







 回归分析起源于高尔顿的研究,用于数值预测和实证分析。本文聚焦预测模型的构建,介绍基于机器学习的线性回归,通过损失函数(如均方误差)评估模型,并使用梯度下降进行参数优化。讨论了模型泛化、欠拟合和过拟合问题,以及防止过拟合的正则化技术。并以Pokemon精灵攻击力预测为例,展示了回归模型的构建过程。
回归分析起源于高尔顿的研究,用于数值预测和实证分析。本文聚焦预测模型的构建,介绍基于机器学习的线性回归,通过损失函数(如均方误差)评估模型,并使用梯度下降进行参数优化。讨论了模型泛化、欠拟合和过拟合问题,以及防止过拟合的正则化技术。并以Pokemon精灵攻击力预测为例,展示了回归模型的构建过程。
1. 回归(regression)
1.1 起源与定义
回归最早是被高尔顿提出的。他通过研究发现:如果父母都比较高一些,那么生出的子女身高会低于父母的平均身高;反之,如果父母双亲都比较矮一些,那么生出的子女身高要高于父母平均身高。他认为,自然界有一种约束力,使得身高的分布不会向高矮两个极端发展,而是趋于回到中心,所以称为回归。
目前,从用法角度将其定义为一种数值(scalar)预测的技术,区别于分类(类别预测技术)。
1.2 不同的用法
1.2.1 解释(Explanation)
回归可用于做实证研究,研究自变量和因变量之间的内在联系和规律,常见于社会科学研究中。
- 互联网的普及降低了教育不平等程度吗?
- 大学生就业选择的影响因素有哪些?
- 医疗电子商务场景下客户满意度的影响因素有哪些?
1.2.2 预测(Prediction)
回归也可用来做预测,根据已知的信息去准确预测未知的事情。
- 股市预测:根据过去10年股票的变动、新闻咨询、公司并购咨询等,预测股市明天的平均值。
- 商品推荐:根据用户过去的购买记录和候选的商品信息,预测用户购买某个商品的可能性。
- 自动驾驶:根据汽车的各个sensor的数据,例如路况和车距等,预测正确的方向盘角度。
1.3 模型的构建
无论目的是解释还是预测,都需要掌握与任务相关的规律(认识世界),即建立合理的模型。
不同的一点是,解释模型只需要基于训练集构建,一般具备解析解(计量经济模型)。 预测模型必须在测试集上做检验和调整,一般不具备解析解,需要通过机器学习的方法去调整参数。因此,同样的模型框架和数据集,最优的解释模型和预测模型很可能是不相同的。
本文主要关注预测模型的构建,不涉及解释模型相关的内容。
2. 基于机器学习的模型构建
我们以Pokemon精灵攻击力预测这个任务为例,梳理机器学习三个步骤的详细内容。
- 输入:进化前的CP值、物种(Bulbasaur)、血量(HP)、重量(Weight)、高度(Height)
- 输出:进化后的CP值

2.1 模型假设 - 线性模型
为了方便,我们选择最简单的线性模型来作为完成回归任务的模型框架。我们可以使用单特征或者多特征的线性回归模型,后者会更加复杂,模型集合会更大。
 为选择合理的模型框架,提前对数据集进行探索,观察变量间的关系是很有必要的,这将决定最终将哪些变量放入模型,以及是否需要对变量进行再次处理(二次项、取倒数等)。
为选择合理的模型框架,提前对数据集进行探索,观察变量间的关系是很有必要的,这将决定最终将哪些变量放入模型,以及是否需要对变量进行再次处理(二次项、取倒数等)。
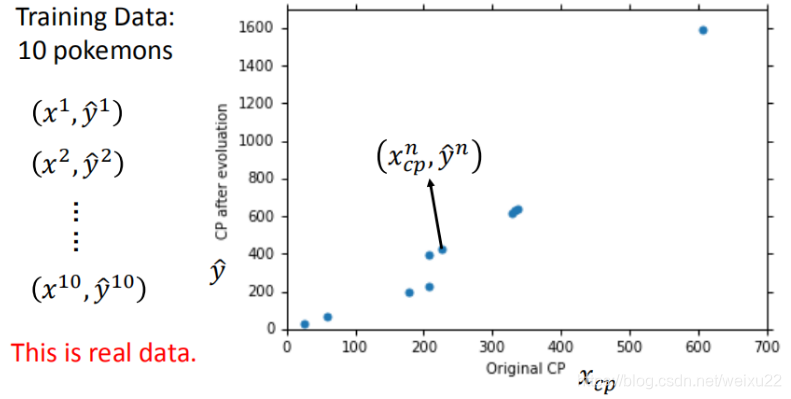
可以看出,横轴和纵轴主要呈直线关系,也有一些二次关系(可考虑加二次项)。
模型框架(预先设定) + 参数(待估计) = 模型(目标)
目前模型的参数包括各个特征的权重 w i w_i wi 以及偏移量 b b b。
2.2 模型评价 - 损失函数
本文阐述的回归任务属于有监督学习场景,因此需要收集足够的输入输出对以指导模型的构建。

有了这些真实的数据,那我们怎么衡量模型的好坏呢?从数学的角度来讲,我们使用损失函数(Loss function) 来衡量模型的好坏。Loss function基于模型预测值和实际值的差异来设置。

在本文中,我们选择常用的均方误差作为损失函数。
2.3 模型调优 - 梯度下降
当模型非凸时,是没有解析解的,只能通过启发式的方式迭代优化,常用的方法是梯度下降。

首先,我们随机选择一个 w 0 w^0 w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









