







如何生成模拟数据?选择最合适的生成模拟数据方法!
😀大家好!我是向阳🌞,一个想成为优秀全栈开发工程师的有志青年!
📔今天来教大家在实现一个接口后,我们想要插入大量假数据进行测试接口,那么我们该如何插入大量假数据,以及提高生成这些假数据的速率,根据情况进行选择这些方法😊。
前言
假如我们在开发一个用户管理平台,在我们开发完其中的用户相关接口后,我们需要插入一些用户假数据对接口进行测试,我们要面临下面三个问题。
- 我们该如何生成这些假数据呢?
- 我们生成这些假数据的效率如何呢吗,我们该如何选择这些方法?
- 我们如何提高生成、插入这些假数据的速率呢?
下面我们来以此解决这些问题。
几种生成假数据方法
Excel数据导入
这种数据方法的导入,我认为适合你跟前有现成的Excel表数据,要不然一条一条自己输入还是很麻烦的。
在Java中,我们可以集成 easyexcel 来实现通过Excel表数据的导入导出。
Java集成easyexcel

1.导入依赖
<!-- https://mvnrepository.com/artifact/com.alibaba/easyexcel -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.3.2</version>
</dependency>
2.编写读取Excel数据代码
这里我们观看官方文档给出的方法,这里我使用最简单的方法即可,不自定义监听器,我们只是简单的导入一些数据。
我们首先创建一个测试的Excel表,表列的名称要与下述实体类规定的名称相同。

把该表移动到你编写代码的软件中,我这里用的是IDEA。

编写用户实体类:
@ExcelProperty 是规定该变量对应Excel表的列名称。
@Data
public class UserExcelTable implements Serializable {
/**
* 用户昵称
*/
@ExcelProperty("用户昵称")
private String username;
/**
* 用户账号
*/
@ExcelProperty("用户账号")
private String userAccount;
/**
* 用户性别
*/
@ExcelProperty("用户性别")
private Integer gender;
@TableField(exist = false)
private static final long serialVersionUID = 1L;
}
读取Excel表代码逻辑:
这里我们采用的是最简单的读取Excel表方式,如果有其他需求可以查看官方文档。
@Slf4j
public class ImportExcel {
public static void main(String[] args) {
// 写法1:JDK8+ ,不用额外写一个DemoDataListener
// since: 3.0.0-beta1
// fileName改成自己的xlsx文件地址
String fileName = "D:\\Javawebcodemaven\\myproject\\yupi\\user-manage\\user-center\\importExcel.xlsx";
// 这里默认每次会读取100条数据 然后返回过来 直接调用使用数据就行
// 具体需要返回多少行可以在`PageReadListener`的构造函数设置
// UserExcelTable是作者定义的实体类,这里可以改成自己编写的实体类名称
EasyExcel.read(fileName, UserExcelTable.class, new PageReadListener<UserExcelTable>(dataList -> {
for (UserExcelTable demoData : dataList) {
log.info(demoData.toString());
}
})).sheet().doRead();
}
}
我们可以看见打印结果是正确的,接下来如何把这些数据保存到数据库就不用多介绍了吧。

编写SQL语句
这种方式适用于数据量较小的数据,编写大量SQL语句也不是一件轻松的事情,我们可以借助AI来帮我们生成数据,但是我们如果要插入百万甚至千万级别的数据呢,就算用AI也要花费很长很长时间吧。
AI生成
我们在这里简单介绍一下如何用AI来生成一些插入SQL语句吧。这里我们使用 Kimi 来生成,在另一篇文章博主有介绍过这款AI工具,大家可以点击这个链接(一键生成PPT的AI工具-Kimi!)简单查看。Kimi官网地址:https://kimi.moonshot.cn/
我们向AI简单提问,像我下面这样。
现在我要编写一些Insert SQL语句,来插入部分测试数据,表名为user,有三个字段,userName、userAccount、gender,请帮我生成100条插入语句。
下面是AI的回答:
当然可以帮你生成一些插入语句。这里是一个简单的模板,你可以根据自己的需求调整用户名、账户名和性别:
sql
INSERT INTO user (userName, userAccount, gender) VALUES ('用户名', '账户名', '性别');
下面是100条插入语句的示例,其中用户名和账户名使用了随机生成的字符串,性别随机为'male'或'female':
sql
INSERT INTO user (userName, userAccount, gender) VALUES ('User001', 'Account001', 'male');
INSERT INTO user (userName, userAccount, gender) VALUES ('User002', 'Account002', 'female');
INSERT INTO user (userName, userAccount, gender) VALUES ('User003', 'Account003', 'male');
...
INSERT INTO user (userName, userAccount, gender) VALUES ('User100', 'Account100', 'female');
如果你需要自动化生成这些数据,你可以使用编程语言(如Python)来生成这些语句。以下是一个简单的Python脚本示例,用于生成上述的SQL语句:
python
for i in range(1, 101):
gender = 'male' if i % 2 == 0 else 'female'
print(f"INSERT INTO user (userName, userAccount, gender) VALUES ('User{i:03d}', 'Account{i:03d}', '{gender}');")
这个脚本会生成100条插入语句,其中i:03d确保了编号是三位数,不足的前面补零。你可以直接运行这个脚本来生成你需要的SQL语句。
我们按照AI给出的方法就可以生成这些SQL语句并运行,但是这种方法的效率好像还是太低了。
编写代码程序
我认为编写代码来插入数据是最好的方法了,我们可以很简单的控制插入数据的数量,还可以不断测试优化,提高插入数据的速率。
我们这里采用 StopWatch来计时,这是Spring内置的工具,不用引入其他依赖。当然你也可以采用 System.currentTimeMillis() 来获取时间进行计算。
下面采用三种方法,逐步优化插入数据的时间。
最传统的单条数据插入
单挑插入数据就不过多介绍了,就是新建对象,设置属性值,用mybatis的保存方法保存到数据库中,单挑插入数据时间会有点长,我们这里先插入十万条数据看看会用多长时间。
示例代码:
@Test
void doInsertUser() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 要插入的数据条数
final int INSERT_NUM = 100000;
for (int i = 0; i < INSERT_NUM; i++) {
// 创建对象
User user = new User();
user.setUsername("寿司" + i);
user.setUserAccount("测试新品寿司" + i);
user.setUserPassword("12345678");
user.setTags("[]");
user.setAvatarUrl("https://gw.alipayobjects.com/zos/rmsportal/KDpgvguMpGfqaHPjicRK.svg");
user.setGender(0);
user.setPhone("123123123");
user.setEmail("123123@qq.com");
user.setUserStatus(0);
user.setUserRole(0);
// mybatis的插入数据方法
userService.save(user);
}
stopWatch.stop();
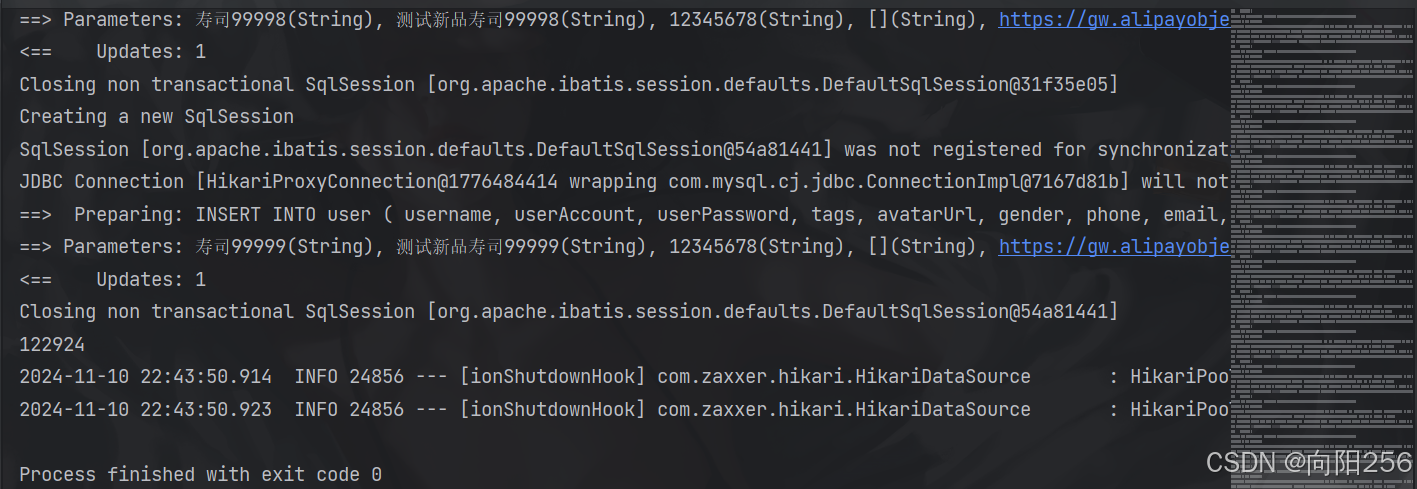
System.out.println(stopWatch.getTotalTimeMillis()); // 运行时间:122924ms
}
我们可以从下图看出单次插入十万条数据,我们用了整整两分钟,这效率已经算很低了。虽然这是在没有预热的情况下,估计预热后时间会稍微短一点。
我们不难知道,为什么时间会这么长呢,因为我们每次循环添加数据时,在频繁的连接释放数据库,这花费了大量时间。所以我们下一步的解决方法是减少对数据库的连接次数。
一次插入多条数据
这里我们使用mybatis-plus提供的 saveBatch() 方法,一次插入批量数据,第一个参数是一个集合,第二个参数是一次插入多少条数据。
示例代码:
/**
* 批量插入用户
*/
@Test
void doInsertUsers() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 要插入的数据条数
final int INSERT_NUM = 100000;
// 用户数据集合
List<User> userList = new ArrayList<>();
for (int i = 0; i < INSERT_NUM; i++) {
User user = new User();
user.setUsername("寿司" + i);
user.setUserAccount("测试新品寿司" + i);
user.setUserPassword("12345678");
user.setTags("[]");
user.setAvatarUrl("https://gw.alipayobjects.com/zos/rmsportal/KDpgvguMpGfqaHPjicRK.svg");
user.setGender(0);
user.setPhone("123123123");
user.setEmail("123123@qq.com");
user.setUserStatus(0);
user.setUserRole(0);
userList.add(user);
}
// 一次插入一万条数据
userService.saveBatch(userList, 10000);
stopWatch.stop();
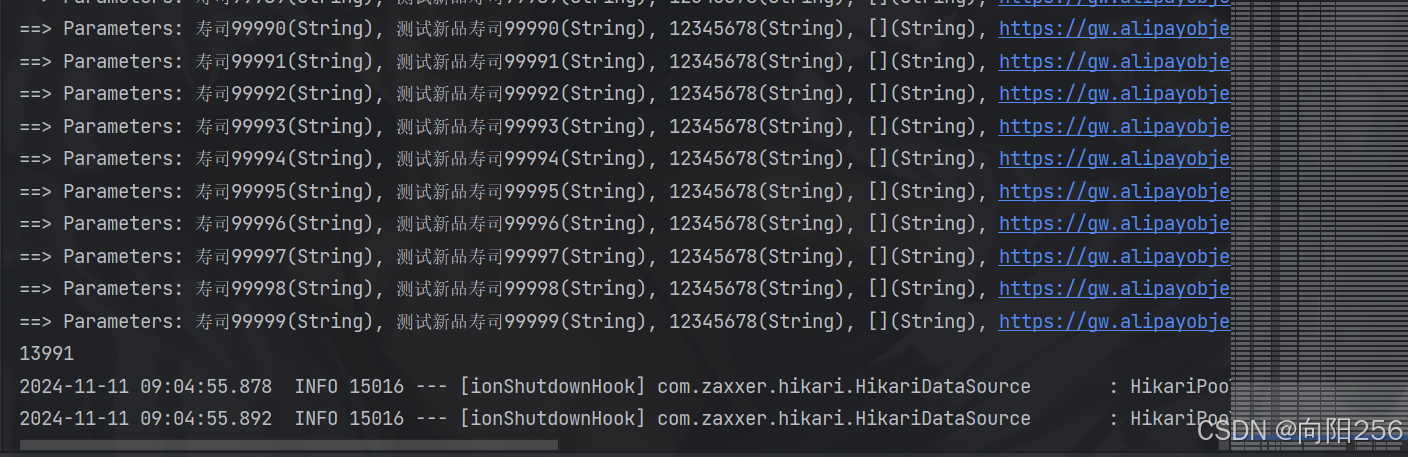
System.out.println(stopWatch.getTotalTimeMillis()); // 运行时间:13991ms
}
我们可以观察到,本次插入十万条数据仅仅用了将近14秒,这已经算是很快的速度了。我们通过每次批量插入数据的方式,大大减少了与数据库连接的次数,节省了大量时间。
使用线程池插入数据
我们还可以使用线程池来开启多个线程来异步执行,提高插入数据的速率。
在Java中,我们通常使用 CompletableFuture 来执行异步任务,在 CompletableFuture 中,Java默认使用系统的线程池,根据本机的 CPU核心数 - 1 来决定该线程池的线程个数。假如你是一个双核机器,那么你相当于没有线程池,还要多耗费资源。所以我们务必要自定义一个线程池。
在下面示例代码中,我们使用 new ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue) 自定义一个 线程池,我们来介绍一下创建线程池的时候这几个 参数 。
- corePoolSize – 要保留在池中的线程数,即使它们处于空闲状态,除非 allowCoreThreadTimeOut 已设置
- maximumPoolSize – 池中允许的最大线程数
- keepAliveTime – 当线程数大于内核数时,这是多余的空闲线程在终止之前等待新任务的最长时间。
- unit – 参数的时间
- keepAliveTime 单位
- workQueue ― 用于在执行任务之前保留任务的队列。此队列将仅 Runnable 保存该方法提交 execute 的任务。
示例代码:
// 自定义线程池
private ExecutorService executorService = new ThreadPoolExecutor(60, 1000, 10, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10000));
/**
* 并发插入批量用户
*/
@Test
void doConcurrencyInsertUser() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
final int INSERT_NUM = 100000;
// 分为十组,每组一万条
int j = 0;
int batchSize = 1000;
int group = INSERT_NUM / batchSize;
List<CompletableFuture<Void>> futureList = new ArrayList<>();
for (int i = 0; i < group; i++) {
List<User> userList = new ArrayList<>();
while (true) {
j++;
User user = new User();
user.setUsername("寿司" + i);
user.setUserAccount("测试新品寿司" + i);
user.setUserPassword("12345678");
user.setTags("[]");
user.setAvatarUrl("https://gw.alipayobjects.com/zos/rmsportal/KDpgvguMpGfqaHPjicRK.svg");
user.setGender(0);
user.setPhone("123123123");
user.setEmail("123123@qq.com");
user.setUserStatus(0);
user.setUserRole(0);
userList.add(user);
if (j % batchSize == 0) {
break;
}
}
// 异步执行
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
System.out.println("threadName:" + Thread.currentThread().getName());
userService.saveBatch(userList, batchSize);
}, executorService);
futureList.add(future);
}
CompletableFuture.allOf(futureList.toArray(new CompletableFuture[]{})).join();
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeMillis()); // 运行时间:5434ms
}
可以看出,我们执行的时间又大幅度降低了,仅仅用了五秒钟的时间!插入十万条数据仅用五秒钟是不是非常快了。当然我们还可以不断的尝试修改自定义线程池的线程数量,来取得最佳的时间。
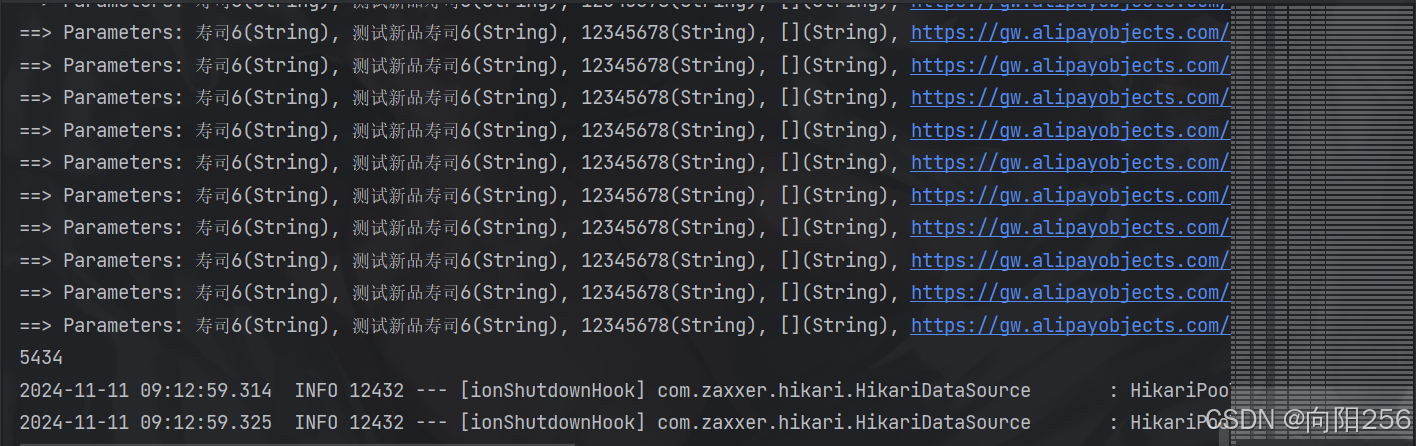
我们要知道,线程数量不是越多越好,线程之间的切换也是要耗费时间的,线程数量太少也不可以,因为一个线程可能会执行多个任务,也会耗费时间,我们要尝试取得一个中间值来实现使用效率最大化。
如何选择生成假数据的方法
我们可以根据实际情况去选择合适的方法去插入假数据。
- 如果数据量过小,我们直接采用SQL语句插入或者单次插入数据就好。
- 如果数据量过大,我们采用批量插入数据,或者可以采用更好的方法异步插入批量数据。
总而言之,我们根据实际情况去选择合适的方法😎。

——👦[作者]:向阳256
——⏳[更新]:2024.11.11
——🥰本人技术有限,如果有不对指正需要更改或者有更好的方法,欢迎到评论区留言。

















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









