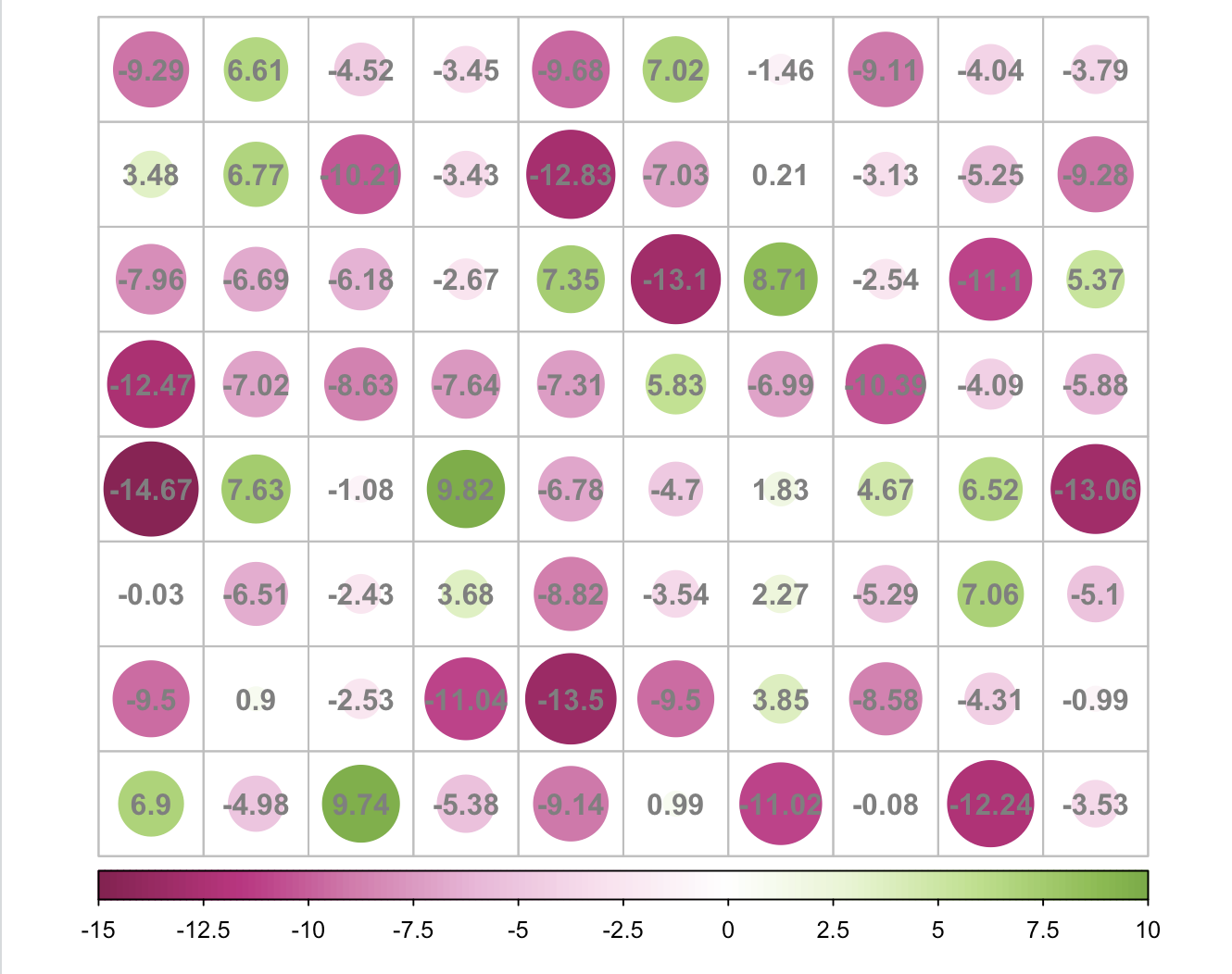
## using diverging colors
corrplot(N2, is.corr = FALSE, method = 'color', col.lim = c(-15, 10), tl.pos = 'n',
col = COL2('PiYG'), cl.pos = 'b', addCoef.col = 'grey50')
注意:当 is.corr 为 TRUE 时,col.lim 只影响颜色图例。如果您更改它,相关矩阵图上的颜色仍然是根据 c(-1, 1) 分配的。
# when is.corr=TRUE, col.lim only affect the color legend display
corrplot(M/2)
corrplot(M/2, col.lim=c(-0.5, 0.5))
默认情况下,corrplot 将 NA 值渲染为字符 ‘?’。使用 na.label 参数,可以使用不同的值(最多支持两个字符)。
从 0.78 版本开始,可以在变量名中使用 plotmath 表达式。要激活 plotmath 渲染,请在标签前加上 ‘$’。
M2 = M
diag(M2) = NA
colnames(M2) = rep(c('$alpha+beta', '$alpha[0]', '$alpha[beta]'),
c(4, 4, 3))
rownames(M2) = rep(c('$Sigma[i]^n', '$sigma', '$alpha[0]^100', '$alpha[beta]'),
c(2, 4, 2, 3))
corrplot(10*abs(M2), is.corr = FALSE, col.lim = c(0, 10), tl.cex = 1.5)
可视化 p 值和置信区间
corrplot() 也可以在相关矩阵图上可视化 p 值和置信区间。以下是一些重要参数。
关于 p 值:
p.mat是 p 值矩阵,如果为NULL,则参数sig.level、insig、pch、pch.col、pch.cex无效。sig.level是显著性水平,默认值为 0.05。如果p-mat中的 p 值大于sig.level,则相应的相关系数被视为不显著。如果insig是 ‘label_sig’,sig.level可以是一个递增的显著性水平向量,在这种情况下,pch将用于最高 p 值区间,并多次使用(例如 ‘‘、’‘、’’)用于每个较低的 p 值区间。insig字符,指定不显著的相关系数,‘pch’(默认),‘p-value’,‘blank’,‘n’ 或 ‘label_sig’。如果为 ‘blank’,擦除相应的图形符号;如果为 ‘p-value’,添加 p 值到相应的图形符号;如果为 ‘pch’,在相应的图形符号上添加字符(详见pch);如果为 ‘n’,不采取任何措施;如果为 ‘label_sig’,用pch标记显著的相关性(参见sig.level)。pch用于在不显著相关系数的图形符号上添加字符(仅当insig为 ‘pch’ 时有效)。参见?par。
关于置信区间:
plotCI是用于绘制置信区间的方法的字符。如果为 ‘n’,不绘制置信区间。如果为 ‘rect’,绘制矩形,其上边表示上界,下边表示下界。lowCI.mat是置信区间下界的矩阵。uppCI.mat是置信区间上界的矩阵。
我们可以通过 cor.mtest() 获取 p 值矩阵和置信区间矩阵,它返回一个包含以下内容的列表:
p是 p 值矩阵。lowCI是置信区间下界矩阵。uppCI是置信区间上界矩阵。
testRes = cor.mtest(mtcars, conf.level = 0.95)
## specialized the insignificant value according to the significant level
corrplot(M, p.mat = testRes$p, sig.level = 0.10, order = 'hclust', addrect = 2)
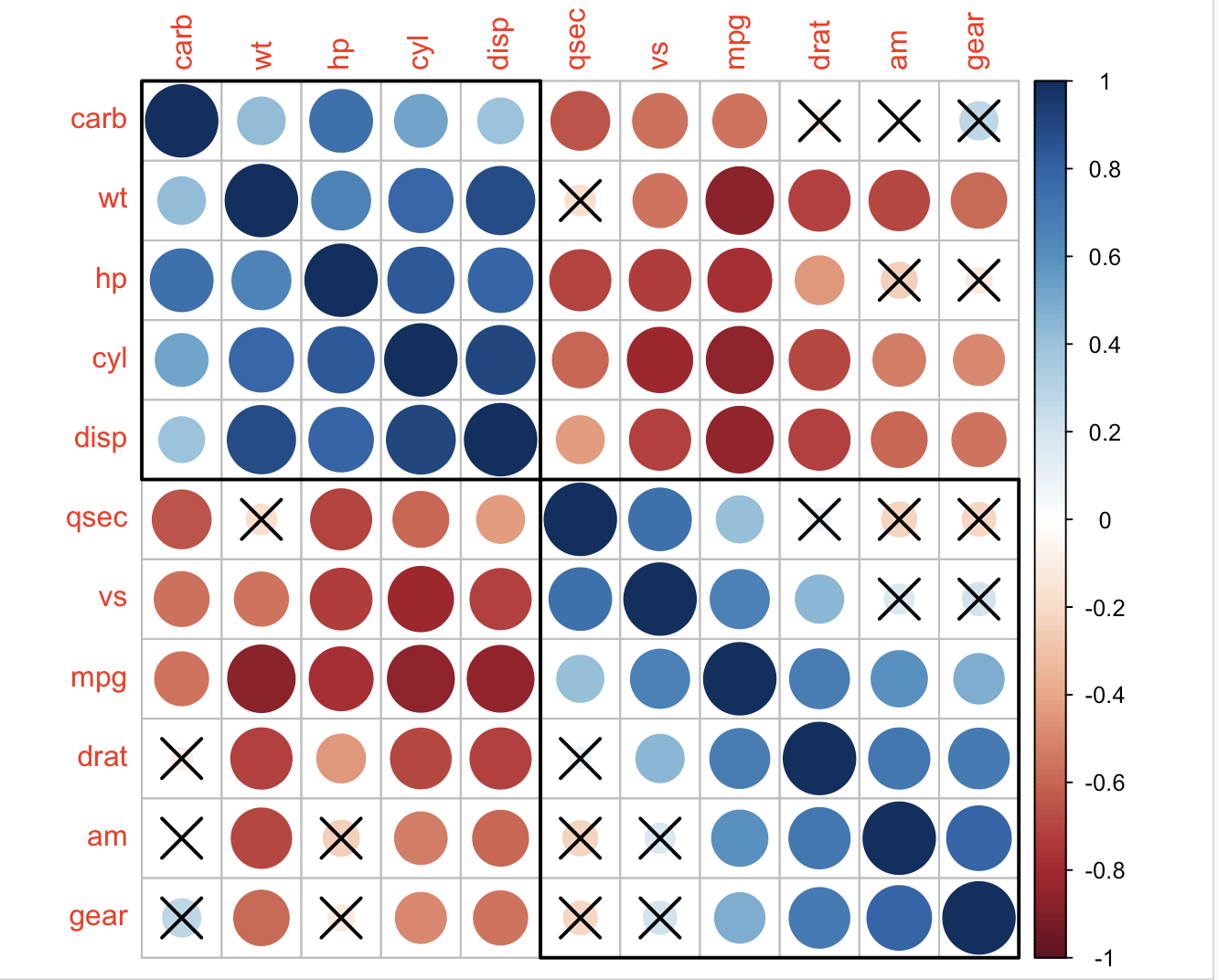
## leave blank on non-significant coefficient
## add significant correlation coefficients
corrplot(M, p.mat = testRes$p, method = 'circle', type = 'lower', insig='blank',
addCoef.col ='black', number.cex = 0.8, order = 'AOE', diag=FALSE)
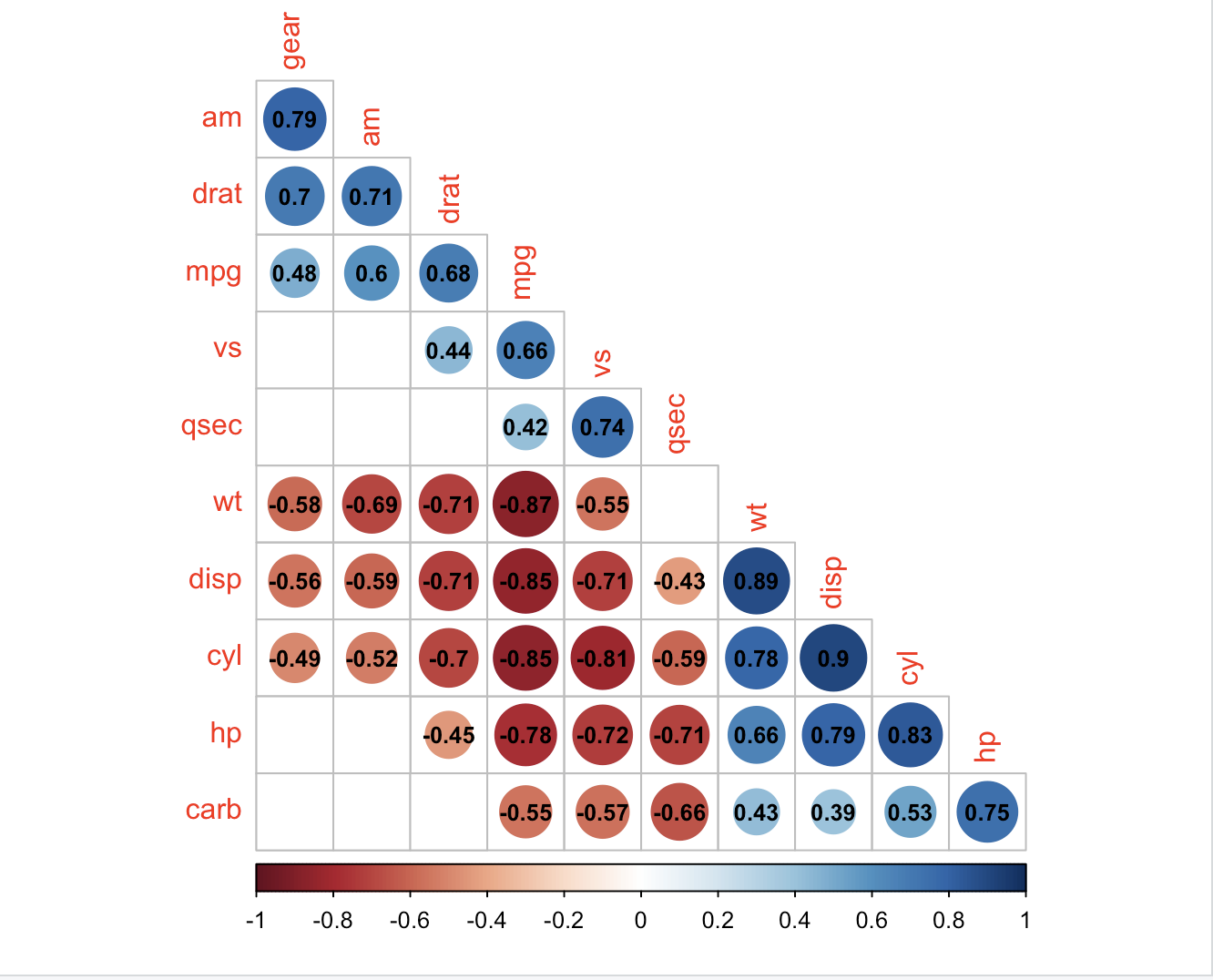
## leave blank on non-significant coefficient
## add all correlation coefficients
corrplot(M, p.mat = testRes$p, method = 'circle', type = 'lower', insig='blank',
order = 'AOE', diag = FALSE)$corrPos -> p1
text(p1$x, p1$y, round(p1$corr, 2))
## add p-values on no significant coefficients
corrplot(M, p.mat = testRes$p, insig = 'p-value')
## add all p-values
corrplot(M, p.mat = testRes$p, insig = 'p-value', sig.level = -1)
## add significant level stars
corrplot(M, p.mat = testRes$p, method = 'color', diag = FALSE, type = 'upper',
sig.level = c(0.001, 0.01, 0.05), pch.cex = 0.9,
insig = 'label_sig', pch.col = 'grey20', order = 'AOE')
## add significant level stars and cluster rectangles
corrplot(M, p.mat = testRes$p, tl.pos = 'd', order = 'hclust', addrect = 2,
insig = 'label_sig', sig.level = c(0.001, 0.01, 0.05),
pch.cex = 0.9, pch.col = 'grey20')
可视化置信区间。
# Visualize confidence interval
corrplot(M, lowCI = testRes$lowCI, uppCI = testRes$uppCI, order = 'hclust',
tl.pos = 'd', rect.col = 'navy', plotC = 'rect', cl.pos = 'n')
# Visualize confidence interval and cross the significant coefficients
corrplot(M, p.mat = testRes$p, lowCI = testRes$lowCI, uppCI = testRes$uppCI,
addrect = 3, rect.col = 'navy', plotC = 'rect', cl.pos = 'n')
参考文献
-
Michael Friendly (2002). Corrgrams: Exploratory displays for correlation matrices. The American Statistician, 56, 316–324.
-
D.J. Murdoch, E.D. Chow (1996). A graphical display of large correlation matrices. The American Statistician, 50, 178–180.
-
Michael Hahsler, Christian Buchta and Kurt Hornik (2020). seriation: Infrastructure for Ordering Objects Using Seriation. R package version 1.2-9. https://CRAN.R-project.org/package=seriation
-
Hahsler M, Hornik K, Buchta C (2008). “Getting things in order: An introduction to the R package seriation.” Journal of Statistical Software, 25(3), 1-34. ISSN 1548-7660, doi: 10.18637/jss.v025.i03IF:
5.4 Q1 (URL: ), <URL: https://www.jstatsoft.org/v25/i03/>.

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









