







前言
人工智能的四要素为:数据、算法、算力、场景,训练深度学习模型离不开数据
目标
(1)了解常见的数据类型
(2)掌握数据集划分的原则
(3)掌握处理模型方差与偏差的方法
一、数据集
1.数据类型1
在计算机视觉中,常用的信息主要包含图像数据和视频数据,它俩都是非结构化的数据,我们需要将这些非结构化的数据转化为结构化的数据才能进行处理。
(一)结构化数据
行数据或者列数据,能存储在数据库当中可以用二维表结构来逻辑表达实现的一些数据,结构化数据可以进行比较,比较方便进行搜索,比如说二维表,例如学生的成绩组成一个二维表的数据
(二)非结构化的数据
典型代表就是图像数据、视频数据、文本数据,图像和视频数据通常会用卷积神经网络来提取特征
2.数据类型2
--语音数据

--文本数据

此二者都是序列数据
3.数据类型3
--时序数据
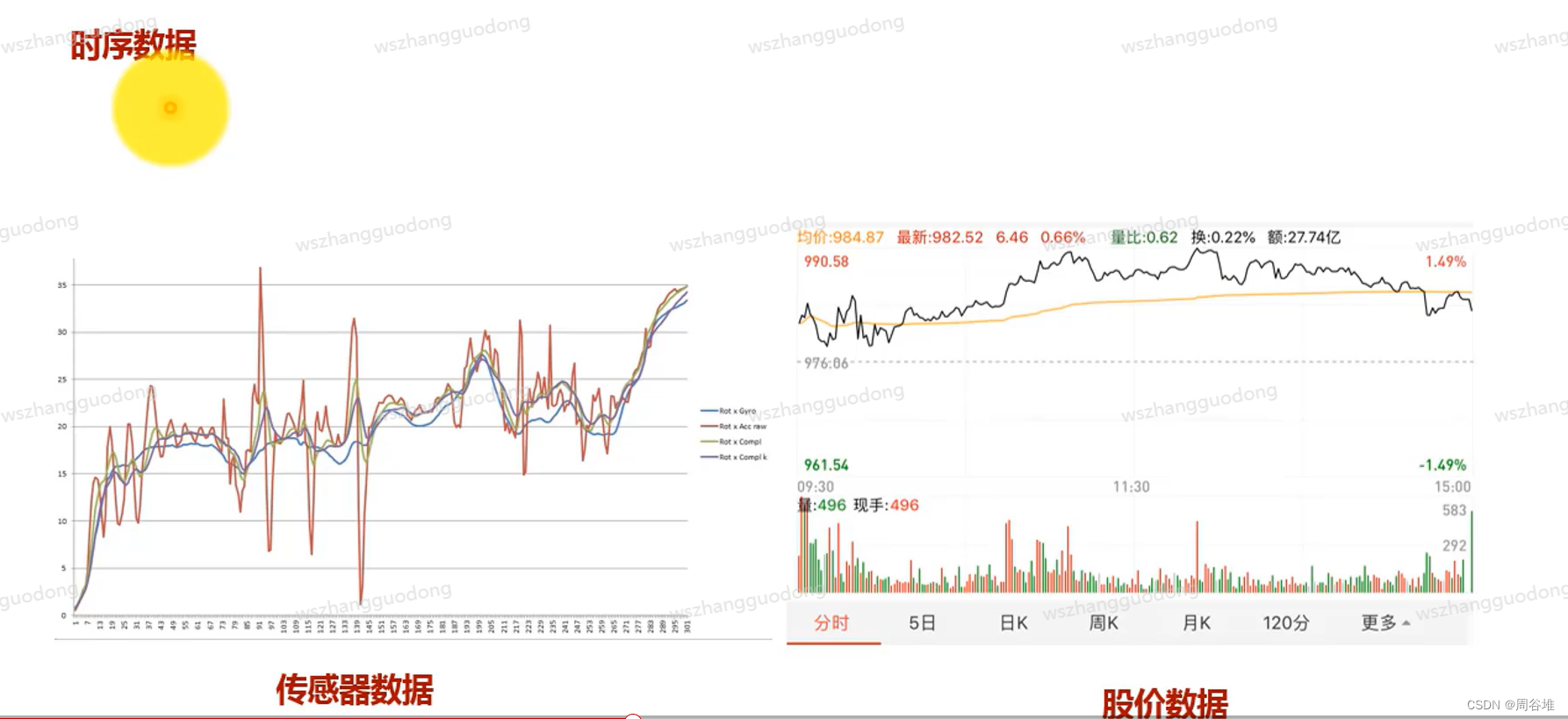
时序数据是一种具有巨大挖掘价值的数据对象,它广泛存在于各个领域当中,比如流媒体文件数据、金融财务数据、气象观测数据、人口普查数据、系统日志数据等等。
常见的时序数据类型包括传感器数据和股价数据
时序数据和序列数据通常会用循环神经网络来提取特征
4.数据集定义

序号1-5这一组数据叫做一个数据集
其中的每一条数据叫做一个样本
面积、学区、朝向为特征
房价为标签,这是做深度学习当中需要进行预测的一列数据
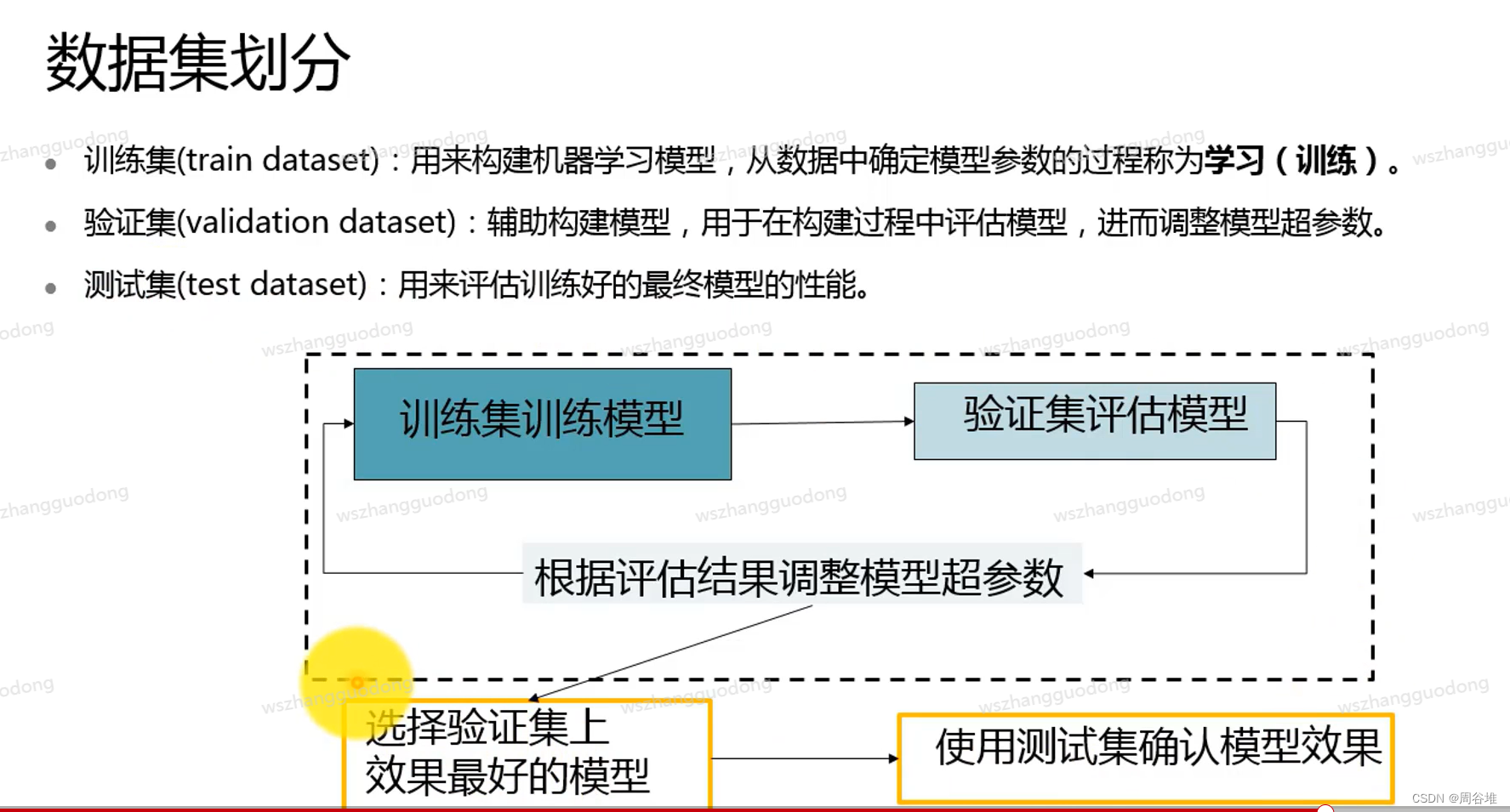
5.数据集划分
二、数据集分割
以下是保证训练集和测试集同分布的俩种方法
1.留出法

注意事项的解决方案


2.k-折交叉验证

将数据集中的数据随机打乱,再划分为k个子集,再k份当中选一份作为测试集,其余k-1作为训练集,接着依次在k份中取一份为测试集,最终训练过程重复了k次,最后取平均测试结果作为最后输出。
优点是对数据量的要求不高,样本信息损失不多,k是一个超参数,通常取10
实际应用中,由于数据集非常大,通常会选用留出法
3.训练集与测试集不同分布

在做鸟的检测任务当中,训练集的图像大多都是高清静止的,测试集中大多是模糊的运动的,二者不是同分布的
解决方案如下

需要在训练集当中加入一些鸟运动的图像以达到训练集和测试集数据分布的属性一致
三、偏差与方差
1.定义


数据不具代表性会导致方差

偏差好比一个人瞄准的能力,方差就是枪的性能
2. 各情况解决方案




--合理选择模型的复杂程度(训练程度)
复杂度过高容易出现过拟合,复杂度过低容易出现欠拟合
--训练不足时,学习器拟合能力比较弱,训练数据的扰动不足会使得学习器产生显著变化,此时偏差占主导,随着训练程度加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐被学习器拟合,此时方差开始占主导,训练程度充足以后,学习器的拟合能力非常强,训练数据发生的轻微扰动都会使学习器发生显著变化。若训练数据自身的非全局的特点被学习器学到了,这时候就会过拟合。















 2632
2632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









