







一 爬虫和python

二 爬虫的合法性

三 爬虫的介绍
 通过程序去访问网站,网站肯定希望用户来访问网站,而不是程序来访问,可以使用一些技术手段。设置障碍。
通过程序去访问网站,网站肯定希望用户来访问网站,而不是程序来访问,可以使用一些技术手段。设置障碍。

越过障碍。


四 爬虫示例
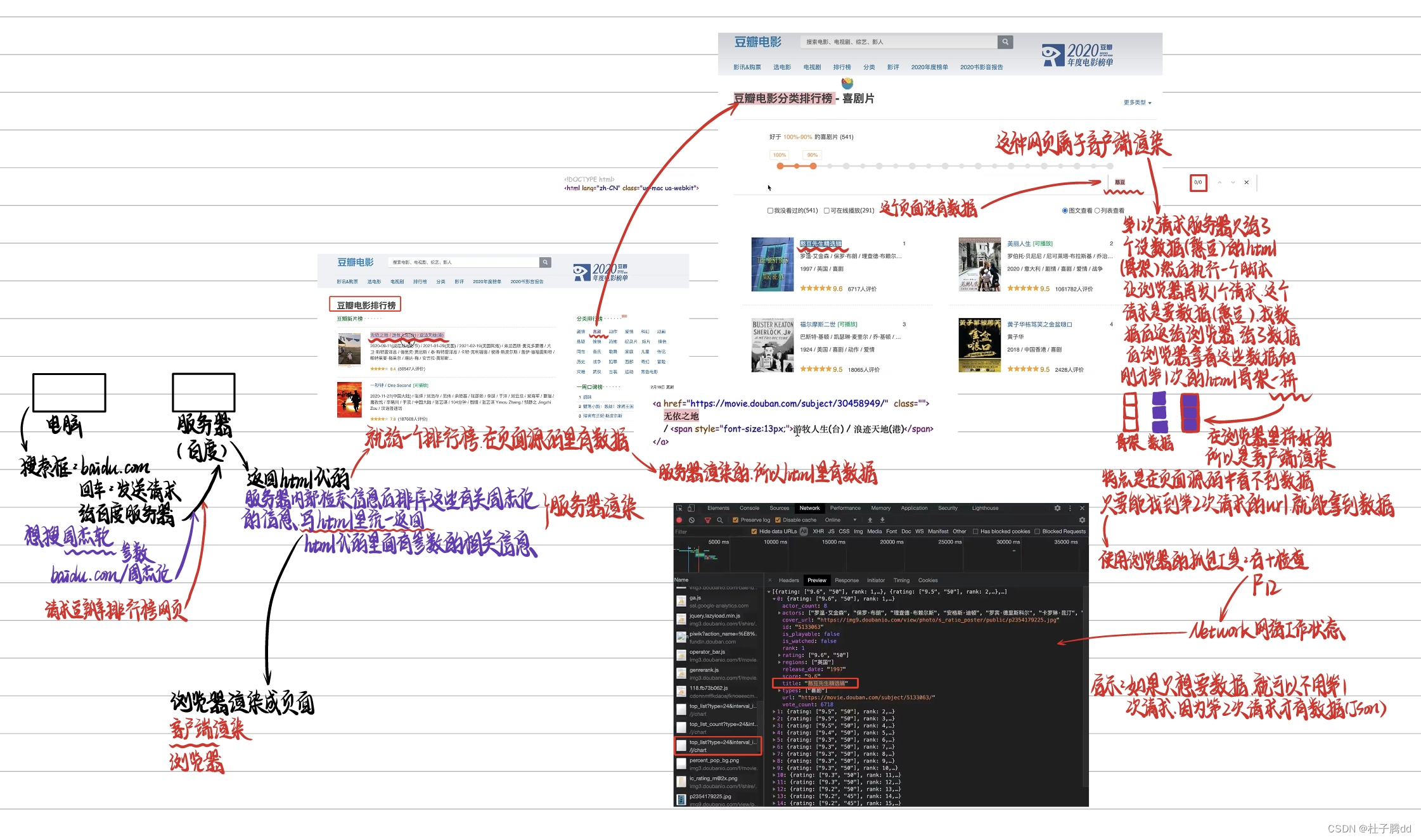
需求:用程序模拟浏览器。输入一个网址。从该网址中获取到资源或者内容。
请求:就是输入一个网址回车后就是请求。




在浏览器输入百度网址后,会找到百度的服务器,百度服务器会返回给浏览器一堆 html ,然后浏览器把html代码运行成界面。
五 web请求全过程解析
六 HTTP协议
表示这个URL地址在数据传输的时候遵循http协议。
什么是协议
两个电脑进行数据传输的时候要遵守的协议,我给你发的数据格式是怎样的,你收到的时候就有规定。解析数据有规则。
因为计算机传输的时候就是一堆0和1,为了数据方便看就要约定好前面多少位数什么,后多少位是什么。

超文本传输,传输的是超文本的东西,看到的HTML代码就是超文本,HTML叫超文本标记语言,这个语言写出的叫超文本。
就是http协议传输的是网站的页面源代码。
请求和响应得到的数据格式不一样。
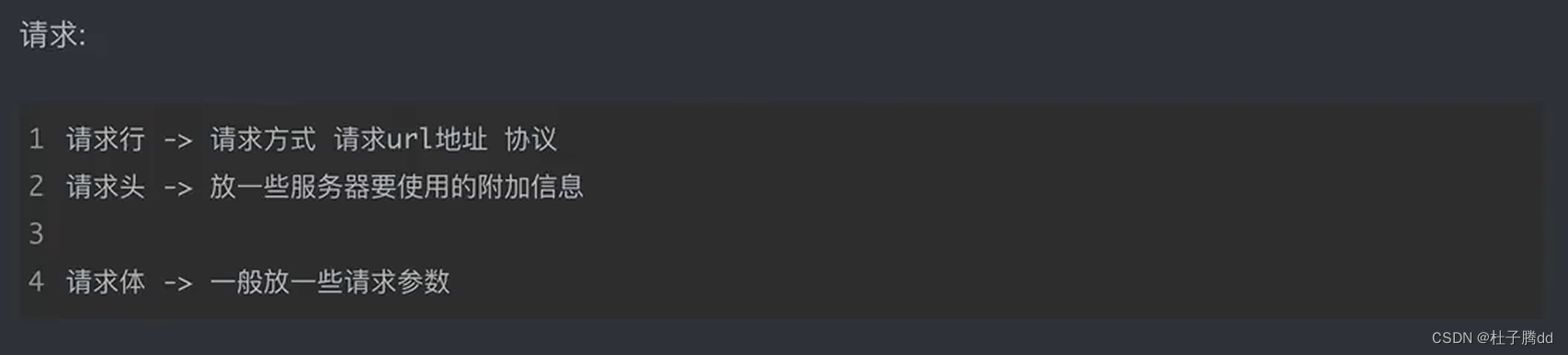
请求方式:比如 get 。常见的是 get 和 post 。
一般查询东西用get,显式提交,想修改数据的时候,对服务器里面的数据做更改,上传东西用post,隐式提交。
请求头:服务器需要知道你当前这个请求是从哪里来的,你发出请求的浏览器对返回的数据有什么要求,还有一些反爬的内容。和数据没关系。
请求体:放请求的参数。(周杰伦)
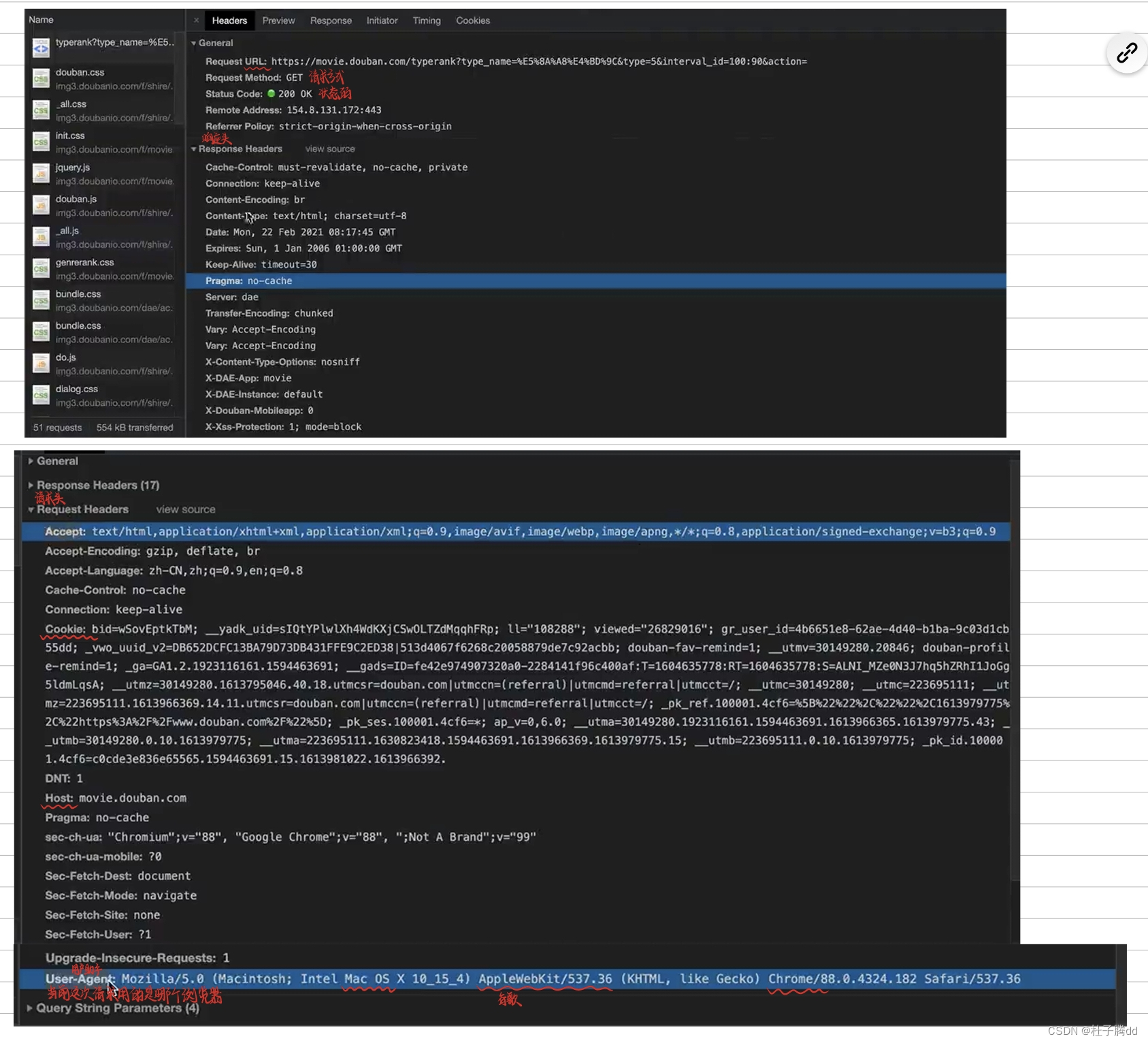
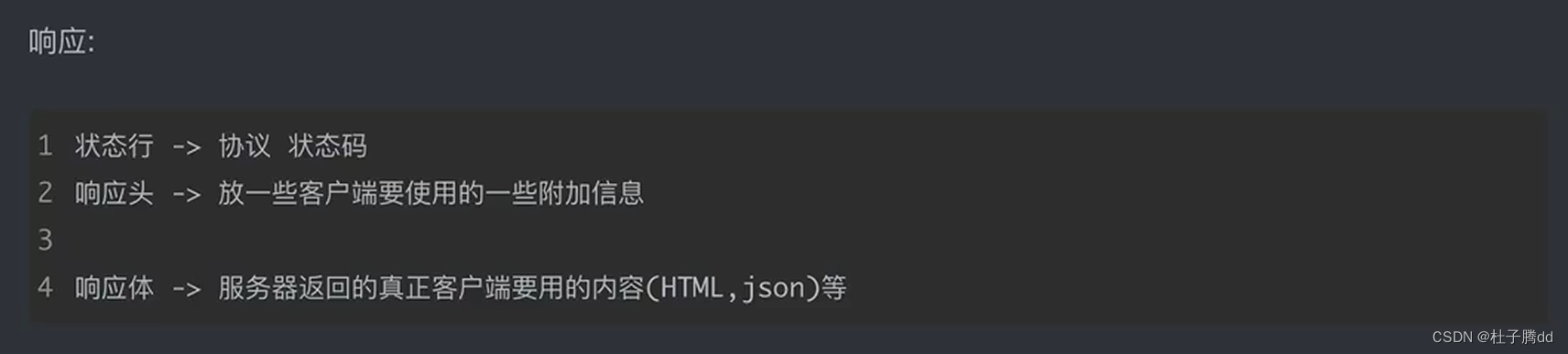 状态码:这次请求是否成功,要告诉结果。200:成功,404:丢失 ,500服务器报错,百度机房炸了,302:请求成功了但是真正想要的内容要去另一个地址,重定向。
状态码:这次请求是否成功,要告诉结果。200:成功,404:丢失 ,500服务器报错,百度机房炸了,302:请求成功了但是真正想要的内容要去另一个地址,重定向。
响应头:放一些客户端可能要用到的信息,比如cookie,数据加密,密钥。
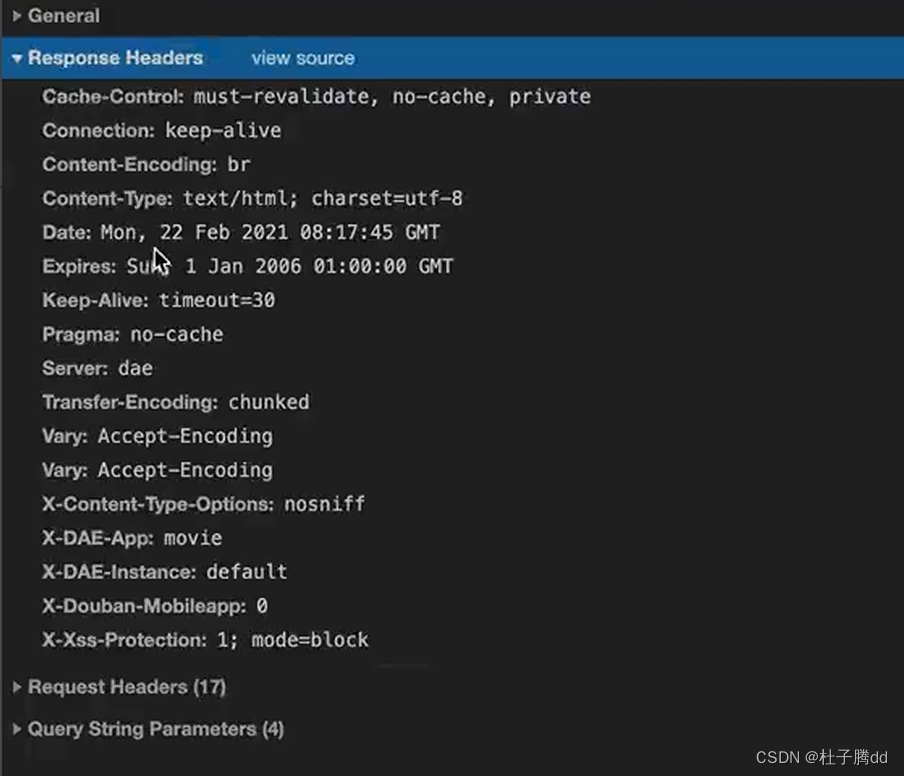
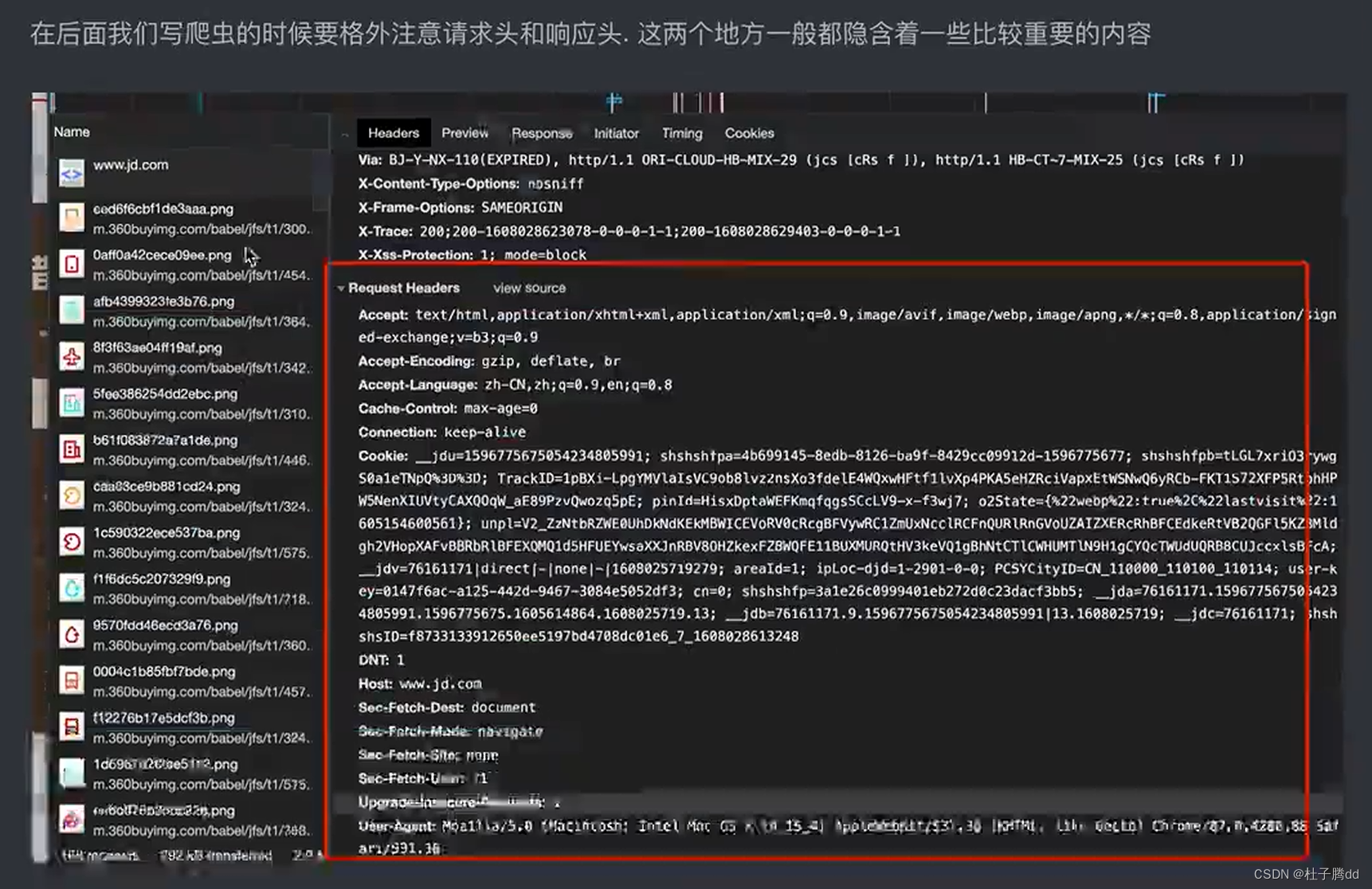
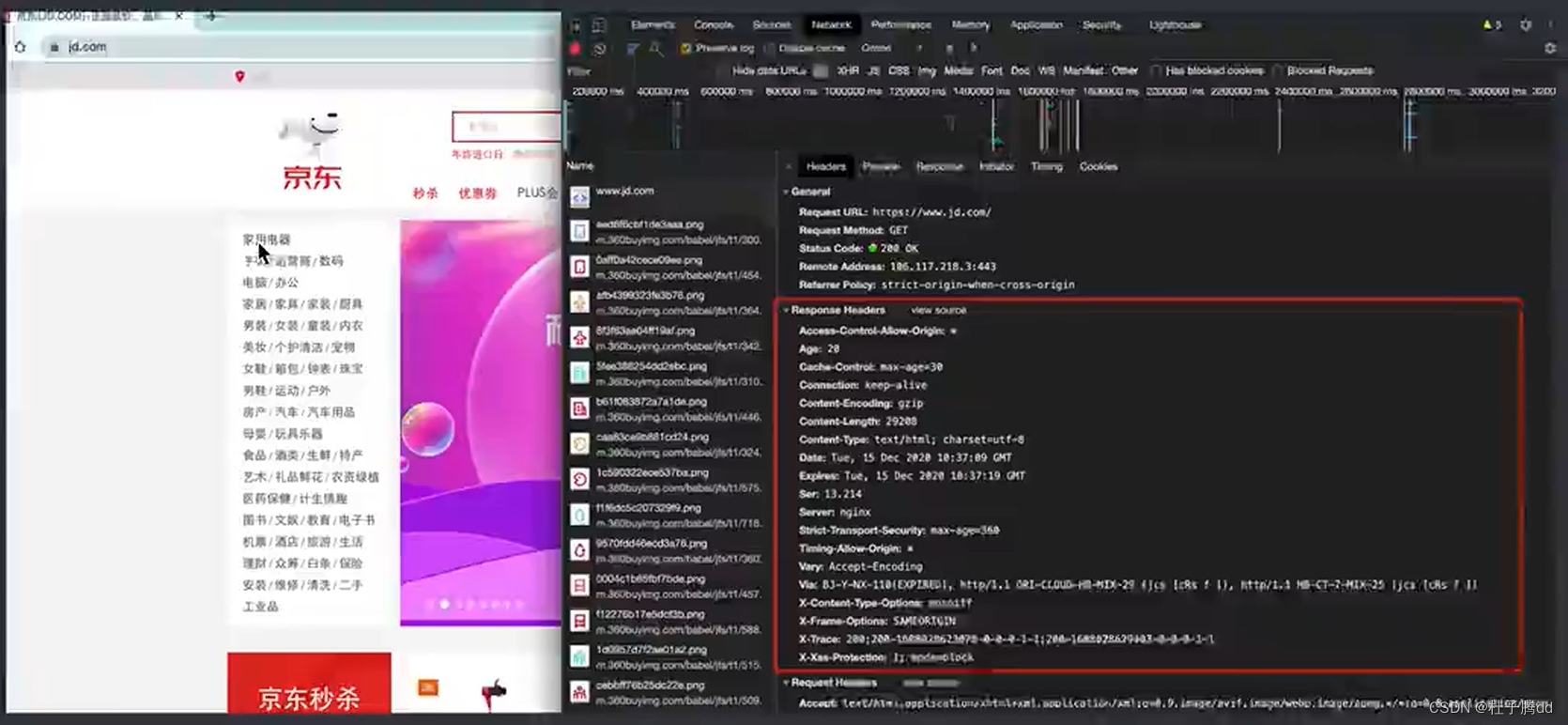

反爬手段一般都是在请求头和相应头。不同网站这两个头可能不一样。
七 requests模块入门
简化获取页面源代码的过程。
前面案例:from urllib.request import urlopen
用 urlopen 去打开网址。request可以进一步简化步骤。
这个模块不是Python自带的,要安装。
pip install requests,最好在 pycharm 里的 terminal 装。
在浏览器地址栏里面输入的URL都是使用get方式提交。
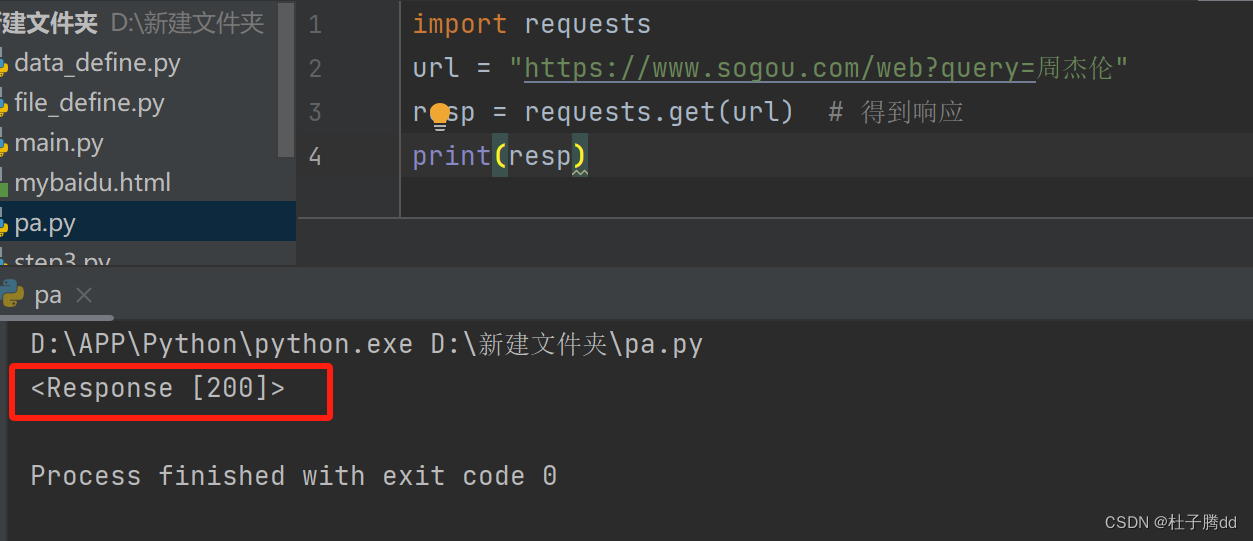
表示成功发送请求和成功收到响应了。
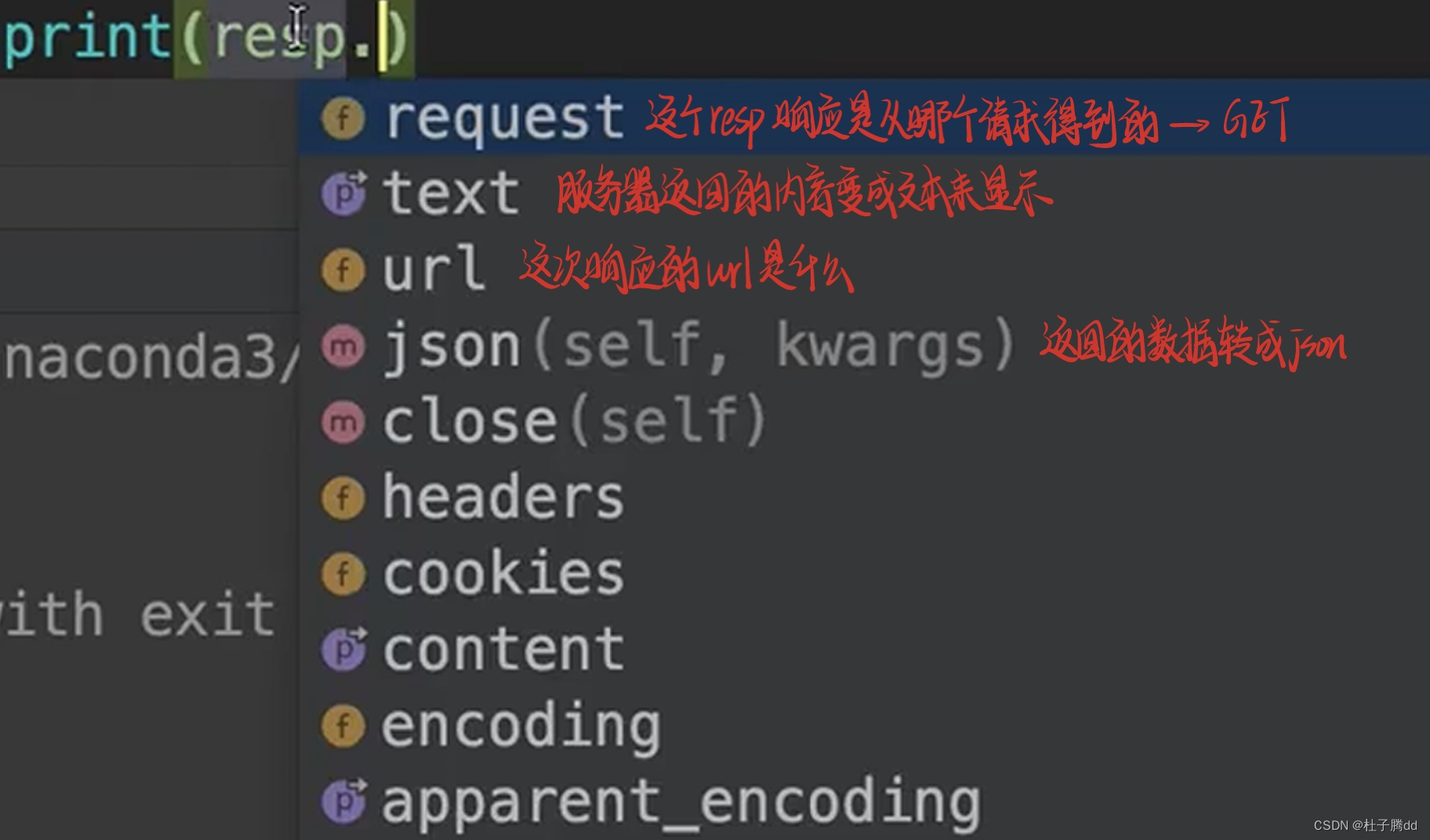
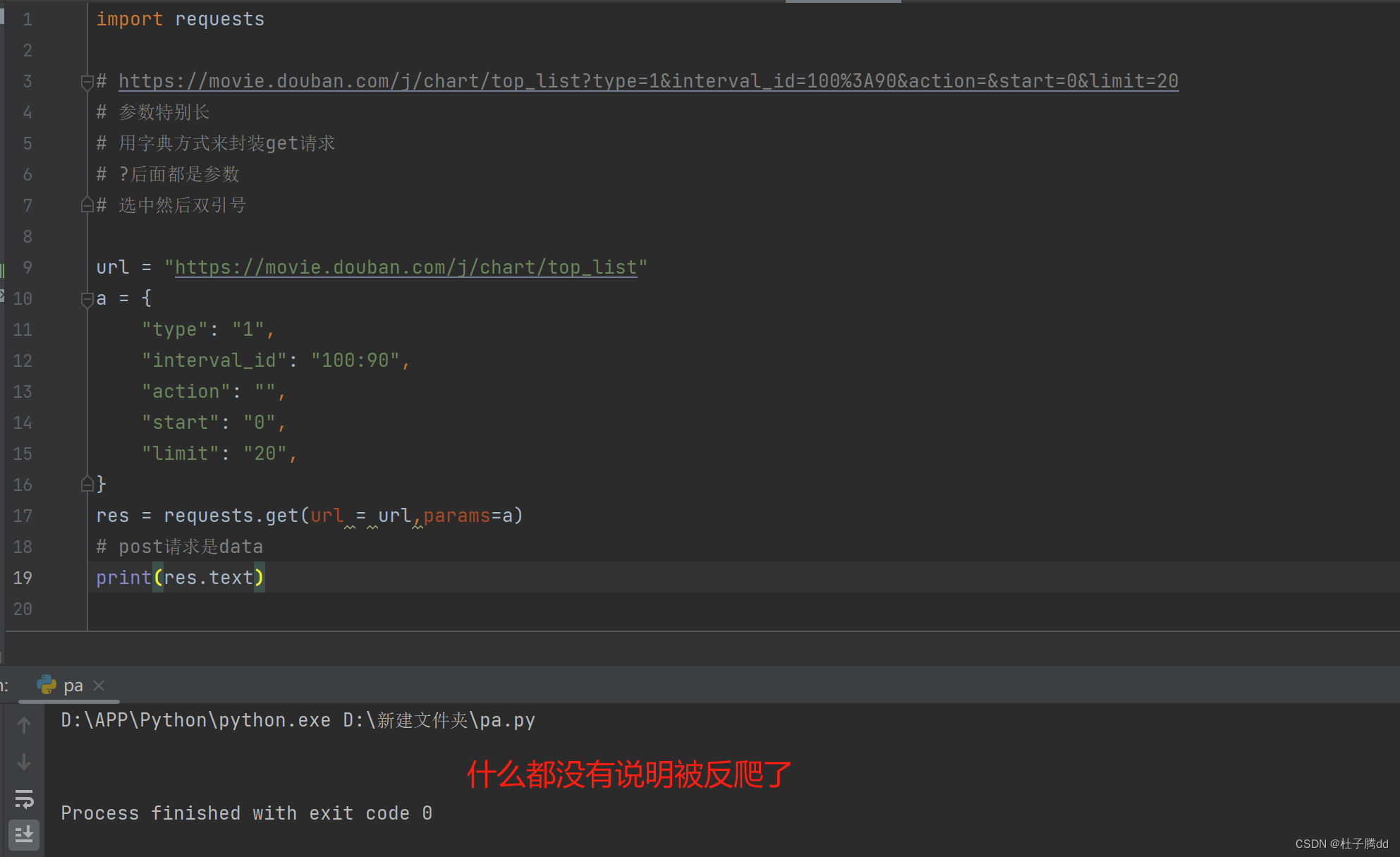
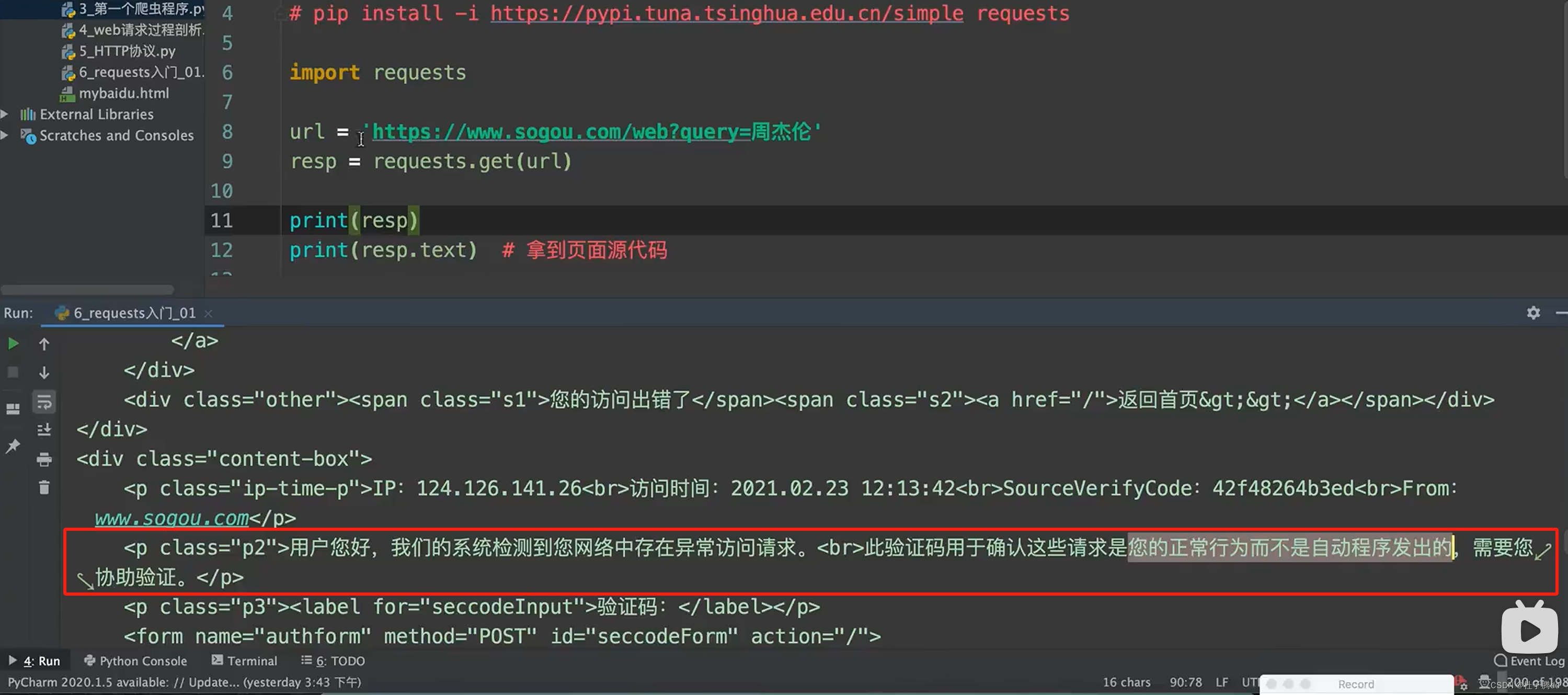 被抓到了,所以要让这个爬虫程序伪装成浏览器。
被抓到了,所以要让这个爬虫程序伪装成浏览器。
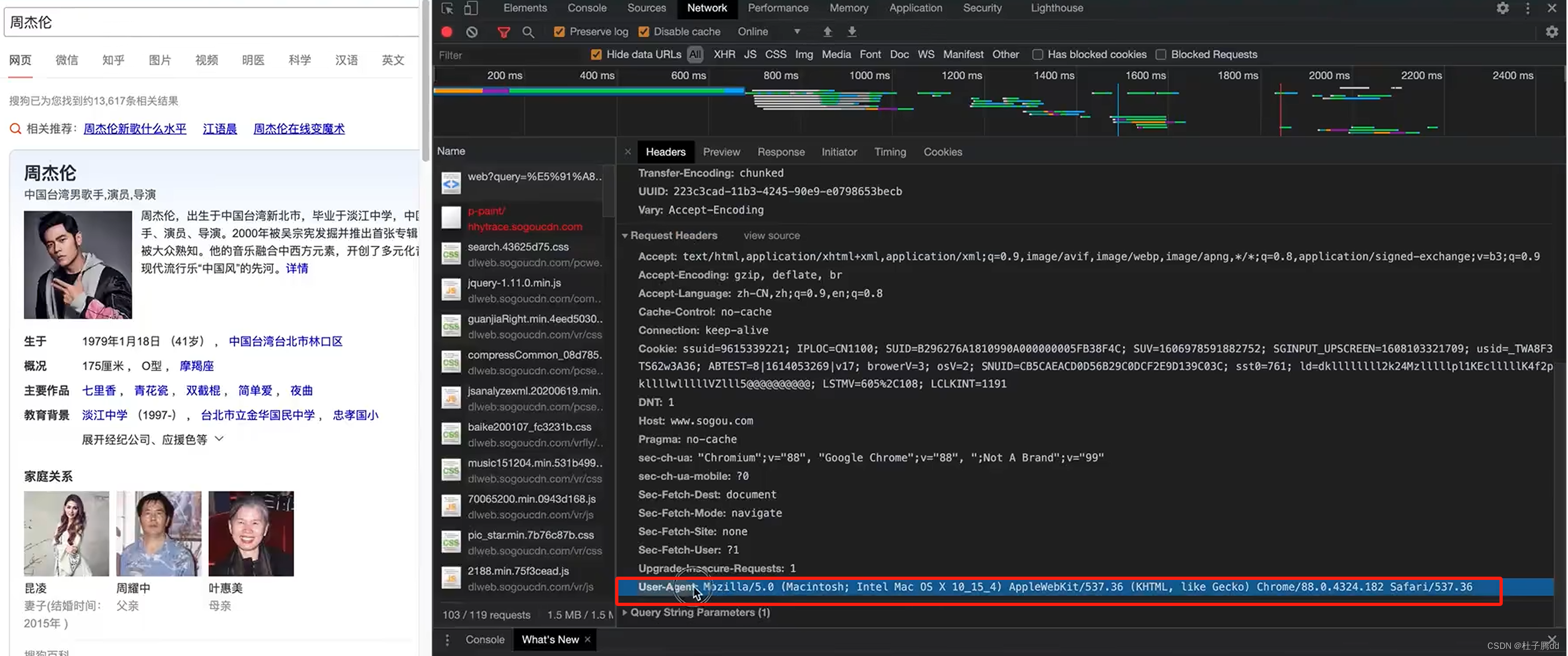
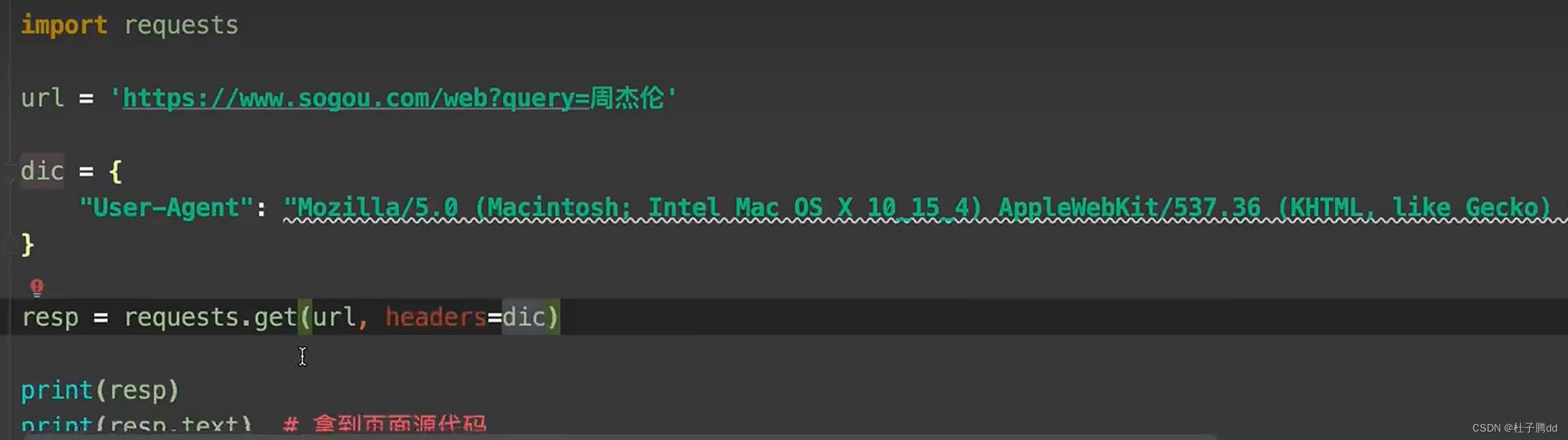
处理了一个小反爬。
如果默认 requests.get(url) 有一个自动化程序的 user agent ,伪装成浏览器就是加上请求头设备。
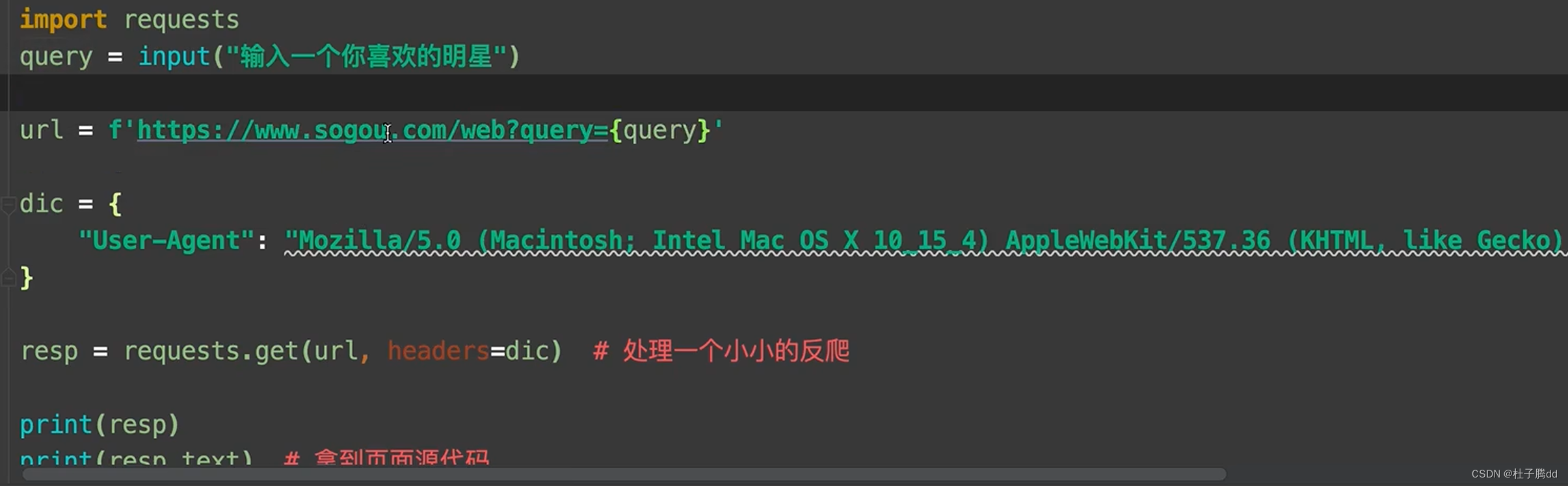
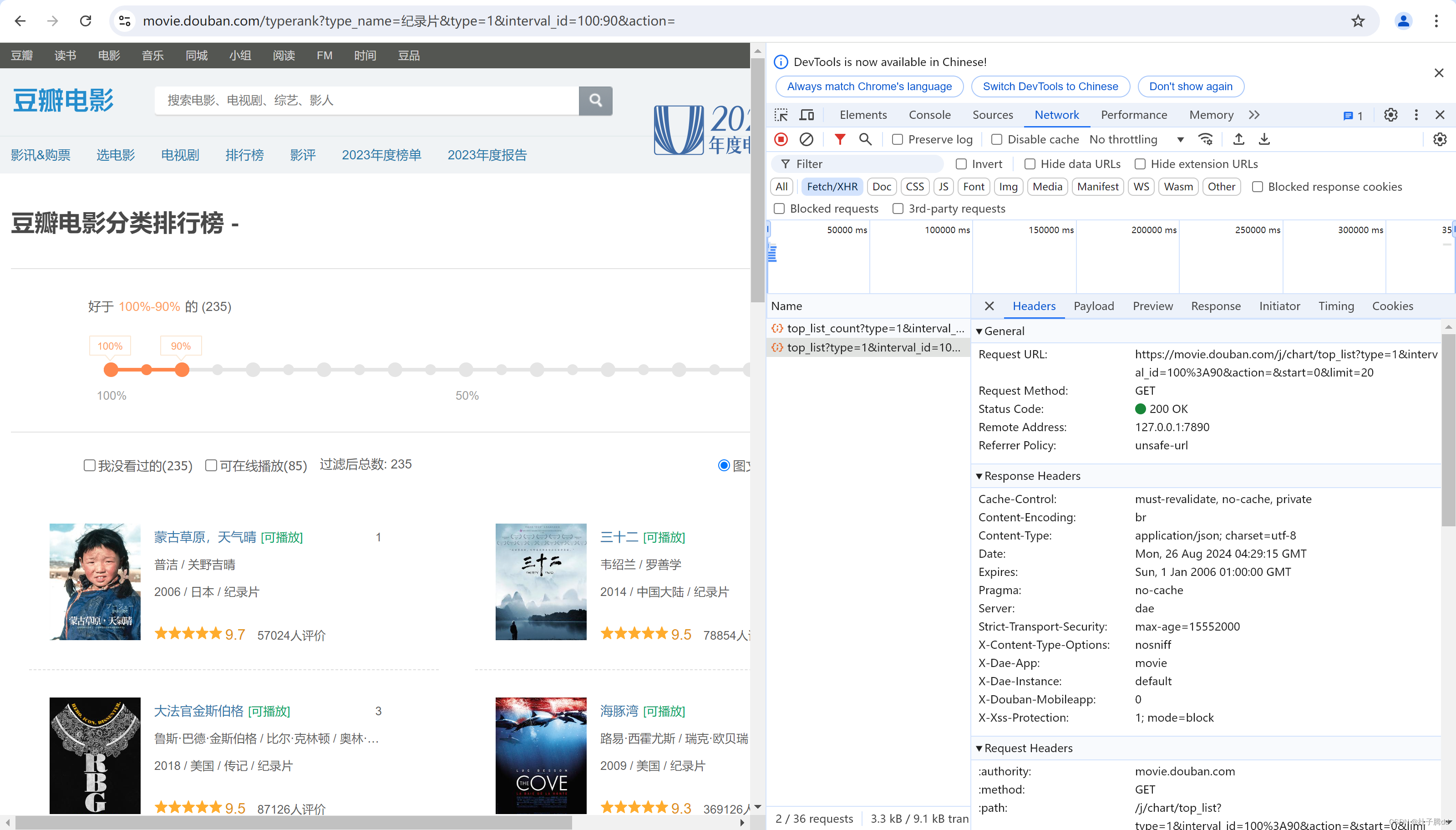
案例演示:获取百度翻译的结果。
F12,然后进入百度翻译界面,再清空network记录。
在翻译框里面输入一个单词,英文输入法。
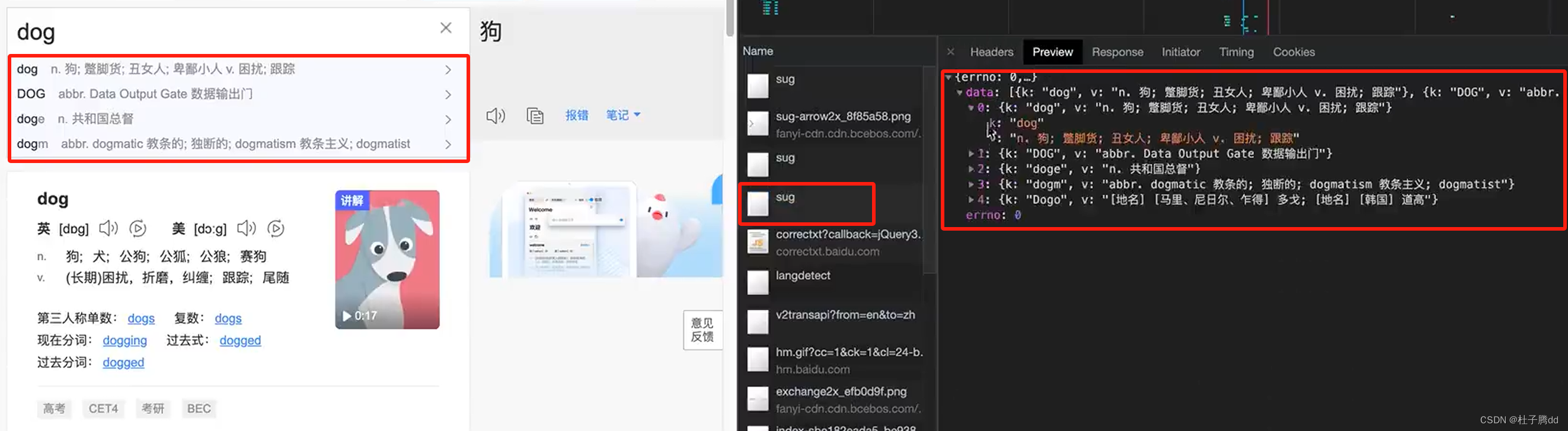
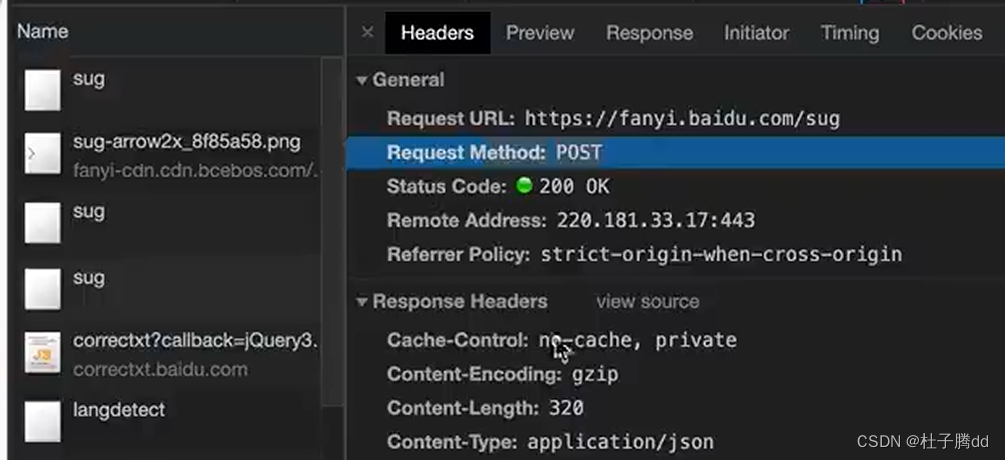
请求方式是post,最下面有一个Form Data,拉开后有个 kw:dog。(没有就是在payload里面)
用post发送请求,发送到参数就是 Form Data 。和get请求传参方式不一样。get发送到参数是query string parameter。重新整理了发送的参数。
get请求参数直接拼接在URL里面,https://sogou.com/web?query=周杰伦。?后面是参数。
post不能用这种方式。
三个sug分给是 d do dog




案例演示:获取百度翻译的结果。

要依次查看到底是什么原因。
1.useragent
默认的useragent是
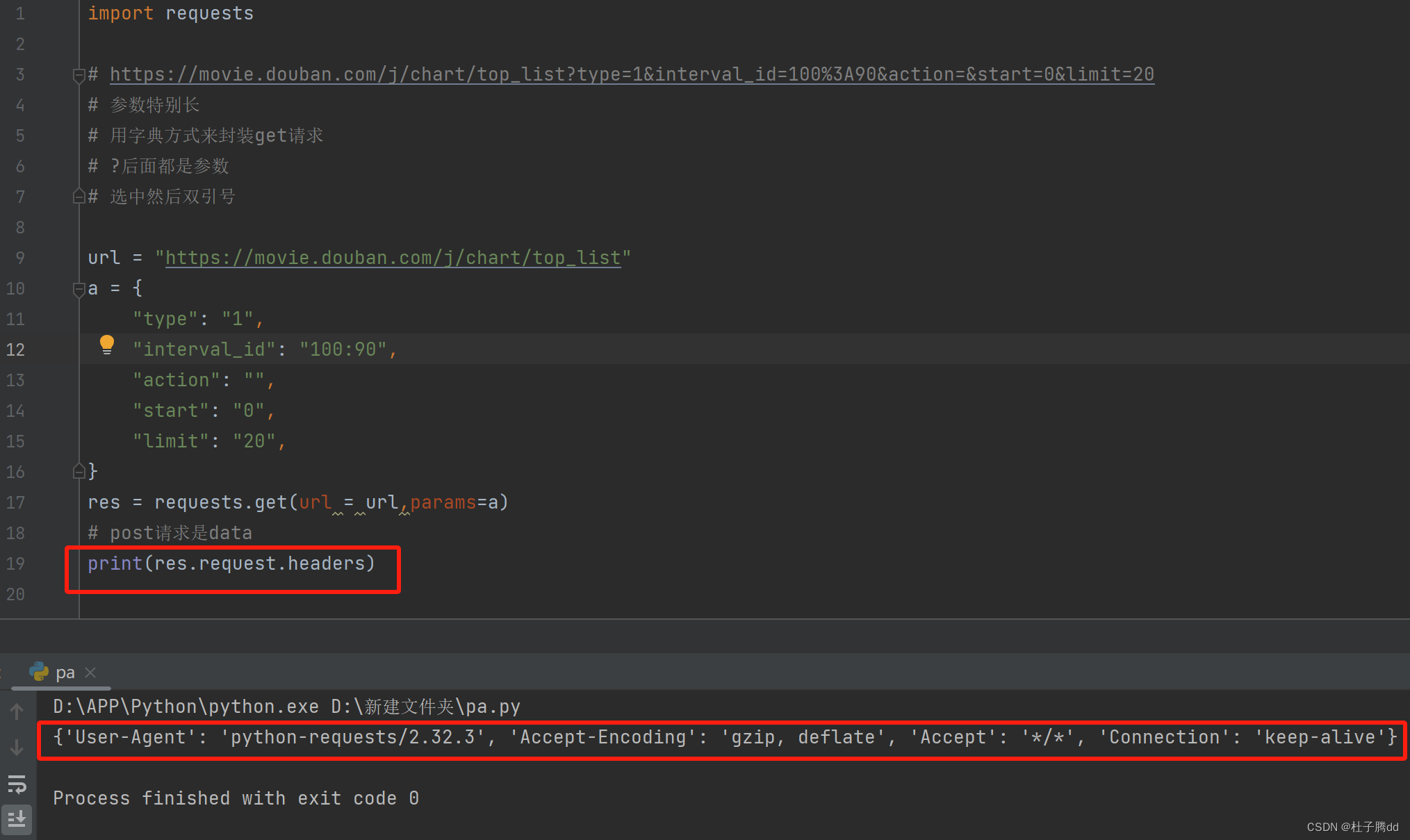
到浏览器中复制过来改。
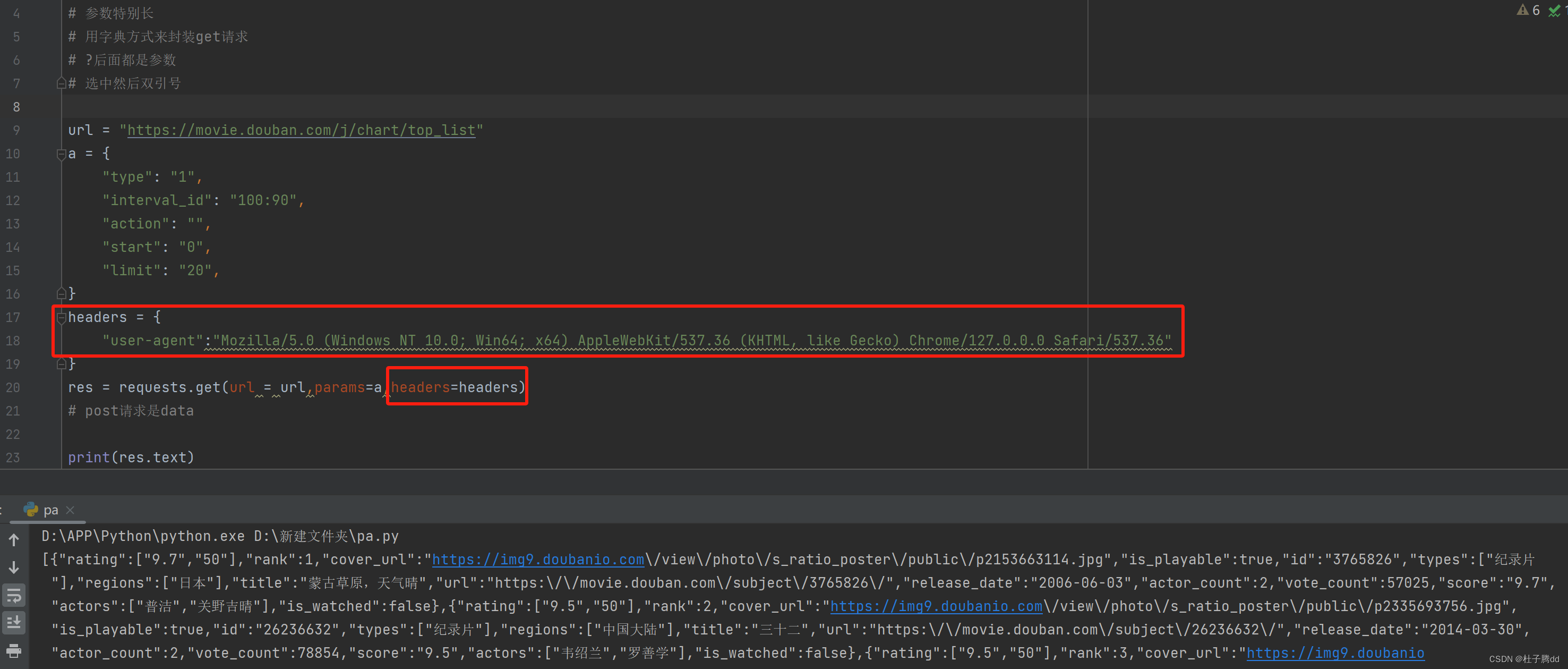
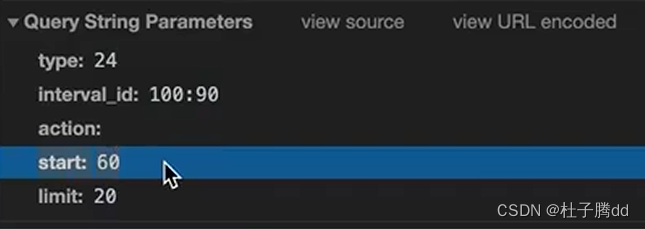
每次滚动加载这个start都会递增。
在爬完数据后要resp.close()
如果不关访问的次数过多后再去访问就会报错,你请求的地方被堵死。
创建,写入,关闭三件套















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









