






1.基础篇
1.1 数据库概述
●
数据库(
DataBase
)为了方便数据的存储和管理,它将数据按照特定的
规则存储在磁盘上
,
就是一个存储数据的仓库。
●
数据库的相关概念
DB
:数据库(
DataBase
)
存储数据的容器,它保存了一系列有组织的数据。
DBMS
:数据库管理系统(
DataBase Management System
)
又称为数据库软件或数据库产品,用于创建或管理
DB
。
1.2 MySql数据库
1.2.1 MySql概述
● MySQL
是一个关系型数据库管理系统
,
由瑞典
MySQL AB
公司开发,目
前属于
Oracle
旗下产品。
MySQL
流行的关系型数据库管理系统。
● MySql
是一种关系数据库管理系统。
● MySql
软件是一种开放源码软件
,
你可以修改源码来开发自己的
Mysql
系统。
● MySql
数据库服务器具有快速、可靠和易于使用的特点。
● MySql
使用标准的
sql
语言
,
并且支持多种操作系统
,
支持多种语言
.
1.2.3 MySQL的安装
●
命令行方式连接
mysql
登录:
mysql [-hlocalhost -P3306]
(本机可省略)
-uroot -p
(可以直
接写密码,不能有空格)
-h
:主机名
-P
:端口号
-u
:用户名
-p
:密码
退出:
exit
1.2.4 MySQL的常用命令
查看当前所有的数据库:
show databases;
选择指定的库:
use
库名
查看当前的所有表:
show tables;
查看其他库的所有表:
show tables from
库名
;
查看
mysql
版本
select version();
安装可视化客户端工具
SQLyog / Navicat
1.3 Sql
结构化查询语言
(Structured Query Language)
简称
SQL
,是一种特殊
目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以
及查询、更新和管理关系数据库系统
.
SQL
优点:
不是某个特定数据库供应商专有的语是言,几乎所有
DBMS
都支持
SQL
简单易学,灵活使用可以进行非常复杂和高级的数据库操作
1.4 DDL
●
数据
(
结构
)
定义语言
DDL(Data Definition Language)
,是用于创
建和修改数据库表结构的语言。
●
常用的语句:
create ,alter,drop,rename
数据库表的基本概念
1、数据表
表(table)是数据存储的最常见和最简单的形式,是构成关系型数据库的基本元素。
表的最简单形式是由行和列组成,分别都包含着数据。 每个表都有一个表头和表体,表头定
义表名和列名 .表中的行被看作是文件中的记录,表中的列被看作是这些记录的字段。
2、字段
字段是表里的一列,用于保存每条记录的特定信息。如客户订单表的字段包括“订单
ID”、“姓名”、“客户ID”、“职务”、“上级”、“地区”、“运货商”、“国家”等。
数据表的一列包含了特定字段的全部信息。
3、记录
记录也被称为一行数据,是表里的一行数据。
●
设 计 表
●
对于具体的某一个表,在创建之前,需要确定表的下列特征:
●
表名
(
表信息
)
●
表中的字段
●
字段的数据类型和长度
●
哪些约束
设计表
(
数据类型
)
char
(
n
) 长度为
n
的定长字符串
,
最大长度
255
个字符
varchar(n
) 最大长度为
n
的可变长字符串
date
日期, 包含年月日
datetime
年月日 时分秒
设计表
(
数据类型
)
TEXT
列字符字符串
有
4
种
TEXT
类型:
TINYTEXT
、
TEXT
、
MEDIUMTEXT
和
LONGTEXT
。
它的长度:
TINYTEXT
:最大长度
255
个字符
(2^8-1)
TEXT
:最大长度
65535(2^16-1)
MEDIUMTEXT
:最大长度
16777215(2^24-1)
LONGTEXT
最大长度
4294967295(2^32-1)
主键:
在一张表中代表唯一的一条记录
,
不能为空
,
不能重复
约束
:
PRIMARY KEY
设置主键约束
NOT NULL
不能为空约束
UNIQUE
唯一性约束
检查约束 设置条件
外键约束
主键自动增长
,
设置为自动增长时
,
只能为整数类型
AUTO_INCREMENT
默认值
DEFAULT default_value
字段注释
:
comment '
注释
'
接下来是一段样例代码用来创建数据库和创建表
CREATE DATABASE NBA
CREATE TABLE nba_team(
num INT PRIMARY KEY AUTO_INCREMENT,
team_name VARCHAR(20) NOT NULL UNIQUE COMMENT'team-name',
address VARCHAR(10) NOT NULL UNIQUE COMMENT'address'
);
CREATE TABLE player(
num INT PRIMARY KEY AUTO_INCREMENT,
player_name VARCHAR(20) NOT NULL,
birth date,
height INT,
weight INT,
postioning CHAR(2)
);以上代码表1 是球队信息,表2是球员信息
删除表,修改表名
删除表
DROP TABLE [if exists ]表名
修改表名
RENAME TABLE 旧表名 TO 新表名
复制表结构
CREATE TABLE 新表名 LIKE 被复制表名;
插入数据
方式
1: INSERT INTO
表名
(
列
1,
列
2……,
列
n) VALUES(
值
1,
值
2…..,
值
n);
方式
2: INSERT INTO
表名
set
列名
1=
值
1,..
列名
n=
值
n;
方式
3: INSERT INTO
表名
(
列
1,
列
2……,
列
n) VALUES(
值
1,
值
2…..,
值
n),(
值
1,
值
2…..,
值
n);
方式
4:INSERT INTO
表名
(
列
1,
列
2……,
列
n)
查询语句
(
查询的列数与插入列数匹配
)
接下来为我们已经创建好的表中插入数据这里我们采用方式1
-- 使用insert into语句向球员表和球队表插入数据
INSERT INTO nba_team (team_name,address)VALUES('湖人','洛杉矶');
INSERT INTO nba_team (team_name,address)VALUES('火箭','休斯顿');
INSERT INTO nba_team (team_name,address)VALUES('凯尔特人','波士顿');
INSERT INTO nba_team (team_name,address)VALUES('骑士','克利夫兰');
INSERT INTO nba_team (team_name,address)VALUES('马刺','圣安东尼奥');
INSERT INTO nba_team (team_name,address)VALUES('魔术','奥兰多');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('德怀恩韦德','1982-1-17','193','96','后卫');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('勒布朗詹姆斯','1984-12-30','203','113','前锋');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('科比布莱恩特','1978-8-23','198','99','后卫');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('德克诺维斯基','1978-6-19','213','111','中锋');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('克里斯保罗','1985-5-6','182','79','后卫');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('托尼帕克','1982-5-17','187','83','后卫');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('凯文加内特','1981-7-14','212','113','前锋');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('保罗皮尔斯','1977-10-13','200','106','前锋');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('迈克尔乔丹','1963-2-17','198','98','前锋');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('德怀特霍华德','1985-12-8','210','120','中锋');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('姚明','1980-9-12','229','140','中锋');
INSERT INTO player (player_name,birth,height,weight,postioning)VALUES('沙葵奥尼尔','1972-3-6','215','147','中锋');
修改数据
UPDATE
表名
SET
列名
=
‘新值’
WHERE
条件
删除数据
DELETE FROM
表名
WHERE
条件
TRUNCATE TABLE
表名
;
清空整张表
1.5 DQL-基础查询
● DQL
(
Data Query Language
)数据查询语言查询是使用频率最高的一个操作,
可以从一个表中查询数据,也可以从多个表中查询数据。
●
基础查询
●
语法:
select
查询列表
from
表名
;
●
特点:
查询列表可以是:表中的字段、常量、表达式、函数
查询的结果是一个虚拟的表格
●
查询结果处理:
特定列查询
:select column1,column2 from table
全部列查询
: select * from table
算数运算符
:+ - * /
排除重复行
: select distinct column1,column2 from table
查询函数:
select
函数
; /
例如
version()
●
查询结果处理:
●
函数
:
类似于
java
中的方法,将一组逻辑语句事先在数据库中定义好
,
可以直接调
用
分类:
单行函数:如
concat
、
length
、
ifnull
等
分组函数:做统计使用,又称为统计函数、聚合函数、组函数
●
单行函数
●
字符函数
length()
:获取参数值的字节个数
char_length()
获取参数值的字符个数
concat(str1,str2,.....)
:拼接字符串
upper()/lower()
:将字符串变成大写
/
小写
substring(str,pos,length)
:截取字符串 位置从
1
开始
instr(str,
指定字符
)
:返回子串第一次出现的索引,如果找不到返回
0
trim(str)
:去掉字符串前后的空格或子串
,trim(
指定子串
from
字符串
)
lpad(str,length,
填充字符
)
:用指定的字符实现左填充将
str
填充为指定长度
rpad(str,length,
填充字符
)
:用指定的字符实现右填充将
str
填充为指定长度
replace(str,old,new)
:替换,替换所有的子串
●
单行函数
•
逻辑处理
case when 条件 then 结果1 else 结果2 end; 可以有多个when
ifnull(被检测值,默认值)函数检测是否为null,如果为null,则返回指定的值,否则返回
原本的值
if函数:if else的 效果 if(条件,结果1,结果2)
●
单行函数
●
数学函数
round(
数值
)
:四舍五入
ceil(
数值
)
:向上取整,返回
>=
该参数的最小整数
floor(
数值
)
:向下取整,返回
<=
该参数的最大整数
truncate(
数值
,
保留小数的位数
)
:截断,小数点后截断到几位
mod(
被除数
,
除数
)
:取余,被除数为正,则为正;被除数为负,则为负
rand()
:获取随机数,返回
0-1
之间的小数
●
单行函数
日期函数
now()
:返回当前系统日期
+
时间
curdate()
:返回当前系统日期,不包含时间
curtime()
:返回当前时间,不包含日期
可以获取指定的部分,年、月、日、小时、分钟、秒
YEAR(
日期列
),MONTH(
日期
列
),DAY(
日期
列
) ,HOUR(
日期
列
) ,MINUTE(
日期
列
)
SECOND(
日期
列
)
str_to_date(
字符串格式日期
,
格式
)
:将日期格式的字符转换成指定格式的日期
date_format(
日期列
,
格式
)
:将日期转换成字符串
datediff(big,small)
:返回两个日期相差的天数
●
日期格式
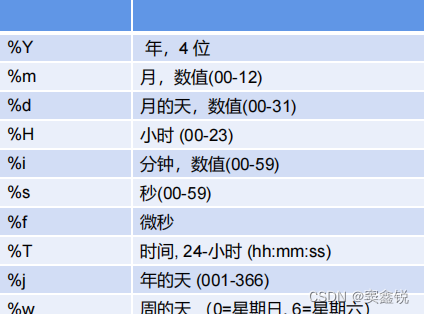
●
分组函数
功能:用作统计使用,又称为聚合函数或统计函数或组函数
分类:
sum
求和、
avg
平均值、
max
最大值、
min
最小值、
count
计数
(非空)
1.sum
,
avg
一般用于处理数值型
max
,
min
,
count
可以处理任何类型
2.
以上分组函数都忽略
null
值
3.count
函数的一般使用
count
(
*
)用作统计行数
4.
和分组函数一同查询的字段要求是
group by
后的字段
●
条件查询
使用WHERE 子句,将不满足条件的行过滤掉,WHERE 子句紧随 FROM 子句。
语法
:select <
结果
> from <
表名
> where <
条件
>
比较
=, !=
或
<>, >, <, >=, <=
逻辑运算
and
与
or
或
not
非
●
条件查询
模糊查询
LIKE
:是否匹配于一个模式 一般和通配符搭配使用,可以判断字符型数值
或数值型.
通配符: % 任意多个字符
between and 两者之间,包含临界值;
in 判断某字段的值是否属于in列表中的某一项
IS NULL(为空的)或 IS NOT NULL(不为空的)
1
、
UNION
的语法如下:
[SQL
语句
1]
UNION
[SQL
语句
2]
2
、
UNION ALL
的语法如下:
[SQL
语句
1]
UNION ALL
[SQL
语句
2]
当使用union 时,mysql 会把结果集中重复的记录删掉,而使用union all ,
mysql 会把所有的记录返回,且效率高于union 。
•
排序
查询结果排序,使用 ORDER BY 子句排序 order by 排序列 ASC/DESC
asc代表的是升序,desc代表的是降序,如果不写,默认是升序
order by子句中可以支持单个字段、多个字段
•
数量限制
limit子句:对查询的显示结果限制数目 (sql语句最末尾位置)
SELECT * FROM table LIMIT offset rows;
SELECT * from table LIMIT 0,5;
分组查询
语法:
select
分组函数,列(要求出现在
group by
的后面)
from
表
[where
筛选条件
]
group by
分组的列表
[having
分组后的筛选
]
[order by
子句
]
注意:查询列表比较特殊,要求是分组函数和
group by
后出现的字段
分组查询中的筛选条件分为两类
:
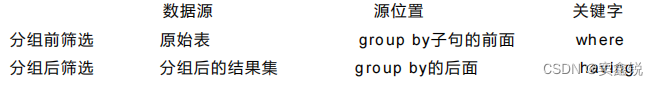
以下是一些查询的基本使用
select (1982) as years ,(count(*)) as number from player where(YEAR(birth)=1982);-- 查询1982出生年球员的数量
select postioning,(count(*))as number FROM player group by postioning ;-- 分组查询各个位置的球员个数
select * from player where height>190 AND height<220;-- 查询身高在190到220之间的球员信息
select * from player where height>200 AND weight>100;-- 查询身高大于200且体重大于100的球员信息
●
数据库设计范式
● 1
.第一范式
(
确保每列保持原子性
)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就
说明该数据库表满足了第一范式。
●
数据库设计范式
2
. 第二范式就是要有主键,要求其他字段都依赖于主键。
•
没有主键就没有唯一性,没有唯一性在集合中就定位不到这行记录,所以要主键。
•
其他字段为什么要依赖于主键?因为不依赖于主键,就找不到他们。更重要的是,其
他字段组成的这行记录和主键表示的是同一个东西,而主键是唯一的,它们只需要依
赖于主键,也就成了唯一的。
●
数据库设计范式
3.
第三范式
,
确保每列都和主键列直接相关
,
而不是间接相关
,
要求一个数据库表中不包含
已在其它表中包含的非主关键字信息
●
外键:引用另外一个数据表的某条记录。
外键列类型与主键列类型保持一致
数据表之间的关联/引用关系是依靠具体的主键(primary key)和外键
(foreign key)建立起来的。
create table student(
id int not null auto_increment primary key,
num int,
name varchar(10)
majorid int,
CONSTRAINT 约束名 foreign key(majorid ) references major(id)
);
约束名规则:
例:FK_ForeignTable_PrimaryTable_On_ForeignColumn
1、当主表中没有对应的记录时,不能将记录添加到从表
2、不能更改主表中的值而导致从表中的记录孤立
3、从表存在与主表对应的记录,不能从主表中删除该行
4、删除主表前,先删从表
●
关联查询
含义:又称多表查询,当查询的字段来自于多个表时,就会用到连接查询
笛卡尔乘积现象:表
1
有
m
行,表
2
有
n
行,结果
=m*n
发生原因:没有有效的连接条件
如何避免:添加有效的连接条件
按功能分类:
自连接
SELECT * FROM AREA ar INNER JOIN AREA aq ON ar.pid = aq.id WHERE ar.name = '西安市';
SELECT * FROM AREA WHERE pid = 610000;
内连接
外连接
左外连接
右外连接
●
关联查询
●
内连接
(inner join)
●
把满足了条件的两张表中的交集数据查询出来
语法:
Select
结果
from
表
1
,表
2 where
表
1.column1 =
表
2.column2
SELECT * FROM(SELECT gname,COUNT(*) c FROM Goods GROUP BY gname) temp WHERE temp.c>1;
SELECT * FROM Goods WHERE goodsnum = (SELECT MAX(goodsnum) FROM Goods);
SELECT * FROM Goods WHERE goodsnum IN(SELECT goodsnum FROM Goods WHERE goodsnum = 4 OR gname = '马嘉祺超绝肌肉promax手办');
SELECT * FROM player WHERE postioning = (SELECT postioning FROM player WHERE player_name = '勒布朗詹姆斯')
SELECT * FROM player WHERE height > (SELECT AVG(height) FROM player )
SELECT * FROM player p INNER JOIN (SELECT postioning,MAX(height)h FROM player GROUP BY postioning) s
ON p.postioning = s.postioning AND p.height = s.h
●
多表关联
●
左外连接
(left join)
select
结果
from
表
1 left join
表
2 on
表
1.column1 =
表
2.column2
子查询
含义:出现在其他语句中的
select
语句,称为子查询或内查询;外部的查询语句,称为主查询或
外查询
.
分类:
按子查询出现的位置:
from
后面:支持表子查询
where
:支持标量子查询,列子查询
按功能、结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
表子查询(结果集一般为多行多列)


















 7919
7919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











