







强调:尊重网站的爬虫规则十分重要,不要过度请求或者对网站造成过大的负载
1. 我们这里要用到两个库,requests 和 re。以及需要正则的一些用法
2. 大致流程
# 拿到页面源代码
# 编写正则
# 保存数据
3.常见的一些注意事项:
a.我们通常要确保是否需要解码,下面的步骤 可以及逆行判断:
"""
url = "....."
resp = requests.get(...)
print(resp.text)
如果返回为空 没有得到想要的值,就是要进行解码
"""
如果返回为空 没有得到想要的值(这个文本),就是要进行解码
b.
注意如果在得到文本中有乱码的存在,可以在文本中加入encording= utf-8,
resp.encoding='utf-8'c.我们爬取东西的时候最好使用 谷歌浏览器,会让你很便利
3.接下来我们进入正轨(我会在文中穿插一些知识点)
1.首先让我们找到网站的地址,复制下来
url = 'https://movie.douban.com/top250?start=0'注意这个start 在我们后面进行 阅历和提取剩下的24页,重要关键点
2.我们进行是否需要解码
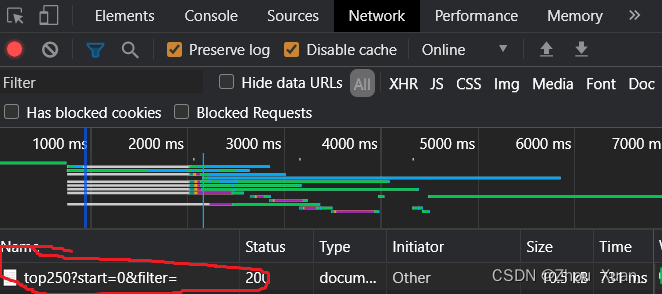
a.这个图可以在找到网页后使用f12键,上面调成Network,接着在进行网页刷新一下即可。

b.我们可以知道这是一个GET请求的, (一般来讲只有一些登录是POST请求,理解为上传是POSTGET,通常来说,POST 比 GET安全性更高)
c.网站 判断显示我们并不是通过浏览器就行搜索,对我们的访问进行拒绝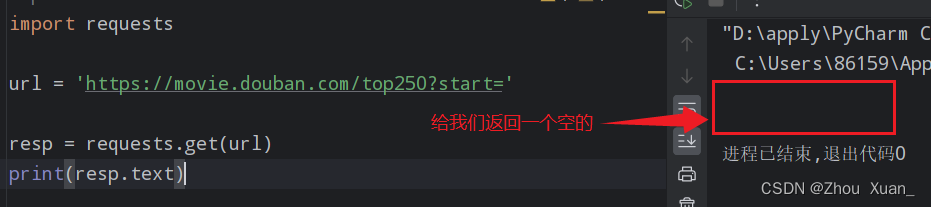
此时我们就需要进行反爬(这里举一个比较常用的 反爬方法)
这里我们可以提前把这个' '写好,等下复制 的时候就方便了

我们将整个User-Agent 给复制下来

注意接下来 ,可能会有一部分电脑出现错误(有的编译器不是utf-8导致,所以代码中需要添加)

3.好,接下来进入重点(re板块)
1. 在页面右键单击,点击查看页面源代码,以我的为例,我的某瓣第一是《肖申克的救赎》,按住CTRL +F, 进入查找,接下来的一部分,使用正则,我们爬虫经常使用的惰性匹配(.*?)
关于详细讲解在另一篇文章中讲解。
.*? 含义是粗糙的理解是将a到b之间全部匹配上,因直接发布源代码是错误且不道德的,接下来,我会举例进行讲解。
<div class="info">
<div class="aoyigei">
<a href="https://movie.douban.com/subject/6786002/" class="">
<span class="title">别管,我是电影</span>
<span class="title"> / Intouchables</span>
<span class="other"> / </span>
</a>
</div>
<div class="svj">
<p class="">
作者 无敌 sdnvsonv 主...<br>
2050 / 梦想国 / 喜剧
</p>
<div class="star">
<span class="rdbs"></span>
<span class=iy" property="v:average">9.3</span>
<span property="v:best" content="21"></span>
<span>1112235人评价</span>
</div>
<p class="dsmkv">
<span class="inq">让人难过的喜剧。</span>
</p>
</div>2.通过观察每一步的结构,我们可以知道每一部分的结构类似于像上面一样的结构,我们可以从这里开始<div class="aoyigei">进行正则
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p class="">.*?导演: (?P<director>.*?)<br>(?P<time>.*?) / '
r'(?P<tradition>.*?) .*?<span class="rating_num" property="v:average">'
r'(?P<score>.*?)</span>.*?<span>(?P<num>.*?)</span>')a.这里就是一直在用.*?对两个中间进行匹配
b.这里让我思考的是 .*?<p class="">.*?导演: , 为什么不是直接匹配到.*?导演:
正则表达式中“ . ”,可以匹配到除了换行符以外所有的任意字符
通常在使用完 正则后,我们要将正则用过后的提取出来,这里用finditer(),并且后面要遍历输出
result = obj.finditer(Page) c.这里展开与findall()进行比较:
finditer()函数和findall()函数的主要区别如下:
1. 返回值类型:finditer()函数返回一个迭代器对象,而findall()函数返回一个列表。
2. 遍历方式:通过finditer()函数返回的迭代器对象可以使用迭代器(for循环)方式逐个访问匹配结果;而使用findall()函数返回的列表可以直接访问其中的元素。
3. 内存占用:findall()函数返回的是一个完整的列表,如果匹配结果较多或字符串较大,可能会占用较多的内存空间;而finditer()函数返回的是一个迭代器对象,只在需要的时候才生成匹配结果,可以节省内存空间。
4. 使用场景:finditer()函数适用于需要逐个处理每个匹配结果的场景,比如对每个匹配结果进行进一步处理或分析;而findall()函数适用于需要获取所有匹配结果,并对结果进行整体处理的场景。
综上所述,finditer()和findall()函数在功能上是类似的,都用于查找所有匹配正则表达式的结果,只是返回值类型和使用方式略有不同。根据具体的需求,可以选择适合自己的函数使用。
d.然后是进行遍历:
for item in result:
name = item.group('name')
director = item.group('director')
time = item.group('time')
tradition = item.group('tradition')
score = item.group('score')
num = item.group('num')
print(name, director, time, tradition, score, num)
那么接下来我们有一个疑问,如何将250条都给做出来,然后放进一个文件里呢?
前面我们说到,start = 0 ,我们是否可以通过for循环进行遍历得出呢?
如何将得到的内容放进一个文件呢?
我们知道一页是20个,那么 20 * page ,如此通过for循环,让 page 从0到24,实际上循环了25次
for page in range(25):
url = f"https://movie.douban.com/top250?start={page}"至于另一个问题就是写入文件了
f = open('top250csv', mode = 'w', encoding = 'utf-8')
# 写入参数
f.write( , , ,)
f.close()上述 是每一步的思考,如果你全部理解了,那么恭喜你掌握了。下面是完整代码:
# 拿到页面源代码
# 编写正则
# 保存数据
import re
import requests
"""
url = "....."
resp = requests.get(...)
print(resp.text)
诺返回为空 没有得到想要的值,就是要进行解码
"""
f = open('top250.csv', mode='w', encoding='utf-8')
for page in range(10):
url = f"https://movie.douban.com/top250?start={page * 25}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/86.0.4240.198 Safari/537.36'
}
resp = requests.get(url, headers=headers)
# 如果出现乱码问题, 使用 resp.encoding = 'utf-8'
PageSource = resp.text
# 编写正则表达式
# 记住第一步先在里面写上r''
# obj -> 目的 compile -> 汇编
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<title>.*?)</span>'
r'.*?<p class="">.*?导演: .*?(?P<dao>.*?) .*?'
r'<br>(?P<time>.*?) / (?P<tradition>.*?) / .*?<span>'
r'(?P<population>.*?)</span>', re.S)
result = obj.finditer(PageSource)
for item in result:
title = item.group("title")
dao = item.group("dao")
time = item.group("time").strip()
tradition = item.group("tradition")
population = item.group("population")
f.write(f"{title},{dao},{time},{tradition},{population}\n")
# 标题 导演 时间 国家 人数
# print(title, dao, time, tradition, population)
print('ok')
"""
strip()
1.strip() 除去 用于去除两边的字符串
2.该方法的含义是:从字符串的开头和结尾一直往中间逐个字符检查,如果该字符在指定的字符集合中,则将其从字符串中去除。
3..strip('a') 这里的a要包括你要删除的,这个里面有啥符号就是你要删出的
1.正则表达式是不能够换行,但是python 可以。我们在使用的过程中,会有换行的情况,使用re.S
"""















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











