






归一化 normalization
归一化的目的
归一化(Normalization)是一种数据处理方法,目的在于消除不同数据之间的量纲影响,使数据具有更好的可比性,便于数据分析和处理。在多个领域中,如统计学、机器学习、数据挖掘等,归一化都是一项重要的技术。归一化主要有以下几个目的:
1.统一量纲:当数据集中的不同特征的量纲(单位)不同时,可能会导致某些特征在学习算法中占据主导地位。通过归一化,可以将所有特征的量纲统一到相同的尺度,确保每个特征在模型中的贡献是平等的。
2.加速学习过程:在某些算法中,例如梯度下降,特征的大范围数值可能会导致学习率的选择变得复杂,且可能需要更多迭代才能收敛。归一化可以使得特征数值范围更紧凑,有助于加速学习过程。
-
提高精度:对于一些模型,尤其是距离计算敏感的模型(如K-近邻、K-均值聚类、神经网络),特征的规模差异可能会导致模型性能下降。归一化可以消除这种影响,提高模型精度。
-
处理异常值:通过将数据映射到一个标准范围(如0到1之间),归一化可以减少异常值对模型的影响。
-
满足算法要求:某些算法或模型要求输入数据必须满足特定的分布(如正态分布),归一化可以帮助数据更好地符合这些要求。
-
便于可视化:在数据可视化中,如果数据规模差异很大,那么较小的数值在图表中将几乎不可见。归一化可以帮助在图表中更准确地展示所有数据。
归一化有多种方法,常见的包括线性归一化(min-max归一化)、Z-score归一化、对数归一化等。选择哪种归一化方法取决于数据的特性和分析的目的。
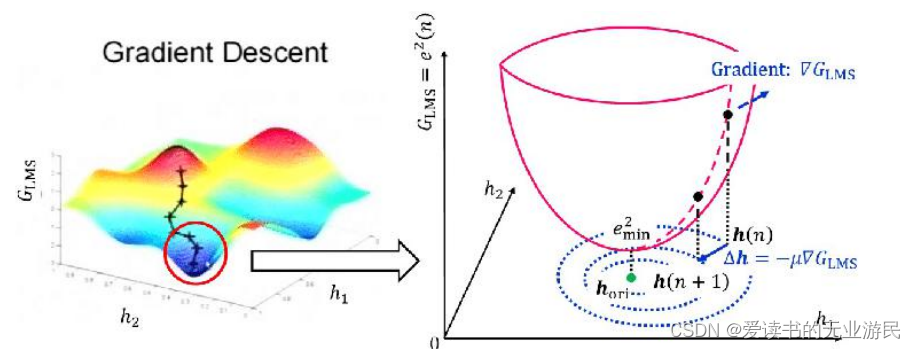 下图左是做了归一化的俯瞰图,下图右是没有做归一化的俯瞰图。
下图左是做了归一化的俯瞰图,下图右是没有做归一化的俯瞰图。
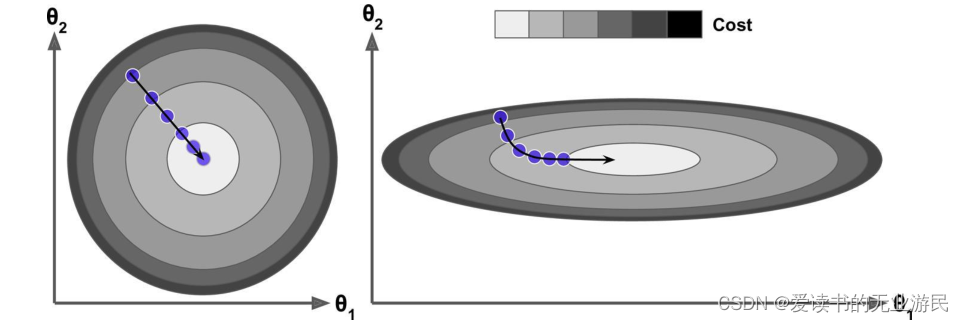 归一化的一个重要目的是使得最终梯度下降的时候可以不同维度θ参数可以在接近的调整幅度上。这就好比社会主义,可以一小部分先富裕起来,至少 loss 整体可以下降,然后只是会等另外一部分人富裕起来。但是更好的是要实现共同富裕,最后每个人都不能落下,优化的步伐是一致的。
归一化的一个重要目的是使得最终梯度下降的时候可以不同维度θ参数可以在接近的调整幅度上。这就好比社会主义,可以一小部分先富裕起来,至少 loss 整体可以下降,然后只是会等另外一部分人富裕起来。但是更好的是要实现共同富裕,最后每个人都不能落下,优化的步伐是一致的。
归一化有可能提高精度
归一化的其它好处是有可能提高精度!一些分类器需要计算样本之间的距离(如欧氏距离),例如 KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。同样的再举例分类器的例子,由于特征维度的量纲不同,所以很可能 X1 在 10000 到 20000 的区间,X2 在 1 到 2的区间,这样所有点都在一条直线上,出现无法找到分界线的情况。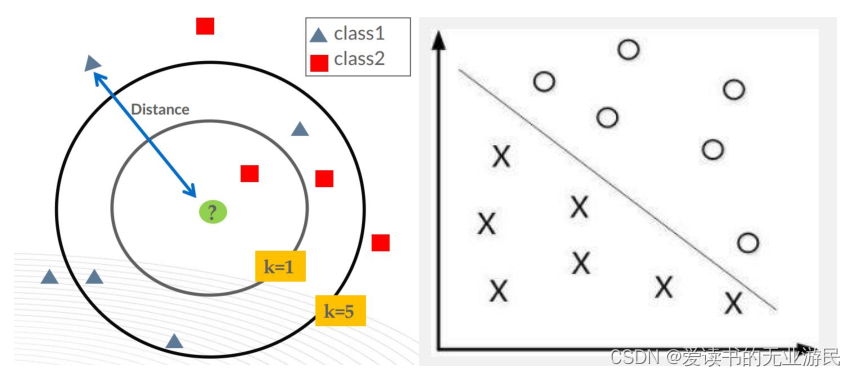
最大值最小值归一化
min max scaling
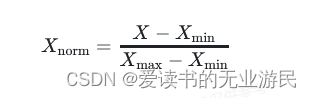 Xnorm 是归一化后的值。
Xnorm 是归一化后的值。
X 是原始数据。
Xmin是数据集中的最小值。
Xmax是数据集中的最大值。
通过这种方法,数据集中的最小值会映射为0,最大值会映射为1,而其他所有值则会按照它们在原始数据集中的位置,等比例地映射到0和1之间的某个值。
最大值最小值归一化适用于对数据分布形状没有特定要求的情况,它保留了数据中原始数值的相对大小关系。但是,这种方法对异常值比较敏感,因为异常值会影响到最大值和最小值的计算,从而影响整个数据集的归一化效果。此外,如果最大值和最小值是变化的,那么归一化后的值也会随之变化,这在动态数据集或者在线学习场景中需要特别注意。
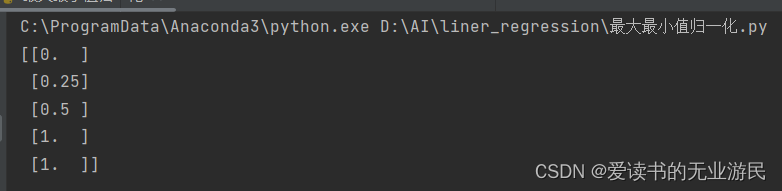
代码实现:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
import numpy as np
temp = np.array([1,2,3,5,5])
print(scaler.fit_transform(temp.reshape(-1,1)))
结果:
标准归一化
通常标准归一化中包含了均值归一化和方差归一化。经过处理的数据符合标准正态分布,即均值为 0,标准差为 1,其转化函数为:
 其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
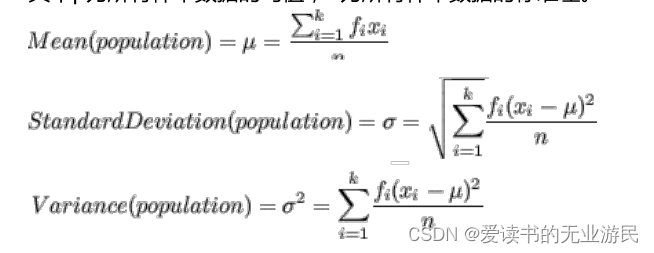 相对于最大值最小值归一化来说,因为标准归一化是除以的是标准差,而标准差的计算会考虑到所有样本数据,所以受到离群值的影响会小一些,这就是除以方差的好处!但是如果是使用标准归一化不一定会把数据缩放到 0 到 1 之间了。
相对于最大值最小值归一化来说,因为标准归一化是除以的是标准差,而标准差的计算会考虑到所有样本数据,所以受到离群值的影响会小一些,这就是除以方差的好处!但是如果是使用标准归一化不一定会把数据缩放到 0 到 1 之间了。
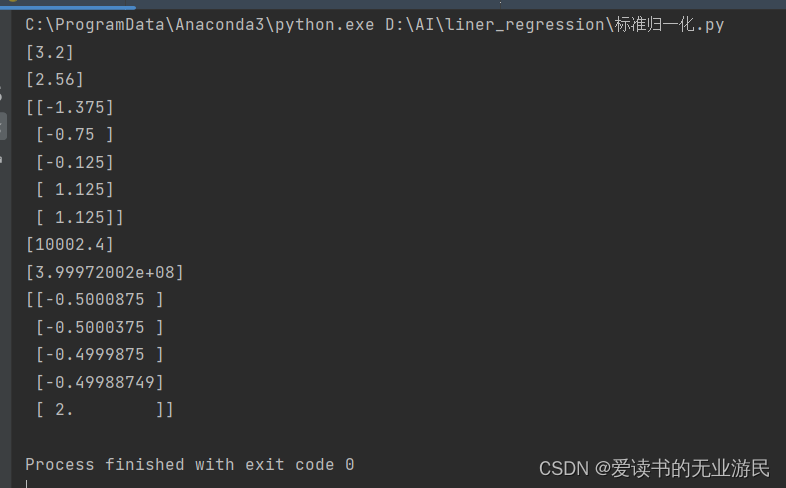
代码实现标准归一化
from sklearn.preprocessing import StandardScaler
import numpy as np
temp = np.array([1,2,3,5,5])
temp = temp.reshape(-1,1)
scaler = StandardScaler()
scaler.fit(temp)
#打印均值
print(scaler.mean_)
#打印方差
print(scaler.var_)
#转换数据
print(scaler.transform(temp))
data = np.array([1,2,3,5,50001]).reshape(-1,1)
scaler_1 = StandardScaler()
scaler_1.fit(data)
print(scaler_1.mean_)
print(scaler_1.var_)
print(scaler_1.transform(data))
结果:
 我们在做特征工程的时候,很多时候如果对训练集的数据进行了预处理,比如这里讲的归一化,那么未来对测试集的时候,和模型上线来新的数据的时候,都要进行相同的数据预处理流程,而且所使用的均值和方差是来自当时训练集的均值和方差!
我们在做特征工程的时候,很多时候如果对训练集的数据进行了预处理,比如这里讲的归一化,那么未来对测试集的时候,和模型上线来新的数据的时候,都要进行相同的数据预处理流程,而且所使用的均值和方差是来自当时训练集的均值和方差!
因为我们人工智能要干的事情就是从训练集数据中找规律,然后利用找到的规律去预测未来。这也就是说假设训练集和测试集以及未来新来的数据是属于同分布的!从代码上面来说如何去使用训练集的均值和方差呢?如果是上面代码的话,就需要把** scaler 对象持久化,回头模型上线的时候再加载进来去对新来的数据使用**。
总结
本文介绍了归一化基本概念及python中如何实现,后续将继续介绍机器学习相关内容,下一节介绍正则化。















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









