







Map接口
Map没有继承Collection接口,提供3种集的视图;
其内容可以被当作一组key的集KeySet,一组value的集Values,和一组key-value映射EntrySet;
要遍历一个Map可以从这三个视图入手,根据不同的需要使用相应的视图。
| 视图 | 对应集 | 其他特性 |
|---|---|---|
Set<K> KeySet | key的集 | 待完善 |
Clloection<V> Values | value的集 | 待完善 |
Set<Map.Entry<K,V> > EntrySet | key-value映射集 | 待完善 |
1 Map实现类
1.1 Hashtable
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
......
}
Hashtable实现Map接口继承Dictionary,实现一个key-value映射的哈希表。
任何非空(non-null)的对象都可作为key或者value。
添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。
1.1.1 构造方法
它有三个构造方法:
构造方法1:入参为初始容量(initialCapacity)和装填因子(loadFactor)
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
initHashSeedAsNeeded(initialCapacity);
}
构造方法2:入参为初始容量(initialCapacity)
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
构造方法3:无参的构造方法
public Hashtable() {
this(11, 0.75f);
}
构造方法3生成的hashtable容量为11,装填因子为0.75,也就是当该hashtable的数据达到容量的3/4[11×0.75=8]的时候会进行扩容同时进行再散列(rehash()),代码主要是put方法中执行这个动作:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
......
......
//第一个构造方法中
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}
扩容:会将容量增致原容量的两倍,新容量为:11*2+1=23
//rehash()方法中
int newCapacity = (oldCapacity << 1) + 1;
1.1.2 同步机制
Hashtable是线程安全的,关键方法都是同步的:
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
圈中的都是同步的方法:
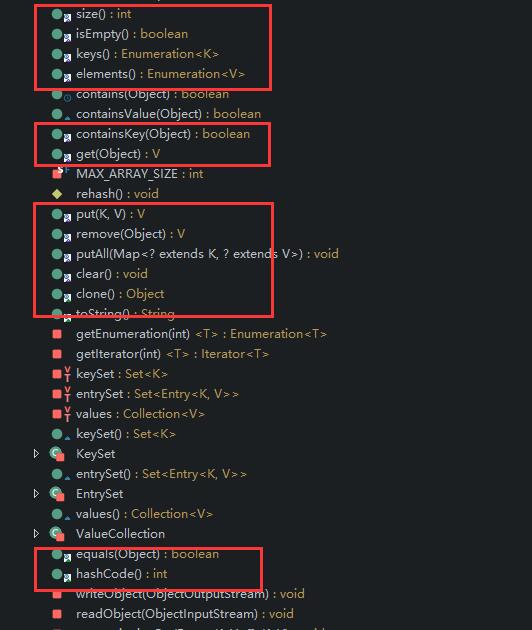
1.1.3 小结
Hashtable 的实例有两个参数影响其性能:初始容量initial capacity 和加载因子load factor;
由所有类的“collection 视图方法”返回的 collection 的 iterator 方法返回的迭代器都是快速失败 的;
在创建 Iterator 之后,如果从结构上对 Hashtable 进行修改,除非通过 Iterator 自身的 remove 方法;
否则在任何时间以任何方式对其进行修改,Iterator 都将抛出ConcurrentModificationException;
因此,面对并发的修改,Iterator 很快就会完全失败,而不冒在将来某个不确定的时间发生任意不确定行为的风险;
Hashtable 的键和元素方法返回的 Enumeration 不是快速失败的。
1.2 HashMap类
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
......
}
HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。
1.2.1 构造方法
HashMap有跟Hashtable一样的三个构造方法,不同的是不带参数的那个:
//static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
HashMap初始容量为16,加载因子也为0.75。
迭代集合视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)的和成比例;
如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低),
容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。如果很多映射关系要存储在 HashMap 实例中,则相对于按需执行自动的 rehash 操作以增大表的容量来说,使用足够大的初始容量创建它将使得映射关系能更有效地存储。
加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,默认加载因子 (.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。
当哈希表中的条目数超出了加载因子与当前容量的乘积时,通过调用 rehash 方法将容量翻倍。
1.2.2 同步机制
HashMap不是同步的。
如果多个线程同时访问此映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
结构上的修改是指添加或删除一个或多个映射关系的操作;仅改变与实例已经包含的键关联的值不是结构上的修改。
这一般通过对自然封装该映射的对象进行同步操作来完成,HashMap不存在这样的方法,
则应该使用 Collections.synchronizedMap 方法来“包装”该映射。
在创建时完成这一操作,以防止对映射进行意外的不同步访问,如下所示:
Map map = Collections.synchronizedMap(new HashMap(...));
由所有此类的“集合视图方法”所返回的迭代器都是快速失败的。
1.2.3 HashMap的遍历
Map的实现基本上都是这样遍历的,使用的是Map提供的三个视图:
- 1 entrySet().iterator()
Map map = new HashMap();
for (int i = 0; i < 1000000; i++) {
map.put(i, i);
}
Iterator iterator = map.entrySet().iterator();
long begin = System.currentTimeMillis();
while (iterator.hasNext()) {
Entry next = (Entry) iterator.next();
Object key = next.getKey();
Object value = next.getValue();
// System.out.println(">>>>>key>>>>>" + next.getKey() + ">>>>>value>>>" +
// next.getValue());
}
long end = System.currentTimeMillis();
System.out.println("---myHashMap1 - cost---" + (end - begin));
- 2 keySet()
Map map = new HashMap();
for (int i = 0; i < 1000000; i++) {
map.put(i, i);
}
long begin = System.currentTimeMillis();
for (Object obj : map.keySet()) {
Object key = obj;
Object value = map.get(key);
// System.out.println(">>>>>key>>>>>" + key + ">>>>>value>>>" + map.get(key));
}
long end = System.currentTimeMillis();
System.out.println("---myHashMap2 - cost---" + (end - begin));
- 3 entrySet()
Map map = new HashMap();
for (int i = 0; i < 1000000; i++) {
map.put(i, i);
}
long begin = System.currentTimeMillis();
for (Object object : map.entrySet()) {
Map.Entry<Integer, Integer> entry = (Entry<Integer, Integer>) object;
Integer key = entry.getKey();
Integer value = entry.getValue();
// System.out.println(">>>>>key>>>>>" + entry.getKey() + ">>>>>value>>>" +
// entry.getValue());
}
long end = System.currentTimeMillis();
System.out.println("---myHashMap3 - cost---" + (end - begin));
结果:
---myHashMap1 - cost---20
---myHashMap2 - cost---22
---myHashMap3 - cost---15
1.2.4 put方法
HashMap的put方法:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)//如果key为空的情况
return putForNullKey(value);
int hash = hash(key);//计算key的hash值
int i = indexFor(hash, table.length); //计算该hash值在table中的下标
for (Entry<K,V> e = table[i]; e != null; e = e.next) {//对table[i]存放的链表进行遍历
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;//把新的值赋予给对应键值
e.recordAccess(this);//空方法,留待实现
return oldValue;//返回相同键值的对应的旧的值
}
}
modCount++;//结构性更改的次数+1
addEntry(hash, key, value, i); //把当前key,value添加到table[i]的链表中
return null;//没有相同的键值返回
put 其实是一个有返回的方法,它会把相同键值的 put 覆盖掉并返回旧的值, HashMap 的结构是一个table加上在相应位置的Entry的链表。
public Object put(Object key, Object value) {
Object k = maskNull(key);
put方法中这段是判断键值是否为空,如果为空,它会返回一个static Object 作为键值,这就是HashMap允许空键值的原因。
int hash = hash(k);
int i = indexFor(hash, table.length);
hash 就是通过 key 这个Object的 hashcode 进行 hash计算,正确的返回索引,然后通过 indexFor 获得在Object table的索引值。对于hash操作,最重要也是最困难的就是如何确定hash的位置:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
计算该hash值在table中的下标:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 :
//"length must be a non-zero power of 2";
return h & (length-1);
}
计算了hash值,并用该hash值来求得哈希表中的索引值之后,如何把该key-value插入到该索引的链表中:
调用 addEntry(hash, key, value, i) 方法:
首先取得bucketIndex位置的Entry头结点,并创建新节点,把该新节点插入到链表中的头部,该新节点的next指针指向原来的头结点 。
//addEntry方法
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果size大于极限容量,将要进行重建内部数据结构操作,之后的容量是原来的两倍,
//并且重新设置hash值和hash值在table中的索引值
if ((size >= threshold) && (null != table[bucketIndex])) {
//threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//threshold 是实际容纳的量
resize(2 * table.length);//容量扩至初始容量的两倍
hash = (null != key) ? hash(key) : 0;
//这一步就是对null的处理,如果key为null,hash值为0,也就是会插入到哈希表的表头table[0]的位置
bucketIndex = indexFor(hash, table.length);
}
//真正创建Entry节点的操作
createEntry(hash, key, value, bucketIndex);
}
//createEntry方法
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
这里有两点需要注意:
- 1 链的产生
这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。
如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。 - 2 扩容问题
还记得HashMap中的一个变量吗,threshold,这是容器的容量极限,还有一个变量size,这是指HashMap中键值对的数量,也就是node的数量
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
1.2.5 汇总
HashMap是声明了Map,Cloneable, Serializable 接口,和继承了AbstractMap类,里面的Iterator主要都是其内部类HashIterator 和其他几个iterator类实现,还有一个很重要的继承了Map.Entry的 Entry 内部类;
Entry 内部类,它包含了hash,value,key 和next 这四个属性,很重要。
- 1 传入key和value,判断key是否为null,如果为null,则调用putForNullKey,以null作为key存储到哈希表中;
- 2 然后计算key的hash值,根据hash值搜索在哈希表table中的索引位置,若当前索引位置不为null,则对该位置的Entry链表进行遍历,如果链中存在该key,则用传入的value覆盖掉旧的value,同时把旧的value返回,结束;
- 3 否则调用addEntry,用key-value创建一个新的节点,并把该节点插入到该索引对应的链表的头部
1.3 LinkedHashMap
LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同。
LinkedHashMap可以用来实现LRU算法(这会在下面的源码中进行分析)。
LinkedHashMap同样是非线程安全的,只在单线程环境下使用。
在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比 LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
1.4 WeakHashMap类
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
1.5 Map实现类总结
由于作为key的对象将通过计算其散列函数来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方法。
hashCode和equals方法继承自根类Object,如果你用自定义的类当作key的话,要相当小心,按照散列函数的定义,如果两个对象相同,
即obj1.equals(obj2)=true,则它们的hashCode必须相同,但如果两个对象不同,则它们的hashCode不一定不同,如果两个不同对象的hashCode相同,这种现象称为冲突,冲突会导致操作哈希表的时间开销增大,所以尽量定义好的hashCode()方法,能加快哈希
表的操作。
如果相同的对象有不同的hashCode,对哈希表的操作会出现意想不到的结果(期待的get方法返回null),要避免这种问题,只需要牢记一条:要同时复写equals方法和hashCode方法,而不要只写其中一个。HashMap和Hashtable (table是小写)
a.HashMap不是线程安全的;HashTable是线程安全的,其线程安全是通过Sychronize实现。
b.由于上述原因,HashMap效率高于HashTable。 c.HashMap的键可以为null,HashTable不可以。
d.多线程环境下,通常也不是用HashTable,因为效率低。HashMap配合Collections工具类使用实现线程安全。
同时还有ConcurrentHashMap可以选择,该类的线程安全是通过Lock的方式实现的,所以效率高于Hashtable。















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









