






目录
前言
数据归一化(Normalization),也称为特征缩放(Feature Scaling),是数据预处理中的一个重要步骤,它将数据调整到一个特定的范围内,通常是0到1之间。
一 为什么要对数据进行归一化处理
1.加快学习速度
归一化后的数据可以加快机器学习算法的收敛速度,特别是在梯度下降法等优化算法中。
2.避免数值问题
不同特征的量纲和数值范围可能差异很大,归一化可以减少这些差异,避免算法在数值上遇到问题,比如数值下溢或上溢。
3.提高模型性能
不同的特征尺度可能会导致模型对某些特征赋予过高或过低的权重,从而影响模型的性能。归一化后,所有特征都在相同的尺度上,有助于模型更公平地对待每个特征。
4.改善模型的泛化能力
通过归一化,模型可以更好地学习到数据的内在结构,而不是被特征的尺度所误导,从而提高模型的泛化能力。
二 归一化的缺点
1.对异常值敏感
Min-Max Normalization会将数据缩放到0到1的范围内,这个过程依赖于数据的最大值和最小值。如果数据中存在异常值,这些极端值会影响整个数据集的归一化结果,导致其他数据点被压缩到一个很小的范围内。
2.数据分布改变
这种归一化方法可能会改变原始数据的分布形状,尤其是当数据分布不均匀时,可能会导致信息损失。
三 Min-Max Normalization的原理
Min-Max Normalization(最小-最大归一化)是一种线性变换的数据预处理技术,其目的是将数据的数值范围缩放到一个指定的区间,通常是[0, 1],但也可以是任何其他指定的区间[a, b]。这种归一化方法通过以下公式实现:
=
其中:X 是原始数据值
是数据集中的最小值
是数据集中的最大值
是归一化之后的数据值
这个公式将原始数据值 X 减去最小值 ,然后除以数据的范围(最大值
减去最小值
)。这样,所有的数据值都会被缩放到0到1之间。
如果需要将数据缩放到[a, b]区间,公式可以稍作修改:
这里,a和b是你想要映射到的最小值和最大值。
四 在Python中实现数据归一化的两种方法
1.使用sklearn
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 假设X是包含数据的二维numpy数组
X = np.array([[1, 2], [3, 4], [5, 6]])
# 创建MinMaxScaler对象
scaler = MinMaxScaler()
# 拟合并转换数据
X_scaled = scaler.fit_transform(X)
print(X_scaled)得到的结果如下所示,读者可根据上述的原理进行计算验证:
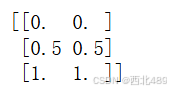
2.只使用numpy
import numpy as np
def min_max_normalization(X):
# 计算每个特征的最小值和最大值
X_min = X.min(axis=0)
X_max = X.max(axis=0)
# 归一化数据
X_scaled = (X - X_min) / (X_max - X_min)
return X_scaled
# 假设X是包含数据的二维numpy数组
X = np.array([[1, 2], [3, 4], [5, 6]])
# 归一化数据
X_scaled = min_max_normalization(X)
print(X_scaled)得到的结果如下所示,读者可根据上述的原理进行计算验证:
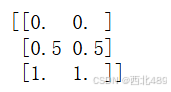
总结
本篇博客介绍了对数据进行归一化的原因,实现数据归一化的原理,以及在Python中对数据进行归一化的两种方法。

















 5641
5641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









