







 文章介绍了如何利用Python的requests库调用百度翻译的API进行单个单词或连续输入的多词翻译,并展示了如何通过while循环实现连续输入的翻译功能。
文章介绍了如何利用Python的requests库调用百度翻译的API进行单个单词或连续输入的多词翻译,并展示了如何通过while循环实现连续输入的翻译功能。

首先找到网址
百度翻译-200种语言互译、沟通全世界! (baidu.com)
然后检查
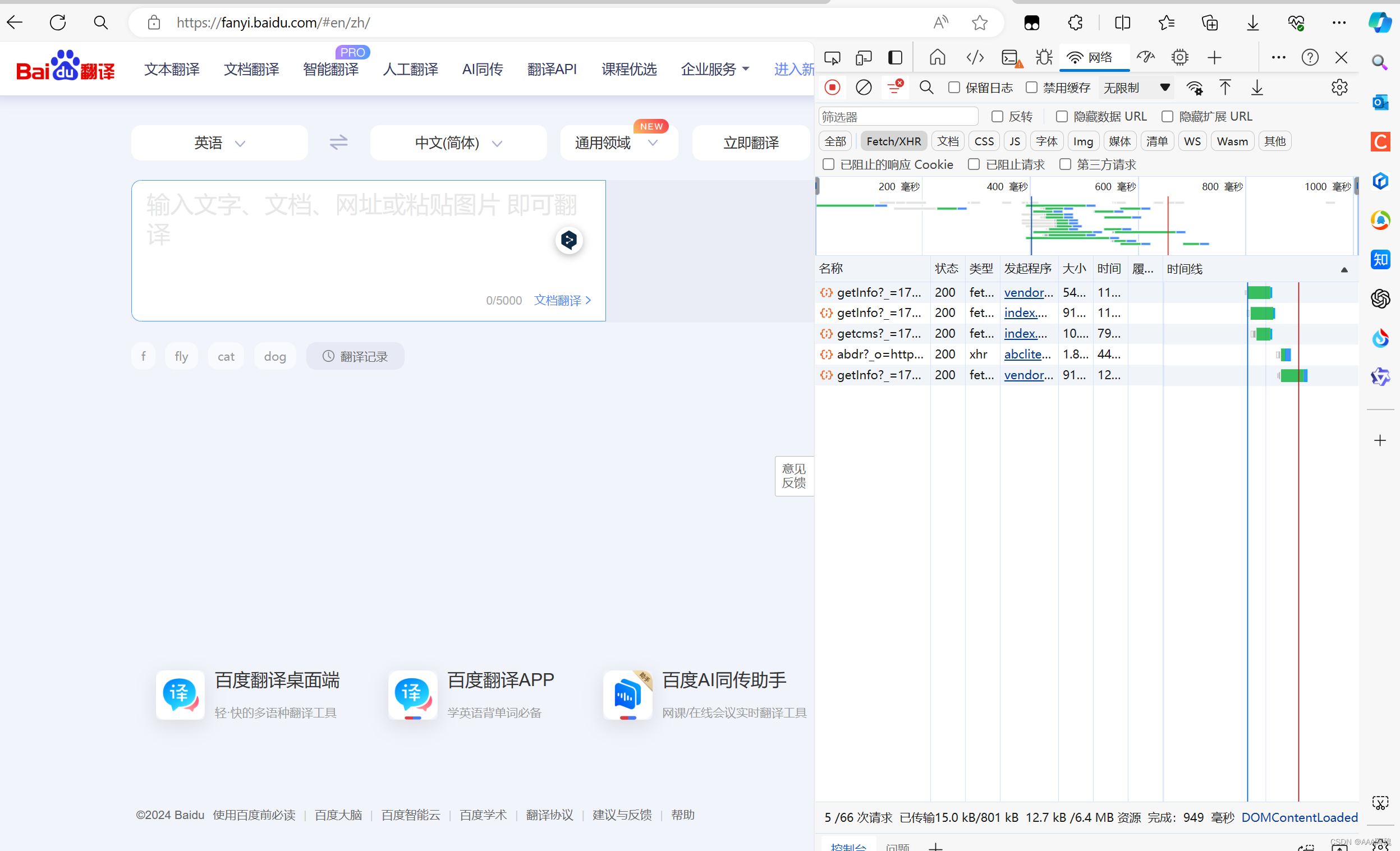
猜测

中的en为英语的缩写,zh为中文的缩写
输入目标单词
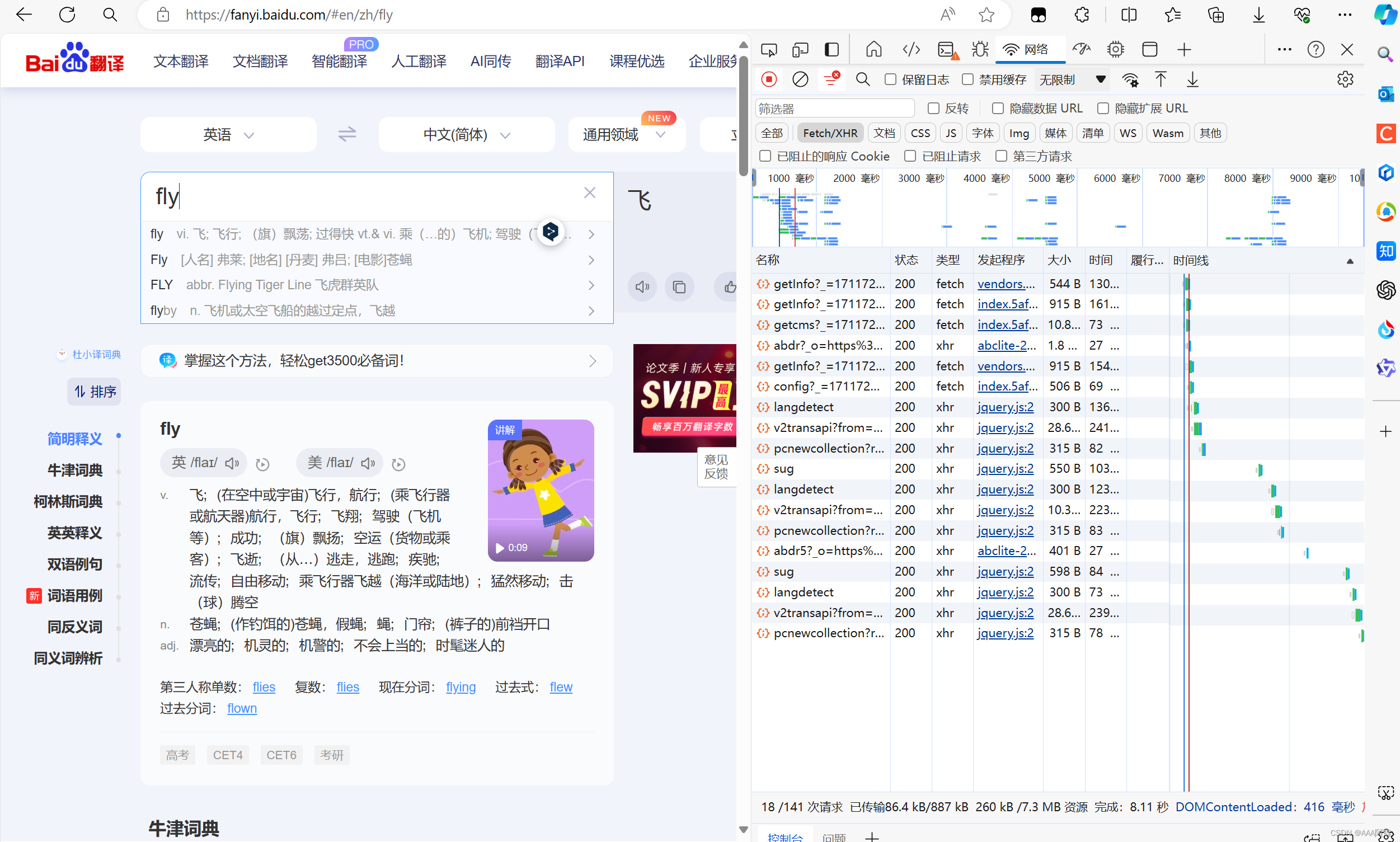
观察右侧的变化
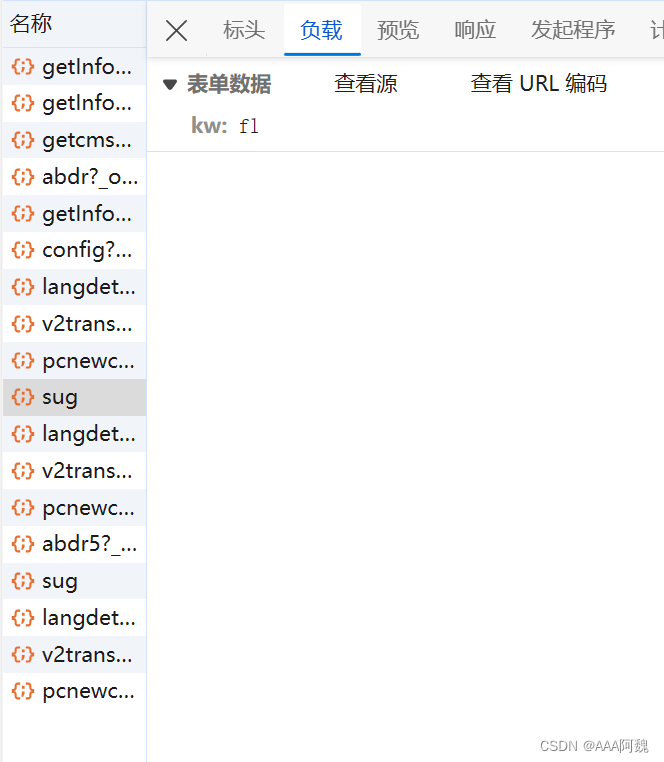
可以发现第二个sug的负载为fl,第三个sug的负载为fly
将fly换成cat仍然是这个规律

不难发现我们要输入的数据样式即为kw:words;
这是请求url等
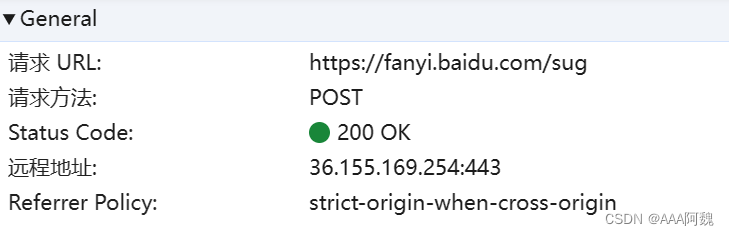

开始写代码
import requests
#目标url
url='https://fanyi.baidu.com/sug'
#伪装
headers={
'User-Agent':'Mozilla/5.0'
}
words=input("请输入要翻译的内容:")
#数据格式
data={
'kw':words
}
#发起请求1
resp=requests.post(url=url,headers=headers,data=data)
#解析成json格式
result=resp.json()
print(result)
这个只能一次书一个单词进行翻译
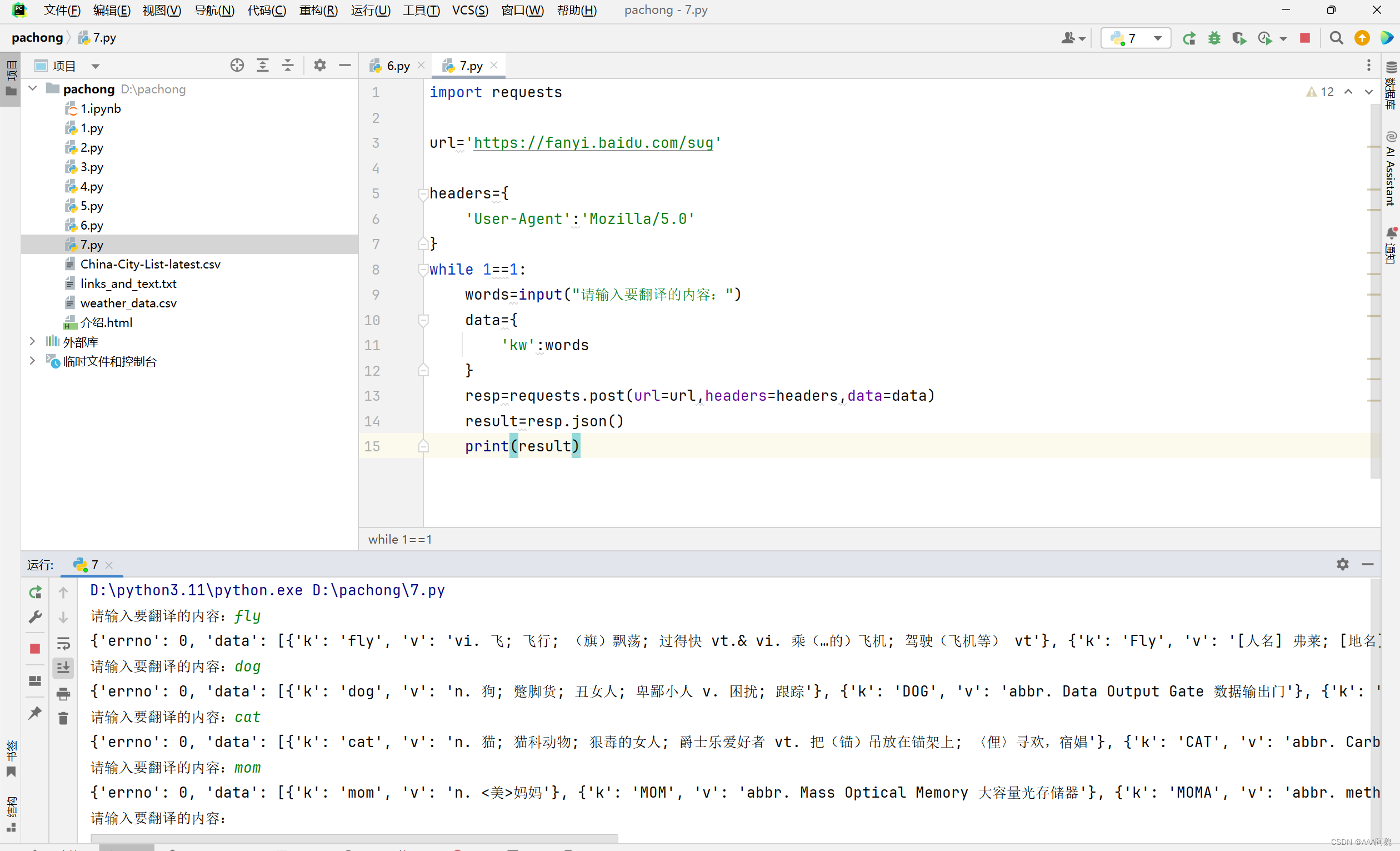
加上while优化
import requests
url='https://fanyi.baidu.com/sug'
headers={
'User-Agent':'Mozilla/5.0'
}
while 1==1:
words=input("请输入要翻译的内容:")
data={
'kw':words
}
resp=requests.post(url=url,headers=headers,data=data)
result=resp.json()
print(result)结果
 结束!
结束!

















 3254
3254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











