






 本文介绍了朴素贝叶斯分类的基本概念,包括贝叶斯定理的应用、特征条件独立假设,以及其实现过程中的优点(如简单、高效)和局限性(如对相关特征的假设)。通过sklearn中的红酒数据集展示了代码实例。
本文介绍了朴素贝叶斯分类的基本概念,包括贝叶斯定理的应用、特征条件独立假设,以及其实现过程中的优点(如简单、高效)和局限性(如对相关特征的假设)。通过sklearn中的红酒数据集展示了代码实例。
朴素贝叶斯
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。朴素贝叶斯是一种基于贝叶斯定理和特征条件独立假设的分类方法,朴素贝叶斯分类同时也是贝叶斯分类中最简单,也是常见的一种分类方法
一、贝叶斯定理
- 什么是贝叶斯定理? *
- 在信息和条件有限的情况下,基于过去的数据,通过动态调整的方法,帮助我们一步步预测出事件发生的接近真实的概率。
在这个定理中有三个关键字:“基于过去的数据”,“动态调整”,“预测”。
我们使用《统计学习方法》中的例子来理解这三个关键词:

这个例子中有十五个样本,两个特征,一个标签,
X
(
1
)
=
{
1
,
2
,
3
}
X^{\left( 1 \right)}=\left\{ 1,2,3 \right\}
X(1)={1,2,3},
X
(
2
)
=
{
S
,
M
,
L
}
X^{\left( 2 \right)}=\left\{ S,M,L \right\}
X(2)={S,M,L} ,
Y
=
{
1
,
−
1
}
Y=\left\{ 1,-1 \right\}
Y={1,−1}。假设我们现在有一个新的样本,也就是第16个样本(x1,x2,y),y的取值无非是1或-1,至于到底是1还是-1我们是不清楚的,但是我们基于过去的数据发现Y=1的占9/15,Y=-1的占6/15,从这个概率上来看我们认为y=1(第16个样本的标签)的概率较大,我们把这个概率也就是
P
(
Y
=
1
)
=
9
15
P\left( Y=1 \right) =\frac{9}{15}
P(Y=1)=159 ,
P
(
Y
=
−
1
)
=
6
15
P\left( Y=-1 \right) =\frac{6}{15}
P(Y=−1)=156称为先验概率
当然,只有先验概率当然是不行的(光听名字也知道应该会有一个后验概率),在贝叶斯思维中,我们的基于过去的是数据做出的经验判断作出一个大致的判断,然后通过其他信息来调整我们的判断,得出最终结论。这个调整的方法就是上面关键词之一的“动态调整”,比如在Y=1的前提下,
X
(
1
)
=
1
X^{\left( 1 \right)}=1
X(1)=1的概率为
2
9
\frac{2}{9}
92,写成公式就是这个样子:
P
(
X
(
1
)
=
1
∣
Y
=
1
)
=
2
9
P\left( X^{\left( 1 \right)}=1|Y=1 \right) =\frac{2}{9}
P(X(1)=1∣Y=1)=92
就是所谓的条件概率,看到这里就有点贝叶斯公式那味了
P
(
Y
=
c
k
∣
X
=
x
)
=
P
(
X
=
x
∣
Y
=
c
k
)
∗
P
(
Y
=
c
k
)
P
(
X
=
x
)
P\left( Y=c_k|X=x \right) =\frac{P\left( X=x|Y=c_k \right) *P\left( Y=c_k \right)}{P\left( X=x \right)}
P(Y=ck∣X=x)=P(X=x)P(X=x∣Y=ck)∗P(Y=ck)
全概率公式变换得:
P
(
Y
=
c
k
∣
X
=
x
)
=
P
(
X
=
x
∣
Y
=
c
k
)
∗
P
(
Y
=
c
k
)
∑
k
P
(
X
=
x
∣
Y
=
c
k
)
P
(
Y
=
c
k
)
P\left( Y=c_k|X=x \right) =\frac{P\left( X=x|Y=c_k \right) *P\left( Y=c_k \right)}{\sum_k{P\left( X=x|Y=c_k \right) P\left( Y=c_k \right)}}
P(Y=ck∣X=x)=∑kP(X=x∣Y=ck)P(Y=ck)P(X=x∣Y=ck)∗P(Y=ck)
其中
P
(
Y
=
c
k
∣
X
=
x
)
P\left( Y=c_k|X=x \right)
P(Y=ck∣X=x)表示后验概率,
P
(
X
=
x
∣
Y
=
c
k
)
{P\left( X=x|Y=c_k \right)}
P(X=x∣Y=ck)表示条件概率(调整因子),
P
(
Y
=
c
k
)
{P\left( Y=c_k \right)}
P(Y=ck)表示先验概率,可以看出后验概率与先验概率和调整因子的乘积有关。
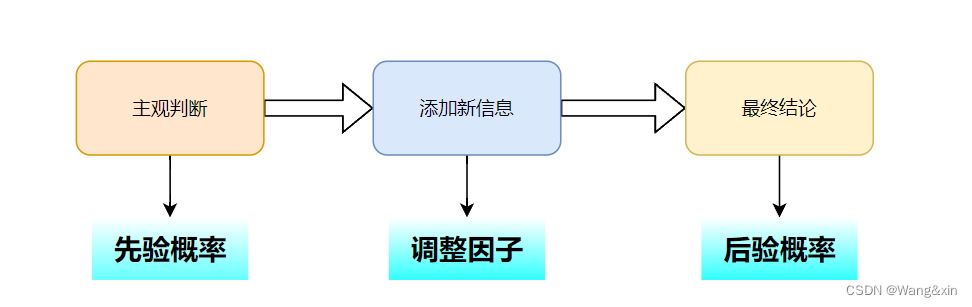
我们最终是一个分类问题,y的取值为后验概率最大的情况。
y
=
a
r
g
max
c
k
P
(
Y
=
c
k
∣
X
=
x
)
y=\underset{c_k}{arg\max}P\left( Y=c_k|X=x \right)
y=ckargmaxP(Y=ck∣X=x)
从这里就可以看出贝叶斯模型并不像判别模型样有具体的公式,而是通过最大概率得到最后的分类类别。
二、特征条件独立假设
- 朴素贝叶斯为什么朴素?
朴素贝叶斯分类器之所以被称为“朴素”,是因为它在建模时对特征之间条件独立性的假设过于简化,即它假定所有特征在类别判断中相互独立,并且每个特征对分类结果的贡献是独立计算的。这个假设在实际数据中往往并不成立,因为现实世界的数据特征往往是相关的或相互依赖的。
尽管如此,朴素贝叶斯算法依然因其这种简化的假设而具备几个突出的优点:
1.算法实现简单快速。
2. 对缺失数据不太敏感,可以处理大规模高维度数据集。
3.在某些应用中,即使特征之间存在一定的相关性,朴素贝叶斯仍然能够取得较好的分类效果。
因此,“朴素”一词在这里表示模型对于复杂性的忽略或者说是一种简化的策略,牺牲了对现实世界细节的高度模拟,以换取算法的高效性和可行性。
在李航的《统计学习方法》中对朴素贝叶斯的条件独立性假设是这样定义的:
P
(
X
=
x
∣
Y
=
c
k
)
=
P
(
X
(
1
)
=
x
(
1
)
,
.
.
.
,
X
(
n
)
=
x
(
n
)
∣
Y
=
c
k
)
=
∏
j
=
1
n
P
(
X
(
j
)
=
x
(
j
)
∣
Y
=
c
k
)
P\left( X=x|Y=c_k \right) =P\left( X^{\left( 1 \right)}=x^{\left( 1 \right)},...,X^{\left( n \right)}=x^{\left( n \right)}|Y=c_k \right) =\prod_{j=1}^n{P\left( X^{\left( j \right)}=x^{\left( j \right)}|Y=c_k \right)}
P(X=x∣Y=ck)=P(X(1)=x(1),...,X(n)=x(n)∣Y=ck)=j=1∏nP(X(j)=x(j)∣Y=ck)
代码示例
这里使用sklearn中自带的红酒数据集
import numpy as np
from sklearn.datasets import load_wine
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
import pandas as pd
wine_data = load_wine() # 导入数据
X = wine_data.data
feature_name = wine_data.feature_names
Y = wine_data.target
x_data = pd.DataFrame(data = X,columns=feature_name)
y_data = pd.Series(Y)
# 划分训练集和数据集
# length = len(y_data)
# x_train = x_data[:int(length*0.7)]
# y_train = y_data[:int(length*0.7)]
# x_test = x_data[:(length-int(length*0.7))]
# y_test = y_data[:(length-int(length*0.7))]
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=0) # random_state=0,打乱数据集
# 创建模型(使用高斯贝叶斯模型)
clf = GaussianNB(var_smoothing=1e-9) #‘var_smoothing’添加到每个特征方差的平滑项
clf.fit(x_train, y_train)
# 评估
y_pred = clf.predict(x_test)
# 计算准确率
acc = np.sum(y_test == y_pred) / x_test.shape[0]#'shape[0]样本数,行数'
print("Test Acc : %.3f" % acc)
# 预测
y_proba = clf.predict_proba(x_test)
print(clf.predict(x_test))
print("预计的概率值:", y_proba)
预测结果如下:

总结
- 优势:模型简单易于理解;对小规模数据集和大规模高维稀疏数据具有高效处理能力;训练速度快,实时性强;即使在特征间相关性的假设不准确时,仍可能达到较好的性能。
- 局限:由于其“朴素”假设往往过于简化,当特征之间存在强烈依赖关系时,分类性能可能会受到影响;对于非独立特征的数据,朴素贝叶斯分类器的效果可能不如那些能够捕捉到特征交互作用的方法。
















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











