








一.线段树
1.1引例
A.给出n个数,n<=100,和m个询问,每次询问区间[l,r]的和,并输出。
一种回答:这也太简单了,O(n)枚举搜索就行了。
另一种回答:还用得着o(n)枚举,前缀和o(1)就搞定。
那好,我再修改一下题目。
B.给出n个数,n<=100,和m个操作,每个操作可能有两种:1、在某个位置加上一个数;2、询问区间[l,r]的和,并输出。
回答:o(n)枚举。
动态修改最起码不能用静态的前缀和做了。
好,我再修改题目:
C.给出n个数,n<=1000000,和m个操作,每个操作可能有两种:1、在某个位置加上一个数;2、询问区间[l,r]的和,并输出。
回答:o(n)枚举绝对超时。
再改:
D,给出n个数,n<=1000000,和m个操作,每个操作修改一段连续区间[a,b]的值
回答:从a枚举到b,一个一个改。。。。。。有点儿常识的人都知道超时
那怎么办?这就需要一种强大的数据结构:线段树。(用于解决区间问题)
1.2基本概念
1、线段树是一棵二叉搜索树,它储存的是一个区间的信息。(不是完全二叉树)
2、每个节点以结构体的方式存储,结构体包含以下几个信息:
区间左端点、右端点;(这两者必有)
这个区间要维护的信息(事实际情况而定,数目不等)。
3、线段树的基本思想:二分。
4、线段树一般结构如图所示:
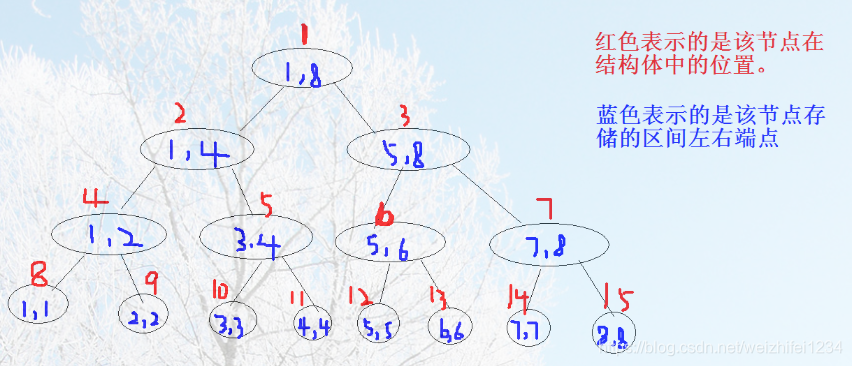
5、特殊性质:
由上图可得,
1、每个节点的左孩子区间范围为[l,mid],右孩子为[mid+1,r]
2、对于结点k,左孩子结点为2*k,右孩子为2*k+1,这符合完全二叉树的性质
class TreeNode:
l,r,w=0,0,0
node=[]#这个如果要固定空间的话为4n+1,n是结点数线段树的基础操作主要有5个:
建树、单点查询、单点修改、区间查询、区间修改。
# -*- coding: utf-8 -*-
class SegmentTree:
"""线段树类"""
def __init__(self, alist, merger_):
"""
Description: 线段树的构造函数
Params:
- alist: 用户传入的一个list(这里我们就不用以前实现的Arr类了,直接用python的list啦,如果想用的话也是一点问题都没有的~)
- func: merge函数,用于对实现两个数合成一个数的功能(比如二元操作符加法、乘法……等等)
"""
self._data = alist[:] # 所以为了不改变传入的数组,需要传其副本
self._tree = [None] * 4 * len(self._data) # 注意是4倍的存储空间,初始化元素全是None
# self._tree = [None for i in range(len(self._data) * 4)]
self._merger = merger_ # merger函数,比如两个元素求和函数……,用lambda表达式比较方便
self._buildSegmentTree(0, 0, len(self._data)-1) # 调用self._buildSegmentTree来构建线段树
def getSize(self):
"""
Description: 获取有效元素的个数
Returns:
有效元素个数
"""
return len(self._data)
def get(self, index):
"""
Description: 根据索引index获取相应元素
时间复杂度:O(1)
Params:
- index: 传入的索引
Returns:
index索引处的元素值
"""
if index < 0 or index >= len(self._data):
raise Exception('Index is illegal!')
return self._data[index]
def query(self, quaryL, quaryR):
"""
Description: 查找[quaryL, quaryR]这个左闭右闭区间上的值(例如对于求和操作就是求这个区间上所有元素的和)
时间复杂度:O(logn)
Params:
- quaryL: 区间左端点的索引
- quaryR: 区间右端点的索引
Returns:
[quaryL, quaryR]区间上的值
"""
if quaryL < 0 or quaryR < 0 or quaryL >= self.getSize() or quaryR >= self.getSize() or quaryR < quaryL: # 索引合法性检查
raise Exception('The indexes is illegal!')
return self._query(0, 0, self.getSize()-1, quaryL, quaryR) # 调用self._quary函数
def set(self, index, e):
"""
Description: 将数组中index位置的元素设为e,因此此时需要对线段树的内容要进行更新操作(也就是线段树的更新操作)
时间复杂度:O(logn)
Params:
- index: 数组中的索引
- e: 索引index上元素的新值e
"""
if index < 0 or index >= self.getSize():
raise Exception('The index is illegal!')
self._data[index] = e # 更新self._data
self._set(0, 0, len(self._data) - 1, index, e) # 调用self._set函数
def printSegmentTree(self):
"""对线段树进行打印"""
print('[', end=' ')
for i in range(len(self._tree)):
if i == len(self._tree) - 1:
print(self._tree[i], end=' ]')
break
print(self._tree[i], end=',')
# private
def _leftChild(self, index):
"""
Description: 和最大堆一样,由于线段树是一颗完全二叉树,所以可以通过索引的方式找到其左、右孩子的索引(元素从索引0开始盛放)
Params:
- index: 输入的索引
Returns:
左孩子的索引值
"""
return 2 * index + 1 # 一定要记住线段树是一棵满树哦,所以用数组就能表示这棵树了,索引关系也和堆是一样的,只不过不需要求父亲节点的索引了
def _rightChild(self, index):
"""
Description: 和最大堆一样,由于线段树是一颗完全二叉树,所以可以通过索引的方式找到其左、右孩子的索引(元素从索引0开始盛放)
Params:
- index: 输入的索引
Returns:
右孩子的索引值
"""
return 2 * index + 2
def _buildSegmentTree(self, treeIndex, left, right):
"""
Description: 以根节点索引为treeIndex,构造self._data索引在[left, right]上的线段树
Params:
- treeIndex: 线段树根节点的索引
- left: 数据左边的索引
- right: 数据右边的索引
"""
if left == right: # 递归到底的情况,left == right,此时只有一个元素
self._tree[treeIndex] = self._data[left] # 相应的,self._tree上索引为treeIndex的位置的值置为self._data[left]就好
return
leftChild_index = self._leftChild(treeIndex) # 获取左孩子的索引
rightChild_index = self._rightChild(treeIndex) # 获取右孩子的索引
mid = left + (right - left) // 2 # 获取left和right的中间值,在python中,可以用(left + right) // 2的方式来获得mid,因为不存在数值越界问题
self._buildSegmentTree(leftChild_index, left, mid) # 递归向左孩子为根的左子树构建线段树
self._buildSegmentTree(rightChild_index, mid + 1, right) # 递归向右孩子为的右子树构建线段树
self._tree[treeIndex] = self._merger(self._tree[leftChild_index], self._tree[rightChild_index]) # 在回归的过程中,用self._merger函数对两个子节点的值进行merger操作,从而完成整棵树的建立
def _query(self, treeIndex, left, right, quaryL, quaryR):
"""
Description: 在根节点索引为treeindex的线段树上查找索引范围为[quaryL, quaryR]上的值,其中left, right值代表该节点所表示的索引范围(左闭右闭)
Params:
- treeIndex: 根节点所在的索引
- left: 根节点所代表的区间的左端的索引值(注意是左闭右闭区间哦)
- right: 根节点所代表的区间的右端点的索引值
- quaryL: 待查询区间的左端的索引值(也是左闭右闭区间)
- quaryR: 待查询区间的右端的索引值
"""
if left == quaryL and right == quaryR: # 递归到底的情况,区间都对上了,直接返回当前treeIndex索引处的值就好
return self._tree[treeIndex] # 返回当前树上索引为treeIndex的元素值
mid = left + (right - left) // 2 # 获取TreeIndex索引处所代表的范围的中点
leftChild_index = self._leftChild(treeIndex) # 获取左孩子的索引
rightChild_index = self._rightChild(treeIndex) # 获取右孩子的索引
if quaryL > mid: # 此时要查询的区间完全位于当前treeIndex所带表的区间的右侧
return self._query(rightChild_index, mid + 1, right, quaryL, quaryR) # 直接去右子树找[quaryL, quaryR]
elif quaryR <= mid: # 此时要查询的区间完全位于当前treIndex所代表的区间的左侧
return self._query(leftChild_index, left, mid, quaryL, quaryR) # 直接去左子树找[quaryL, quaryR]
# 此时一部分在[left, mid]上,一部分在[mid + 1, right]上
leftResult = self._query(leftChild_index, left, mid, quaryL, mid) # 在左子树找区间[quaryL, mid]
rightResult = self._query(rightChild_index, mid + 1, right, mid + 1, quaryR) # 在右子树找区间[mid + 1, quaryR]
return self._merger(leftResult, rightResult) # 最后在回归的过程中两个子节点进行merger操作并返回,得到[quaryL, quaryR]区间上的值
def _set(self, treeIndex, left, right, index, e):
"""
Description: 在以索引treeIndex为根节点的线段树中将索引为index的位置的元素设为e(此时treeIndex索引处所代表的区间范围为:[left, right]
params:
- treeIndex: 传入的线段树的根节点索引值
- left: 根节点所代表的区间的左端的索引值
- right: 根节点所代表的区间的右端点的索引值
- index: 输入的索引值
- e: 新的元素值
"""
if left == right: # 递归到底的情况,也就是在树中找到了索引为index的元素
self._tree[treeIndex] = e # 直接替换
return
mid = left + (right - left) // 2 # 找到索引中间值
leftChild_index = self._leftChild(treeIndex) # 左孩子索引值
rightChild_index = self._rightChild(treeIndex) # 右孩子索引值
if index <= mid: # index处于当前treeIndex所代表的区间的左半区
self._set(leftChild_index, left, mid, index, e) # 到左子树去找index
else: # 否则index处于当前treeIndex所代表的区间的右半区
self._set(rightChild_index, mid + 1, right, index, e) # 到右子树去找index
self._tree[treeIndex] = self._merger(self._tree[leftChild_index], self._tree[rightChild_index]) # 由于对树的最底层元素进行了更新操作,因此需要对树的上层也进行一次更新,所以每次回归的都调用merger操作进行上层的值的更新操作
test
from segmenttree import SegmentTree # 我们的SegmentTree类写在了segmenttree.py文件中
input_list = [-2, 0, 3, -5, 2, -1]
test_st = SegmentTree(input_list, merger_=lambda x, y: x+y) # 这里以求和为例
test_st.printSegmentTree()
print()
print('索引区间[0, 4]上的元素的和为:', test_st.query(0, 4))
print('将索引为0的元素置为10:')
test_st.set(0, 10)
print('此时索引区间[0, 4]上的元素的和为:', test_st.query(0, 4))
这个数据结构属于高级数据结构,一般面试不会用到,并且还有很多牛逼的操作我并没有实现(能力不足)。
线段树适用于无元素添加、删除的数组,并且求解的问题是区间内的问题,用线段树要比常规的O(n)解法快很多(比如求区间内元素的和),毕竟是O(logn)的时间复杂度嘛。
如果不是比赛神马的,没必要掌握的过于深入。
数据结构,这个同志讲的特别好。
二.字典树
2.1引例
字典是干啥的?查找字的。
字典树自然也是起查找作用的。查找的是啥?单词。
看以下几个题:
1、给出n个单词和m个询问,每次询问一个单词,回答这个单词是否在单词表中出现过。
答:简单!map,短小精悍。
好。下一个
2、给出n个单词和m个询问,每次询问一个前缀,回答询问是多少个单词的前缀。
答:map,把每个单词拆开。
judge:n<=200000,TLE!
这就需要一种高级数据结构——Trie树(字典树)
2.2原理
在本篇文章中,假设所有单词都只由小写字母构成
对cat,cash,app,apple,aply,ok 建一颗字典树,建成之后如下图所示

由此可以看出:
1、字典树用边表示字母
2、有相同前缀的单词公用前缀节点,那我们可以的得出每个节点最多有26个子节点(在单词只包含小写字母的情况下)
3、整棵树的根节点是空的。为什么呢?便于插入和查找,这将会在后面解释。
4、每个单词结束的时候用一个特殊字符表示,图中用的‘′,那么从根节点到任意一个‘′,那么从根节点到任意一个‘’所经过的边的所有字母表示一个单词。
操作
插入,查找,删除














 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









