






一、环境部署
环境部署:
安装python3.7以上版本,才能够支持Selenium4 Python官网:Welcome to Python.org
指令:pip install selenium 下载selenium如果觉得下载太慢可以添加国内源
安装webdriver,一定要确保webdriver与浏览器类别一致,以及版本一致,另外chrome会自动更新,一定要关闭自动更新按钮,否则就会出现chrome和webdriver版本不一致的情况
chrome与ChromeDriver
Firefox与geckodriver
edge与edgedriver
Safari与safaridriver
webdriver的官方下载路径:https://chromedriver.storage.googleapis.com/index.html
对于Windows:将下载好的chromedriver解压exe文件到python的安装路径下即可,对于mac,将下载好的chromedriver解压到python的安装路径下即可
核心关键,你的浏览器一定要安装在默认路径下才可以。如果不在默认路径下,则会要配置其他的内容。(默认路径就是一直next就行,不需要任何其他操作)
二、如何准确定位元素
以下方法可以非常准确的定位元素
右键-》检查-》点击右上角的三个点-》点第一个图标(不要内嵌进去,要弹出来,如果内嵌可能会导致一些问题,做元素的定位就会更加准确)
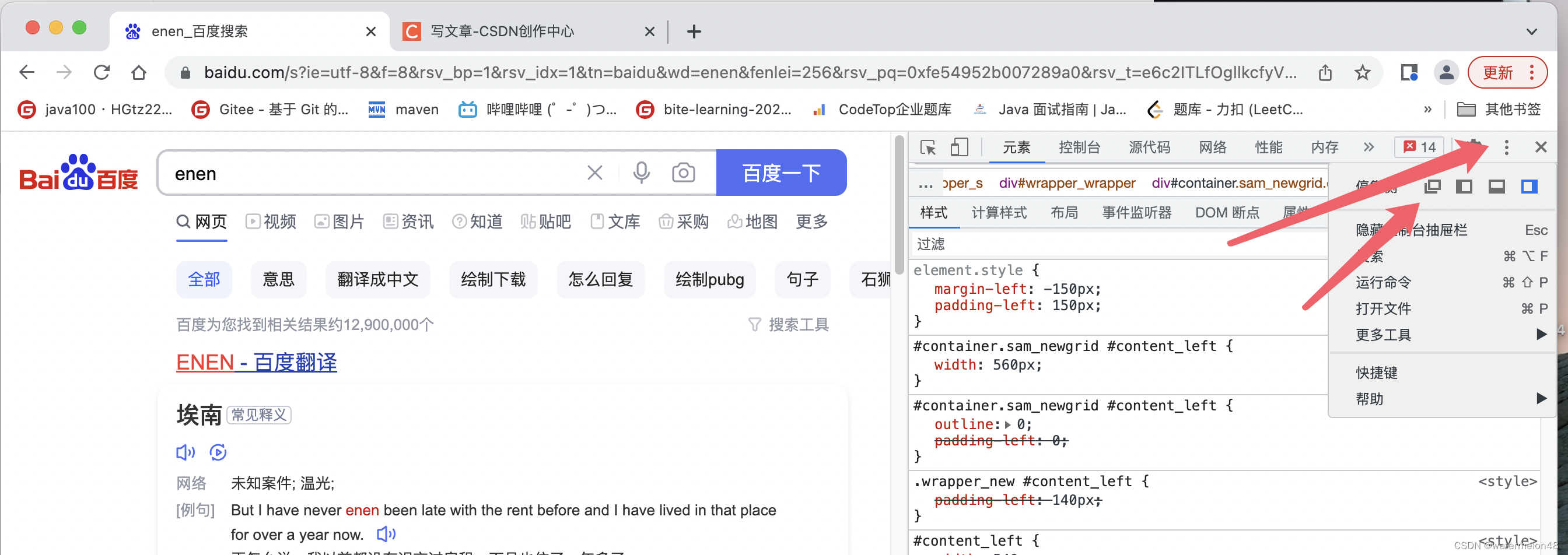
点击左上角的图标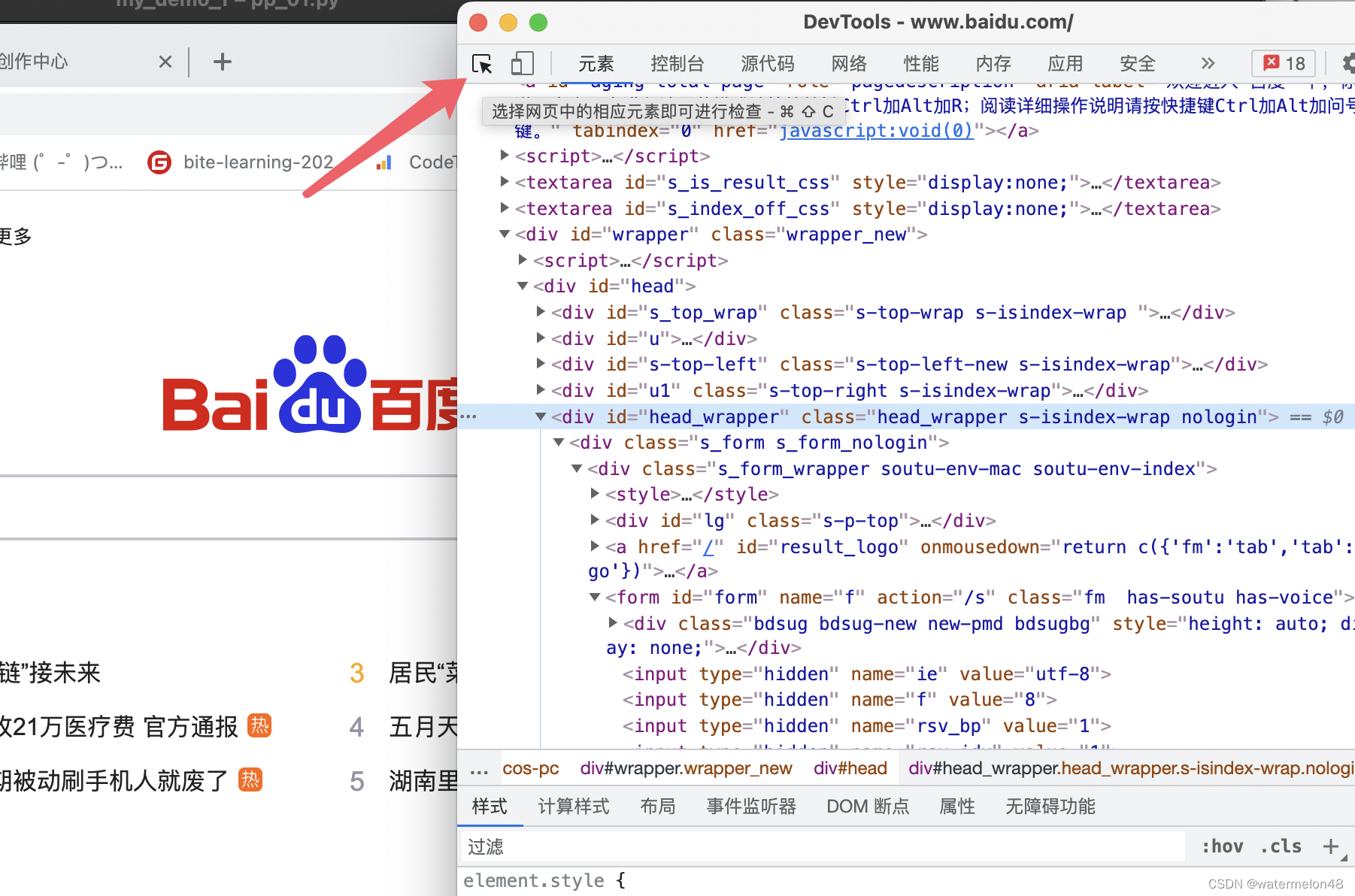
我们停留在百度的输入框,点击之后就会跳转到元素定位页面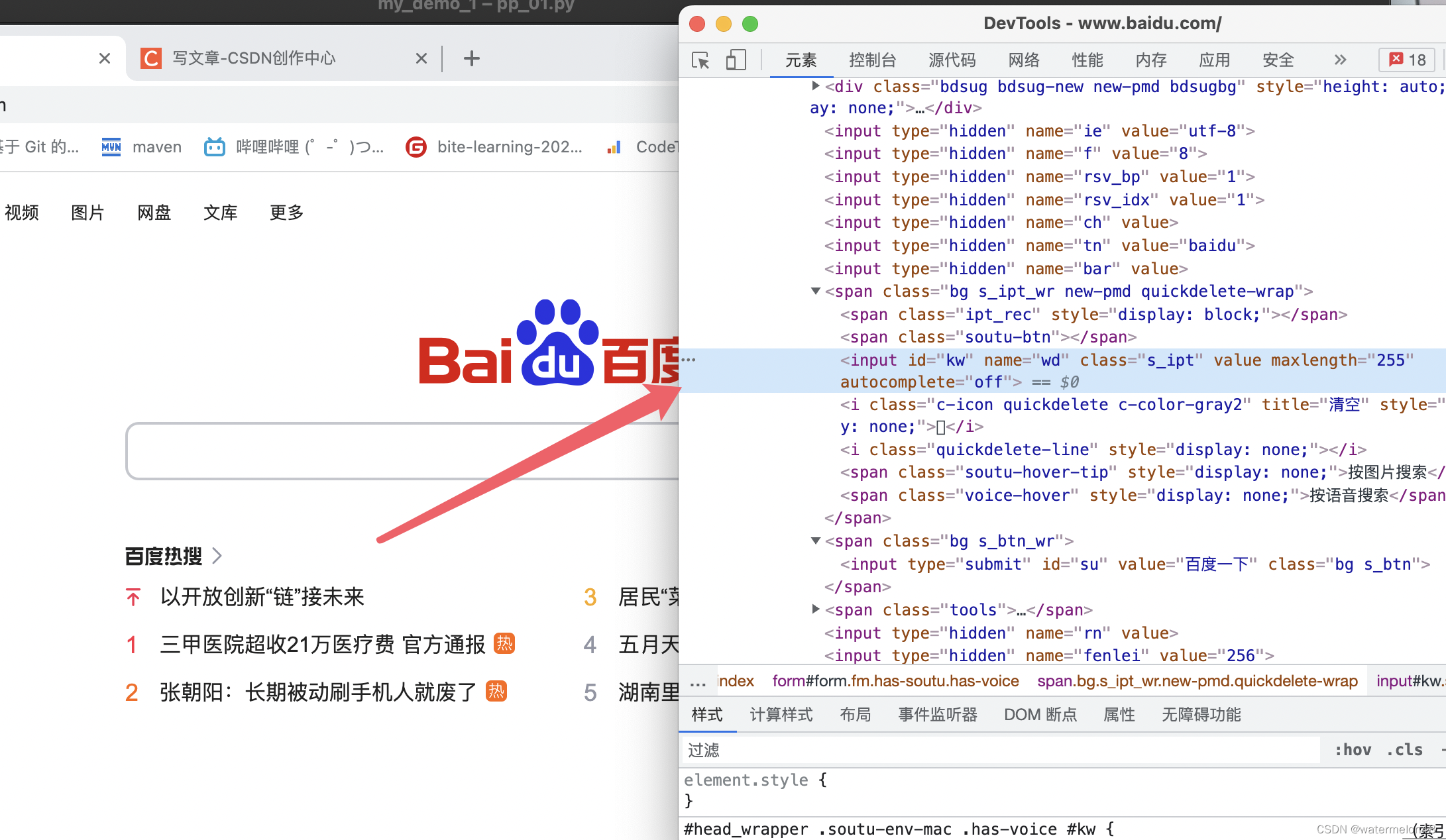
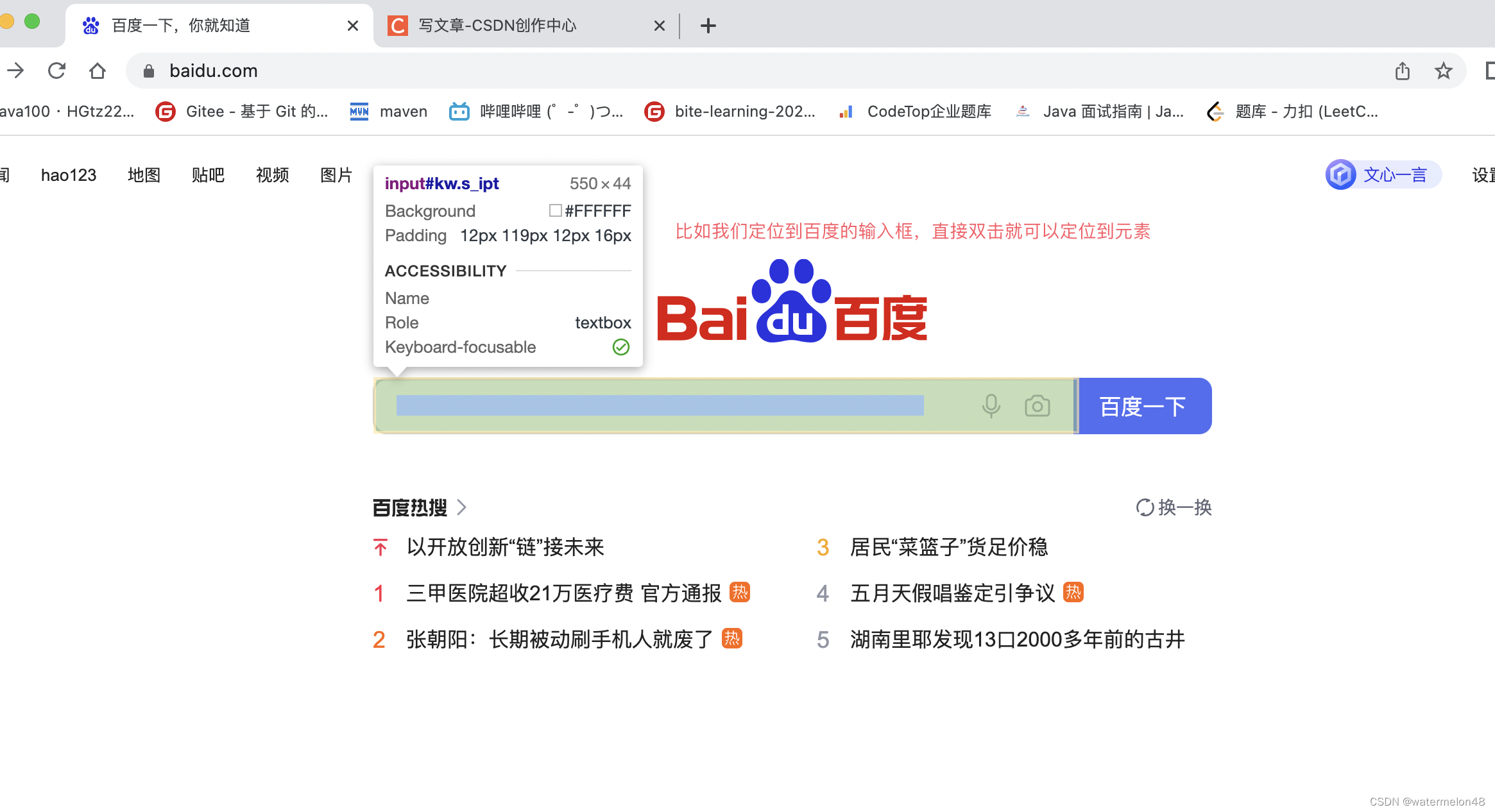
准确找到要定位的元素是前提,接下来我们就可以利用常见的定位元素的方法来进行操作。
三、实现自动化的具体步骤
- 创建浏览器对象
- 访问指定的url,url需要是完整的路径
- 定位到想要操作的元素
- 对定位的元素,通过调用一些方法,实现自动化
四、一个demo实战
实战:定位到百度输入框,实现搜索
from selenium import webdriver
from time import sleep
# 先生成一个浏览器对象
driver = webdriver.Chrome()
# 访问指定的url,url的全部内容一个也不能少
driver.get("http://www.baidu.com")
# 定位到元素,获取输入框元素
el = driver.find_element(by='id', value='kw')
# 输入内容
el.send_keys("自动化")
# 定位到百度一下按钮,获取该元素
el1 = driver.find_element(by="id", value="su")
# 点击一下该按钮
el1.click()
sleep(20)
五、定位元素的八大方式
八大元素定位法则:
1.id:通过元素的id属性来进行元素的获取,一般id都是不会重复的,类似人的身份证
2.name:通过元素的name属性进行元素的获取,一般有可能会重名,类似于人的名字
3.tag name:通过元素的标签名来进行元素的获取,一定会重名,一般在自动化中一般不用。一般在爬虫领域下会用。
4.class name:通过元素的class属性进行元素的获取,不是特别推荐,class的值会特别长,所以在读代码的时候不会特别友好
5.link test: 通过元素的文本进行定位,只能用于a标签进行定位
6.partial link text:与link test一样,只能通过文本进行定位,只能说通过模糊查找到方式进行元素的定位,也是只能用于a标签
7.css selector:定位界的万金油,核心是通过class属性进行定位
8.xpath:定位界的万金油,是基于树状结构进行定位
元素定位的方法:
find_element(by,value)
如果元素在定位过程中有重复属性,导致定位无法精准,selenium定义下,如果有多个元素相同,默认返回第一个获取到的元素
5.1定位元素的三种书写方式
一般情况下,定位元素有三种书写方式
1.driver.find_element('id','header') 2.driver.find_element(By.ID,'header') 3.driver.find_element(by='id',value='header')
5.2 id元素定位
driver.find_element('id','header')5.3 name元素定位
driver.find_element('name','q')5.4 tag name元素定位
driver.find_element('tag name','input')5.5 class name元素定位
driver.find_element('class name','fl js_topSearch seachBtn')5.6link test元素定位
driver.find_element('link text','特殊场合')5.7partial link text元素定位
driver.find_element('partial link text','婚')5.8css元素定位
driver.find_element('css selector','#owl-fecshop > div.owl-wrapper-outer > div > div:nth-child(2) > div > a > img')css元素定位方式稍微有点特殊,通过图示的方法,定位到元素之后,右键-》copy-》copy css xpath元素定位方式类似,只是复制的是xpath
5.9xpath定位元素
通过上述类似于xpath的方式进行元素定位
driver.find_element('xpath', '//*[@id="owl-fecshop"]/div[1]/div/div[2]/div/a/img')5.10 xpath详解
xpath定位方法:根据树状结构来进行元素的获取,类似于操作系统的文件系统,因为需要从html标签开始查找,所以整个元素定位的速度相对css selector会更慢一些。
在元素定位和自动化执行的过程中,我们最优先关注的是稳定性,再才是效率
相对路径和绝对路径的概念:
绝对路径:/html/body/div[1]/div/div[1]/div/div/div/div/div[1]/div 阅读太差,维护太差,所以基本不会使用绝对路径来定位元素,除非实在搞不定
相对路径:
//* [@alt]
//*[@rel="nofollow" and @class="mycoount"]
//*[@id="owl-fecshop"]
//*[text()="我的账户"]
// 从根路径下开始查找
* 任意元素
[] 添加筛选条件
@ 表示基于属性来查找
id 表示属性名称
="owl-fecshop" 表示属性的值
and 表示多条件筛选
xpath的进阶:
xpath的进阶:
1. 元素定位,在开发者工具中,直接通过ctrl+F的搜索框进行元素的确认即可
2. 是可以相对路径+绝对路径来进行定位的:
查找子级:
//li[@class="store_lang"]/a
查找父级:
//li[@class="store_lang"]/..
3. xpath支持函数的应用,主要使用的函数是contains()
//a[contains(text(),"中")]
//a[contains(@id,"中") and @rel and @class]
4. 一定用手写xpath,不要用复制的xpath
1. 提升可读性与维护性
//li[@class="store_lang"]/..
2. 随着经验增加,手写会更加有效率
3. 提升元素定位的准确性
1. 前端界面的质量决定
2. 解决动态元素的定位:动态元素,即属性会动态改变的元素
5. 伪元素:正常定位即可
六、selenium的常见操作
6.1常见操作
创建浏览器驱动对象,生成浏览器session
driver = webdriver.Chrome()访问url:一定要加完整的url内容
driver.get('http://music.163.com')窗体最大化:从Selenium2开始,窗体最大化方法已经很少用了,因为会有bug,可能会导致浏览器超时异常
driver.maximize_window获取标签页的title:用于判断是否进入到指定的页面,仅此而已,调试的时候可以用一用。
driver.title
窗体的尺寸设置
#driver.set_window_size(1080, 5080)查找元素:Selenium支持单个元素获取和多个元素获取。只是多个元素获取的方法一般很少用。
单个元素获取
driver.find_element()多元素获取,默认是返回一个list,不管最终获取的是1个元素还是多个元素,都是以list类型返回,如果要操作,需要通过for循环操作。
driver.find_elements(by, value)输入:send_keys只能够对input标签来进行使用,同时sendKeys可以上传文件,也仅限于input标签
driver.find_element('id', 'kw').send_keys(txt)文件上传
driver.find_element('xpath', '//input[@type="file"]').send_keys(完整文件路径)点击操作:click,不限定元素类型
driver.find_element(by, value).click()悬停操作:将光标移动至指定的元素上,悬停操作过程中,不要动鼠标,否则悬停会失效
ActionChains(driver).move_to_element(driver.find_element('xpath', '//span[text()="设置"]')).perform()下拉列表框的操作
driver.find_element('xpath', '//li[@class="item"]').click()close:关闭标签页,关闭当前的标签页,但是不会关闭浏览器,只有在一个标签页的时候会关闭浏览器,但是不会结束后端进程,webdriver服务不会停止
driver.close()sleep(5)
quit:关闭整个浏览器,结束后端进程,停止webdriver服务,在最后一定记得调用quit方法结束整个服务
driver.quit()
6.2下拉框详解
在页面中的下拉列表框分为三种类型:
1. 基于input标签来实现的:常见于日期控件的实现
2. 基于div标签来实现的:常见于值的选择
3. 基于select标签来实现:最传统的实现方式,现在不用这种
如果是input标签和div标签,则通过点击下拉列表框元素,再点击值,两次click操作实现值的选择,这是最稳妥的方式
如果是input标签,还可以通过修改input标签的属性,去掉readonly,然后用sendKeys方法来进行值的传入,目前而言容易失败如果是select标签,Selenium有专门针对select标签的操作行为
<select id="select">
<options value="a">1</options>
<options value="b">2</options>
<options value="c">3</options>
<options value="d">4</options>
</select>
driver.find_element('xpath', '//div[@class="c-select-selection"]').click()
driver.find_element('xpath', '//p[text()="最近一年"]').click()针对select标签实现下拉列表框的选值操作
select = Select(driver.find_element("id", "select"))
- 基于下标进行选值:从1开始 select.select_by_index(1)
- 基于value值进行选值 select.select_by_value('b')
- 基于值的文本信息来选值 select.select_by_visible_text('3')
6.3特殊操作——句柄
handles:句柄,浏览器的每一个标签页,都是一个句柄
默认打开的浏览器,都是聚焦在第一个标签页,Selenium不会自动切换标签页
如果在运行Selenium时需要切换到新的标签页来进行操作,则需要进行句柄的切换
实际操作过程中,尽可能保持最多不超过两个标签页存在,一般都是关一个,再换一个
不切换句柄无法操作新的标签页,从而导致流程的失败
一般情况下,句柄的操作是固定格式
句柄的切换
handles = driver.window_handles # 获取浏览器的所有句柄
driver.close()
driver.switch_to.window(handles[1])
print(driver.title)
driver.close()
driver.switch_to.window(handles[0])
print(driver.title)6.4特殊操作——iframe
iframe窗体:内嵌在浏览器之中的独立窗体,这个窗体中的所有的内容都无法直接通过driver来获取
如果说遇到iframe窗体,则需要先切换进入iframe,再操作iframe里的元素,操作完成以后再切换出iframe,进行其他操作
如果在操作自动化的过程中,遇到怎么都定位不到的元素,检查了也确实没有问题,记得看看页面结构是否该元素在iframe之中
实现网易云QQ登录的演示,代码没错,但是还是报错了,事例如下:
# 实现网易云登录
driver.get('http://music.163.com')
driver.maximize_window()
sleep(1)
driver.find_element('link text', '登录').click()
sleep(1)
driver.find_element('link text', '选择其他登录模式').click()
sleep(1)
driver.find_element('id', 'j-official-terms').click()
sleep(1)
driver.find_element('link text', 'QQ登录').click()
报错了是为什么呢?
主要原因是QQ登录在iframe窗体里面
iframe窗体,是内嵌在浏览器中的独立窗体,这个窗体里面的内容,都不能通过driver直接获取
所以正确的写法应该是如下:
# 实现网易云登录
#这里大量使用sleep方法,是为了更加直观的看到各个页面的跳转
driver.get('http://music.163.com')
driver.maximize_window()
sleep(1)
driver.find_element('link text', '登录').click()
sleep(1)
driver.find_element('link text', '选择其他登录模式').click()
sleep(1)
driver.find_element('id', 'j-official-terms').click()
sleep(1)
driver.find_element('link text', 'QQ登录').click()
sleep(1)
handles = driver.window_handles # 获取浏览器的所有句柄
# driver.close()
driver.switch_to.window(handles[1])
sleep(3)
# 切换iframe
driver.switch_to.frame(driver.find_element('id', 'ptlogin_iframe'))
driver.find_element('id', 'img_out_2375154305').click()
#一般情况下切换进iframe之后,还要再切换出来,由于这里实现登录了之后,就会直接关闭页面,
#所以不需要再从iframe切换出来
# 从iframe中切换回默认窗体:事例
driver.switch_to.default_content()
sleep(3)
driver.switch_to.window(handles[0])
print(driver.title)
sleep(10)
七、selenium4新增操作
Selenium4新增浏览器有用的行为:
- 自动生成新的标签页
- 自动生成新的浏览器
所有的标签页和浏览器都是通过句柄来控制,如果要切换回旧的页面或者浏览器,切换句柄即可
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
生成新标签页,并自动切换句柄到新的标签页
driver.switch_to.new_window('tab')
生成新的浏览器,并自动切换过去
driver.switch_to.new_window('window')
driver.get('http://www.baidu.com')















 1225
1225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









